Data Wrangling Part 3 - Text Data Processing
This note is the third installment of the “Data Wrangling” trial tour designed to help you efficiently experience Exploratory’s data processing and formatting functions through hands-on practice, focusing on “Text Data Processing.”
When dealing with text data, common issues include inconsistent notation, unwanted characters or symbols, or the need to replace or extract certain strings.
In Exploratory, you can flexibly process text data using the text data processing UI.
In this part, we’ll experience convenient functions for cleaning up text data, replacing strings, and extracting information from strings.
The estimated time required is about 20 minutes.
Let’s get started!
Text Data Processing Grammar
Data primarily consisting of characters is called “text data,” represented as Character type (string type) in Exploratory.
While humans can recognize them as the same, systems treat strings with different notations as separate values, which can lead to incorrect results when aggregating or visualizing in charts.
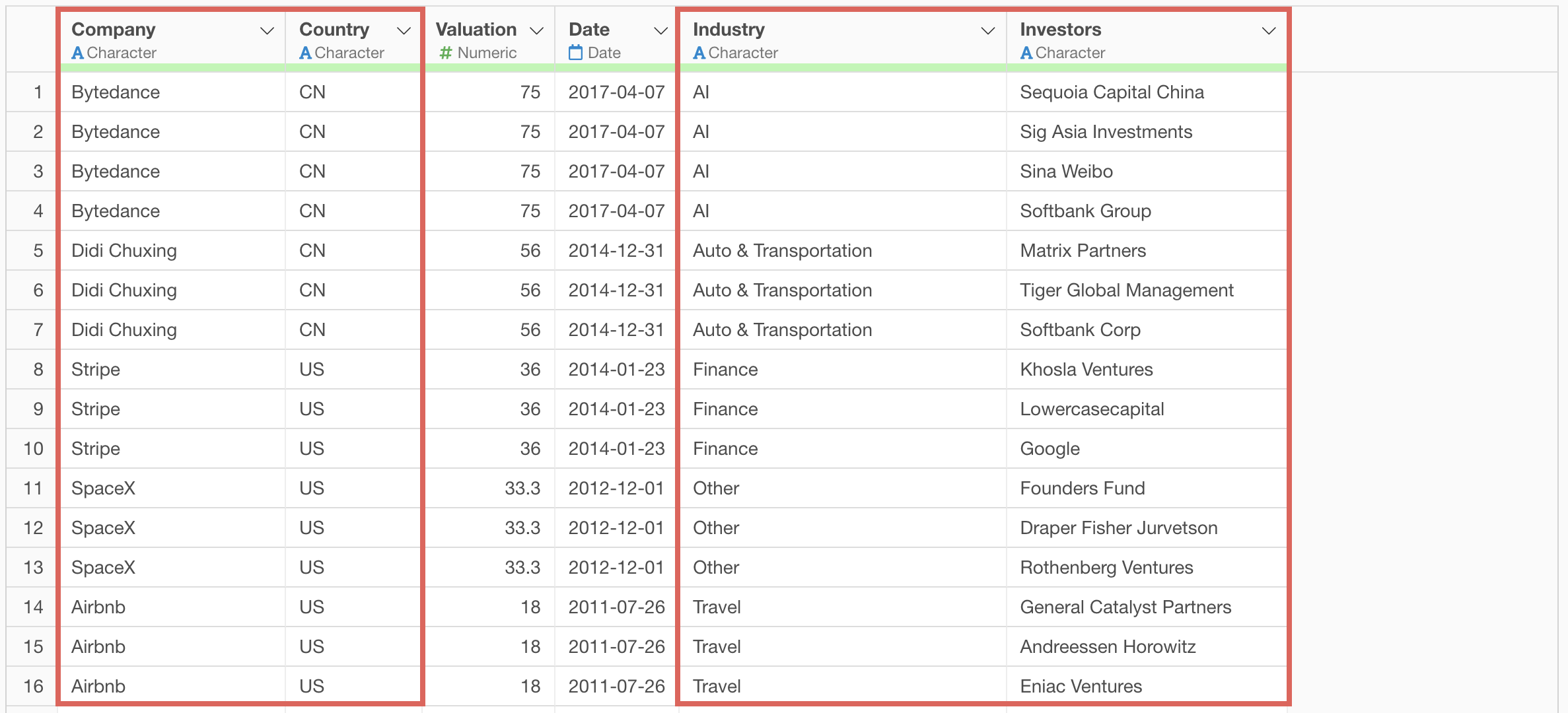
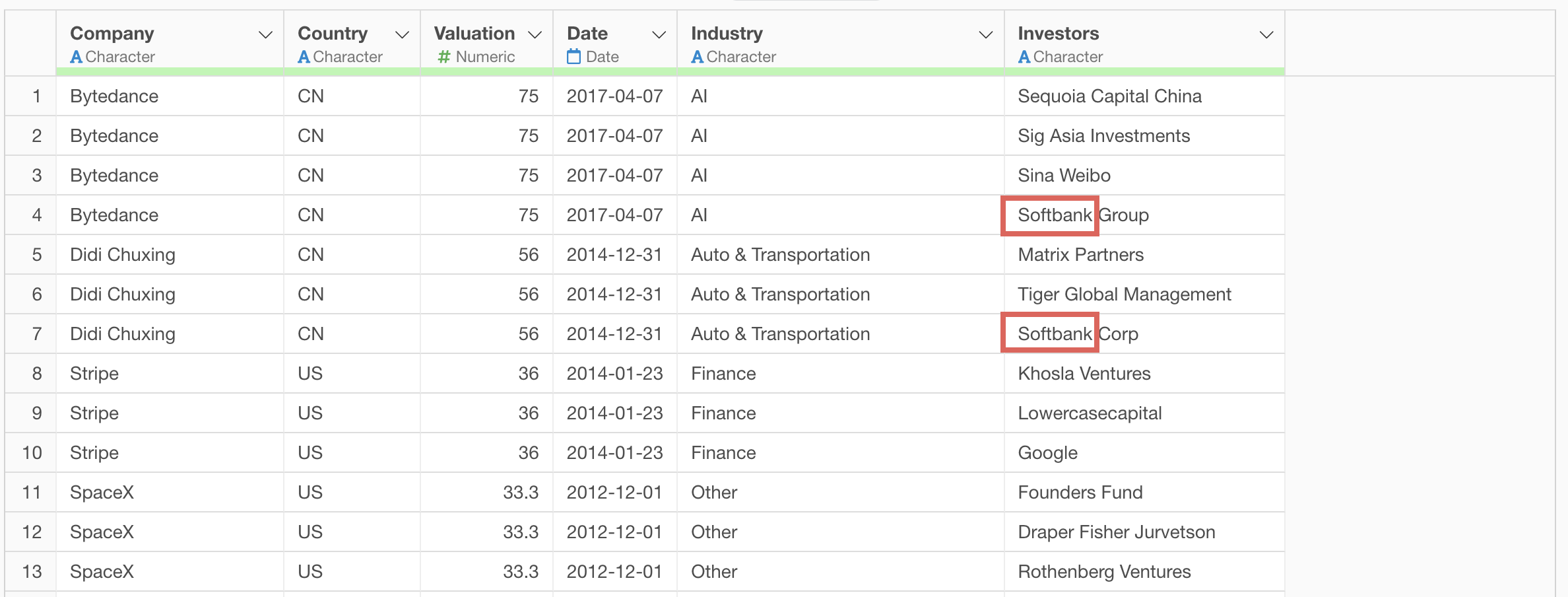
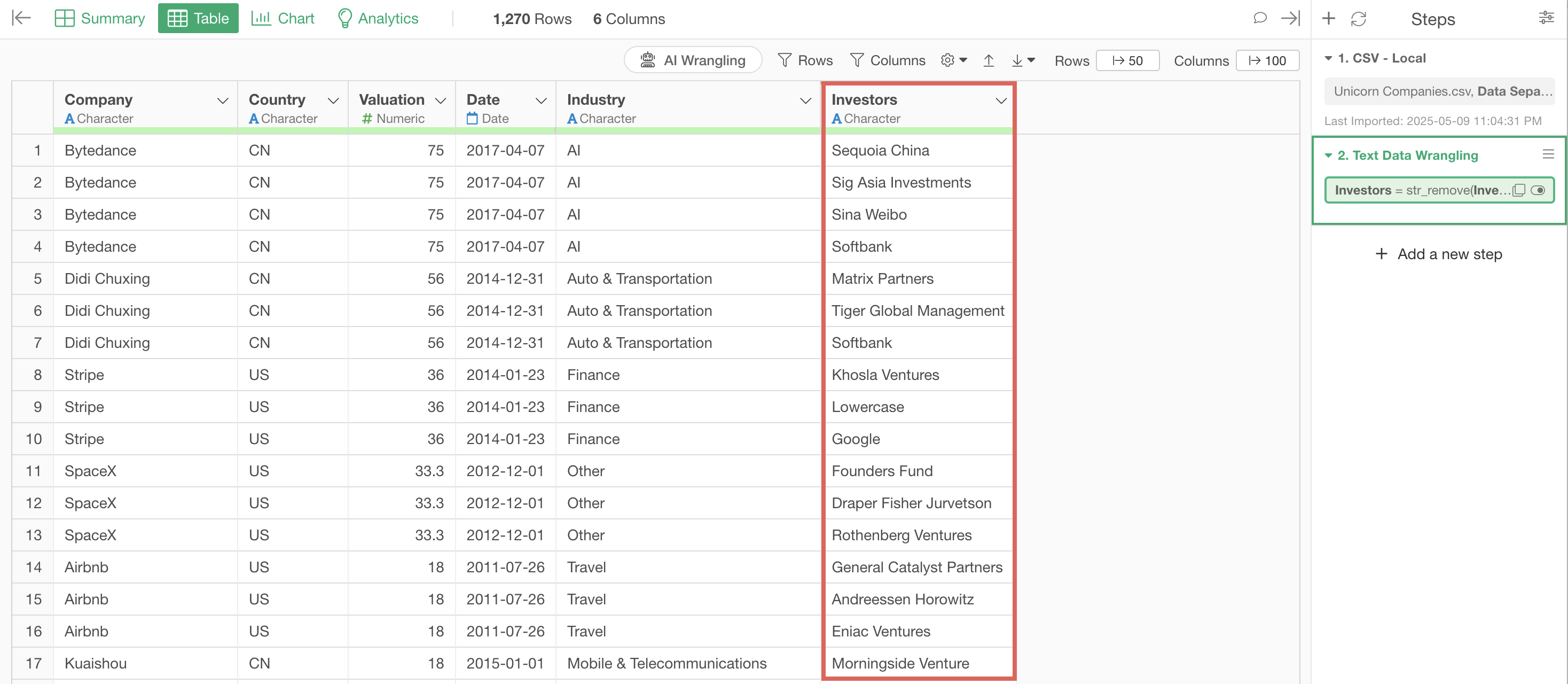
For example, in the aggregation table below, all investors are actually Softbank, but they are treated as separate values due to different notations.
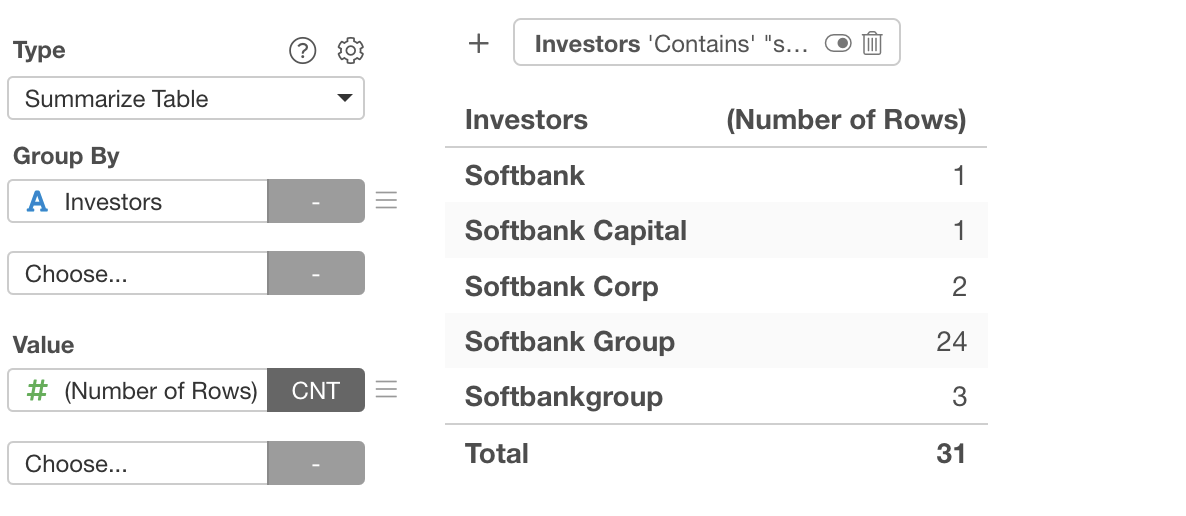
Therefore, values with the same meaning need to be standardized as the same string. This is what “text data processing” does.

Text data processing can be divided into four main types:
- Remove
- Replace
- Extract
- Transform
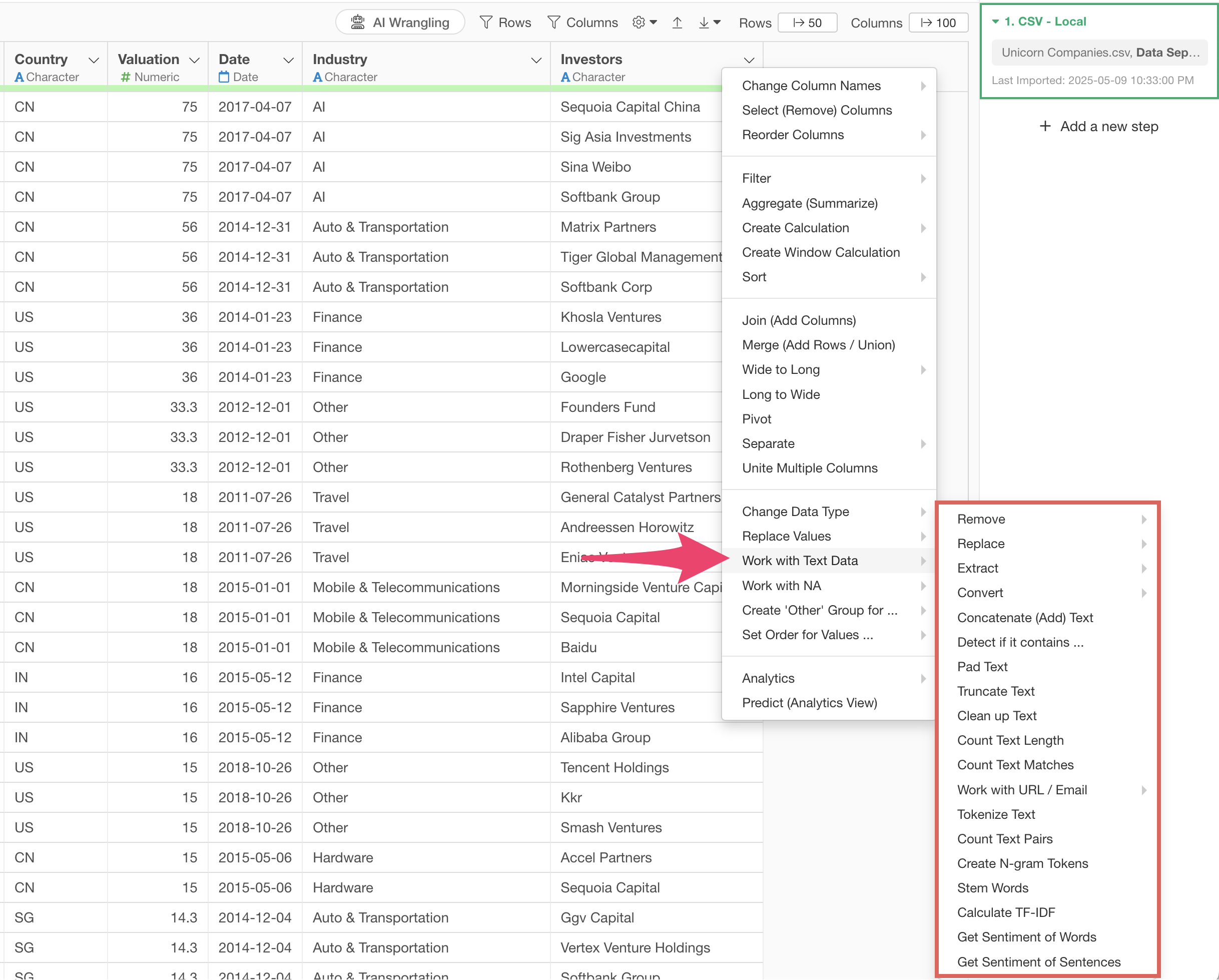
In Exploratory, you can access a rich set of operation types by selecting “Text Data Processing” from the column header menu to easily solve various text data issues.
Importing Data
For this exercise, we’ll use the following two datasets, which can be downloaded from the linked pages:
For data import methods, please refer to this guide.
Using the imported data, we’ll experience three types of text data processing.
Processing Data with AI Prompt
In this section, we’ll experience AI Prompt. If you want to learn more about AI Prompt, please refer to this link.
Let’s process data using AI Prompt.
1. Remove
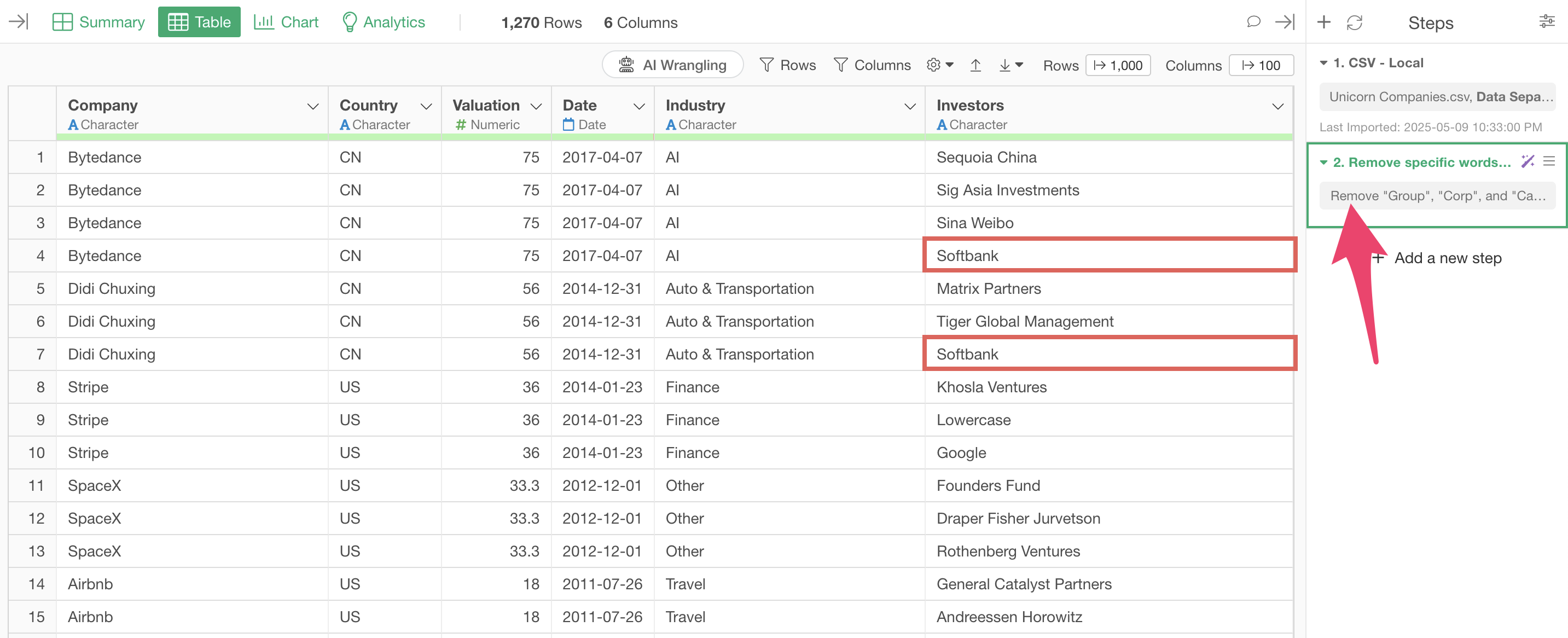
In this part, we’ll use the unicorn company data. Each row represents one company, with rows separated by investor.
