LightGBMの紹介
LightGBMは複数のモデルに学習させ、それぞれの予測結果を一つの予測にまとめるアンサンブル学習の代表的なアルゴリズムの一つです。XGBoostと同じ勾配ブースティングのファミリーに属しており、決定木を一つずつ順に作っていき、前の決定木の予測で間違ったデータに重みをかけて、次の決定木ではその間違いをカバーするように学習を進めていきます。
LightGBMはMicrosoftが開発したフレームワークで、XGBoostに対していくつかの独自技術を導入することで、より高速でメモリ効率の良い学習を実現しています。
主な違いの一つが、木の「育て方」です。XGBoostはデフォルトでは木の各階層をまんべんなく広げていく「Level-wise(レベル単位)」という方法を取ります。これは木全体をバランスよく成長させるイメージです。一方、LightGBMは「Leaf-wise(葉単位)」という方法を取り、「ここを分割すれば一番予測が改善する」という葉だけを優先的に分割していきます。必要なところだけを深掘りするため、同じ数の葉を使っても、より予測精度の高い木を作ることができます。
また、LightGBMには学習をさらに高速化するための工夫がいくつも搭載されています。たとえば、GOSS(Gradient-based One-Side Sampling)は、すでに予測がうまくいっているデータの一部をスキップし、予測を大きく外しているデータに集中して学習する仕組みです。EFB(Exclusive Feature Bundling)は、同時に値を持たないような特徴量(たとえば「Aが1のときBは必ず0」のような関係)をまとめて一つの特徴量として扱うことで、計算量を減らします。さらに、ヒストグラムベースアルゴリズムにより、連続的な数値をあらかじめいくつかのグループ(ビン)に分けておくことで、分割点の探索を高速化しています。
これらの技術により、大規模なデータでも高速に学習できることから、データ分析のコンペティションなどでも広く利用されています。
必要なデータの形式
LightGBMを実行する際には、1行が1観測対象となっているデータを使う必要があります。目的変数には数値型、ロジカル型のどちらも扱うことができます。説明変数におけるデータタイプには特に縛りはありません。しかし、説明変数同士の相関が強い場合は影響度を取り合ってしまい、変数重要度の順番が低く見積もられることがあります。
LightGBMを実行する
今回は、従業員の「給料」を予測するLightGBMのモデルを作成します。
