K-Meansクラスタリング用のデータを作成する方法
クラスタリングとは、似ている特徴を持つデータ(行または観察対象)をグループに分ける手法です。
顧客の購買行動での分類、国の経済指標での分類、アンケート回答者の分類など、様々なシーンで利用されます。その中でも最も一般的に使われるのが、ExploratoryでもサポートしているK-meansクラスタリングです。
K-meansクラスタリングに必要なデータ
K-meansクラスタリングを行うためには、1行がクラスター分けする対象になっている必要があることに加えて、クラスタリングするもととなる変数のデータ型は数値型である必要があります。
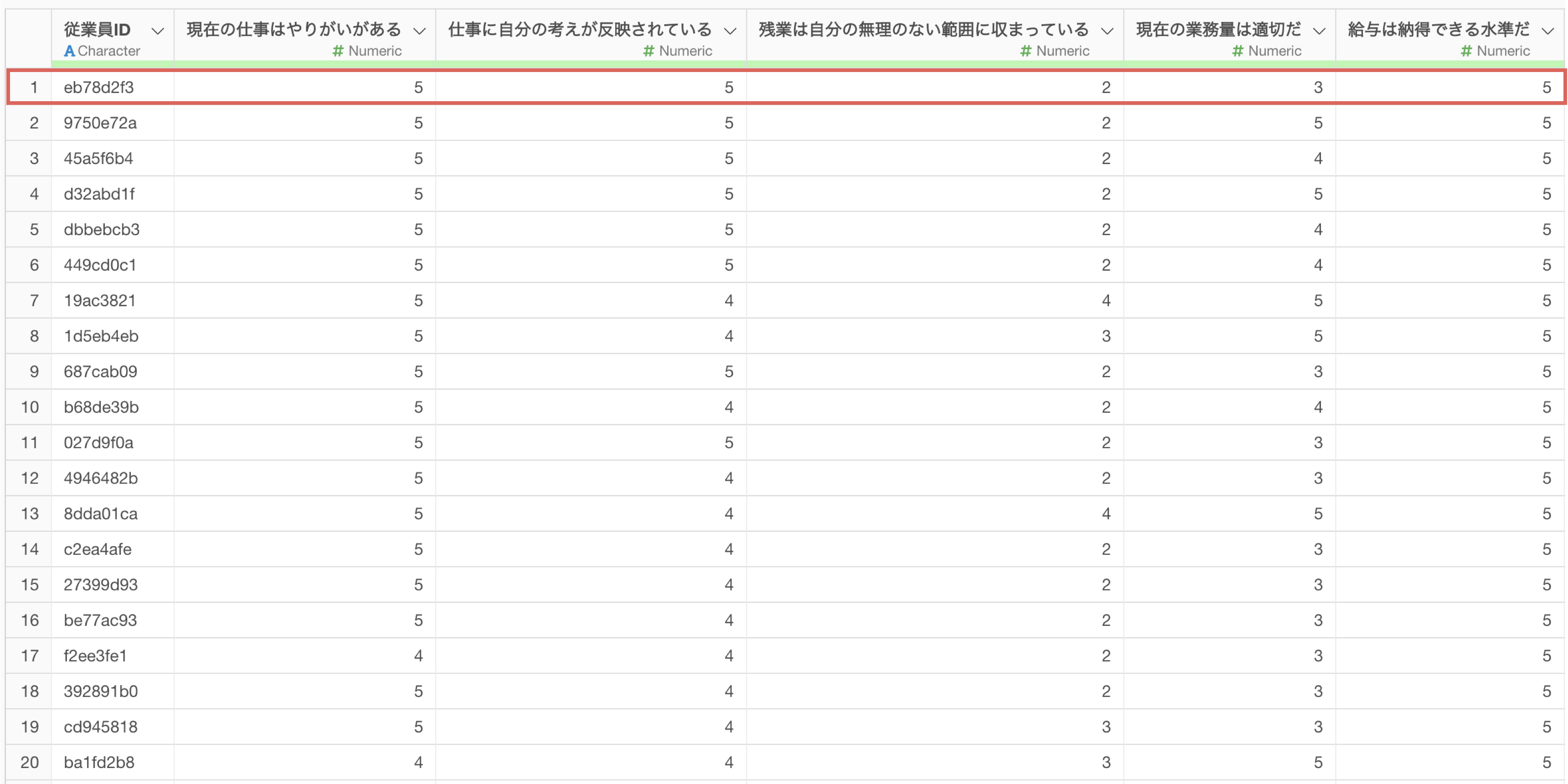
そのため例えば、アンケートの回答者をクラスターに分けたい場合は1行が1人の回答者、国をクラスターに分けたい場合は、1行が1国を表す形式にする必要があります。
しかし、手元にあるデータがそういった観察対象の単位になっていないことも少なくありません。このような場合、データを集計して1行がクラスター分けしたい対象になるような形式に整形することが一般的です。
