Cox回帰モデルによる予測
Cox回帰の予測モデルを使って、データ中の観察対象(ユーザー、患者など)それぞれに、一定時間経過後までにイベント(ユーザーの離脱、患者の死亡など)が起きる確率を出す方法を紹介します。
Cox回帰モデルを作成する
まず最初に、SNSのようなウェブサービスにおいて、ユーザーが最初の一週間で使った機能をもとに、その後のユーザーの生存確率が時間とともにどのように減少していくのかを予測するCox回帰モデルを作成します。
Cox回帰のモデルの作成自体は、アナリティクス・ビューを使えば簡単にできますが、今回はこのモデルを使って後で予測したいので、一つのデータラングリングのステップとしてCox回帰のモデルを作成します。
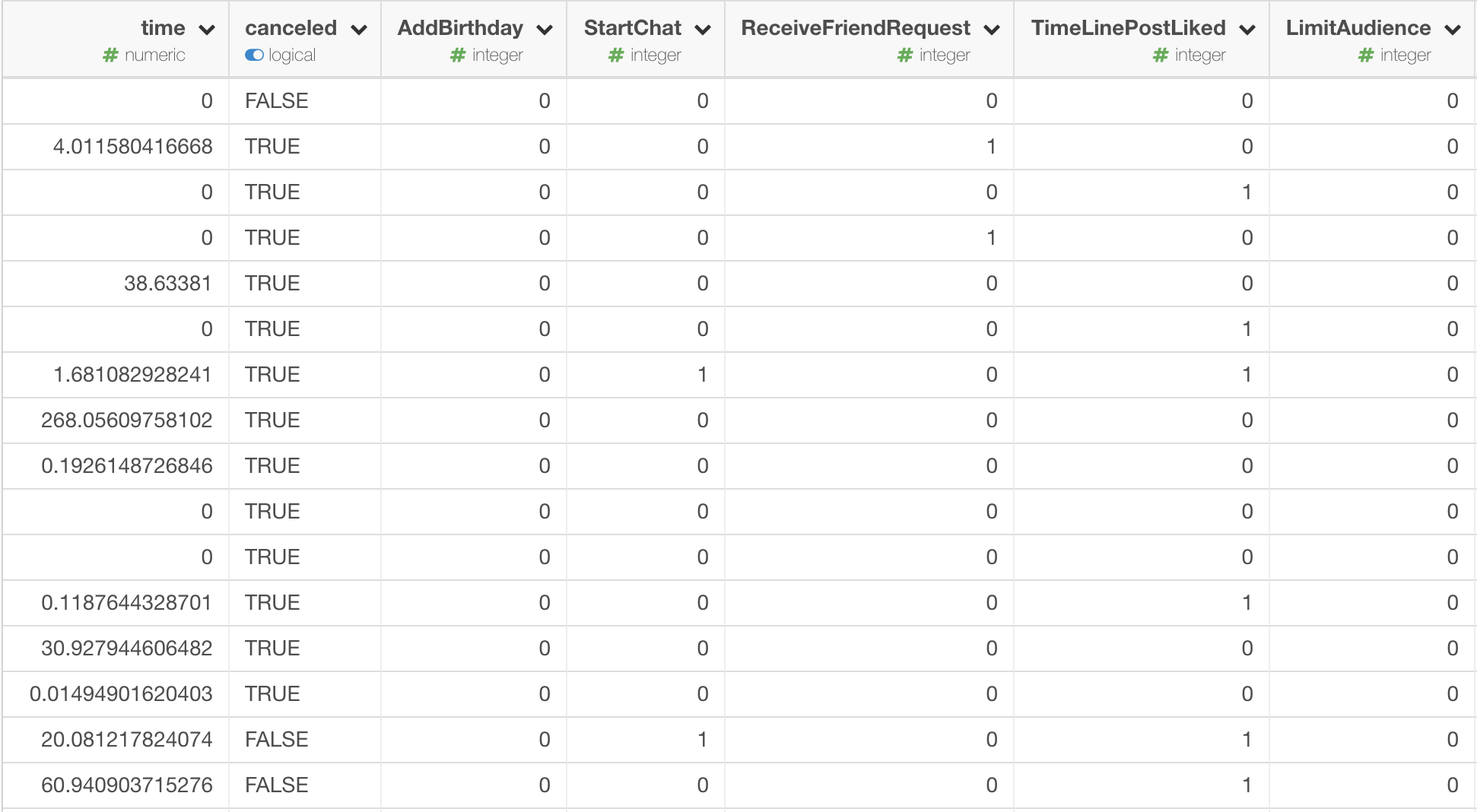
データは、以下の様に、1行が1ユーザーになっています。 ユーザーがサインアップしてから、キャンセル、またはそのまま現在にいたるまでの時間(time列)、キャンセルしたかどうか(cancel列)、ユーザーが各機能を最初の一週間で使ったかどうか(その他の列)といった情報が各列に入っています。
