AIプロンプトで実現する複数列の一括計算処理
Exploratoryの「AIプロンプト」機能は、データ分析ワークフローにおいて最も時間を要するデータラングリング(データの加工・整形)作業を劇的に効率化する機能です。従来のデータ加工では、列の一括計算処理のような処理を行うためには、複雑なUIの操作や専門的なコードの記述が必要でした。処理内容によっては各列に対して個別に加工していく必要があり、作業は非効率的になるだけでなく、ミスの原因にも繋がります。
AIプロンプト機能の革新的な点は、「全ての数値列を標準化して」のような自然な日本語の指示だけで、複数の列に対して一括で処理を実行できることです。自分がやりたいことを言葉で伝えるだけで、AIが適切なRのコマンドを生成し、処理を実行します。これにより、データ加工にかかる時間を大幅に短縮し、本来の目的であるデータからの特徴の発見や意思決定に、より多くの時間を割くことができるようになります。
1. どういった時に使えるのか
AIプロンプト機能による列の一括計算処理は、様々なデータ分析のシーンで役立ちます。
例えば、データの前処理段階での数値の標準化、外れ値の処理、テキストデータのクリーニングなど、データ分析の基礎となる作業を効率化できます。これらをAIプロンプトで処理できれば、分析の前段階で費やす時間を大幅に削減し、より価値の高い分析作業に集中できます。
AIプロンプト機能を使って複数列に対する処理を実行する際には、以下のようなデータで特に効果を発揮するかと思います。
- 複数の数値列を含む販売データや分析データセット
- 外れ値が含まれる可能性のある測定データや調査データ
- 全角・半角や不要な空白が混在する文字列データを含む顧客情報やアンケートデータ
2. ExploratoryでAIプロンプトを活用する
全ての数値型の列を標準化する
この例では「注文データ」を使用します。
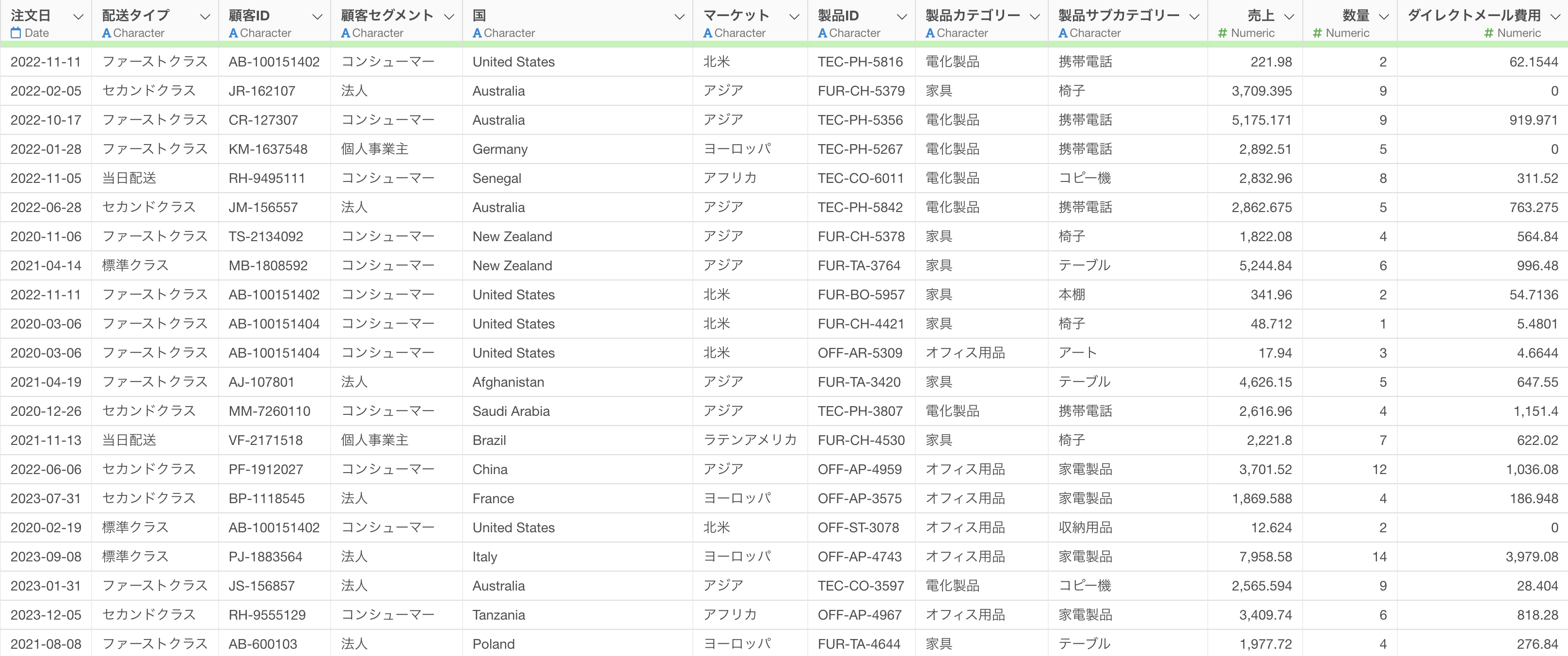 このデータは顧客の注文情報を含み、売上、数量、ダイレクトメール費用などの数値列を持っています。これらの異なる単位を比較しやすくするために、数値列を一気に標準化していきたいです。
