マーケティング領域におけるExploratoryの活用 Part 3 - ANCOVA(共分散分析)
このノートは、マーケティング領域でExploratoryを効率的に使い始めることができるように作られた「マーケティング領域におけるExploratoryの活用」の第3弾、「ANCOVA(共分散分析)」編です。
データをインポートする
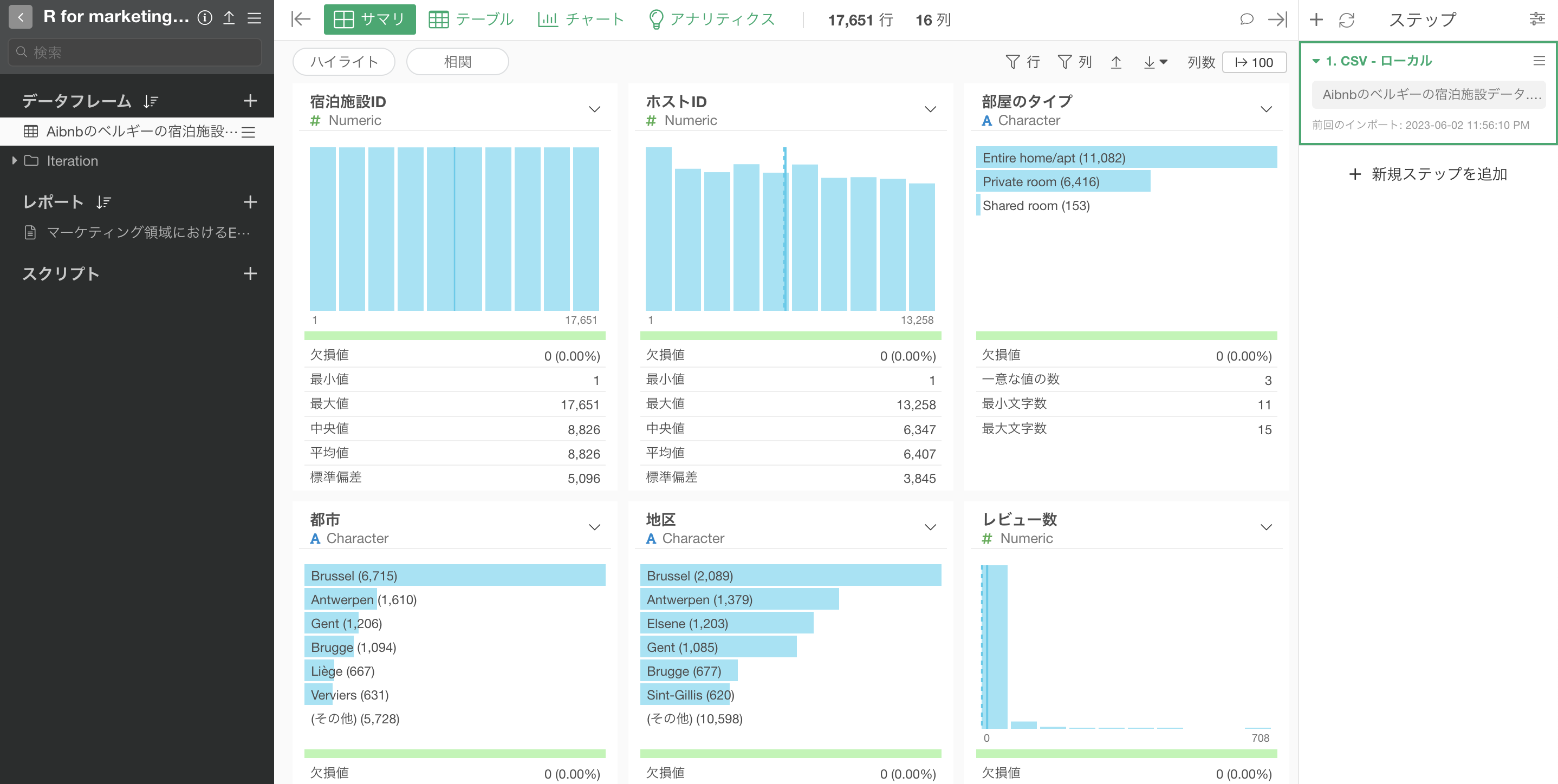
今回はサンプルデータとして「Airbnbのベルギーの宿泊施設」のデータを使用します。このデータは1行が1物件になっており、それぞれの物件に関する価格や広さなどの情報が列として入っています。
データはこちらのページからダウンロードできます。Macをお使いの方は「CSV-UTF8」を、Windowsをお使いの方は「CSV - Shift-JIS」をダウンロードしてください。
Airbnbのデータをダウンロードできたら、ダウンロードしたフォルダを開き、「Airbnbのベルギーの宿泊施設データ.csv」をExploratoryの画面にドラッグ&ドロップします。