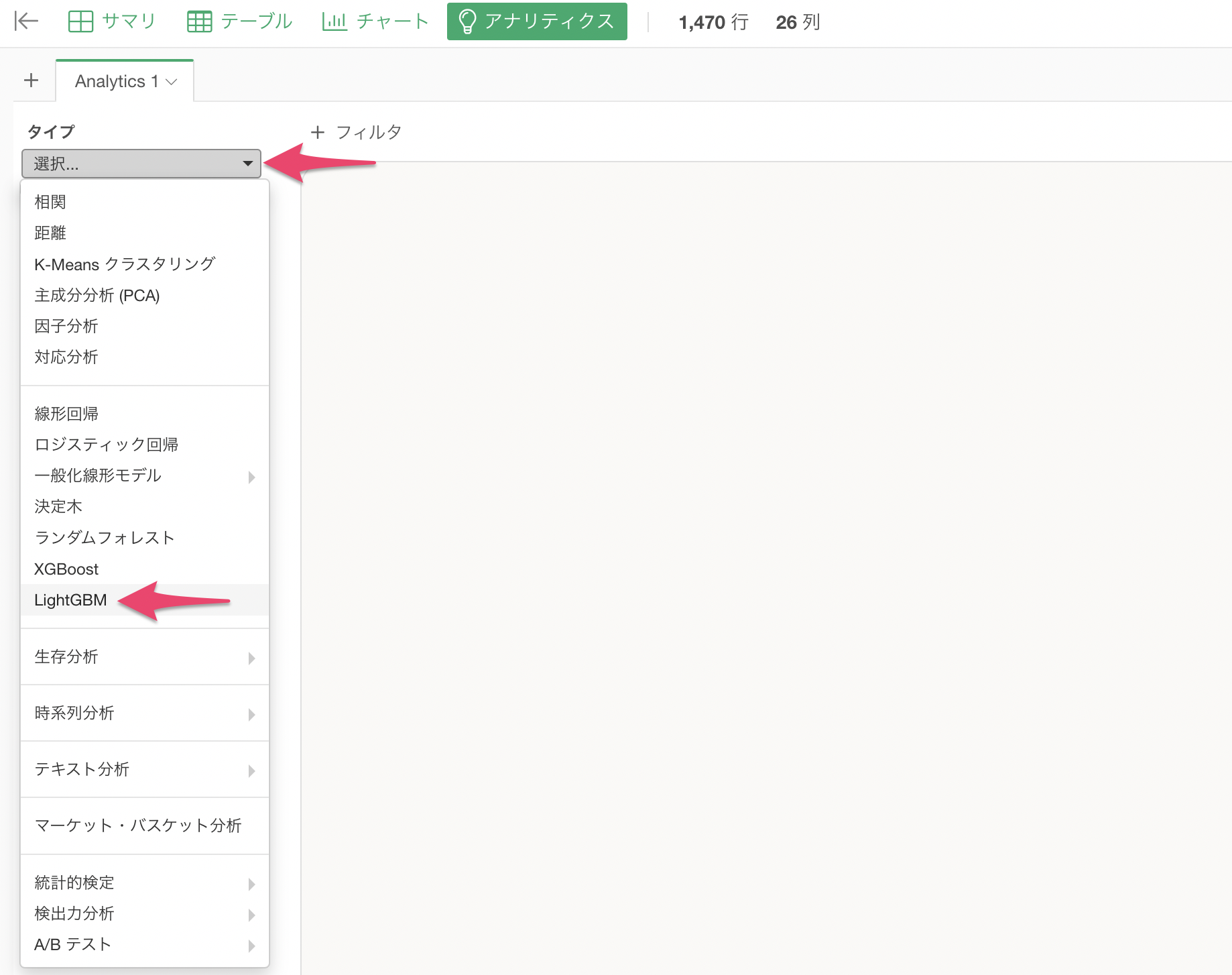
アナリティクスビューを開き、タイプに「LightGBM」を選択します。
目的変数に「給料」を選択します。
説明変数の列をクリックして、給料を予測する上で使用する列を選択します。列の選択画面では、個別に列を選ぶことも、列の範囲を指定してまとめて選ぶこともできます。
説明変数を設定したら、「実行」ボタンをクリックします。
これによってLightGBMを作成することができ、各チャートには解釈のための説明が表示されています。
結果の解釈
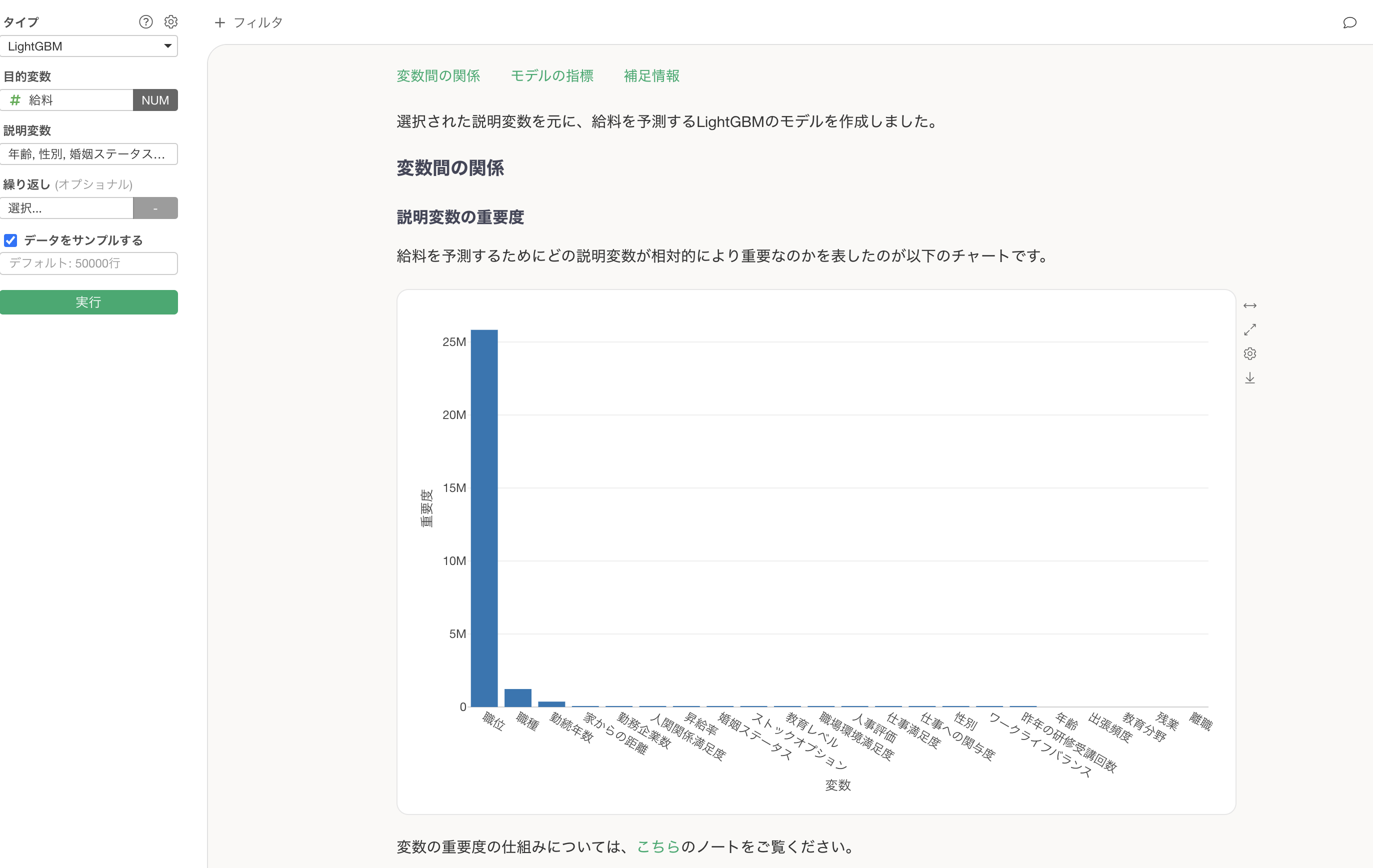
説明変数の重要度
説明変数の重要度のセクションでは、どの変数が目的変数とより相関が強いのか、予測する時により重要なのかを調べることができます。
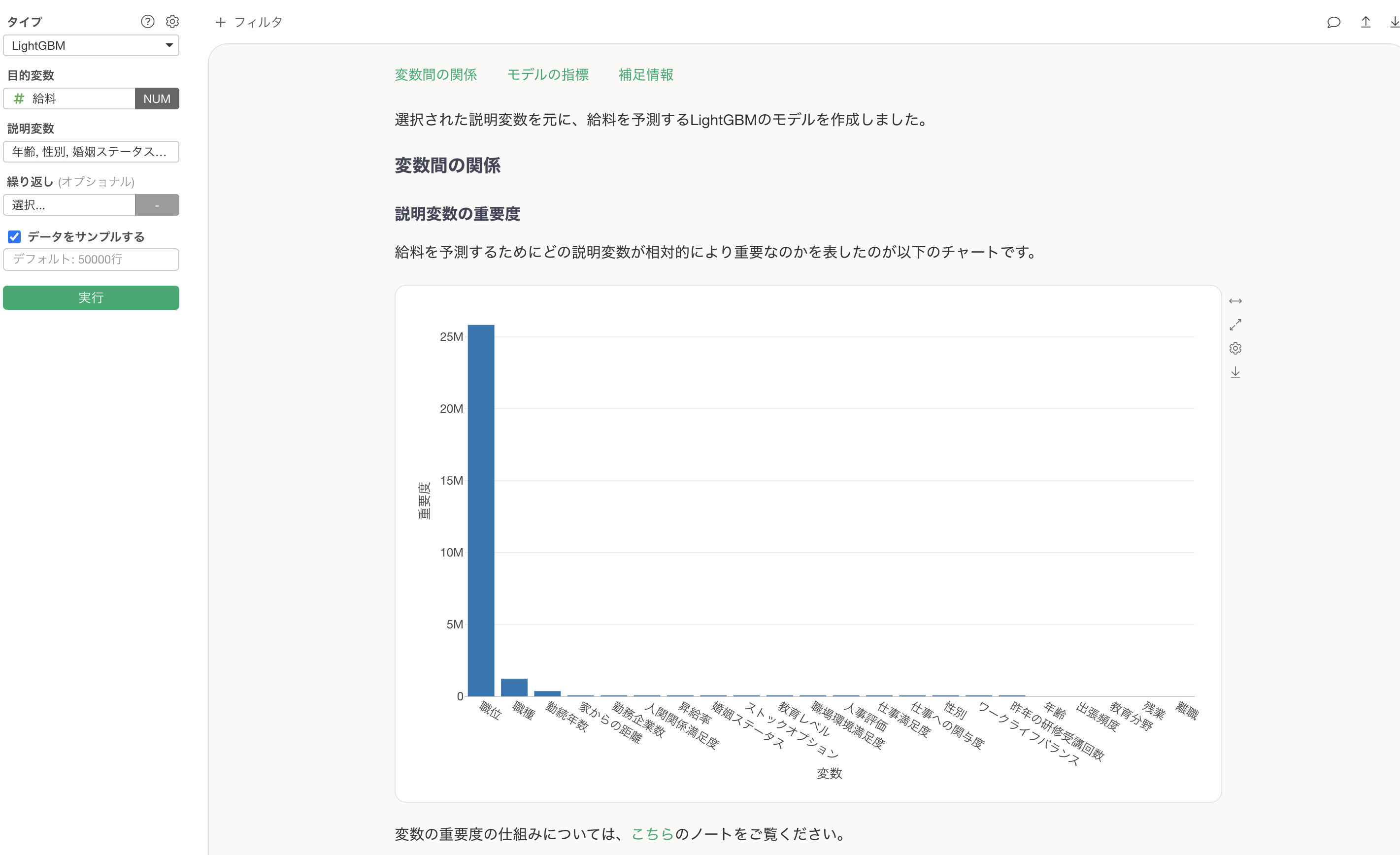
重要度が高い変数ほど、給料を予測する上で重要であることを意味します。今回の例では、職位が給料を予測する上で圧倒的に重要であることがわかります。
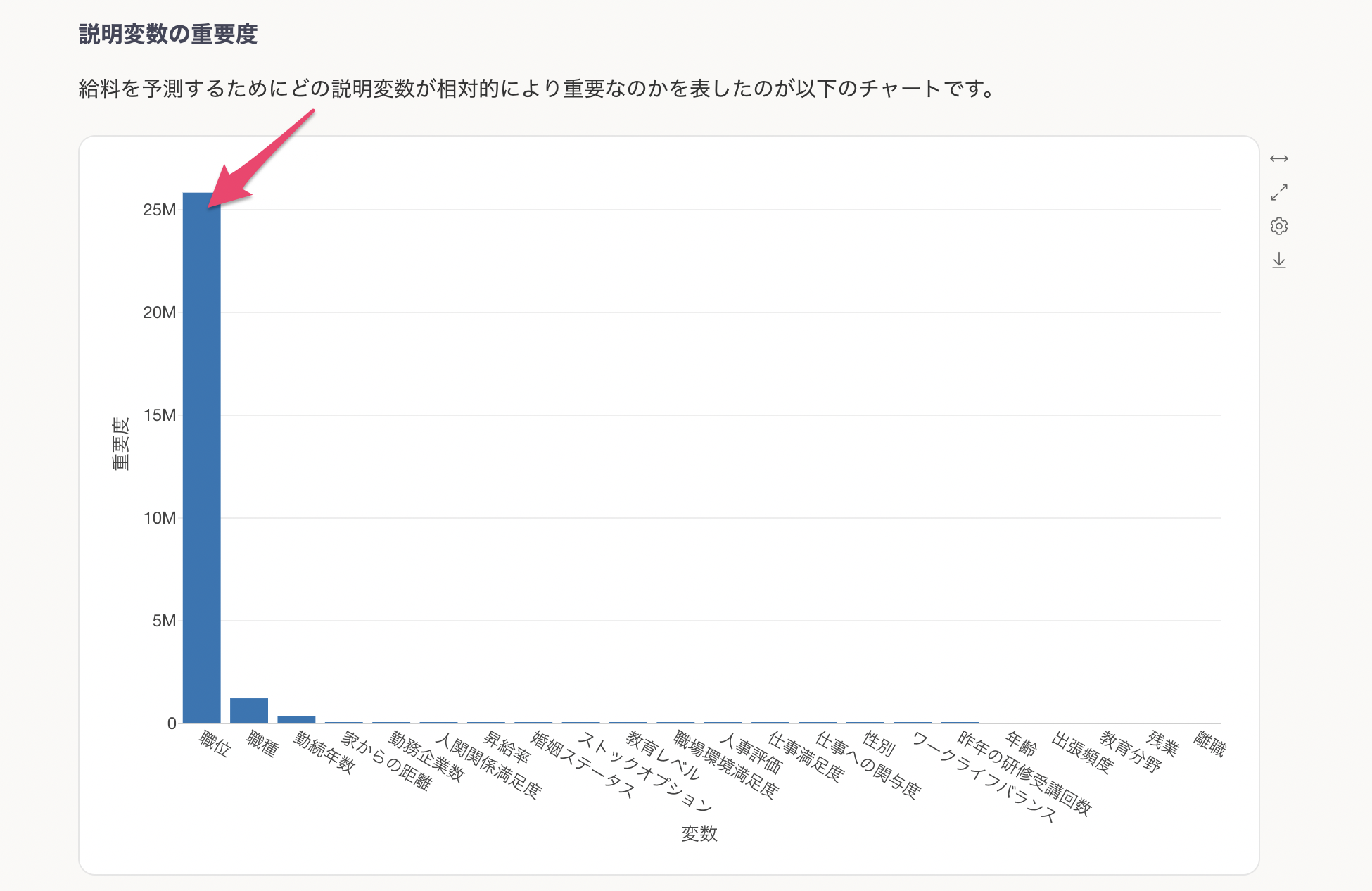
