テキストの組み合わせをカウントする方法
下記はTwitterから「コロナウイルス」をキーワードにデータを取得してきて、文章の単語化(分かち書き)を使ったあとのデータです。
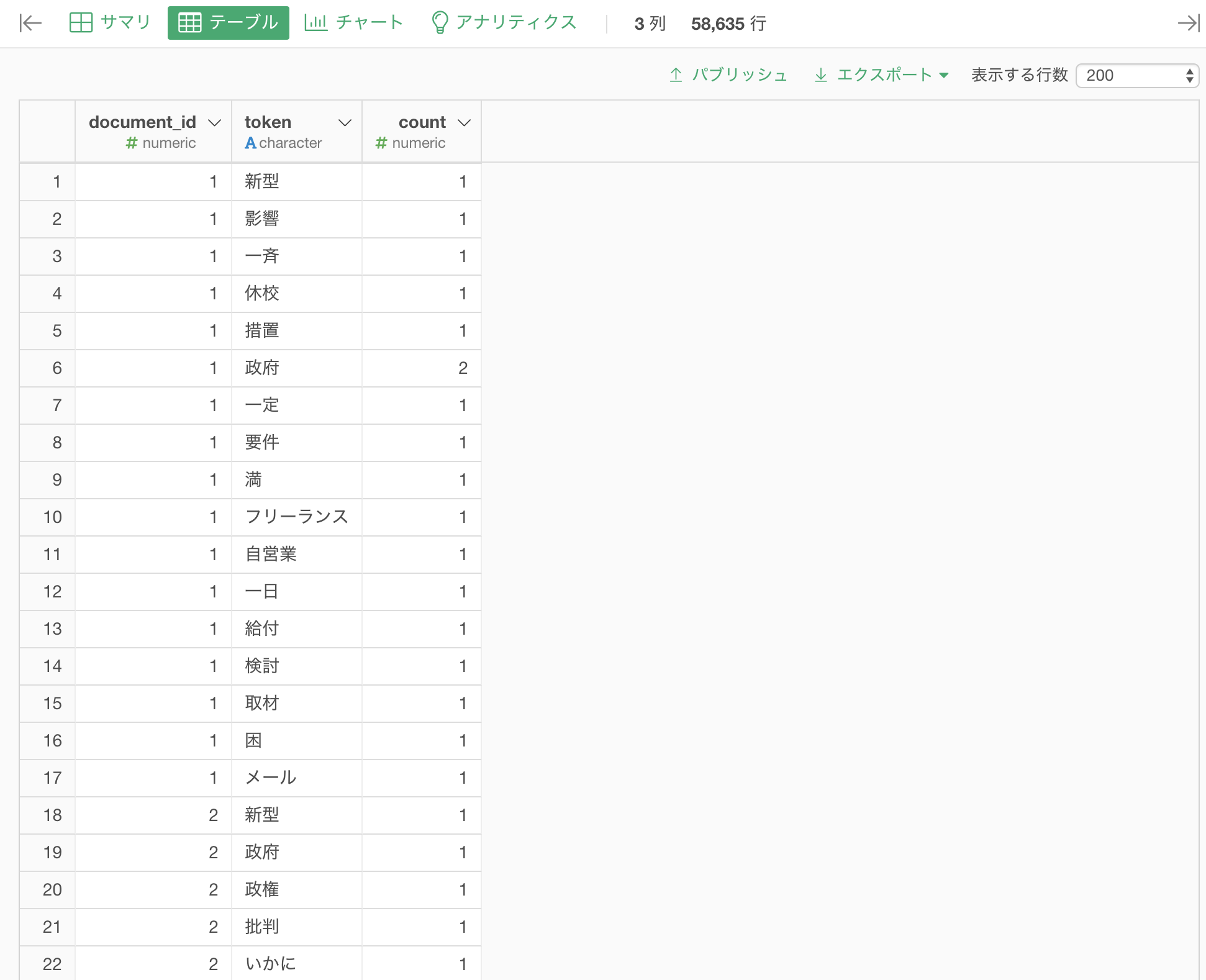
単語の頻出回数だけでなく、どの単語とどの単語がよく使われるのか気になることがあります。
例えば、感染と新型という単語がよく一緒に使われると言ったことを知りたいです。
Exploratoryでは、UIからテキストのペアをカウントすることができます。
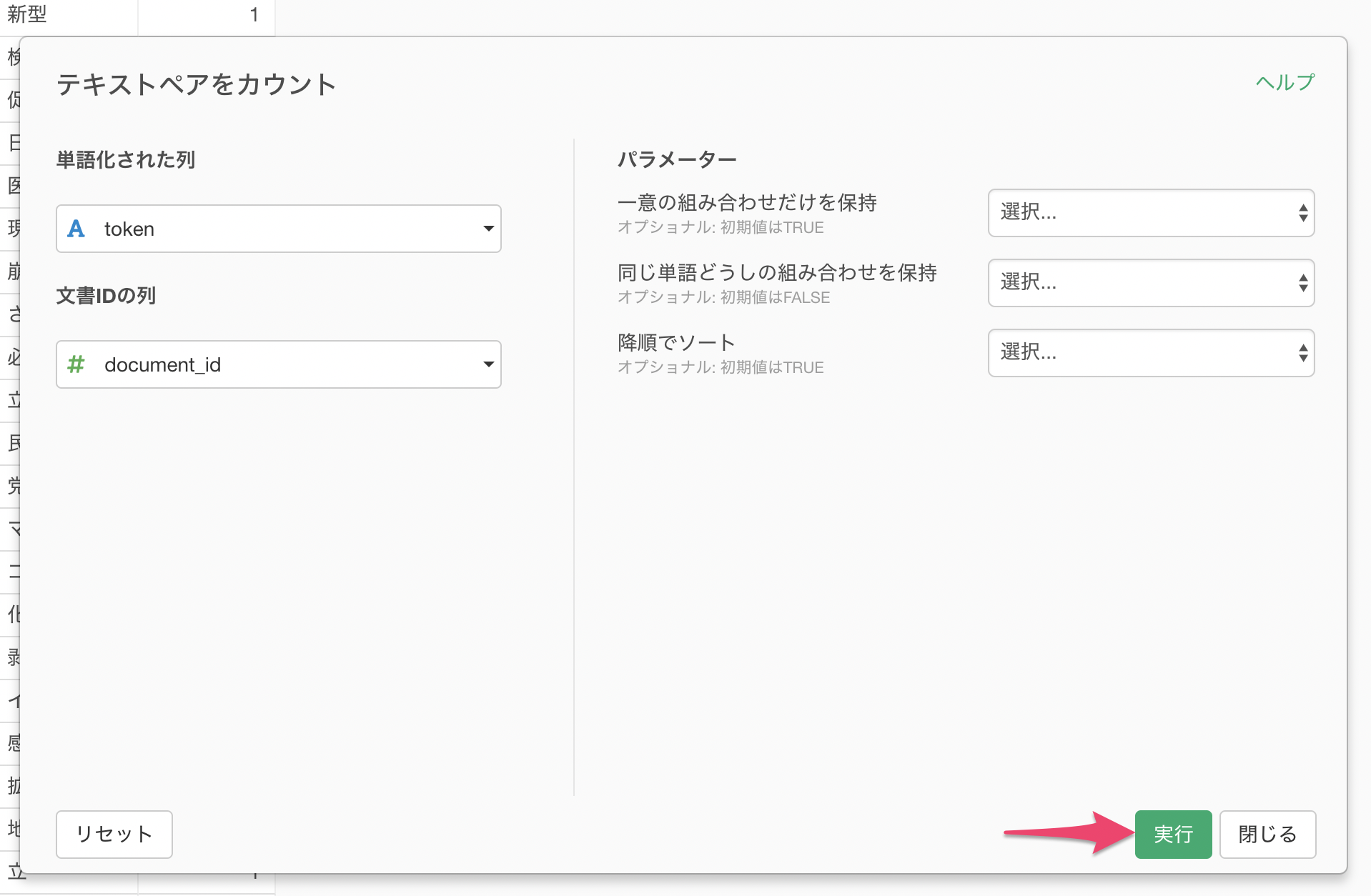