インポートダイアログが表示されました。インポートダイアログの左側にある項目から、インポート時の設定を行うことが可能ですが、今回は設定は不要なため「インポート」ボタンをクリックします。
任意のデータフレーム名を指定して、「作成」ボタンをクリックします。
Airbnbのデータをインポートすることができました。
ANCOVA(共分散分析)
前回の第二弾では、3つ以上のグループ間で平均値に有意な差があるかを検定することが可能なANOVA(分散分析)を使って、部屋のタイプごとに、一泊の価格の平均値に差があるのかを調べました。
その結果、「一軒家/アパート一棟貸しと個室の一泊の価格には有意な差がある」こと、「一軒家/アパート一棟貸しと相部屋の一泊の価格には有意な差がある」ことや、わかりました。
しかし、本当に部屋のタイプごとに、一泊の価格の平均値に差があると言えるのでしょうか。
例えば今回のデータには「総合満足度」という列がありますが、特定の部屋のタイプの総合満足度が高く、その影響がANOVA(分散分析)の結果に出ているのかもしれません。
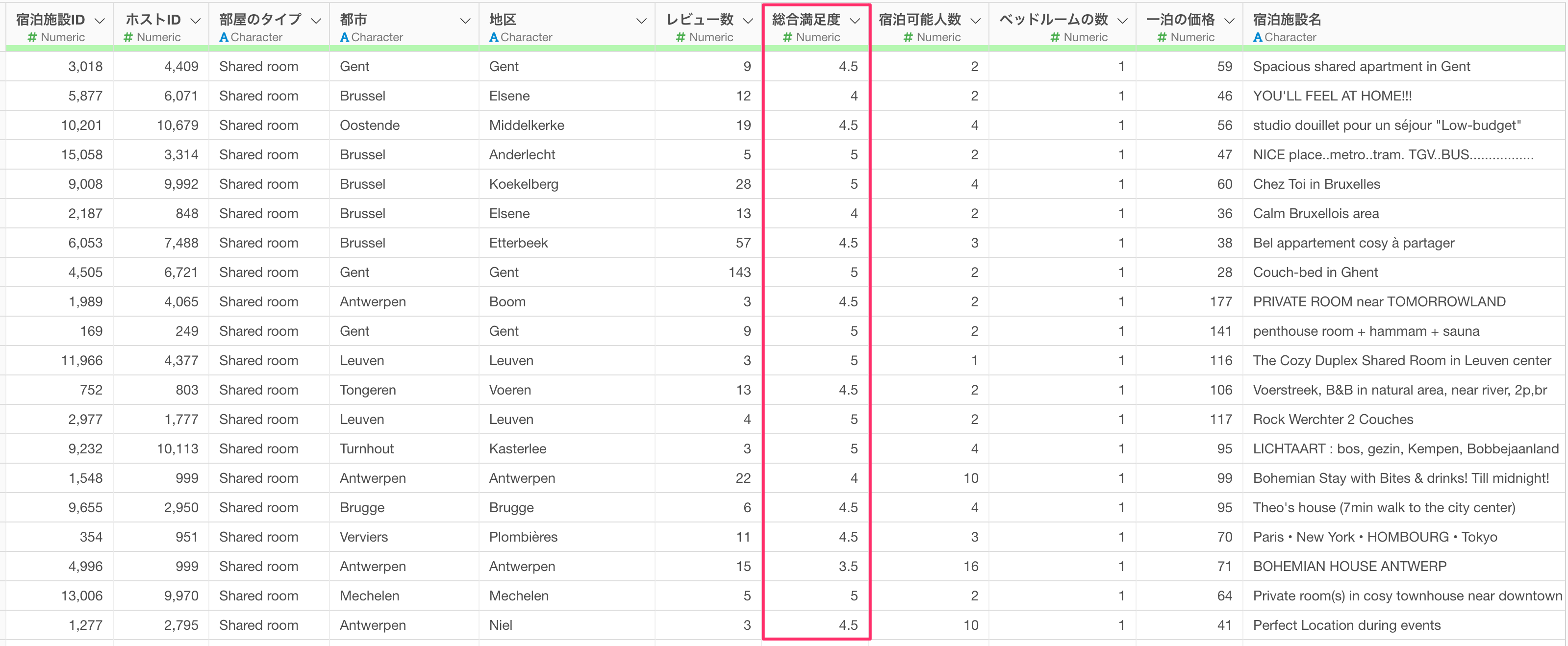
そういったときにはANCOVA(共分散分析)を実行することで、選択した説明変数に影響を与える他のデータ(共変量)の影響を取り除いた差を検定することが可能です。