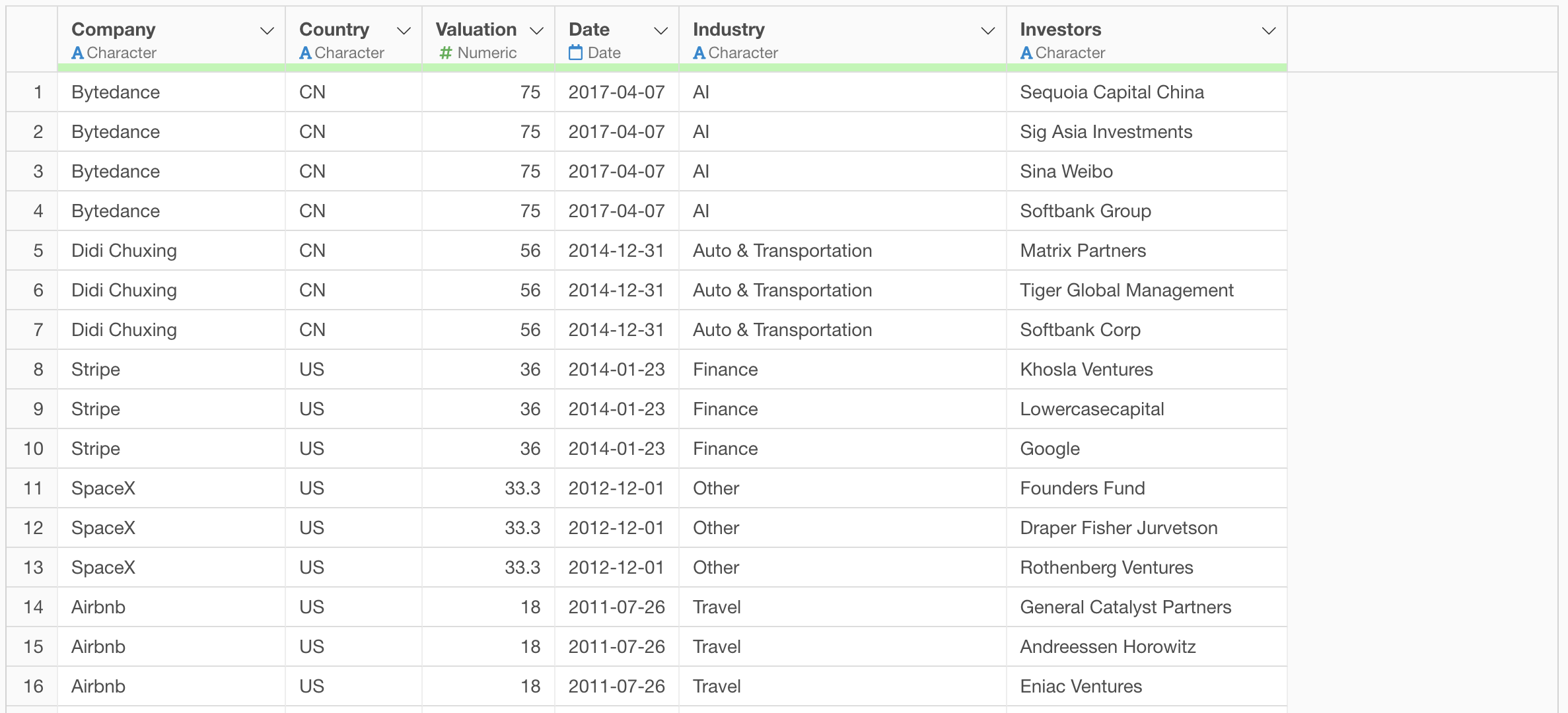
Looking at the investor column, we can see strings like “Softbank Group” and “Softbank Corp”.
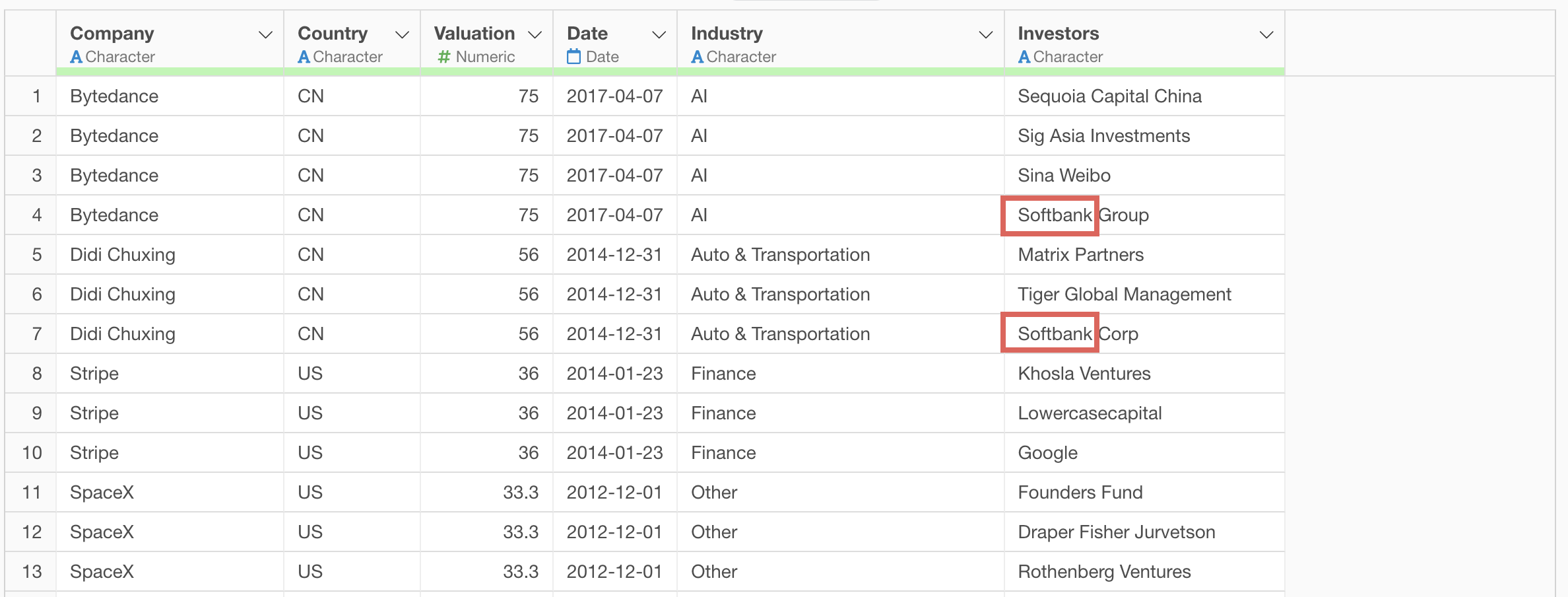
We can also see strings like “Softbank Capital”.
We’ll remove words like Group, Corp, and Capital to standardize the notation to Softbank.
Click the “AI Wrangling” button, and when the AI Prompt dialog appears, enter the following text and execute:
Remove “Group”, “Corp”, and “Capital” from the Investor column
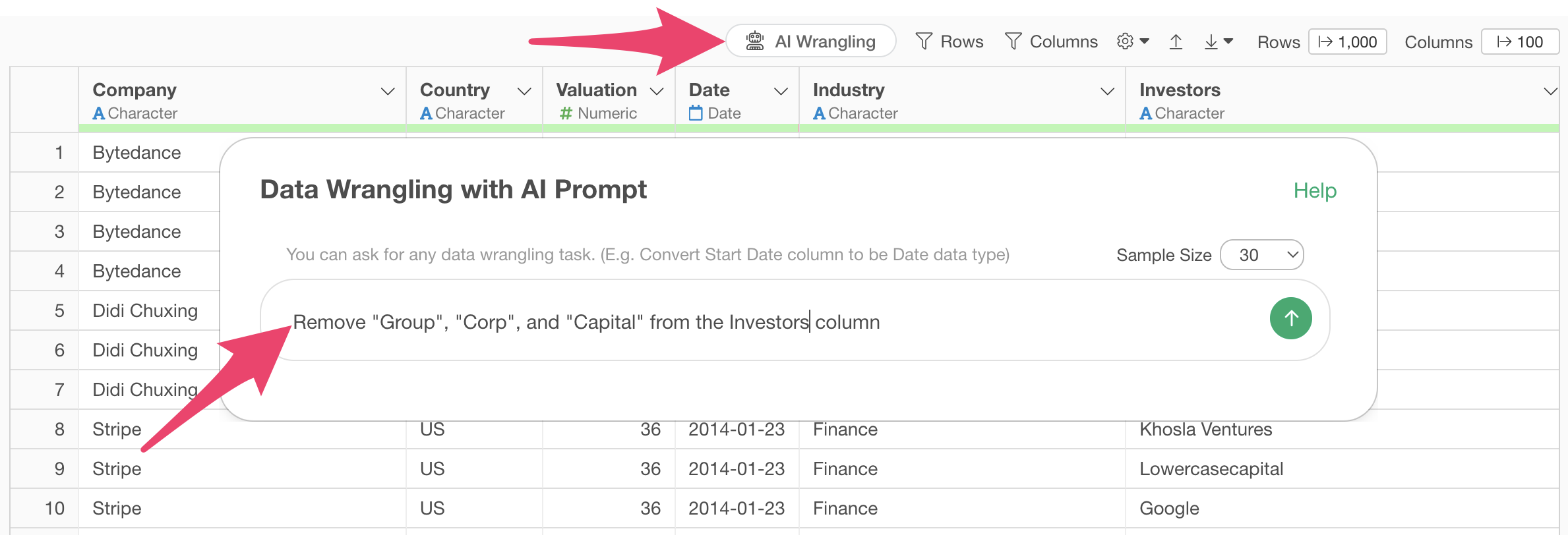
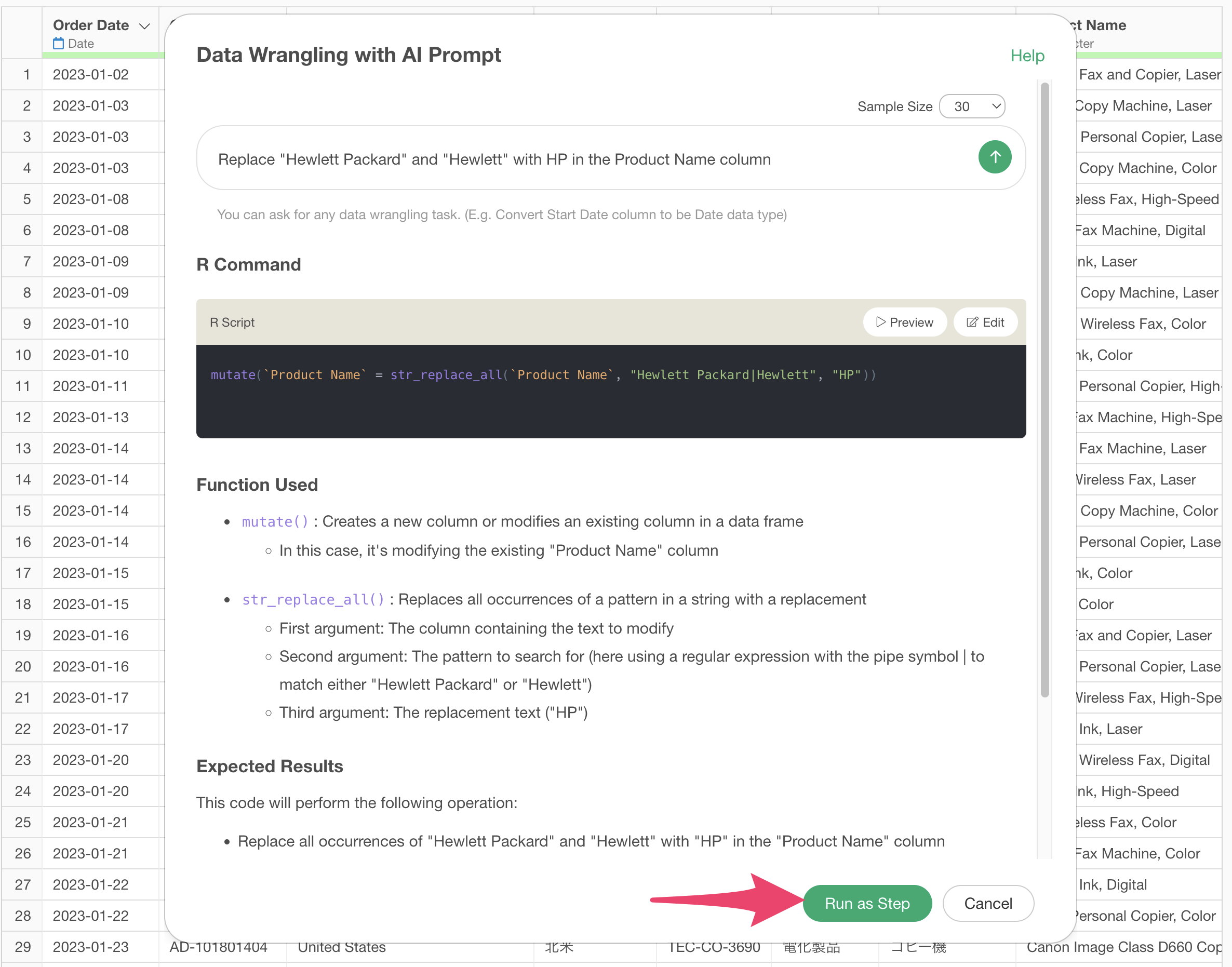
Code will be generated to remove the specified strings from the investor column. Check the explanation and expected results, then click the “Run as Step” button.
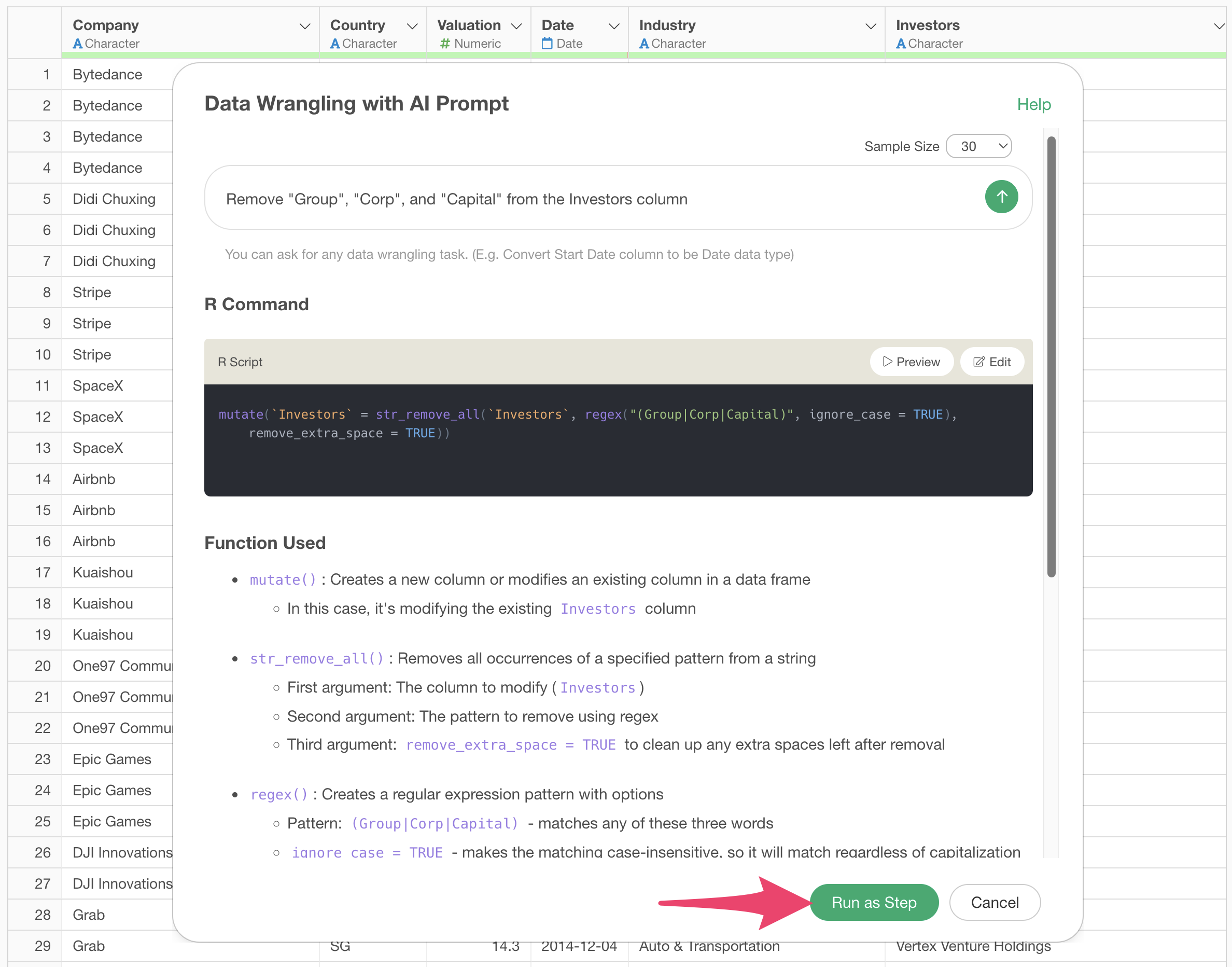
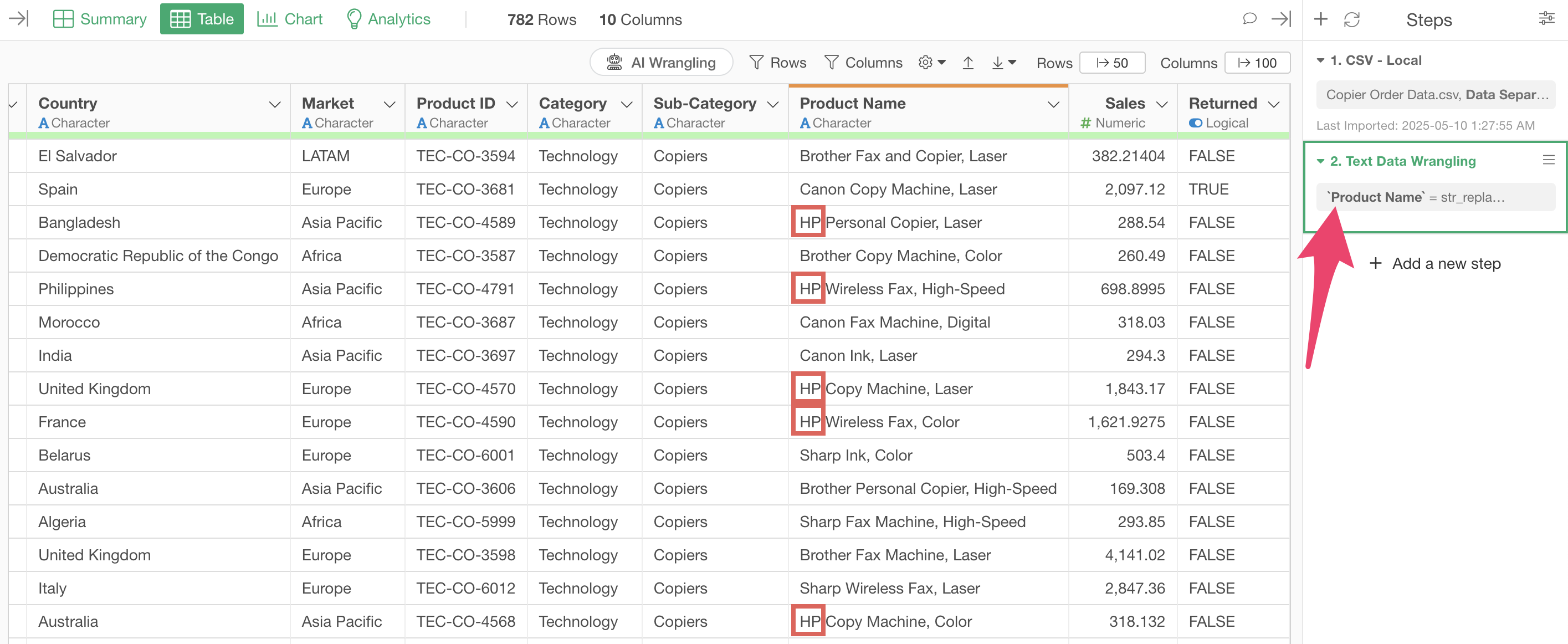
The step is added, and parts like “Group” and “Corp” are removed from strings like “Softbank Group” and “Softbank Corp”, organizing them as “Softbank”.
2. Replace
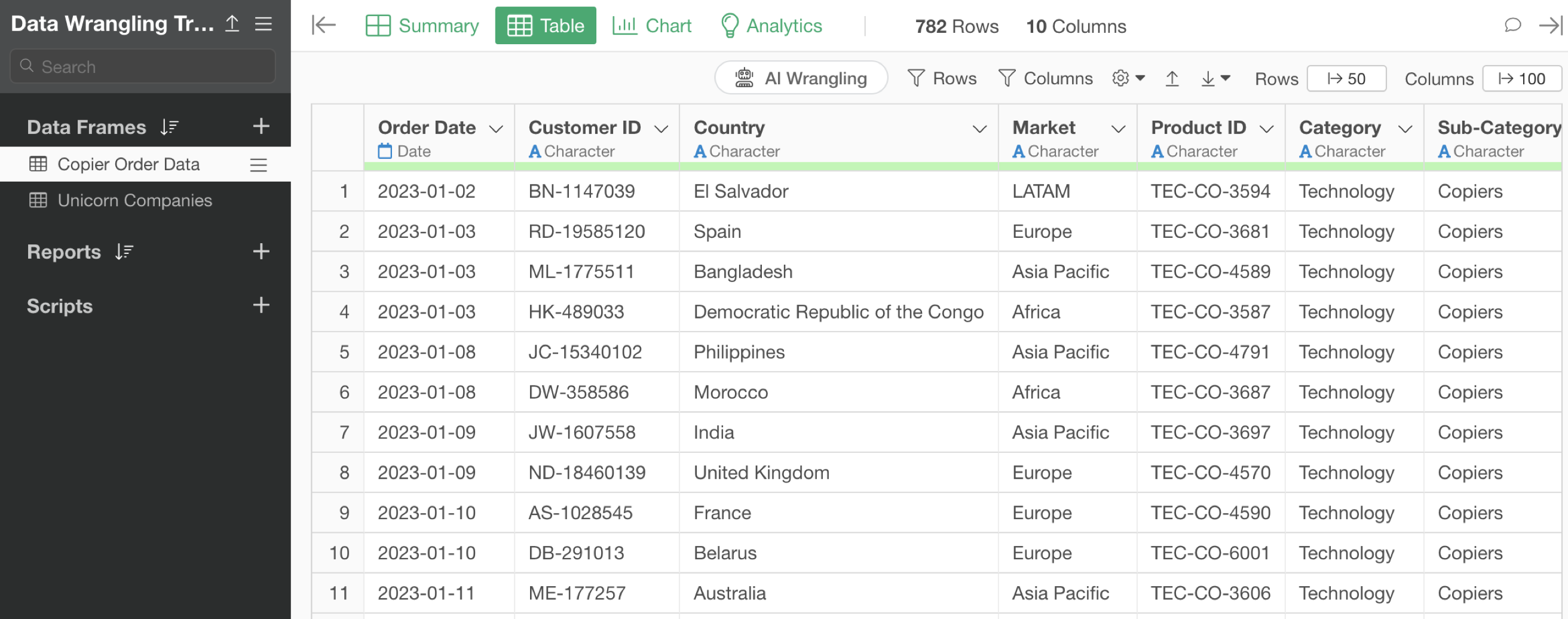
In this part, we’ll use the copier order data. Each row represents one order, with rows separated by product.