既に単語化されている列ヘッダメニューからテキストデータの加工(UI) のテキストペアのカウントを選択します。
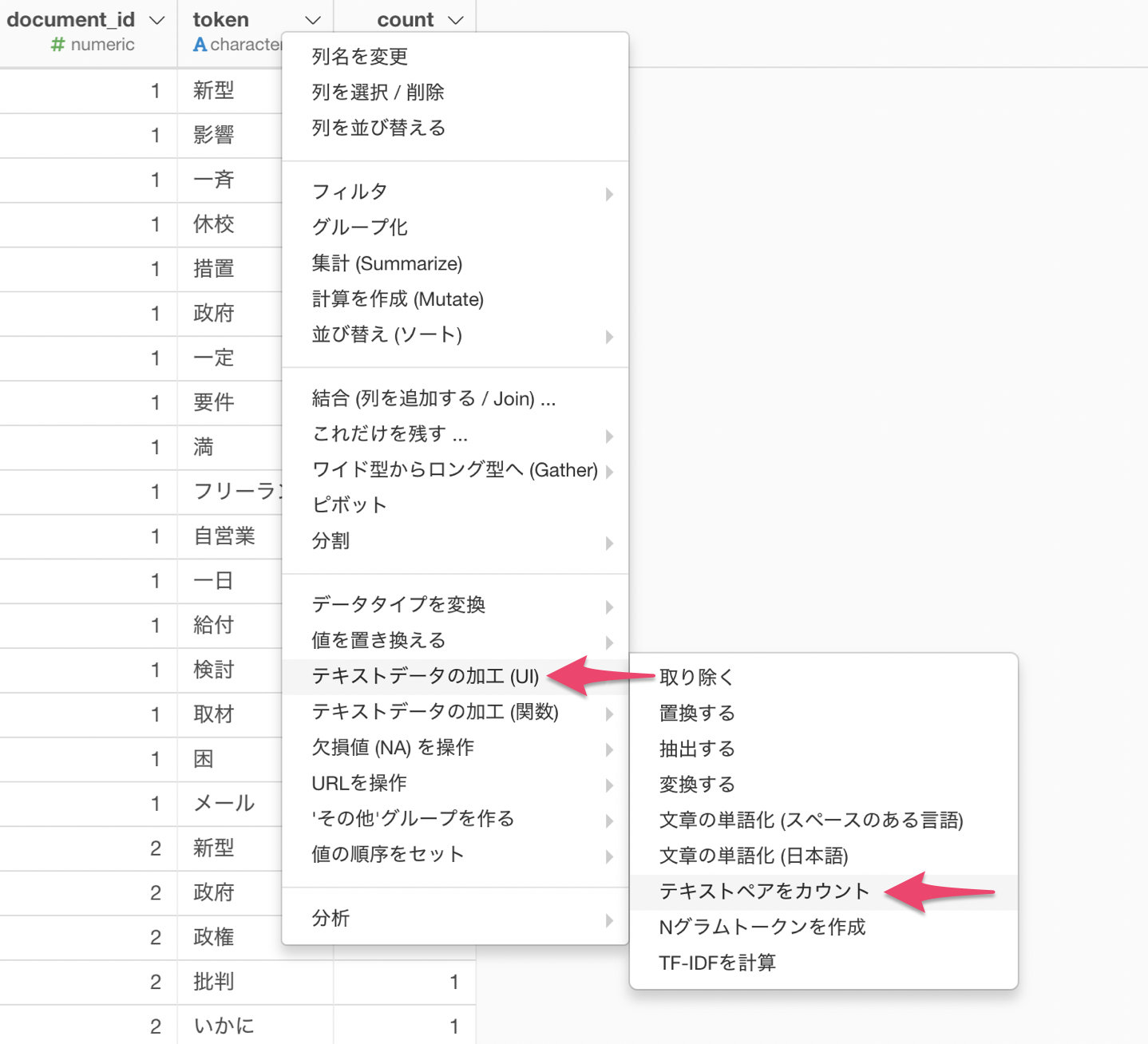
テキストペアをカウントのダイアログが表示されます。
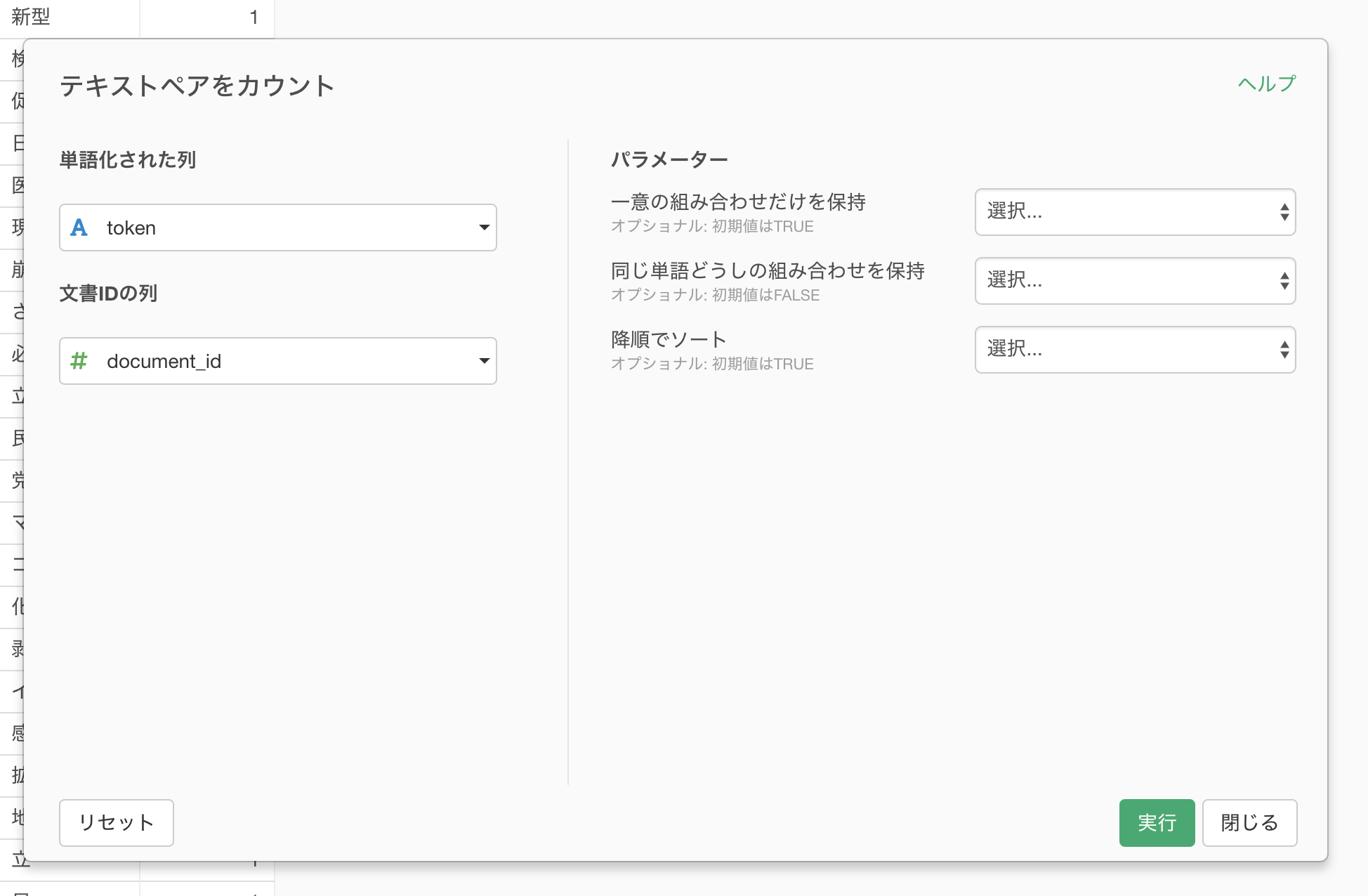
文書IDとは単語化される前の文書の一意なIDのことです。UIから実行できる文章の単語化では、自動でdocument_idと言う列が作成されます。
今回はデフォルトのまま実行します。
それぞれの単語の組み合わせの回数を列として作ることができました。
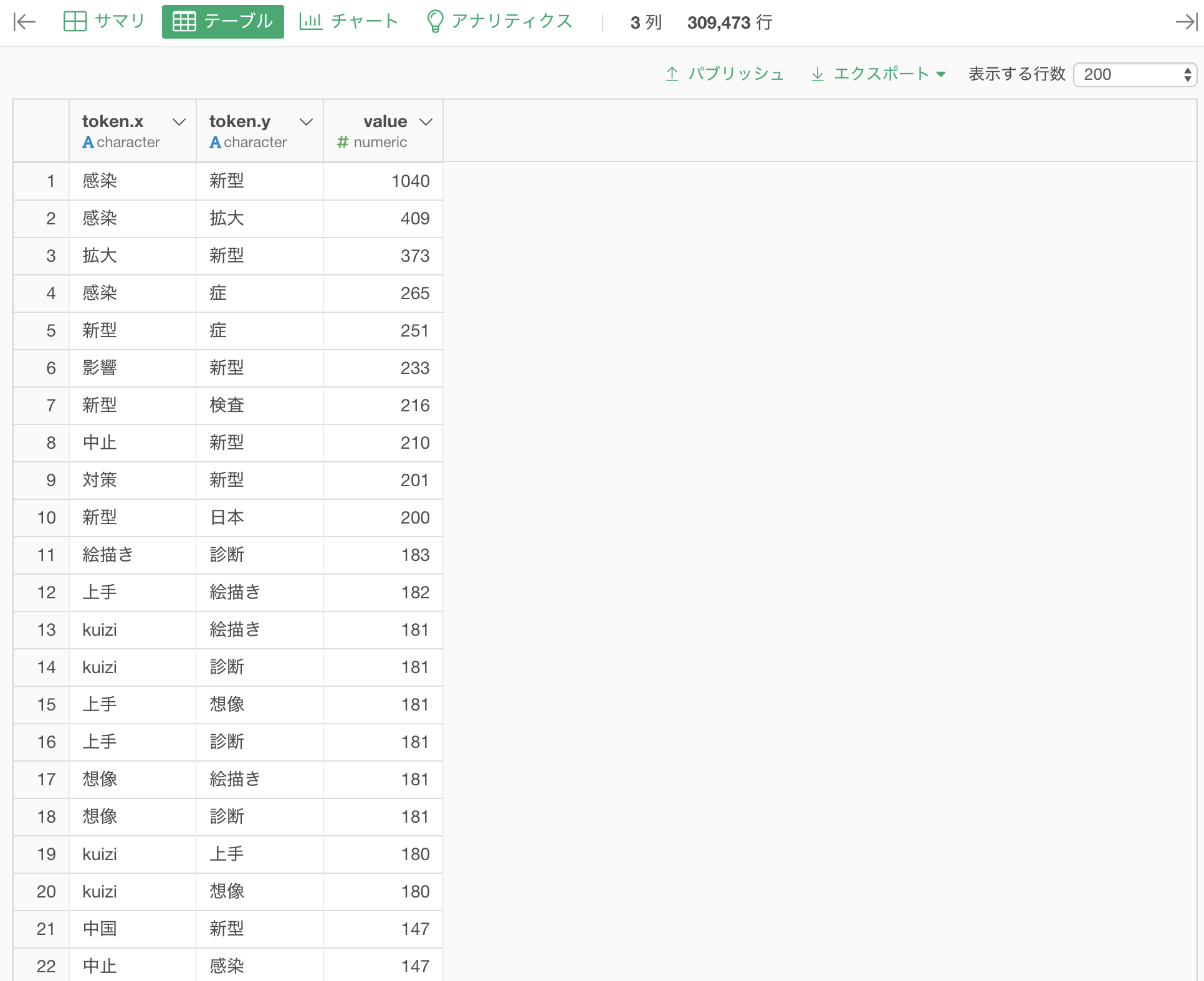
単語のペアが別々の列になっているので、くっつけたいです。