次に重要な変数として、職種や勤続年数が続いており、特定の職種や長い勤続年数も給料に影響を与えていることを示しています。
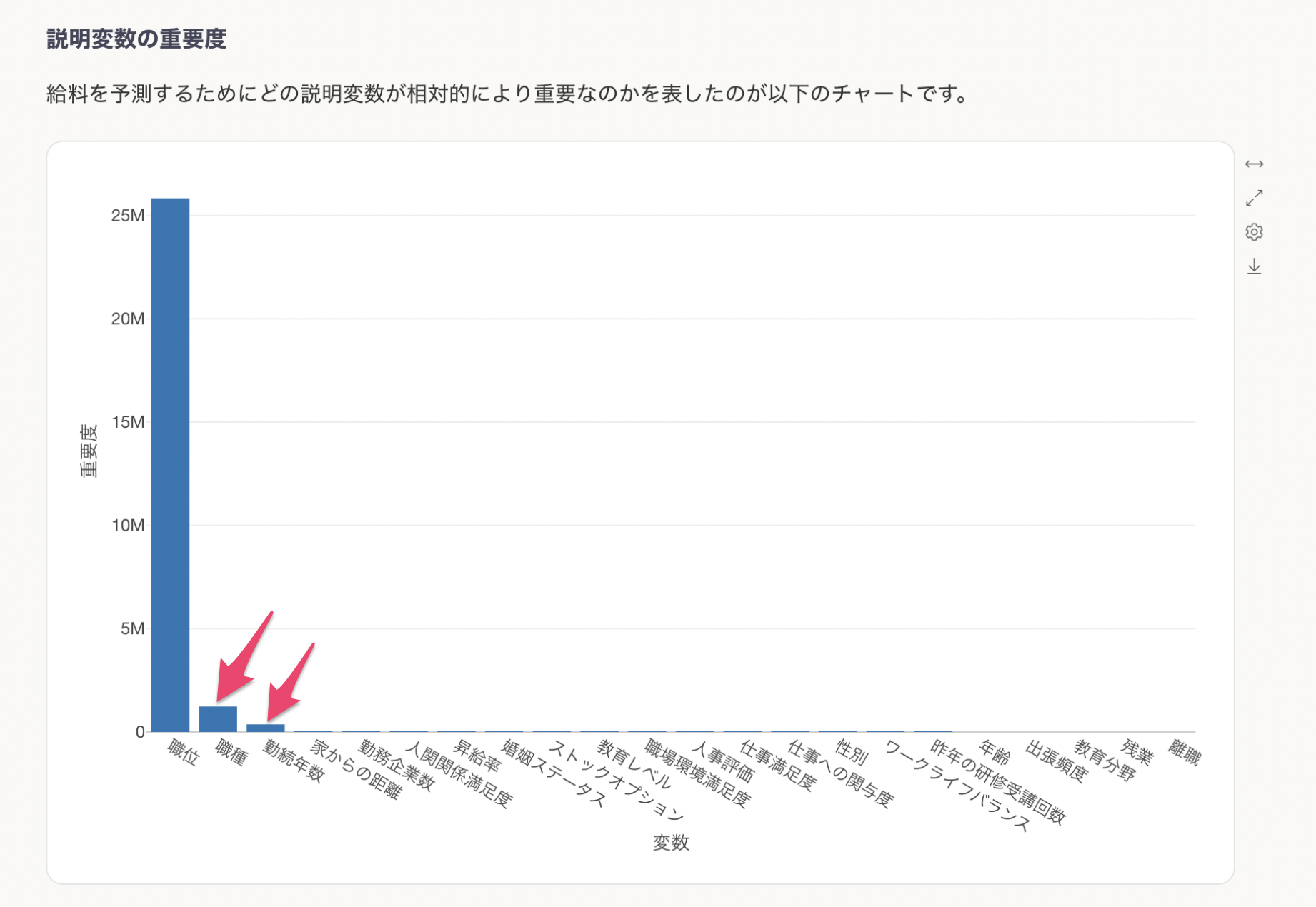
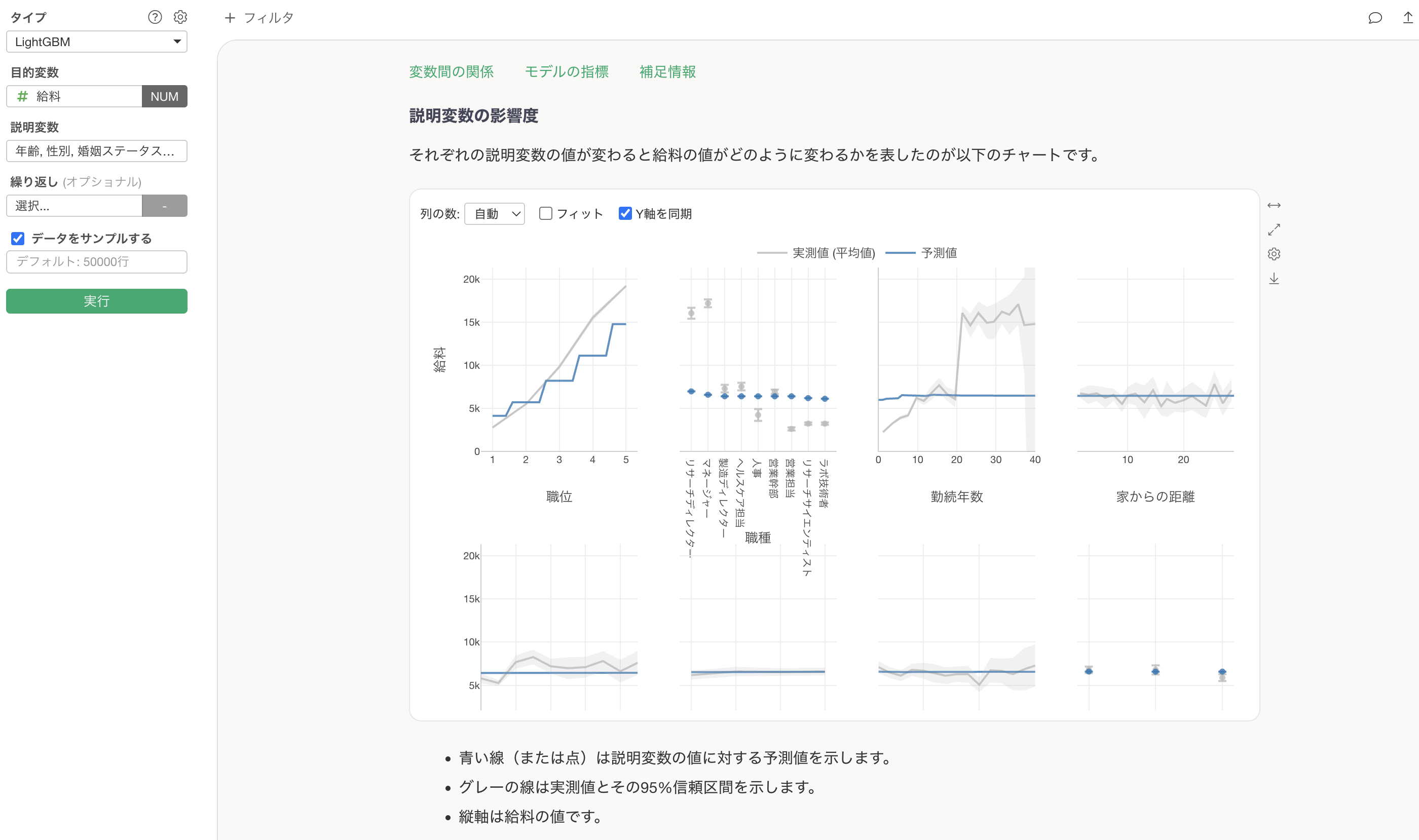
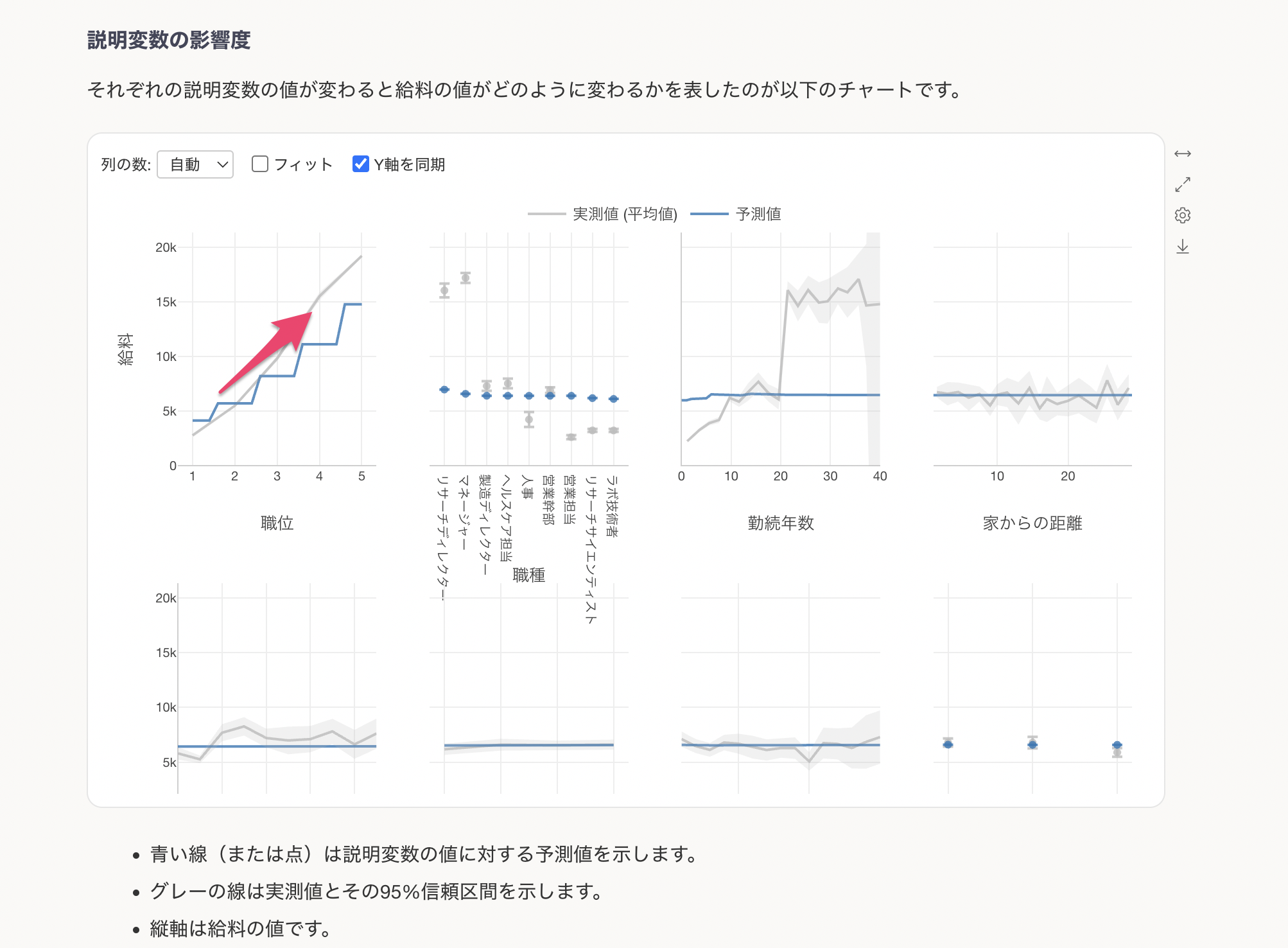
説明変数の影響度
説明変数の影響度のセクションでは、それぞれの変数の値が変わると、目的変数の値はどのように変わるのかがわかります。これはPartial Dependence Plot(PDP)と呼ばれる手法で可視化されています。
グレーの線は実測値を、青い線は予測値(モデルが推定した値)を示しています。例えば、職位ごとの給料の変化を見ると、職位が上がるにつれて給料が大きく上昇する傾向が確認できます。
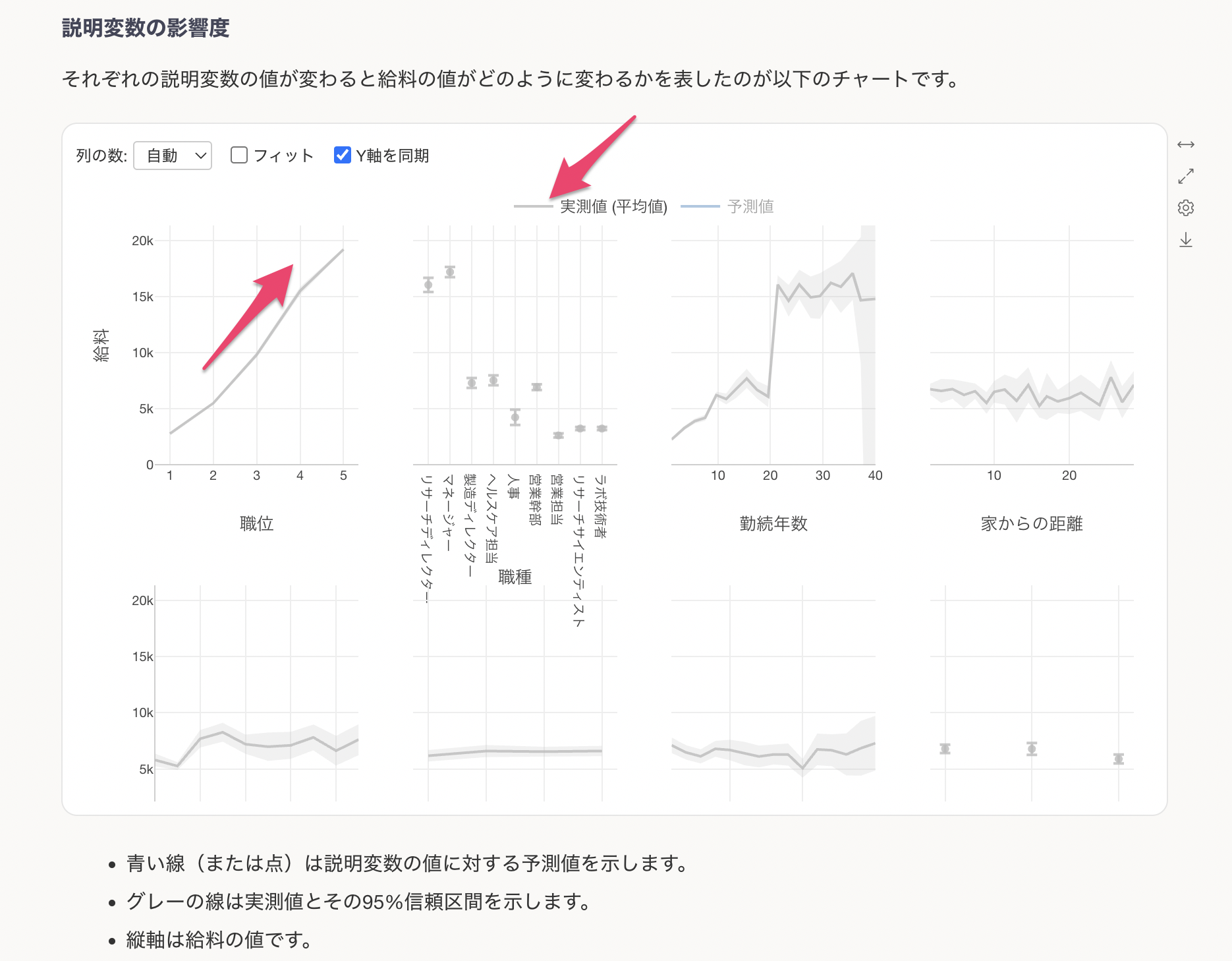
青い線は予測値を表します。
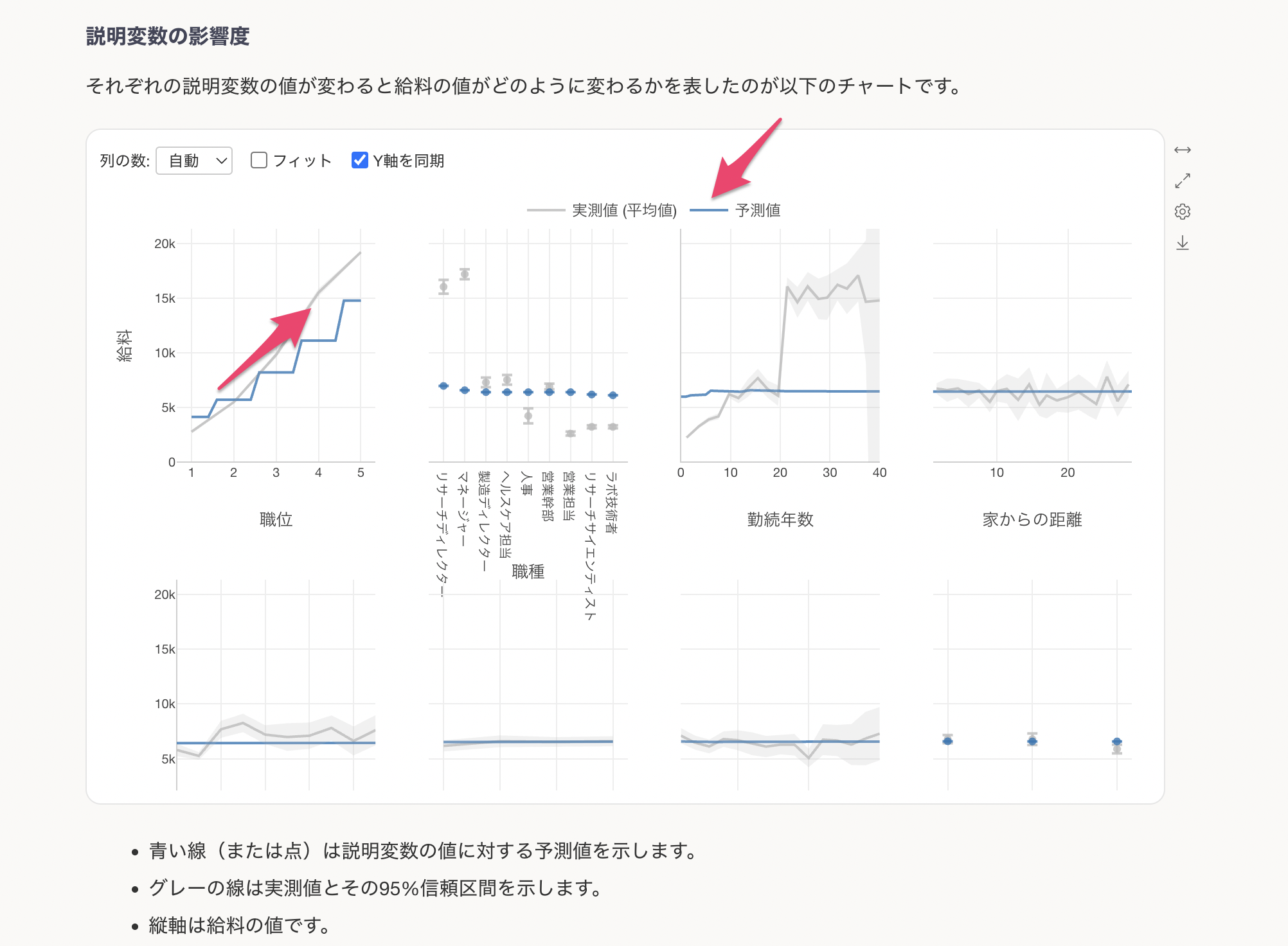
職位が上がると給料が高くなる関係があることがわかります。
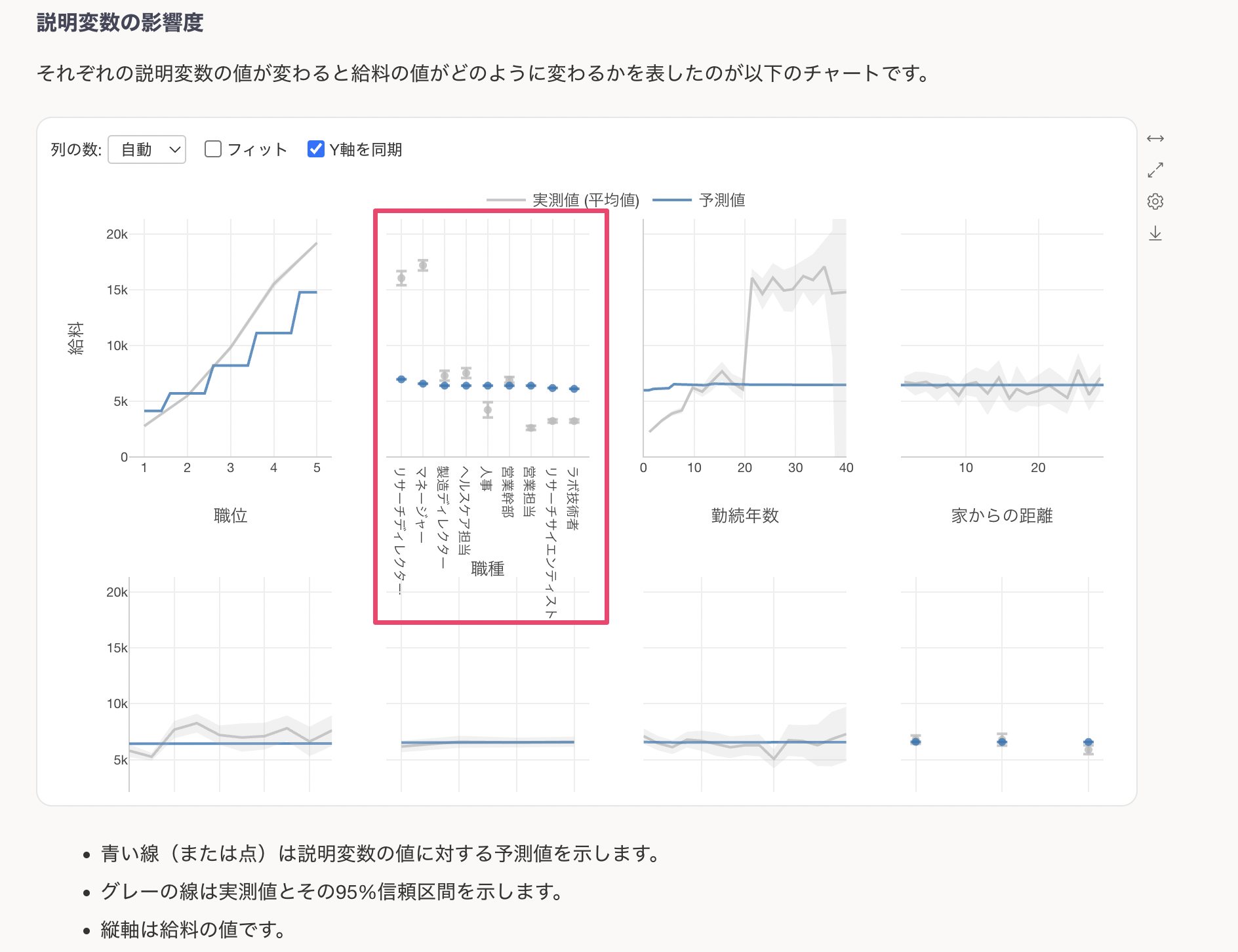
