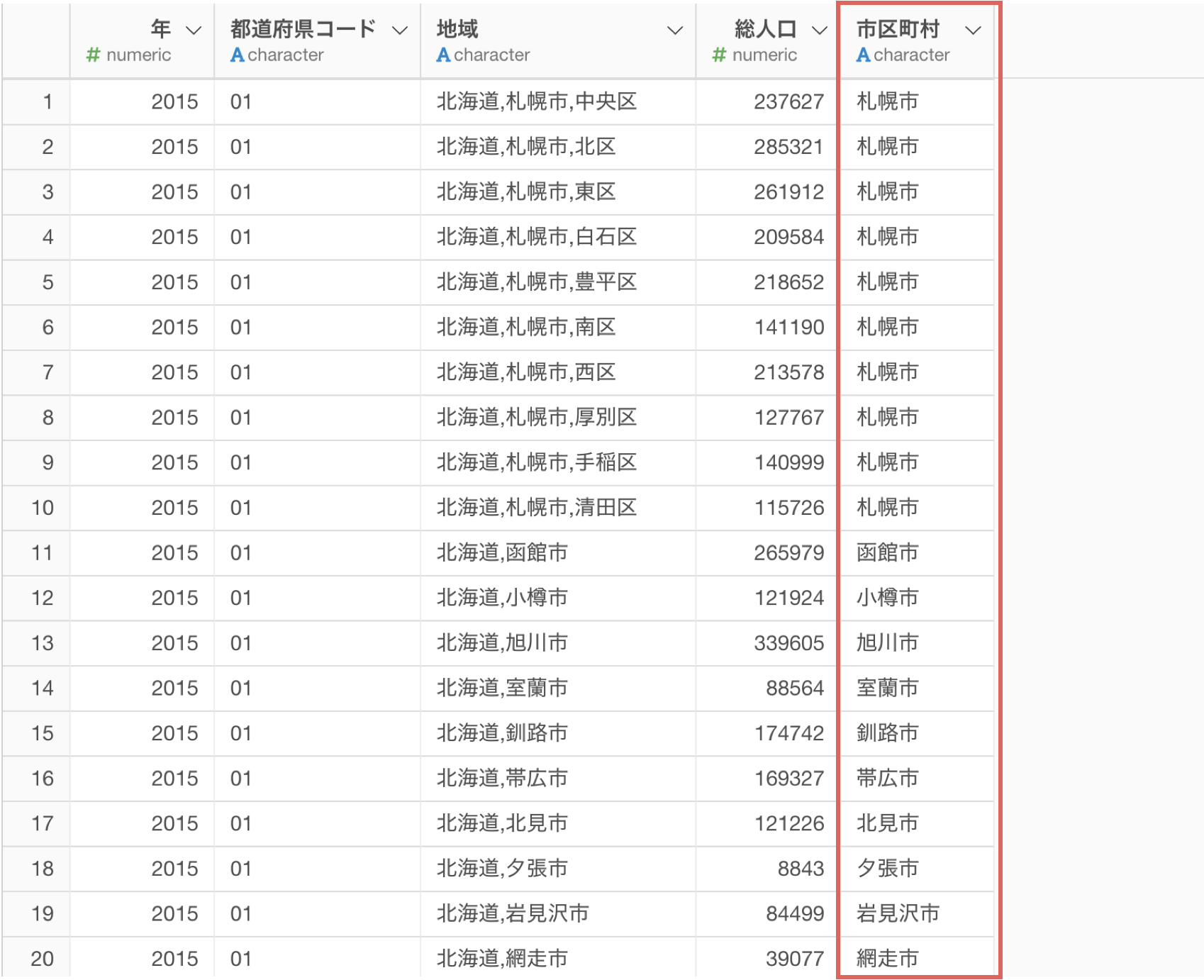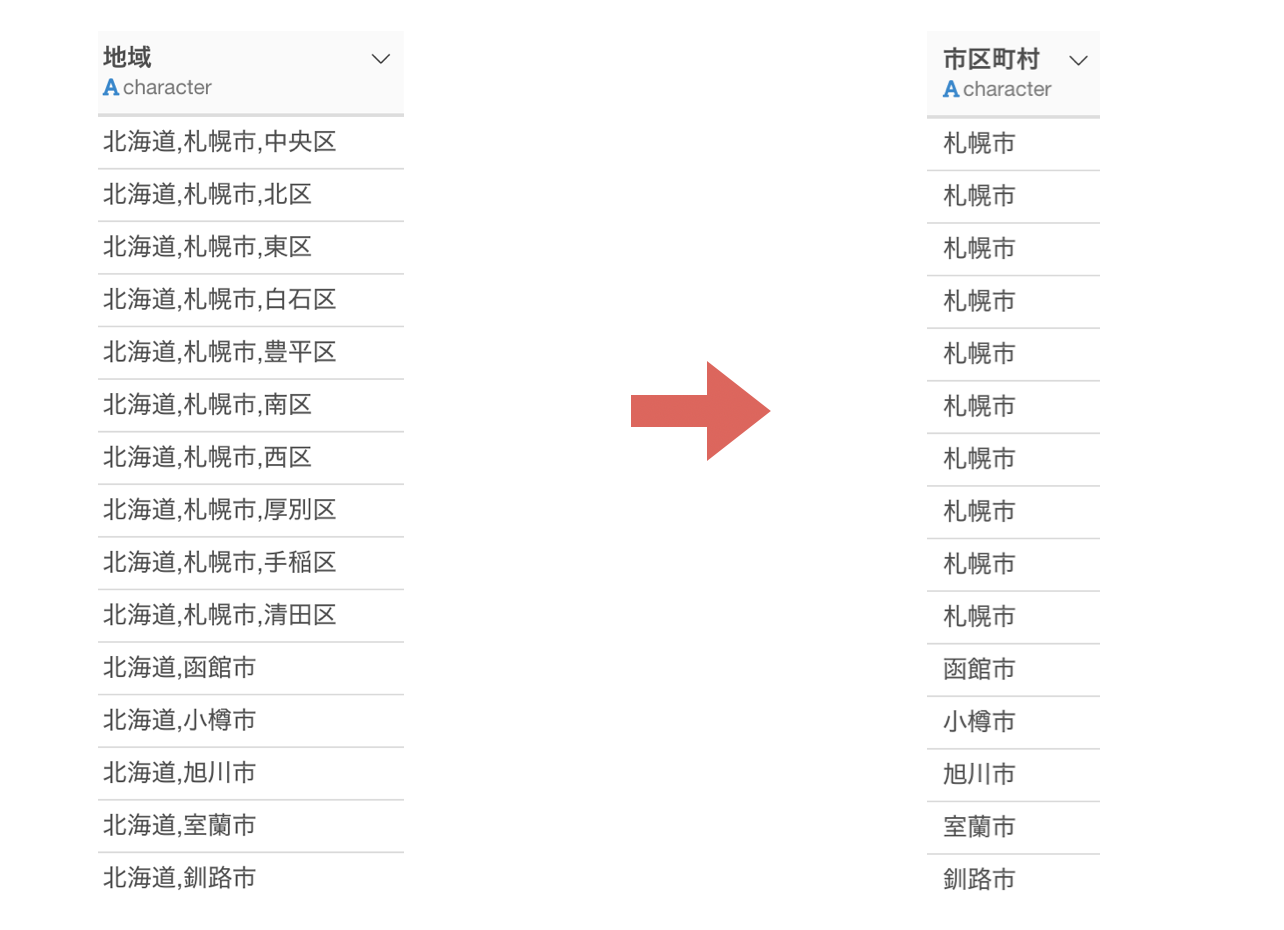
文字列データの中にある2番目の単語を取り出したい