このデータは顧客の注文情報を含み、売上、数量、ダイレクトメール費用などの数値列を持っています。これらの異なる単位を比較しやすくするために、数値列を一気に標準化していきたいです。
テーブルビューから「AIデータ加工」ボタンをクリックしてAIプロンプト機能を開きます。
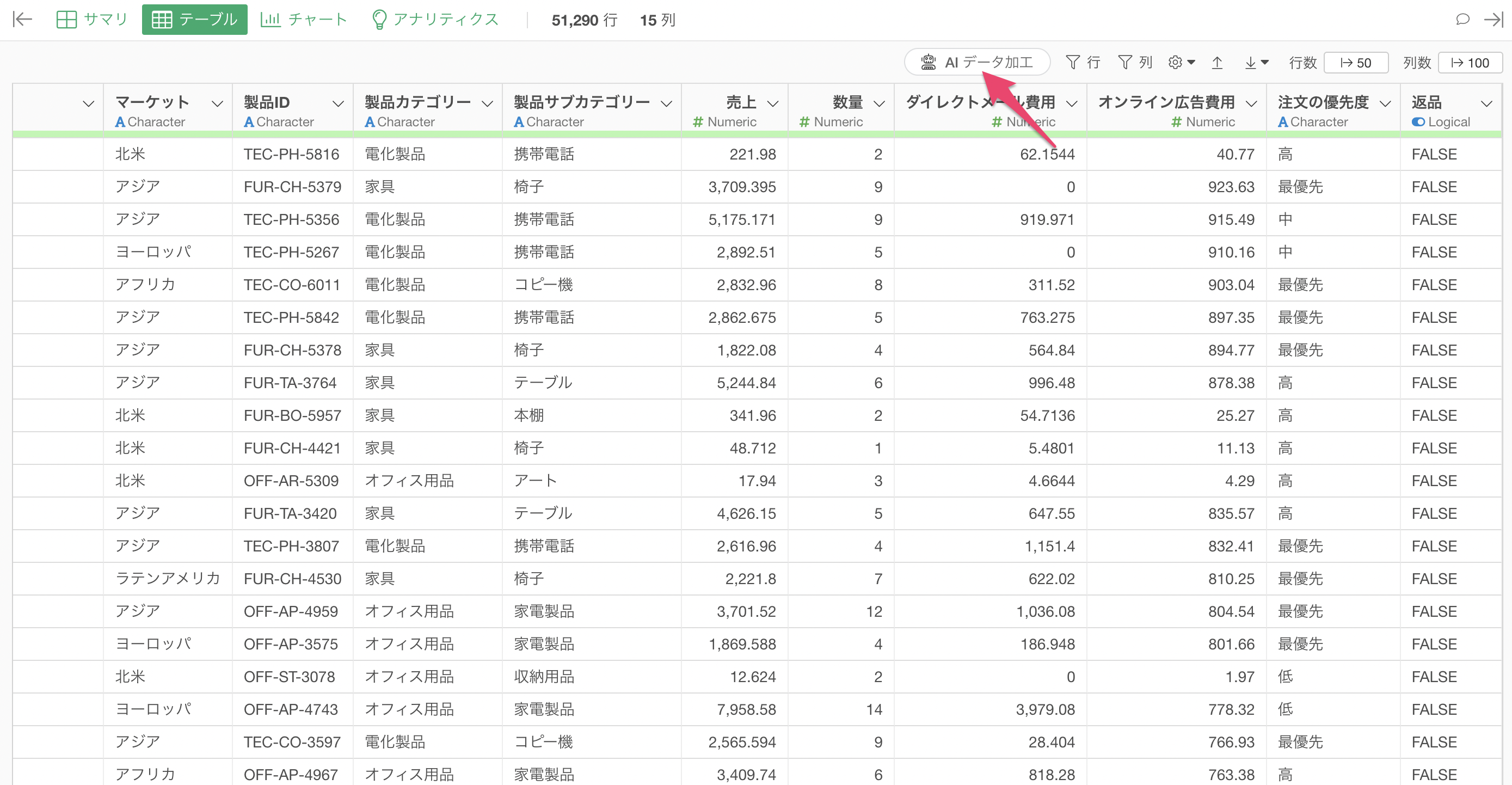
プロンプト入力欄に以下のプロンプトを入力します。
全ての数値列を標準化して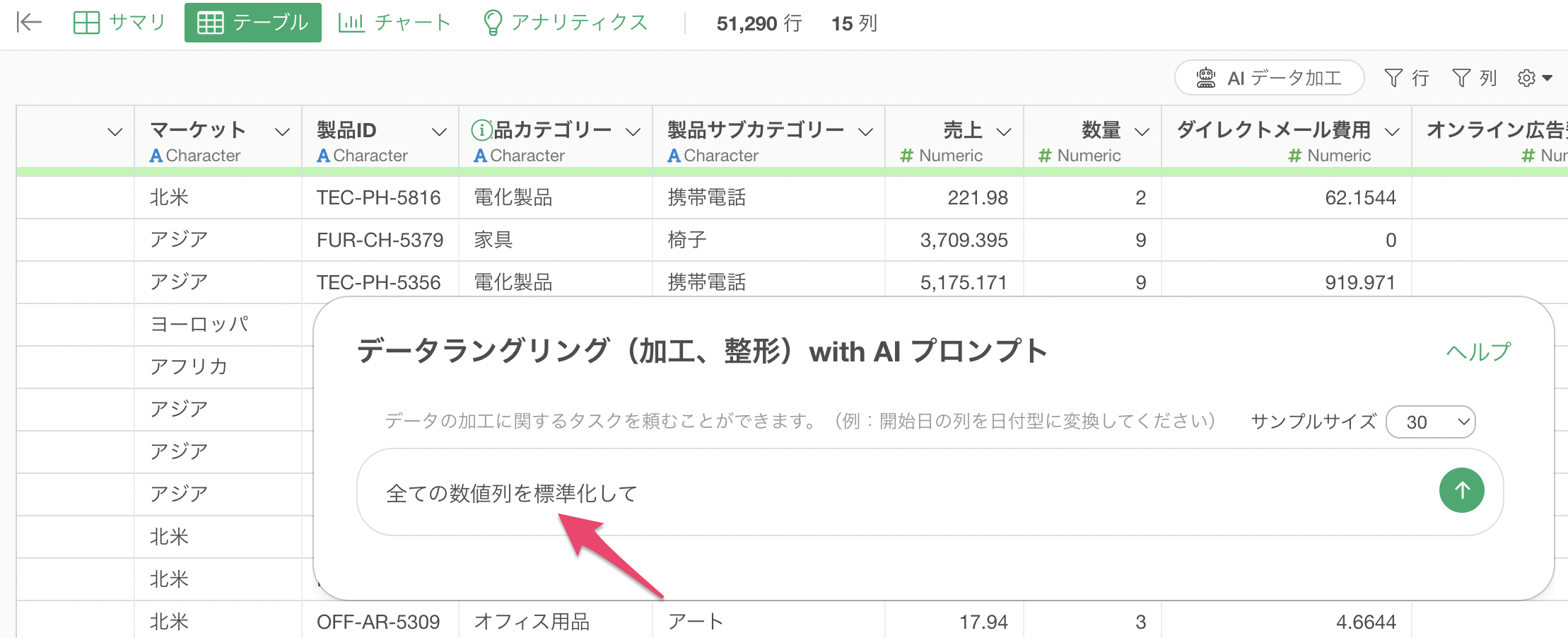
プロンプトを実行すると、AIが自動的に以下のRスクリプトを生成します。
mutate(
`売上_標準化` = normalize(`売上`),
`数量_標準化` = normalize(`数量`),
`ダイレクトメール費用_標準化` = normalize(`ダイレクトメール費用`),
`オンライン広告費用_標準化` = normalize(`オンライン広告費用`)
)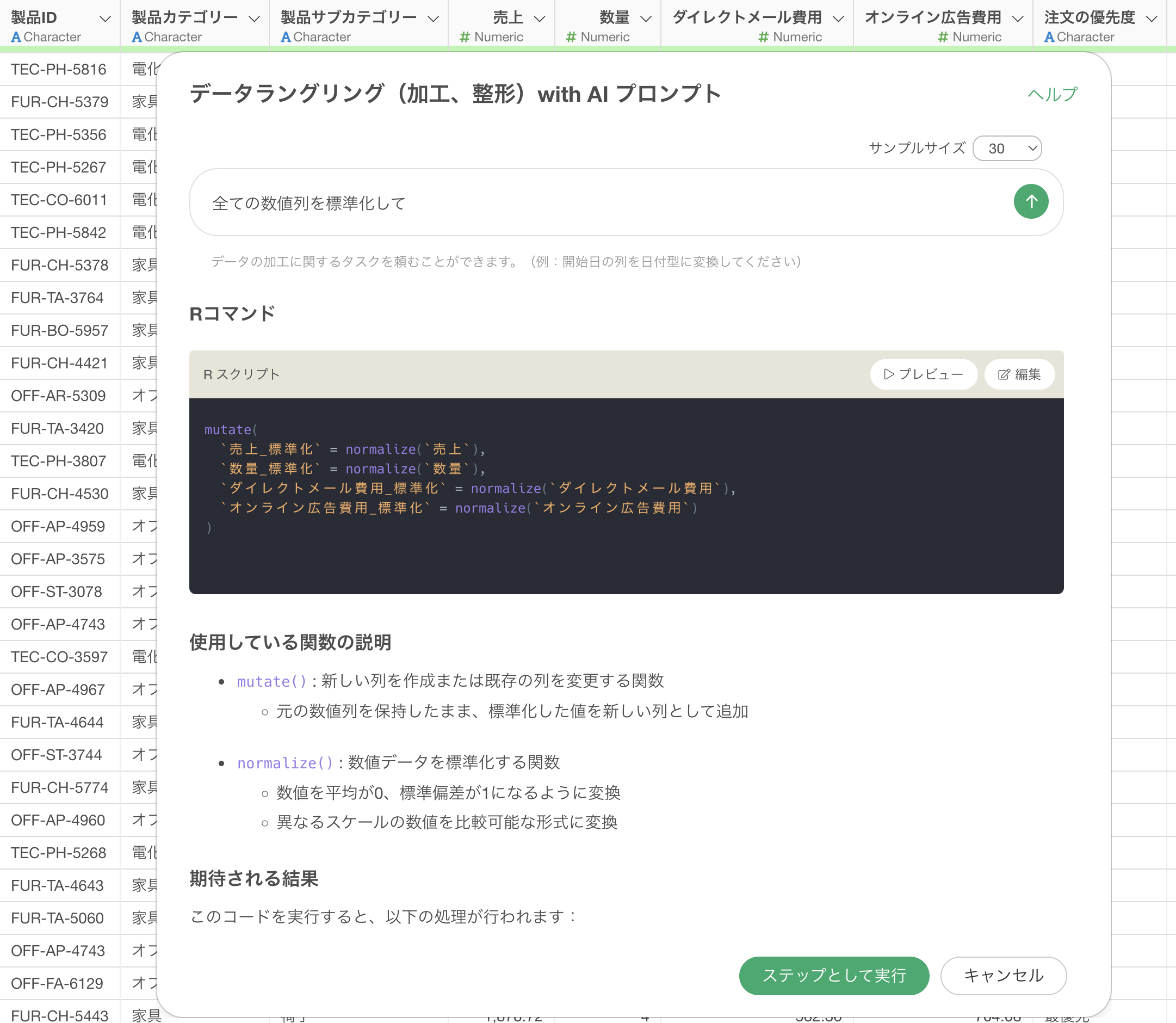
