
自由記述アンケートのテキスト分析 Part 1:文章の単語化とワードクラウドを使った可視化
アンケートを実施するときに自由記述の設問を設けることは、よくやることの1つです。
一方で、集められた自由記述の回答については、眺めるだけで終わってしまったり、アンケートの回答を確認する人の主観的な気付きをまとめただけで分析が終わってしまうことも少なくありません。
そこで、こちらのノートでは、自由記述の文章を単語に分け、集計、可視化することで、どんな言葉がよく使われているのかを簡単に分析する方法を紹介します。
「単語のカウント」機能を利用して可視化する
最新のExploratoryでは、アナリティクスでサポートしているテキスト分析の「単語のカウント」機能を使って、データを加工することなく、数クリックで、よく利用される単語を簡単に可視化できるようになっています。詳細はこちら、または以下のリンクからご確認ください。
- テキスト分析 - 単語のカウントの使い方 - リンク

なお、Exploratoryでは、自由記述のテキストデータを加工して、単語に分け、分けられた単語を「ワードクラウド」チャートを使って可視化すことも可能ですので、そちらのやり方を紹介いたします。
自由記述のテキストを単語に分けて可視化するステップ
- データを取得する
- 文章を単語化する
- 単語化した文章をワードクラウドで可視化する
1. データを取得する
ExploratoryはExcel・データベースなど様々なソースからデータの取得が可能ですが、私達もアンケートを取る時によく使う、Googleフォームからも直接データを取ってくることができます。
ここでは、Googleフォームからのデータの取得について説明します。
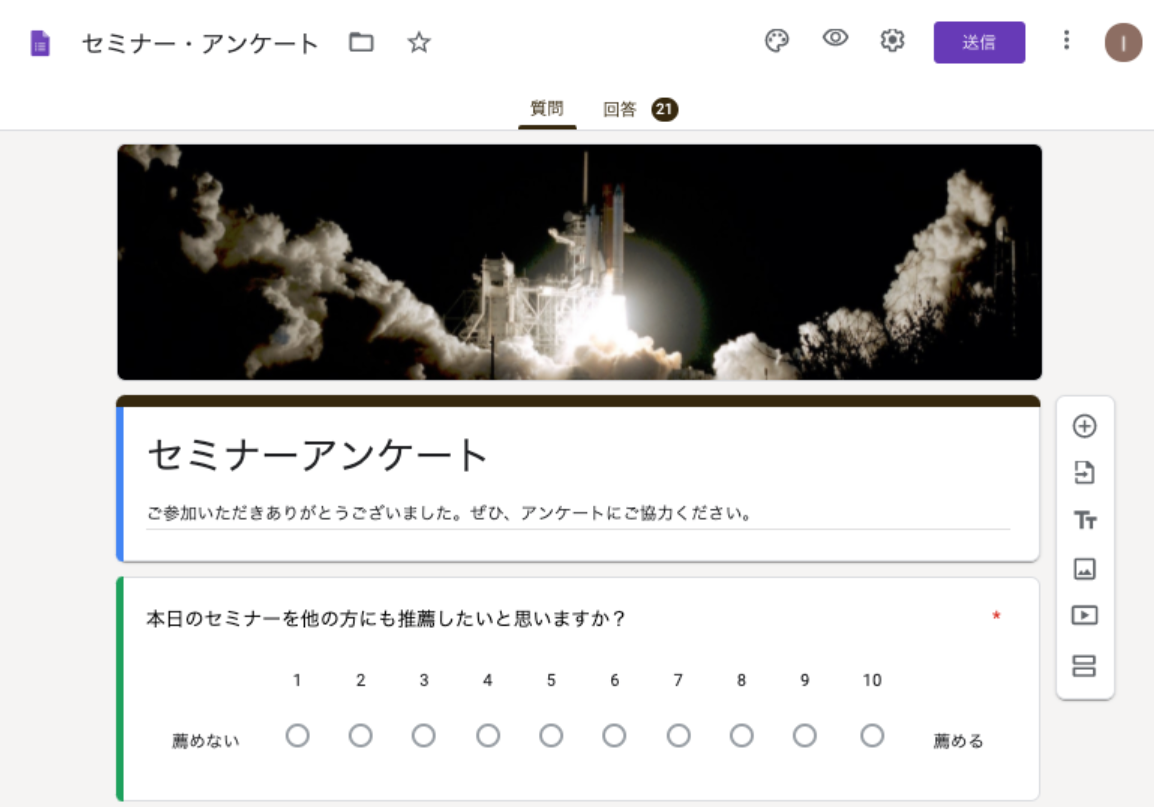
まずは、Googleフォームで集めた回答結果をGoogle Sheetsにエクスポートします。