今回は地域別の人口データを使用していきます。
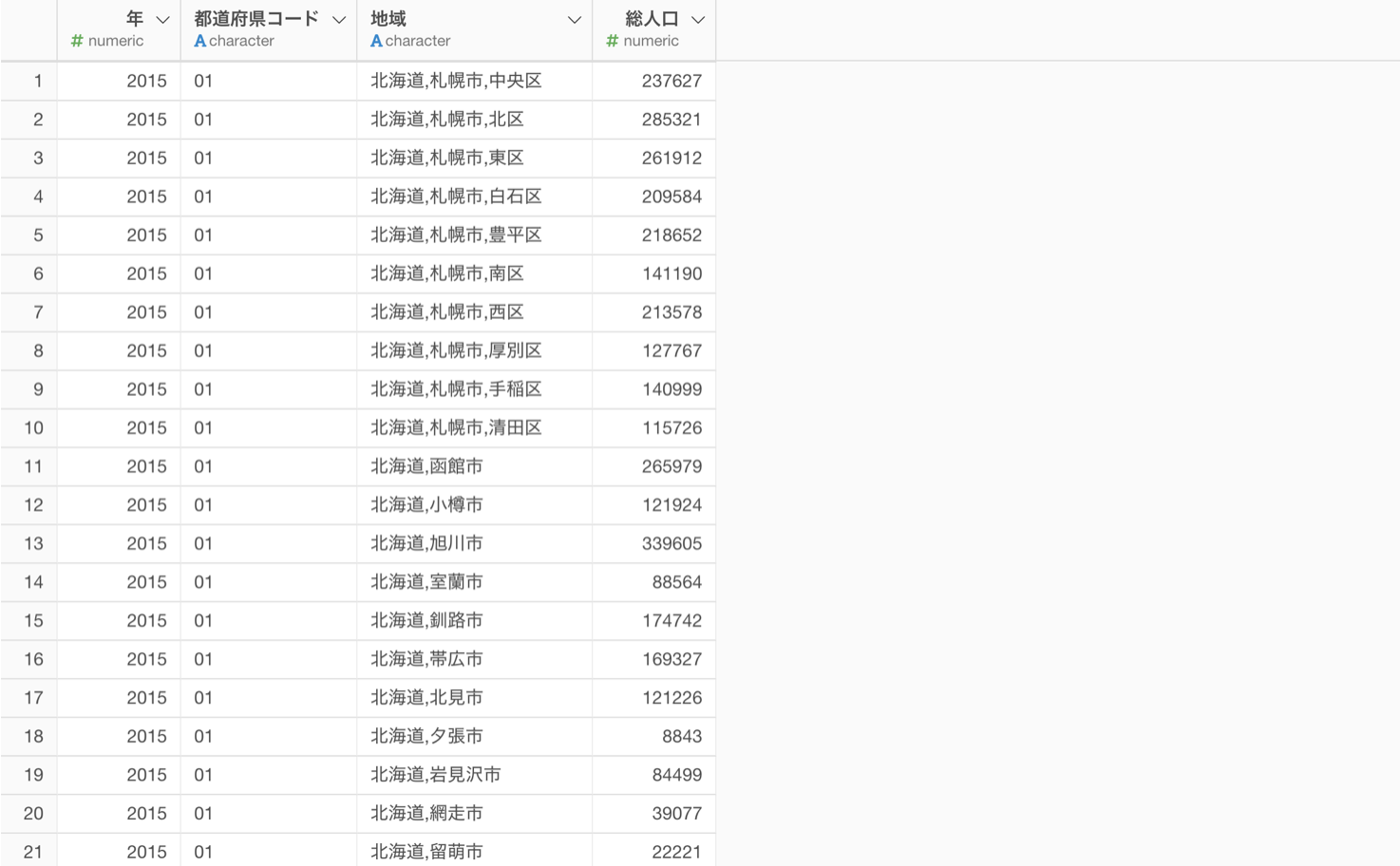
地域の列を見てみると、都道府県、市区町村、それ以降とデータがコンマ(,)で分けられていることがわかります。