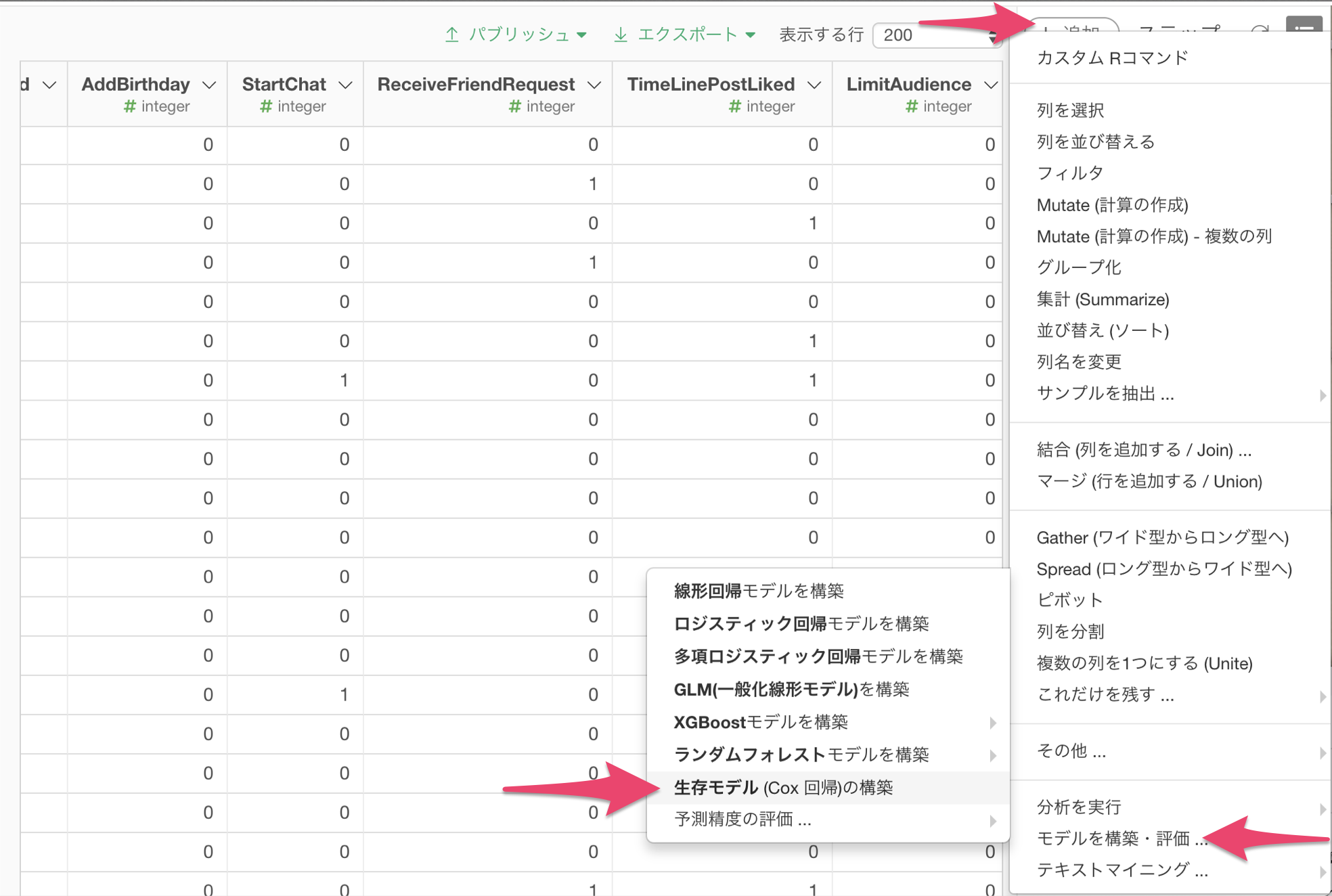
追加ボタンから以下の様にメニューをたどって、生存モデル(Cox回帰)の構築を選択します。
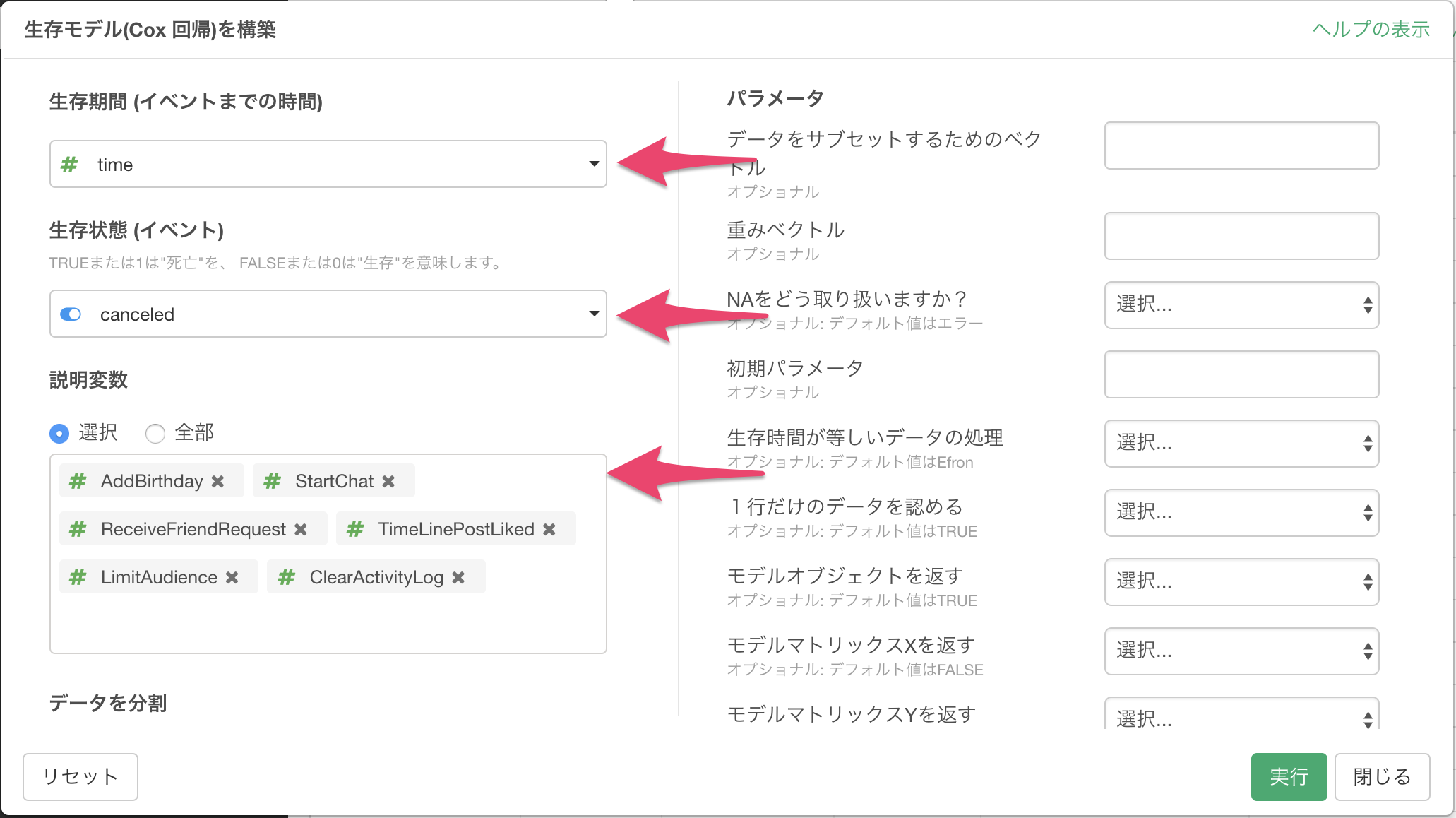
ダイアログ中で、以下の様に、生存期間、生存状態、説明変数の列を指定します。
実行ボタンをクリックすると、モデルが作成され、以下の様にモデルのサマリ画面が表示されます。
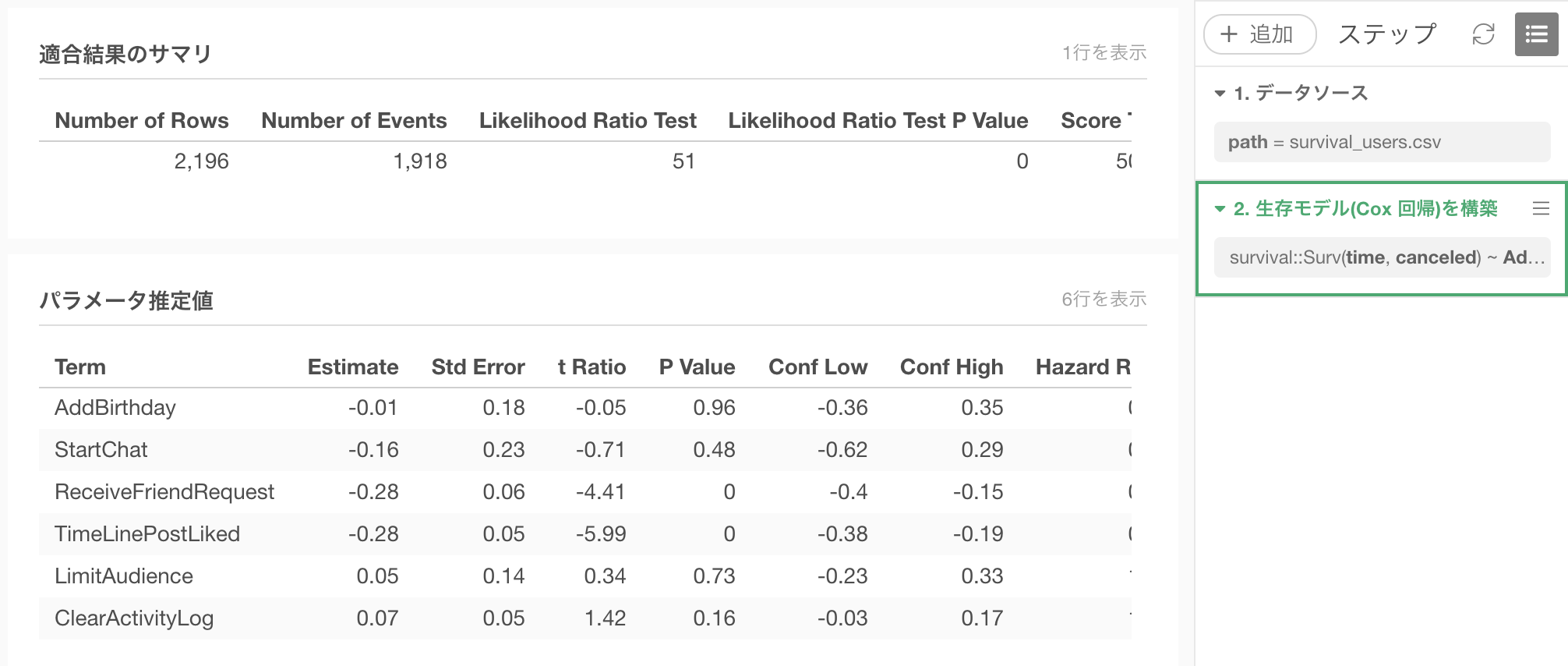
これで、Cox回帰の予測モデルが作られました。