The data is filtered to the “Copier” product subcategory, as if you were a copier sales representative.
Looking at the product name column, we can see that Hewlett Packard products have inconsistent notations like “HP” and “Hewlett”.
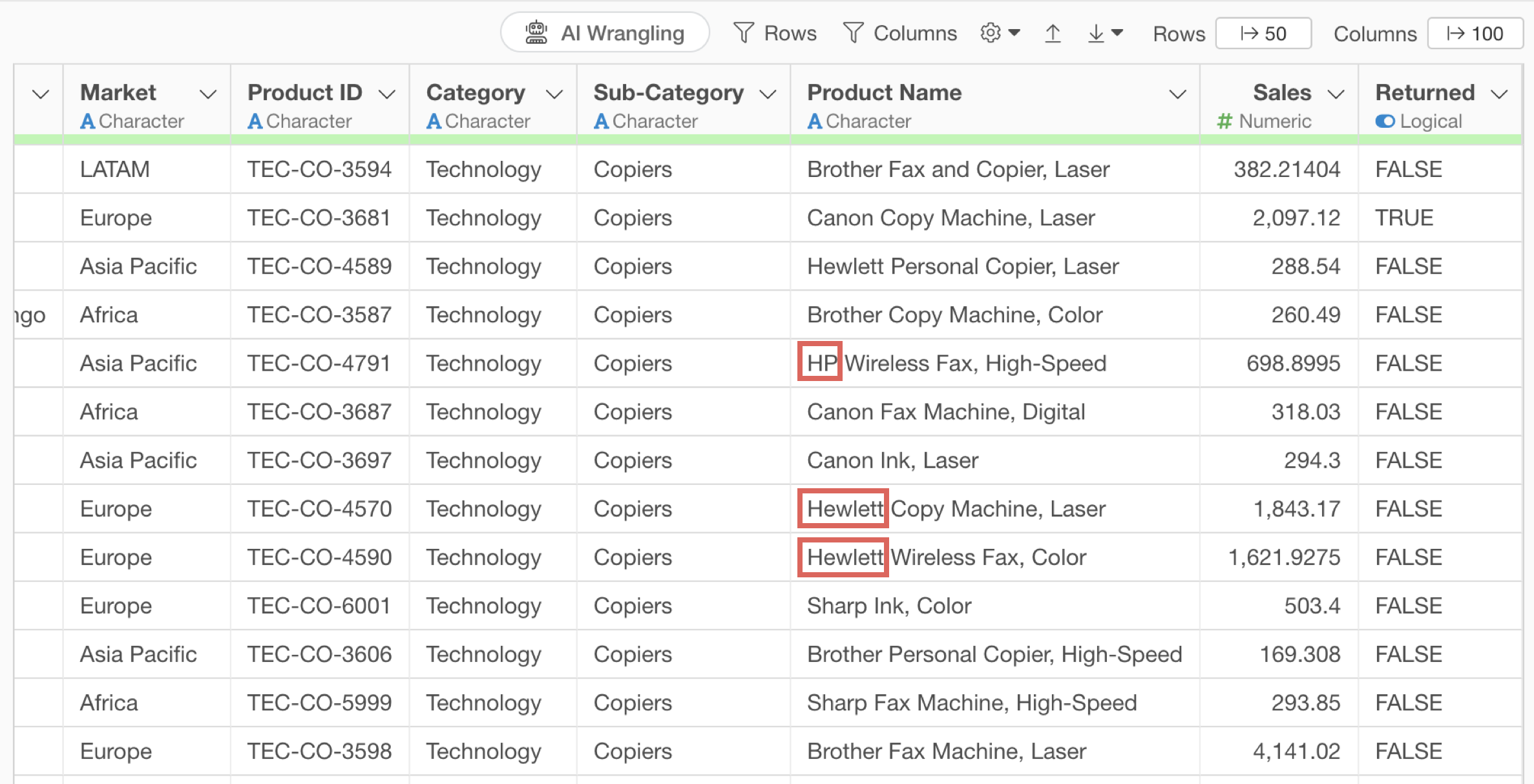
We’ll replace strings like “Hewlett” in the product name with “HP”.
Click the “AI Wrangling” button, and when the AI Prompt dialog appears, enter the following text and execute:
Replace “Hewlett Packard” and “Hewlett” with HP in the product name column
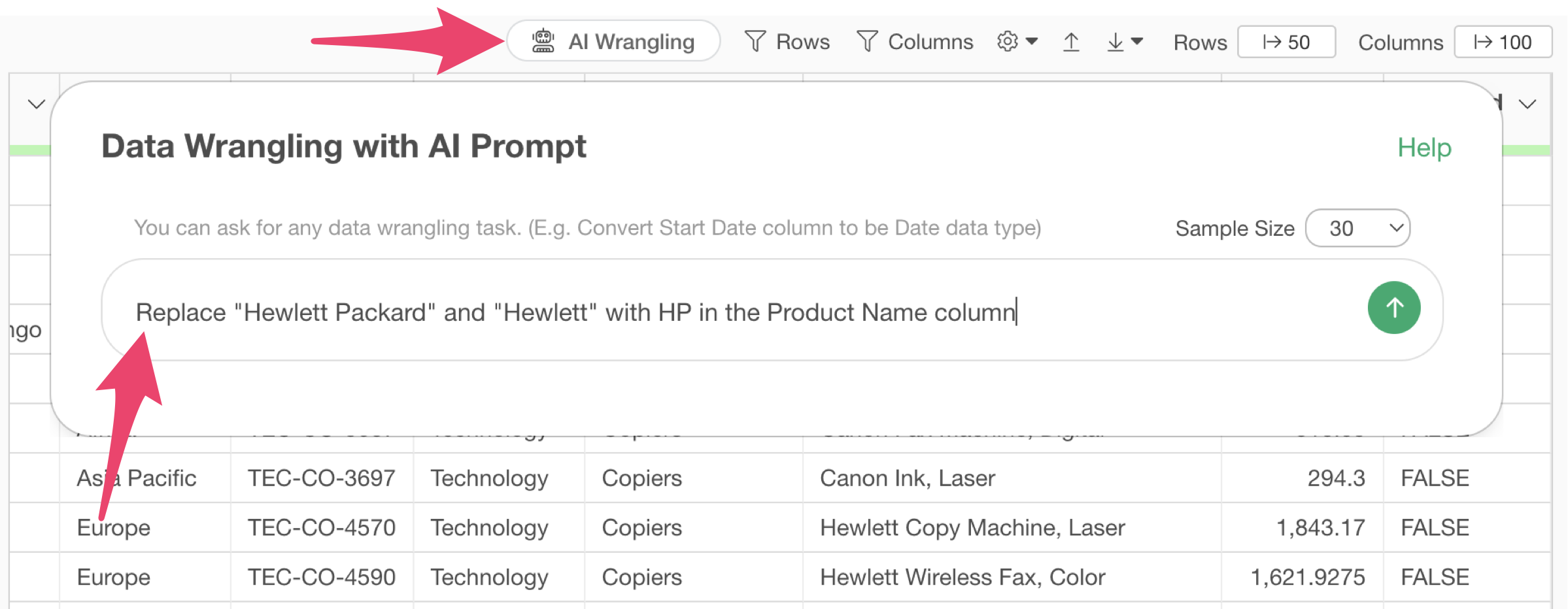
Code will be generated to replace “Hewlett Packard” and “Hewlett” with “HP” in the product name column. Check the explanation of the functions used and the expected results, then click the “Execute as Step” button.
The step is added, and we’ve successfully replaced “Hewlett Packard” and “Hewlett” with “HP”, standardizing the previously inconsistent strings.
3. Extract
We’ll use the same “Copier Order Data” as in the previous part.
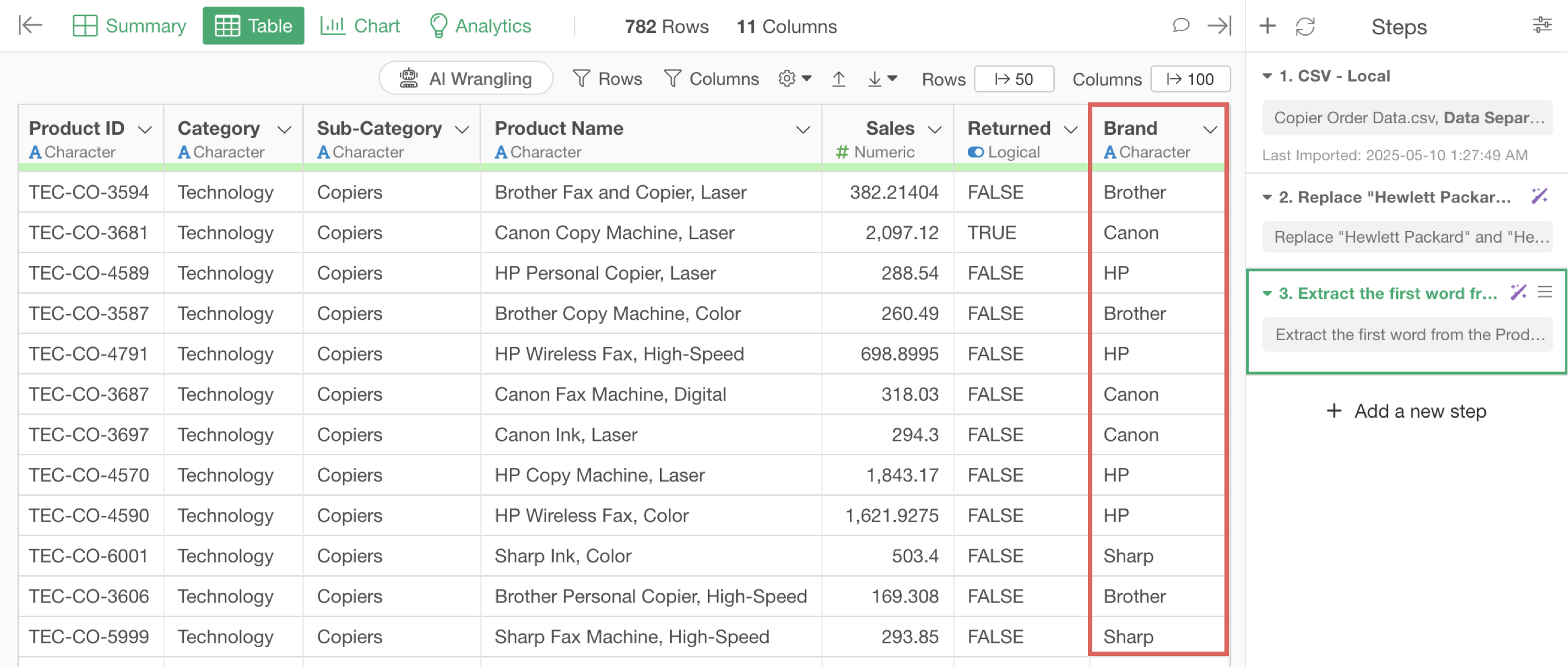
Previously, we replaced “Hewlett Packard” and “Hewlett” with “HP”, but now we want to extract the “first word” from the “Product Name” column as the brand name and create it as a new column.
Click the “AI Wrangling” button and enter the following text in the AI Prompt dialog:
Extract the first word from the product name column
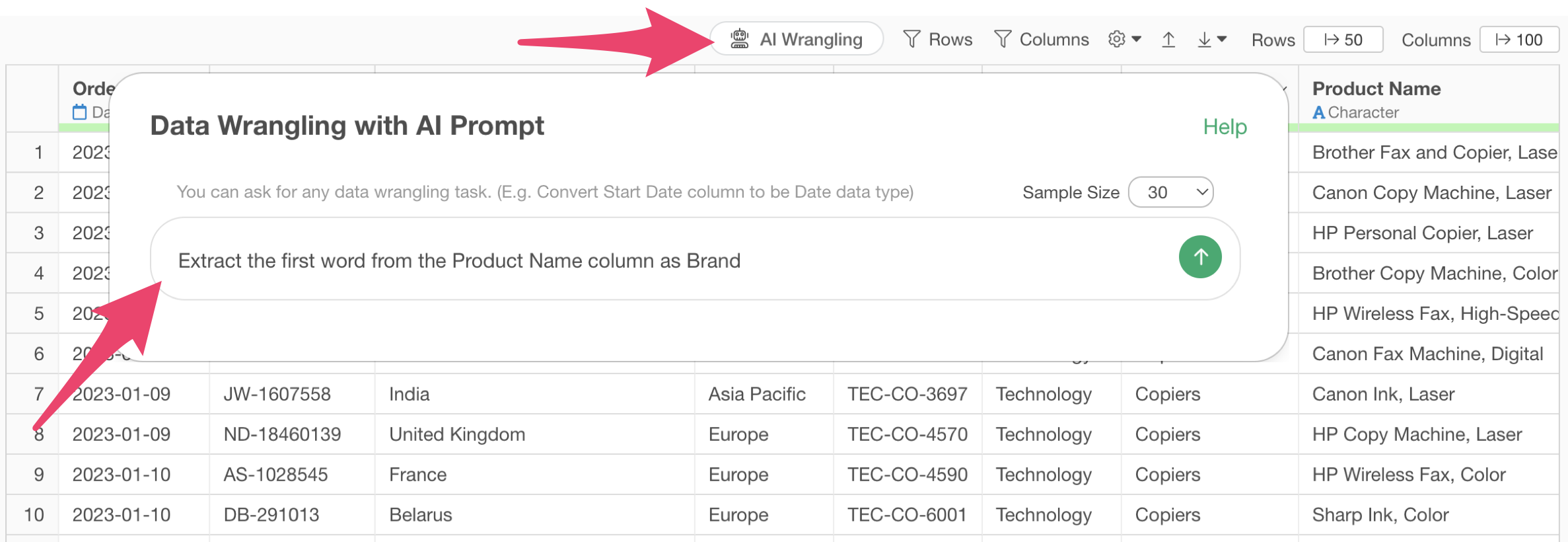
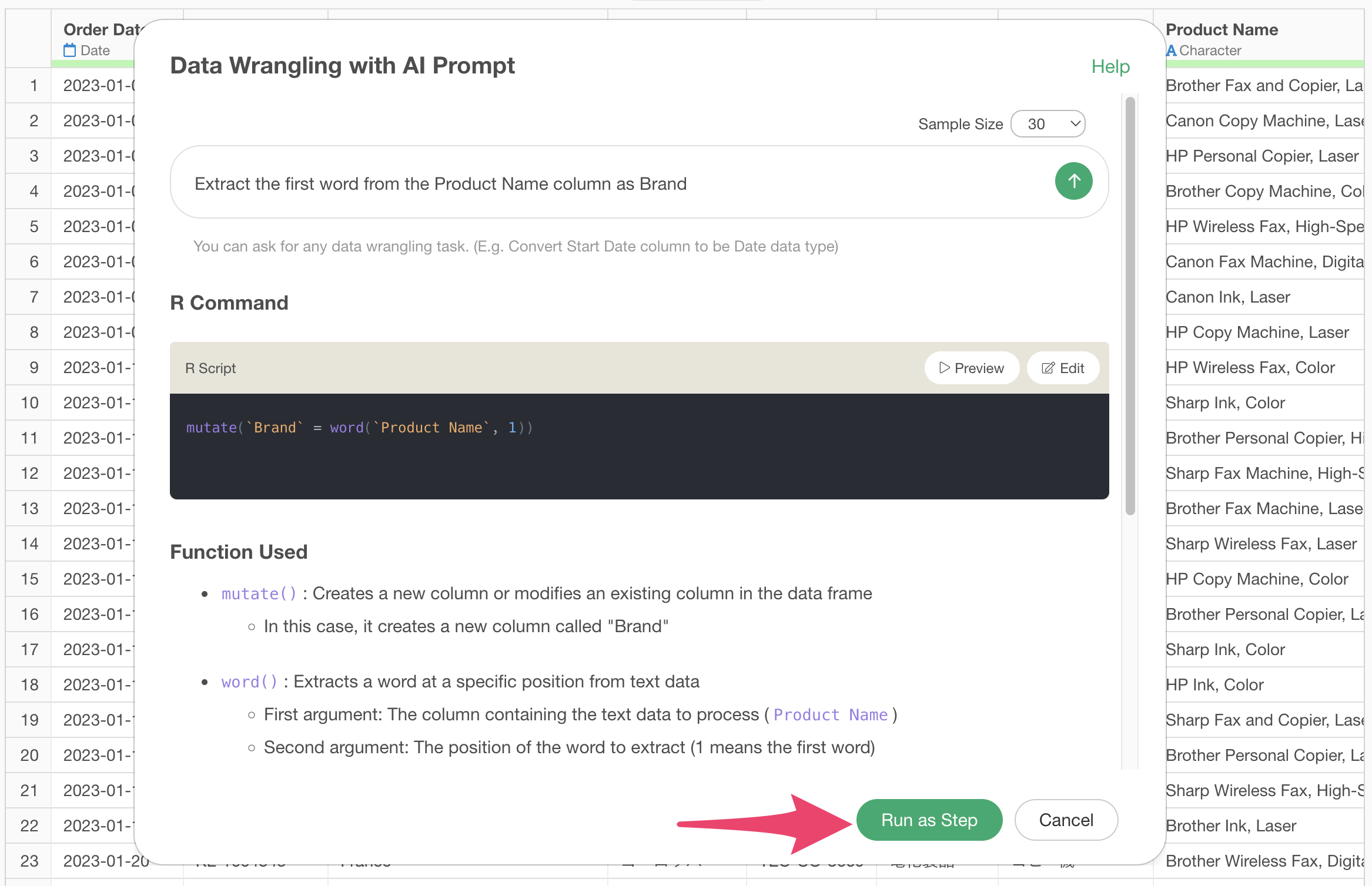
Code will be generated to extract the brand name from the product name column. Check the explanation of the functions used and the expected results, then click the “Execute as Step” button.
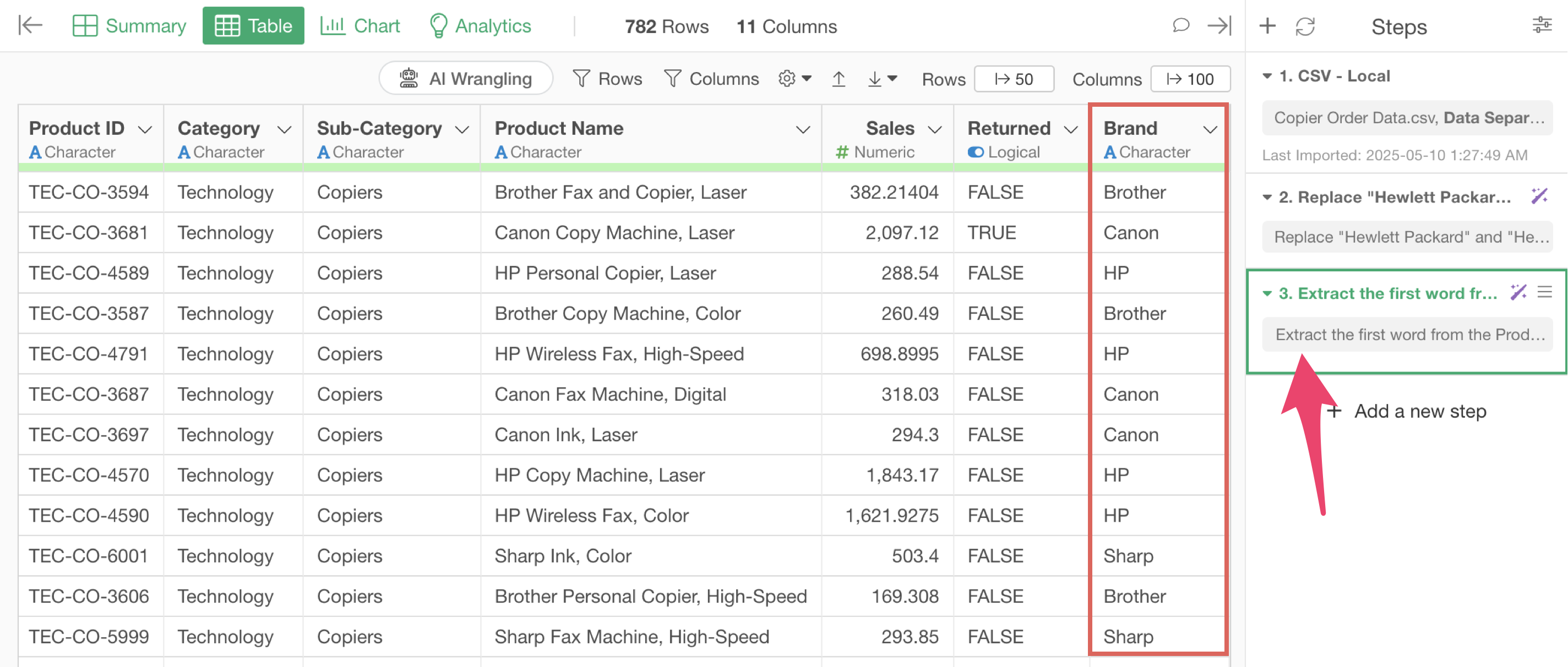
We’ve successfully created a “Brand” column by extracting the brand name from the product name.
Processing Data with UI
1. Remove
In this part, we’ll use the unicorn company data. Each row represents one company, with rows separated by investor.