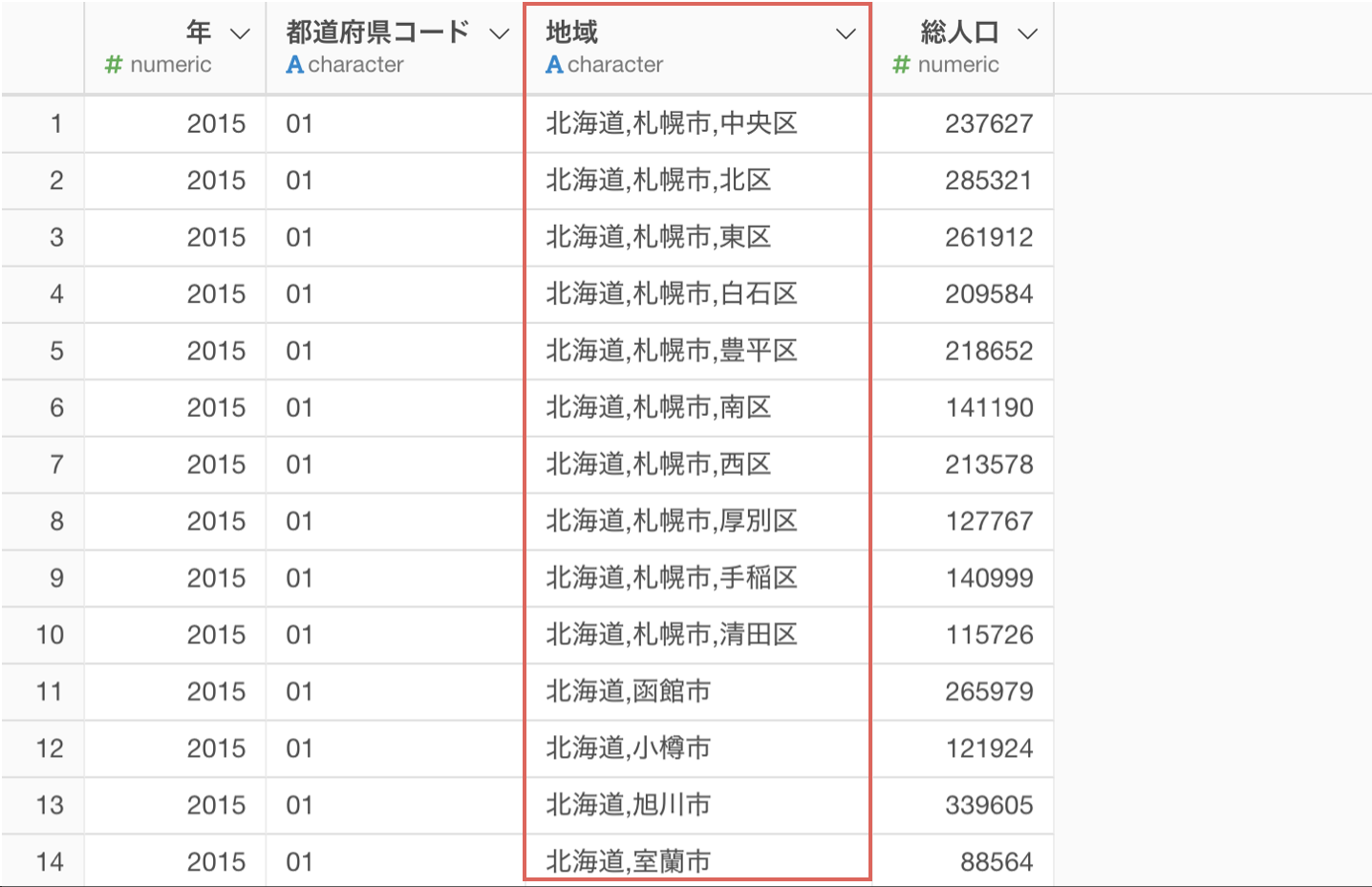
地域の列の2番目にある市区町村の情報を取り出したいです。
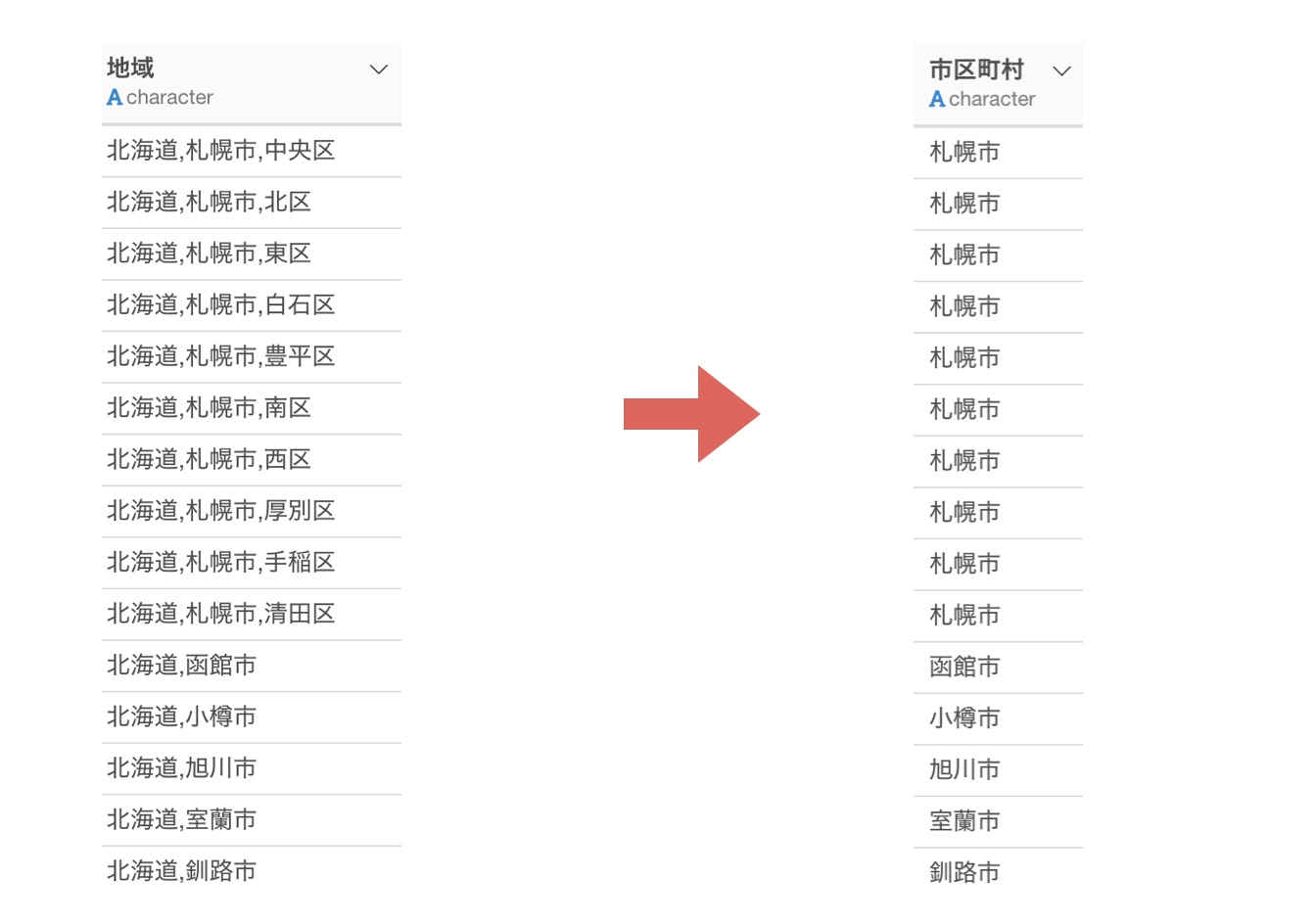