ShiftキーまたはCommndキー(Mac) / ctrlキー(Windows)を押しながらtoken.xとtoken.yを選択し、列ヘッダメニューから複数の列をつなげる(Unite) を選択します。
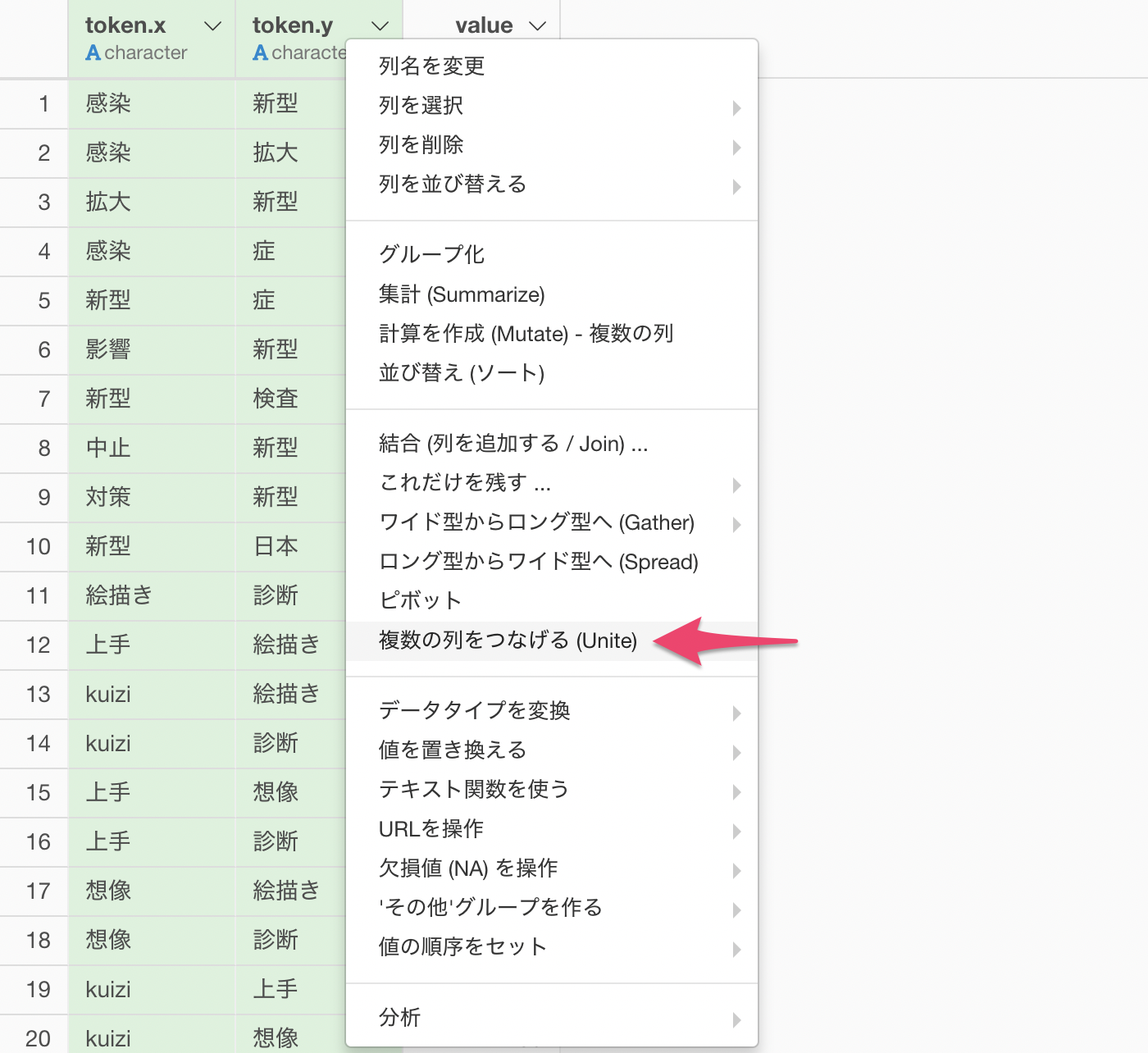
複数の列をつなげる(Unite)のダイアログが表示されます。
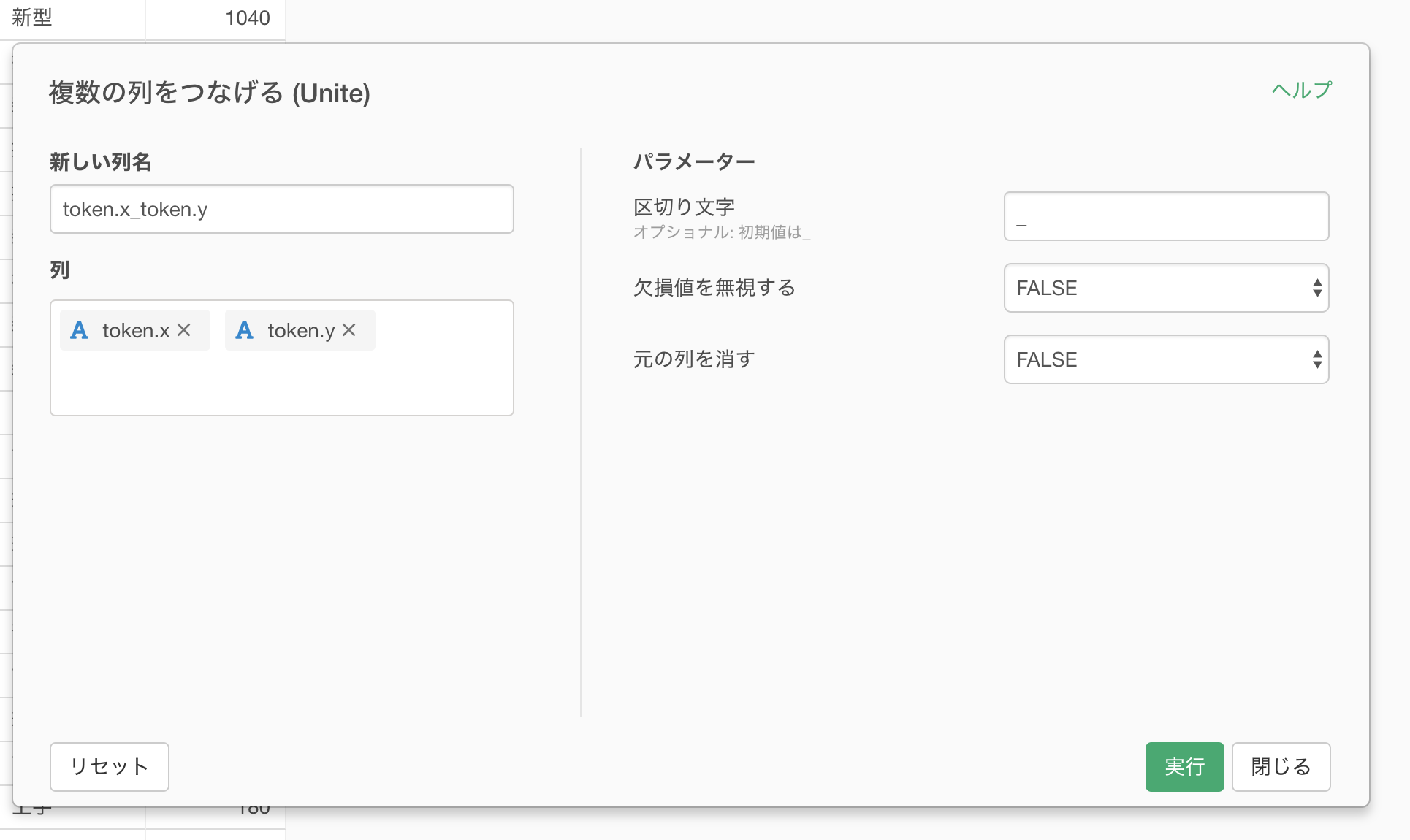
新しい列名に任意の文字を入力して実行します。
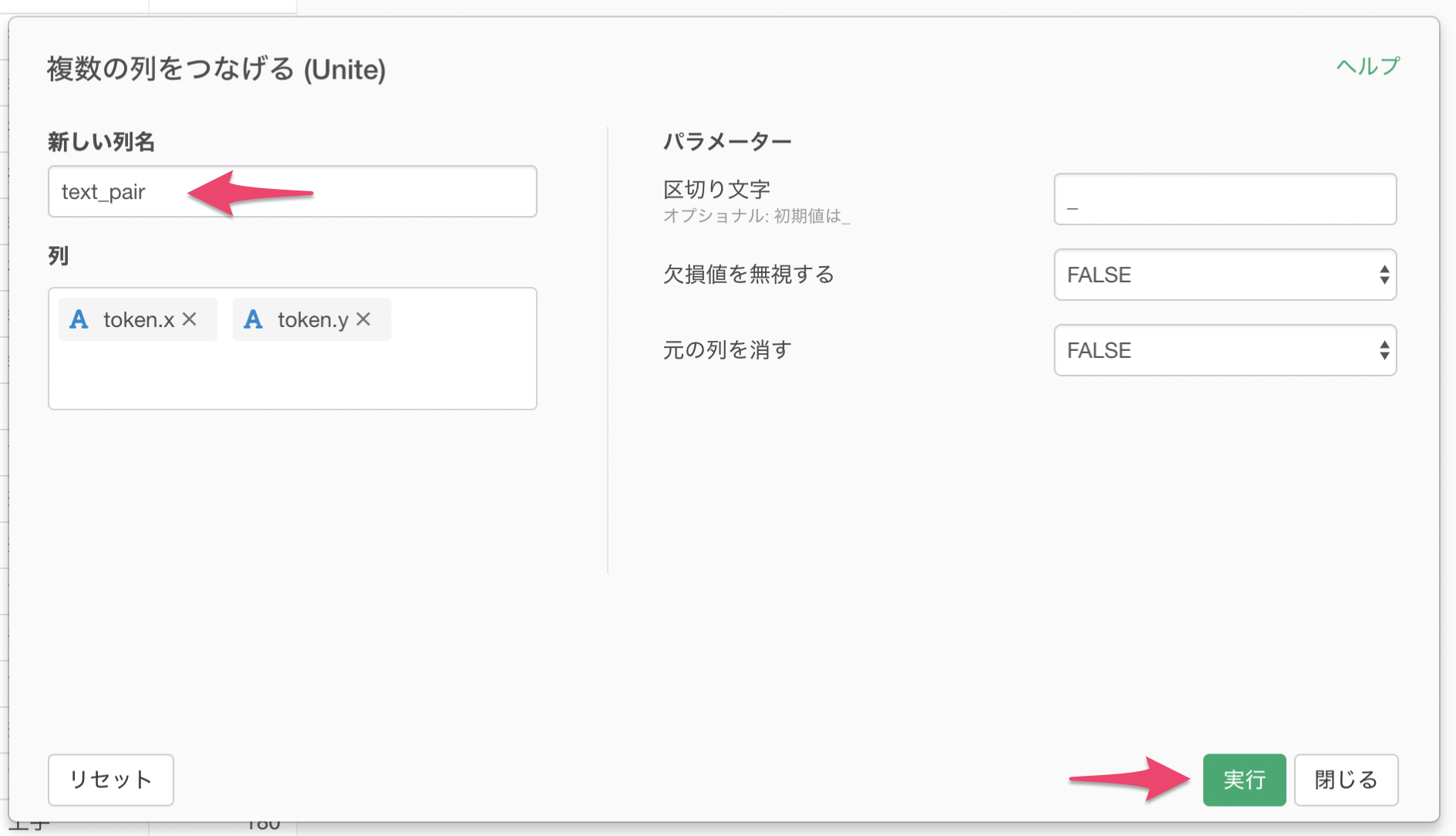
単語のペアをつなげることができました。