一度Google Sheetsにデータをエクスポートできれば後は、直接データを取得するだけです。

- Google Sheetsのデータをインポートする方法 - Link
Google Sheetsのデータを直接取得するために、まずは「クラウドアプリケーションデータ」を選択します。
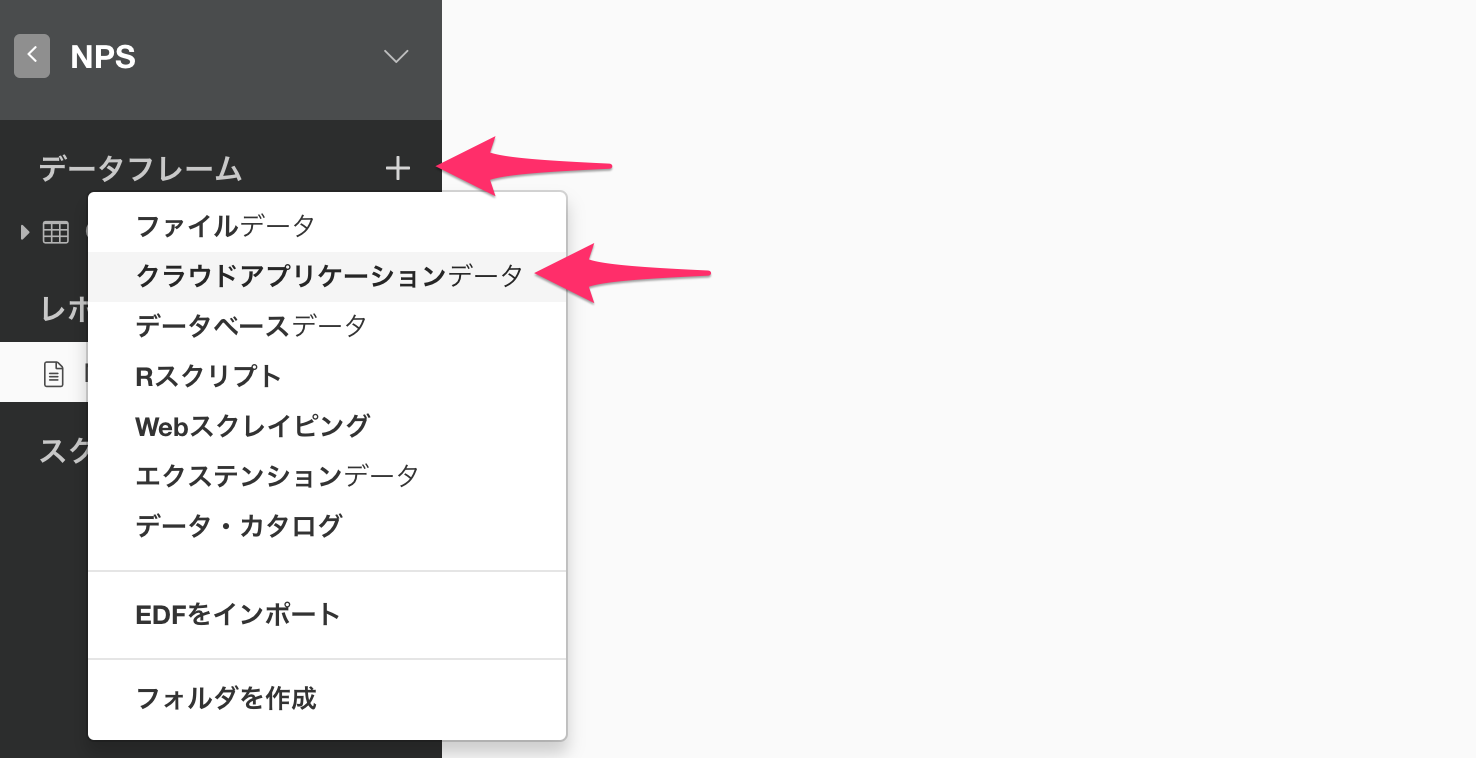
続いてクラウドアプリケーション・データソースからGoogle Sheetsを選択します。

するとインポートダイアログが表示されるので、シート名を選択します。
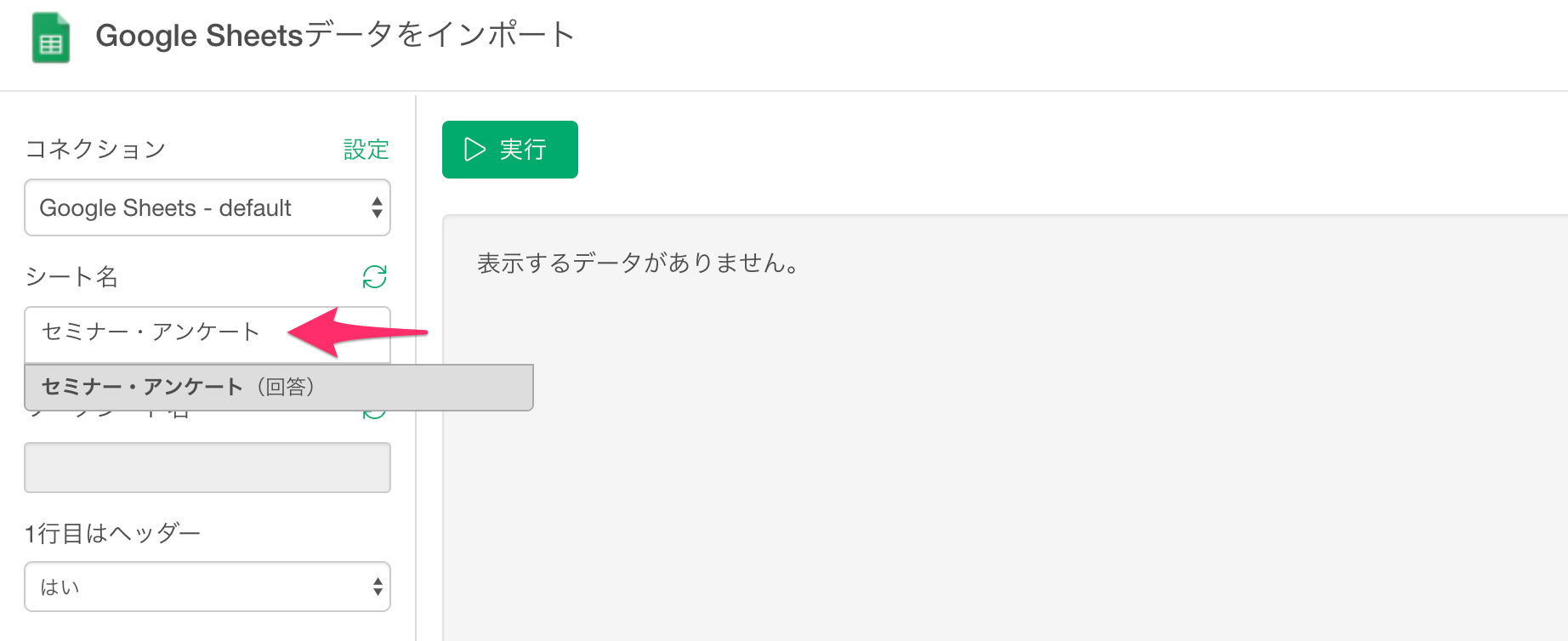
次にシートに含まれるワークシートの候補が表示されるので、インポートしたいワークシートを選択します。
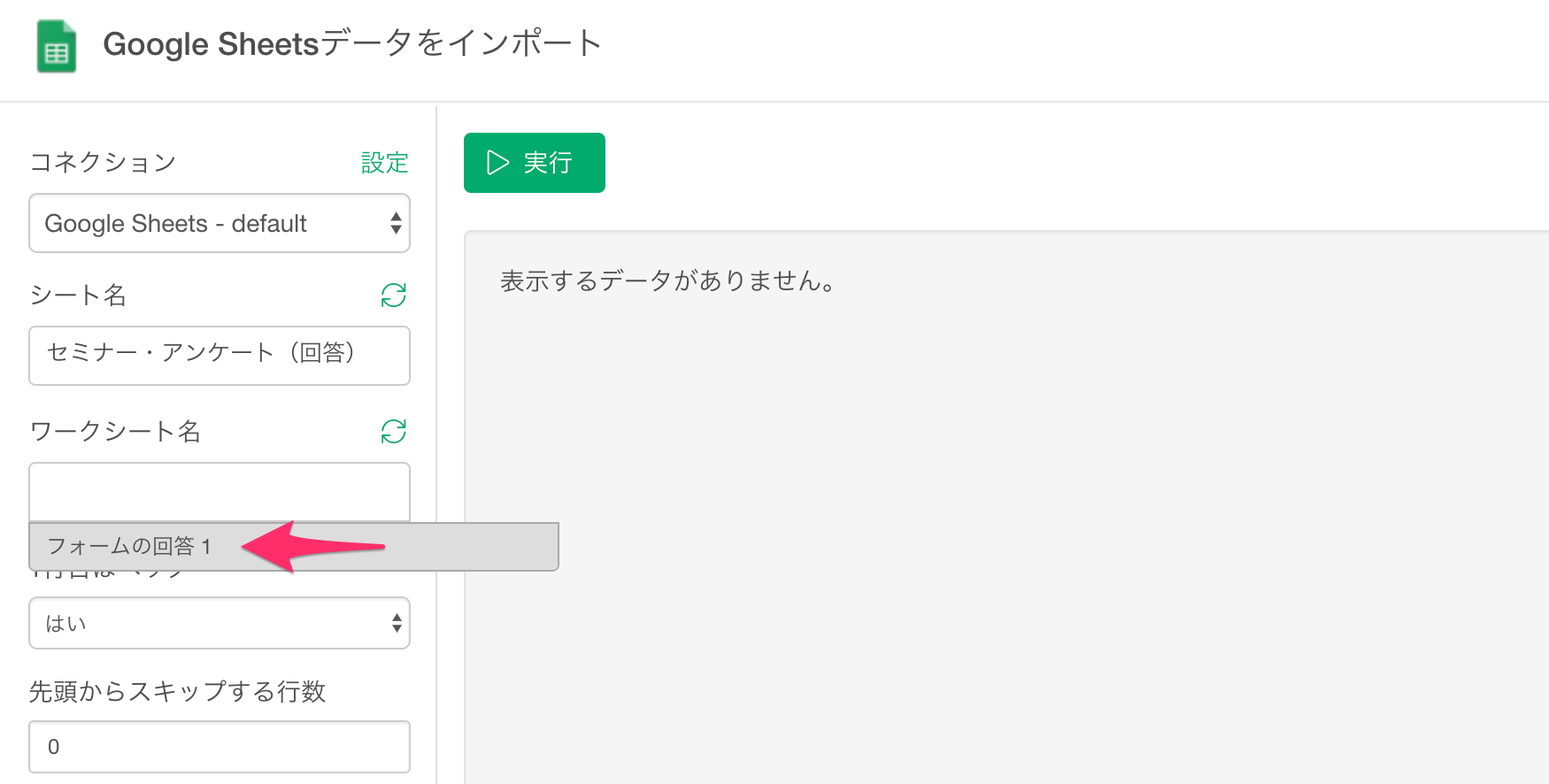