ANCOVA(分散分析) の前提
ところで、マーケティング領域におけるExploratoryの活用 Part 2の One-Way ANOVA(分散分析)でも紹介しましたが、分散分析は以下の二点を前提としていることを忘れないでください。
目的変数の正規性(正規分布していること) 目的変数の分散の均質性(目的変数が大きくなるにつれて分散が大きくなるような傾向がないこと) なお、両者を個別に検定することも可能ですが、Exploratoryで分散分析を行った際には両者の検定も自動で行いますので、今回は個別に決定を実施し両者を確かめることは行わず、Two-Way ANOVA(分散分析)を実施していきます。
結果の解釈
それでは、いよいよANCOVA(共分散分析)を実行していきます。
アナリティクス・ビューに移動し、「統計的検定」から「ANCOVA(共分散分析)」を選択します。
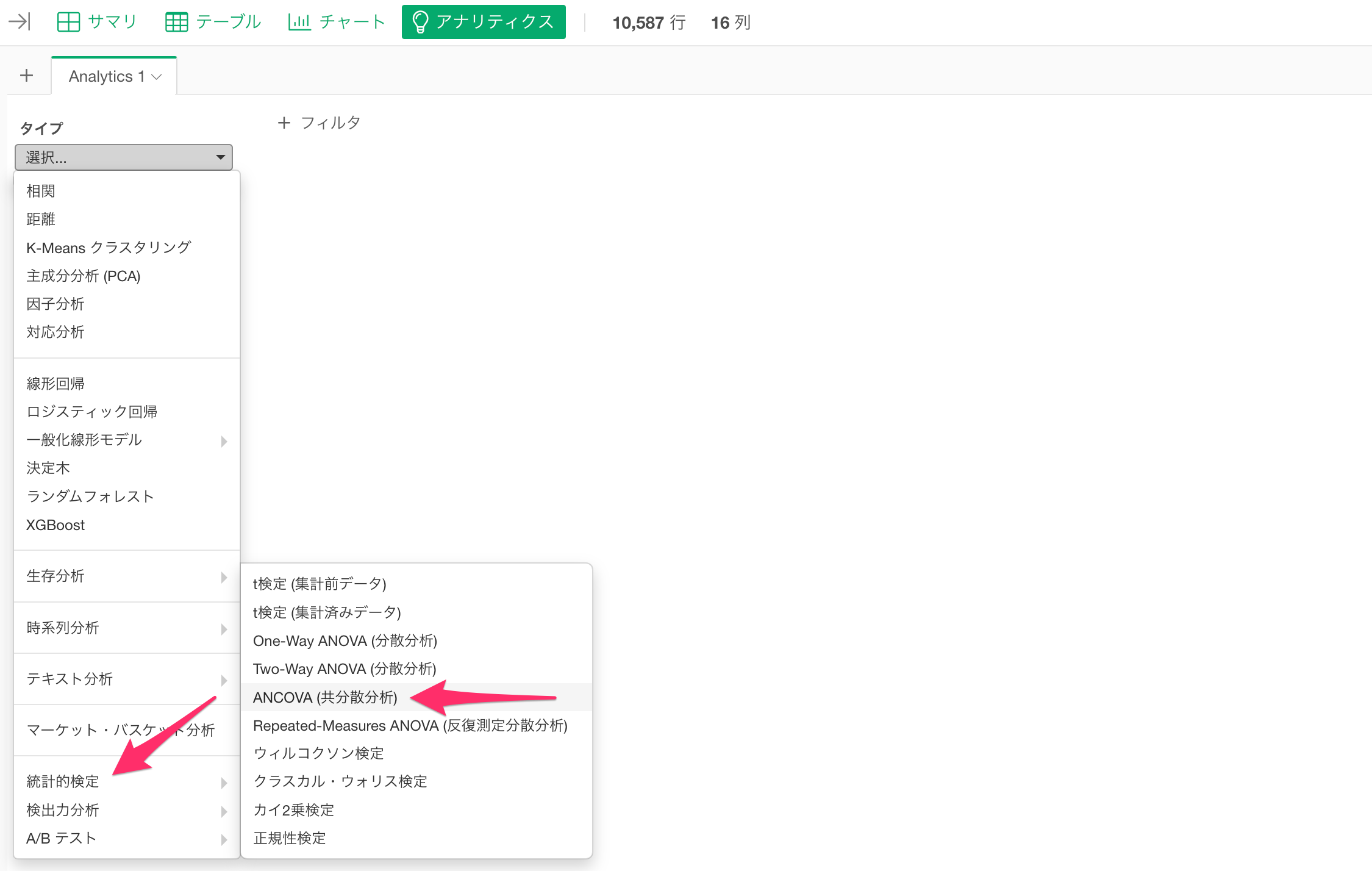
続いて、目的変数に「一泊の価格」、説明変数に「部屋のタイプ」、共変数に「総合満足度」を選択し実行します。

