トピックモデルを実施したときに、結果をうまく解釈できないときの対処法
文書(テキスト)データがあったときに、単語の出現頻度と、それぞれの単語が一緒に利用されるパターンをもとに、それぞれの文書をトピックに分類するトピックモデルという手法があります。(トピックモデルの詳細はこちらからご確認いただけます)
トピックモデルを実行すると、各トピックを解釈するために役立つタブが表示され、例えば、重要語タブでは、それぞれのトピックの重要語が表示されます。
また、ドキュメントタブからは各文章のトピックの確率を確認できます。

多くの場合、これらのタブをいったりきたりすることで、各トピックへの理解を深められますが、これらのタブを確認するだけでは、それぞれのトピックがどのようなものであるかのイメージが湧きづらいこともあります。
そこで、このノートでは、トピックモデルを実施したときに、結果をうまく解釈できないときの対処法について紹介します。
想定される原因と解決のためのアプローチ
トピックモデルを実施したときに、その結果をうまく解釈できない原因を断定することは難しいものの、以下のような問題があることも少なくありません。
- つなぐ単語やストップワードを適切に設定できていない
- 文書全体の特徴を把握できていない
多くの場合、上記の問題は、アナリティクスの「単語のカウント」を利用することで解決が可能です。
そこで、ここからは「単語のカウント」を実行し、トピックモデルの実行結果への理解を深めていきます。(単語のカウントの詳細はこちらから確認いただけます)
前提
今回は1行が1人のアンケートの回答者を表すデータを使います。
