ExploratoryでSVM(サポートベクターマシン)のモデルを構築する方法
このノートでは、SVM(サポートベクターマシン)のモデルを構築する方法を紹介します。
カスタムモデル関数について
exploratory Rパッケージで定義されているbuild_model関数と、broomパッケージで定義されているモデル関数を利用することで、Exploratoryではモデル関数を簡単に利用することができます。
今回はe1071パッケージのSVM関数を使って、モデルを構築していきます。
モデルのクラス名
通常は初めにモデルのRクラス名を決めます。これはモデル関数が返すオブジェクトのクラス名です。今回は "svm "とします。(これは今回利用するe1071パッケージで使用しているモデルクラス名です)
モデル構築のための関数
次にモデルを構築するための関数を定義します。なおモデルを構築する関数は以下の引数を取る必要があります。
- モデル式 : どの予測変数から何を予測するかを定義する式
- データ:モデルを作成するためのトレーニングデータ
モデルを構築する関数は、前のステップで決めたモデルのクラス名を持つモデルオブジェクトを返す必要があります。従って関数の定義は以下のようになります。
svm <- function(formula, data, ...) {
# ここでモデルオブジェクトを構築します。
# モデルオブジェクトのモデルクラス名を設定します。
class(model_object) <- c("svm")
model_object
}幸いなことに、e1071パッケージにはすでに、そのような関数が定義されていますので、改めて定義する必要はありません。
なおe1071パッケージの関数名は、今回たまたまモデルクラス名と同じ "svm "になっていますが、一般的にモデルを構築する関数名とモデルクラス名は同じである必要はありません。
Rパッケージのインストール
今回はモデルを構築する関数を定義せず、e1071パッケージのsvm関数を利用するので、e1071のパッケージをインストールする必要があります。
ちなみに、前述したような形式でモデルを構築する関数を持ったRパッケージはたくさんありますので、e1071パッケージのようにそのままExploratoryで利用することができます。