ANCOVA(共分散分析)の結果が表示されます。
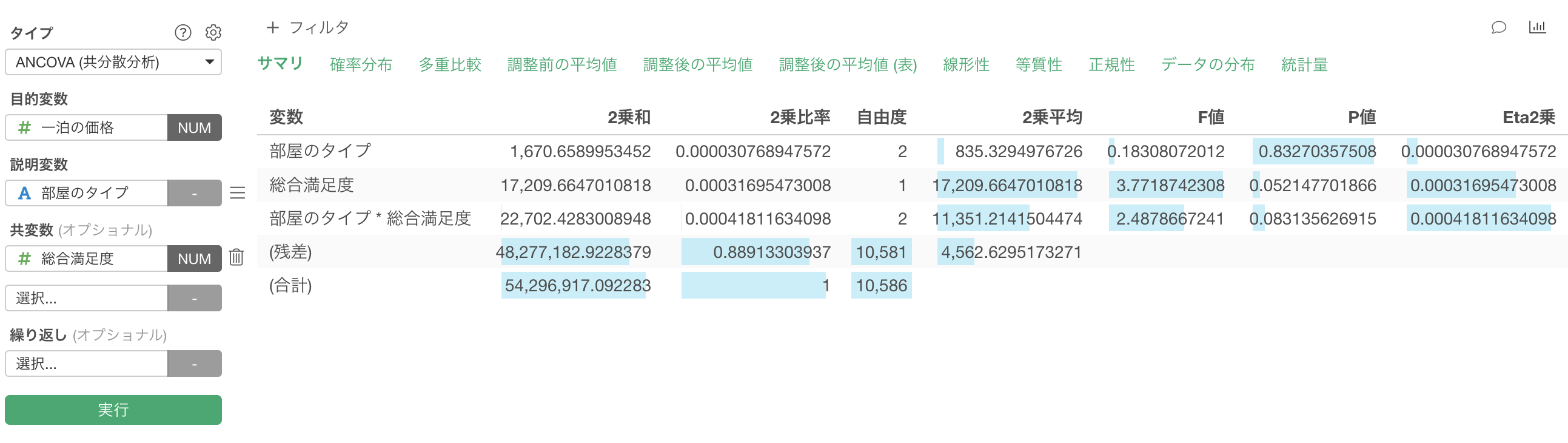
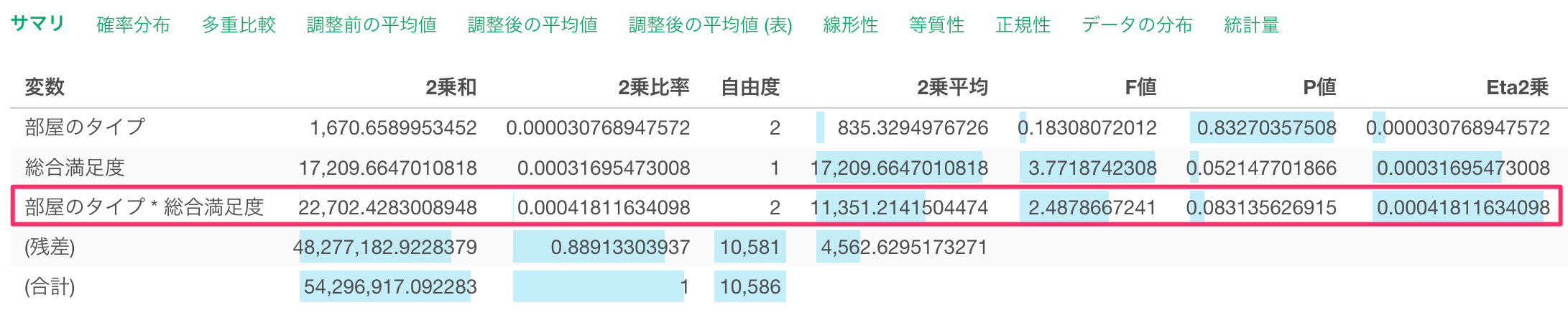
サマリ
「サマリ」タブでは、ANCOVA(分析)の結果が有意かどうかを確認できます。
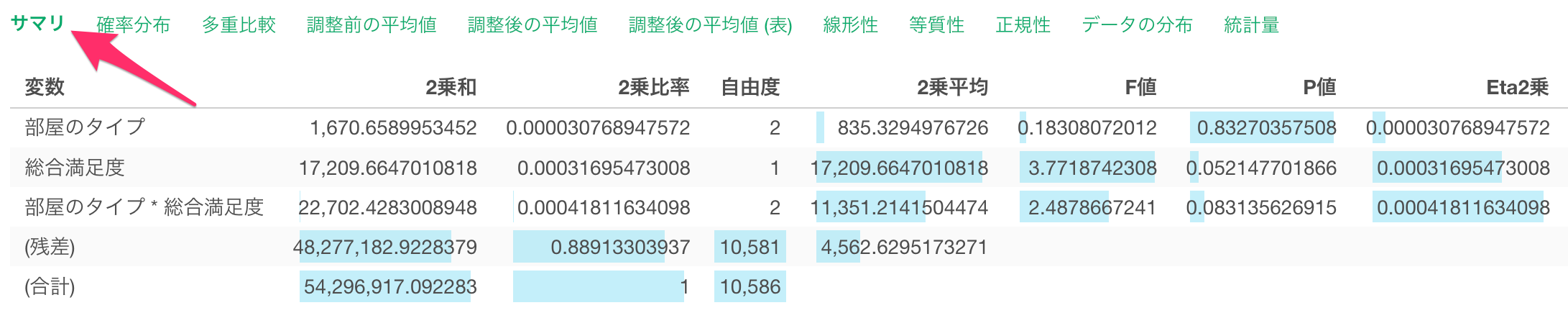
P値では、「複数のグループ間の平均値には差がない」という帰無仮説(前提)を受け入れた場合に、「各変数から得られた平均値の差が観察される確率」を確認できます。
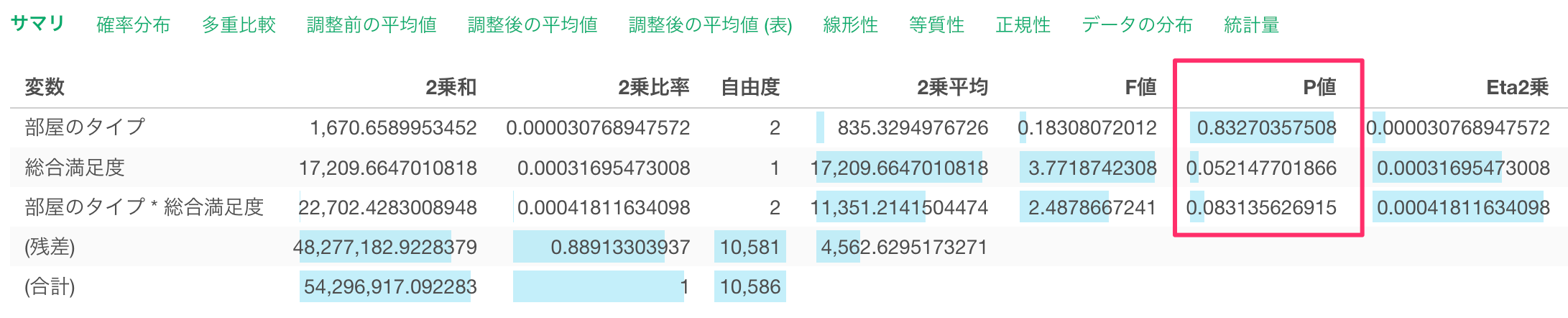
また、共変数(説明変数への影響を取り除きたい変数)に選択した変数(総合満足度)から得られるP値や、
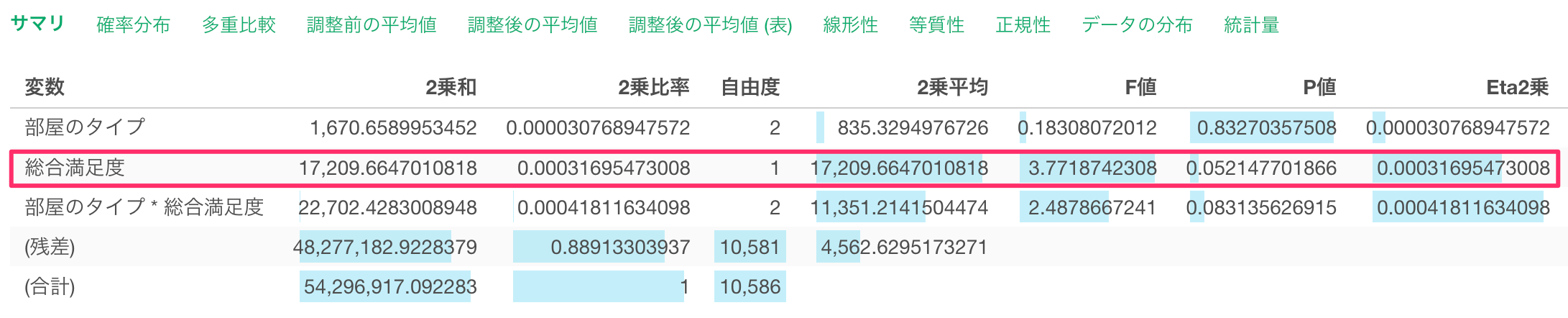
説明変数に選択した変数(部屋のタイプ)と共変数に選択した変数(総合満足度)の影響を掛け合わせた変数から得られるP値も確認することが可能です。
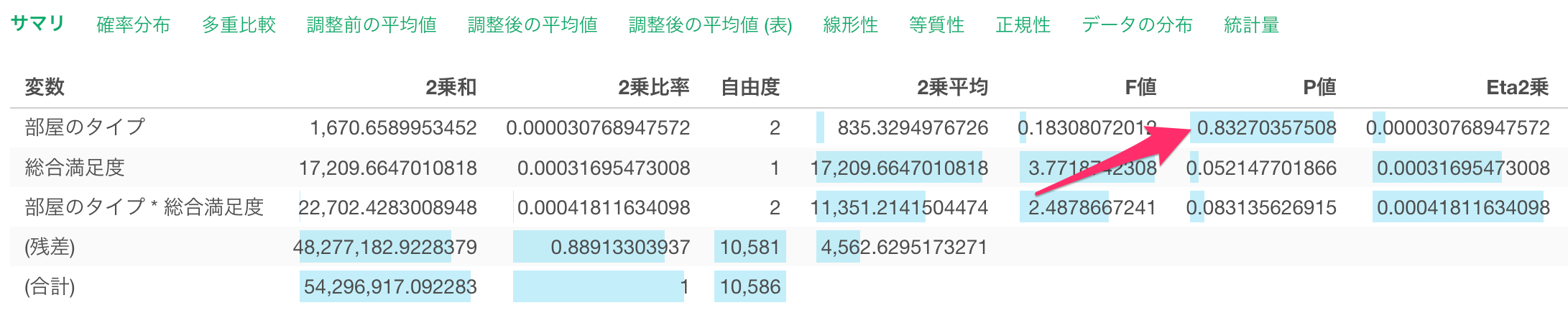