カテゴリカル変数(文字列型の変数)の場合は、カテゴリーごとの予測値が表示されます。例えば、職種で見ると、他の職種に比べてリサーチディレクターとマネージャーの給料が若干高くなることがわかります。
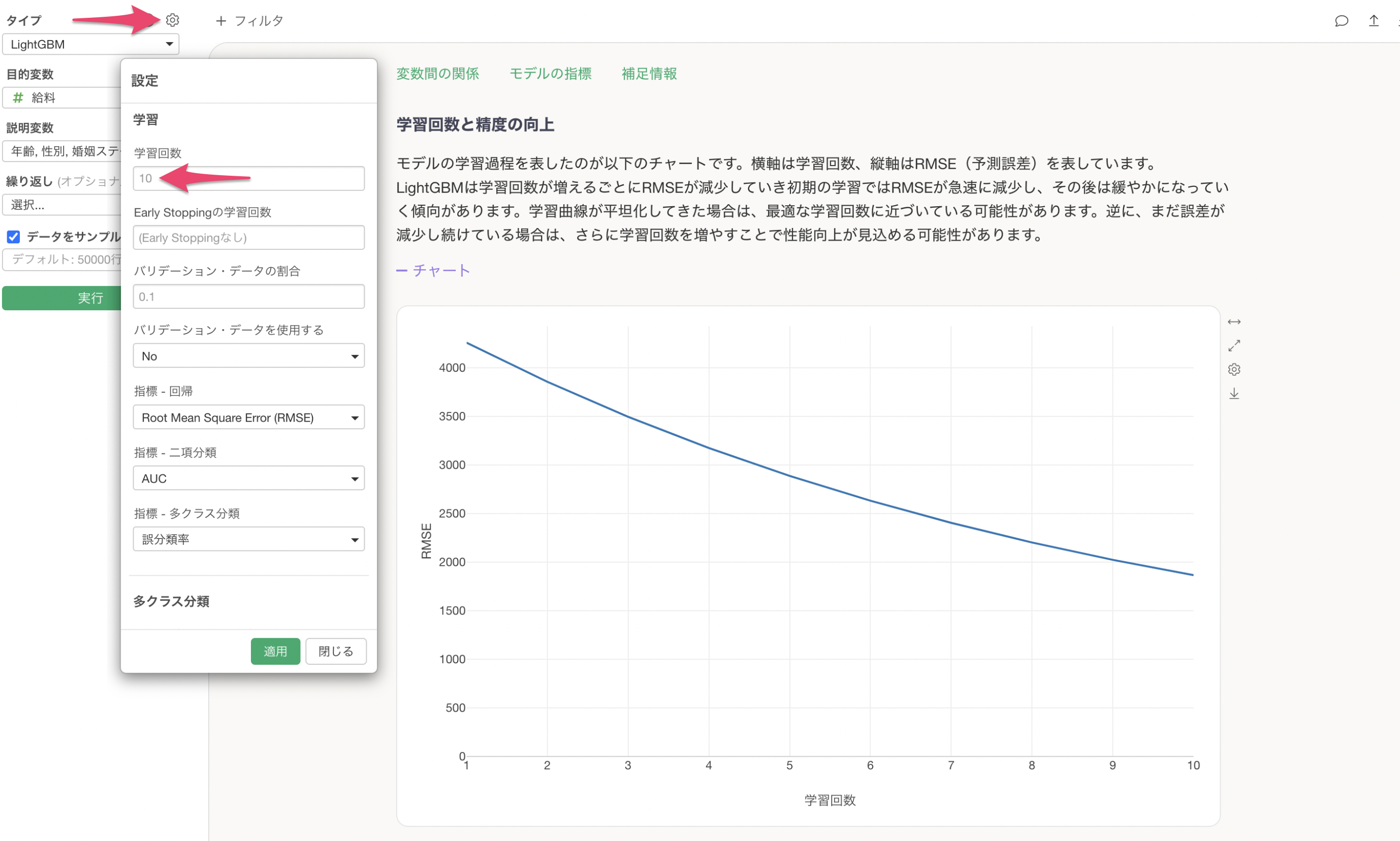
学習回数と精度の向上
学習回数と精度の向上のセクションでは、学習回数(作成された決定木の数)によって、予測精度がどれだけ向上したかが確認できます。
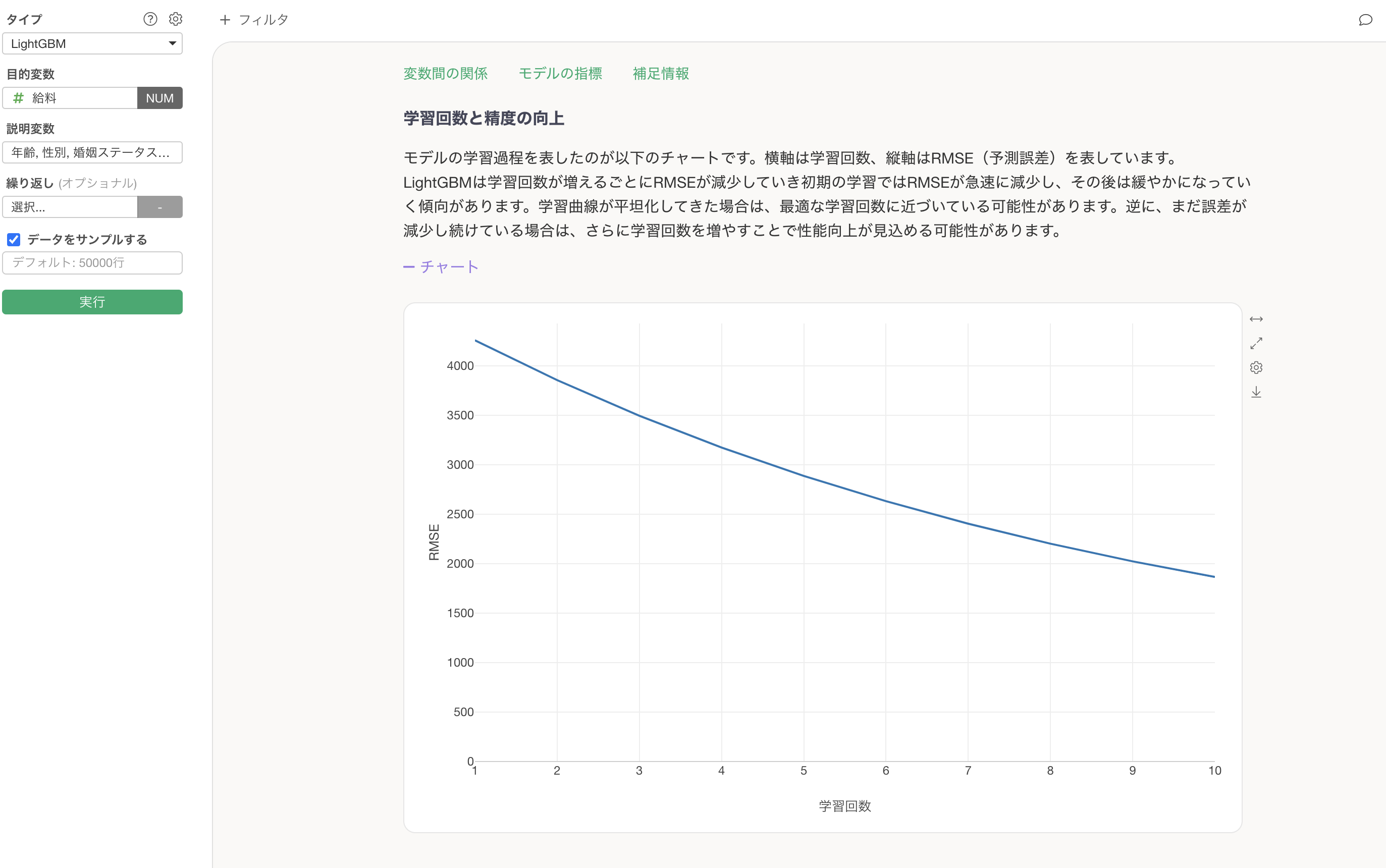
デフォルトの学習回数は10回になっていますが、プロパティから変更いただけます。また、それ以外にもEarly Stoppingの学習回数(学習した結果、予測精度が向上しない時に打ち切る回数)や、学習の際に使用する指標も変更できます。
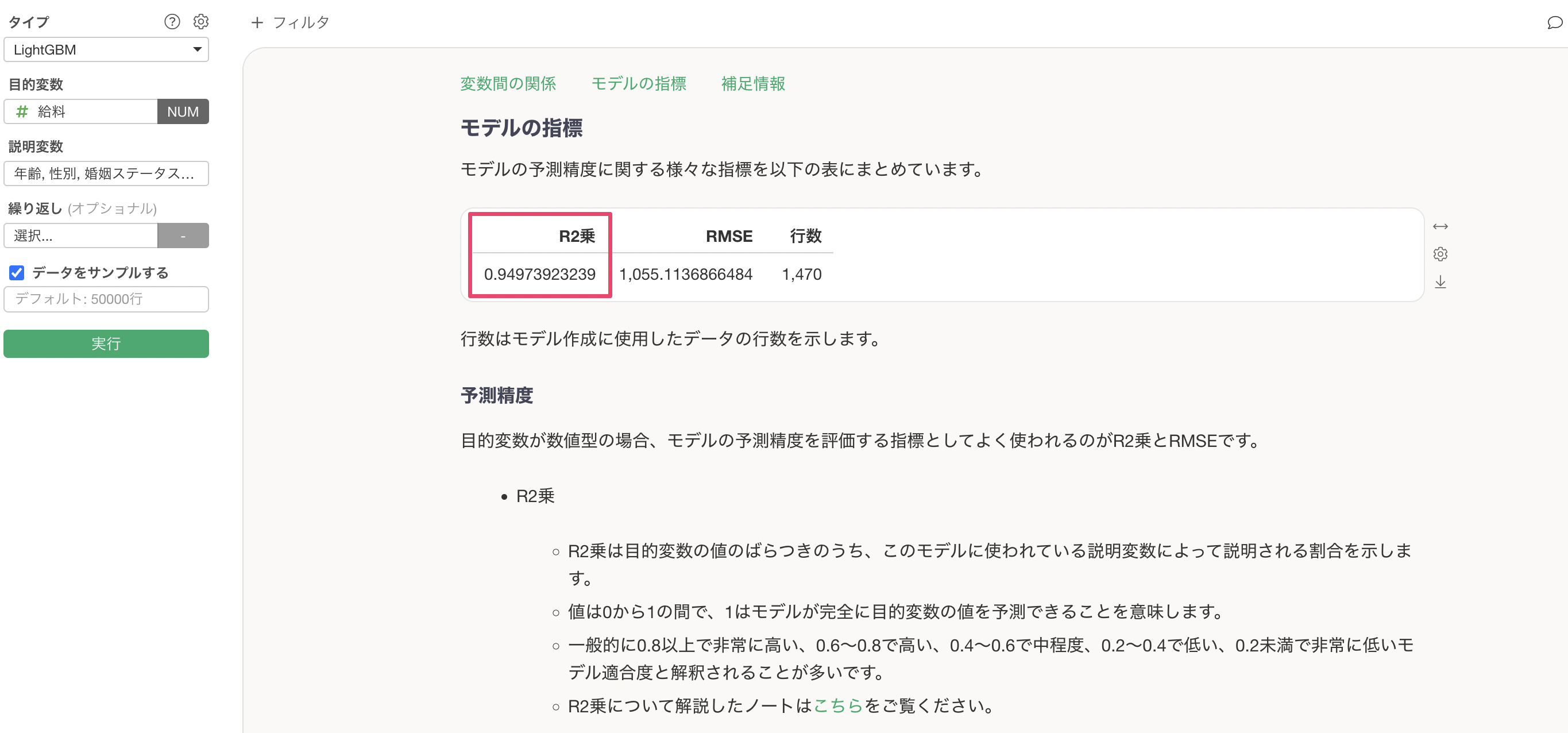
モデルの予測精度
モデルの指標のセクションでは、この予測モデルの予測精度を確認できます。
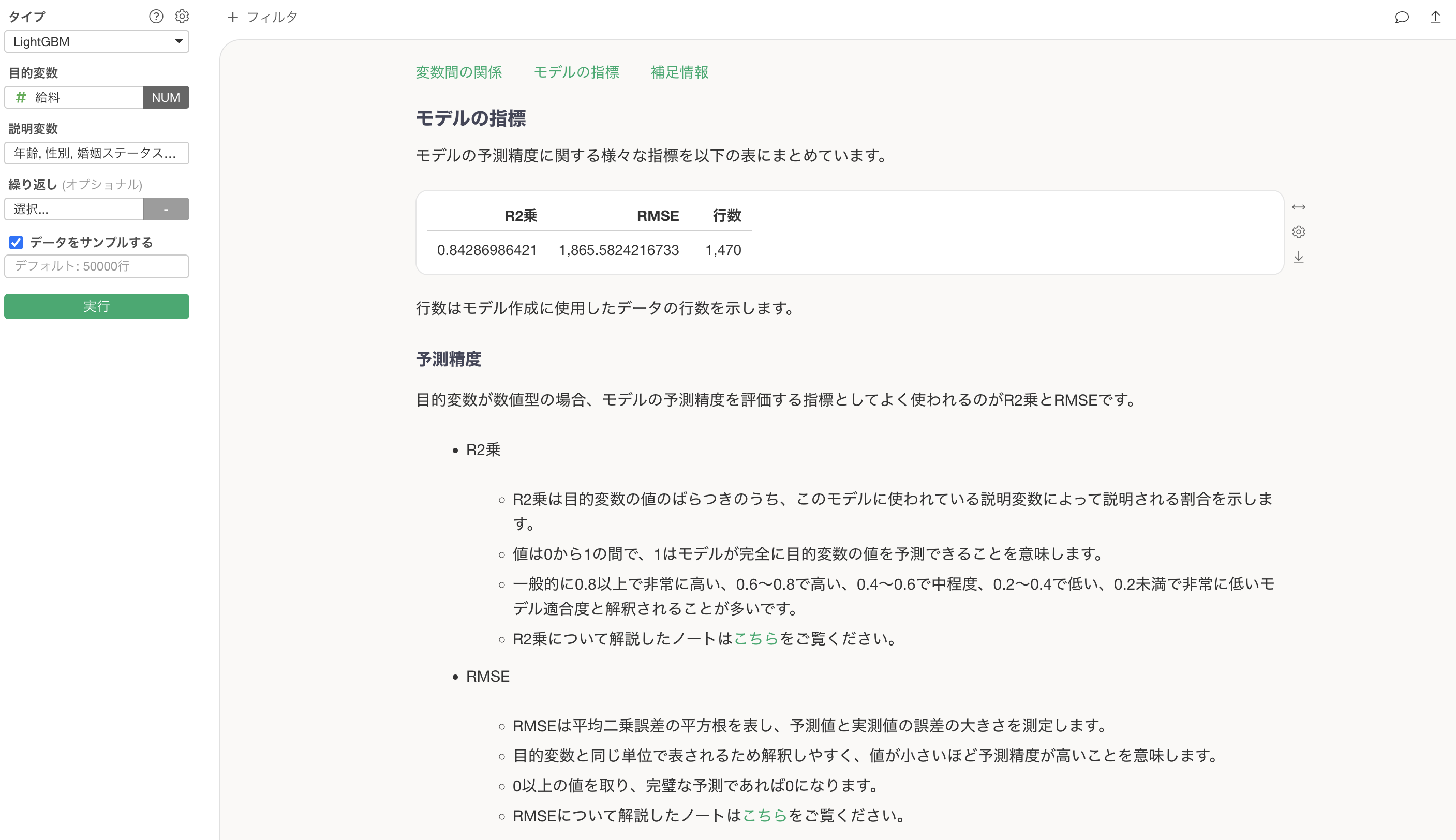
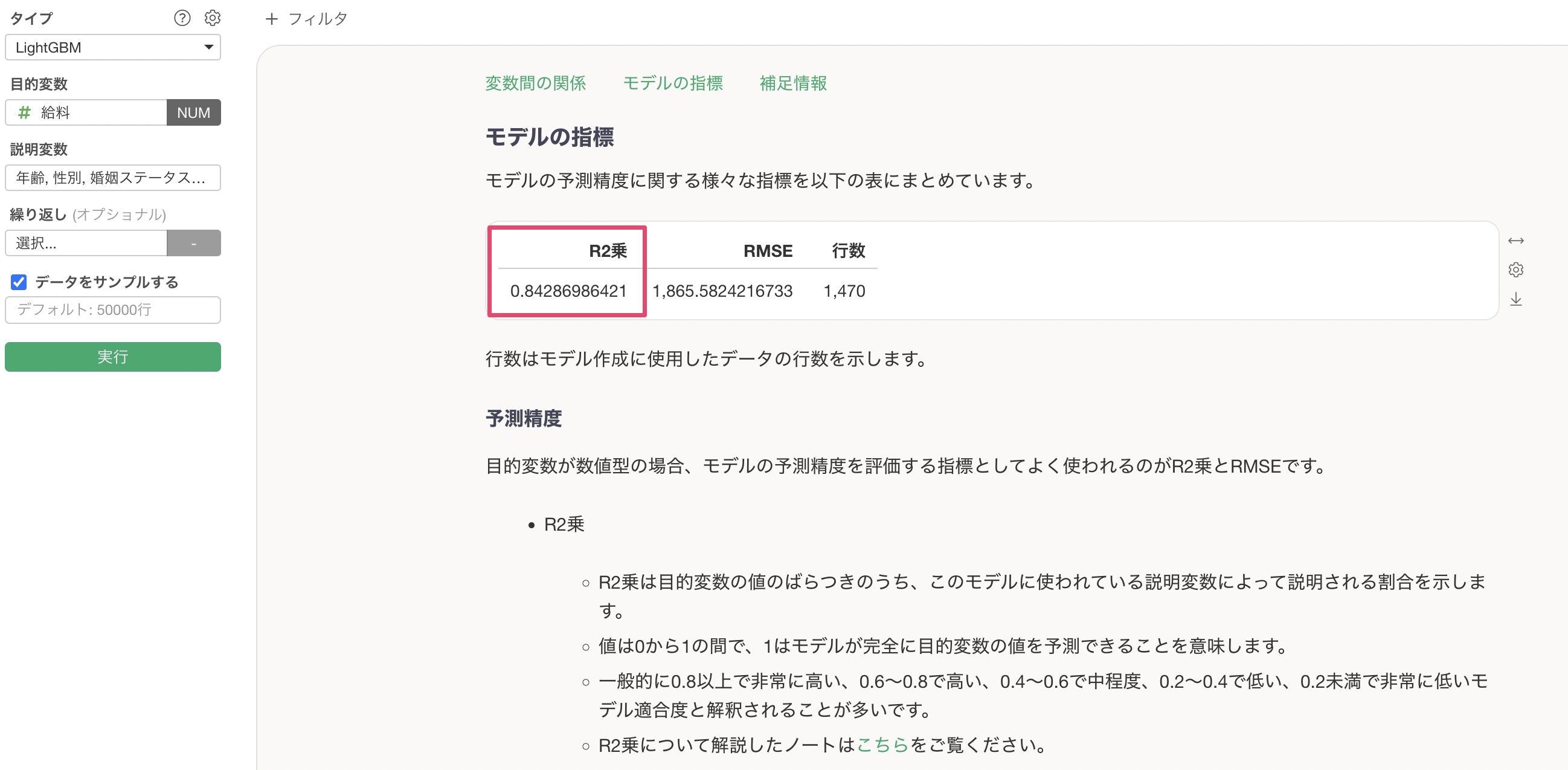