なおモデルの構築に必要なパッケージはExploratoryのインストール時にインストールされている場合と、されていない場合があります。
既にインストールされているパッケージは、プロジェクトメニューから、Rパッケージの管理から確認が可能です。
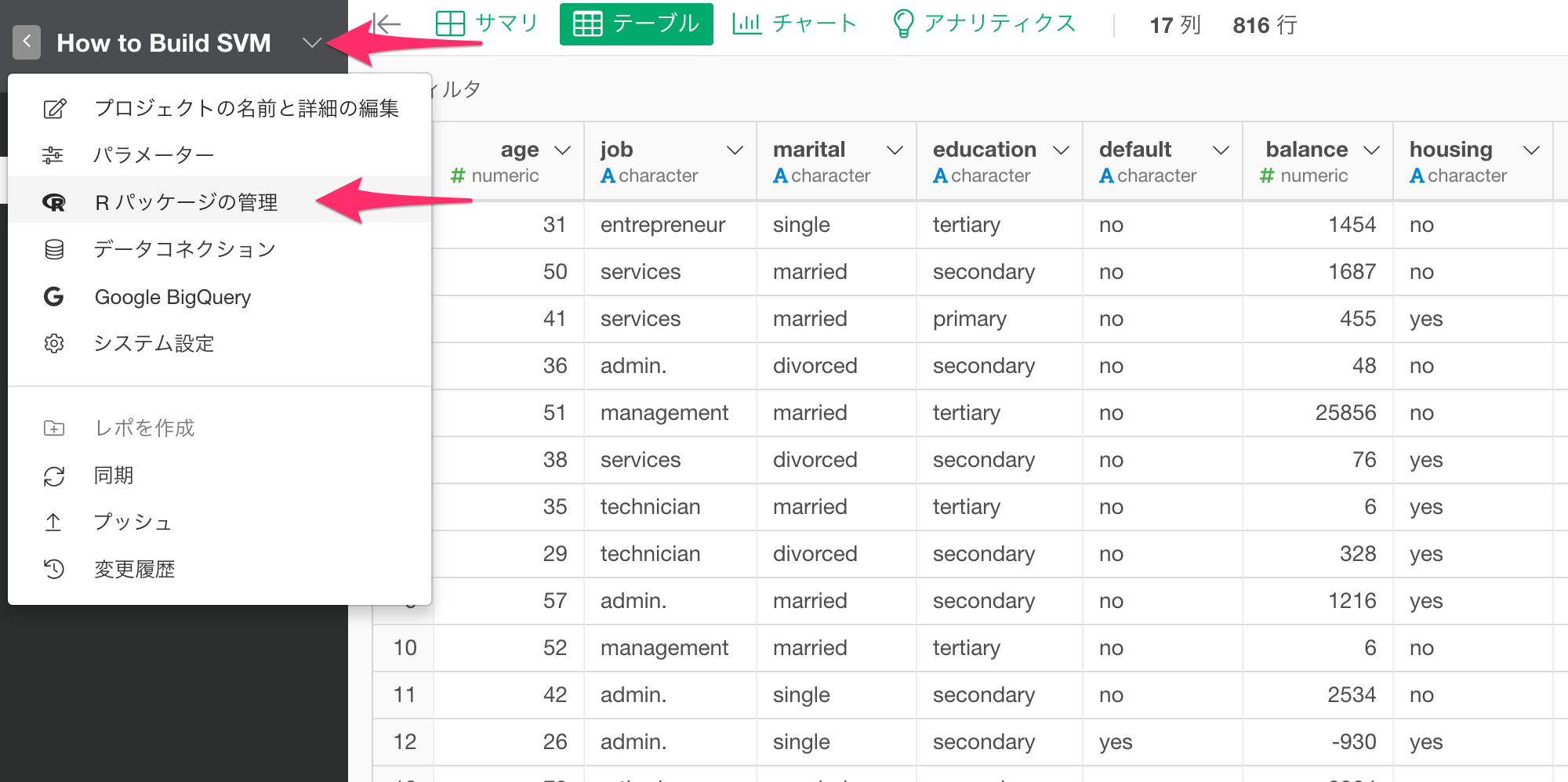
今回はe1071パッケージを利用したいので、「パッケージをインストール」からe1071をインストールします。
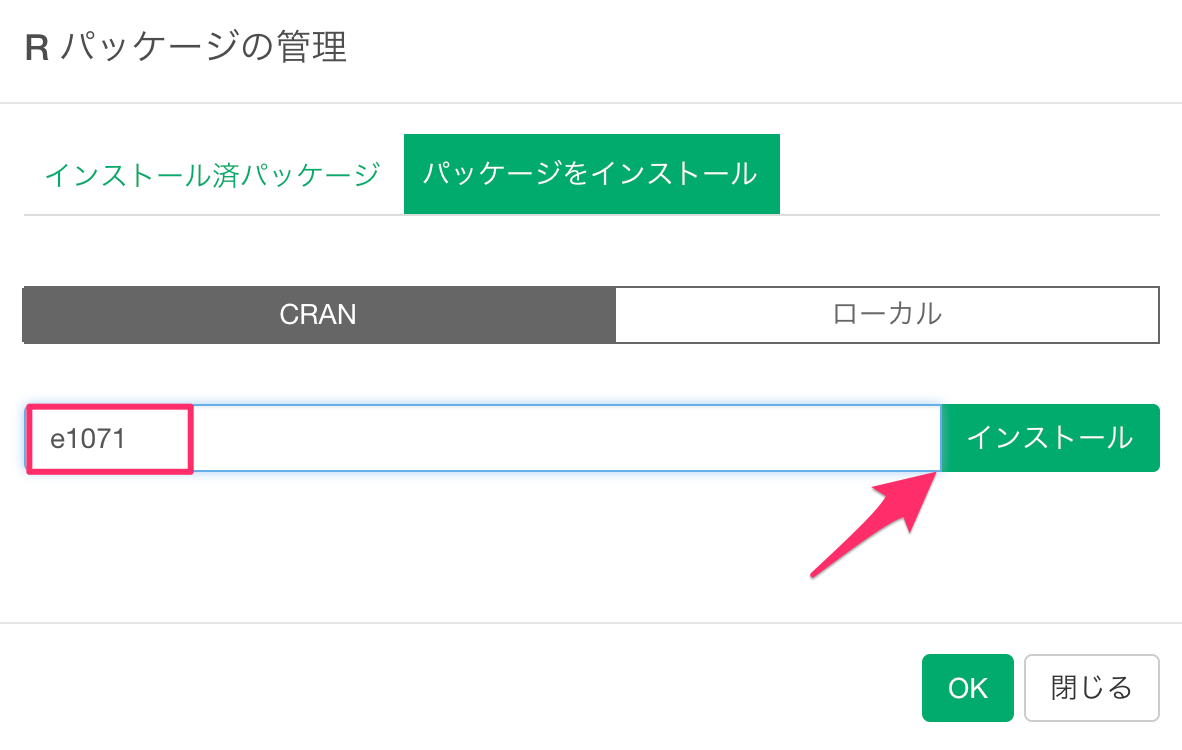
「e1071のインストールに成功しました。」というメッセージが表示されたら、OKボタンをクリックします。
モデルサマリーを表示する関数の定義
Exploratoryはモデル作成時にモデルのサマリーをテーブル形式で表示します。今回はモデルオブジェクトからモデルのサマリー情報をデータフレームとして抽出するための関数を定義していきます。
具体的にはbroomパッケージのtidy関数とglance関数の仕組みを利用してモデルのサマリー情報をデータフレームとして抽出します。