具体的には、個別のデータを集約の単位でグループ化し、各指標の平均値などを計算することで、クラスタリングに適したデータ形式を作成できることがよくあります。
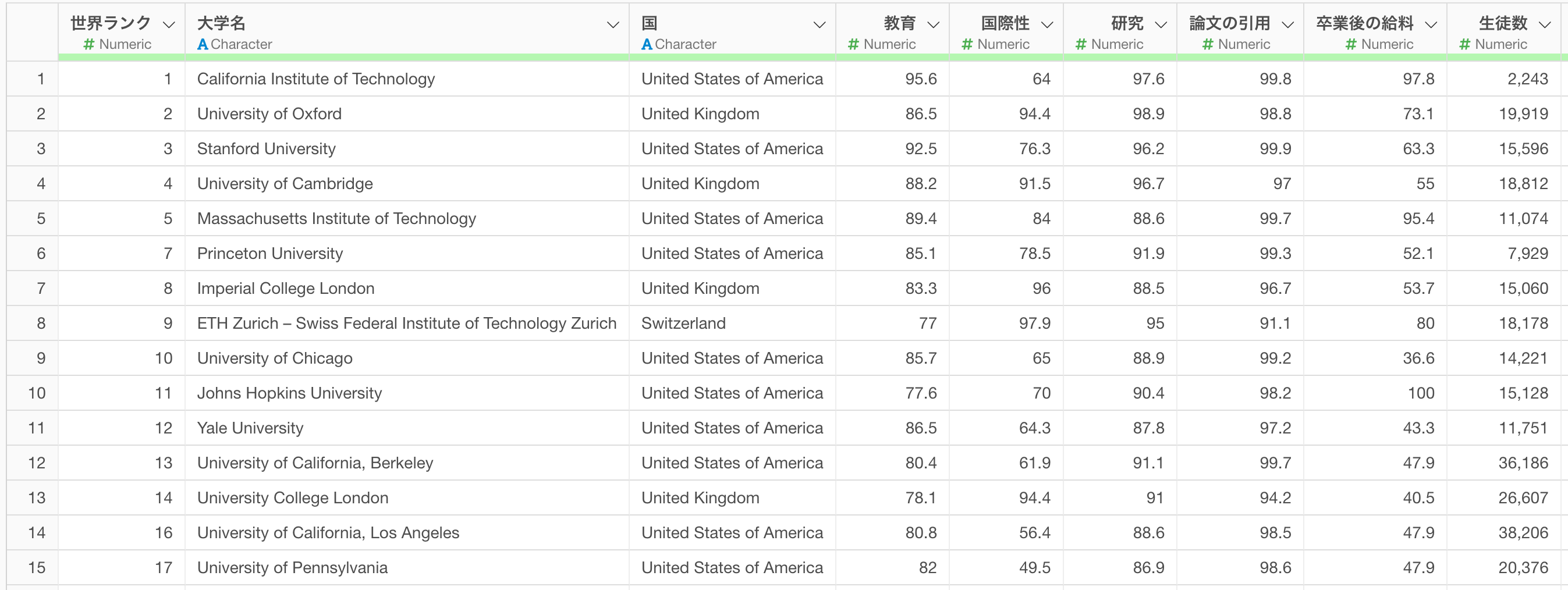
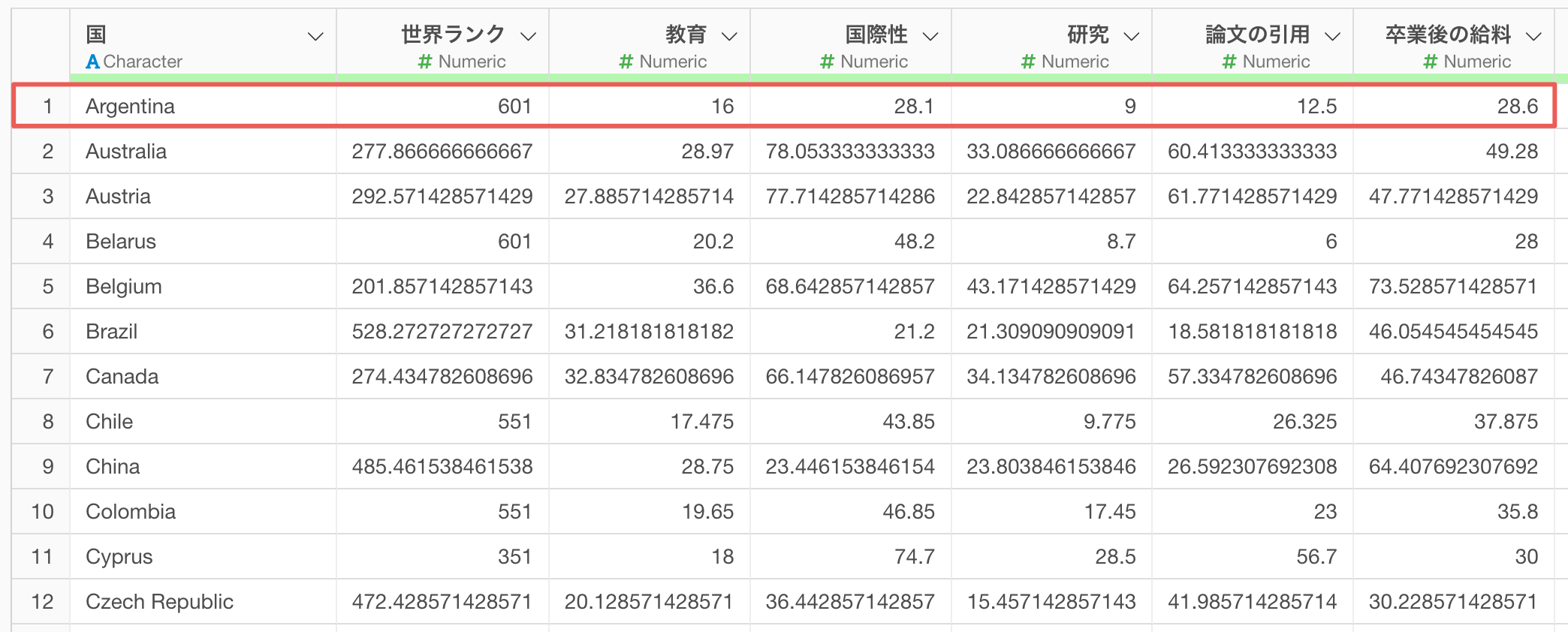
そこで、今回は1行が1つの大学を表し、列には国名や各大学のスコア指標の情報を持つ世界の大学ランキングのデータを使って、国をクラスターに分けるためのデータを作成する方法を紹介します。
