はじめに
ここでは、下記のコロナウイルスに関するデータを使いながら、時系列データの類似度合いを可視化しつつ探索する。データの詳細は下記のページを参照。
- EDA Salon 第9回 - コロナウイルスのデータ_東洋経済オンライン「新型コロナウイルス 国内感染の状況」
- Googleトレンド_キーワード_マスク_47都道府県データ_ 直近3ヶ月分 by Wasabi_sugiaki
- Googleトレンド_キーワード_コロナ_47都道府県データ_ 直近3ヶ月分 by wasabi_sugiaki
ちなみに、これといった結論はでてない…笑…泣…Orz
感染状況や関連情報の可視化
まずは、日本のコロナウイルス感染者数の推移や、特定のキーワードの検索指数(Googleトレンド)を可視化してみる。
日本のコロナウイルス感染者数の推移
まずは、EDA Salon 第9回 - コロナウイルスのデータを使って、日本の感染者数の推移を可視化する。オレンジは累計感染者数。
ウイルス感染の推移なので、指数関数的に増加していることがわかる。下記の動画の説明がわかりよい。
「コロナ」のGoogle検索トレンド
次は、Googleトレンド_キーワード_マスク_47都道府県データ_ 直近3ヶ月分 by Wasabi_sugiakiを使って、都道府県別にキーワード「コロナ」のGoogleでの検索指数を可視化してみる。いくつかスパイクしている部分があるが、その都道府県で感染者が確認されたりすると、そうなるみたい。
感染者数の推移と同じように、徐々に検索指数が上昇している。
「マスク」のGoogle検索トレンド
Googleトレンド_キーワード_コロナ_47都道府県データ_ 直近3ヶ月分 by wasabi_sugiakiを使って、都道府県別にキーワード「マスク」のGoogleでの検索指数を可視化してみる。さきほどの「コロナ」の場合は、その都道府県で感染者でスパイクした部分があったが、その時期辺りに「マスク」の検索指数は多くの都道府県で検索指数がスパイクしている。そして、一旦おさまり、再度上昇している。
検索指数は、他のキーワードとの相対的な数値なので、単純に説明はできないが、日本のどこかで「コロナ」の感染者がでると、日本全国で予防するために「マスク」を検索している結果なのかもしれない。
時系列の類似度合い
ここからは、都道府県別にGoogleトレンドの「コロナ」と「マスク」の時系列の類似度合いを、複数の距離や相関のアルゴリズムを使って、可視化していく。検索指数は0~100なので、標準化などはしていない。
つまり、どこの都道府県であれば、「コロナ」と「マスク」の検索指数の時系列データは似たような動きになるのかを探索していく。
使うアルゴリズムは「DTW(Dynamic Time Warping)/動的時間伸縮法」「ピアソンの相関係数」「ユークリッド距離」「コサイン類似度」の4つ。時系列データには適してないものもあるかもしれないが、一旦触れないでおく。
先にお断りとして記載しますが、因果の話をするわけではない。また、各アルゴリズムの解説をするわけでもない。