この仕組みをモデルオブジェクトクラス(今回の例でいうと "svm")で利用するには、モデルオブジェクトクラスのための関数を定義しなければなりません。
モデルによっては、モデルオブジェクトクラスのための関数がすでに定義されており、そちらの情報は、broomのgithubページにリストアップされています。
残念ながら、svmはそのような関数は定義されていないので、今回はスクリプトを利用して関数を定義していきます。
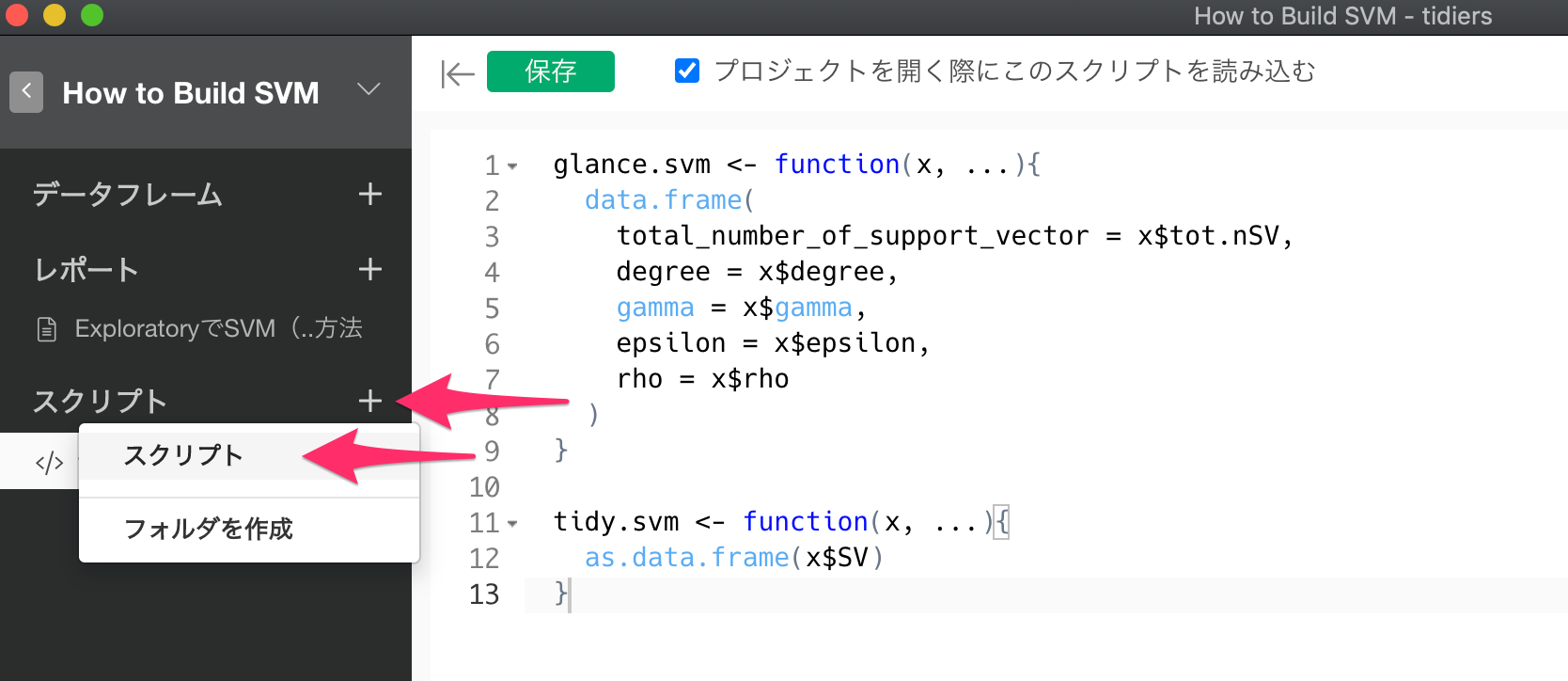
スクリプトの隣の+ボタンをクリックしたら、以下の内容をスクリプトエディタに入力します。
なお、ここではe1071のsvm関数をそのまま使用しているので、モデル構築のための関数を新たに定義する必要はありませんが、利用するモデル構築のための関数があらかじめ定義されていない場合は、ここで関数を定義する必要があります。
svmクラスのglance関数
glance.svm <- function(x, ...){
data.frame(