このコードは、各数値列に対してnormalize()関数を適用し、平均0、標準偏差1の標準化されたデータに変換しています。これにより、異なるスケールを持つ数値列を同じスケールで比較できるようになります。
「ステップとして実行」ボタンをクリックすることで、処理が実行され、結果が反映されます。
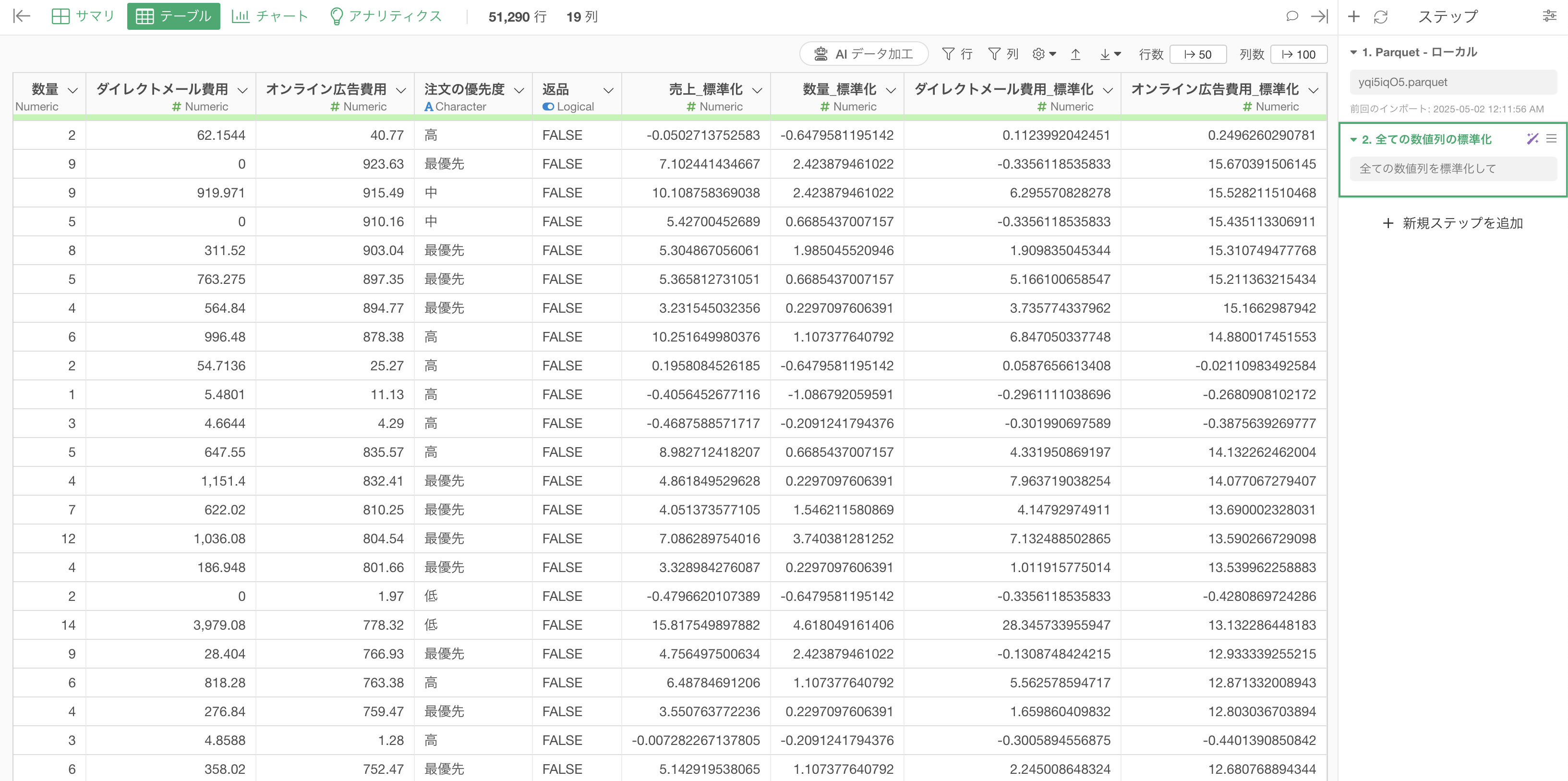
これにより、すべての数値列が標準化され、変数間の比較が容易になります。
全ての数値型の列の外れ値を除去する
この例では「顧客ごとの売上データ」を使用します。
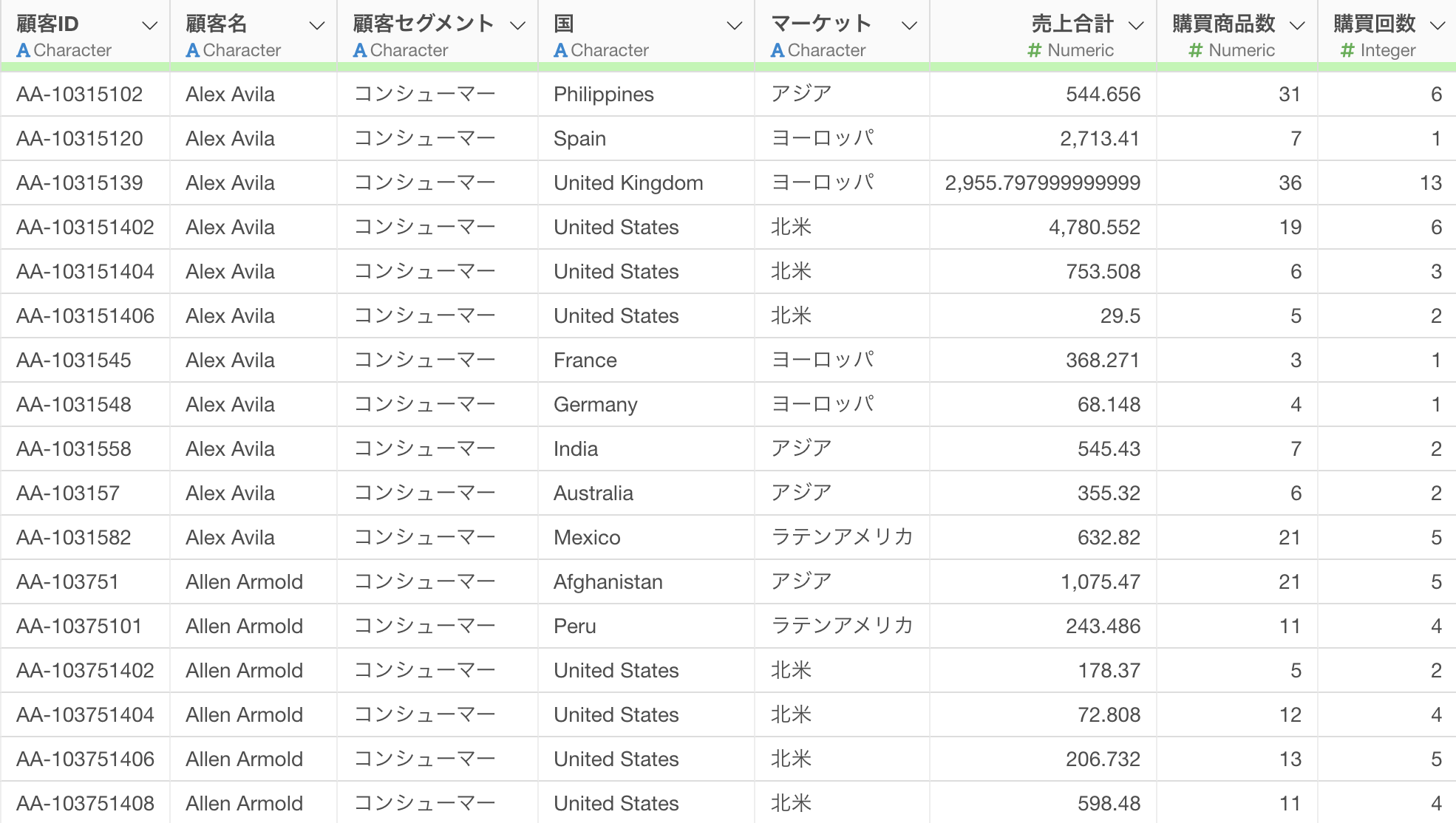
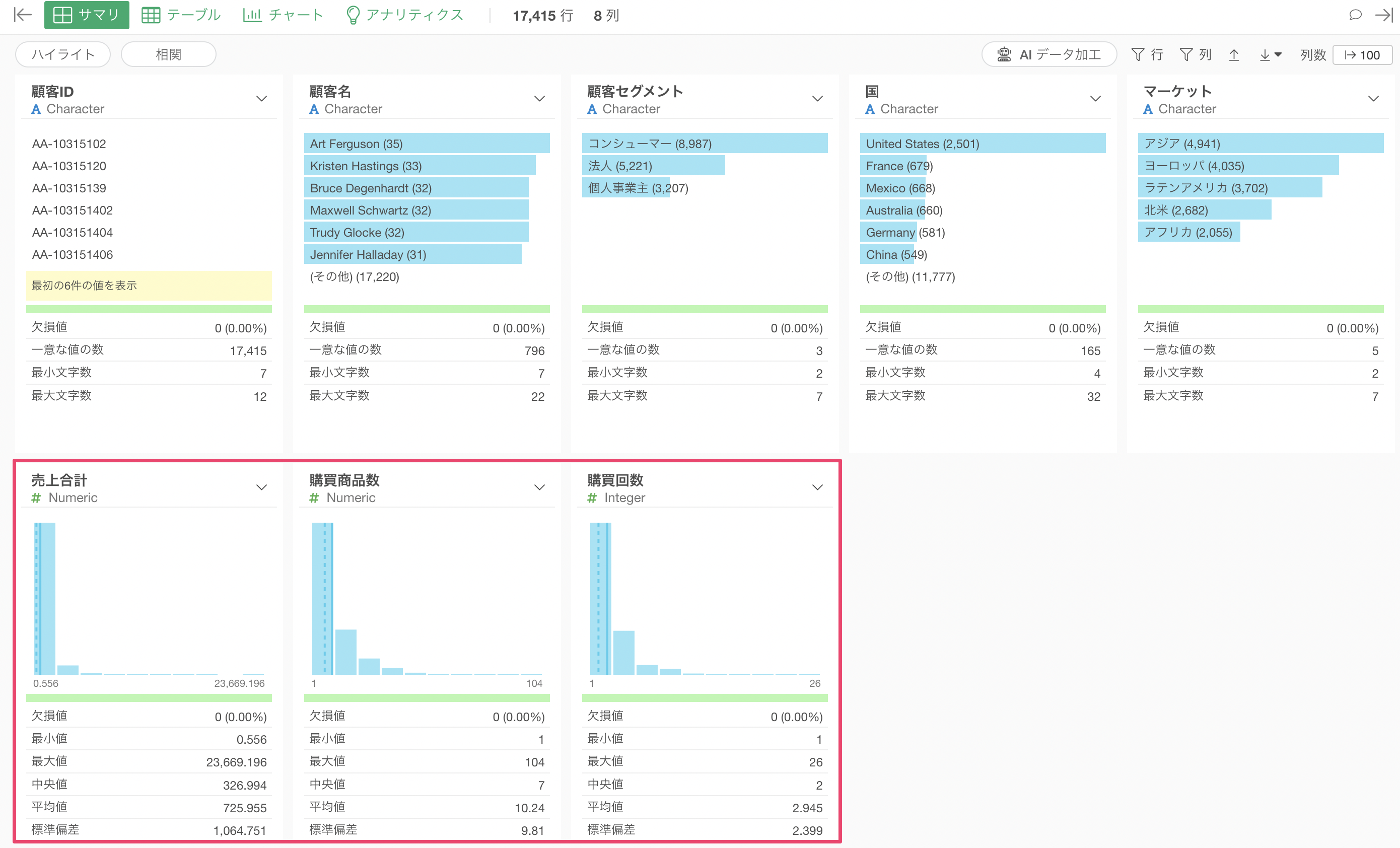
このデータでは、売上合計や購買商品数などで極端に値が大きい外れ値が存在しています。そのため、IQR(四分位範囲)法を用いて外れ値を検出し、外れ値を取り除きたいです。
 テーブルビューから「AIデータ加工」ボタンをクリックしてAIプロンプト機能を開きます。
