統計の予測モデルのデータタイプ別の解釈方法
統計のモデルのデータタイプによって解釈方法が異なります。統計モデルの結果を正しく理解するために、説明変数のデータタイプ(数値データ、カテゴリーデータ)に応じて、係数の意味を適切に解釈する必要があります。
例えば、不動産価格の予測モデルを作った場合、「評価点」のような数値データと「ウォーターフロント(水辺かどうか)」のようなカテゴリーデータでは、係数の読み方が全く異なります。この違いを理解することで、モデルの結果を正確にビジネスに活用できるようになります。
データタイプ別の解釈方法
統計モデルの解釈では、説明変数のデータタイプによって係数の読み方が変わります。基本的な考え方は以下の通りです。
数値データの場合
数値データ(例:年齢、勤続年数、など)では、その変数が1単位増加したときに目的変数がどれだけ変化するかを表します。
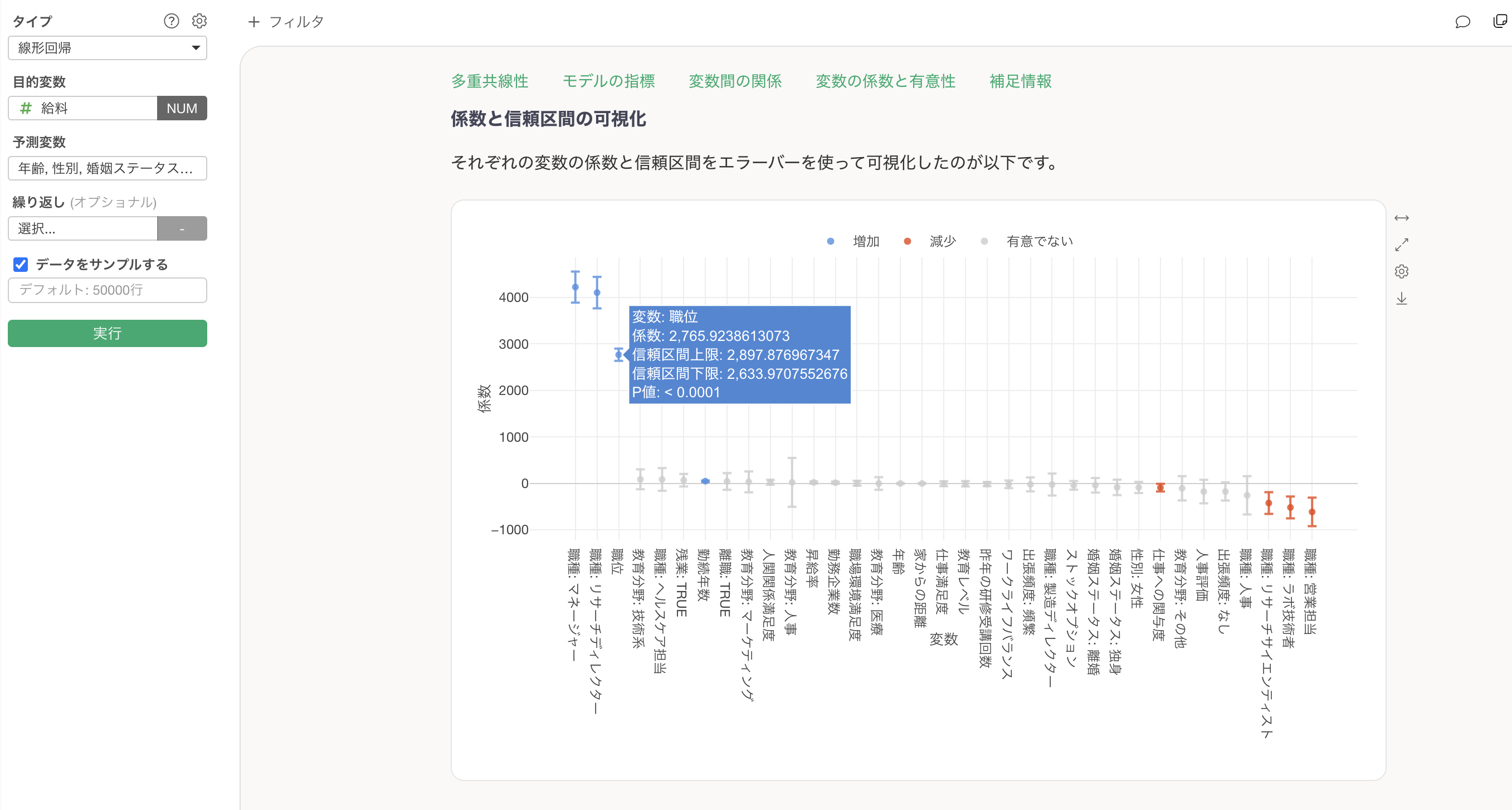
従業員データの給料を予測するモデルで「職位」という数値データを見てみましょう。