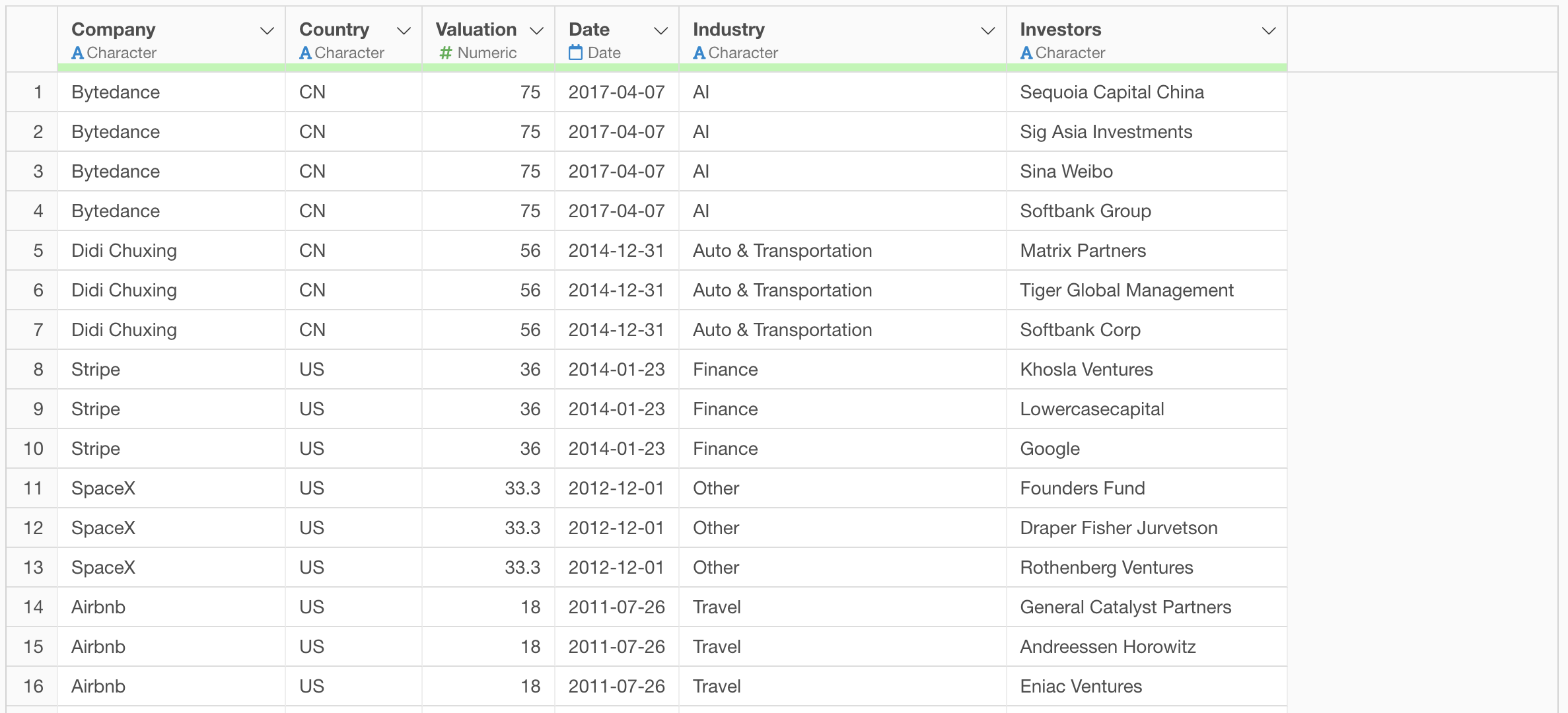
Looking at the investor column, we can see strings like “Softbank Group” and “Softbank Corp”.
We want to remove the “Group” from “Softbank Group” to make it just “Softbank”.
From the column header menu, select “Text Data Processing” > “Remove” > “String”.
The text data processing dialog appears.
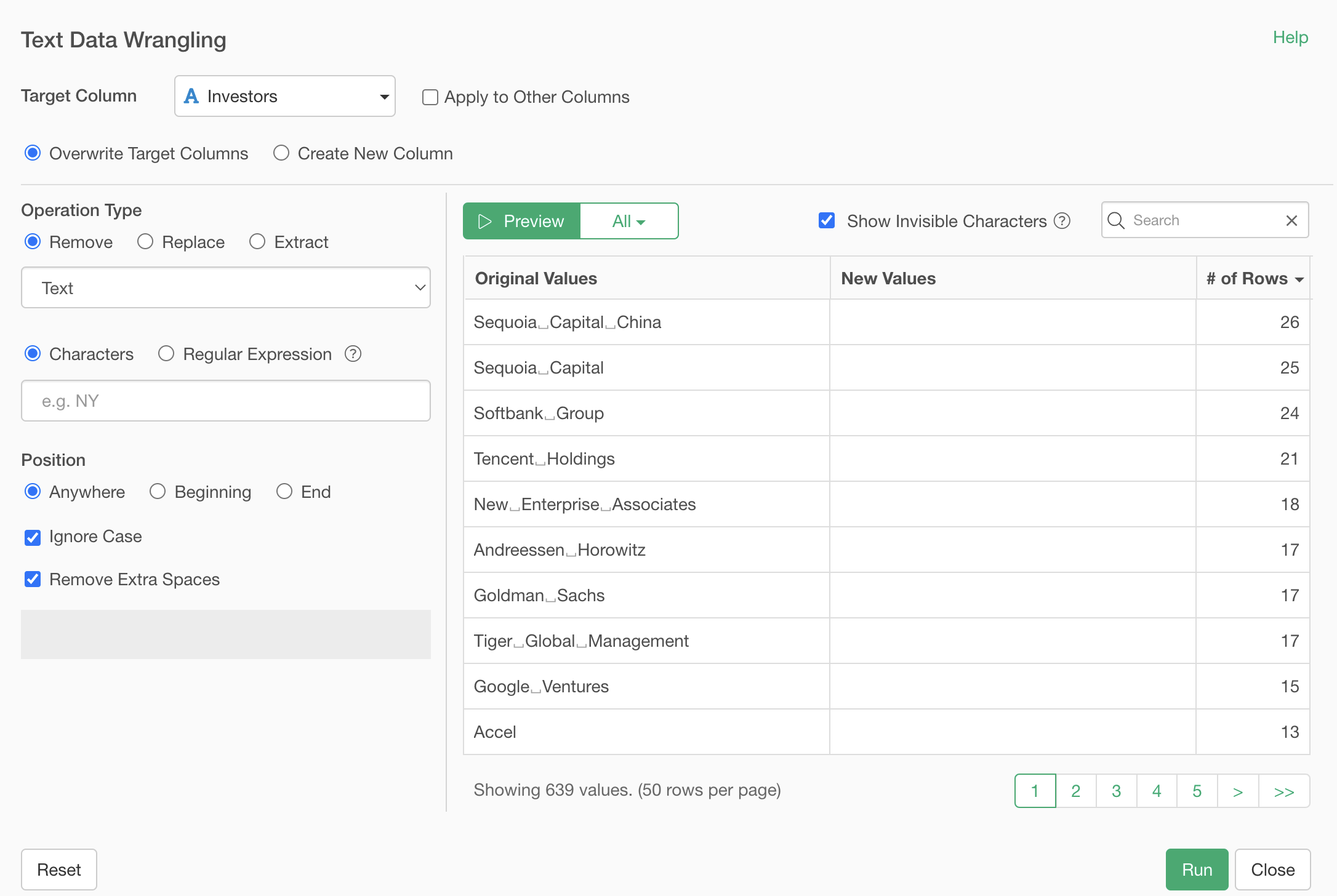
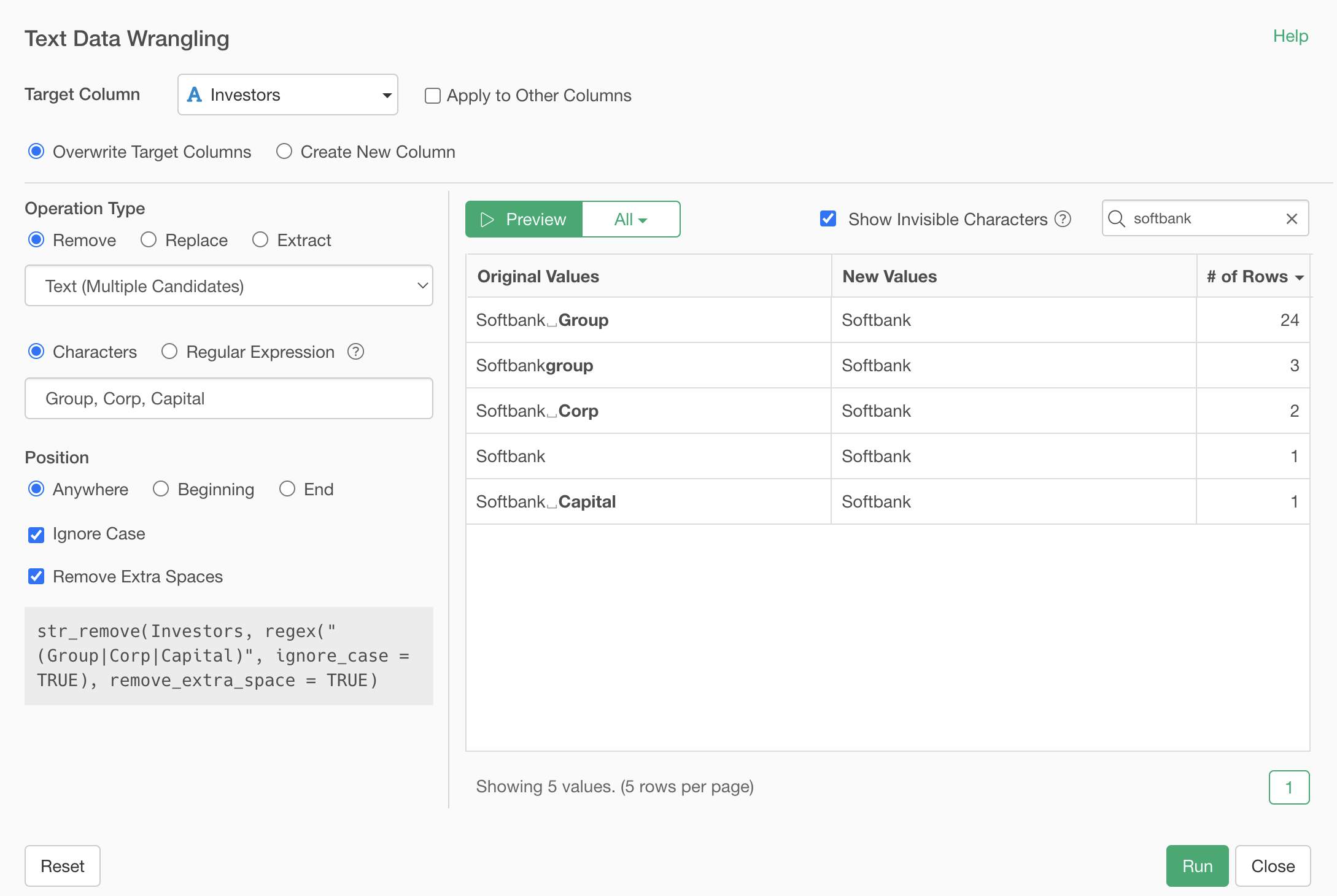
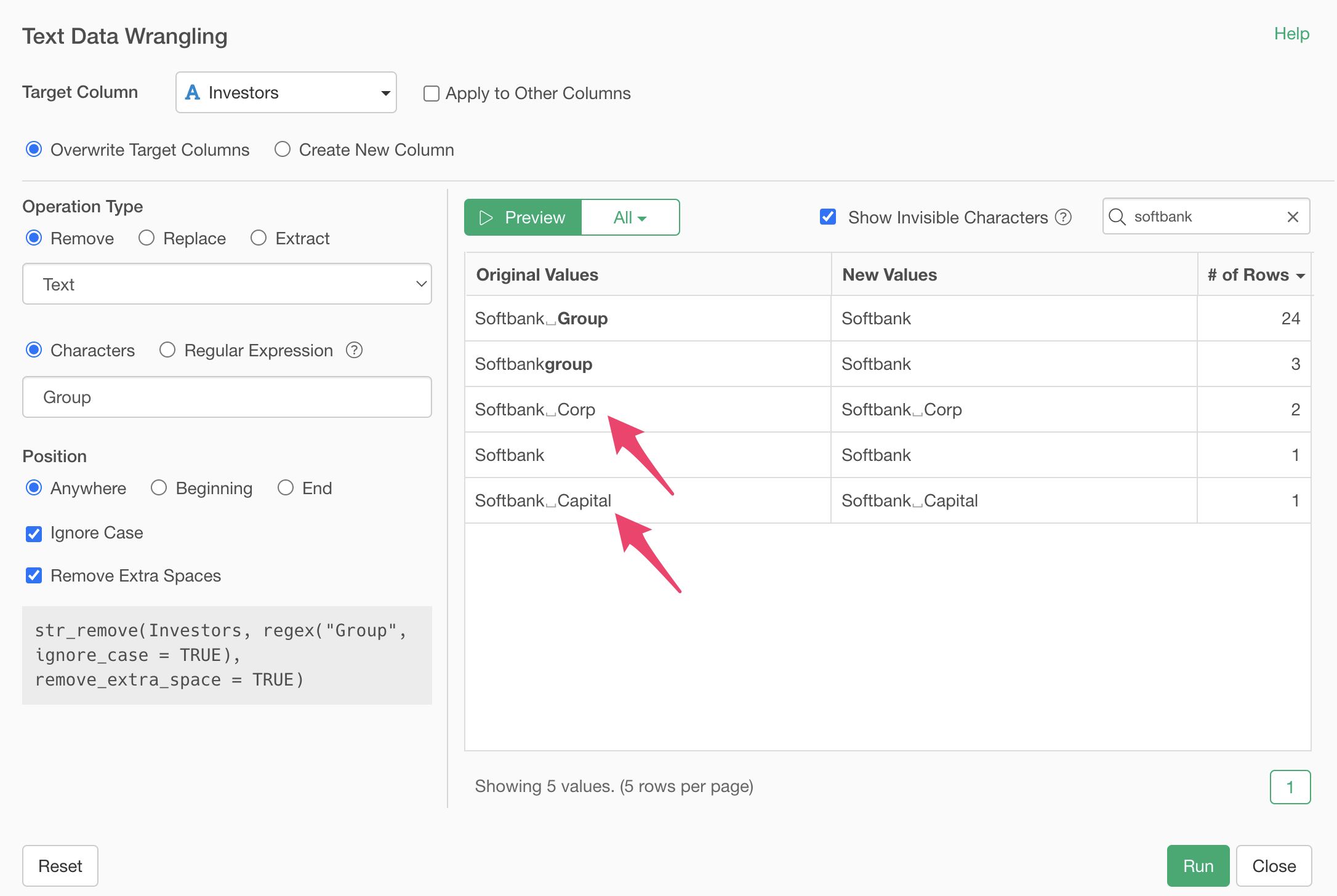
By specifying “softbank” in the search box, only values containing “softbank” are displayed.
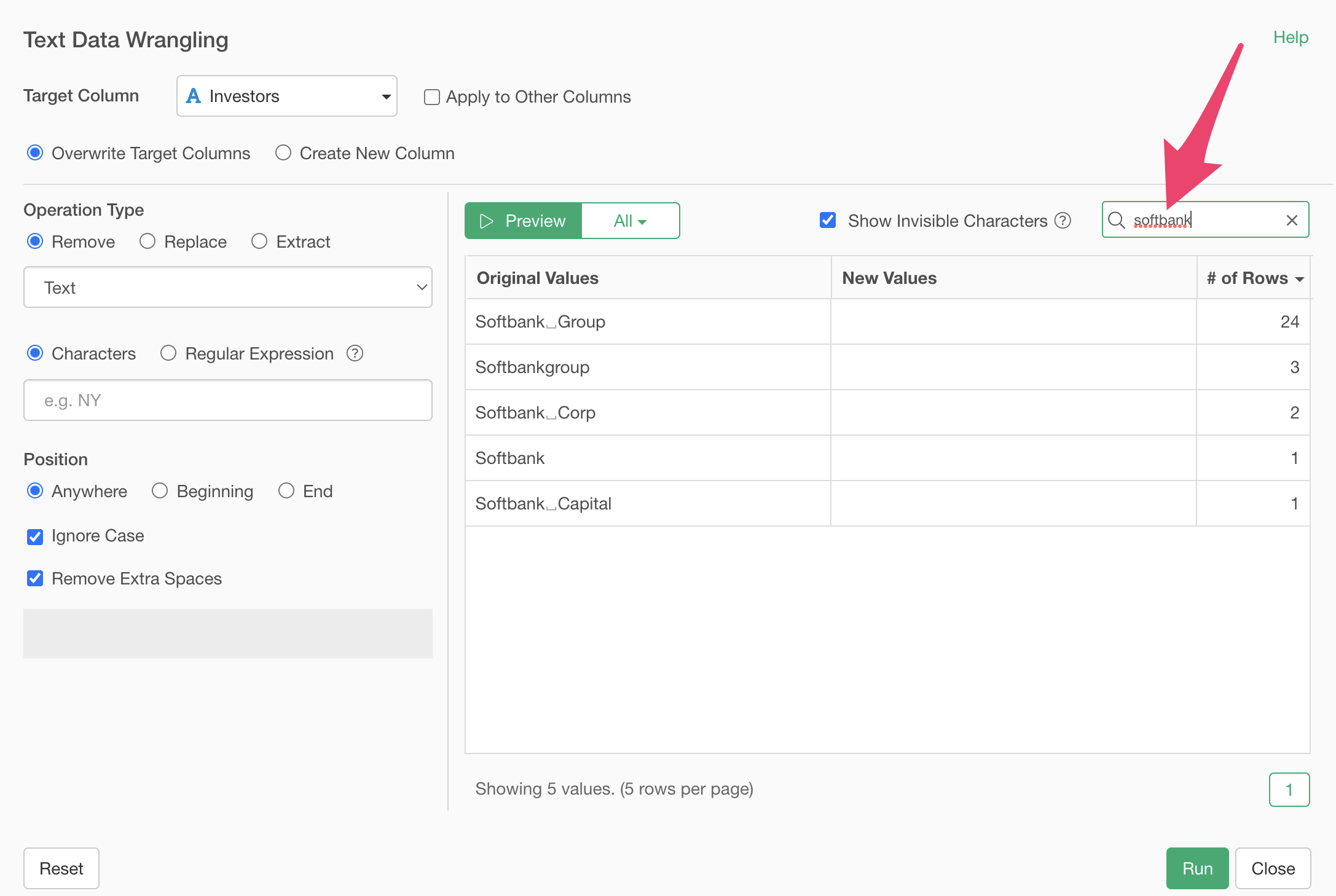
Specify “Group” as the text. This highlights the “Group” text in the original values in bold.
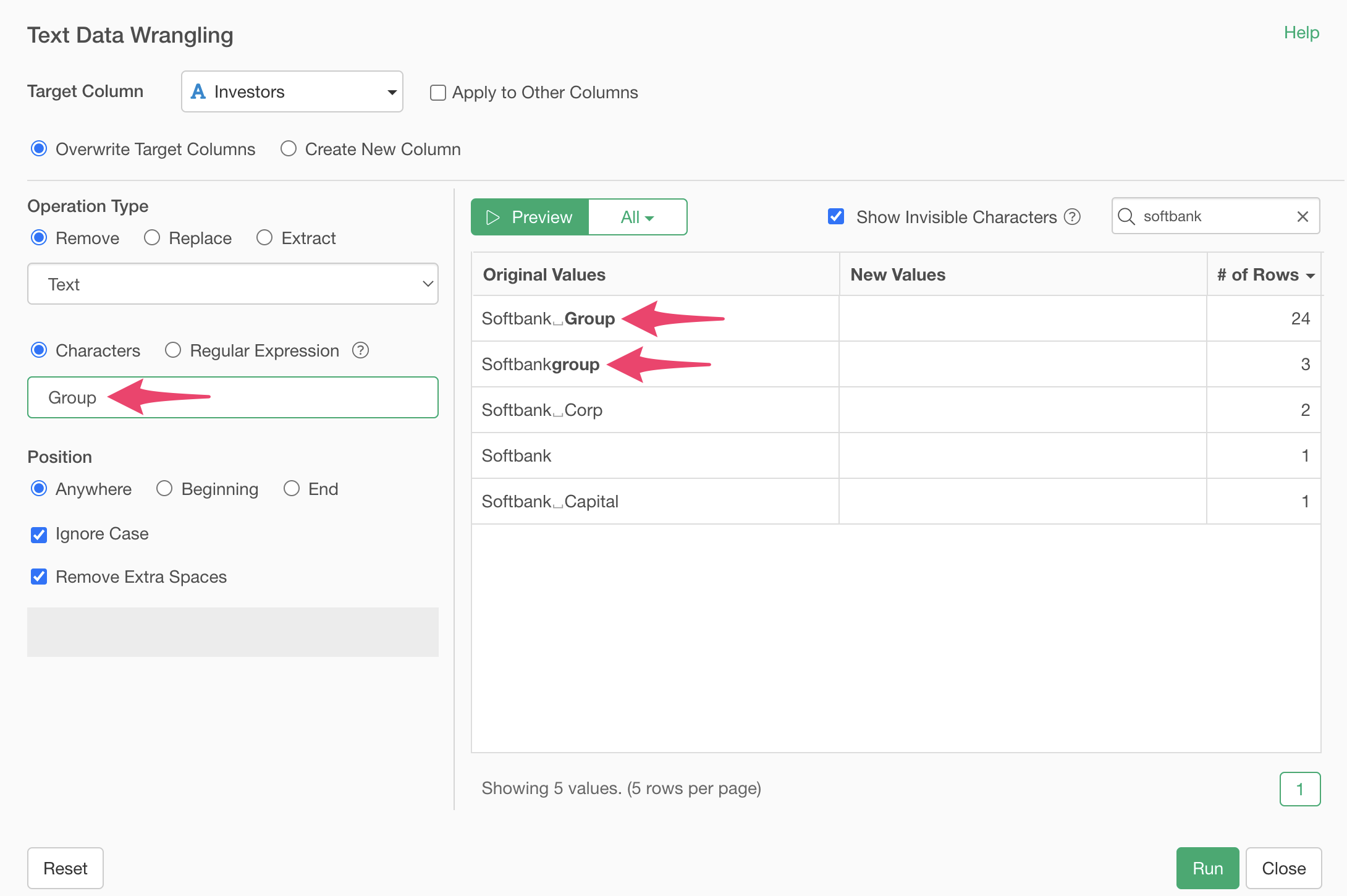
Clicking the preview button shows that “Group” has been removed, leaving “Softbank”.