テーブルビューから「AIデータ加工」ボタンをクリックしてAIプロンプト機能を開きます。
プロンプト入力欄に以下のプロンプトを入力します。
全ての数値列の外れ値をIQRを使って取り除いて 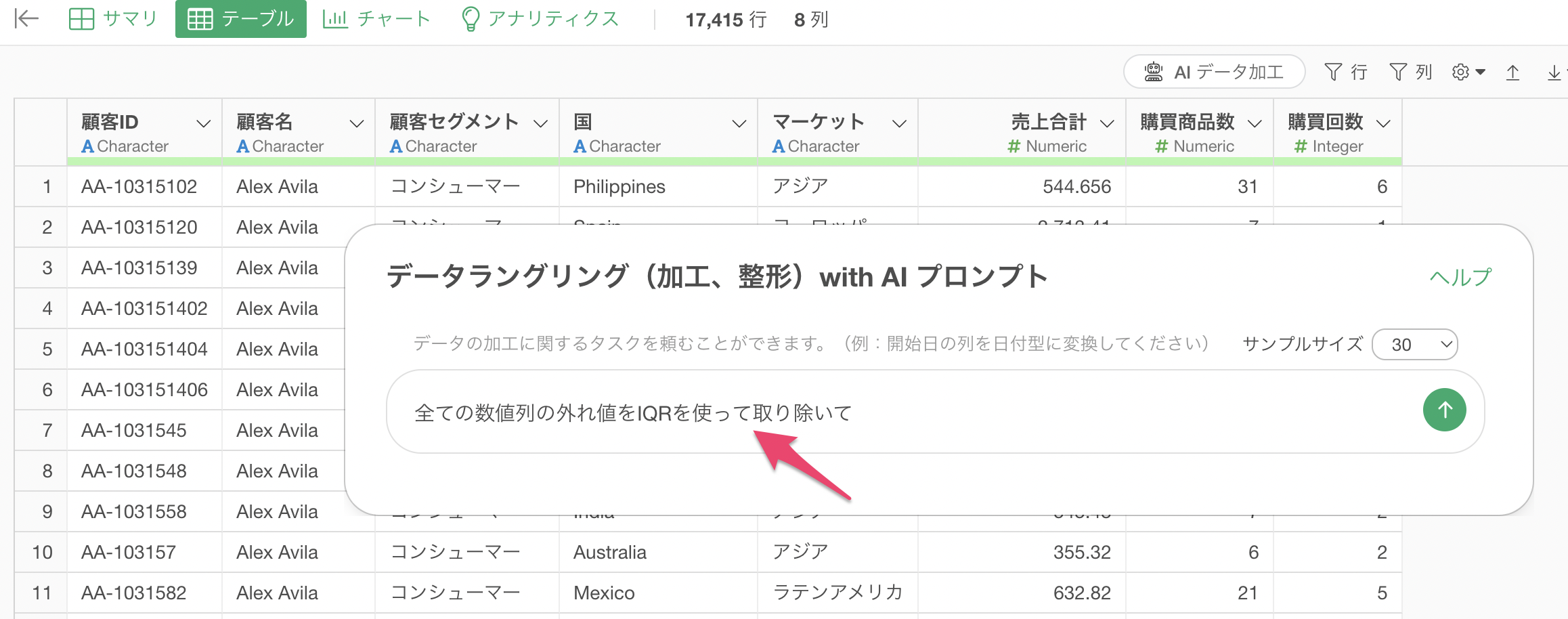
プロンプトを実行すると、AIが自動的に以下のRスクリプトを生成します。
mutate(
`売上合計_外れ値` = detect_outlier(`売上合計`, type = "iqr"),
`購買商品数_外れ値` = detect_outlier(`購買商品数`, type = "iqr"),
`購買回数_外れ値` = detect_outlier(`購買回数`, type = "iqr")
) %>%
filter(
`売上合計_外れ値` == "Normal",
`購買商品数_外れ値` == "Normal",
`購買回数_外れ値` == "Normal"
) %>%
select(-`売上合計_外れ値`, -`購買商品数_外れ値`, -`購買回数_外れ値`)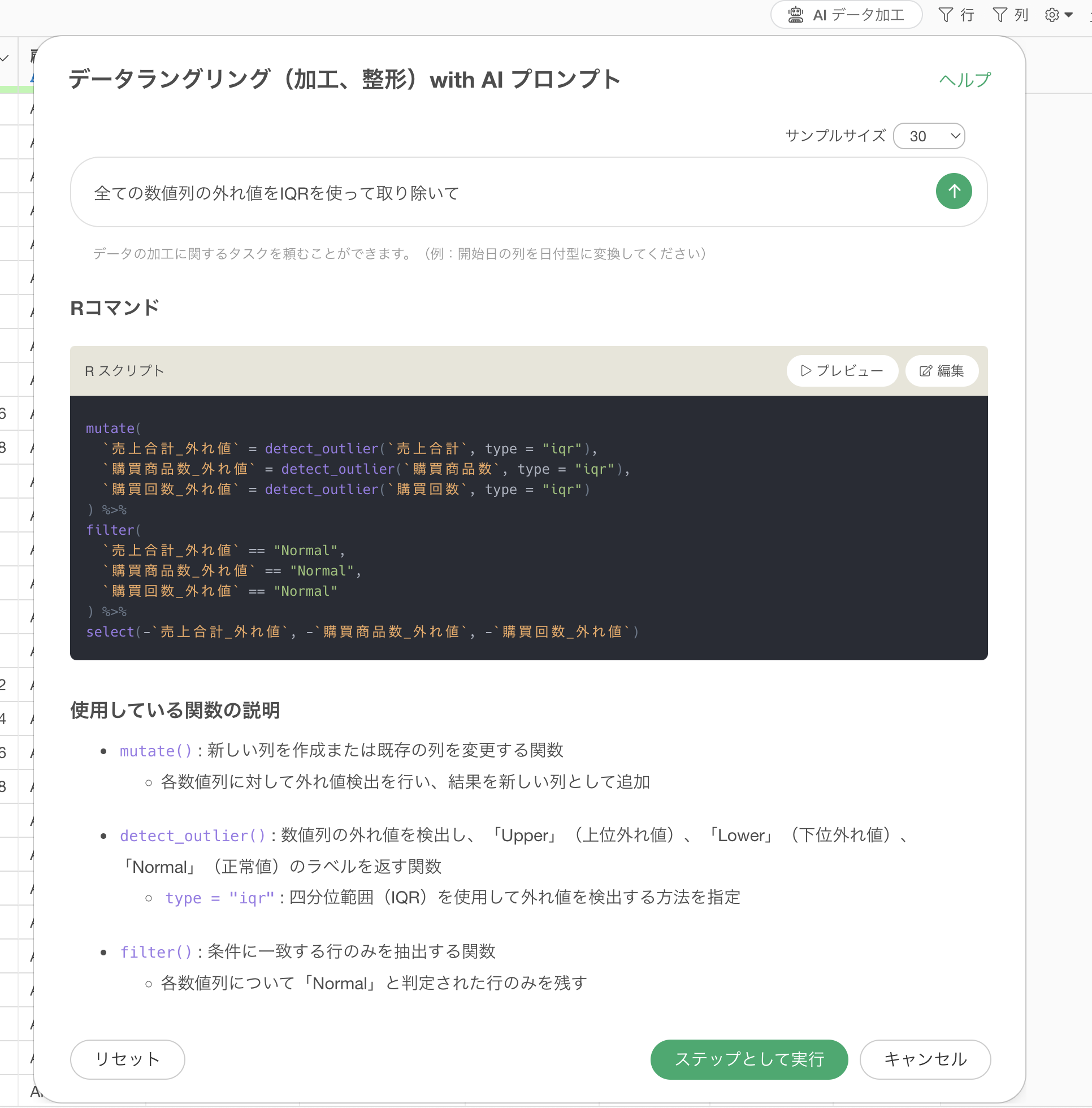