仮に有意水準を5%とした場合、P値が5%を超えていることから、帰無仮説を棄却することができず、「部屋のタイプ」と「一泊の価格」の関係は有意であるとは言えないことになります。
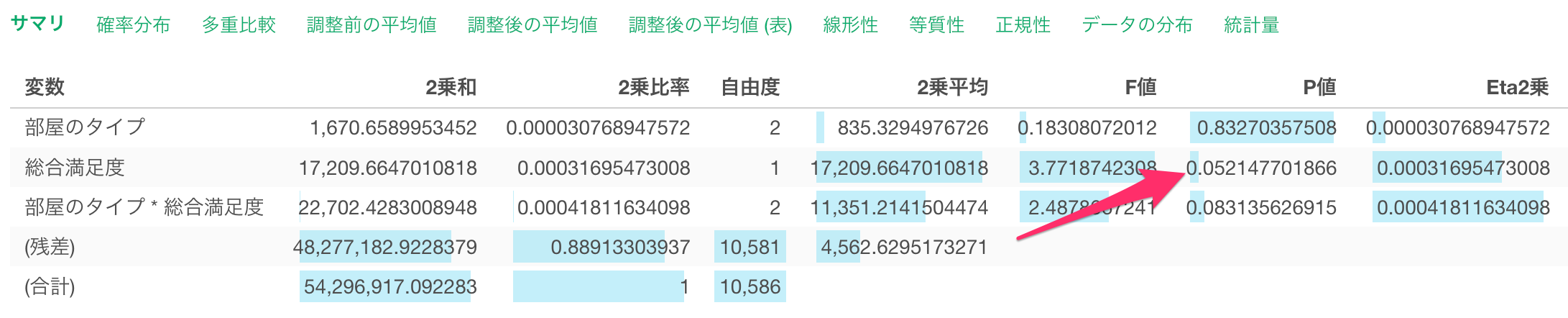
また、「総合満足度」のP値も5%を超えていることから、帰無仮説を棄却することができず、「総合満足度」と「一泊の価格」の関係は有意であるとは言えないことになります。
さらに「部屋のタイプ * 総合満足度」のP値も5%を超えていることから、帰無仮説を棄却することができず、「部屋のタイプと総合満足度の交互作用」と「一泊の価格」の関係は有意であるとは言えないことになります。
均質性
均質性のタブでは、先程紹介した「分散の等質性」の検定結果の確認が可能です。

デフォルトの設定では、「Brown–Forsythe(ブラウン・フォーサイス)検定」を使って分散の均質性を検定します。

均質性の検定における前提(帰無仮説)は「グループ間の「一泊の価格」の分散は均質である」となり、有意水準を5%とした場合、今回のP値は5%を下回っています。

そのため、帰無仮説は棄却され、「グループ間の分散は均質とは言えない」、つまり分散は均質でないと言えるわけです。