R2乗はデータの平均からのばらつきをモデルが説明できている割合の指標で、0から1の間の値を取ります。1に近ければ近いほど、モデルがデータのばらつきをよく説明できていることを示します。
今回はR2乗が0.84のため、データのばらつきの84%をこのモデルで説明できていることになります。
先ほど紹介をした学習回数を10回から20回に増やしてみて、予測精度が向上するかを確認します。
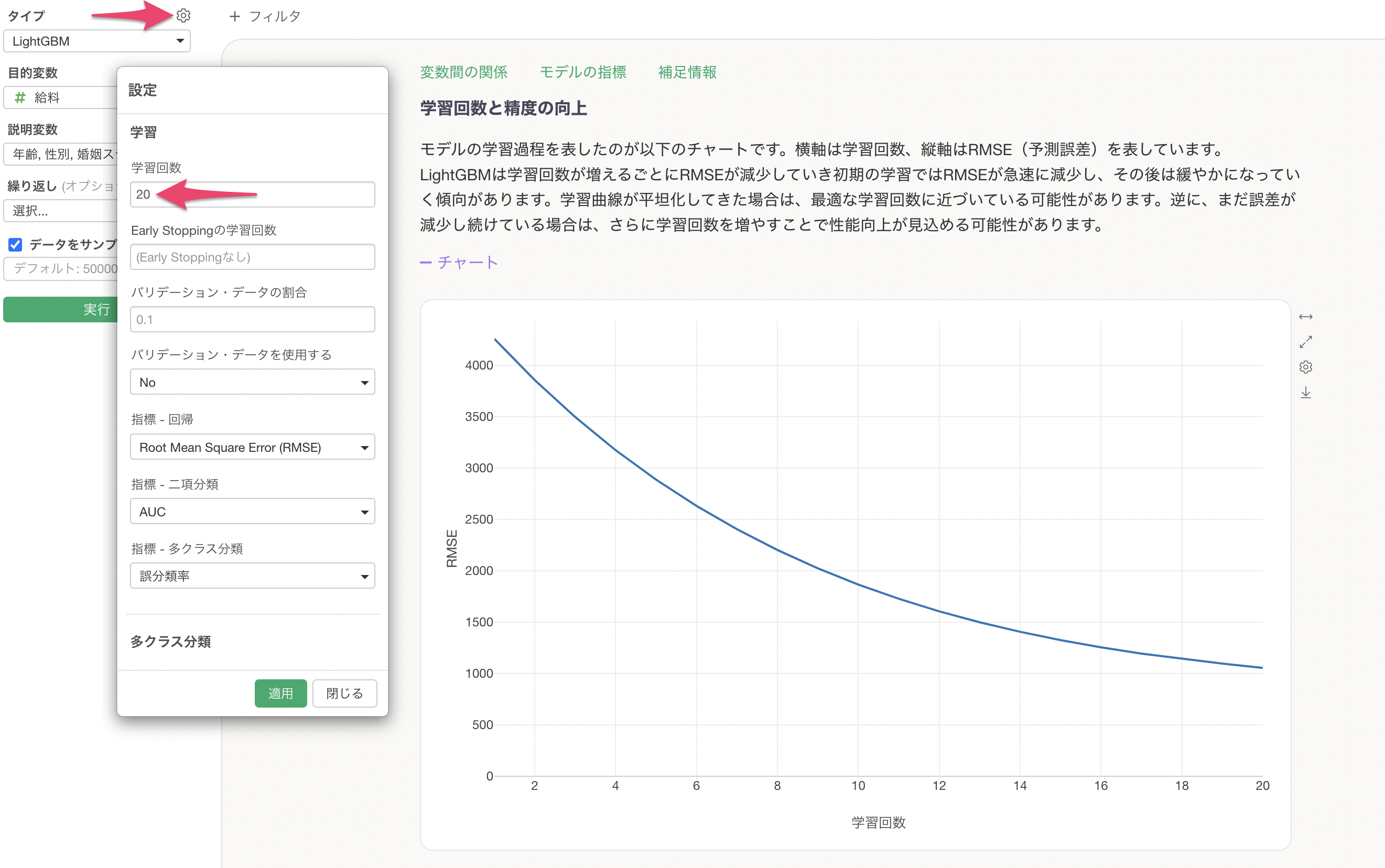
学習回数を増やすことでRMSE(予測と実測値の誤差の大きさ)が減少していることが確認できます。
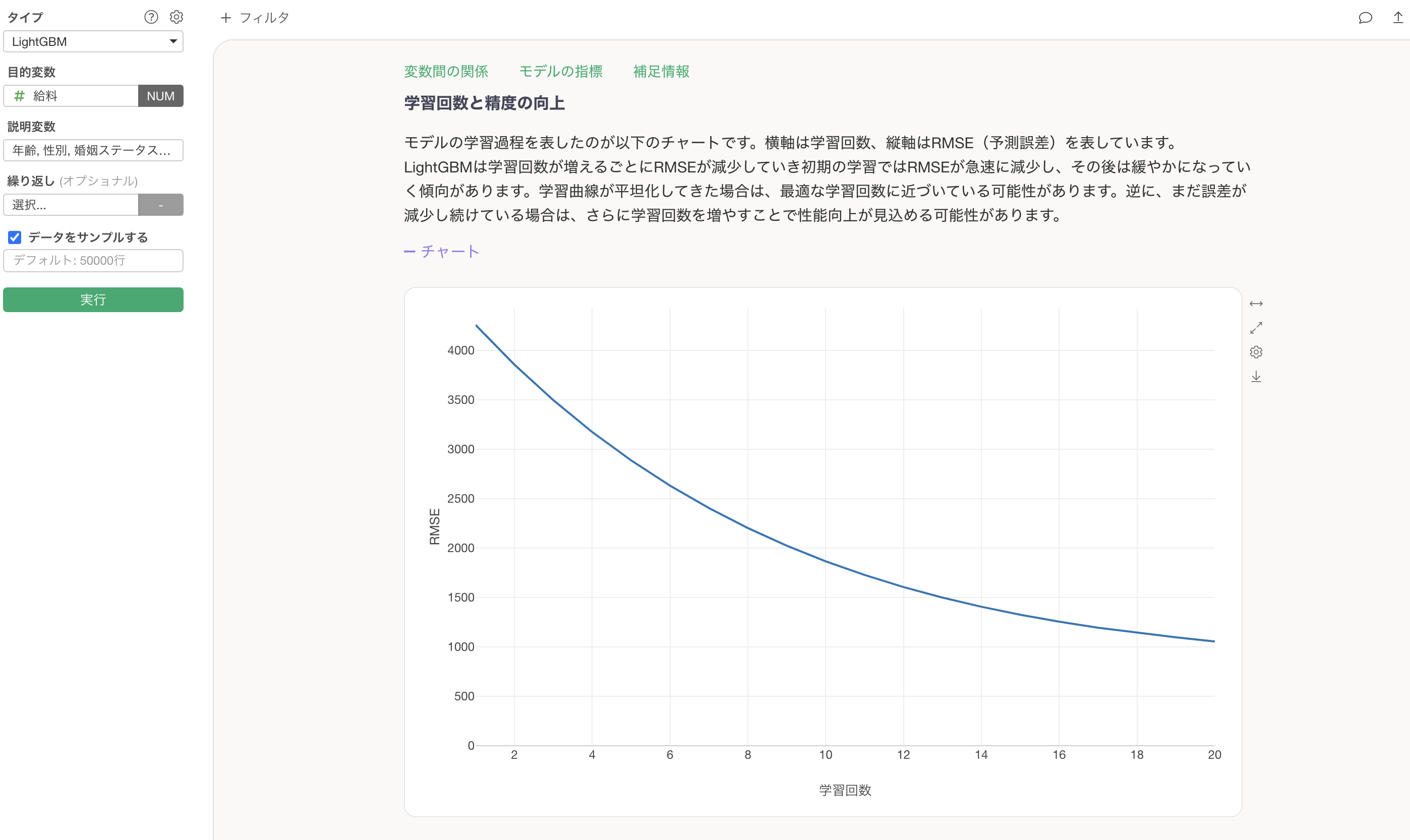
さらには、R2乗も「0.84」から「0.949」と上がっているため、学習回数を増やすことで予測精度が向上していることがわかります。
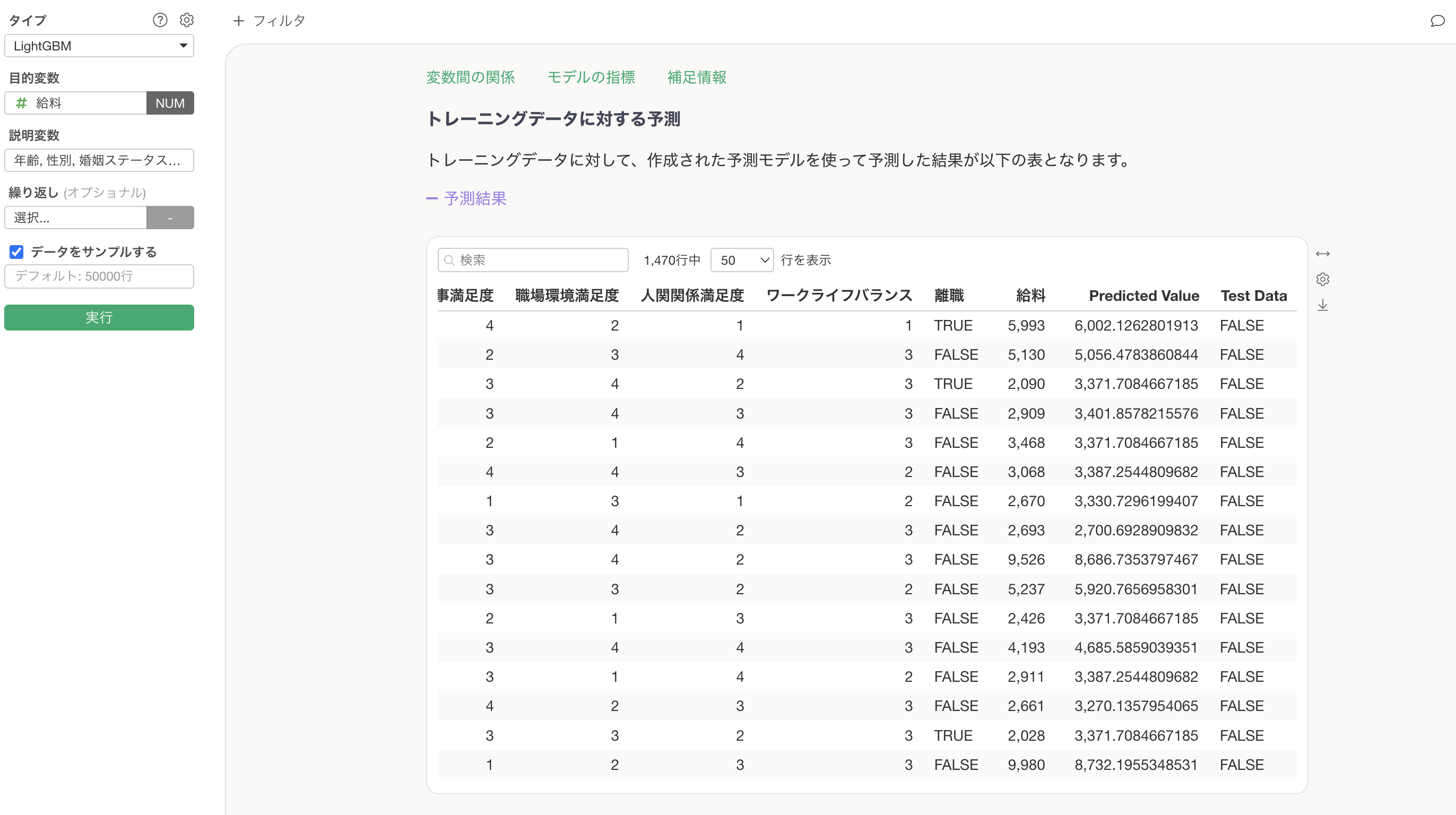
トレーニングデータに対する予測
トレーニングデータに対する予測のセクションでは、モデルに使用したデータと予測値をテーブル形式で確認できます。目的変数である給料と、このモデルで算出された予測値(Predicted Value)を並べて確認することで、モデルの予測がどの程度正確かを個別のデータレベルで把握できます。