このコードは、まず全ての数値列を対象に、detect_outlier関数でIQR方式により外れ値を検出しています。外れ値にはLowerやUpperといったフラグが付き、外れ値でない場合はNormalといったフラグが付きます。
そのため、外れ値でないNormalの値のみを残すようにフィルタをしています。
「ステップとして実行」ボタンをクリックすることで、処理が実行され、結果が反映されます。
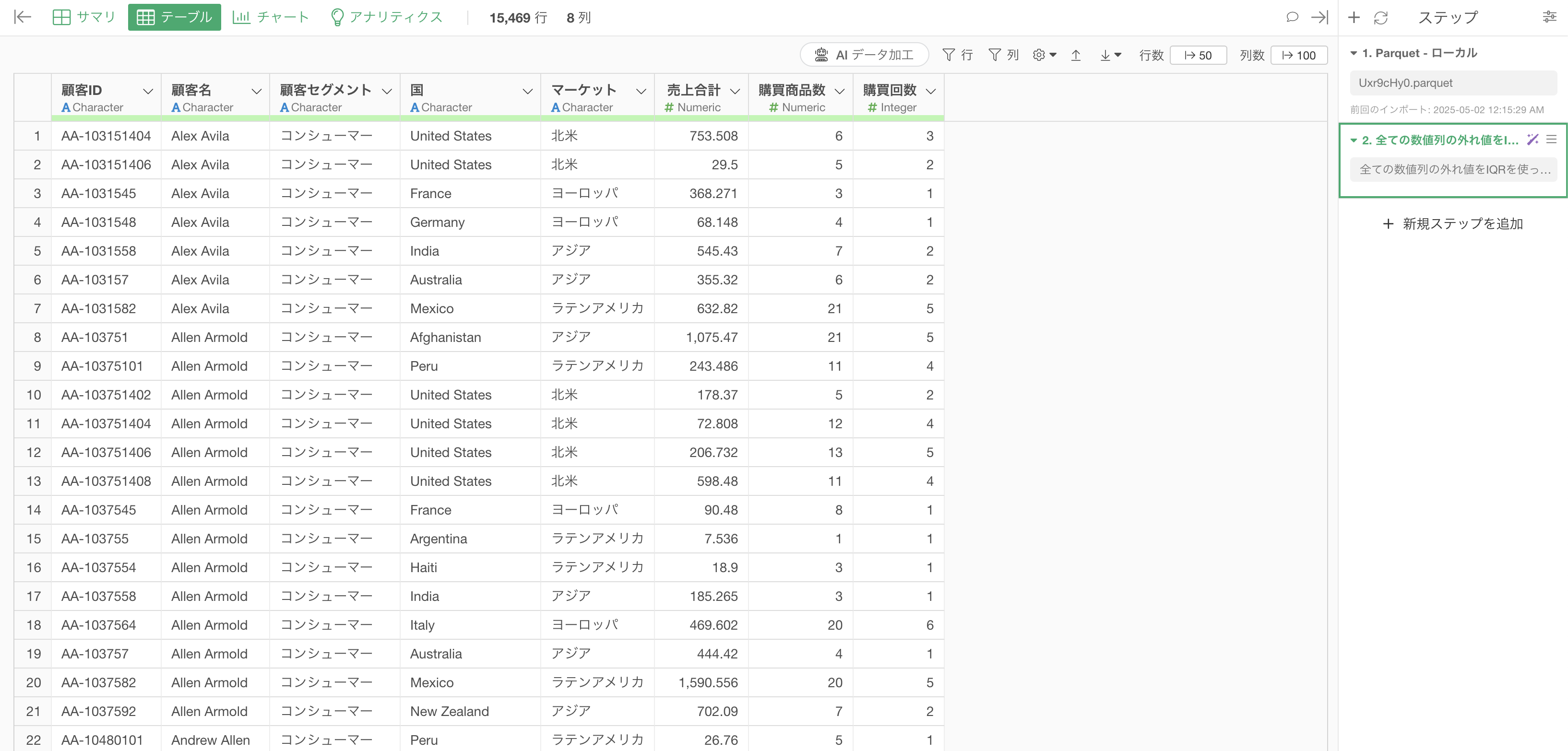
これにより、全ての数値列でIQR(四分位範囲)法を用いて外れ値を取り除くことができました。
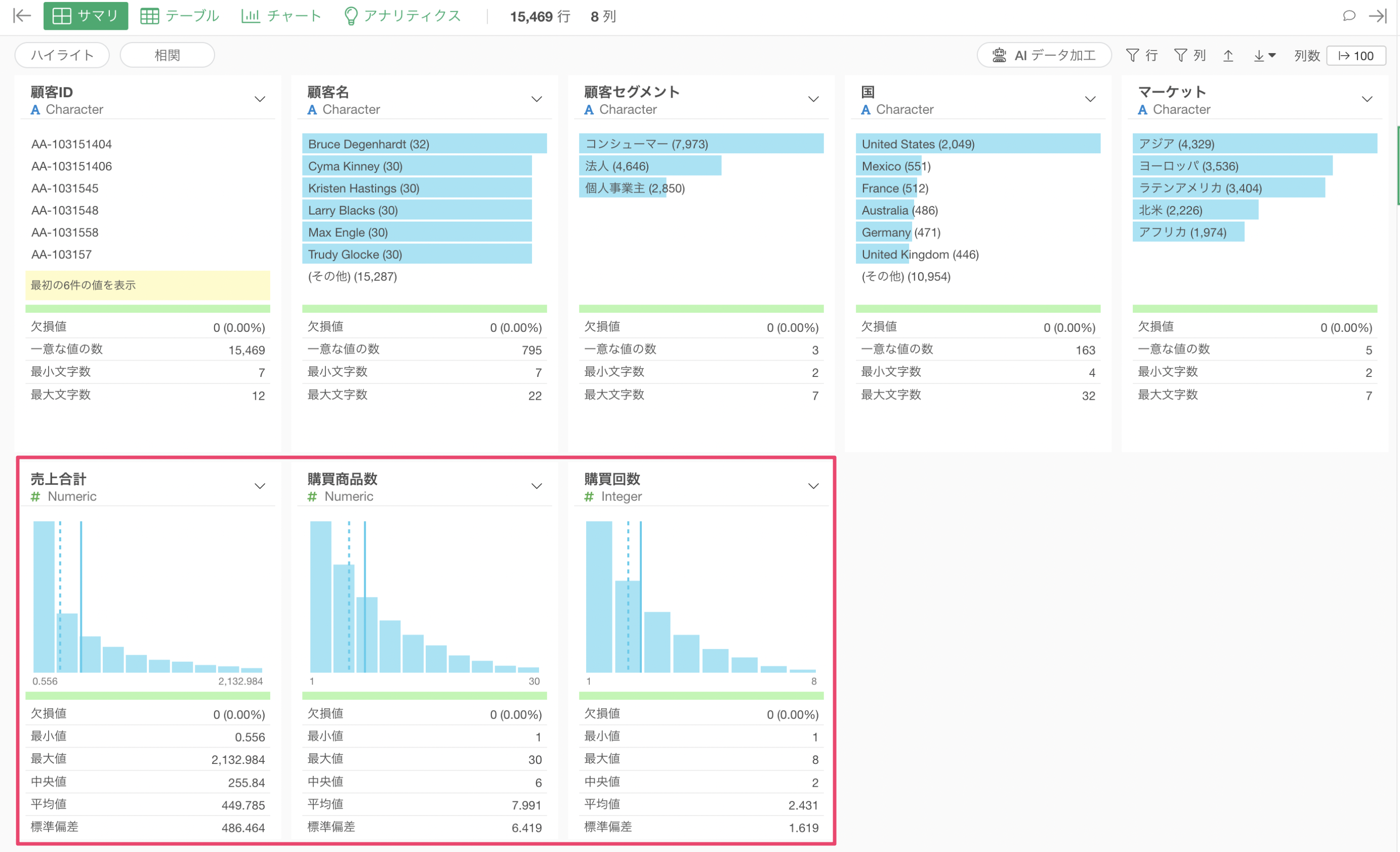
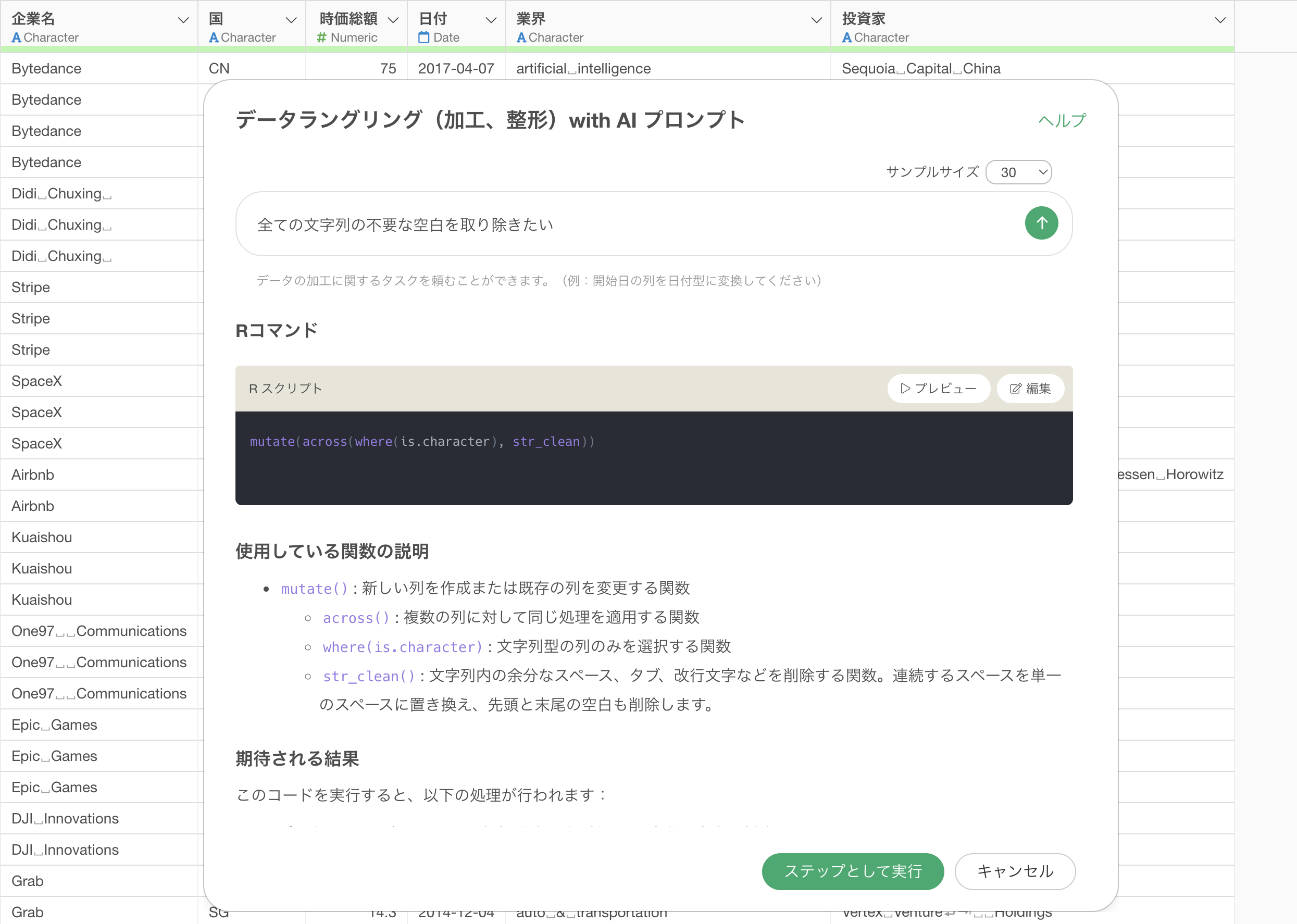
全ての文字列の不要な空白を除去する
この例では「ユニコーン企業」を使用します。