データの集計によるクラスタリング用データの作成
国レベルでクラスタリングを行うには、1行が1大学を表すデータを、1行が1国を表す形式に変換する必要があります。
そこで今回は、国ごとにデータを集計します。
集計したい単位である「国」の列ヘッダーメニューから「集計」を選択します。
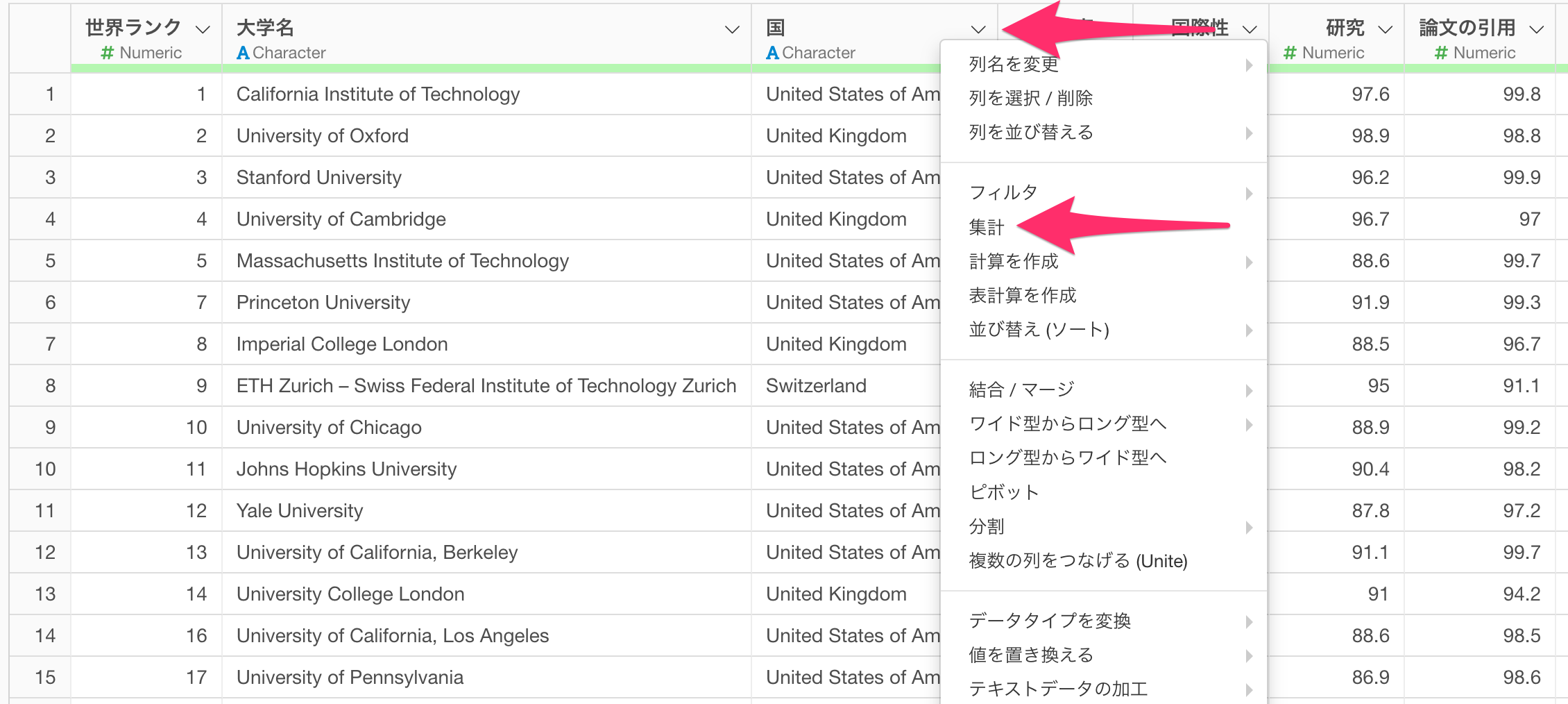
集計のダイアログが表示されたら、グループに集計したい単位となる「国」を設定します。