total_number_of_support_vector = x$tot.nSV,
degree = x$degree,
gamma = x$gamma,
epsilon = x$epsilon,
rho = x$rho
)
}svmクラスのtidy関数
tidy.svm <- function(x, ....){
as.data.frame(x$SV)
}上記のコードについて下記、説明します。
xはモデルオブジェクトを表しており、これらの関数はデータフレームを返すことを期待しています。- 一般的にglance関数は1行のデータフレームを統計値付きで返し、tidy関数は複数行のデータフレームを返します。
- 他の引数が必要ない場合でも
...引数はエラーを避けるために必要です。
関数の定義を入力したら、保存ボタンをクリックします。
モデル関数をデータフレームに適用する
これでステップのカスタムRコマンドからモデル関数を呼び出すことができるようになったので、モデル関数を適用したいデータフレームを開きます。
今回は、銀行口座のデータにsvmを適用していきます。
今回のデータに対しては以下のカスタムRコマンドを実行することでモデル関数がデータフレームに適用されます。
build_model(model_func=e1071::svm, formula = subscribed ~ age + housing + duration, kernel = "linear", test_rate = 0.2, seed = 1)では実際にやってみます。ステップメニューから、カスタムRコマンドを選択します。
ダイアログに上記のRコマンドを入力し、実行ボタンをクリックします。
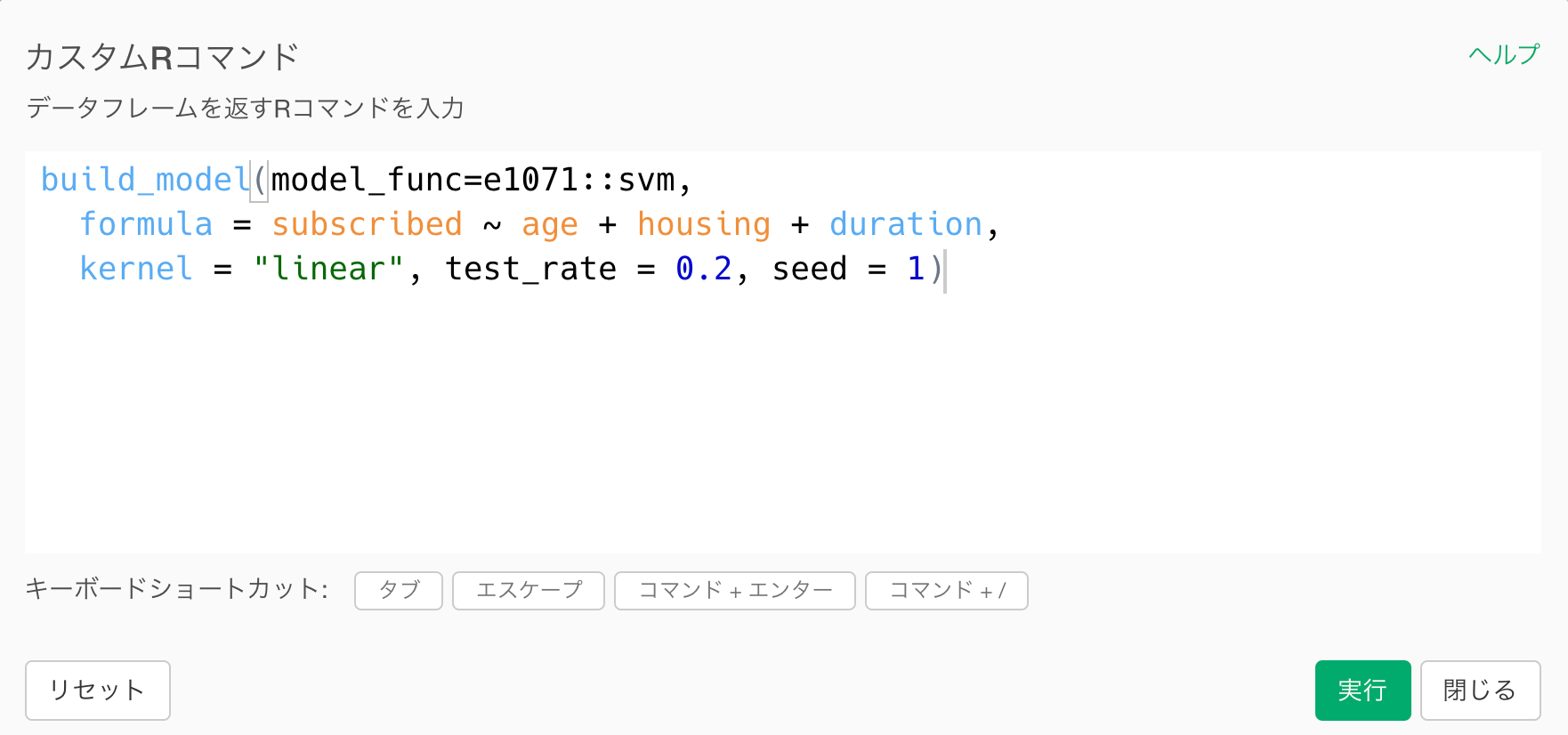
ちなみに、test_rateとseedはbuild_model関数の引数です。 test_rate = 0.2はデータの20%をテストに、80%をトレーニングに利用することを意味し、seed = 1はサンプリングによってトレーニングデータとテストデータを分割するためのランダムシード値を表しています。
加えてformula = subscribed ~ age + housing + duration and kernel = “linear”という部分はe1071::svmというsvm関数の引数となっています。