作成したCox回帰モデルを元に予測をおこなう
今回は、予測モデルの作成に使ったデータの中にあるそれぞれのユーザーがある一定期間の間にキャンセルする率を予測してみたいと思います。
Exploratoryでは、データを予測モデルを作るためのトレーニングデータとモデルの予測精度を検証するためのテストデータに自動的に分離することができ、どちらのデータに対しても予測をすることができます。
また、実際の場面では、ここで作られたモデルを使って新しいデータセット、この場合ですと新しいユーザーに対して予測を行うことになると思います。
ここでは、単純に全てのデータをトレーニングに使い、そのデータの中にあるユーザーが15週間の間にキャンセルする率を、さきほど作成した、最初の一週間に使った機能を元にしたモデルで予測します。
プラス(+)メニューから、以下の様に、トレーニングデータで予測を選択して、ダイアログを開きます。
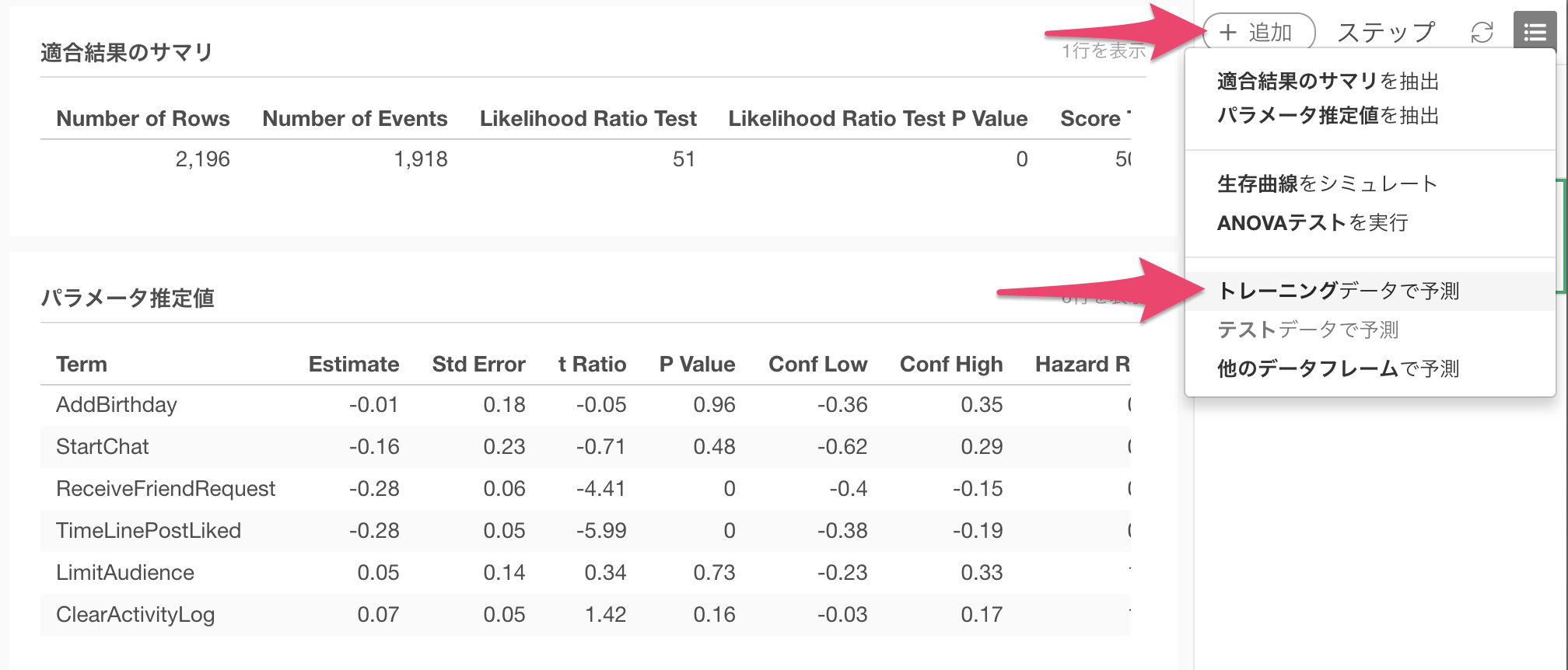
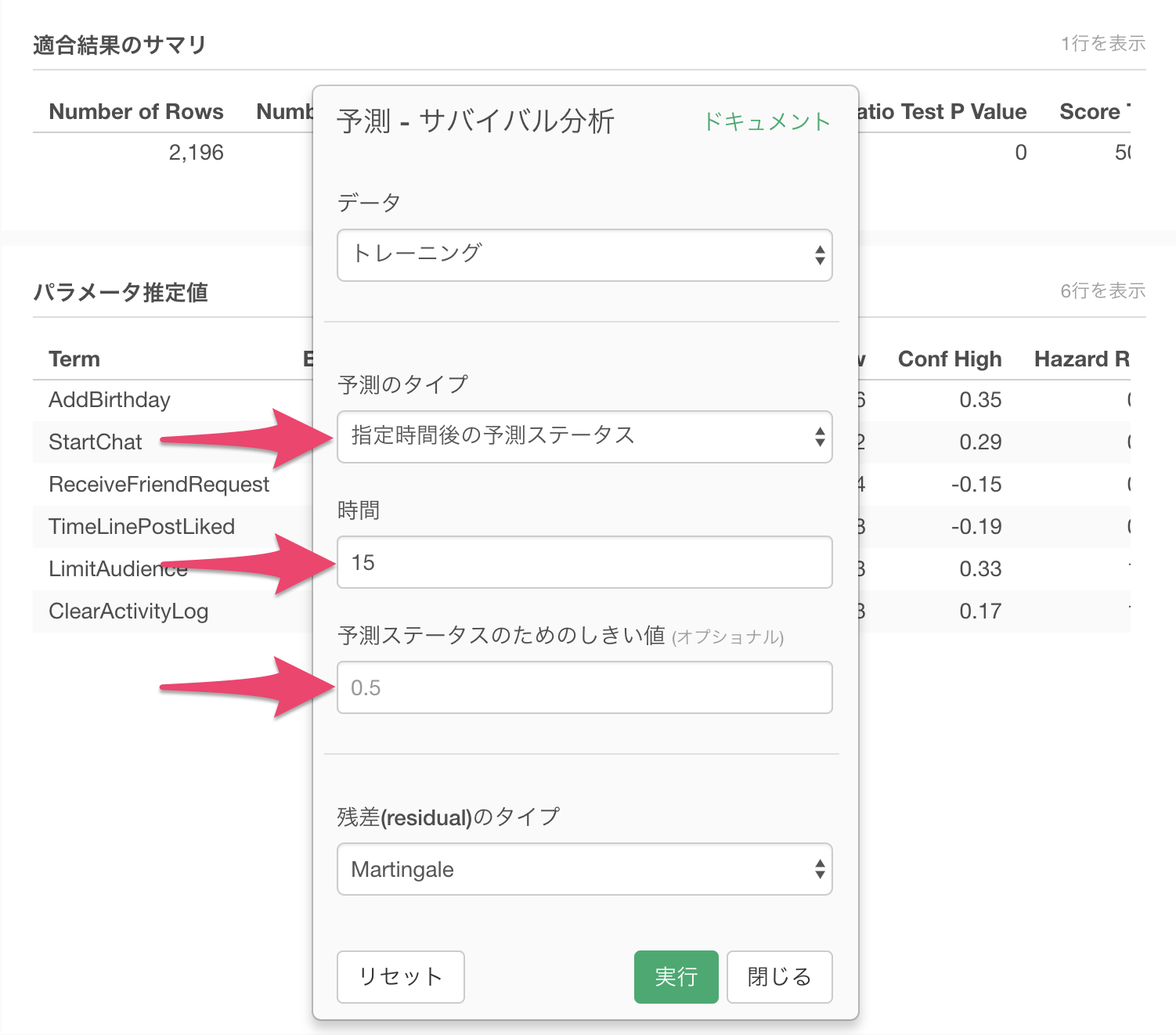