なお、サンプル数が極端に少ない場合を除き、分散の等質性の前提が満たされない状態でANCOVA(共分散分析)を実施しても、その結果に問題がないことも多いため、分散の等質性の前提が満たされない状態でも分析の結果を利用すること があります。
正規性
正規性のタブでは「一泊の価格」が正規分布しているかの検定結果の確認が可能です。

デフォルトの設定では、「Shapiro-Wilk Normality Test (シャピロ-ウィルクの正規性検定)」を使って正規性を検定します。

正規性の検定における前提(帰無仮説)は「一泊の価格は正規分布に従う」となり、有意水準を5%とした場合、今回のP値は5%を下回っています。

そのため、帰無仮説は棄却され、「一泊の価格は正規分布に従うとは言えない」、つまりは正規分布に従わないということになります。
なお、満たされない状態でも、ANCOVA(共分散分析)を実施しても、その結果に問題がないことも多いため、正規性の前提が満たされない状態でも分散分析の結果を利用することはあります。
なお、サンプル数が極端に少ない場合を除き、正規性の前提が分散の等質性の前提が満たされない状態でANCOVA(共分散分析)を実施しても、その結果に問題がないことも多いため、分散の等質性の前提が満たされない状態でも分析の結果を利用することがあります。
多重比較
今回のANCOVA(共分散分析)では、「部屋のタイプによって一泊の価格の平均に差はない」という帰無仮説を検定しています。
今回は「部屋のタイプによって一泊の価格の平均に差はない」ことが既に確認できていますが、仮に有意な違いが出たとしても、それは、平均の比較が可能な「ペア」のうち、少なくとも、1つのペアにおいて有意な差があることのみを表しています。
言い換えれば、以下の三つの組み合わせのみの検定を行っていることになります。
- Entire home/apt(一軒家/アパート一棟貸し)とPrivate room(個室)
- Entire home/apt(一軒家/アパート一棟貸し)とShared room(相部屋)
- Private room(個室)とShared room(相部屋)
そこで、どのペアにおいて有意差が生じていたかは、「多重比較」タブから確認できます。

デフォルトでは、Tukey's HSD Test(テューキーの範囲検定)を利用し、各ペアを検定します。

このときの前提(帰無仮説)は「各ペア内の一泊の価格の平均値に差はない」となり、有意水準を5%とした場合、一部のペアのP値は5%を下回っています。

そのため、今回のデータでは、「一軒家/アパート一棟貸しと個室の一泊の価格には有意な差がある」あるいは「一軒家/アパート一棟貸しと相部屋の一泊の価格には有意な差がある」と言えわけです。
ただし、一点注意が必要なことがあります。それは多重比較タブから確認できる検定結果は、共変数に選択した変数の影響を取り除いたう えでの検定結果になっていないということです。
そのため多重比較タブでは、比べる部屋のペアによっては有意な差があるように見えても、ANCOVA(共分散分析)の結果では、「部屋のタイプ」が有意ではないということが起こりうるわけです。
マーケティング・アナリティクス・トレーニング

効果的なマーケティング活動を行うために必要なデータ分析手法を、見込みまたは既存顧客の購買、属性、行動に関するデータを使い、実際に手を動かしながら短期間で効率的に習得していただくためのトレーニングを開催しています。
データドリブンなマーケティング活動を行うために必要なデータサイエンスの手法を短期間で習得したい方は、ぜひこの機会に参加をご検討ください!