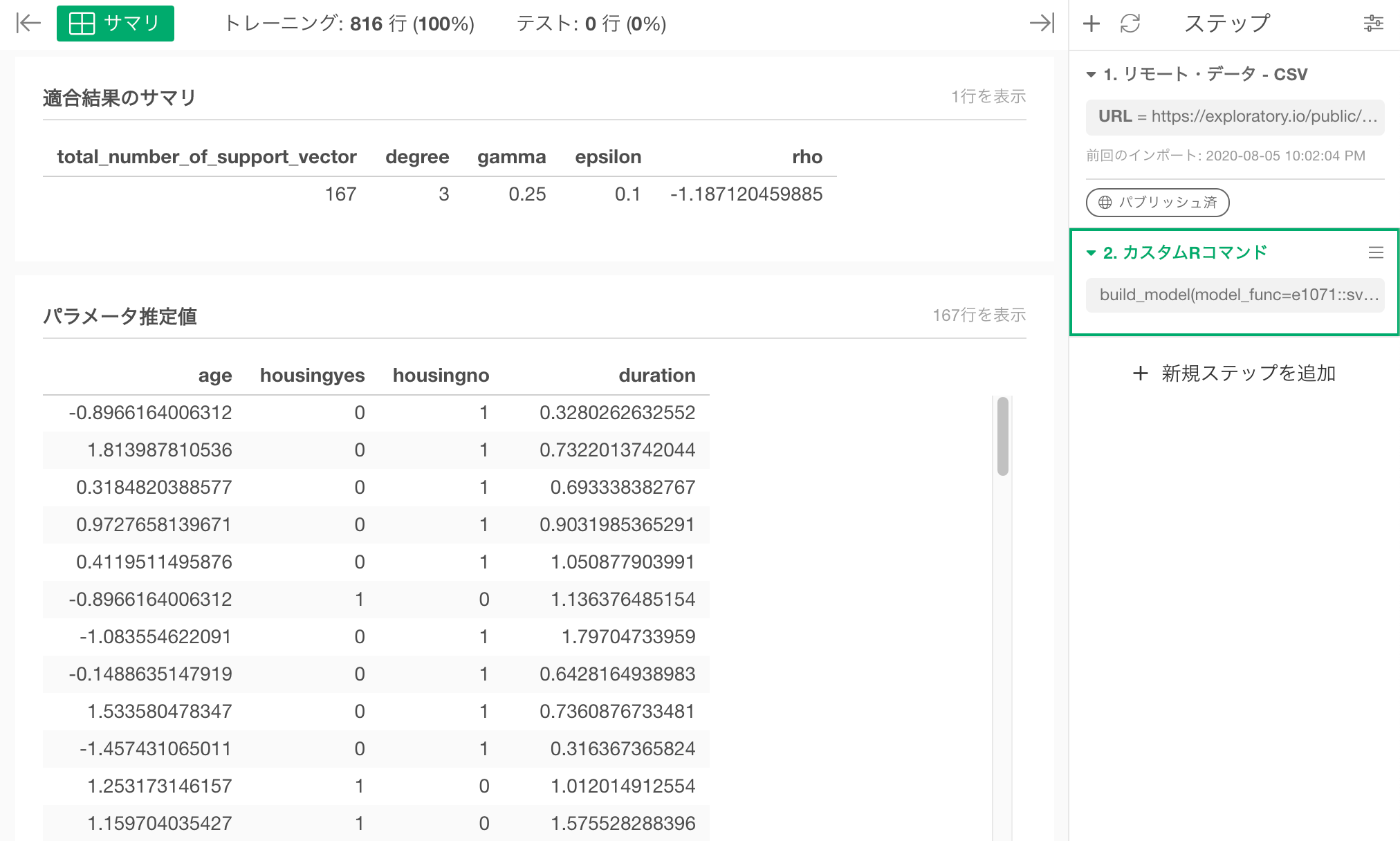
すると、以下のようなモデルのサマリー画面が表示されます。"適合結果のサマリ" が glance 関数の結果、"パラメーター推定値" が tidy 関数の結果となります。
構築したモデルで予測する
ちなみに今回作成したモデルは予測に使うこともできます。broomパッケージにもあるAugment関数を定義することで、モデルを予測に利用することができます。
先程と同じように、スクリプトの隣の+ボタンをクリックして、以下のスクリプトをエディタに入力します。
今回のsvmでは以下のスクリプトでモデルを予測に利用することが可能となります。
augment.svm <- function(x, data = NULL, newdata = NULL, ...) {
if(is.null(newdata)){
if(is.null(data)){
stop("data or newdata is needed")
}