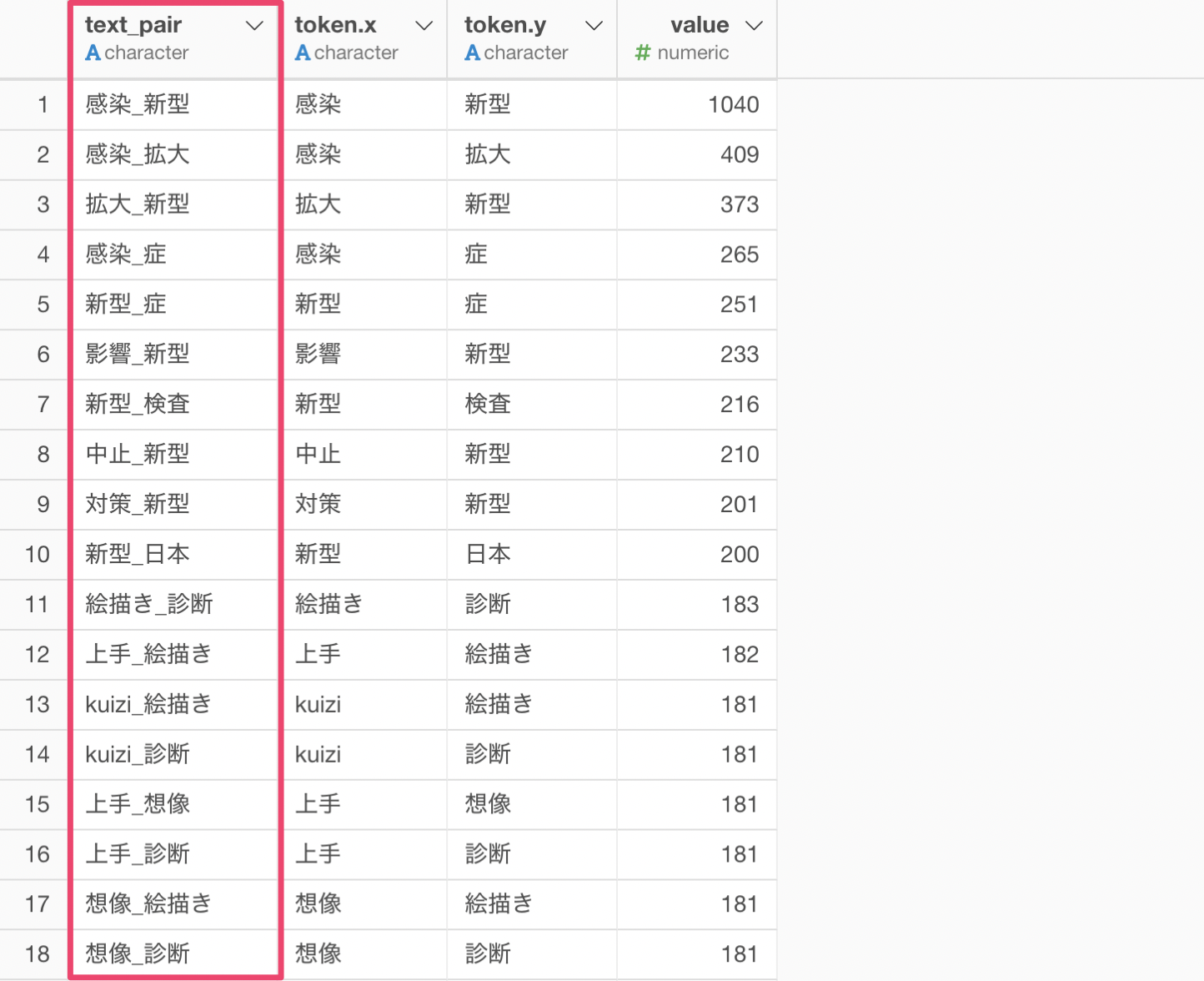
どの単語のペアがよく使われるのかを見るために可視化したいところですが、一意の数が行の数分あります。
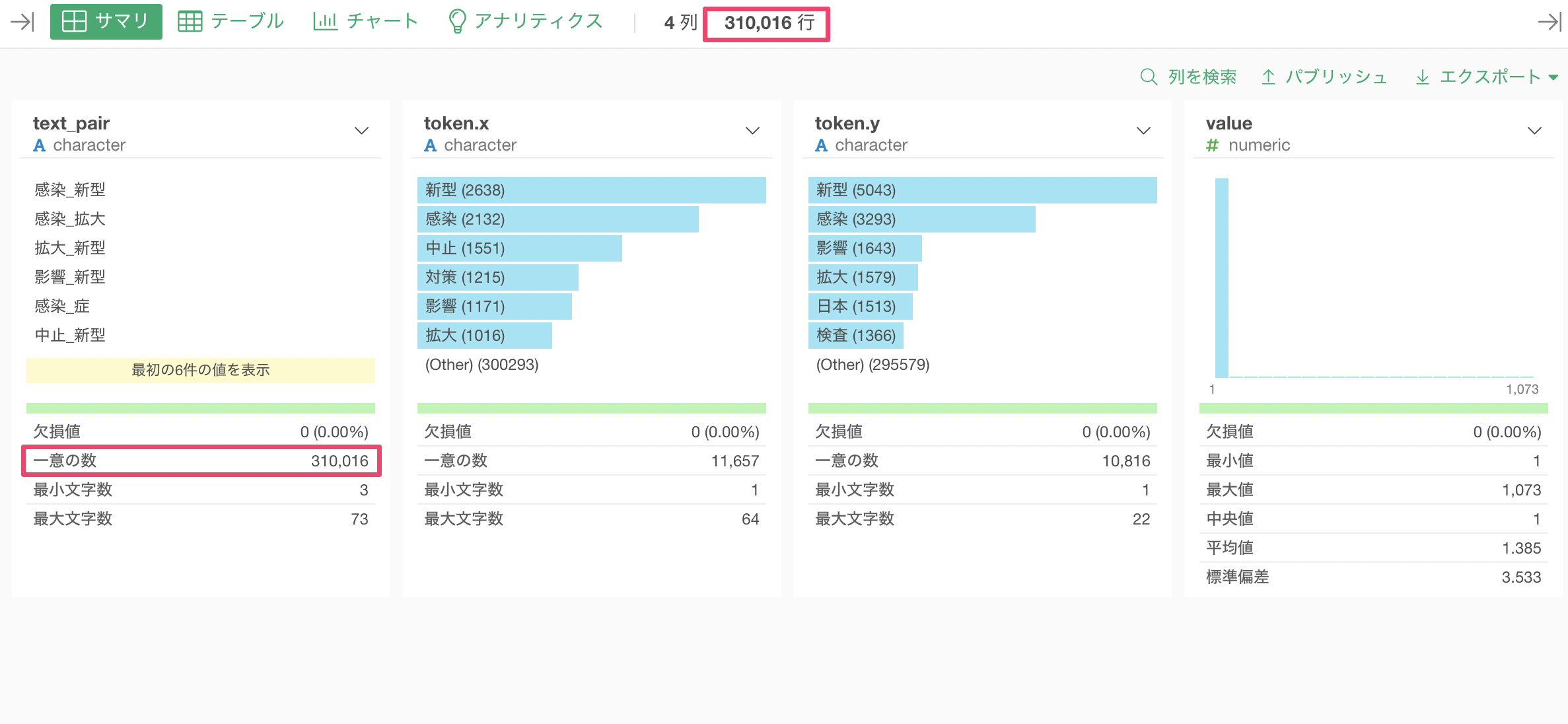
そして、value(単語のペアの出現回数)の列をみると多くの値は0-50のレンジにあることがわかります。
このまま可視化してしまうとチャートでの処理が重くなってしまうので、valueが10以上のデータのみにフィルタしていきます。
valueの列ヘッダメニューから、フィルタを選び、以上を選択します。
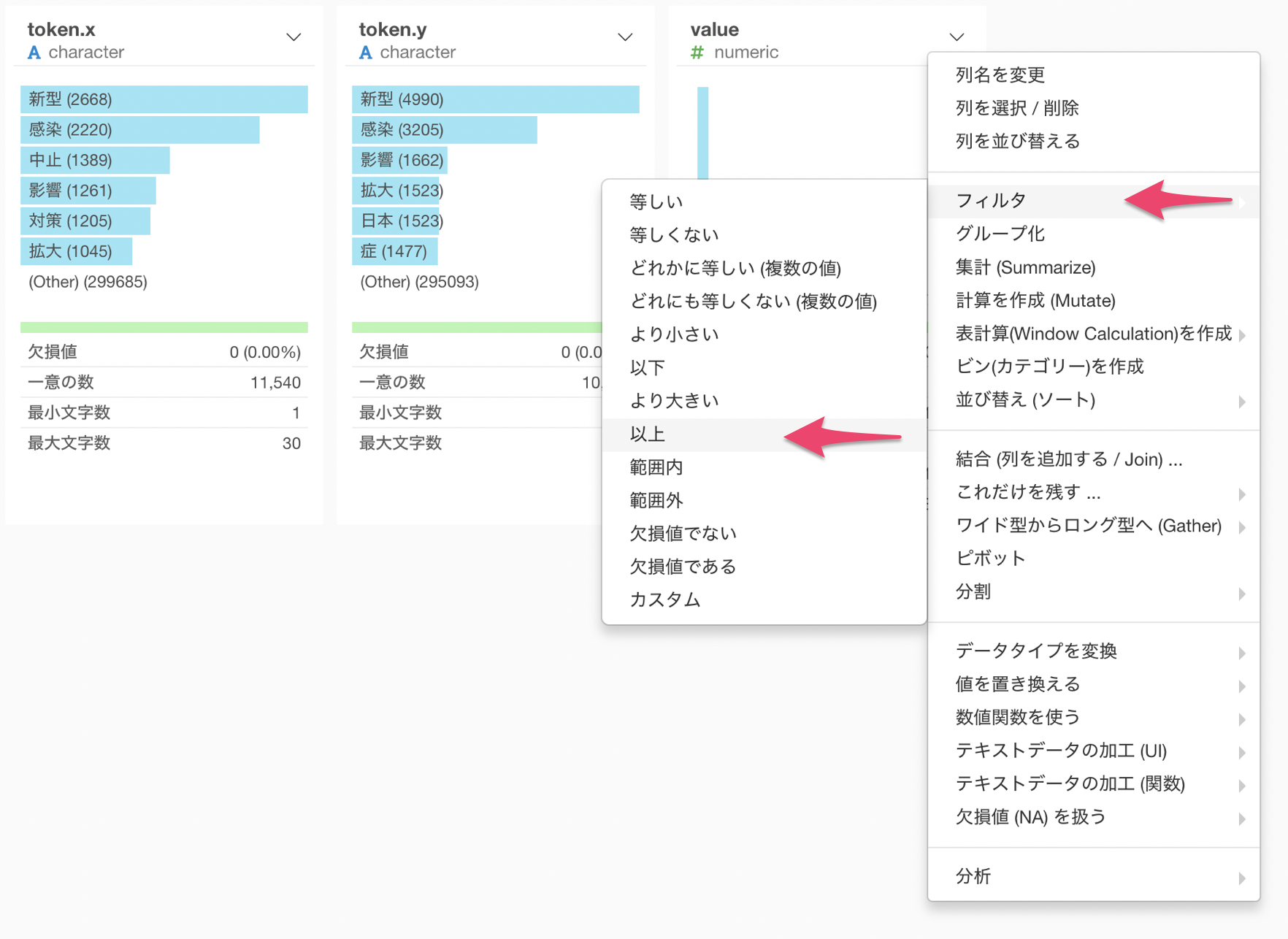