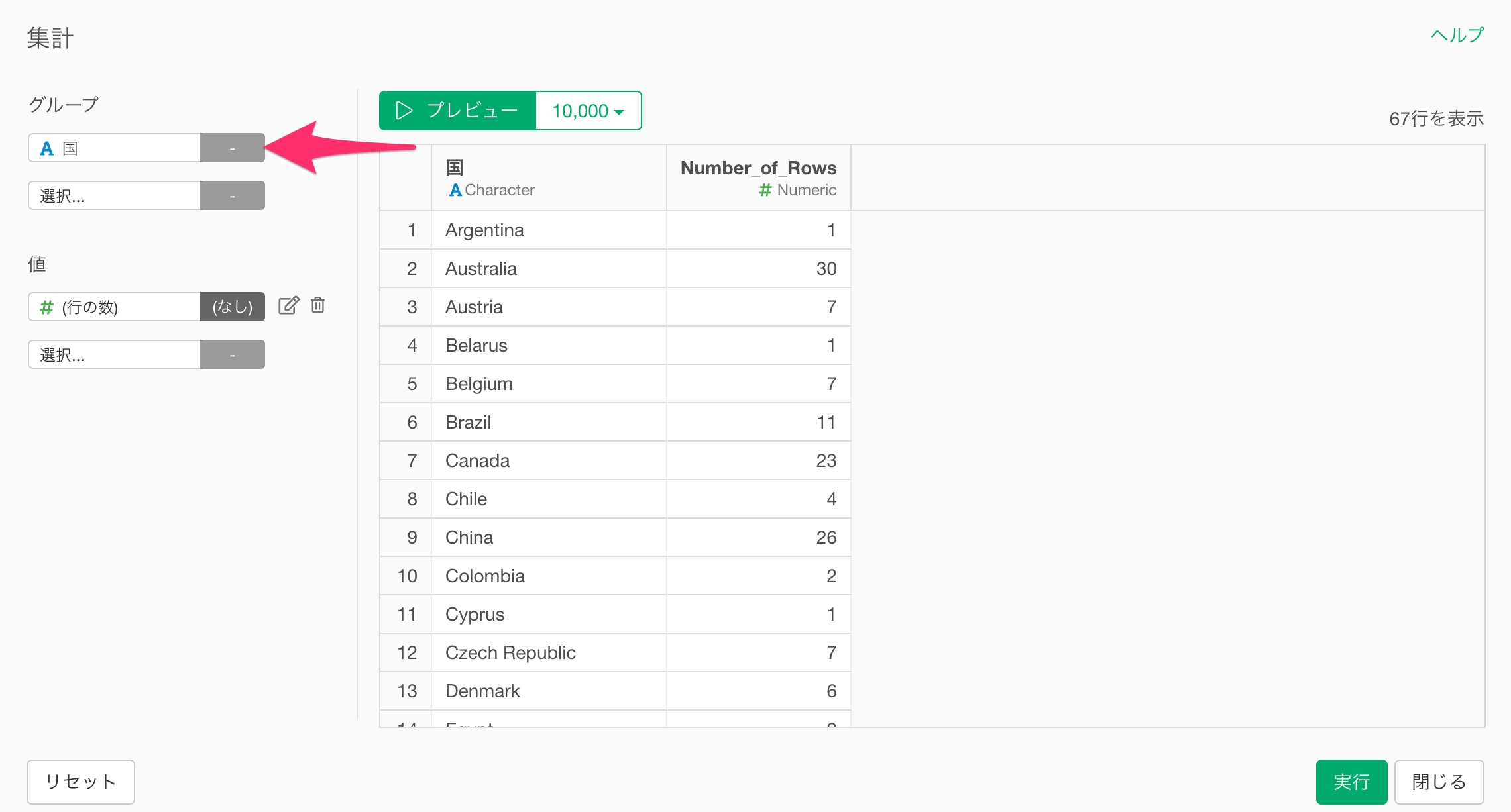
このとき、1列ずつ指標を選択して、それぞれの列の集計関数を個別に指定することも可能です。
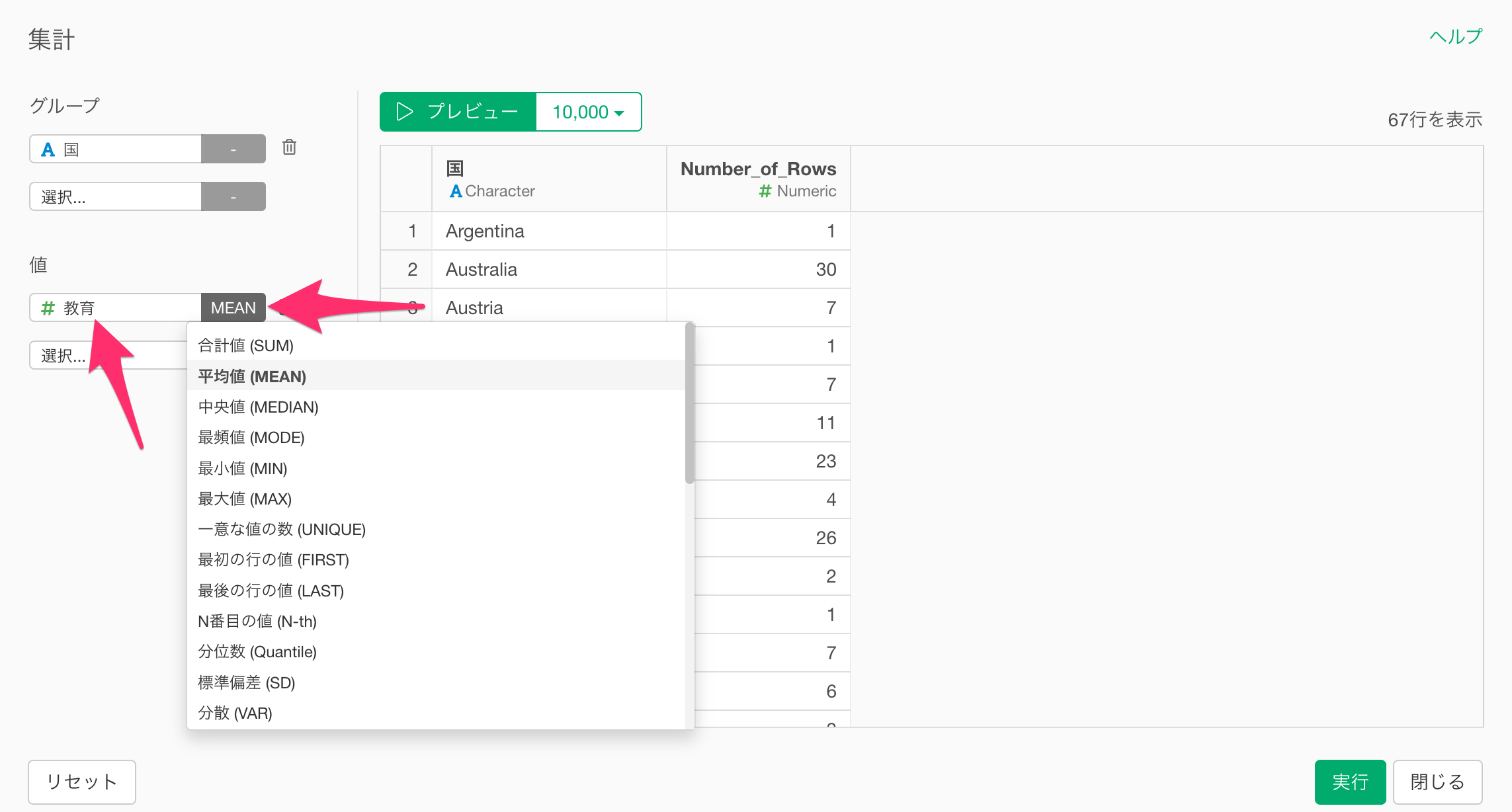
一方で「全ての数値の列」を選択すると、手元にあるデータの全ての数値指標を一度に集計することができるため効率的です。
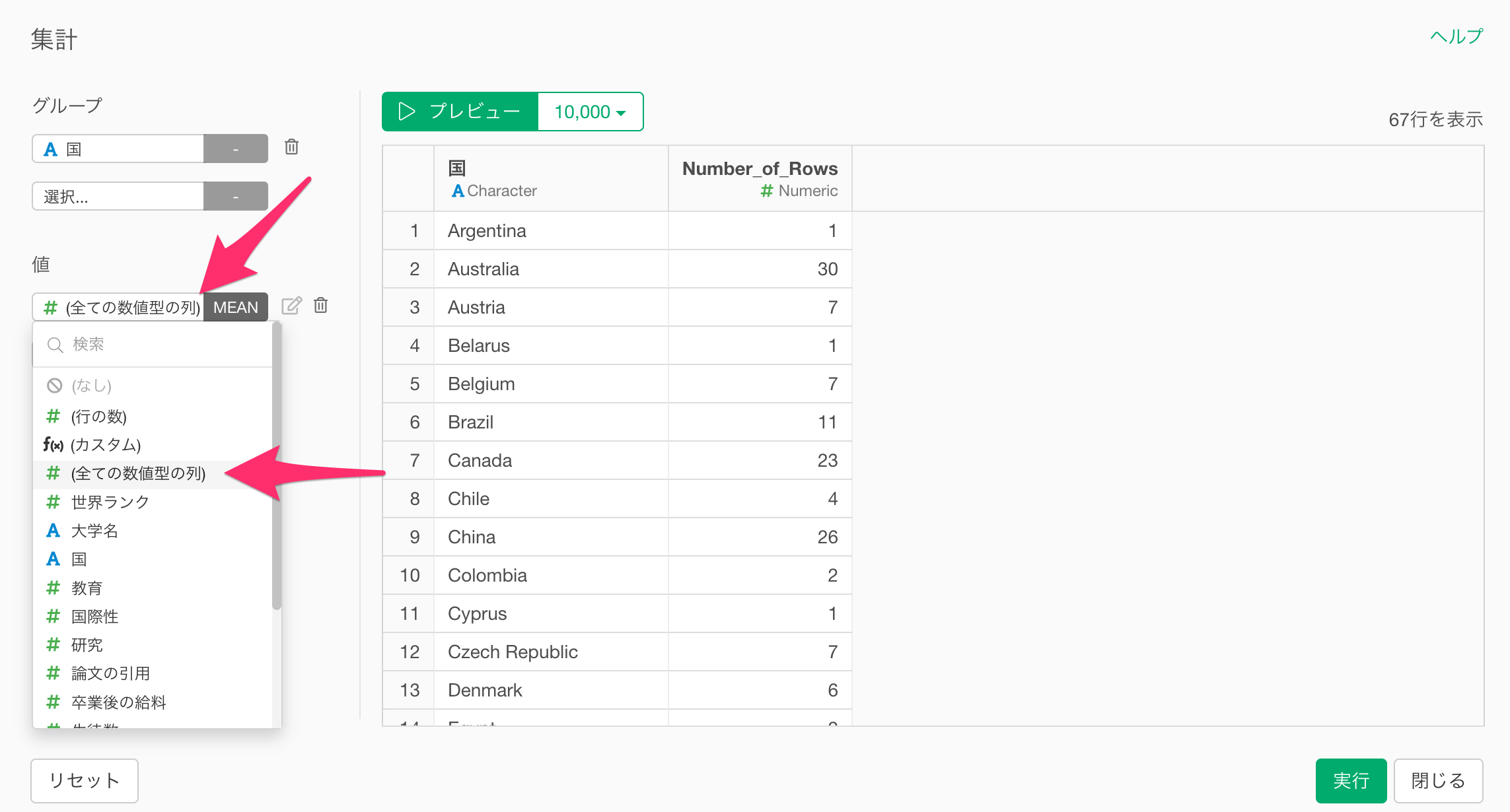