そう言った時に使えるのが、word関数です。
word関数は下記のように記述されます。
word(列名, N番目, sep=",")word関数は3つの引数があり、一つ目の引数は列名です。2つ目の引数は文字列の何番目か、3つ目の引数は区切り文字は何かを指定します。
今回の例では、下記のようになります。
word(地域, 2, sep = ","そして、ExploratoryではUIから簡単にアクセスすることができます。
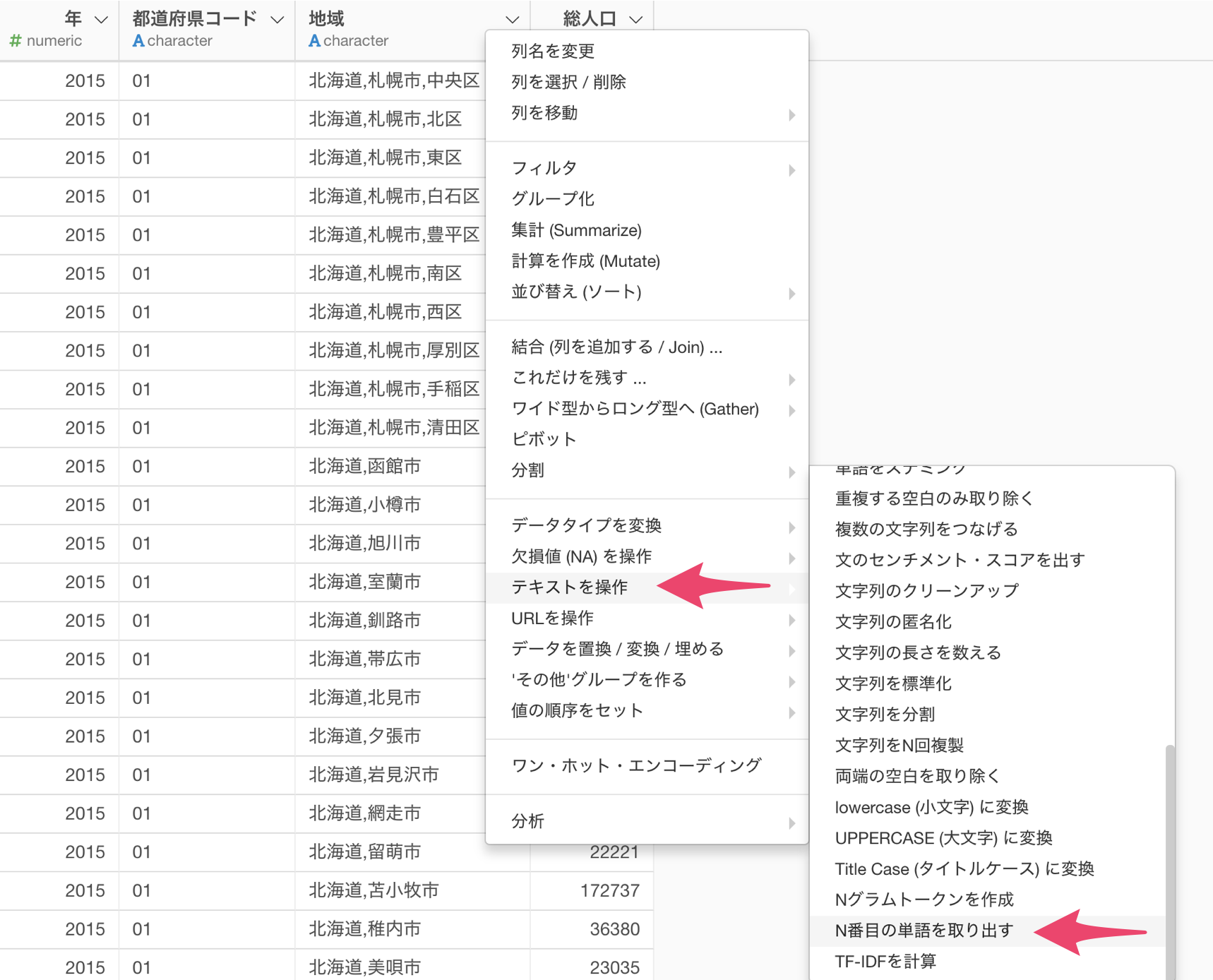
地域の列ヘッダメニューからテキストを操作を選び、N番目の単語を取り出すを選択します。