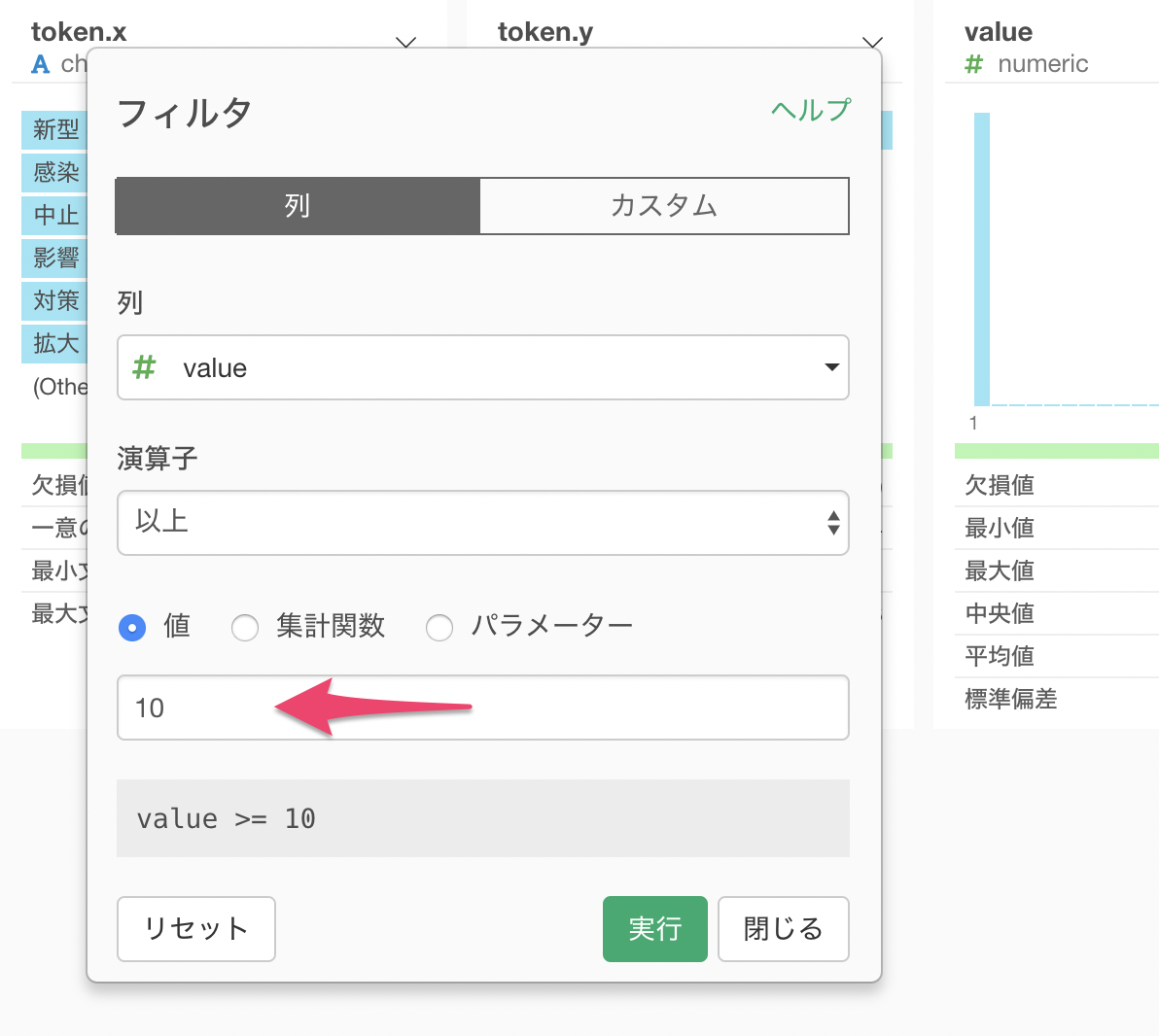
フィルタのダイアログが表示されるので、値に10を入力して実行します。
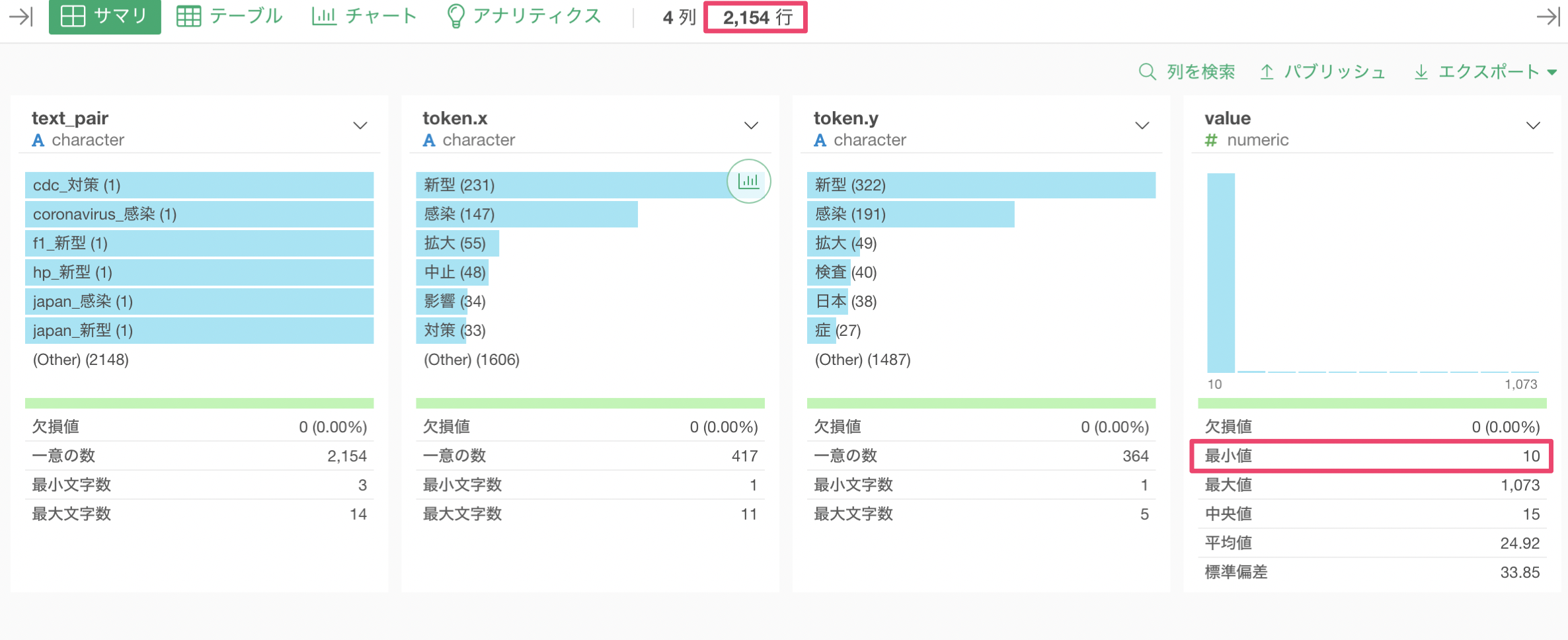
出現回数が10回以上の単語のペアのみを残すことができ、行数は2,154行になっていることがわかります。
単語の組み合わせを可視化する
準備が整ったのでチャートタブに移り可視化していきます。
タイプにバーチャートを選択します。
X軸にはtext_pairを選び、Y軸にはvalueを選び、集計関数は合計値(sum) を選択します。最後にソートから降順(desc) を選択してvalueの大きい順に並び替えます。