今回は集計方法として「平均」を選択し、情報を集約して、実行ボタンをクリックします。
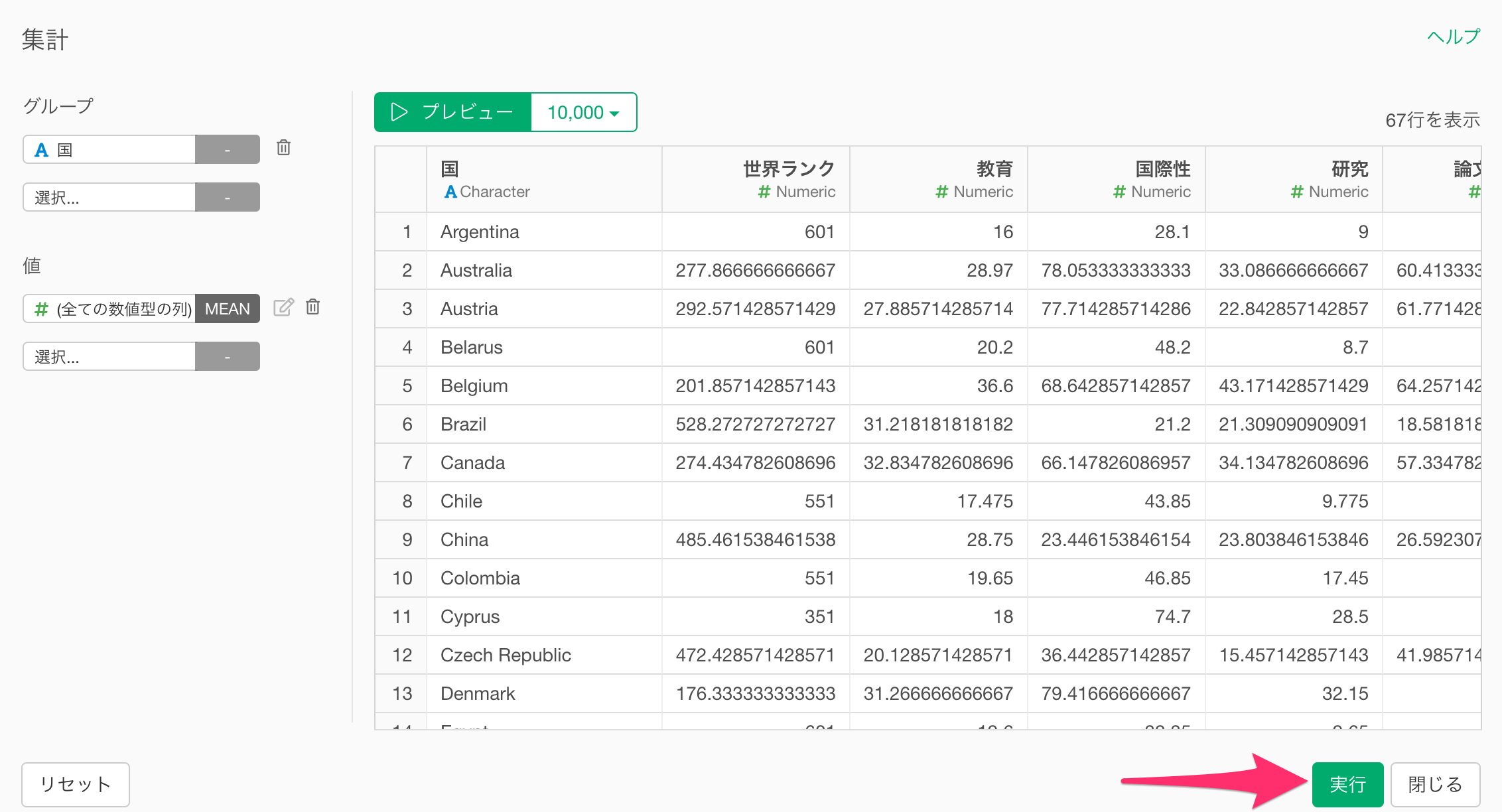
これで元々1行が1大学であったデータが、1行が1国のデータに集約され、各国の大学スコアの平均値を持つクラスタリング用データを作成できました。
カテゴリー型データの処理
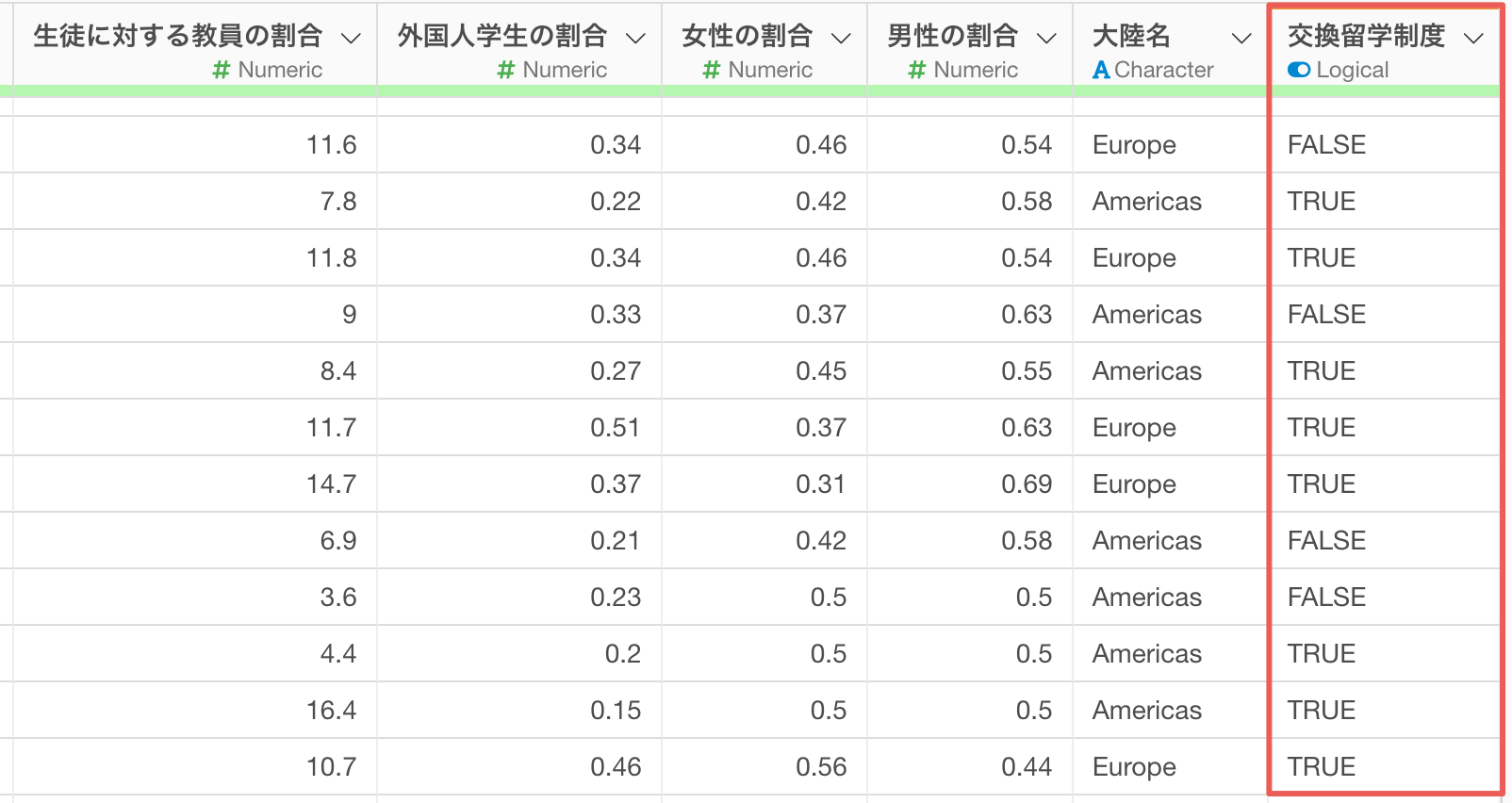
K-meansクラスタリングは数値型の列をもとに観察対象をグループ化するため、カテゴリー型のデータはそのままでは使用できません。