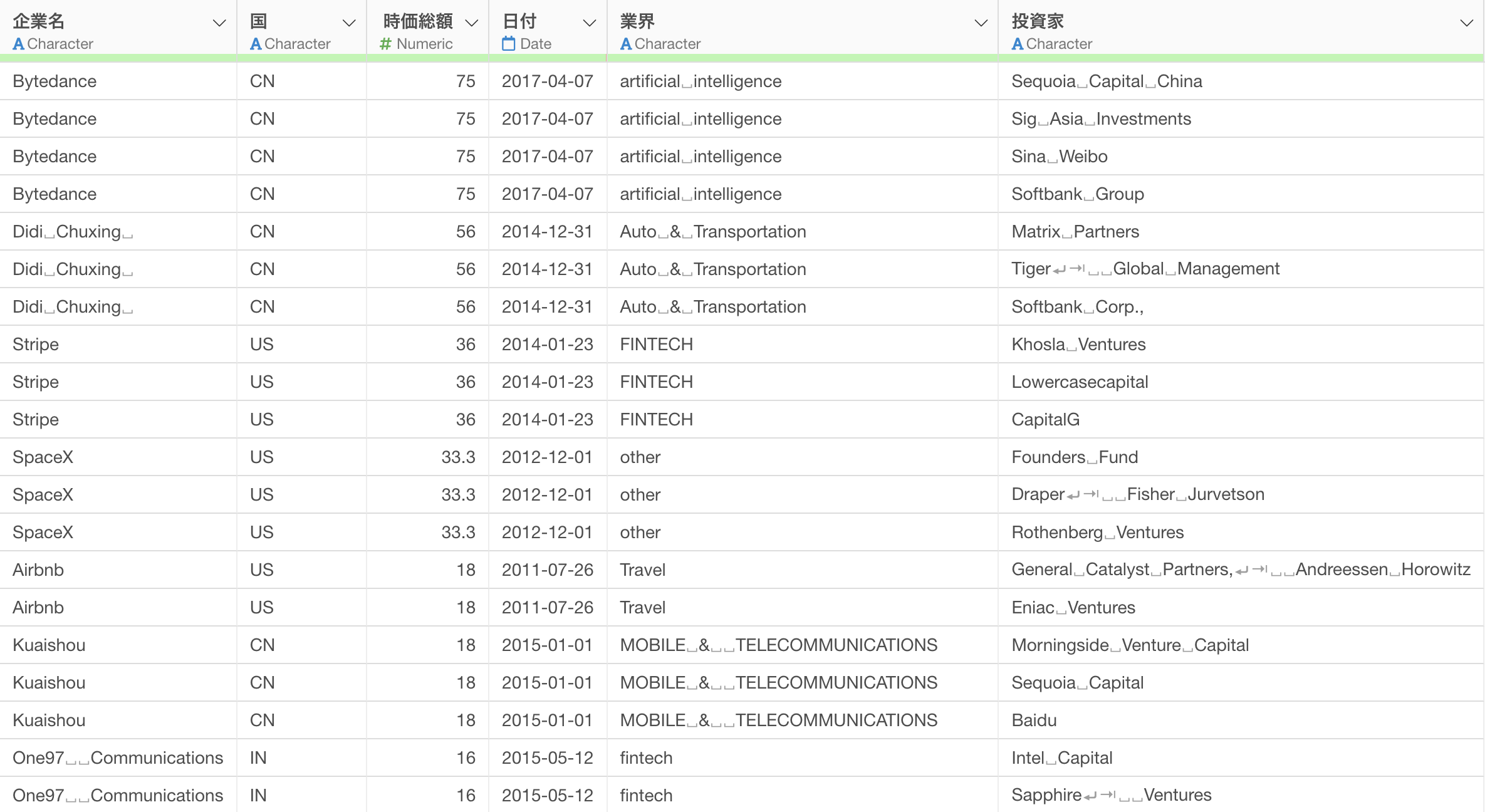 このデータはユニコーン企業(評価額10億ドル以上の非上場企業)に関するデータですが、企業名や投資家などの文字列に余分な空白やタブや改行文字が含まれています。
このデータはユニコーン企業(評価額10億ドル以上の非上場企業)に関するデータですが、企業名や投資家などの文字列に余分な空白やタブや改行文字が含まれています。
そのため、これらの不要な空白を取り除きたいです。
テーブルビューから「AIデータ加工」ボタンをクリックしてAIプロンプト機能を開きます。
プロンプト入力欄に以下のプロンプトを入力します。
全ての文字列の不要な空白を取り除きたい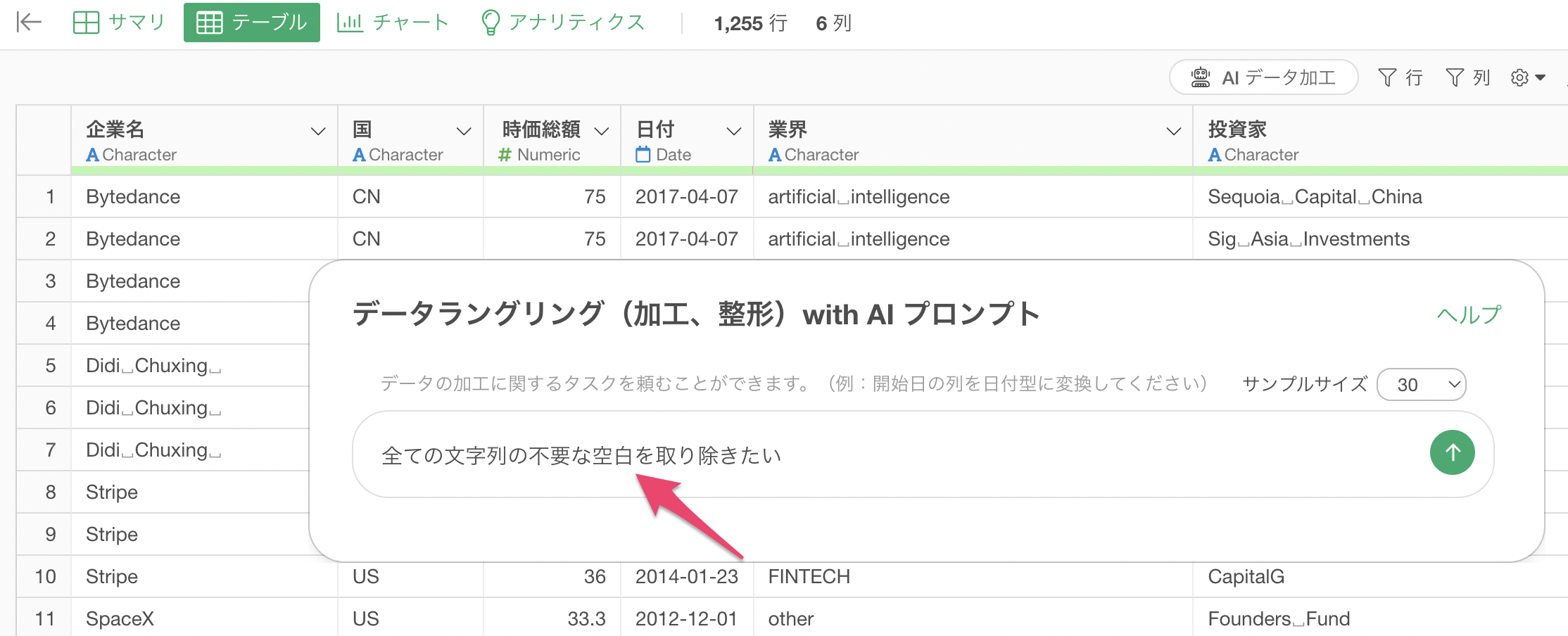
プロンプトを実行すると、AIが自動的に以下のRスクリプトを生成します。
mutate(across(where(is.character), ~ str_clean(.x)))
このコードは、全ての文字列列を対象に、str_clean関数を適用しています。この関数は、文字列の先頭と末尾の空白を削除し、連続する空白を単一の空白に置き換えることができます。さらには、タブ文字や改行文字があった場合も取り除くことが可能です。