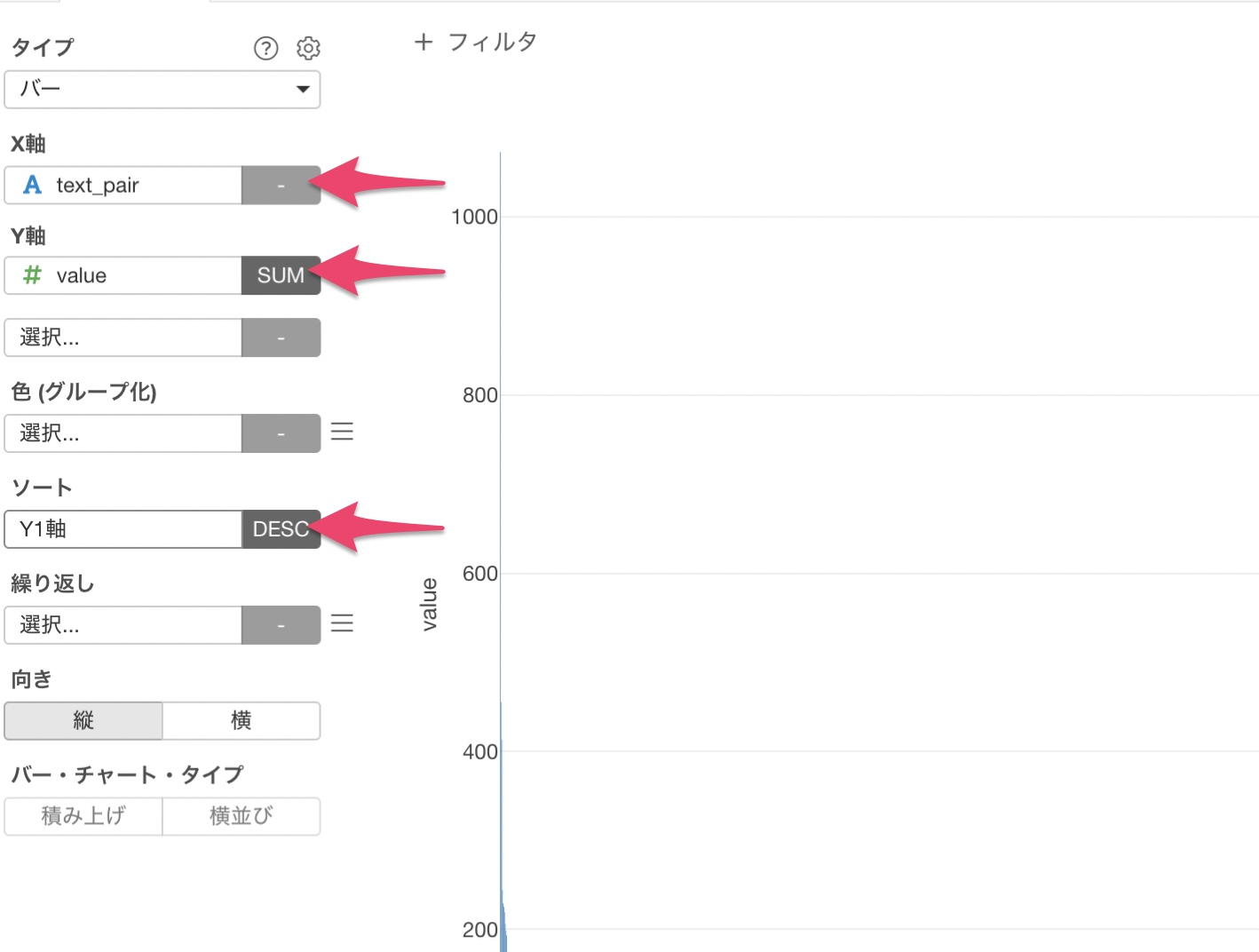
単語のペアの出現回数順で可視化することができました。
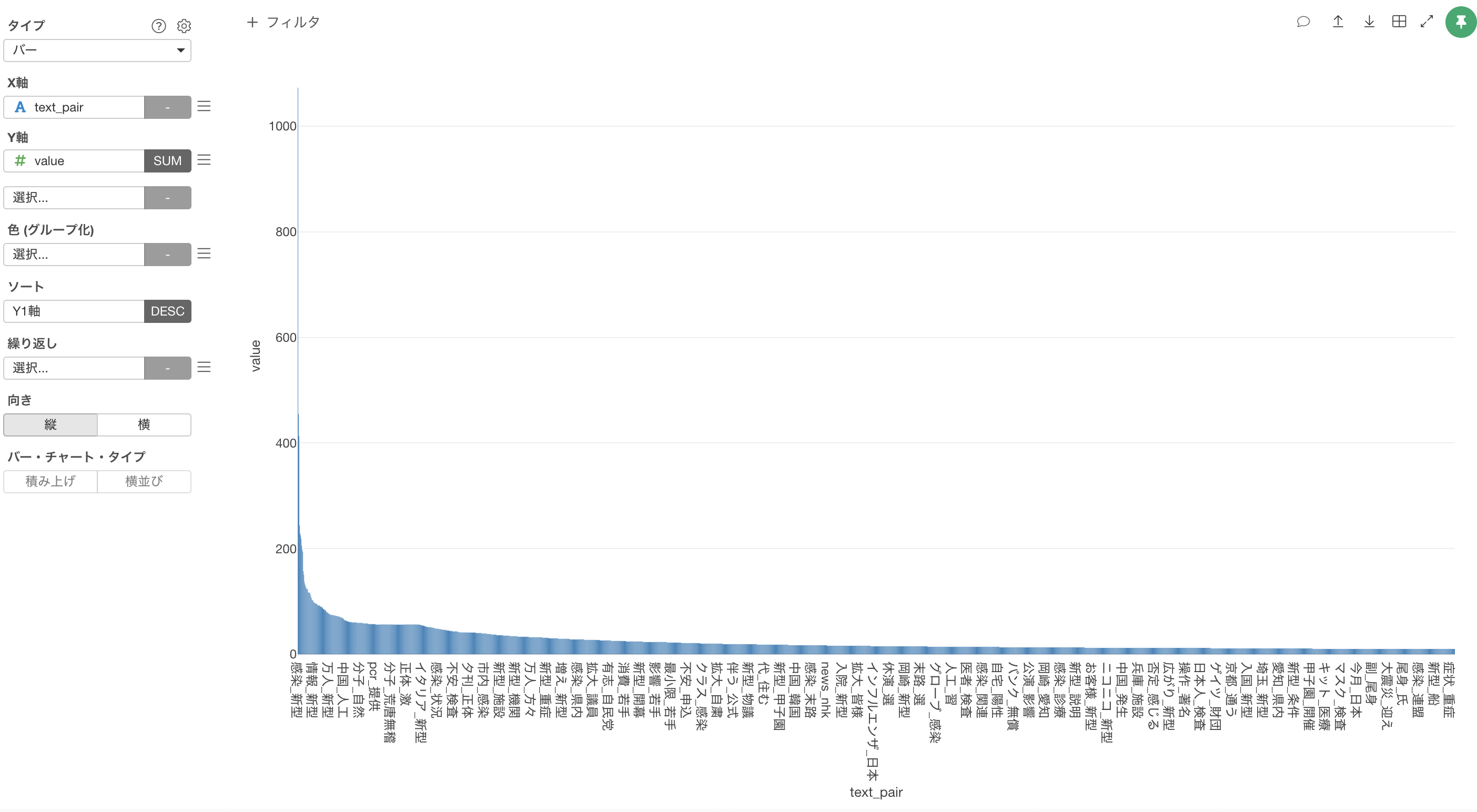
しかし、現在はX軸に行の数分(2,154本)のバーが可視化されていて、多すぎるため上位50のみを残していきます。
X軸から表示する値の制限を選択します。
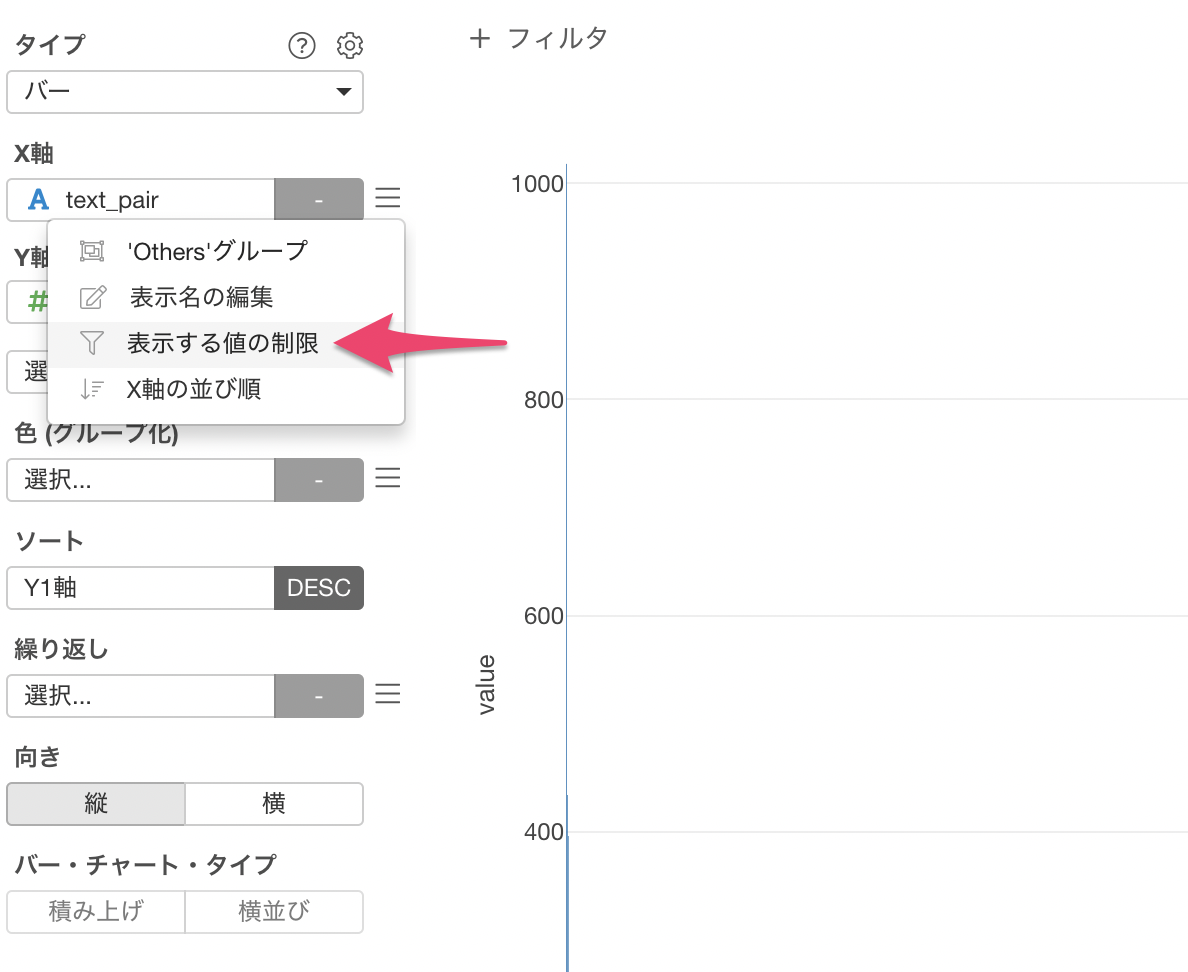
タイプに上位を選び、結果の数に50を入力して適用します。
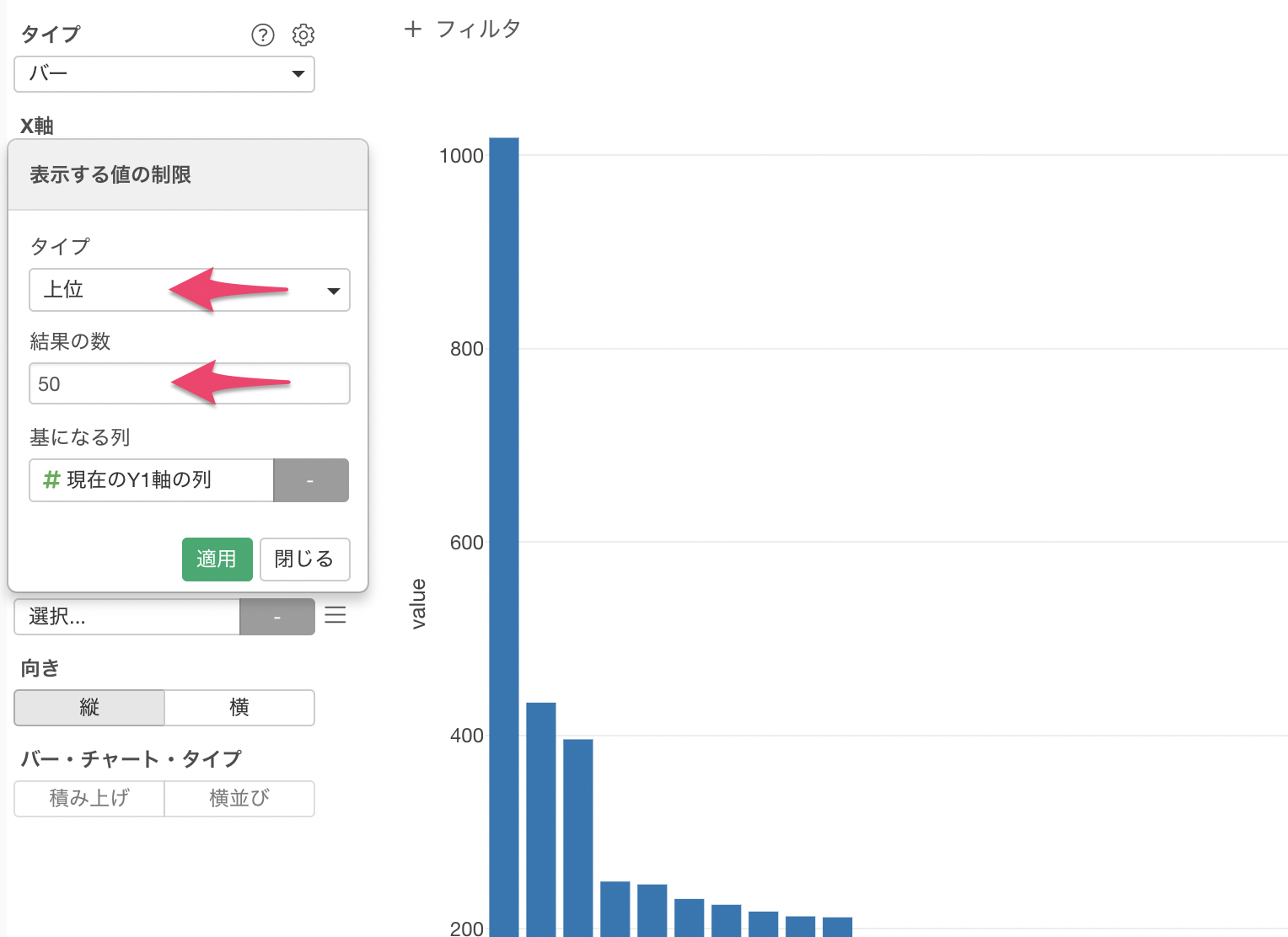