しかし、これらのデータも集計する際、適切な形式に変換することで活用可能です。
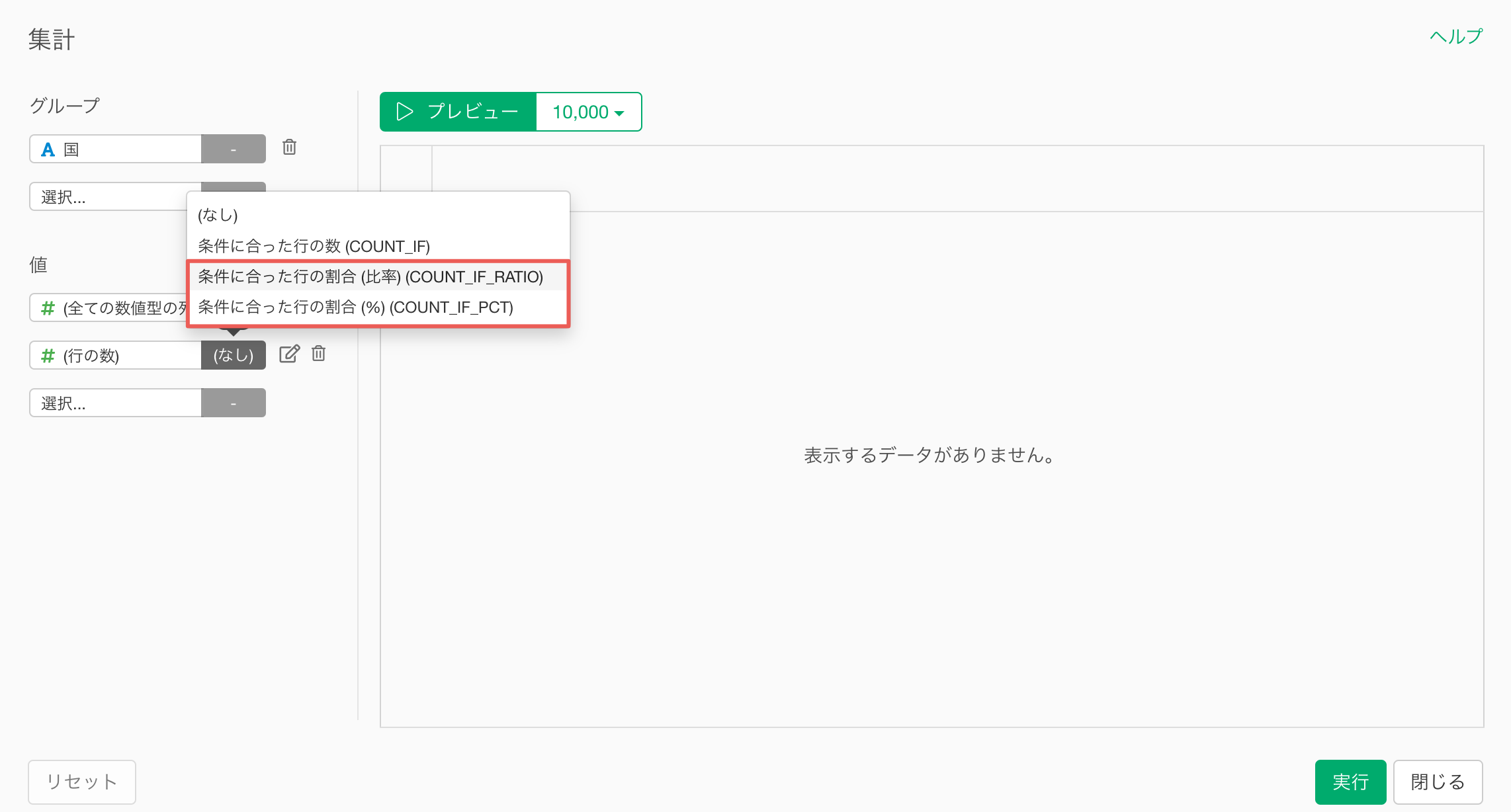
例えば、各大学に「交換留学制度があるかないか」といったTRUE/FALSE型の列がある場合、国単位で集計する際、「TRUEの割合」、つまりは「交換留学制度がある大学の割合」として集計することで、数値データとして活用できます。
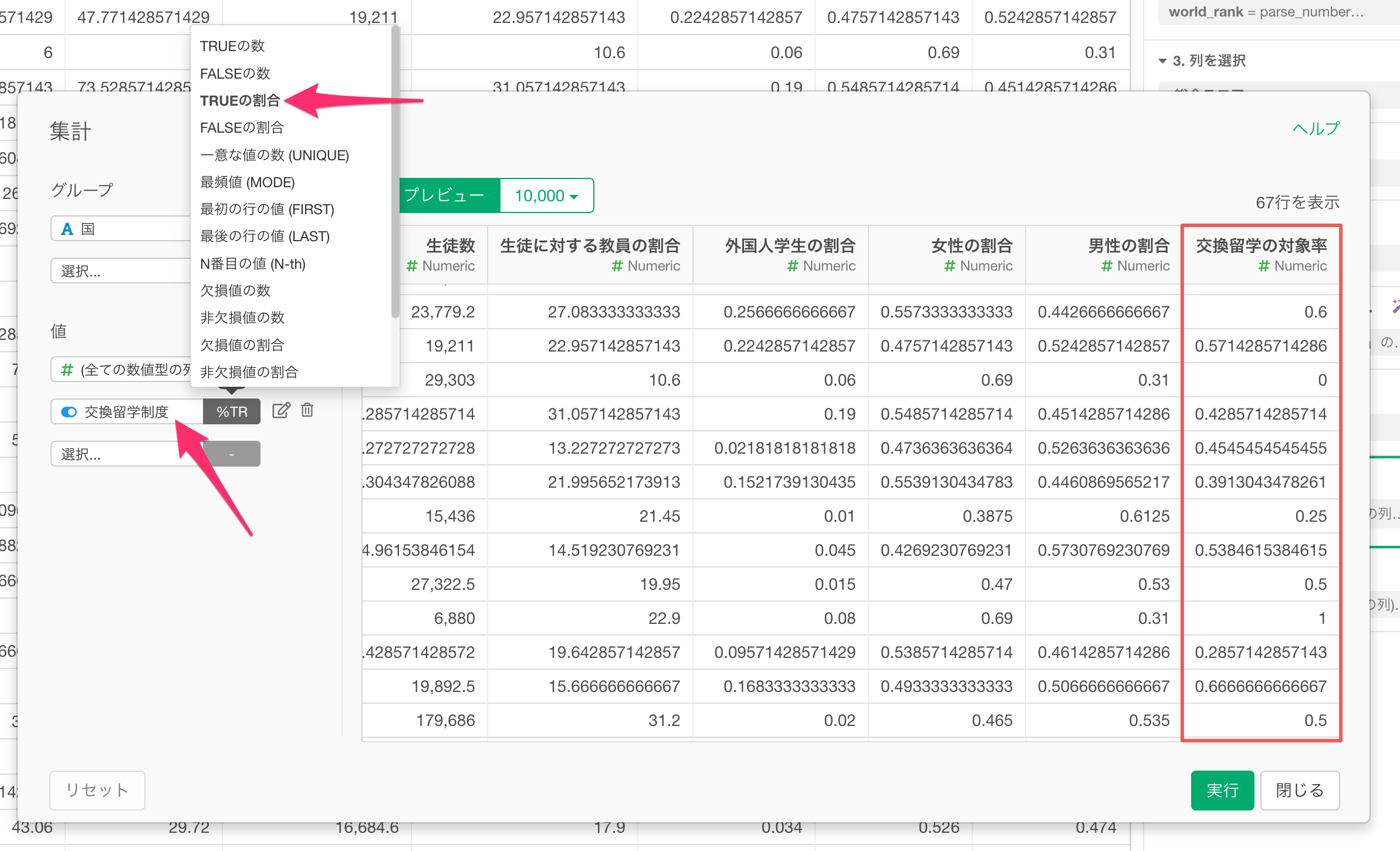