他の変数が一定だった時に、評価が1単位上がると価格が2,765ドル上がることが分かります。また、P値は有意水準の5%よりも小さいために、この関係は統計的に有意であることがわかります。
カテゴリーデータの場合
カテゴリーデータ(例:職種、部署など)では、ベースレベル(基準となるカテゴリー)と比較して目的変数がどれだけ変化するかを表します。
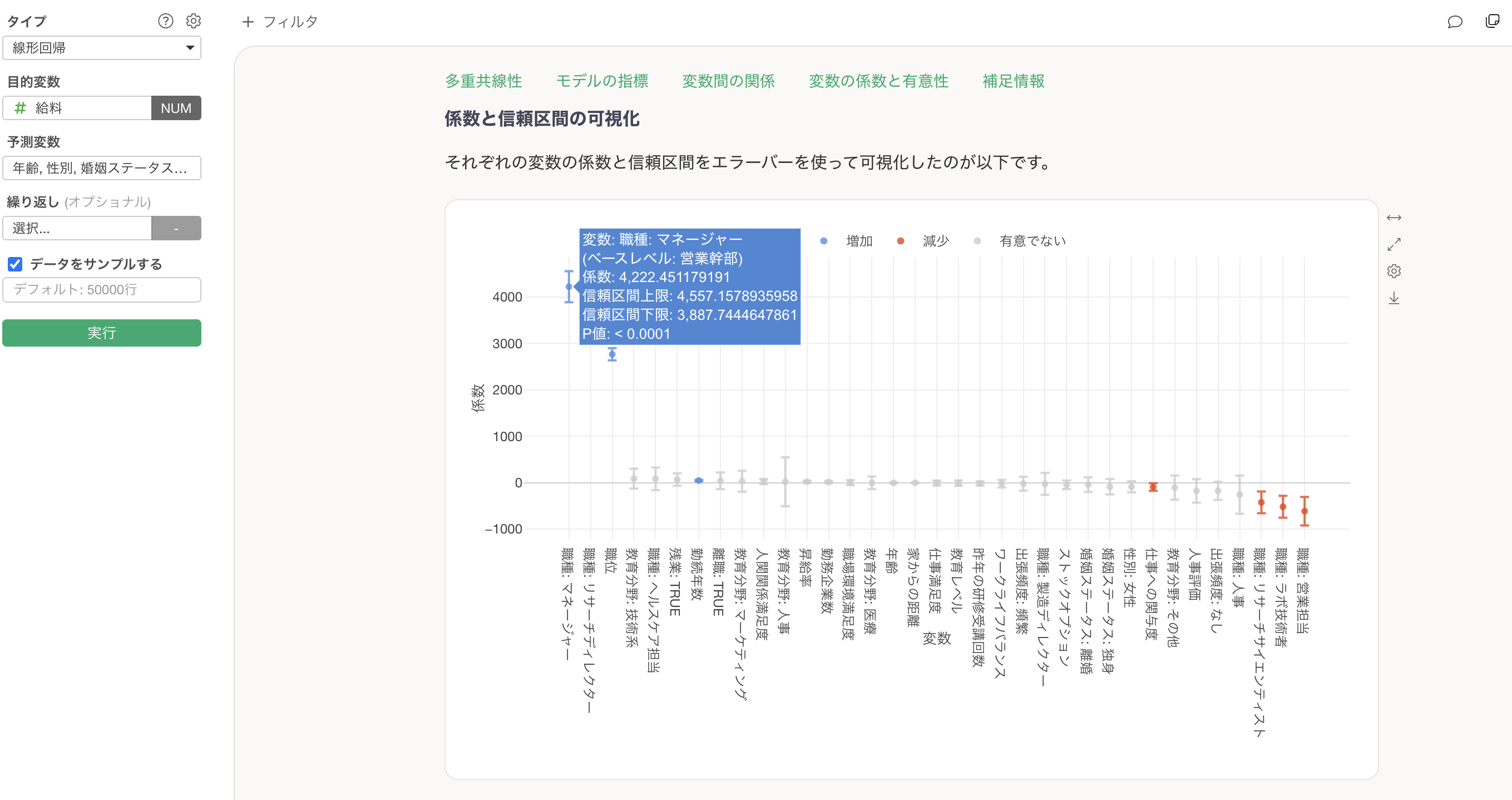
従業員データの給料を予測するモデルで「職種」というカテゴリデータを見てみましょう。
他の変数が一定だった時に、ベースレベルである「営業幹部」と比べて、「マネージャー」になると給料は4,222ドル上がることが分かります。また、P値は有意水準の5%よりも小さいために、この関係は統計的に有意であることがわかります。
まとめ
統計モデルの結果を正しく理解するには、説明変数のデータタイプに応じて係数の意味を適切に解釈する必要があります。数値データの場合、係数はその変数が1単位増加したときの目的変数の変化量を表します。一方、カテゴリーデータでは、ベースレベル(基準カテゴリー)と比較した変化量を表します。このデータタイプ別の解釈方法を理解することで、モデル結果を正確にビジネスに活用できます。