DTM
まずは、時系列データの類似度合いといえばお馴染みのDTW。都道府県ごとにGoogleトレンドの「コロナ」と「マスク」の時系列の類似度合いを、DTWで計算した。
下記は、都道府県別のDTWのコストの一覧。DTWは大きいと似ておらず、小さいほど似ているといえる。「秋田県」が最も類似しておらず、「福井県」が最も類似している。
DTWの距離が最も小さい「福井県」の「コロナ」と「マスク」の検索トレンド。確かに似ている。
「コロナ」と「マスク」の検索トレンドが類似していない都道府県 DTWの距離が最も大きい「秋田県」の「コロナ」と「マスク」の検索トレンド。確かに似ていない。
ピアソンの相関係数
2つ目は、連続変数間のデータの関係性といえばお馴染みのピアソンの相関係数。相関係数は、2変数が連動して変化する度合いを測定しているので、1または-1に近いと連動していて、0に近いほど連動しない。Datasaurusみたいなこともあるので、そこは気をつける。
 Source |
Source | 下記は、都道府県別の相関係数の一覧。
時系列データでピアソンの相関係数を使うと、色々と問題がありますが、ここでは触れませんので、知りたい場合は検索してください。
ピアソンの相関係数が最も大きのは、「愛知県」の「コロナ」と「マスク」の検索トレンド。先ほどとは異なり、上がったら、下がるみたいな連動して変化するところを捉えているのが相関係数らしさがある。DTWは、このあたりはコストが大きくなる要因なので、こういう系列は類似しているとは判定されにくいんだろう。
相関係数が0に近いのはさきほど同様に「秋田県」の「コロナ」と「マスク」の検索トレンド。
時系列データの一番の特徴は、「時間経過による変化」が値に反映されている点なので、その時間の流れを計算として考慮しないピアソンの相関係数は、下記のようなデータの相関を計算しているのと同じ。時間を考慮してない「コロナ」と「マスク」の検索指数の関係性。
ユークリッド距離
3つ目は、距離といえばお馴染みのユークリッドの距離。ユークリッドの距離は、小さいと似ており、大きいと似ていないといえる。似ているというか距離が近い。下記は、都道府県別のユークリッド距離の一覧。
ユークリッド距離が最も小さいの「福井県」の「コロナ」と「マスク」の検索トレンド。
距離が大きいのは、さきほど同様に「秋田県」の「コロナ」と「マスク」の検索トレンド。
コサイン類似度
4つ目は、レコメンド分野でお馴染みのコサイン類似度。コサイン類似度は、1に近ければ類似しており、0に近ければ似ていない。コサイン類似度の一覧。
コサイン類似度でみると、1に近いのは「愛知県」の「コロナ」と「マスク」の検索トレンド。
0に近いのはやはり「秋田県」の「コロナ」と「マスク」の検索トレンド。
類似度合いを探索する
各アルゴリズムで類似度合いを計算して可視化してきたが、表にまとめるとこうなる。
| アルゴリズム | 類似している | 類似していない |
|---|---|---|
| DTW | 福井県 | 秋田県 |
| ピアソンの相関係数 | 愛知県 | 秋田県 |