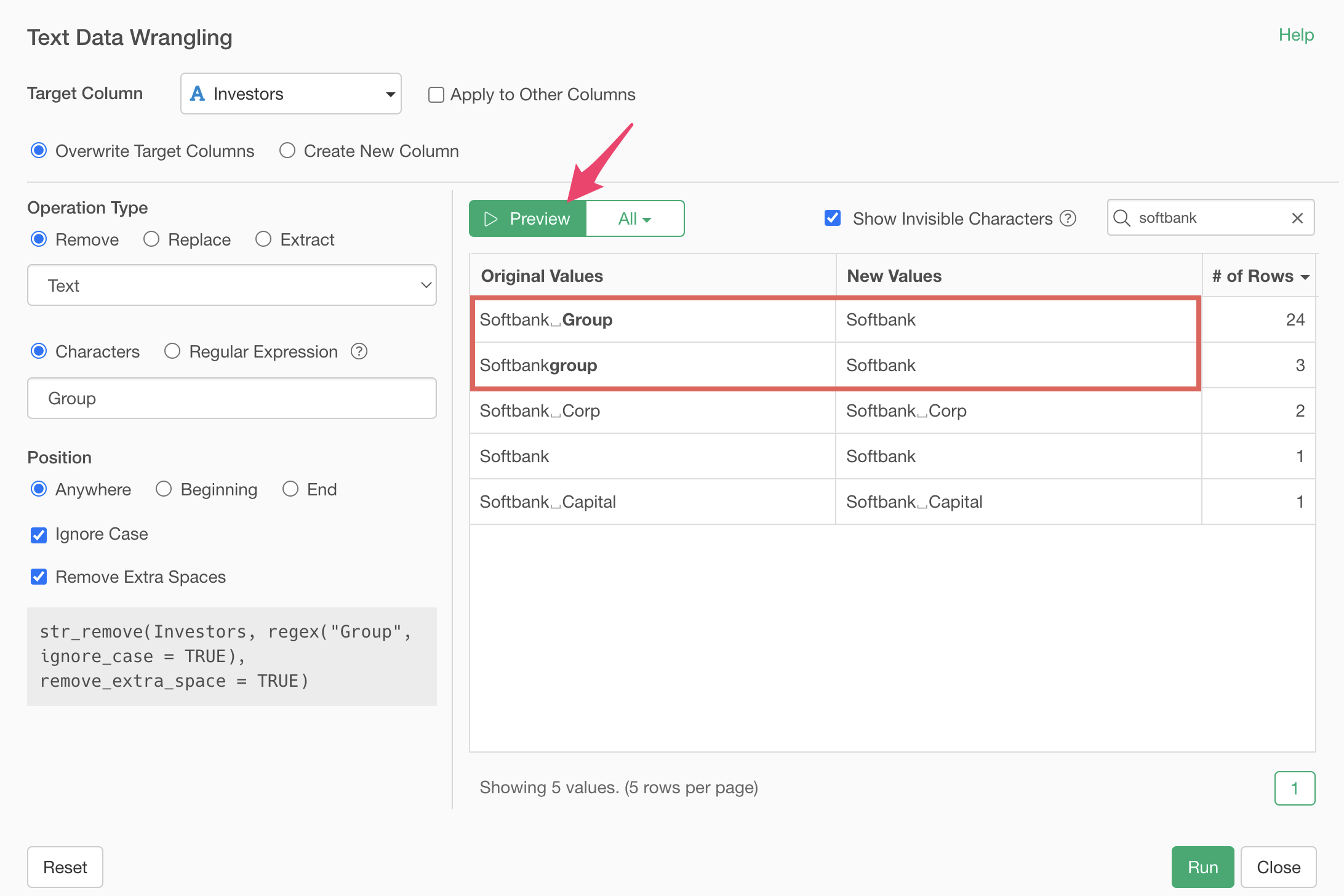
The “Ignore case” option is applied, so even “group” with all lowercase letters is removed because the string matches.
If you uncheck “Ignore case”, text will only be removed if it perfectly matches what you specified in “Text”.
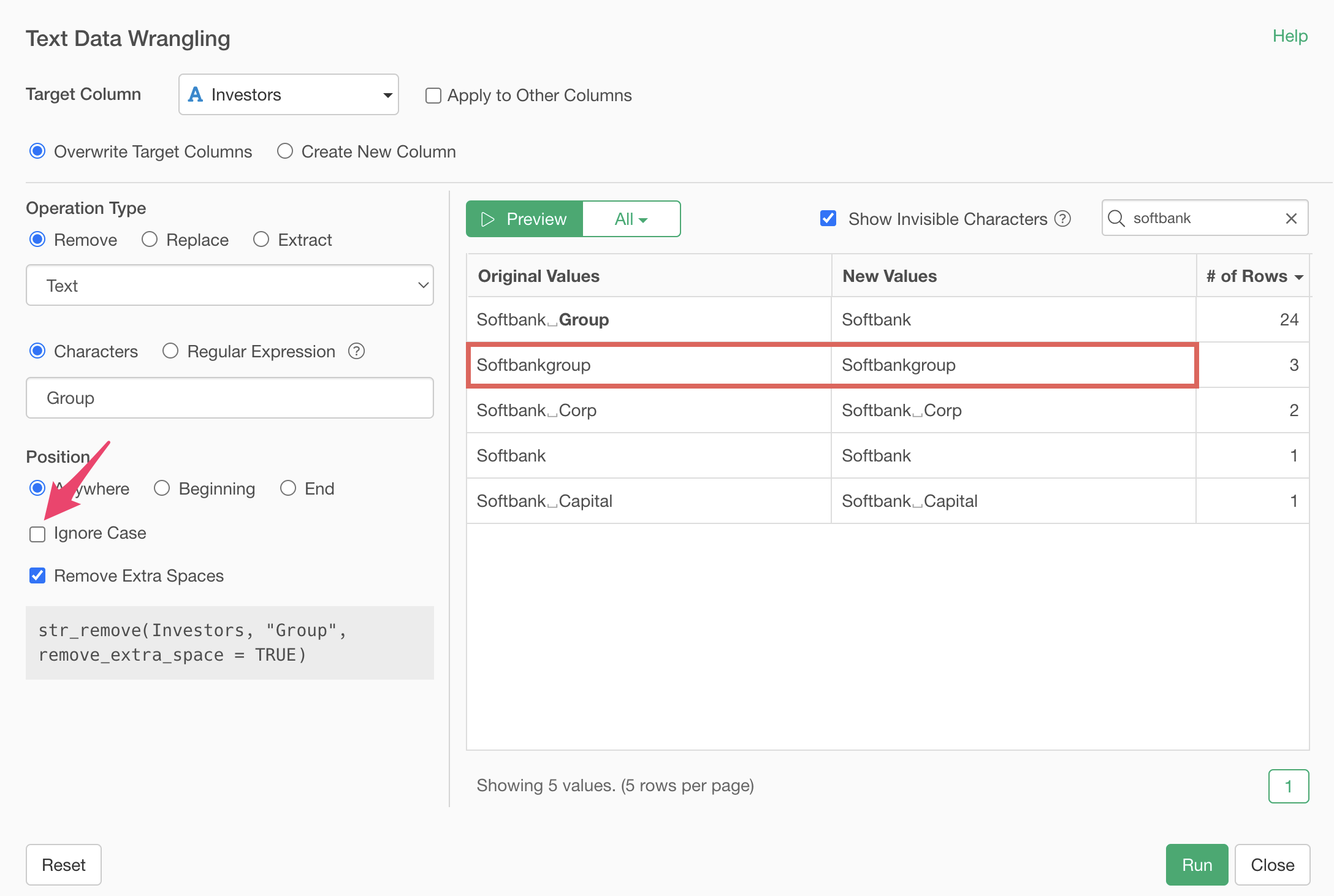
In this case, we want to remove the string regardless of case, so we keep “Ignore case” checked.
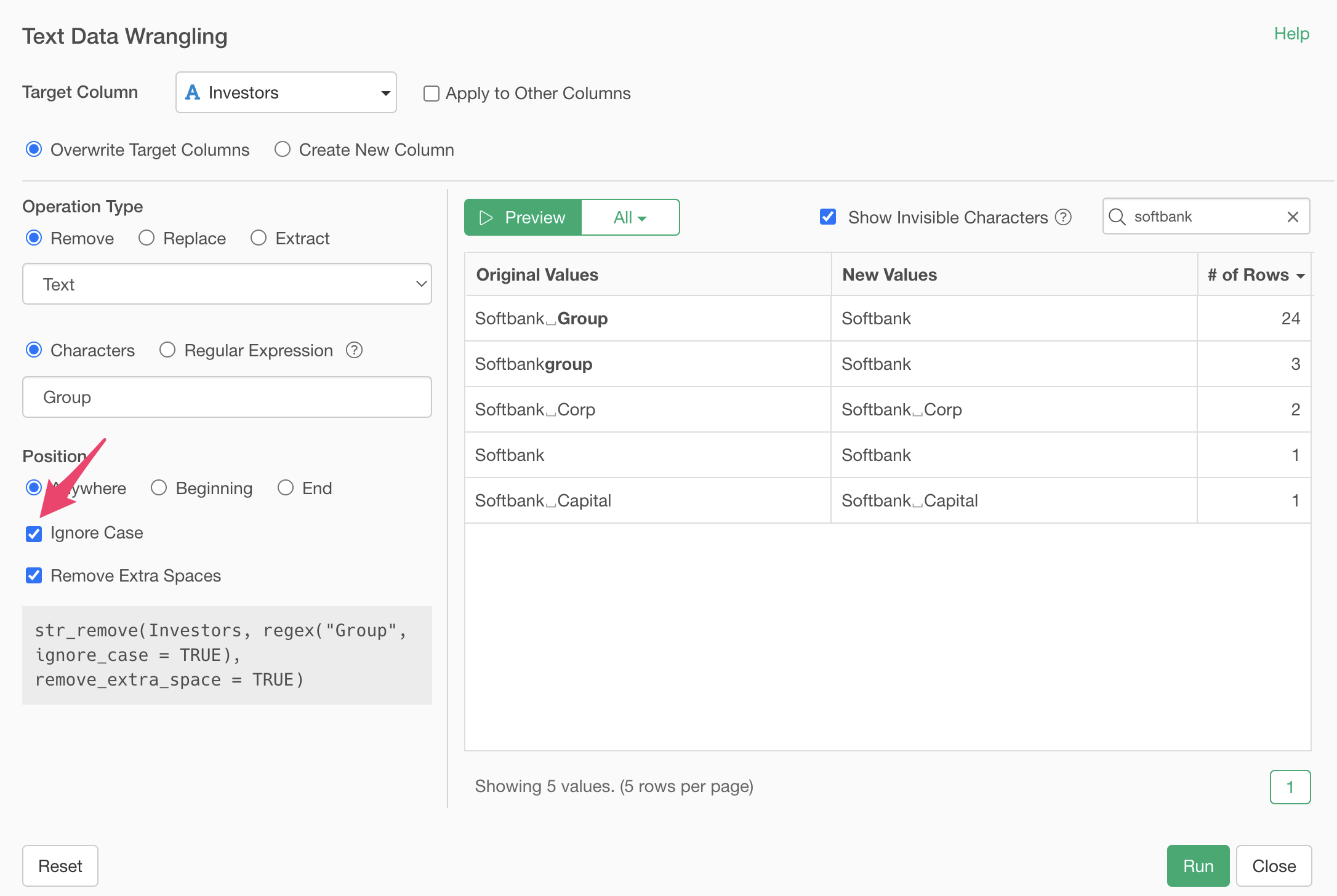
We’ve removed the “Group” string, but we also want to remove strings like “Corp” and “Capital”.
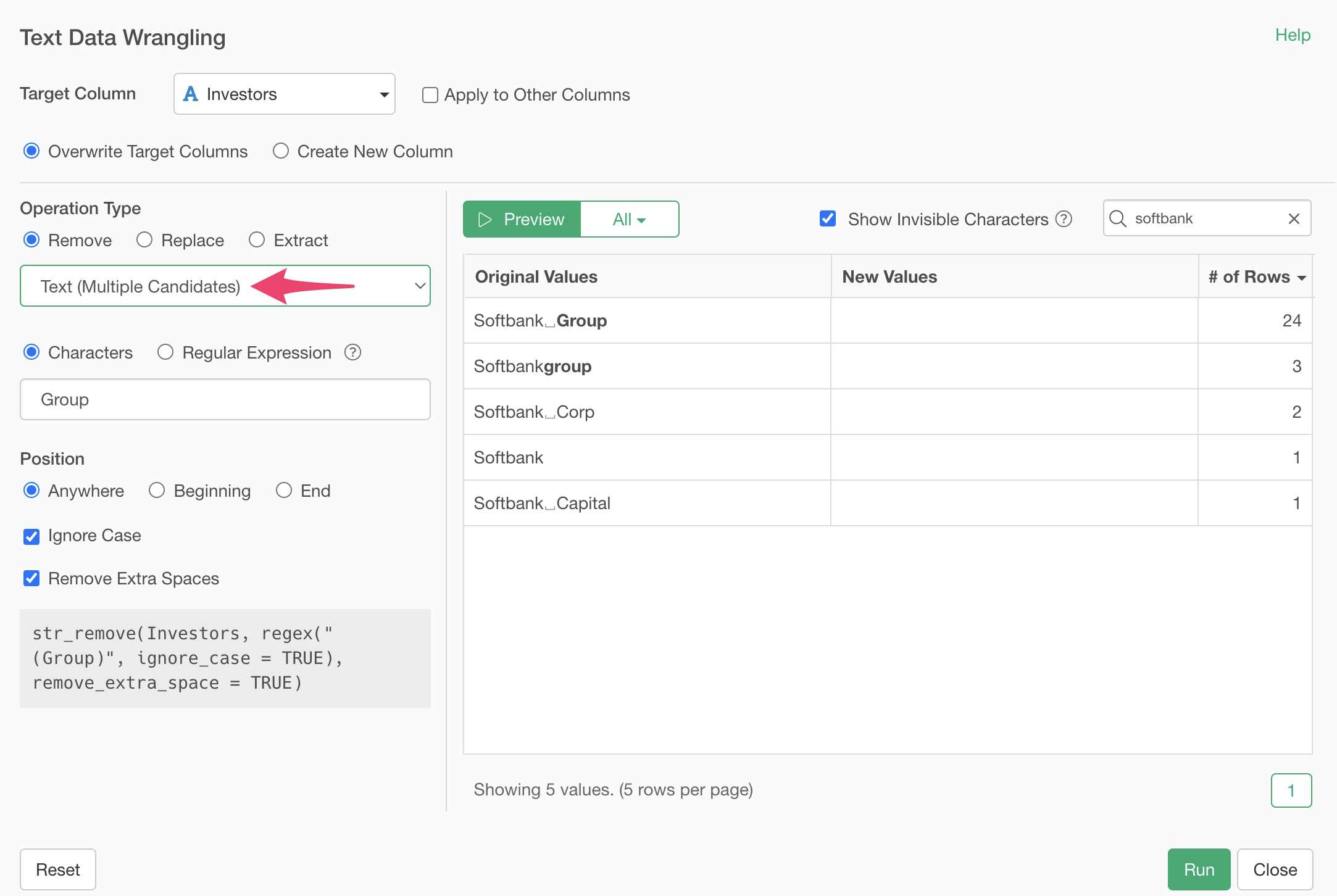
Select “String (multiple candidates)” as the type.
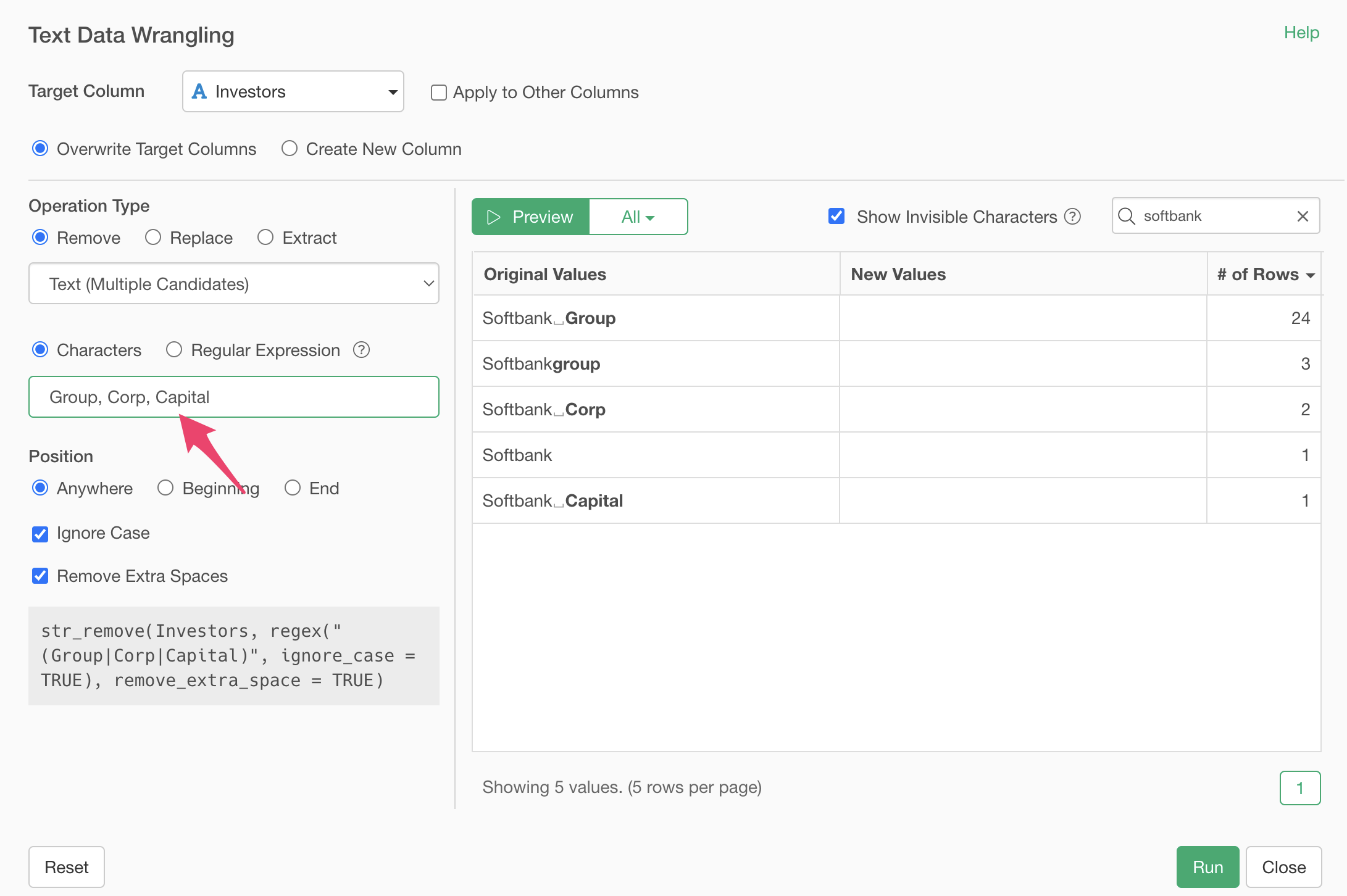
In the text field, specify multiple strings to remove, separated by commas, like “Group, Corp, Capital”.
Clicking the preview button shows that we’ve successfully cleaned up the values to “Softbank”.
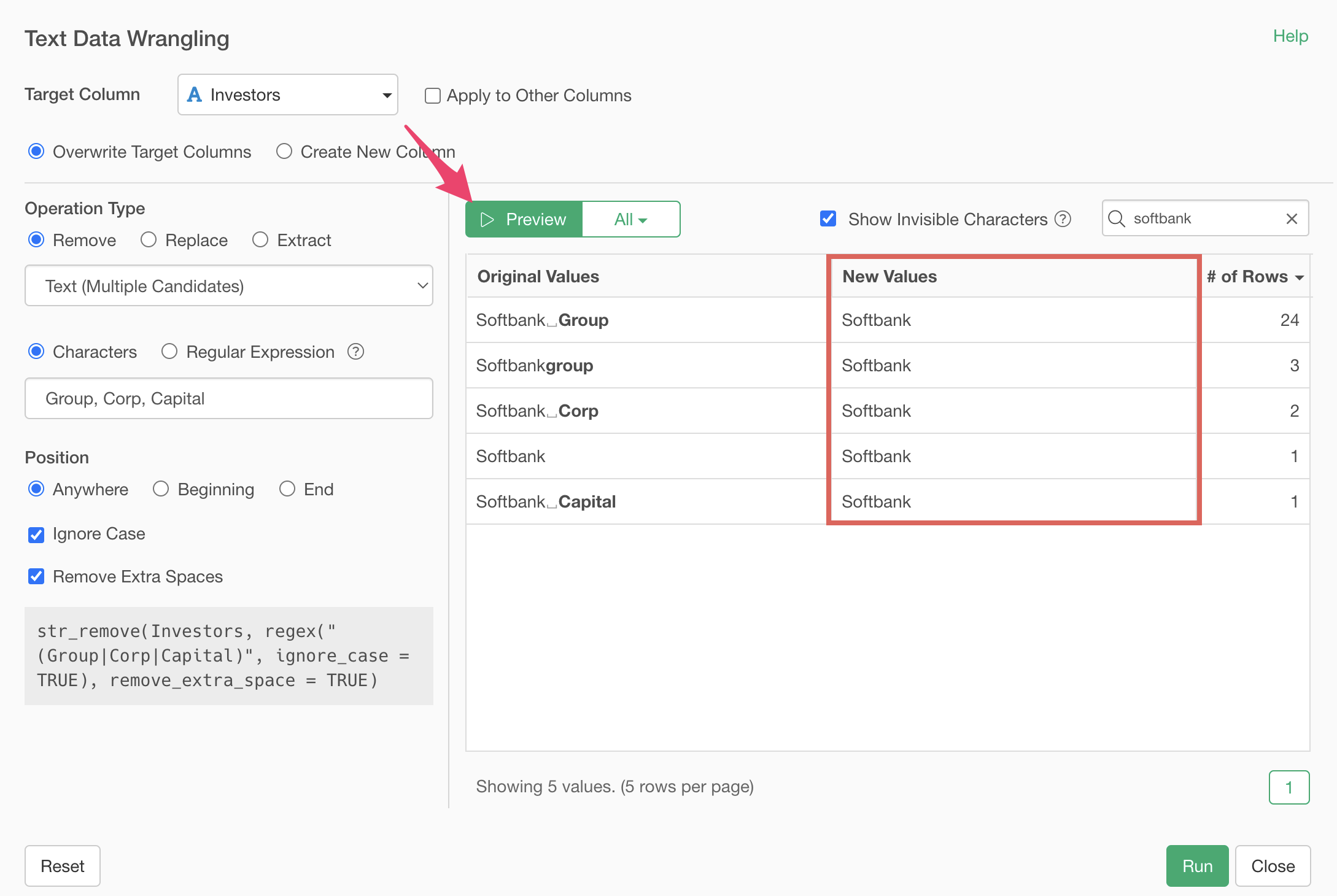
By executing, we’ve removed strings like “Group” and “Corp”, cleaning them up to “Softbank”.