ダイアログ中で、予測のタイプに、指定時間後の予測ステータスを選択し、時間としきい値を指定します。
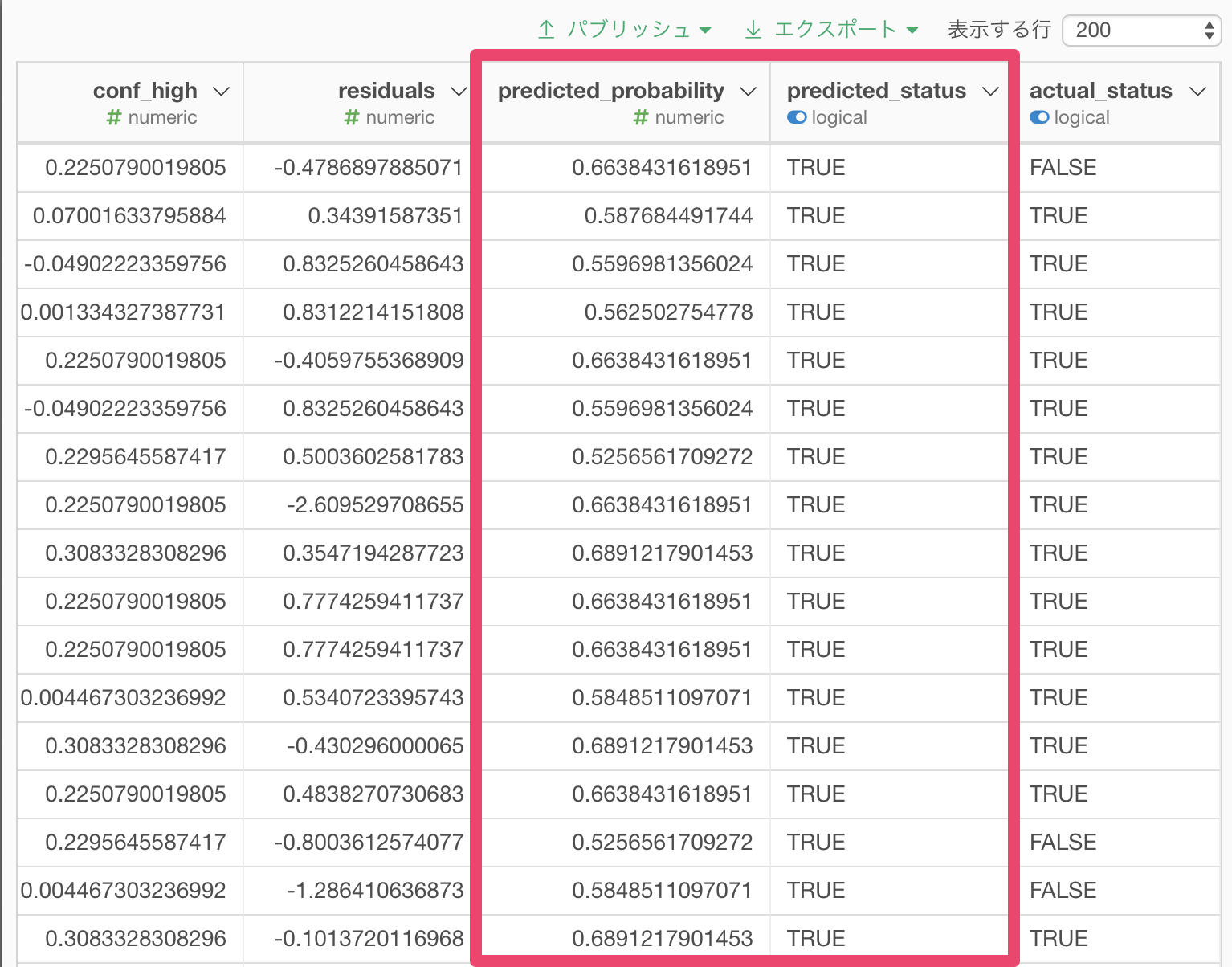
結果のデータフレームは、一行が一ユーザーの形式になっています。 各ユーザーに関して、モデルによって予測される、指定した時間後までにイベントが起きている確率がpredicted_probability列として入ります。
predicted_status列は、この確率を指定したしきい値と比較して作成された予測値です。TRUEはイベントがその時間までに起きる、FALSEは起きない、という予測を表します。
このように、予測結果がデータとしてできてしまえば、このデータを様々なフォーマットでエクスポートすることもできますし、また様々なタイプのチャートを使って可視化することもできます。もちろん、ノートやダッシュボードにその結果を表示して、チームのメンバーと共有するなんてこともあるのではないでしょうか。
今回は、アナリティクス・ビューでなく、データラングリングのステップとしてCox回帰の予測モデルを作成し、そのモデルを使ってそれぞれのユーザーが一定期間の間にキャンセルする率を予測してみました。