| ユークリッドの距離 | 福井県 | 秋田県 |
| コサイン類似度 | 愛知県 | 秋田県 |
ここからは更にデータを加工して、各アルゴリズムの類似度合いを探索していく。
現状、都道府県ごとに各アルゴリズムで計算した距離や類似度合いのデータフレームがあるので、計算した類似度合い(距離、相関係数)をもとにランク(ランキング方法はmin_rank()に従う)を振って、下記の画像のように、都道府県をキーに1つのデータフレームにまとめる。
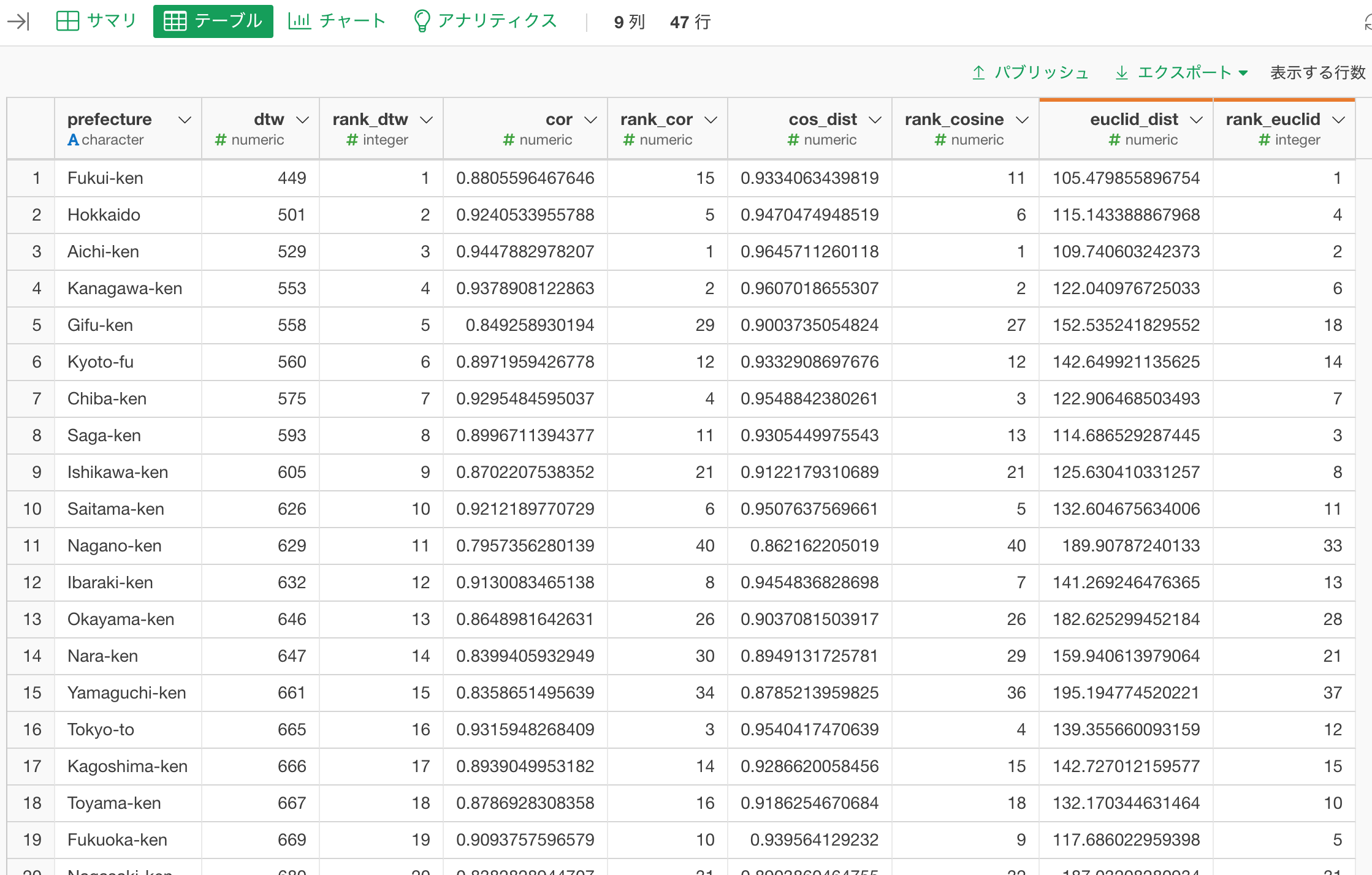
つまり、下記のルールでランクをふっていく。
- DTWであればコストが小さいほうが、ランキングは1位に近づく
- ピアソンの相関係数は、1または-1に近いほどランキングは1位に近づく
- ユークリッド距離は、小さいほどランキングは1位に近づく
- コサイン類似度合いは、1に近いほどランキングは1位に近づく
1位に近いほど、類似していることになるので、これを使って各アルゴリズムが付与した都道府県のランクの関係性を見てみる。
各アルゴリズムの都道府県ごとのランクを使ってスピアマンの順位相関係数で相関係数を求め、散布図行列を可視化したのがこちら。
散布図行列の3行目(または3列目)をみると、DTWは他のアルゴリズムとあまり相関していないことがわかる。一方で、ピアソンの相関係数とコサイン類似度は、都道府県に同じようなランクを付与していることがわかる。加えて、他の組み合わせも相関係数が0.85を超えている。
数理的に一般化できるのかはわかりませんが、今回のデータから言えば、「DTW」と「他のアルゴリズム」では、「時系列データの類似度」の捉え方(計算結果)が違うようである。
周期が少しずれているけど形は似ている…つまり、上がるなら上がる、下がるなら下がる、みたいな同じような動きの時系列データを比較するのであれば、DTWが無難っぽい。
データからは、とくにこれといったインサイトは得ていないが、得られたインサイトとしては、時系列データを扱う知識が私には足りていないことがわかった。「正しく」比較するというのは、難しいな…。
おまけ
ピアソンの相関係数から統計的消去(Statistical Elimination)へ
ピアソンの相関係数が最も大きのは、「愛知県」の「コロナ」と「マスク」の検索トレンド。これを散布図で可視化するとこうなる。
この状態であれば、関係がありそうにみえる。時間経過による、見せかけの相関かもしれないので、時間の影響を取り除くために、hits_corona ~ timeとhits_mask ~ timeの回帰分析を行い、時間timeでは説明ができない部分である各残差(residuals)同士の散布図を見てみる。
時間timeの影響を除いても、関係がありそうに見える。他にも双方に影響する何かはあるかもしれませんが…。
差分系列への回帰分析
単位根の問題(単位根の検定はしてない…)もあるので、hits_corona_diff、hits_mask_diffを計算し、差分系列への回帰分析をしてみたが、これを見ると…関係ありそう。