するとデータがプレビュー画面に表示されるので「保存」ボタンをクリックして、データをインポートします。
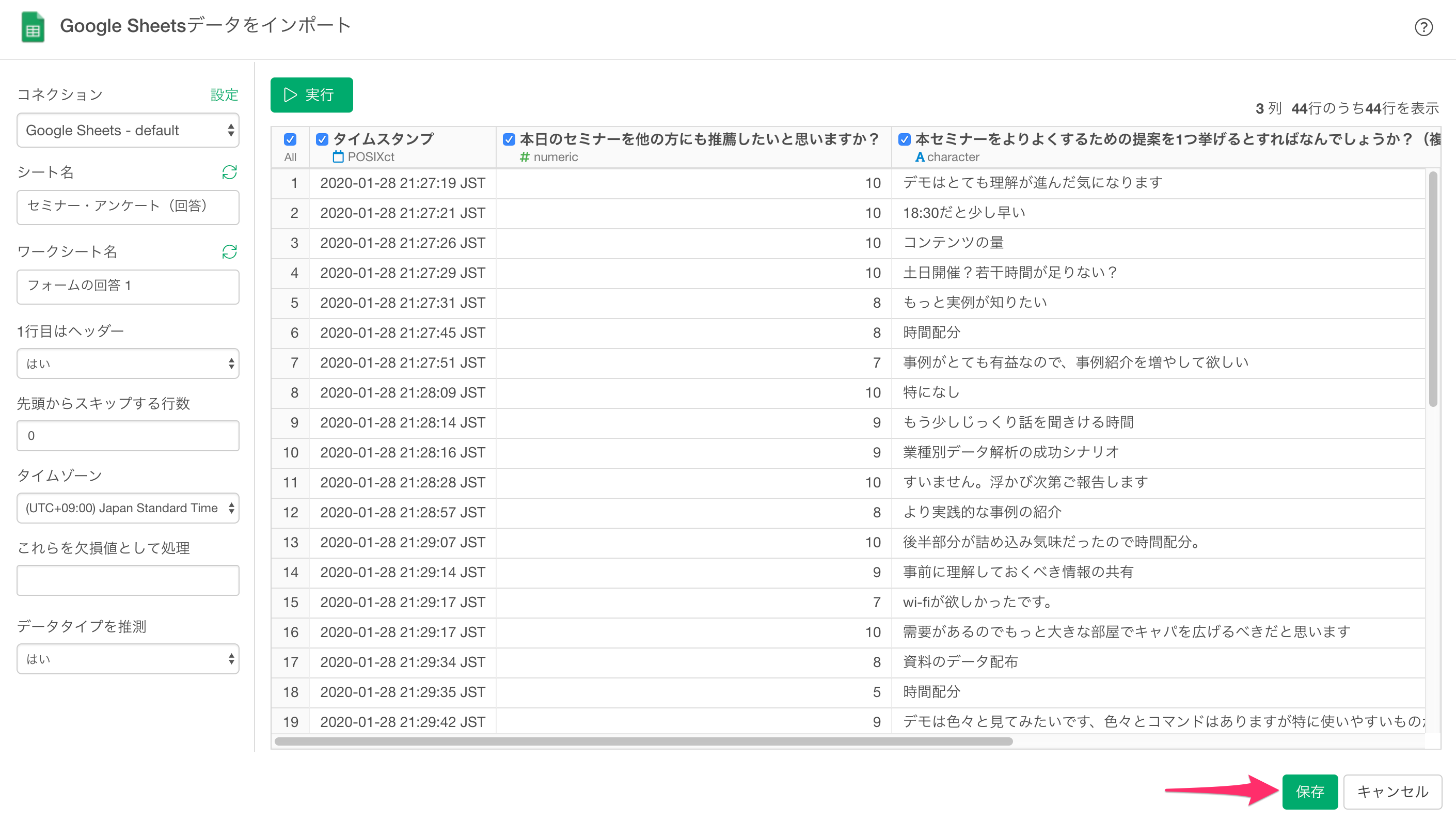
これでデータの取得は完了です。
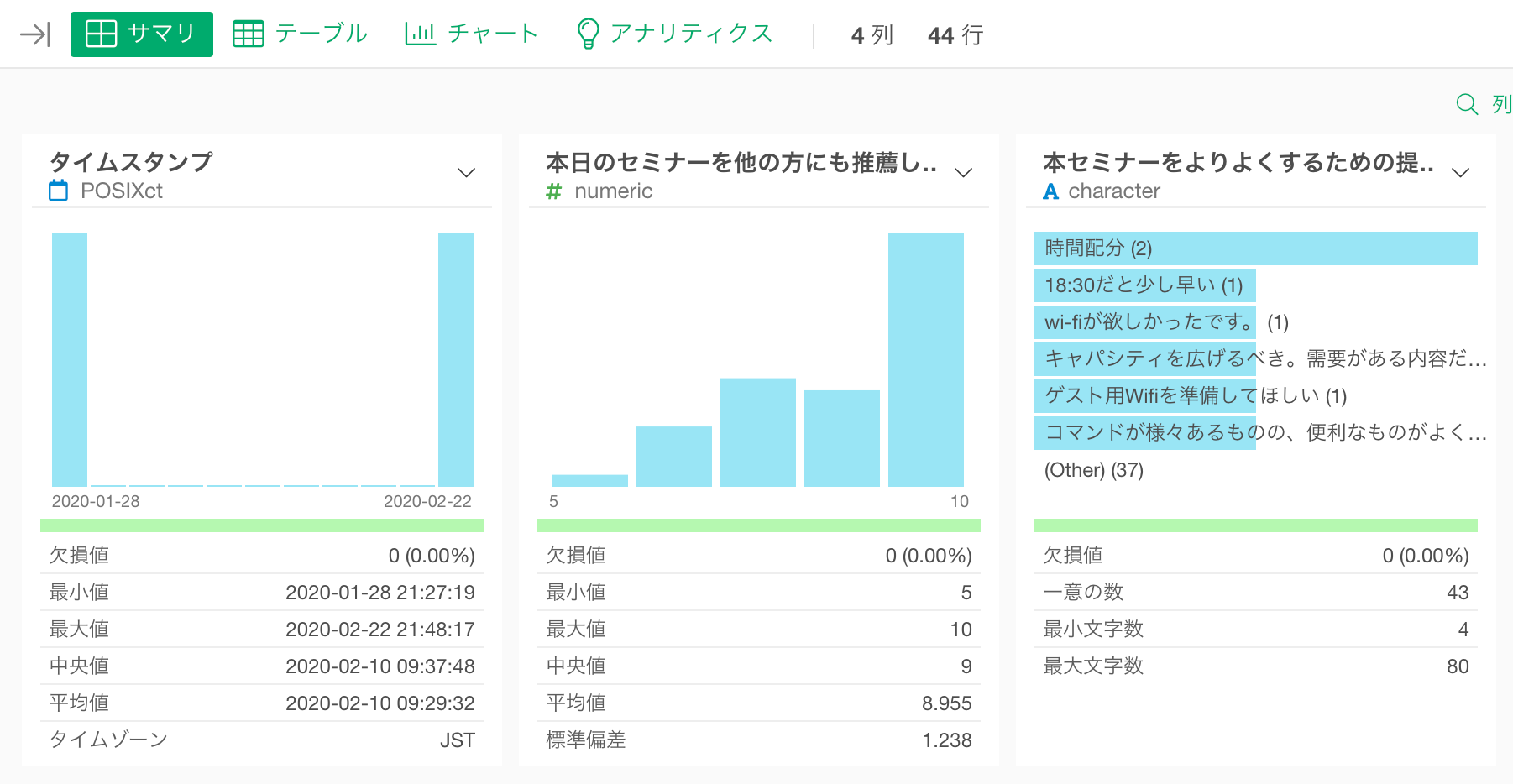
テーブル・ビューに移動するとデータが、以下のように1回答者ごとに1行のデータになっていることが分かります。
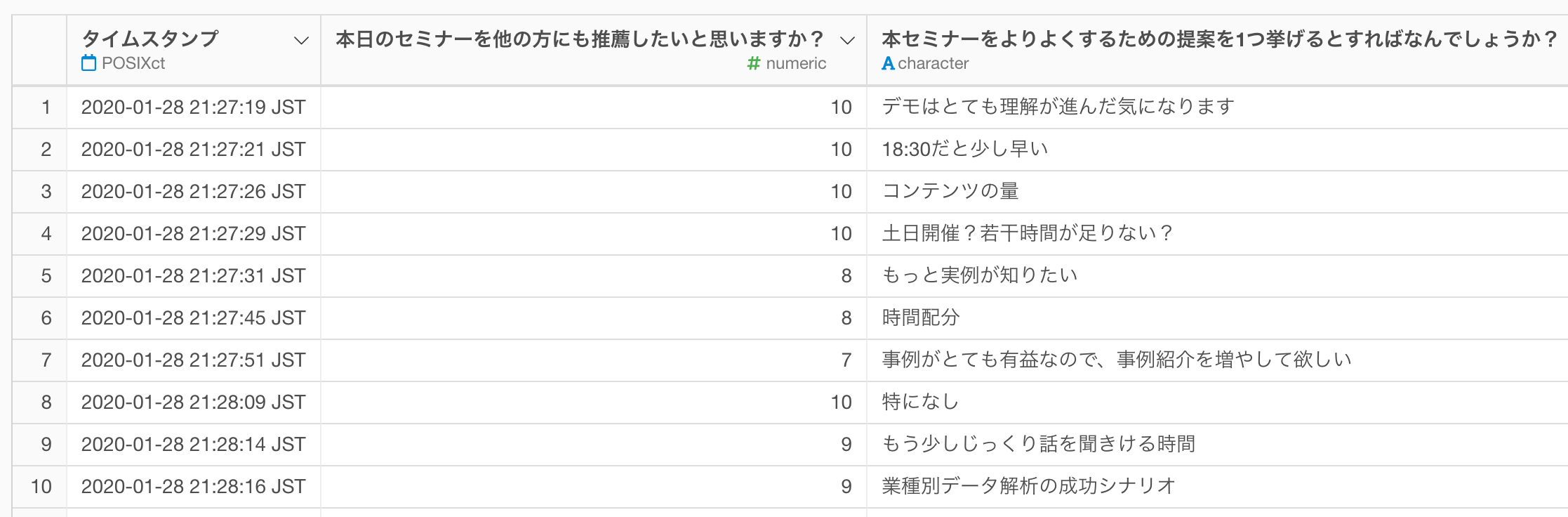
2. 文章を単語化する
今回は自由記述の項目でどのような単語が多く使われているのかを理解して、セミナーの改善ポイントを探していきます。

まずは「文章を単語に分ける」ことから始めていきます。
「本セミナーをよりよくするための提案を1つ挙げるとすればなんでしょうか?」という質問の列ヘッダーメニューから「テキストデータの加工(UI)」、「文章の単語化(日本語化)」を選択します。