単語のペアの出現回数の上位50のみを残すことができました。
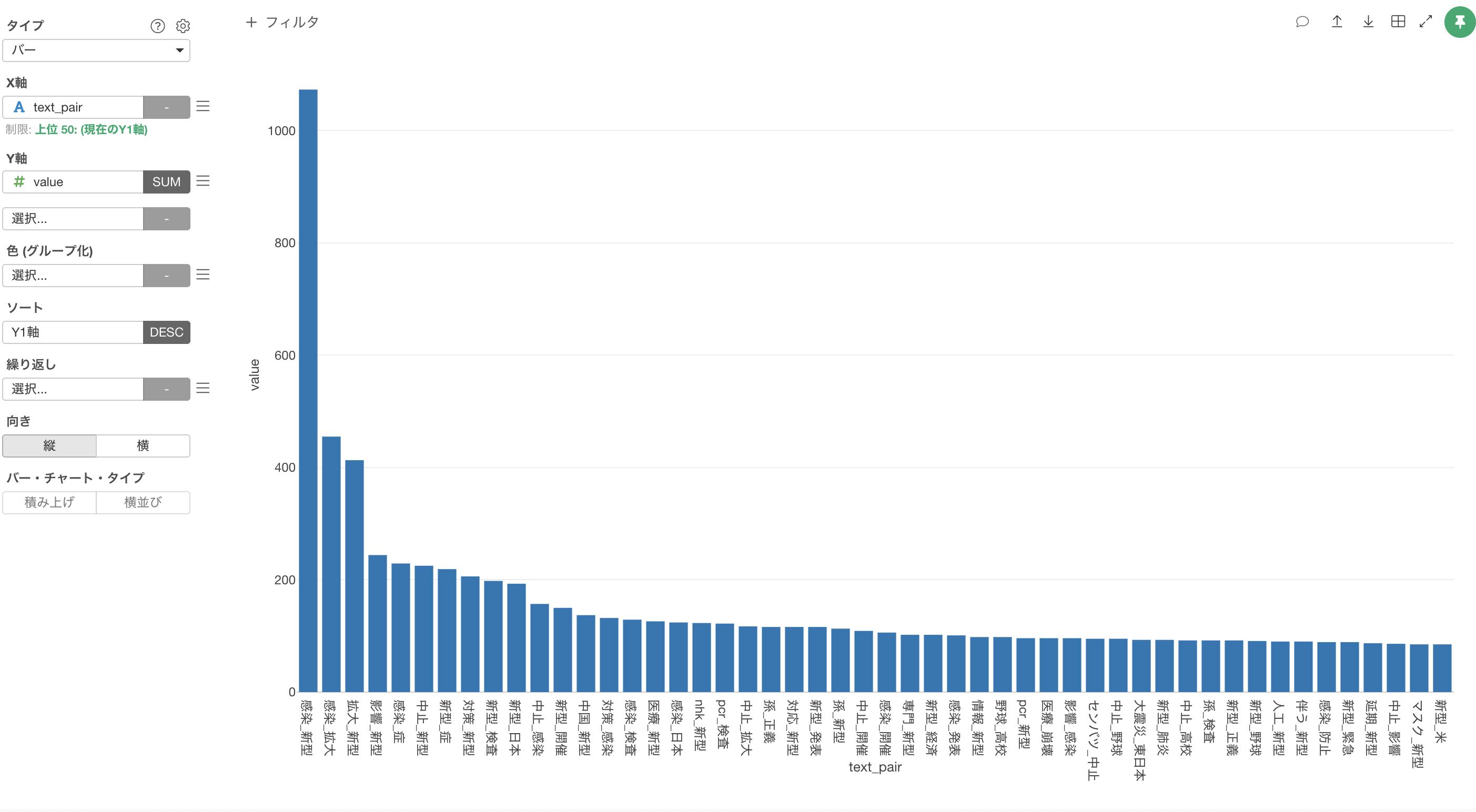
次はバーチャートを横向きにして可視化したいため、向きに横を選択します。
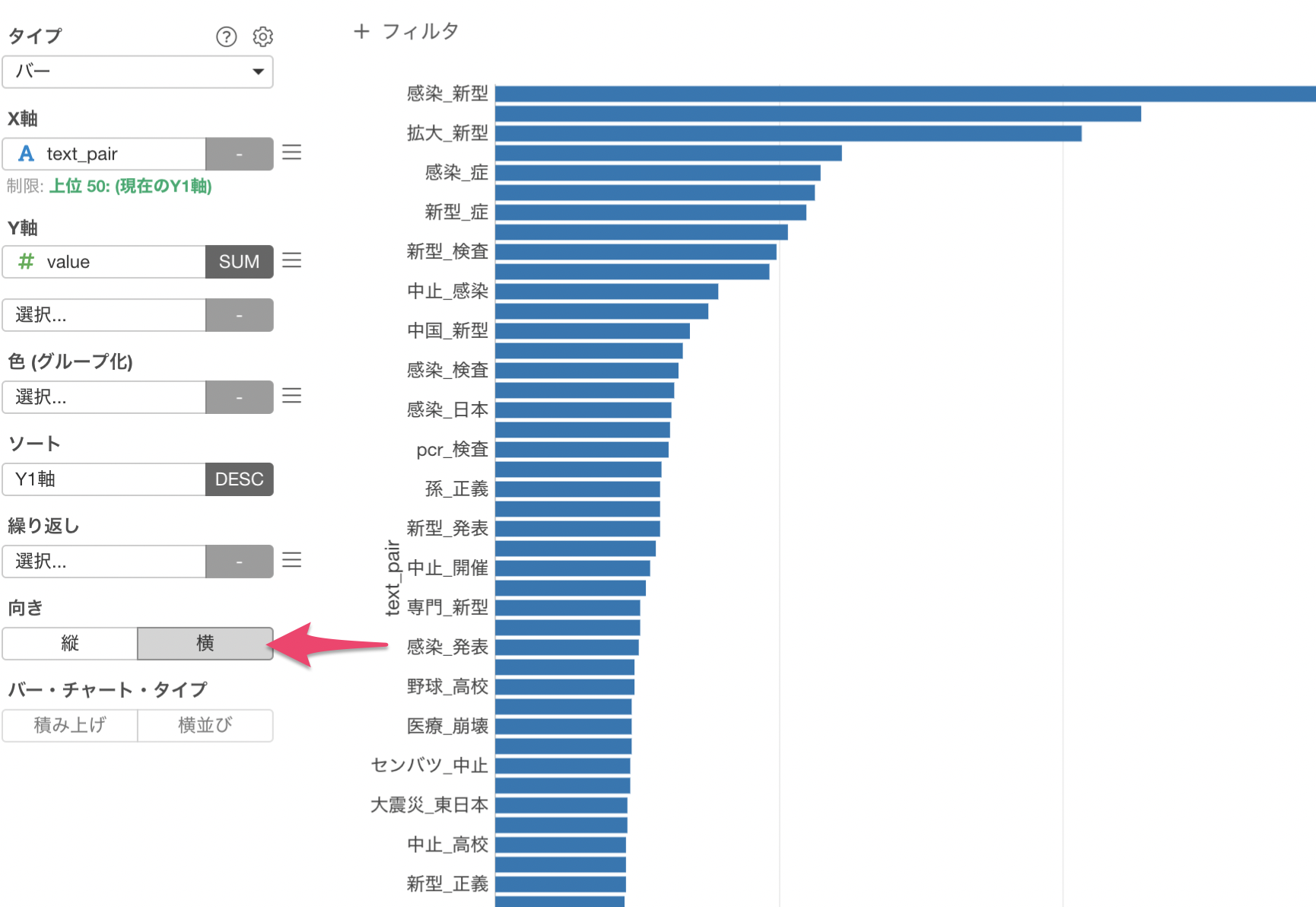
バーチャートを横向きにして可視化することができました。こちらの方がX軸のテキストが読みやすいですね。
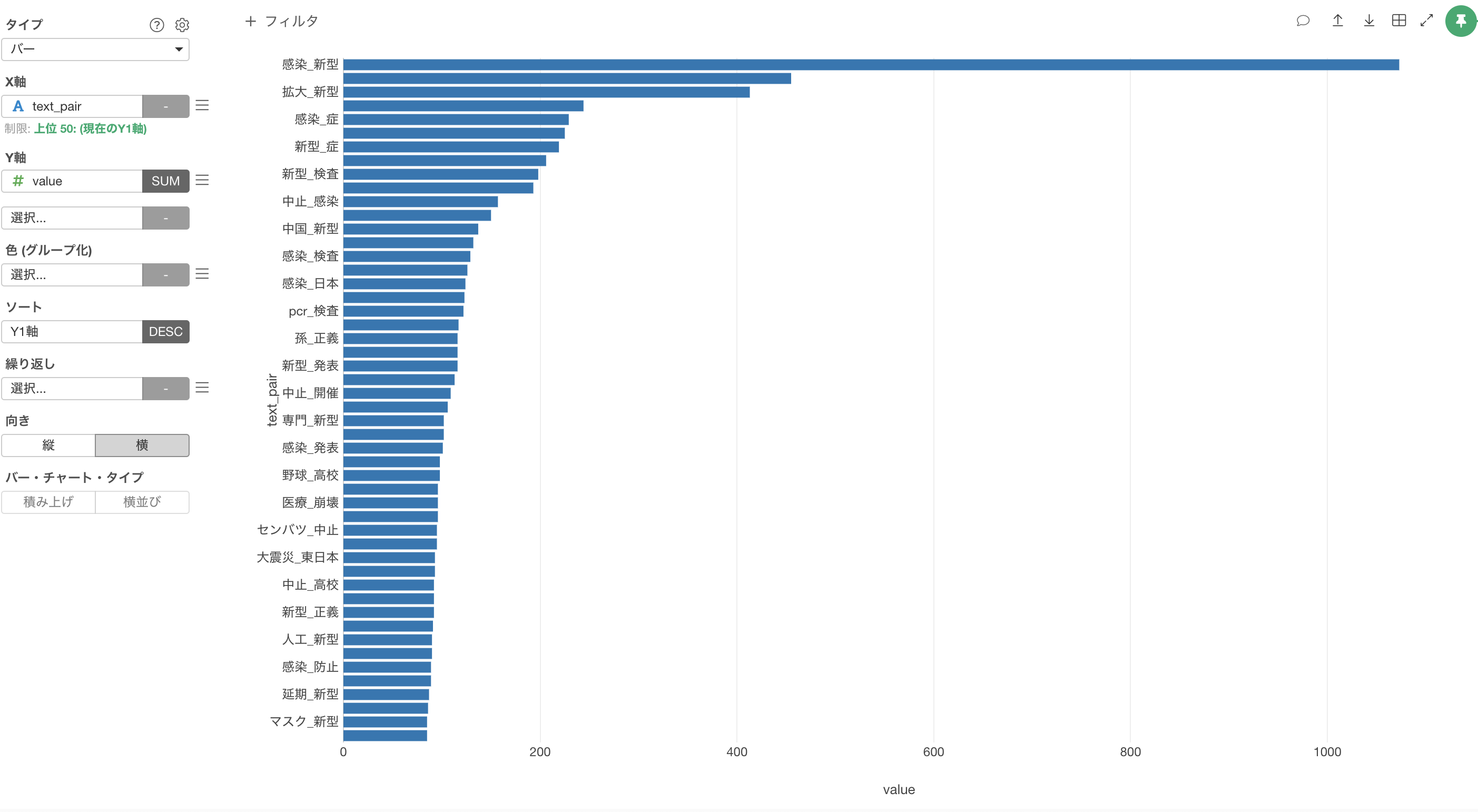
X軸のテキストのサイズが大きいため、プロパティからフォントサイズに10を入力して適用します。
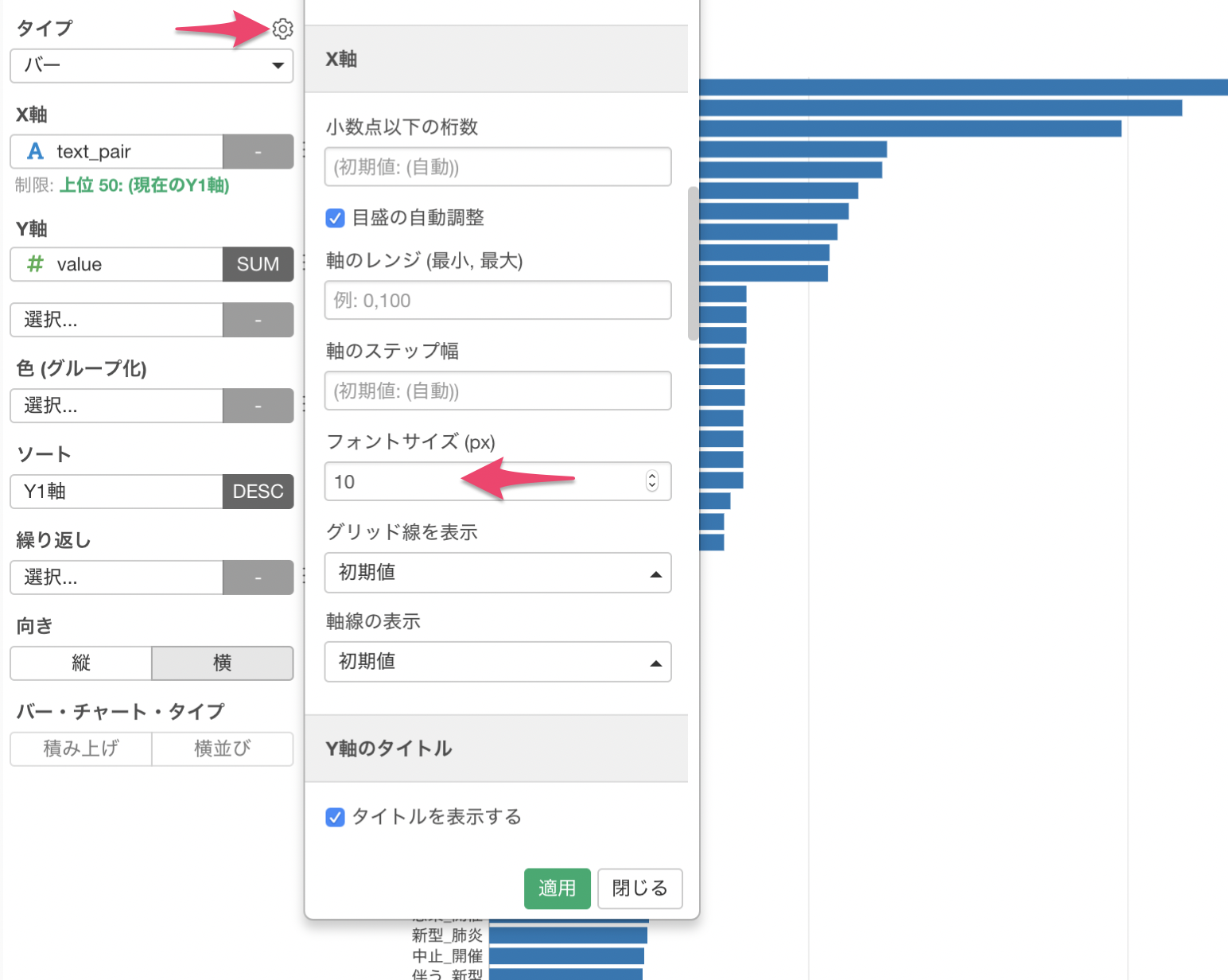