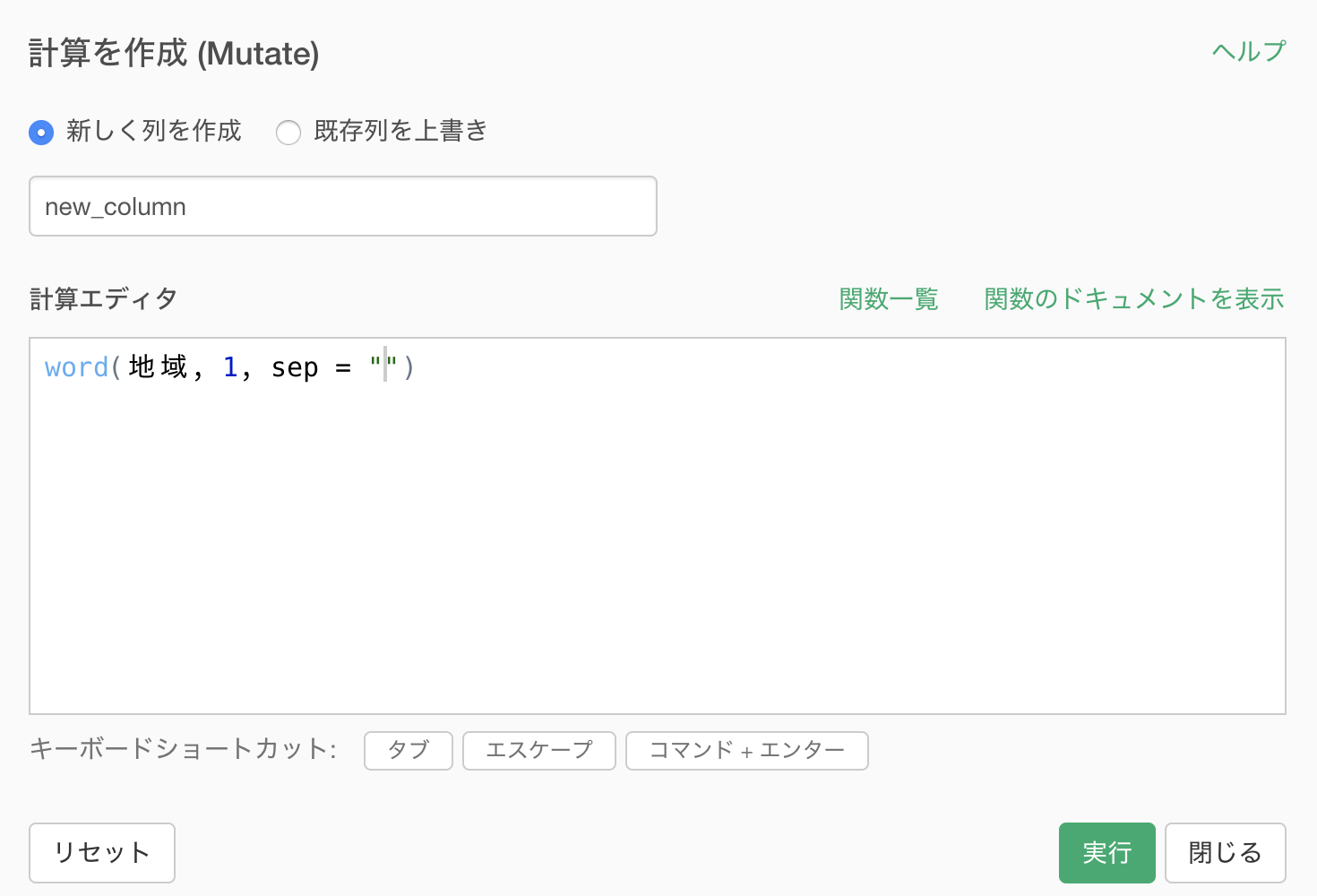
計算を作成のダイアログが開き、すでにword関数と引数が入力されています。
今回は2番目の市区町村の情報を取り出したいので2つ目の引数には2を、コンマ(,)で区切られているため3つ目の引数にはコンマ(,)を指定して実行します。
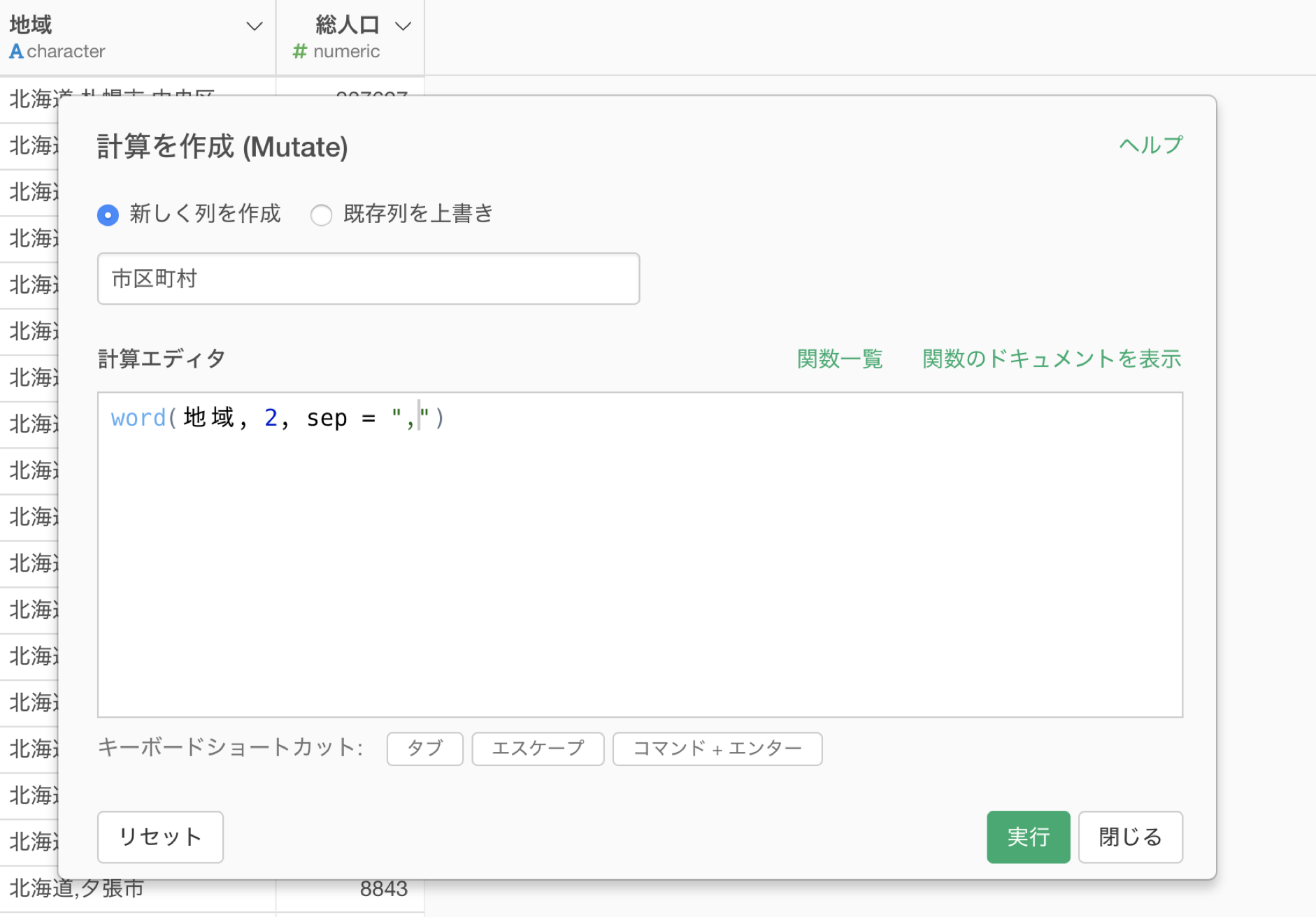
これで地域の列から2番目にある市区町村のデータを取り出すことができました。