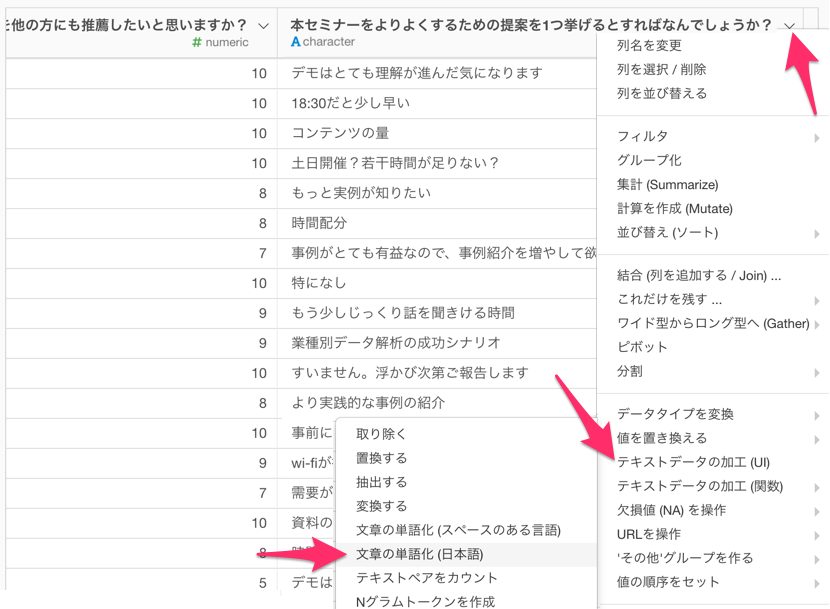
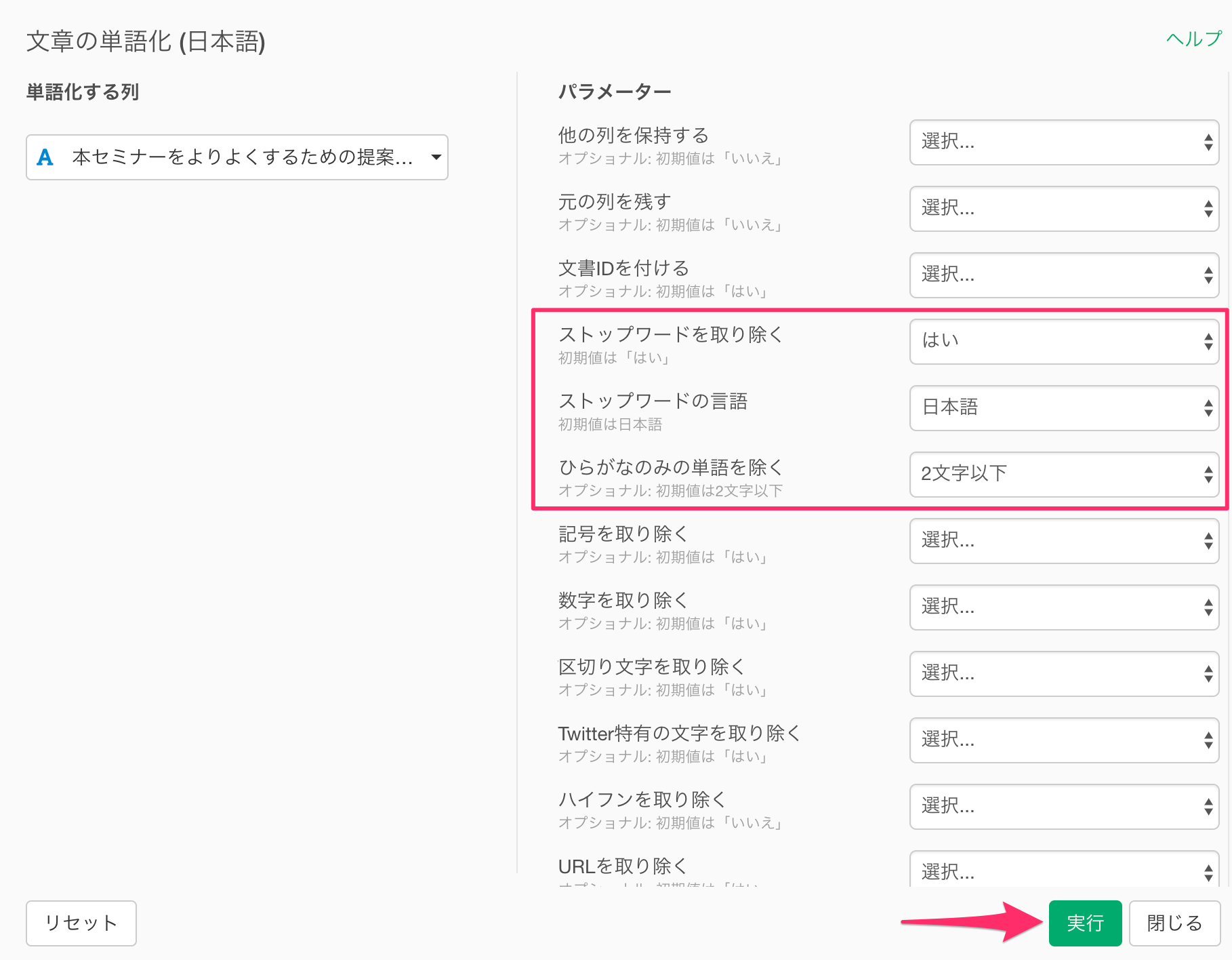
すると「文章の単語化(日本語)」ダイアログが表示されるので、ストップワードを取り除くに「はい」、ストップワードの言語に「日本語」、ひらがなのみの単語を除くに「2文字以下」を選択し、実行します。
なおストップワードは、あまりに一般的な「は」「の」「です」といった、意味をなさない言葉の総称です。
すると以下のように文章が単語に分かれます。
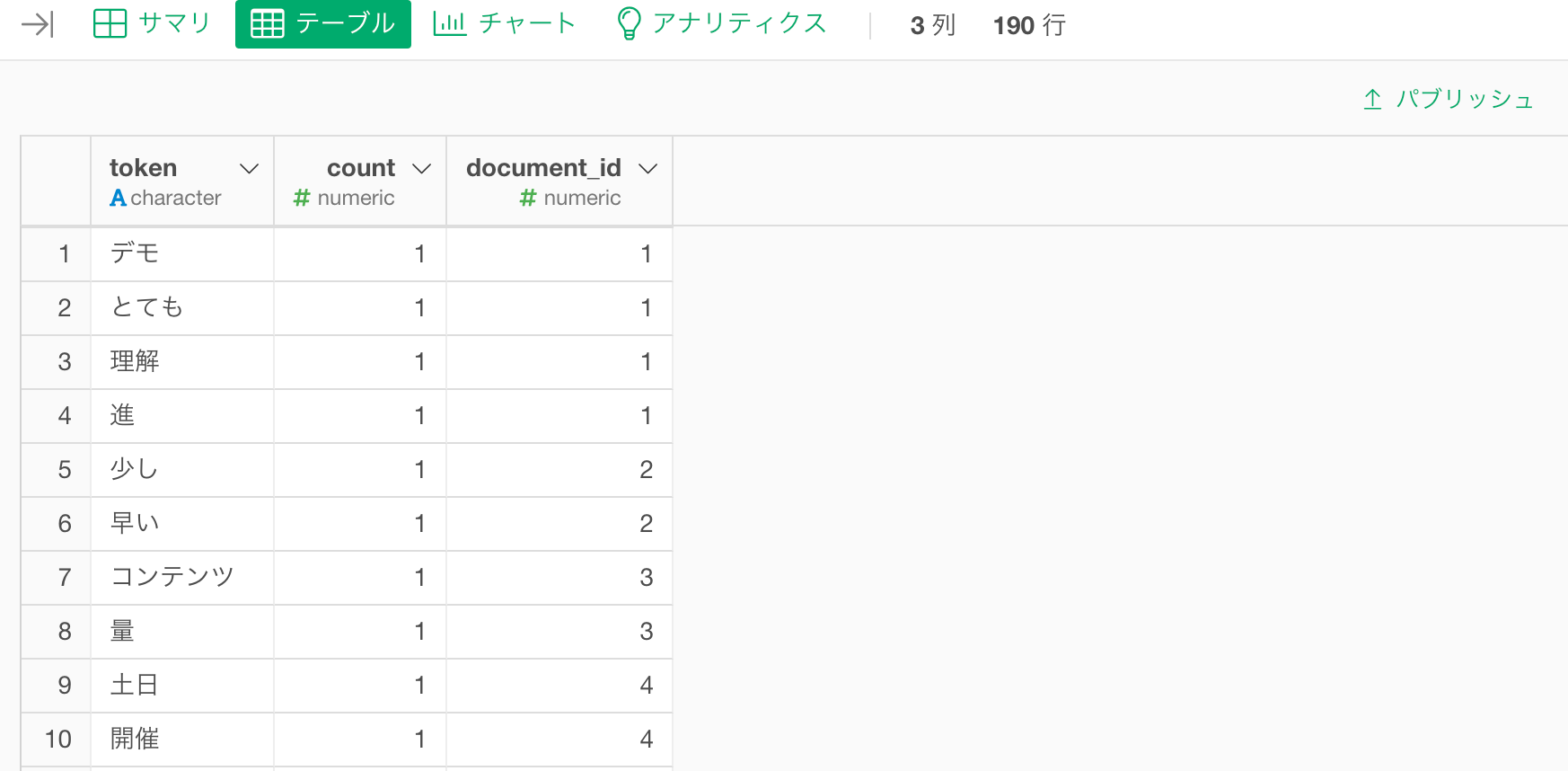
各々の列は以下の意味を表しています。
- token …文章を単語に分解したもの
- count…一つの文章の中でtokenが登場した回数
- document_id…文章ごとにユニークなID