「ステップとして実行」ボタンをクリックすることで、処理が実行され、結果が反映されます。
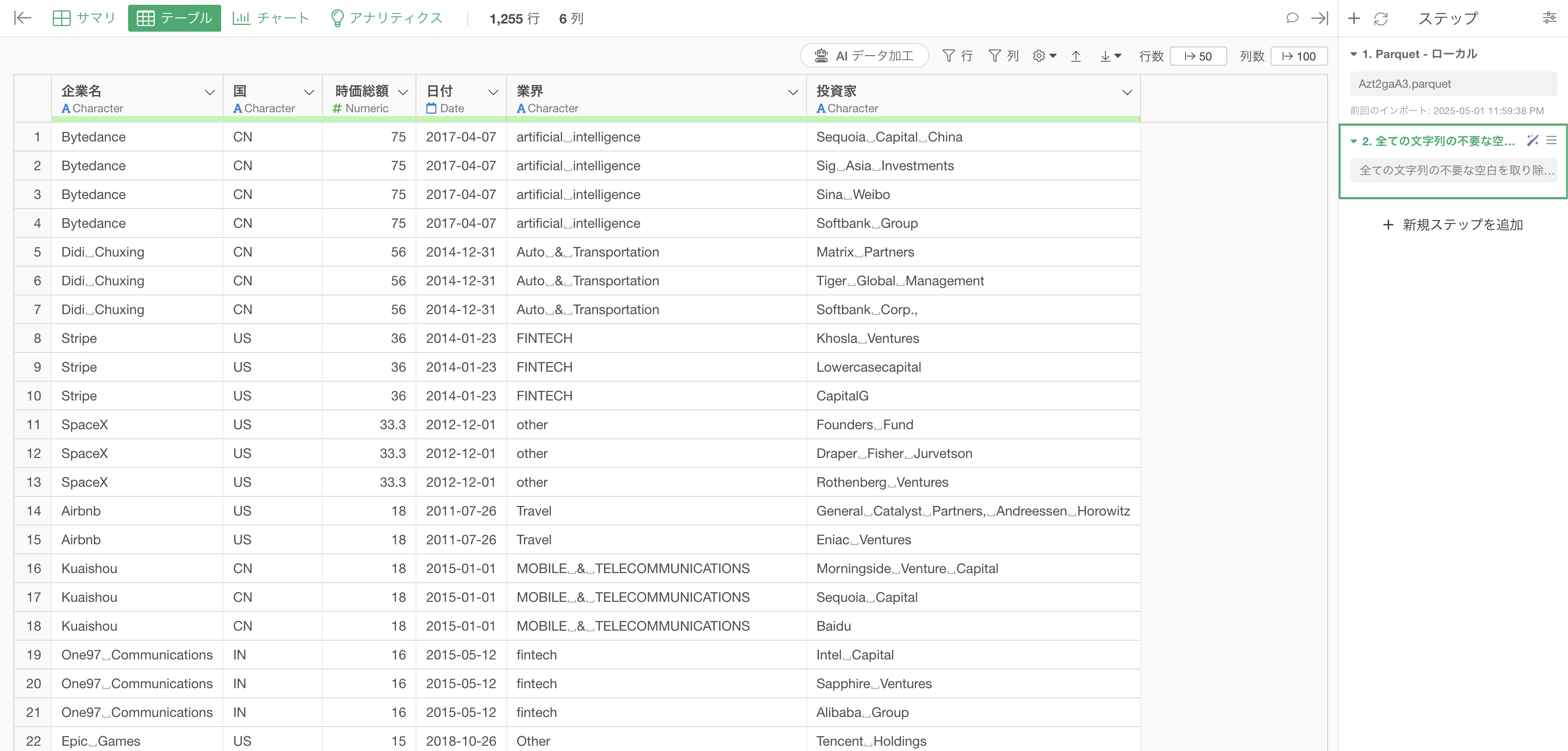
これにより、文字列から不要な空白を取り除くことができました。
3. まとめ
Exploratoryの「AIプロンプト」機能を活用した列の一括計算処理は、データ加工の作業の効率を大幅に向上させることができます。自然言語による指示だけで複雑なデータ処理を実行できるため、プログラミングの専門知識がなくても、高度なデータ加工が可能になります。
特に「全ての数値列を標準化して」や「全ての文字列の不要な空白を取り除きたい」のようなプロンプトを使えば、わずか数秒で複数列に対する一括処理を実現できます。これにより、データ分析の本質的な部分(洞察の発見や意思決定)により多くの時間を割くことができるようになります。
まだExploratoryを使用したことがない方は、30日間無料トライアルをぜひお試しください!