なお、ロジカル型でない列に対しても同じように対応が可能です。
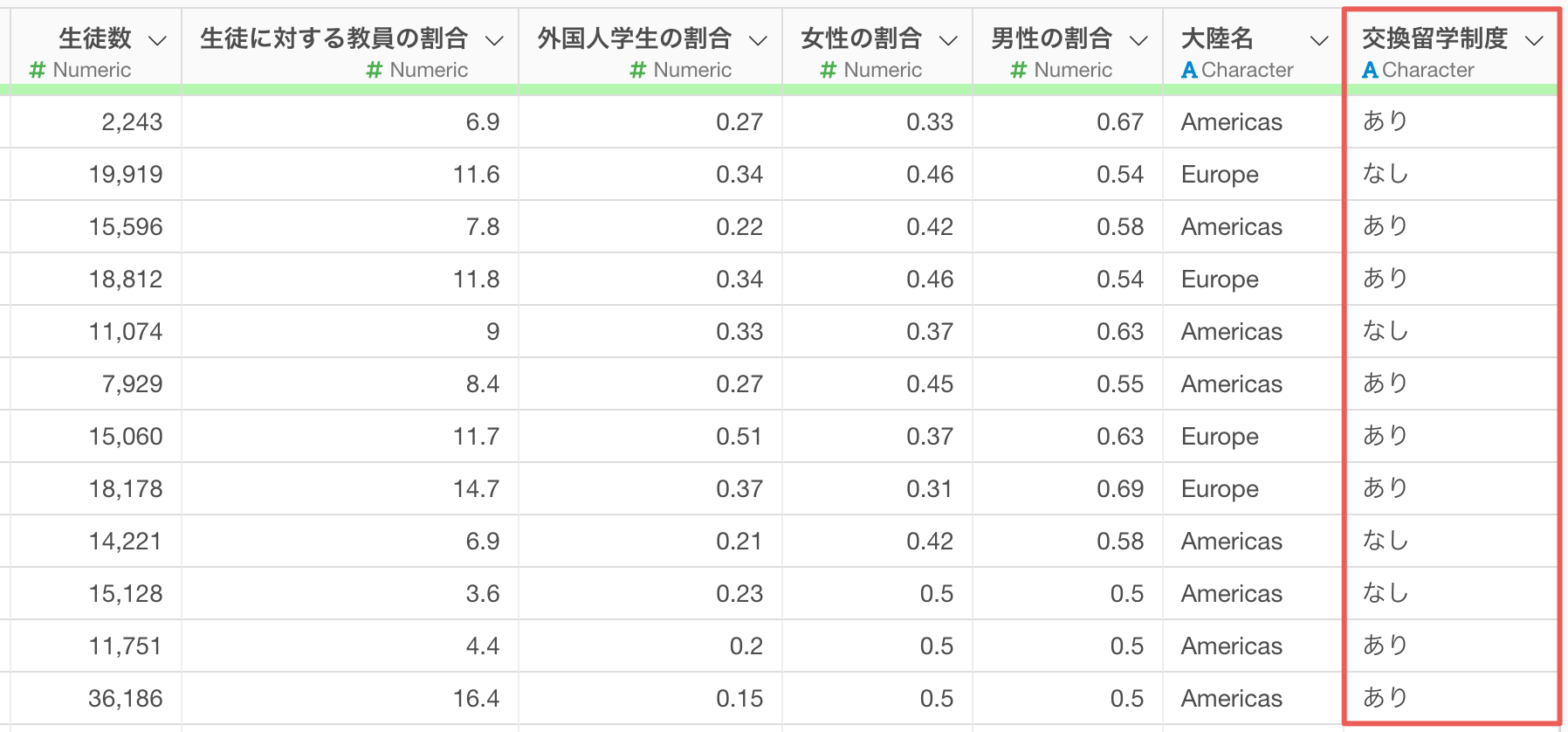
具体的には、条件に合った行の割合などでカテゴリーの情報を集計して、数値型に変換が可能です。
 これでカテゴリー型のデータも割合に変換され、クラスタリングの対象変数として利用できるデータ形式に変換できました。
これでカテゴリー型のデータも割合に変換され、クラスタリングの対象変数として利用できるデータ形式に変換できました。