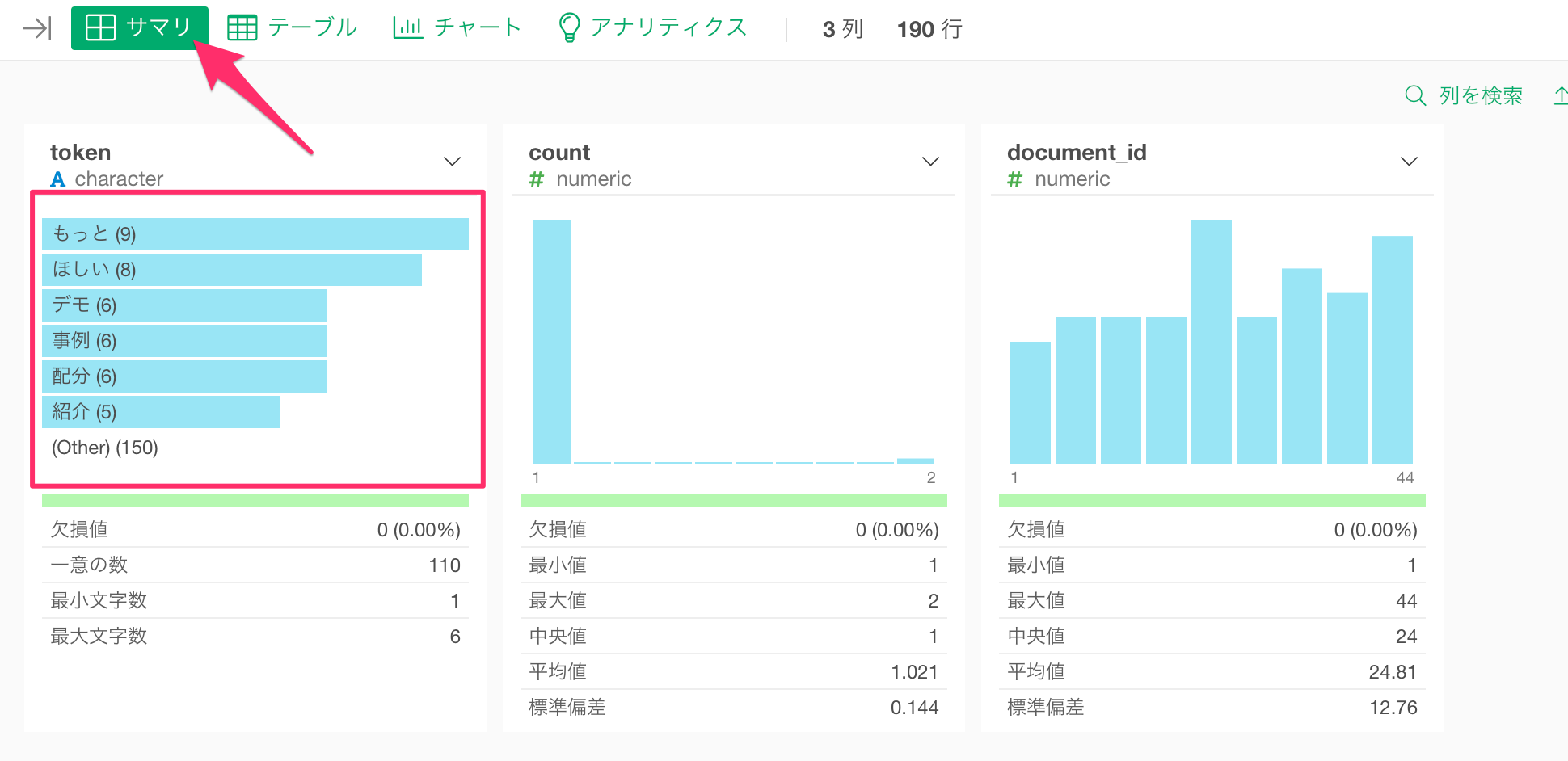
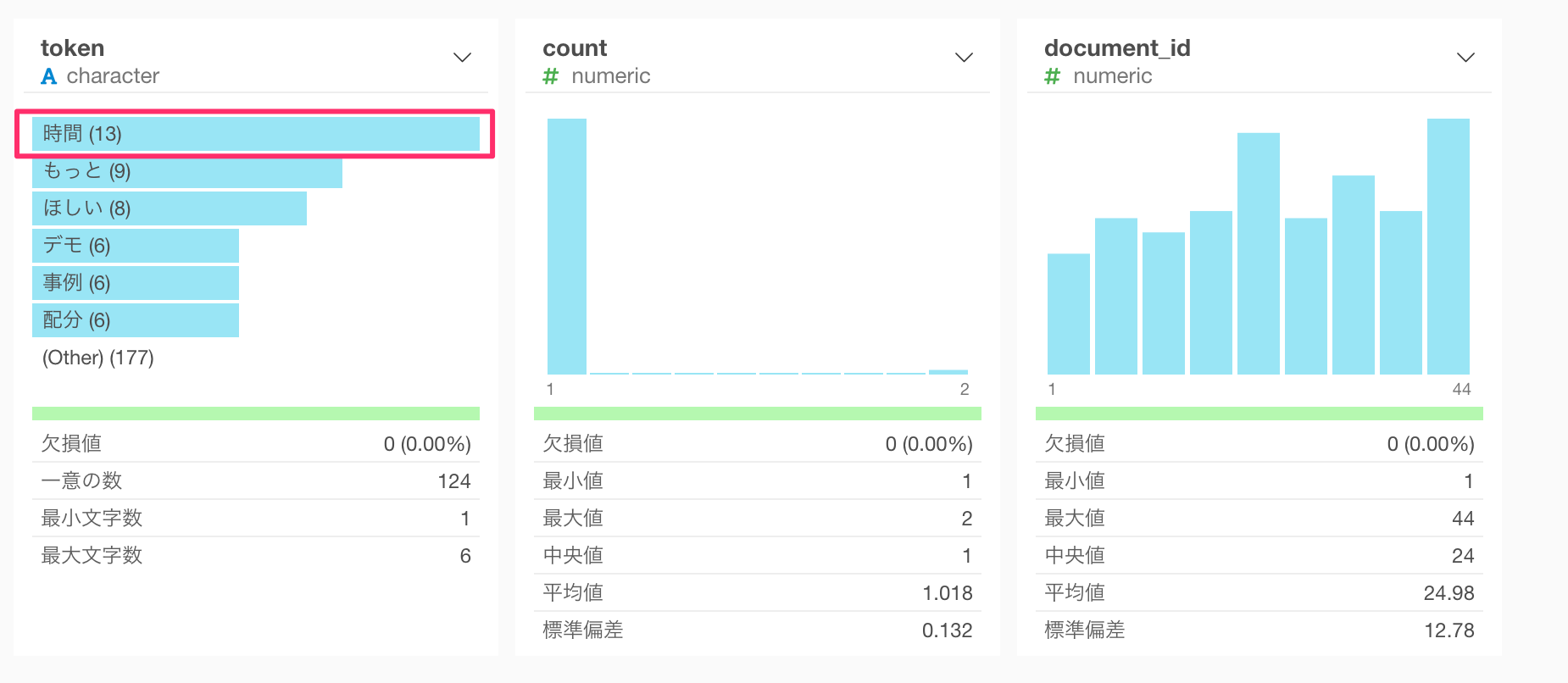
サマリ・ビューに移動すると、「もっと」、「ほしい」といった言葉が多く使われていることが分かります。
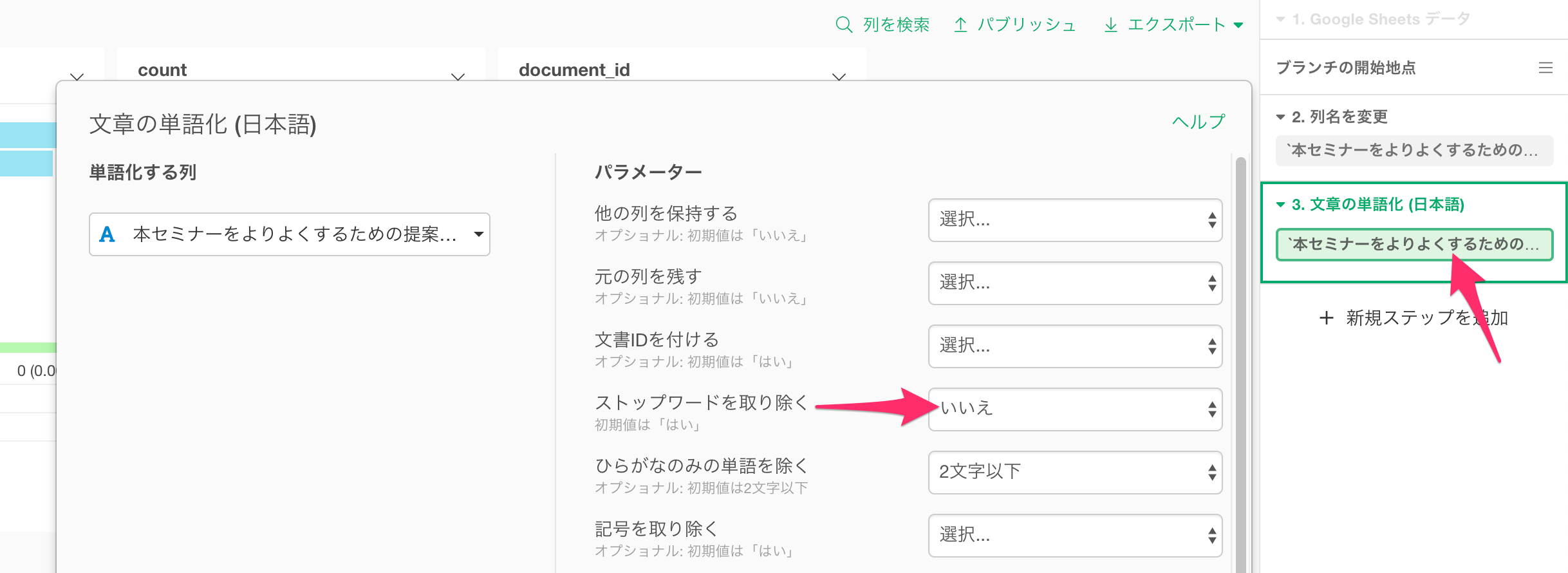
せっかくなので、ストップワードを含むケースも見てみましょう。先ほどのステップに戻って、「文章の単語化(日本語)」のステップの中にある、トークンをクリックします。すると先ほどの「文章の単語化(日本語)」ダイアログが再度表示されるので、今度はストップワードを取り除くに「いいえ」を選択し、実行します。
すると「時間」というtokenが増えていることが分かります。今回はセミナーに関する回答を扱っているので、「時間」という単語が含まれても問題ないと判断し、このまま、可視化まで進んでいきます。