テキストのペアの出現回数を可視化することができました。
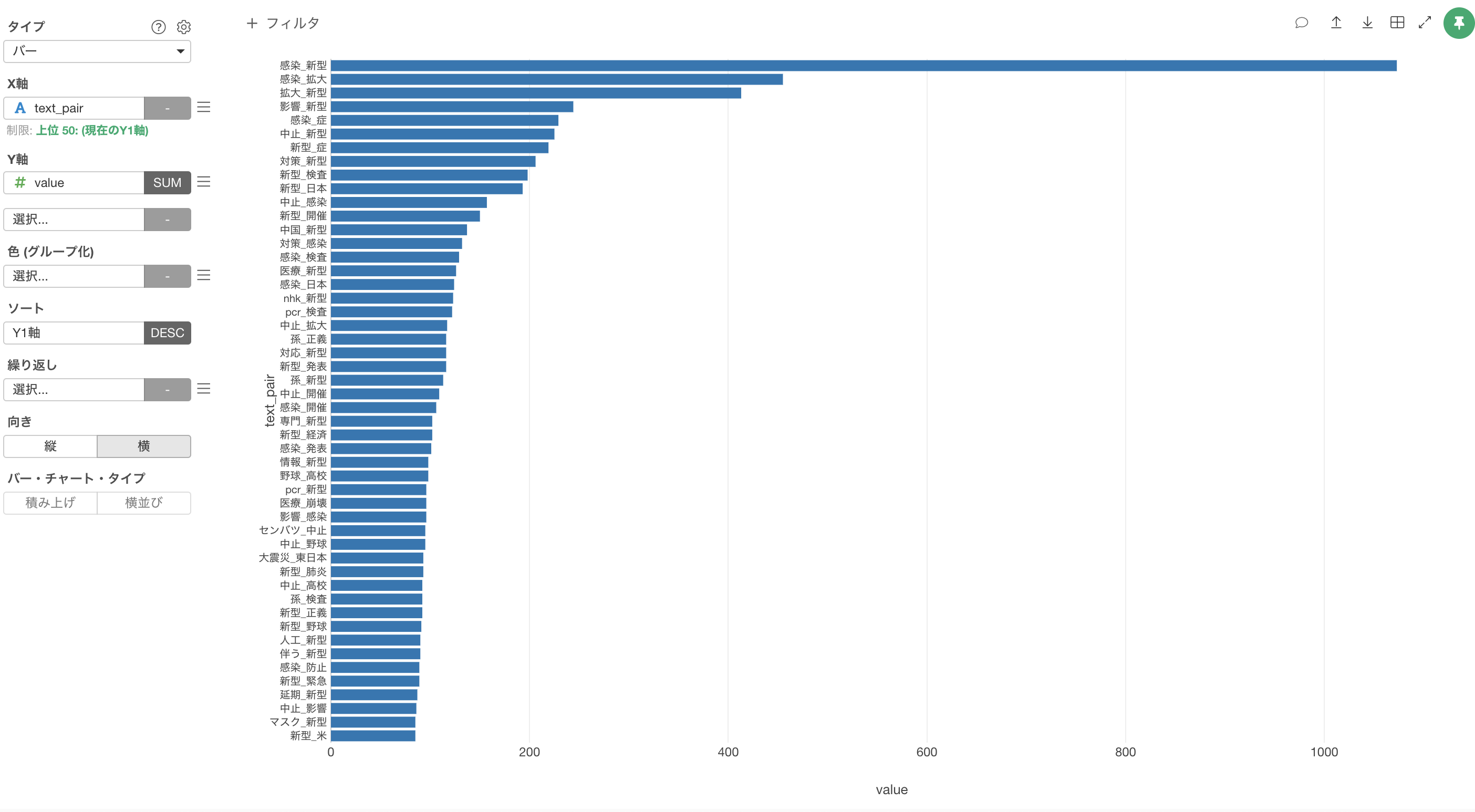
これをみると、感染といった単語のほかいくつか気になるツイートが見つかりました。
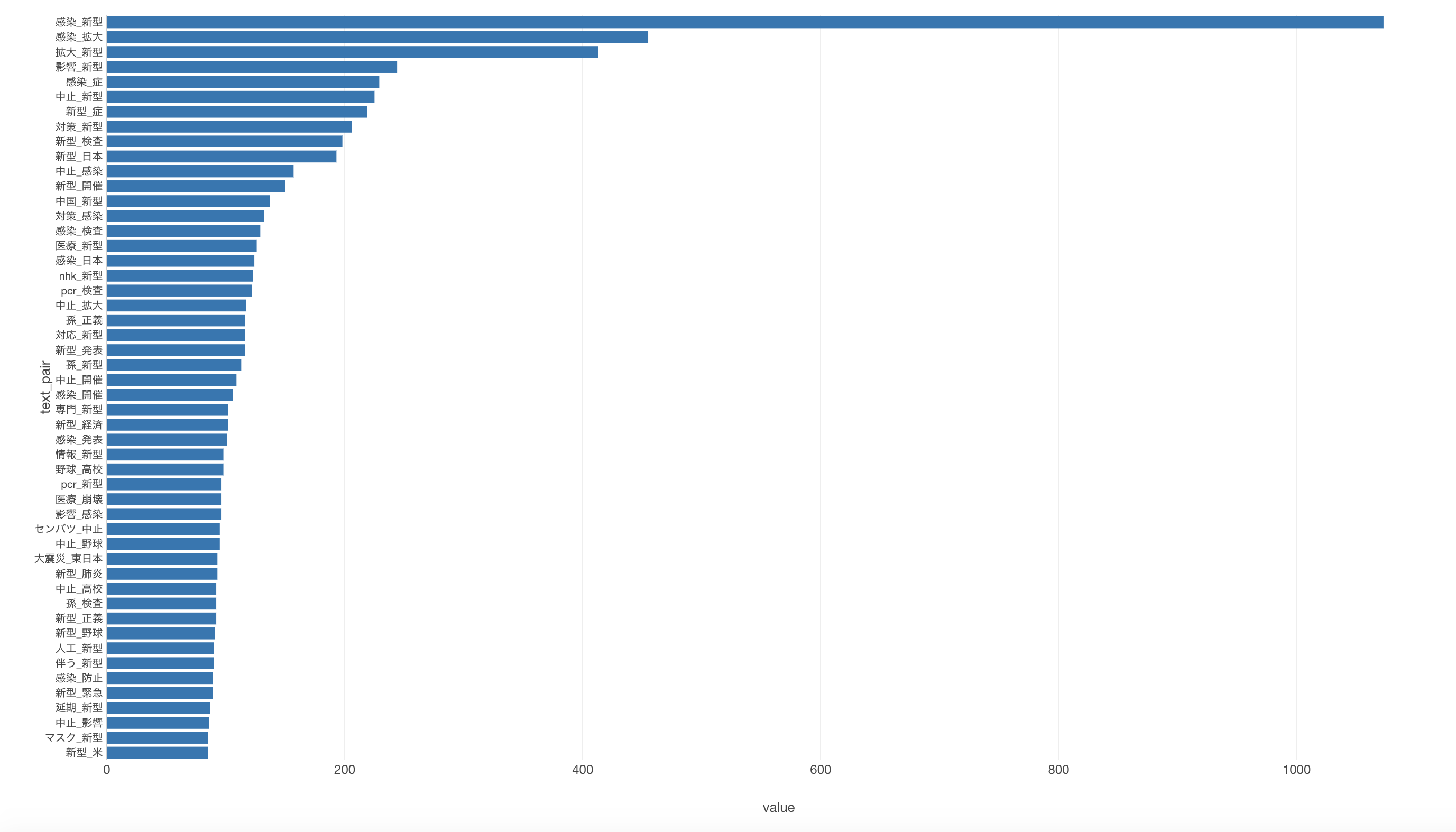
データの取得時点は3/12だったんですが、選抜野球の開催中止を表す単語のペアがいくつかあります。例えば、選抜_中止や野球_中止などがありました。

また、孫正義さんがTwitterでPCR検査を100万人に無償提供する予定とツイートされていましたが、孫_検査や孫_新型とあることからこのことに関してもかなりツイートされていたことがわかります。