data$predicted_value <- x$fitted
data
} else {
predicted <- predict(x, newdata)
newdata$predicted_value <- predicted
newdata
}
}なおxはモデル、dataはトレーニング用のデータフレーム、newdataは予測を行うデータフレームを表しています。
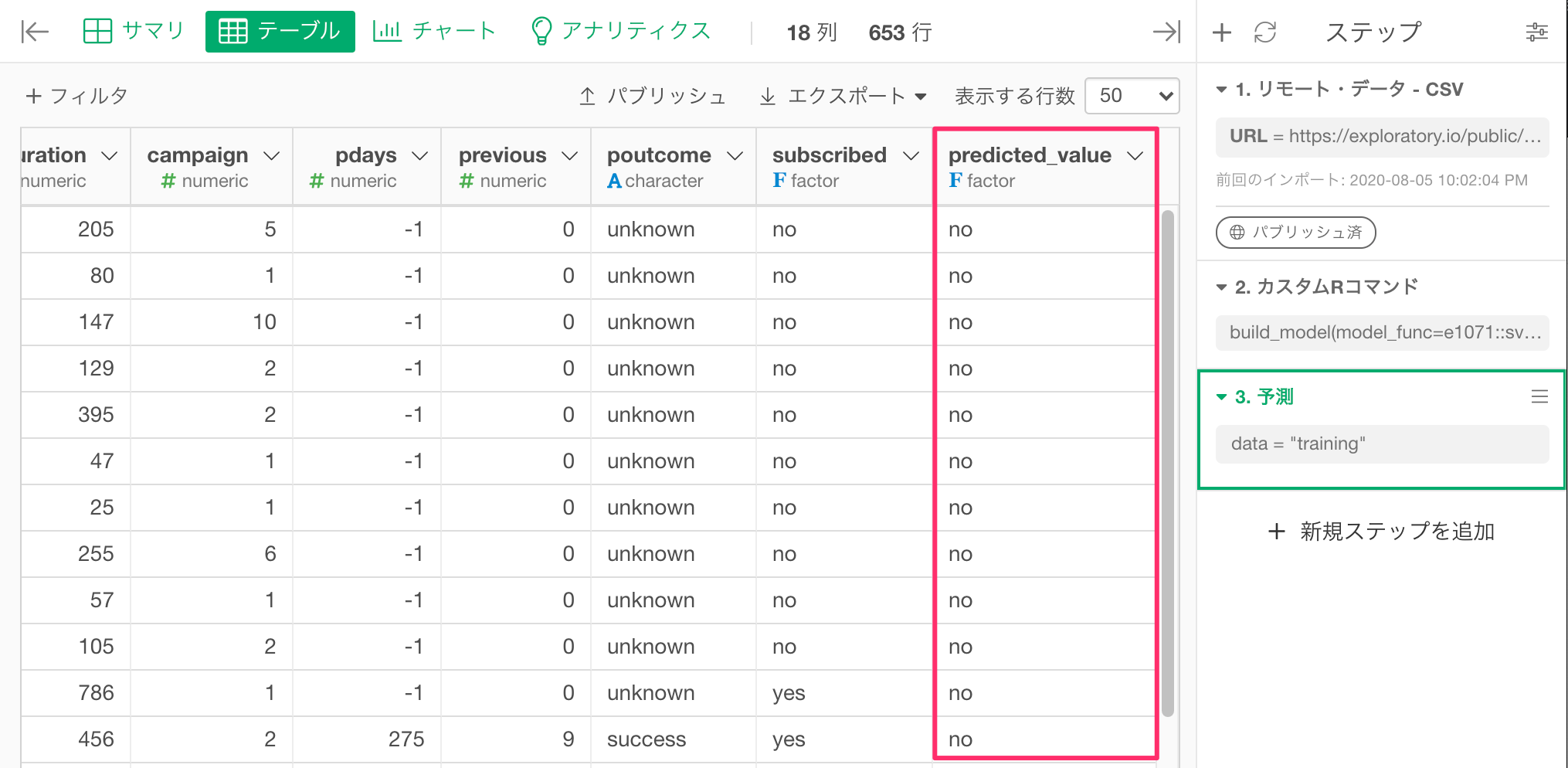
これで各行の予測結果をデータフレームに追加することができます。
実際に予測をしたいときはステップメニューをクリックします。
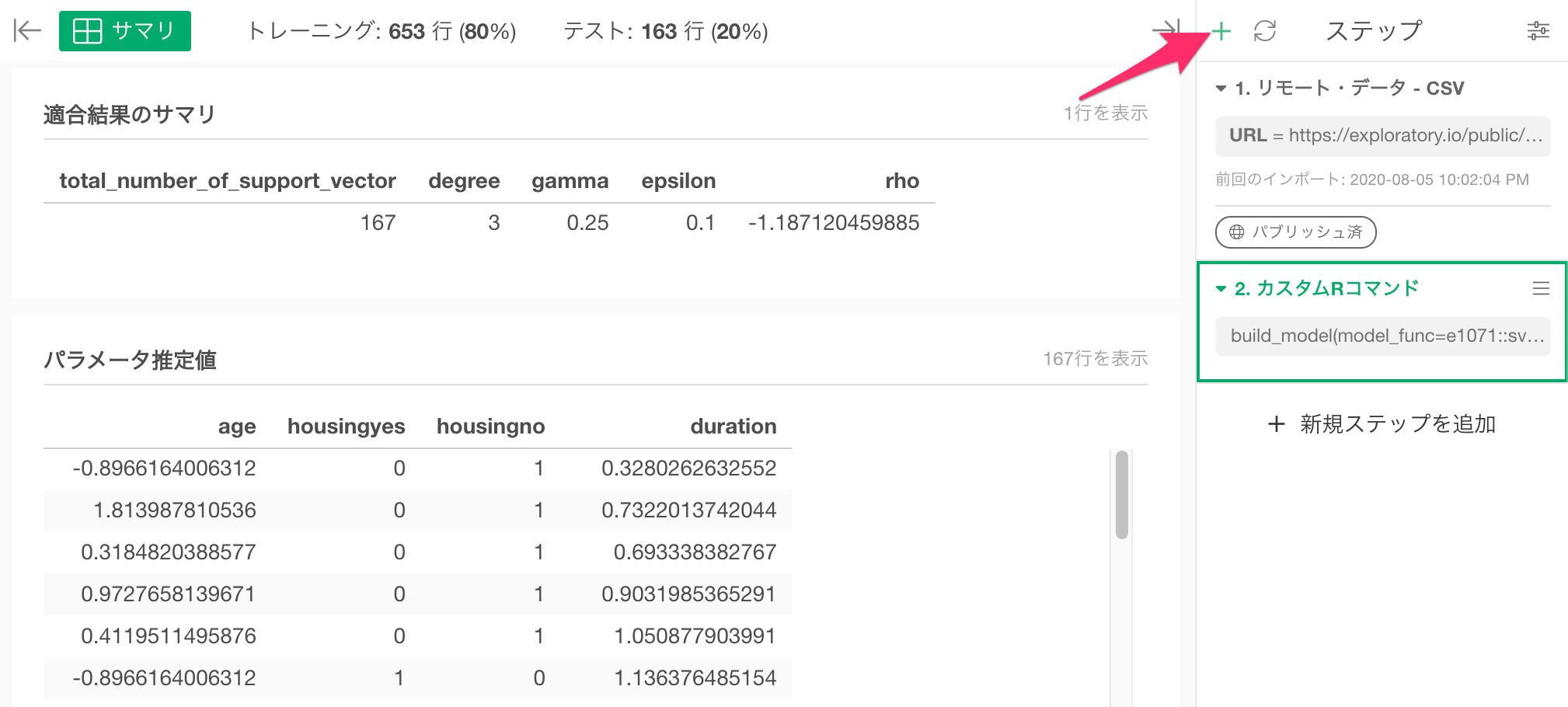
続いて予測に利用したいデータフレームを指定します。
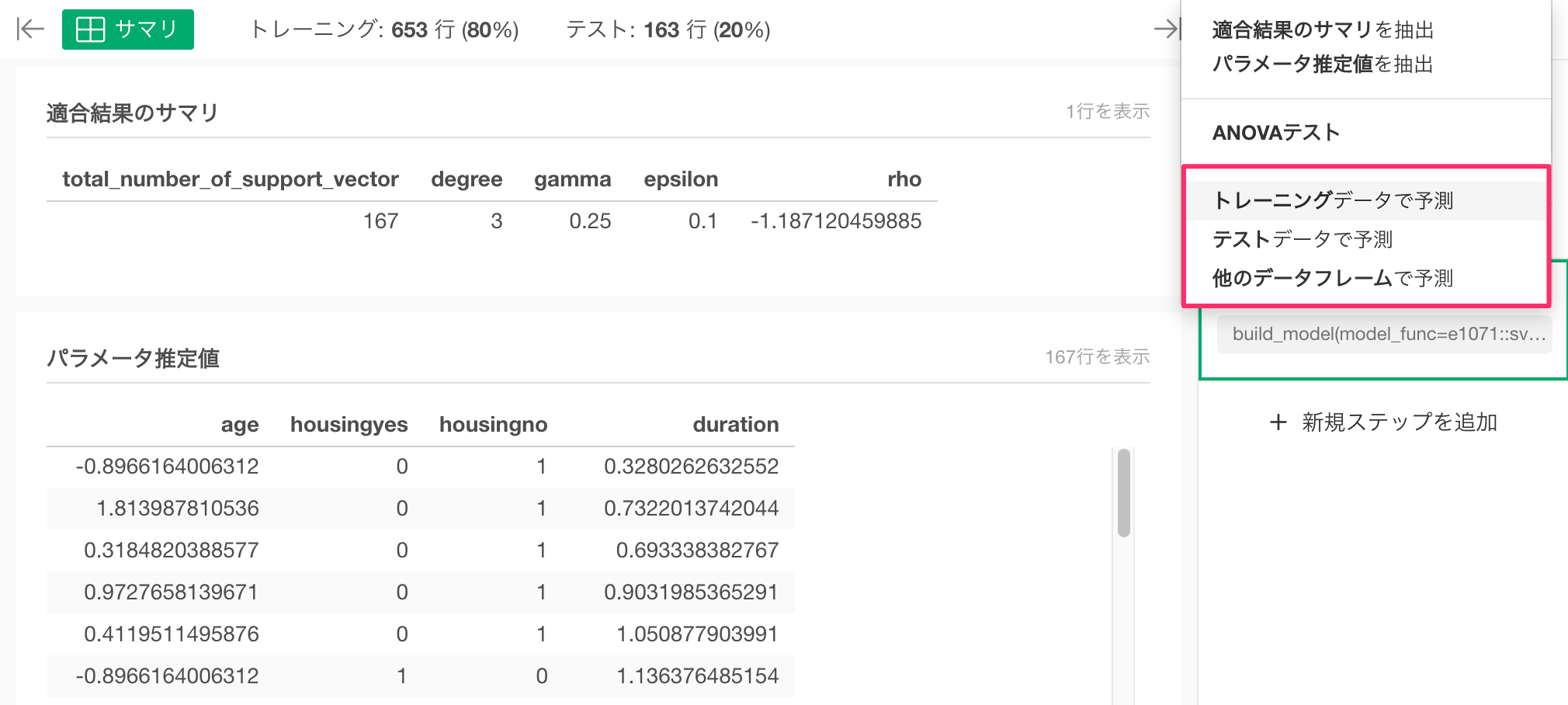
すると以下のように予測結果が返ります。
ユーザー定義モデルを構築する他の例
以下に様々なタイプの機械学習モデルをユーザ定義モデルとしてExploratory上で構築する方法を紹介していますので、よろしければご参考ください。