2. Replace
In this part, we’ll use the copier order data. Each row represents one order, with rows separated by product.
 The
data is filtered to the “Copier” product subcategory, as if you were a
copier sales representative.
The
data is filtered to the “Copier” product subcategory, as if you were a
copier sales representative.
Looking at the product name column, we can see that Hewlett Packard products have inconsistent notations like “HP” and “Hewlett”.
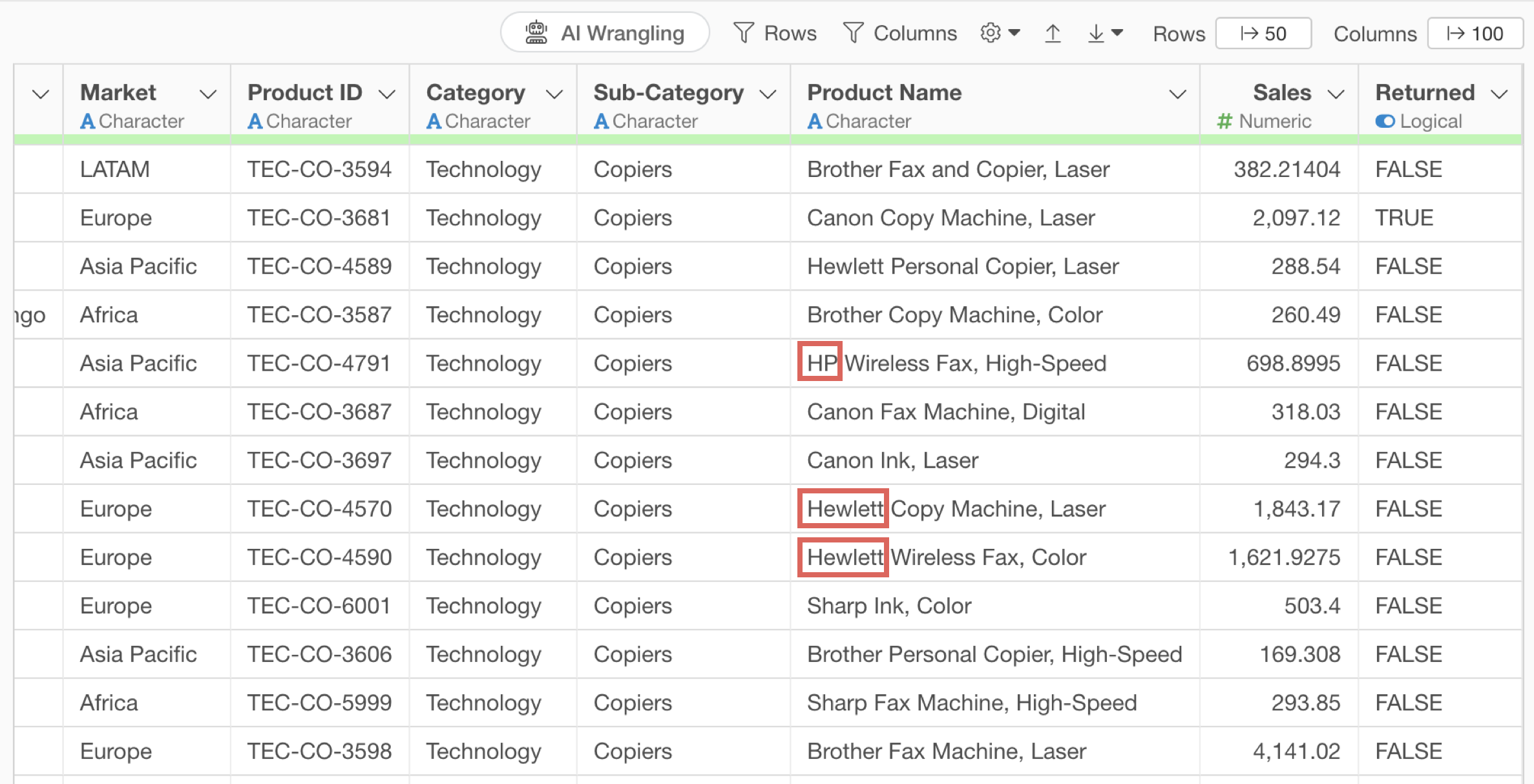
We want to replace strings like “Hewlett” in the product name with “HP”.
From the column header menu, select “Text Data Processing” > “Replace” > “String”.
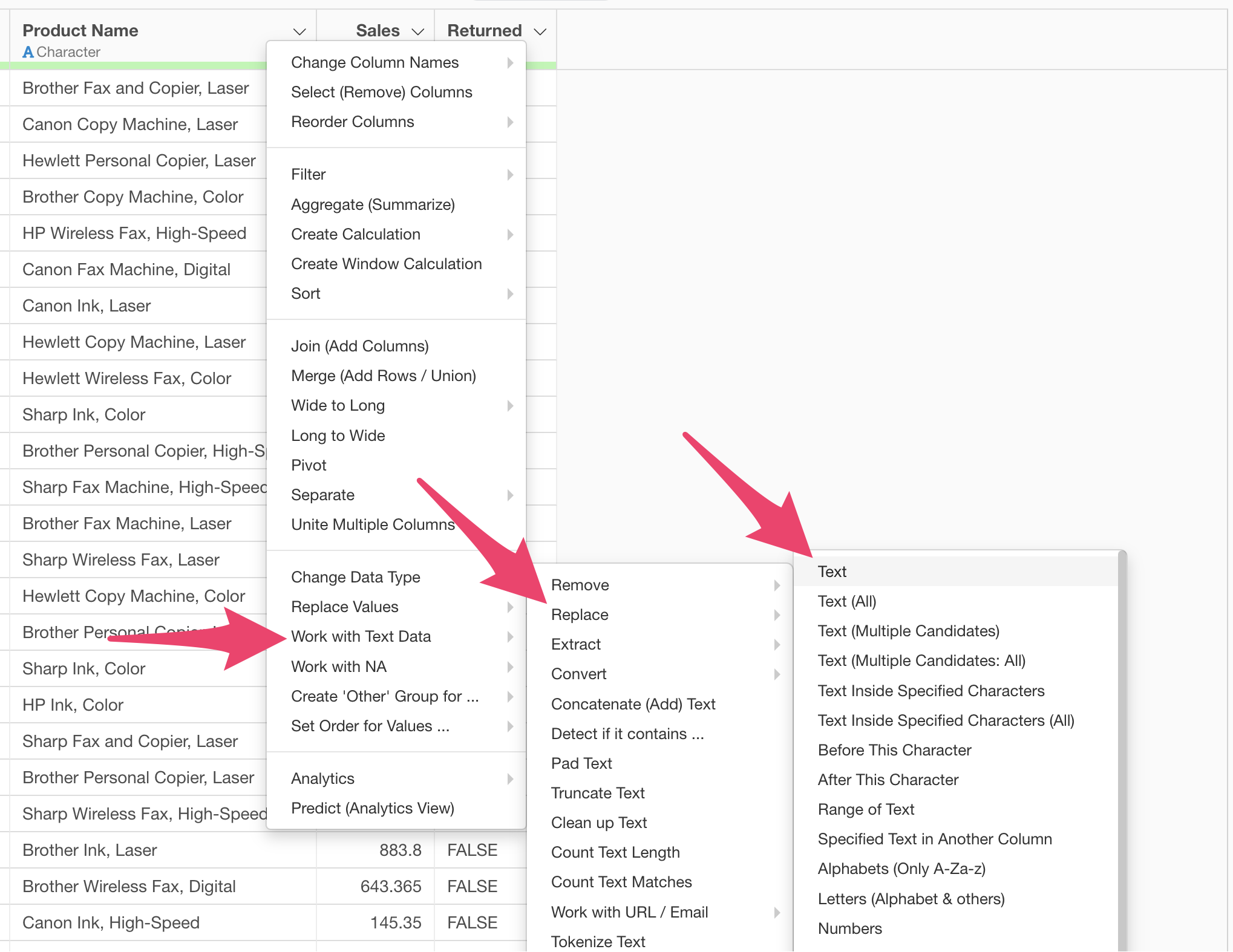
The text data wrangling dialog appears.
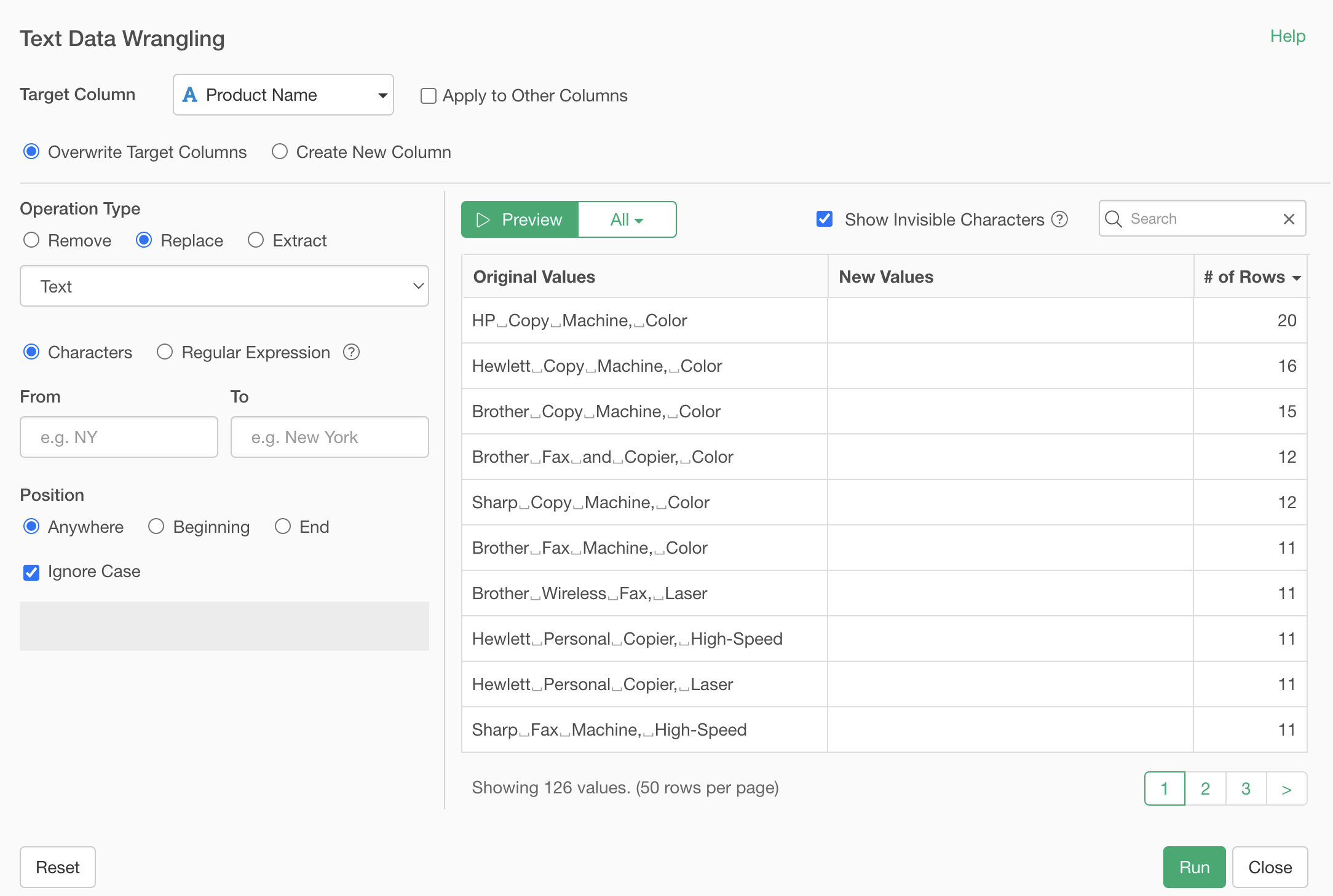
By specifying “Hewlett” in the search box, only values containing “Hewlett” are displayed.
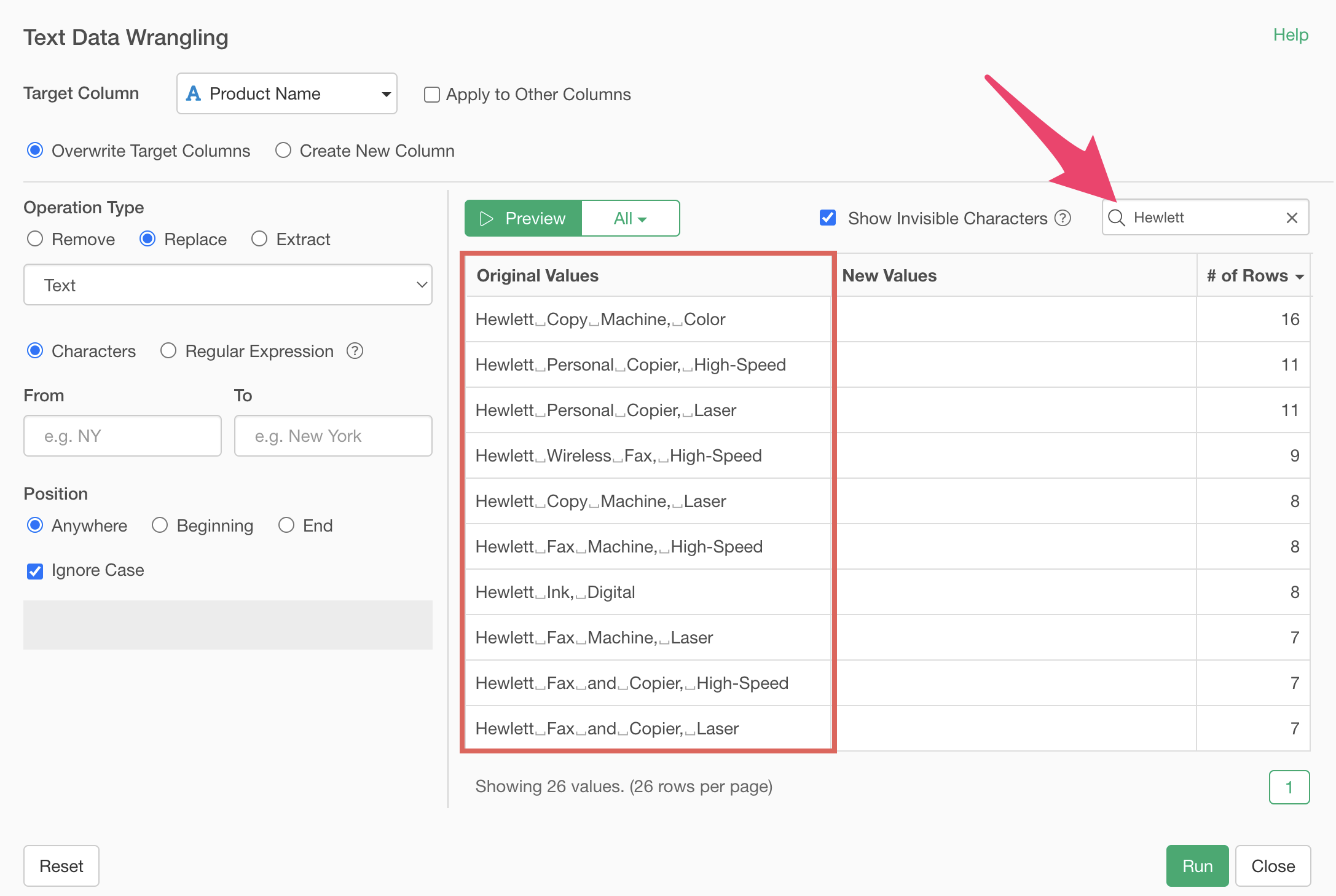
Specify “Hewlett” as the source text and “HP” as the target text. This highlights the “Hewlett” text in the original values in bold.
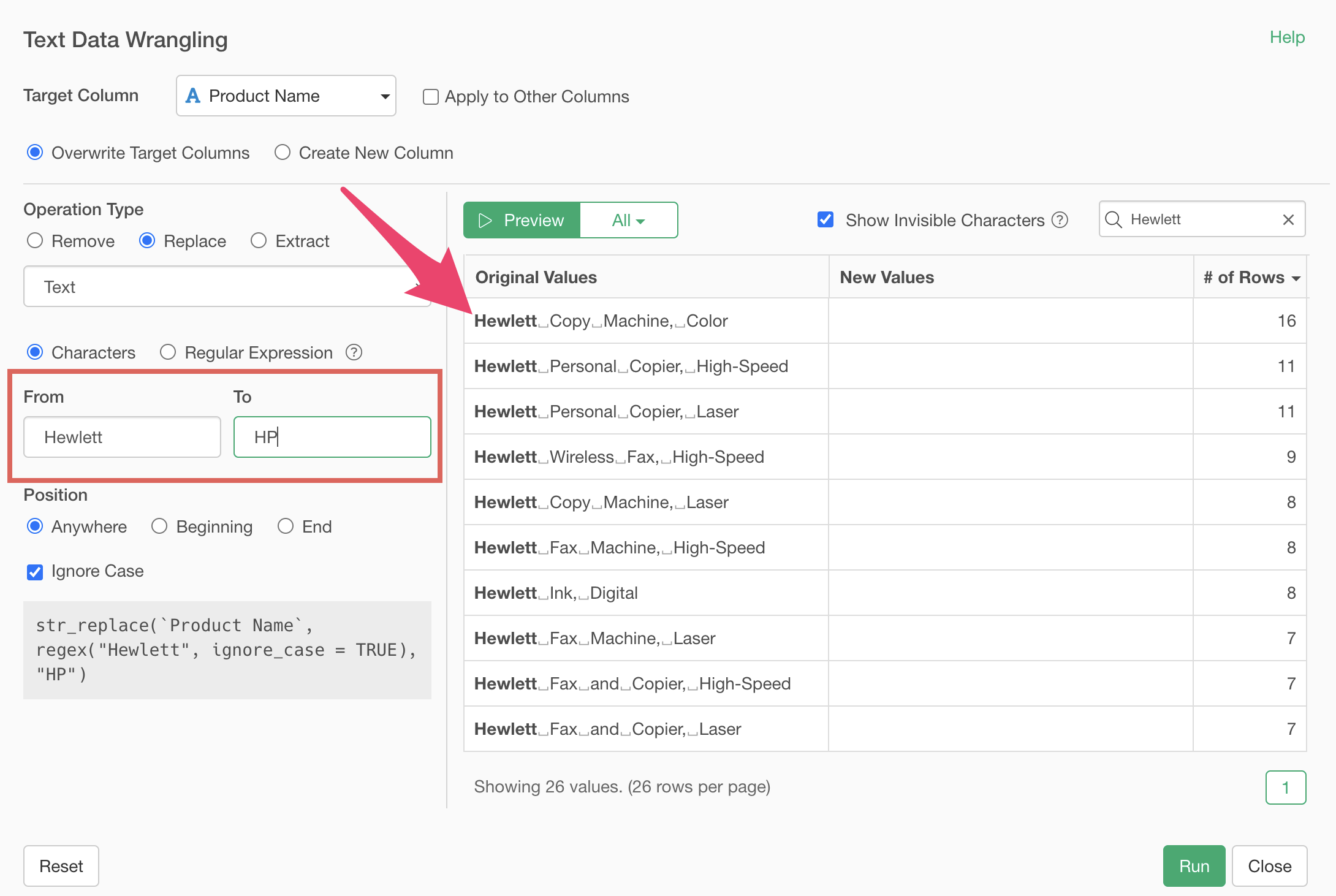
Clicking the preview button shows that “Hewlett” has been replaced with “HP”.