3. 単語化した文章を ワードクラウドで可視化する
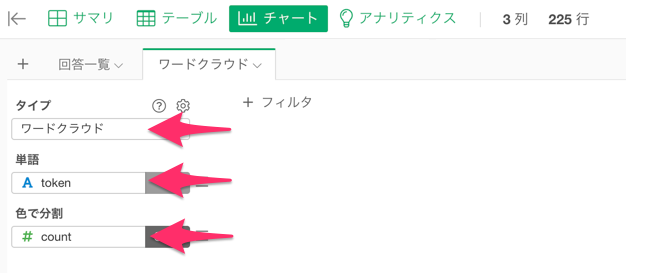
それでは、実際にどのような単語が多く使われているかを可視化していきます。チャート・ビューに移動して、タイプに「ワードクラウド」、単語に「token」、色で分割に「count」を選択します。
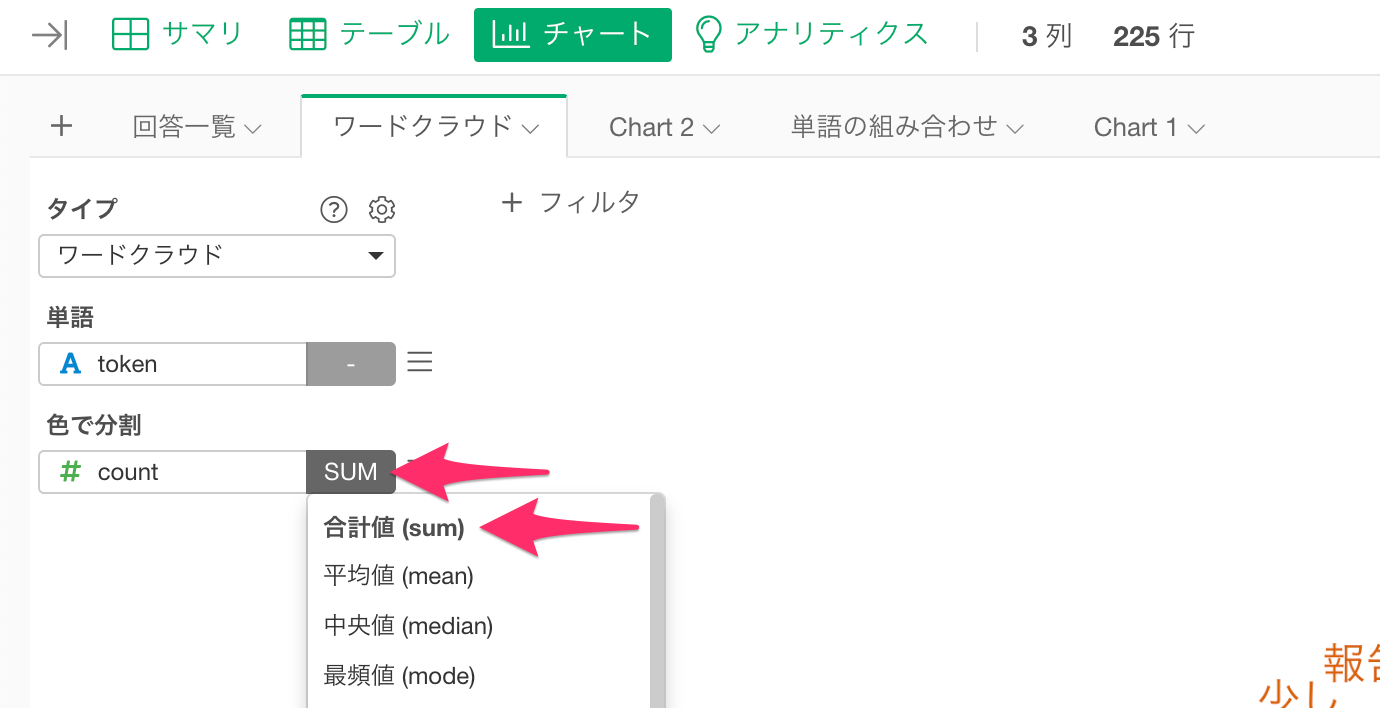
続いて色で分割の集計関数に「合計値(sum)」を選択します。
すると以下のように、いくつかの単語しか可視化されないということがあります。

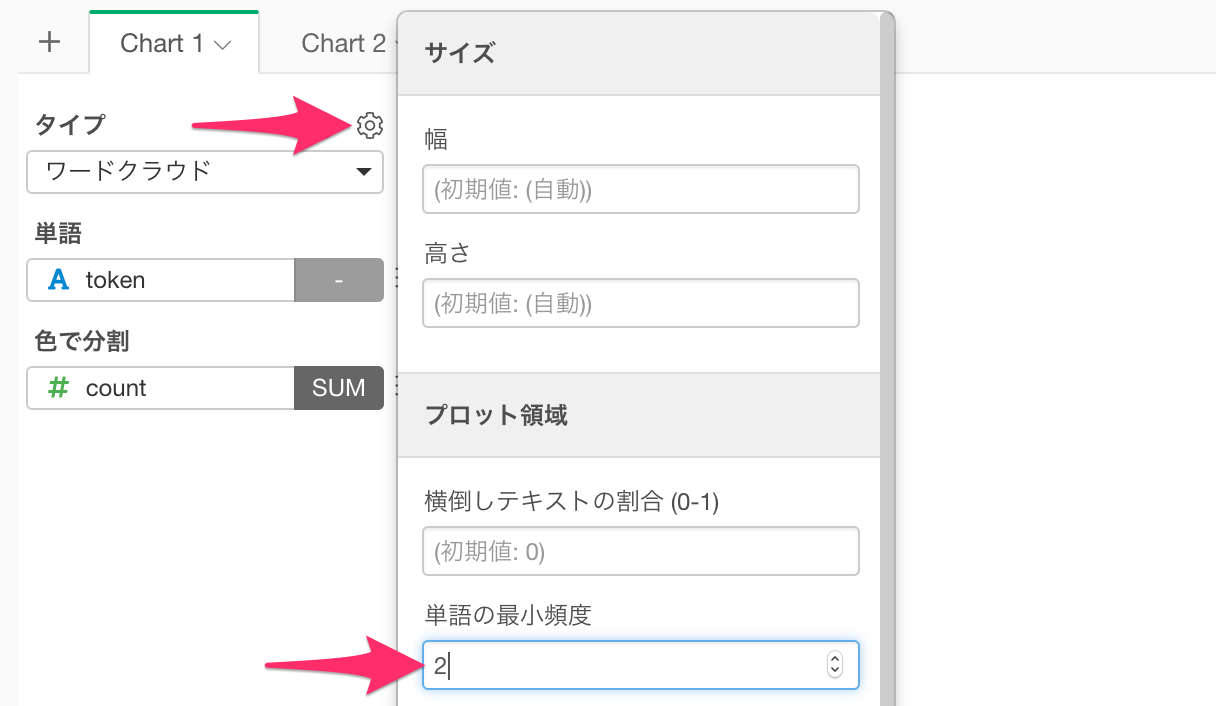
これはワードクラウドがデフォルトで「8」回以上、出現した単語を可視化するためです。そこで今回のようにデータが少ない場合は単語の最小頻度を変更します。
プロパティから単語の最小頻度を「2」に設定します。
すると以下のように単語の出現回数が文字の大きさと色によって可視化されました。どのような単語がよく使われているのかが、直感的にわかるようになりました。

これだけを見ると、「もっと時間がほしい」という回答が多かったのかもしれません。
しかし、それぞれの単語の出現回数だけでは、例えば、「デモ」が「ほしい」のか、「時間」が「ほしい」のか、または「事例」が「ほしい」のかがわかりません。
そういった問題に答えるために、よく一緒に使われる単語の組み合わせごとに頻出回数を集計したりするのですが、そちらはパート2で説明します!
- Part2:アンケートでよく出現する単語の組み合わせを調べる - Link
自分のデータで実際に試してみる
Exploratoryでは30日間、無料でトライアルができます。実際に自分達のデータを使って試してみたい方は下記より無料トライアルをご利用ください!