まとめ
LightGBMはMicrosoftが開発した勾配ブースティングフレームワークで、XGBoostと同様に複数の決定木を順に作成して予測精度を高めていくアルゴリズムです。Exploratoryのアナリティクスビューでは、タイプに「LightGBM」を選択し、目的変数と説明変数を指定して実行するだけで、変数重要度や説明変数の影響度、学習の過程、予測精度などの結果をすぐに確認することができます。
LightGBMはLeaf-wise成長戦略やGOSS、EFBといった独自技術により、XGBoostと比較してより高速な学習とメモリ効率の良さを実現しています。特に大規模なデータを扱う場合にその違いが顕著になるため、データの規模や分析の目的に応じてXGBoostと使い分けることで、より効率的にデータ分析を進めることができます。
LightGBMに関するよくある質問
Q: 予測タブで表示されている実測値はどのように求められているのですか?
予測タブの実測値はそれぞれの予測変数のデータタイプによって表示が異なります。 詳しくはこちらのノートをご覧ください。
Q: 予測タブで表示されている予測値はどのように求められているのですか?
予測値のチャートはPartial Dependence Plot(PDP)と呼ばれるもので、注目している変数の値を変化させたときに、予測結果がどう変わるかを可視化したチャートとなります。詳しくはこちらのノートをご覧ください。
Q: カテゴリーを予測したモデルを使って新しいデータに対して予測をした際に、予測ラベルに欠損値が出てしまう
カテゴリー列の値を予測するモデルを作っていて、そのモデルを使って新しいデータに対して予測をした際に、予測ラベルに欠損値が出てしまうことがあります。
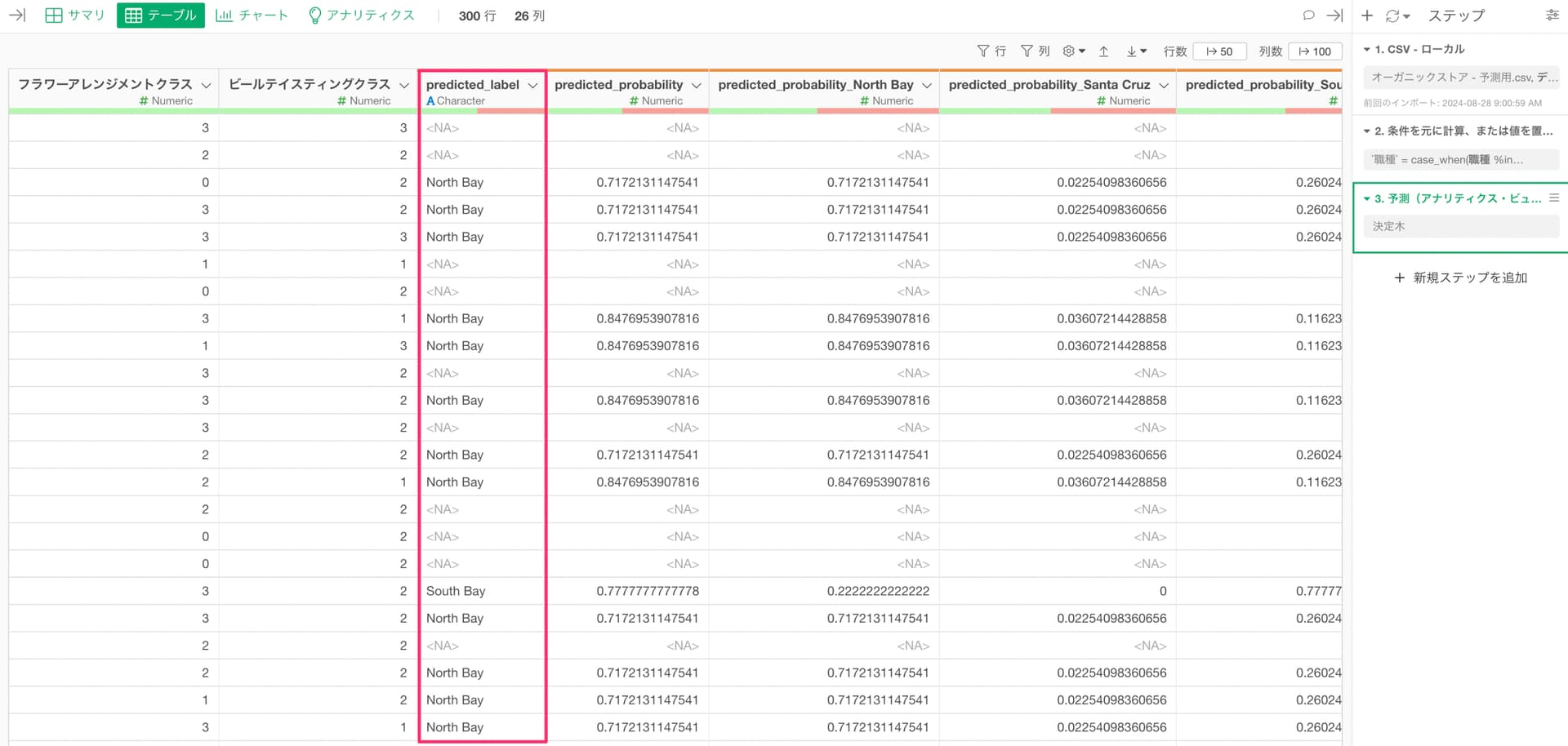
主な原因としては、以下の2つが考えられます。
- 予測モデルの作成時には予測変数側に無かったカテゴリー値が予測対象の新しいデータ側で存在している。
- 予測対象の新しいデータ側で予測変数に使われていた列で欠損値がある。
予測モデルの作成時には予測変数側に無かったカテゴリー値が予測対象の新しいデータ側で存在しているといったケースに該当する場合は、今後もモデルで予測をする際に、そのカテゴリーが含まれる可能性がある時には、モデル側にもそのカテゴリの値があるように組み込んでいただくと良いかもしれません。