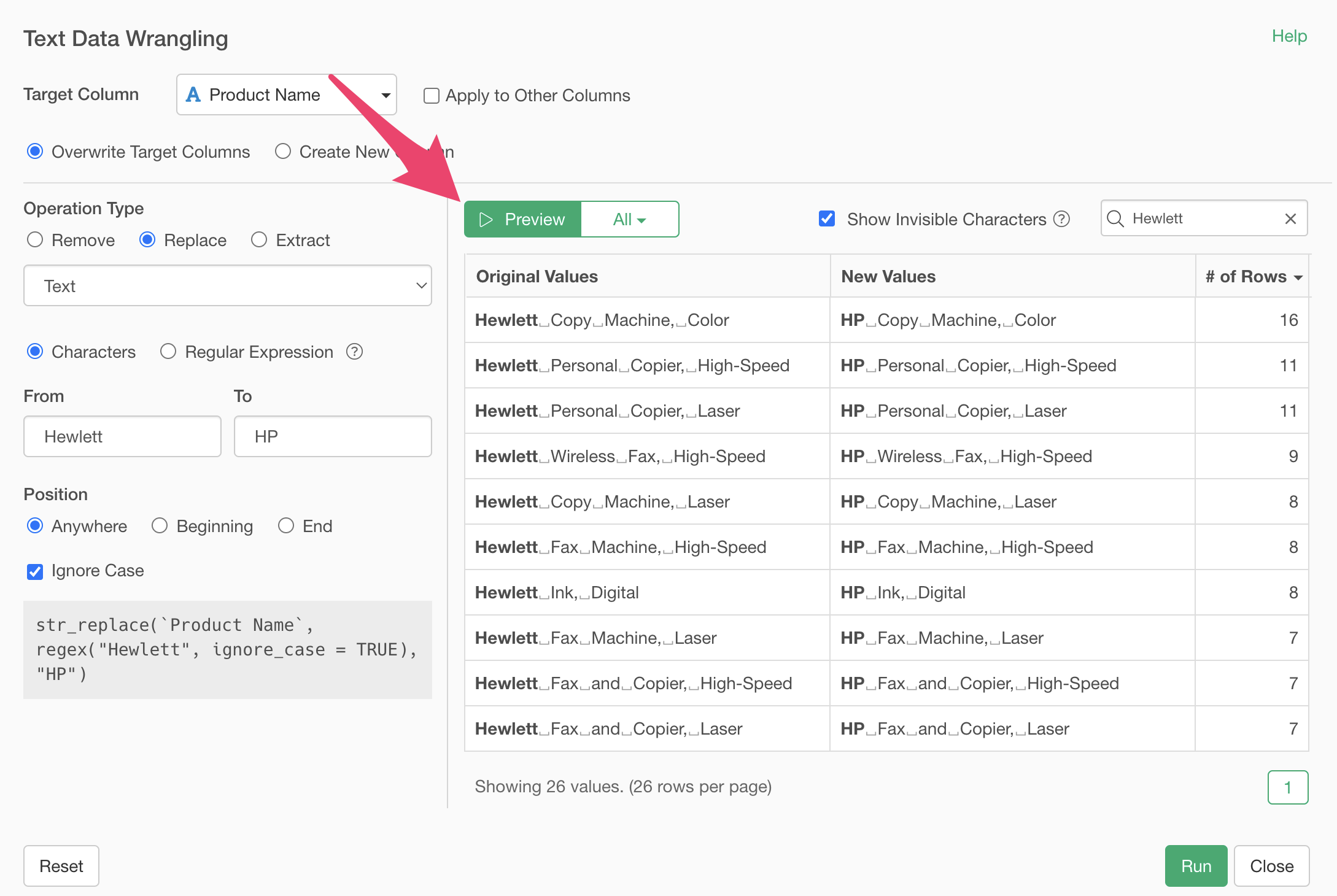
We’ve replaced “Hewlett” with “HP”, but we also see strings like “Hewlett Packard”. We want to replace both “Hewlett Packard” and “Hewlett” with “HP” simultaneously.
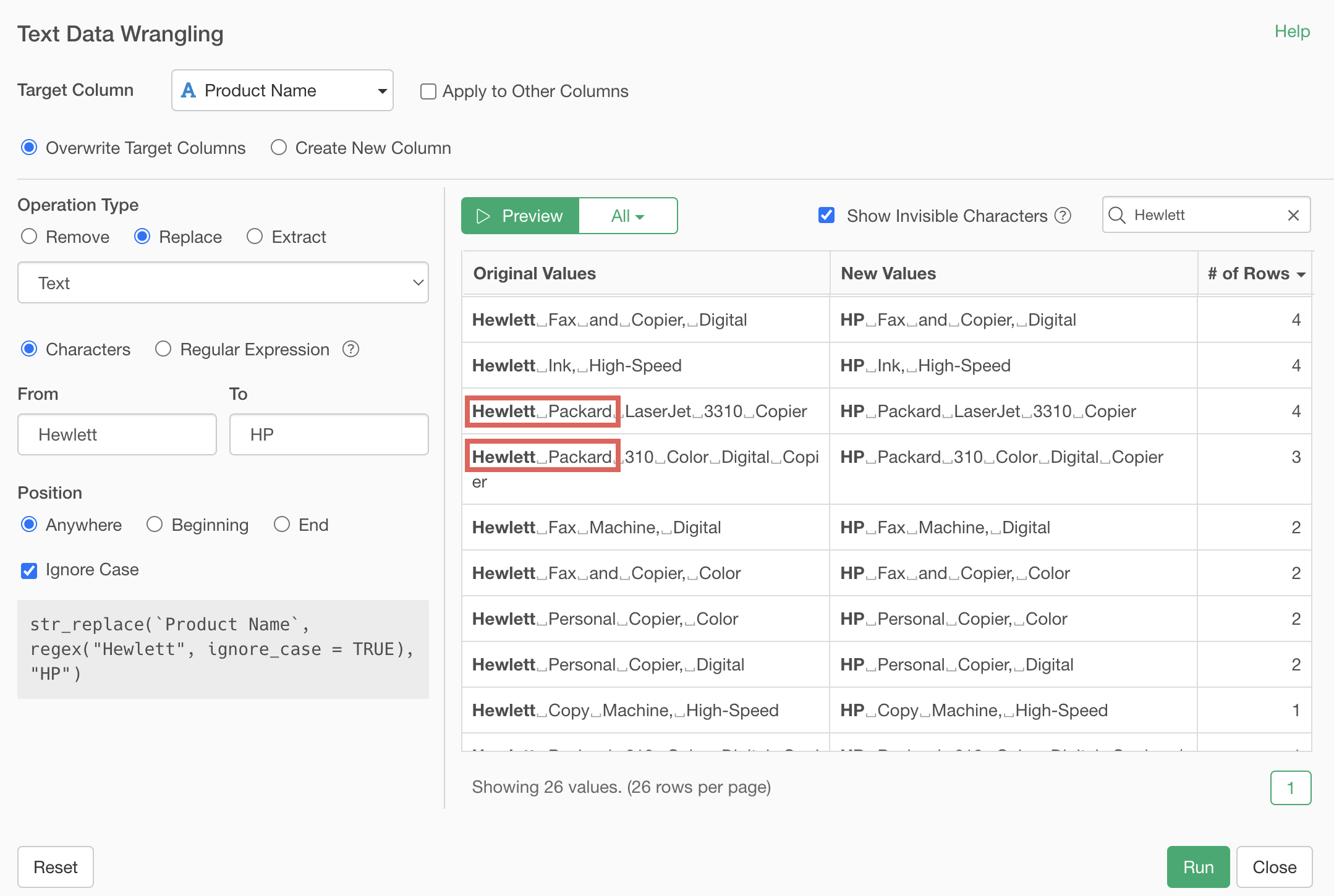
Select “String (multiple candidates)” as the type.
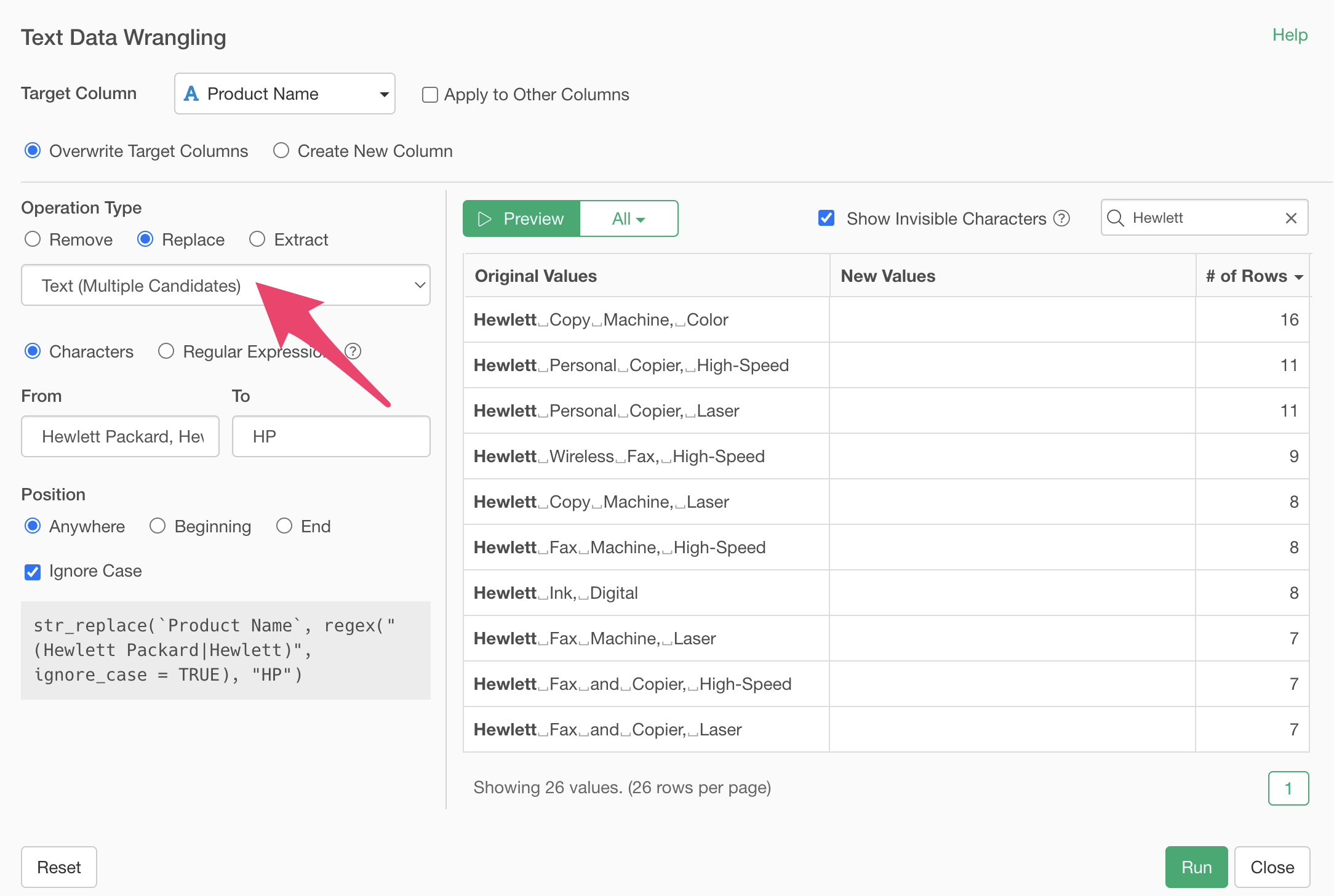
In the text field, specify multiple strings to replace, separated by commas, like “Hewlett Packard, Hewlett”.
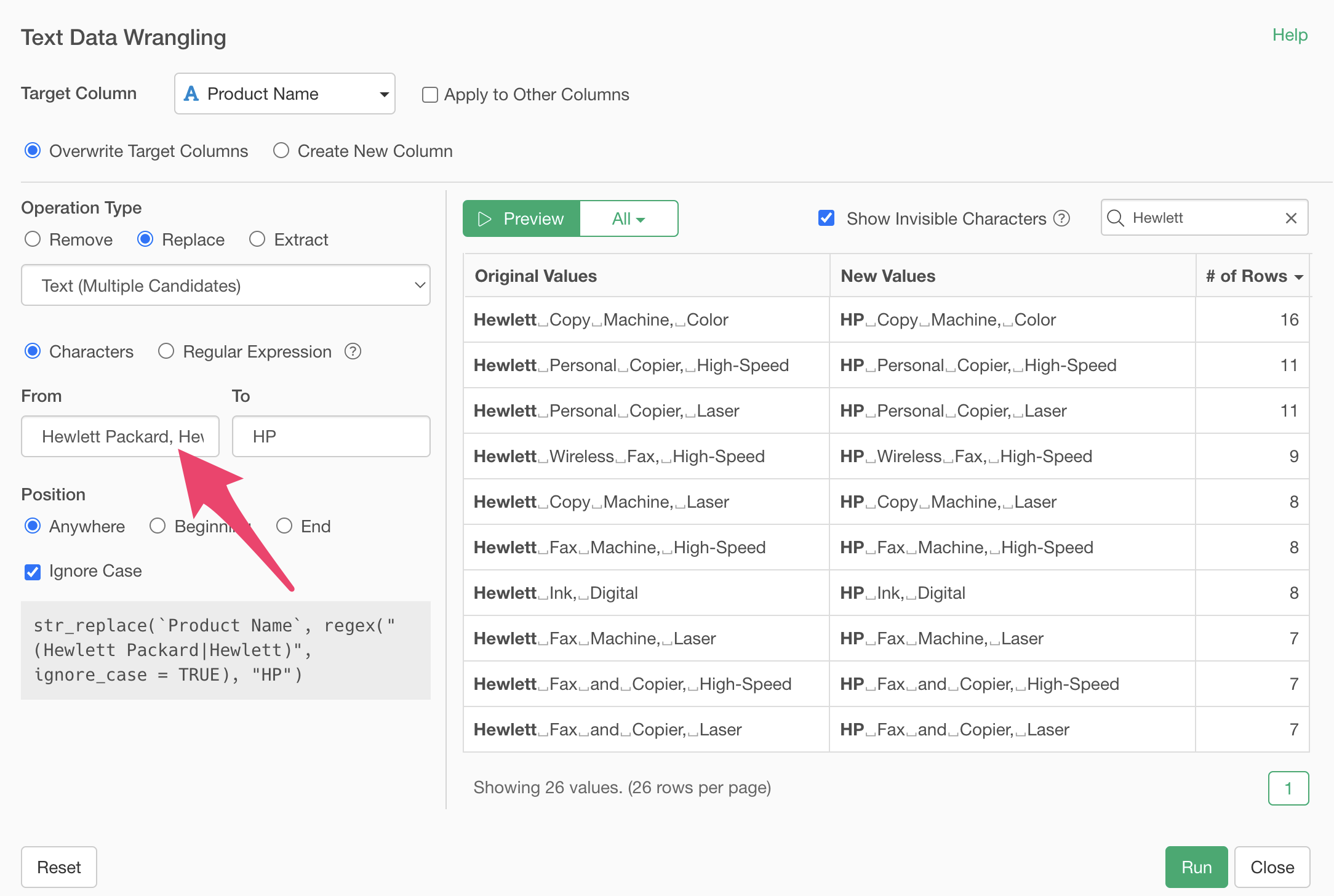
Clicking the preview button shows that we’ve successfully replaced “Hewlett Packard” and “Hewlett” with “HP”.
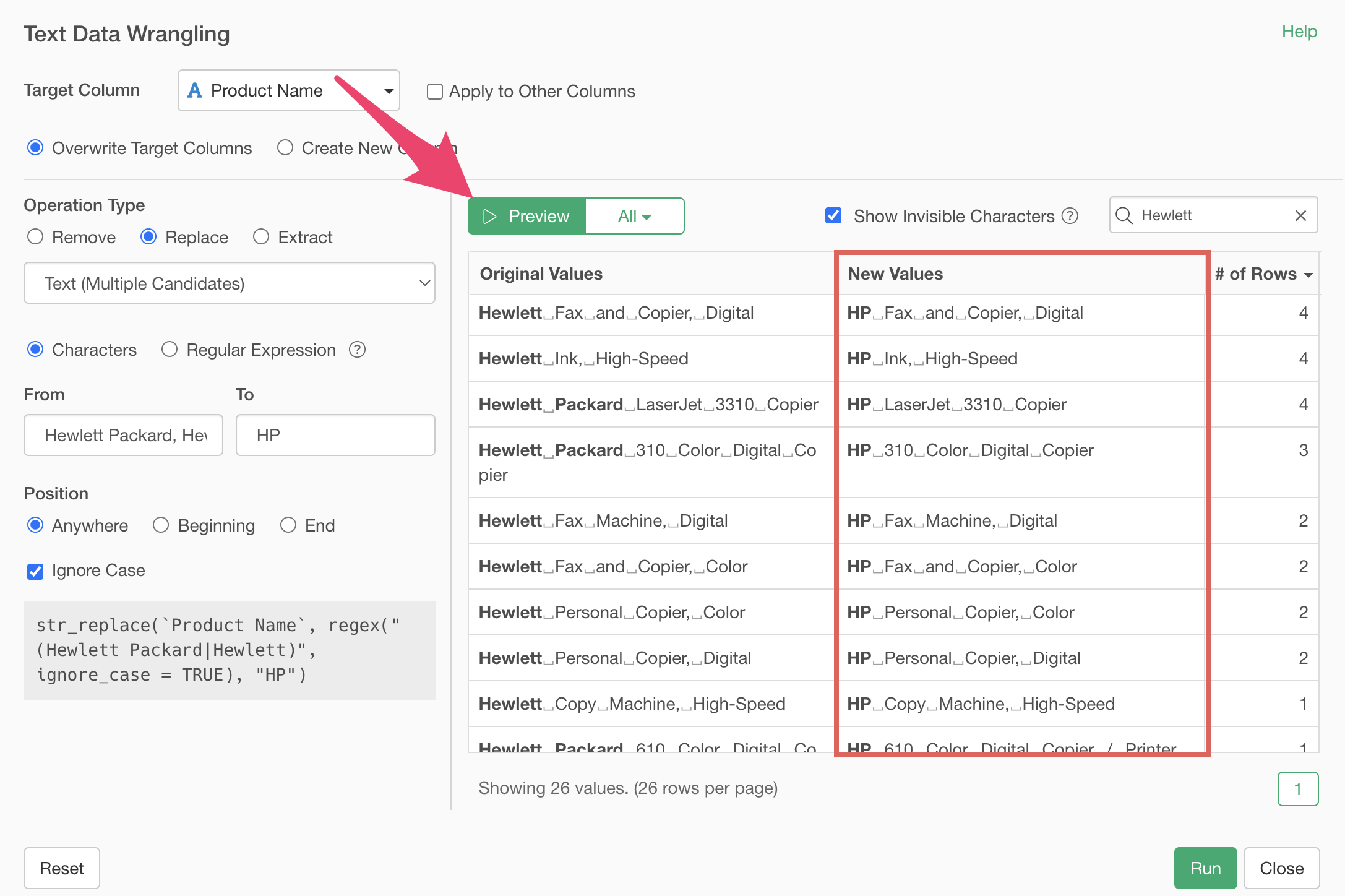
By executing, we’ve replaced “Hewlett Packard” and “Hewlett” with “HP”, standardizing the previously inconsistent strings.
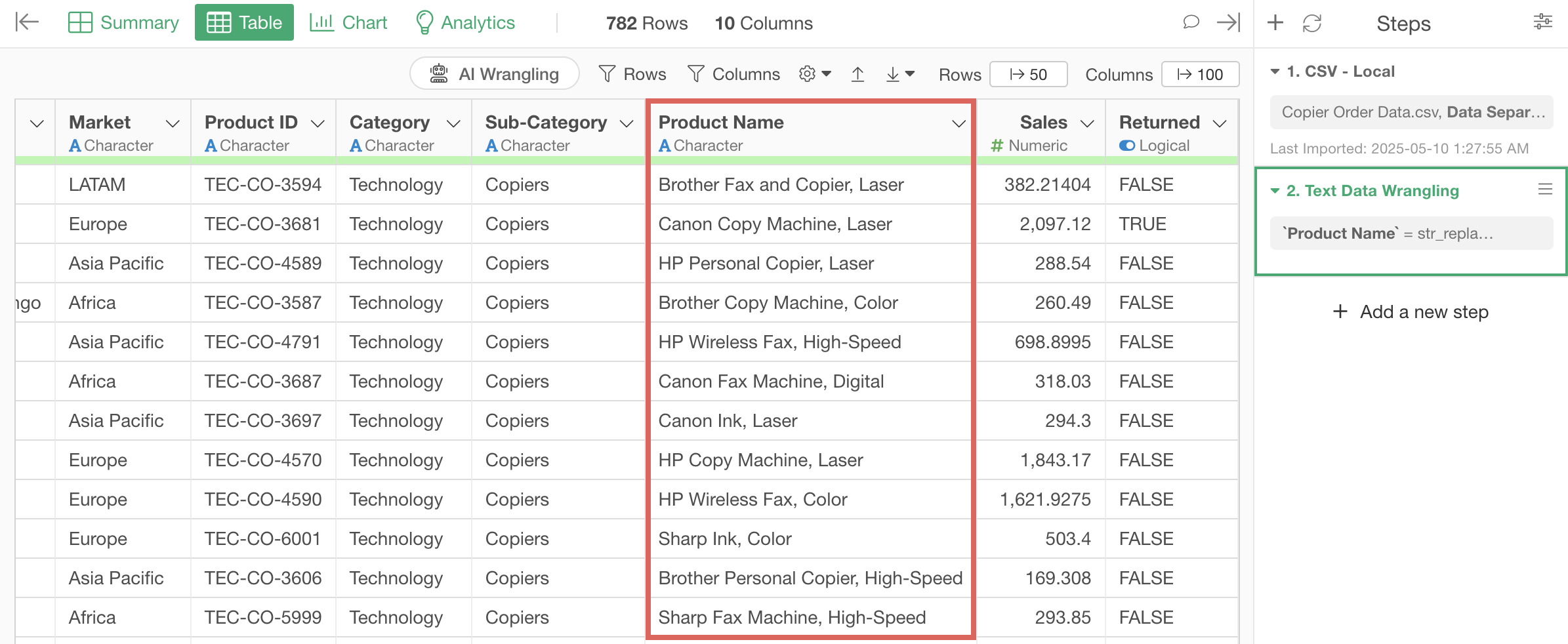
3. Extract
We’ll use the same “Copier Order Data” as in the previous part.
Previously, we replaced “Hewlett Packard” and “Hewlett” with “HP”, but now we want to extract the brand name from the “Product Name” column and create it as a new column.
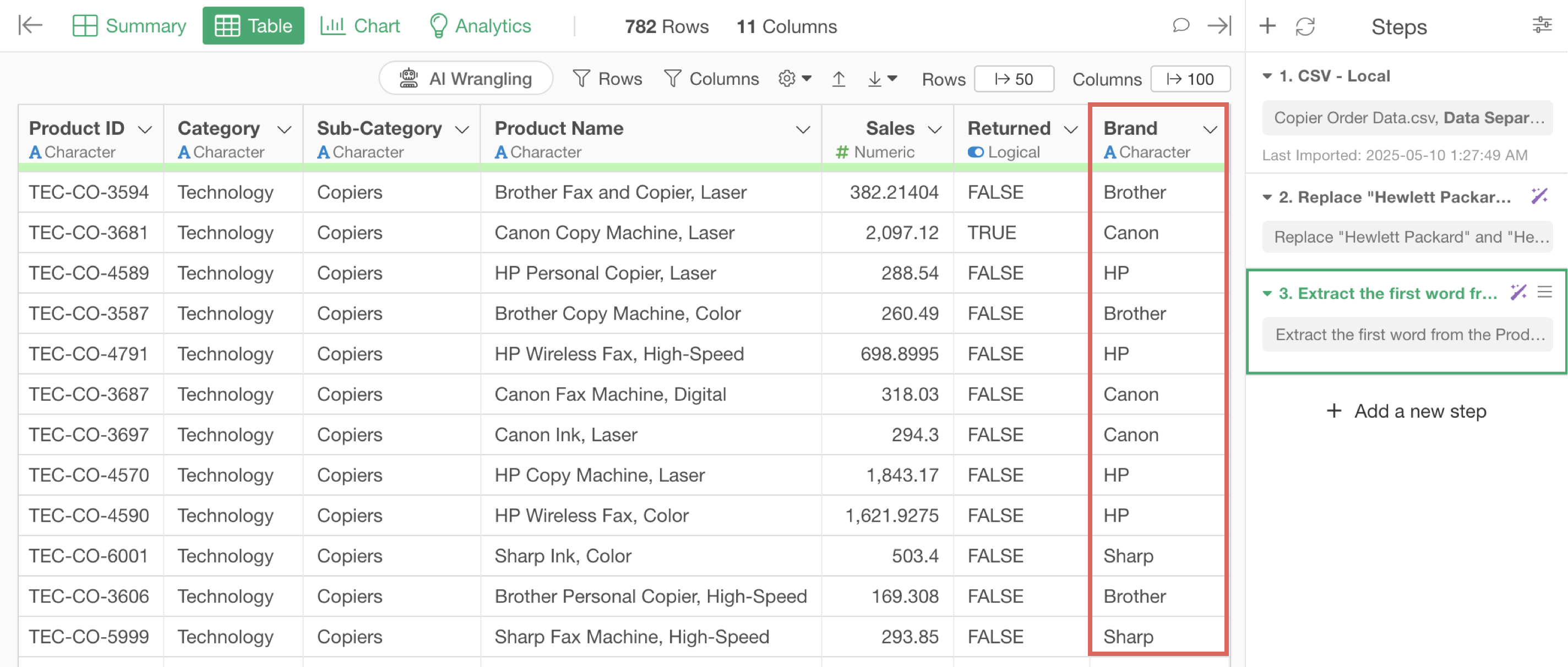
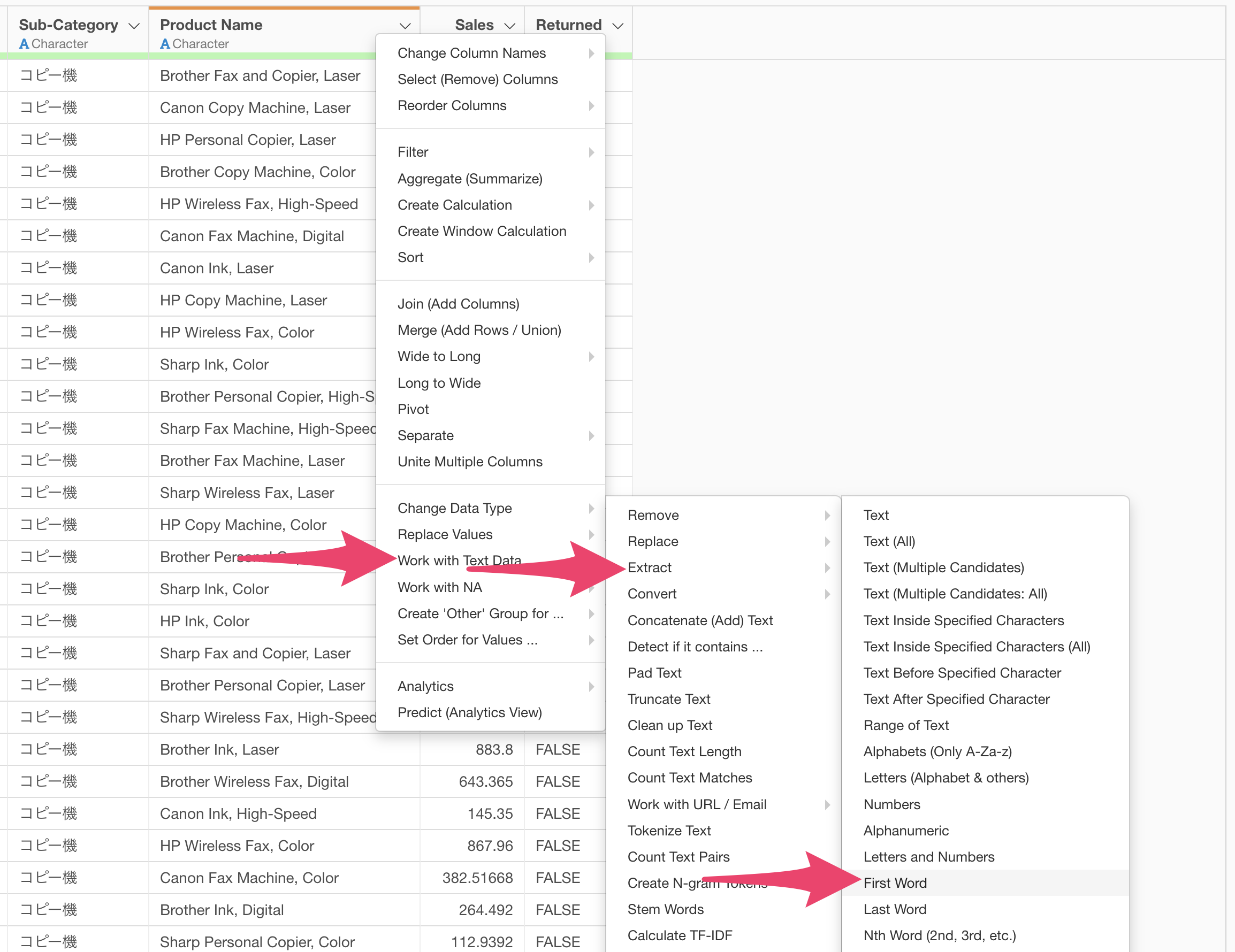
From the product name column, select “Text Data Processing” > “Extract” > “First Word”.
Select “First Word” as the word type to extract and “Space ( )” as the delimiter.
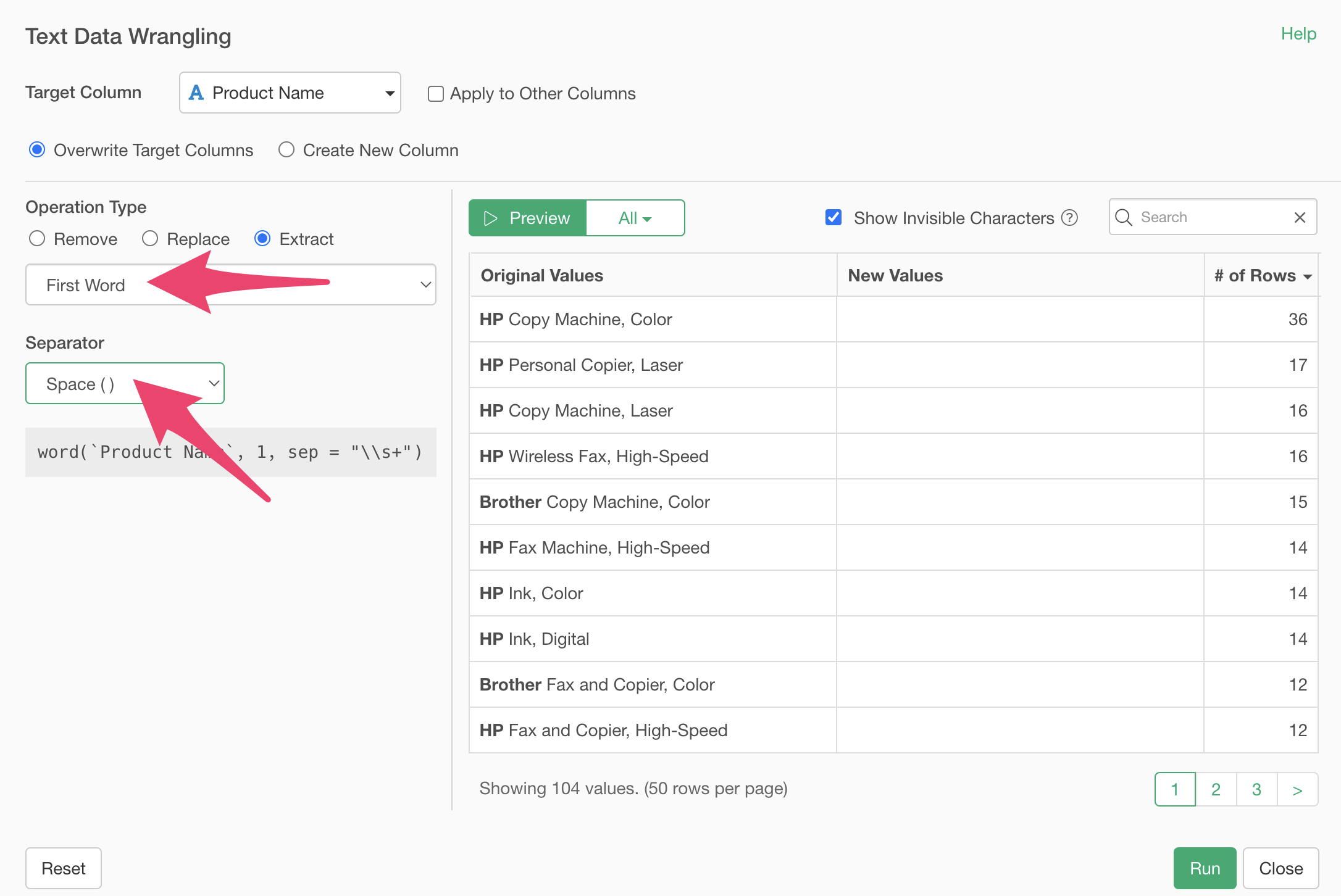
Running the preview confirms that we’ve successfully extracted the brand name from the first word.
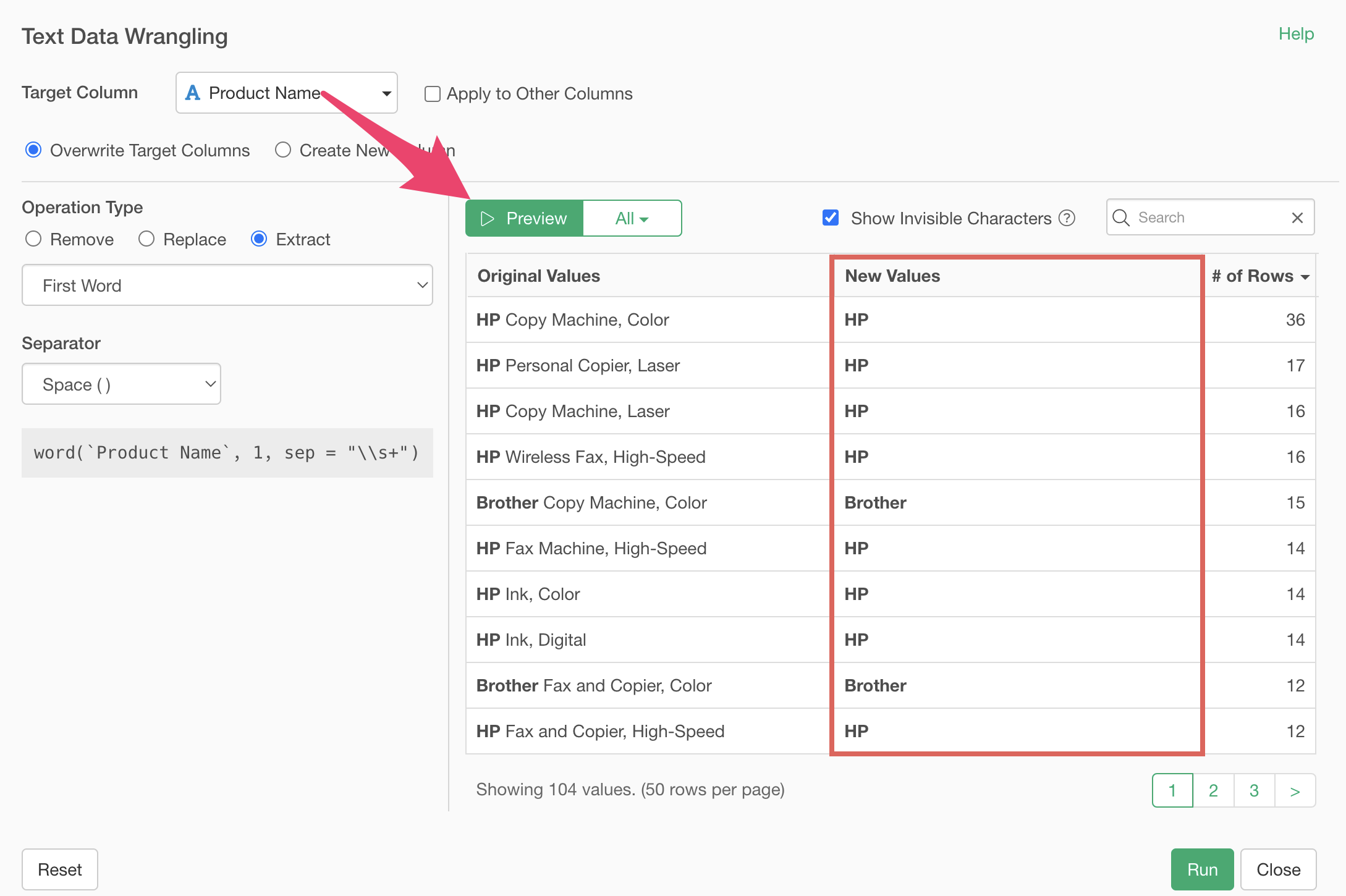
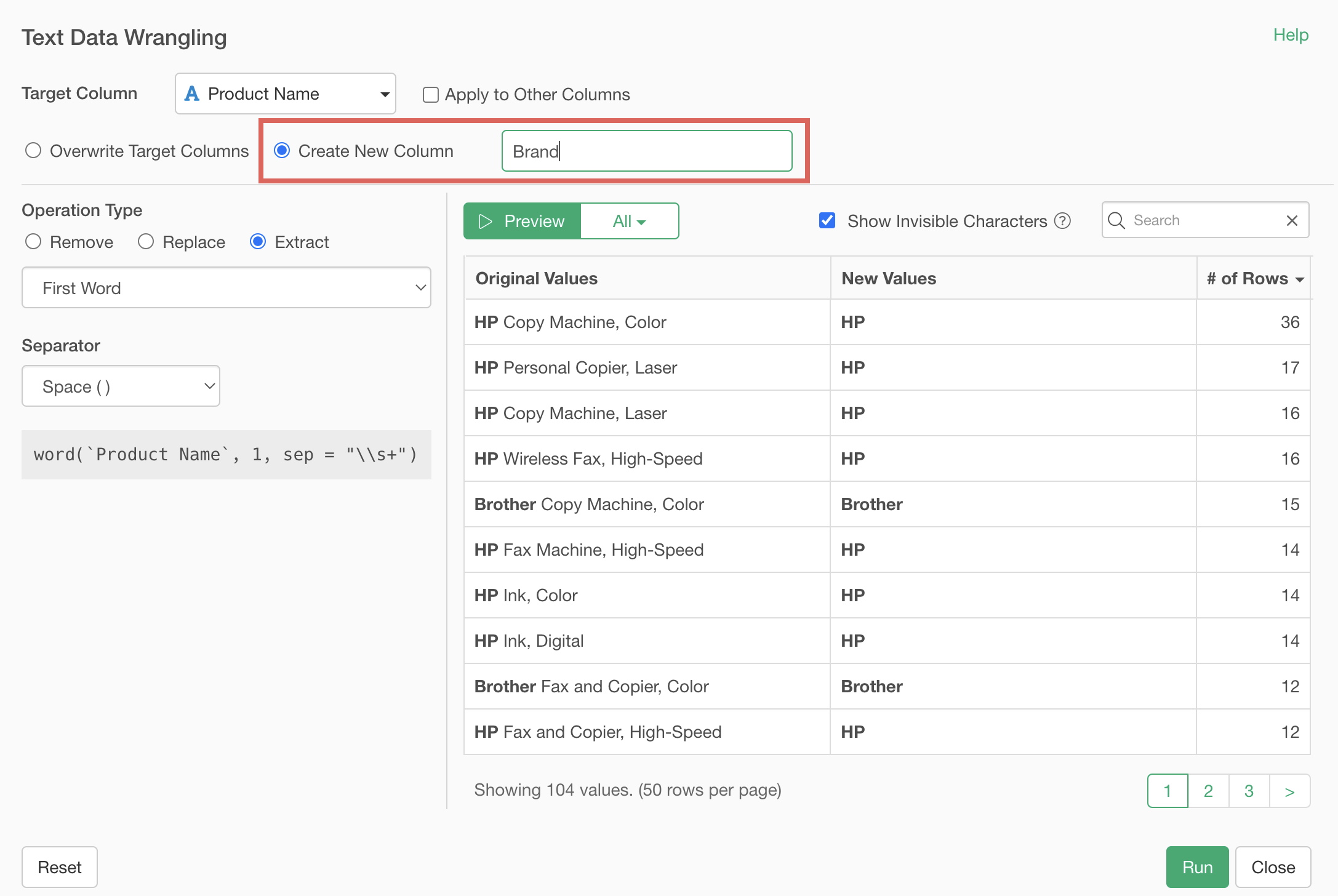
Check “Create as new column”, specify the column name, and click the “Run” button.
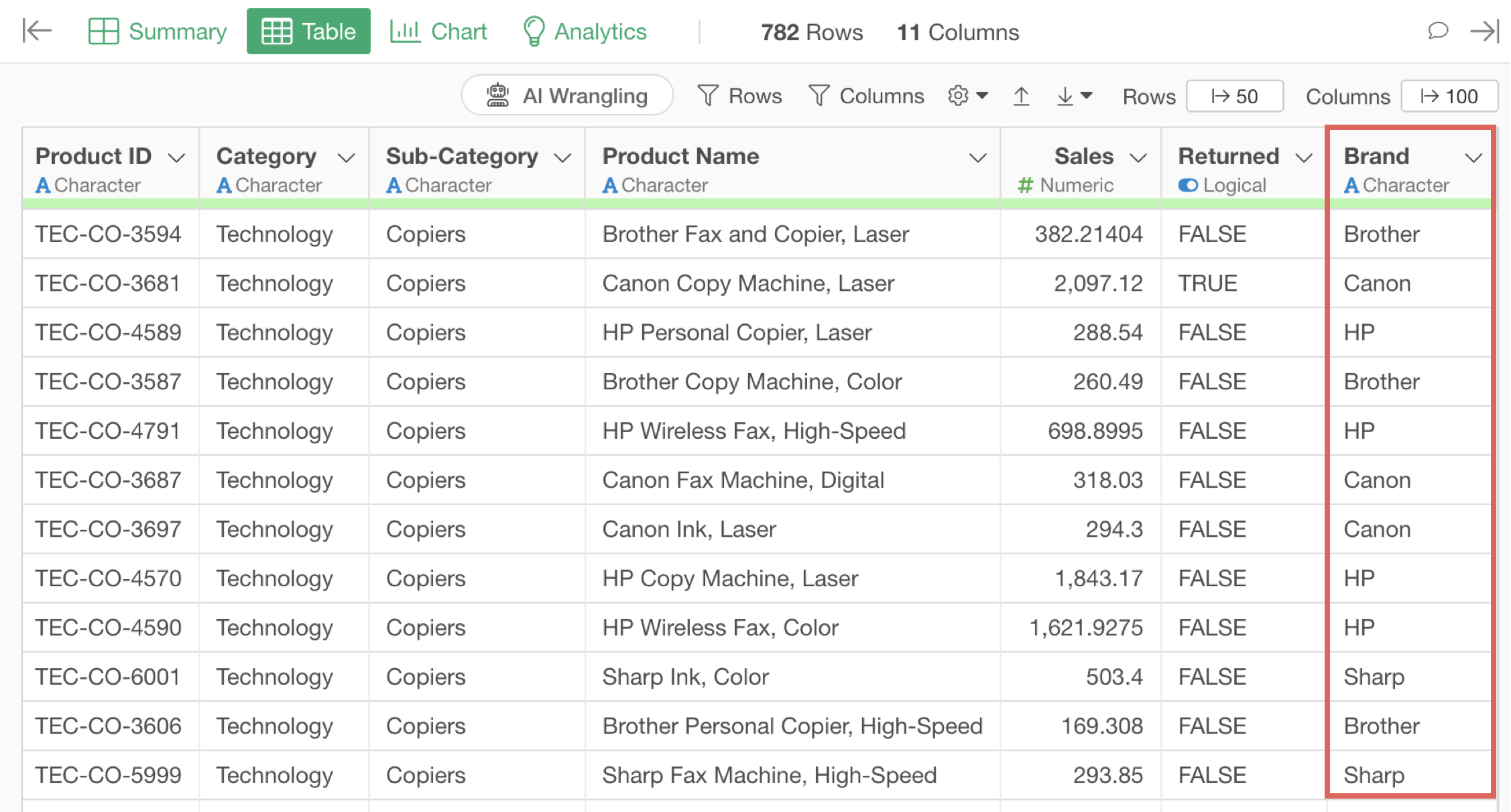
We’ve successfully created a “Brand” column by extracting the brand name from the product name.
This concludes the text data processing edition of the data wrangling trial tour!
Data Wrangling - Trial Tour
You can check other parts of the data wrangling trial tour from the links below. Please try the next part, “Data Structures”, as well.