 このデータはデータサイエンスに関するセミナーに対するアンケートの結果で、「セミナーをよりよくするための提案」に関する自由記述のテキストの列が存在しています。
このデータはデータサイエンスに関するセミナーに対するアンケートの結果で、「セミナーをよりよくするための提案」に関する自由記述のテキストの列が存在しています。

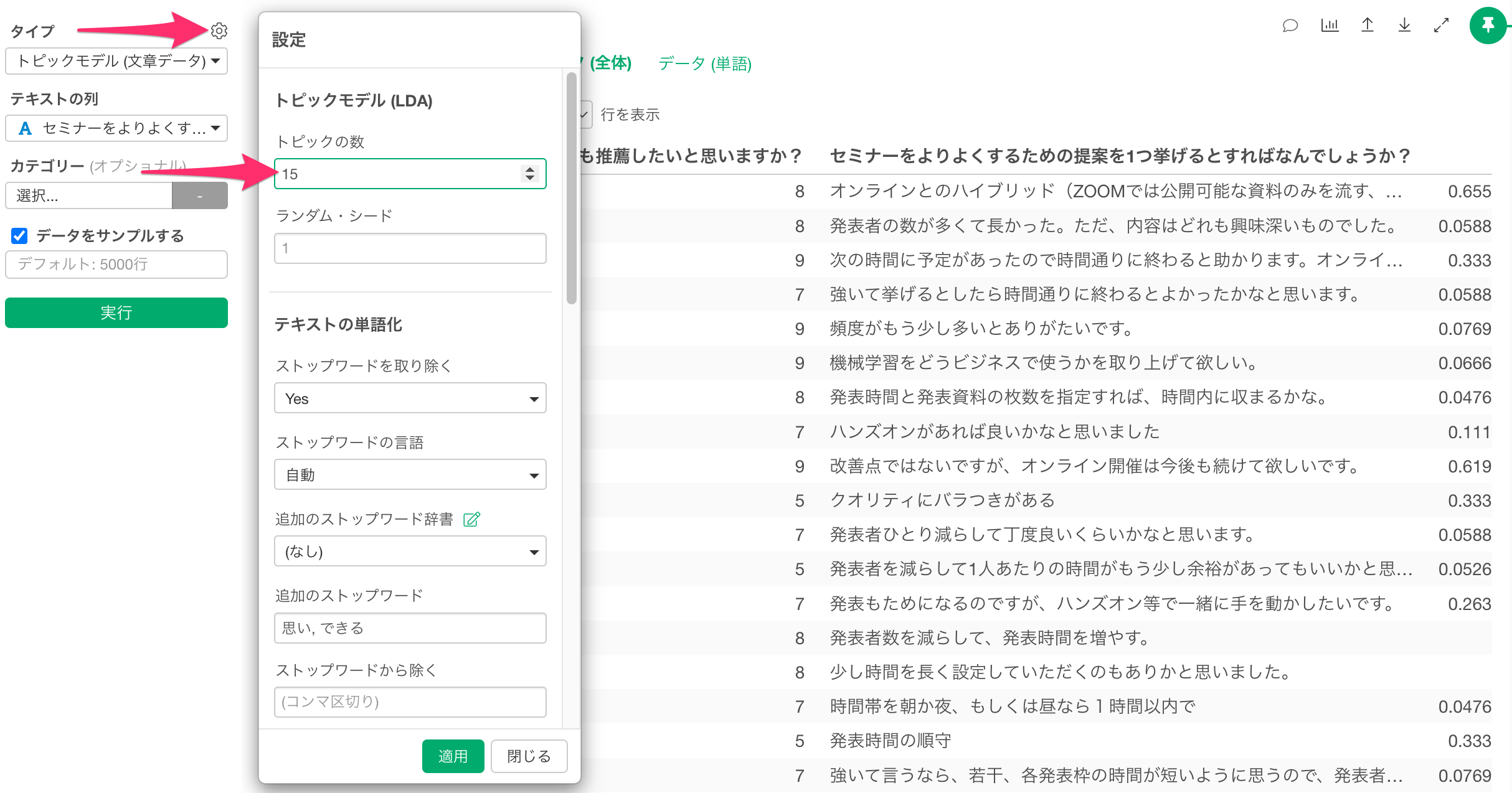
また今回はあらかじめ、トピックの数を5つに設定してトピックモデルを実行しています。
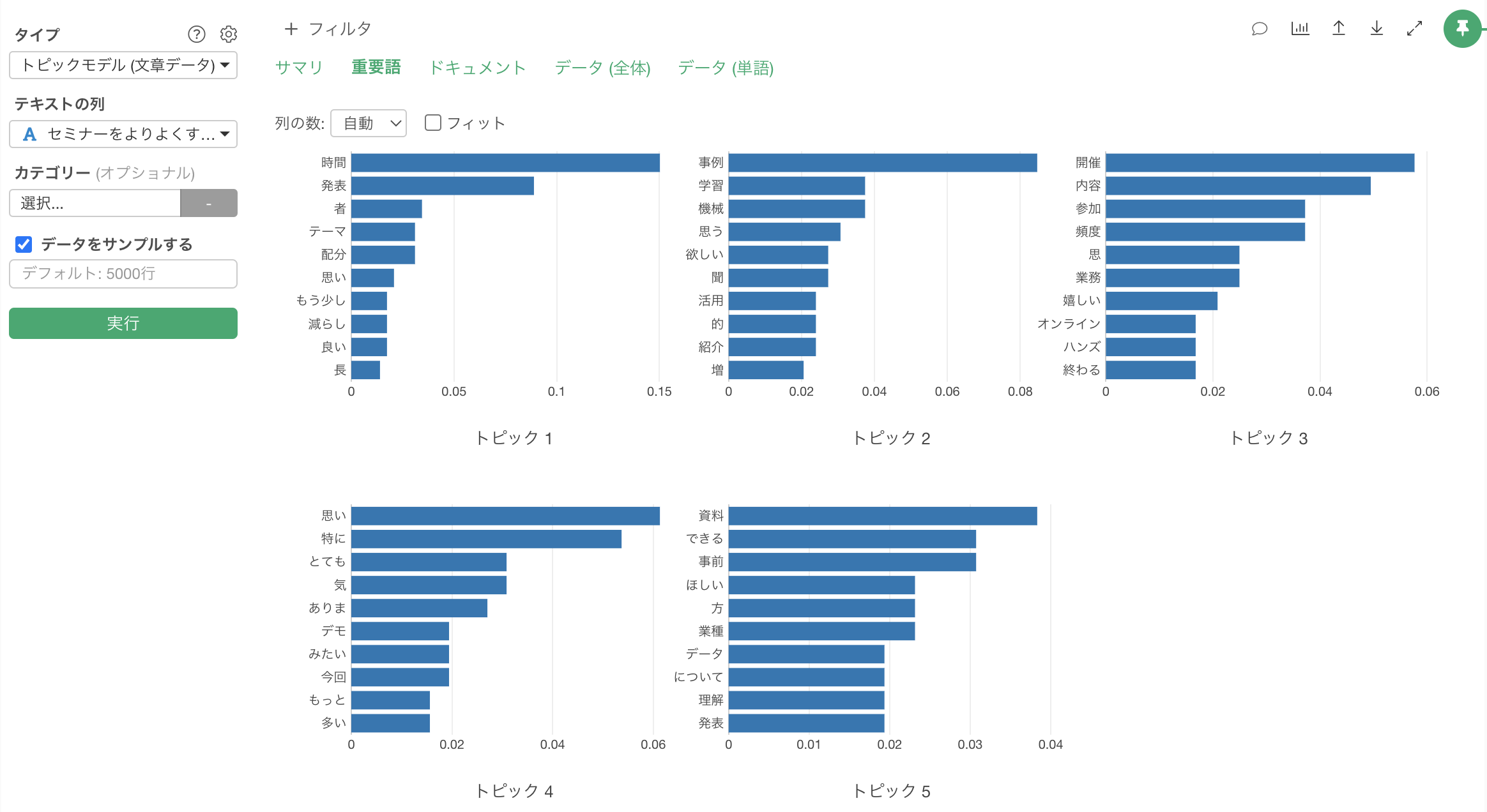
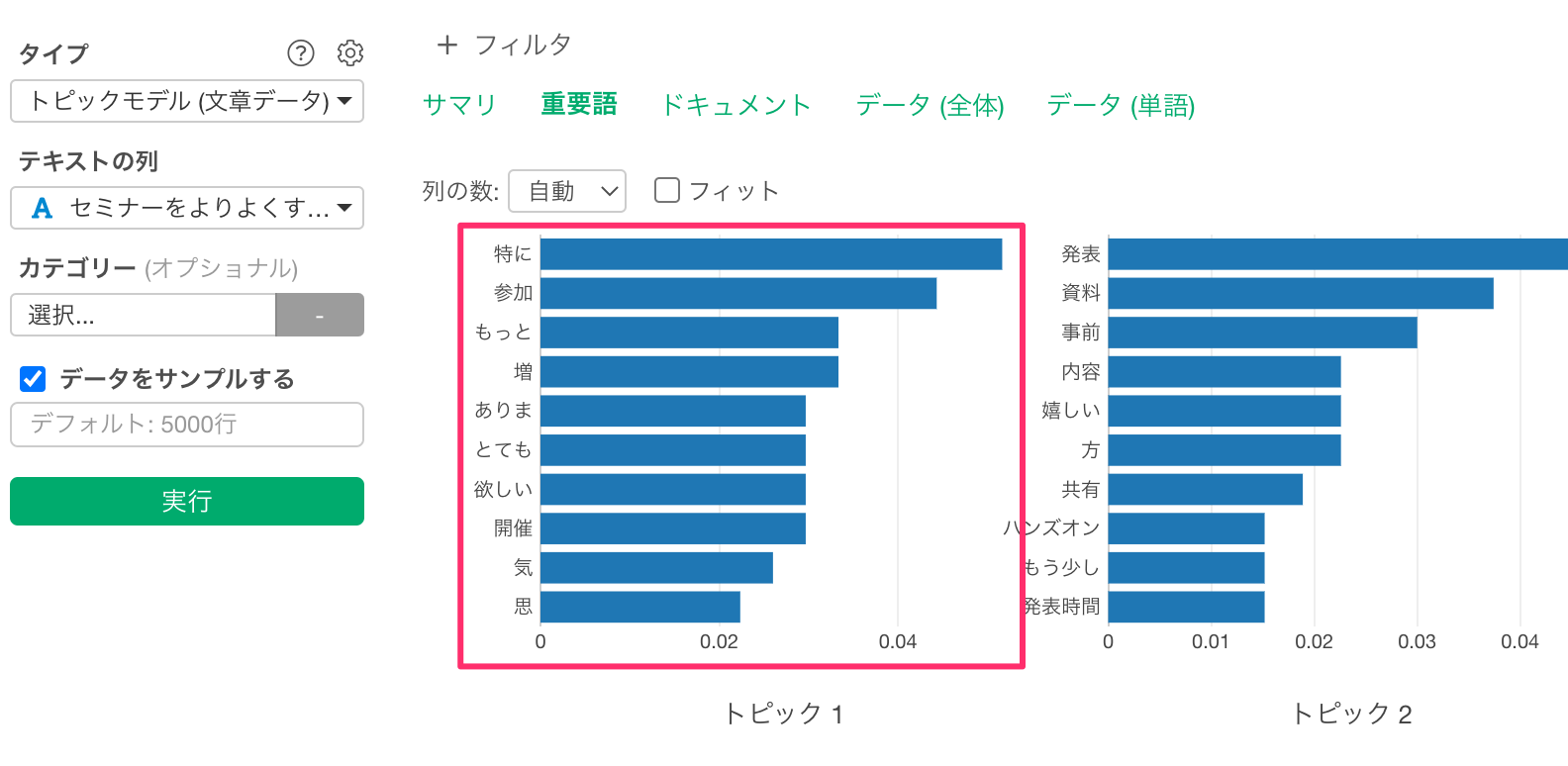
重要語のタブでは以下の結果が表示されています。
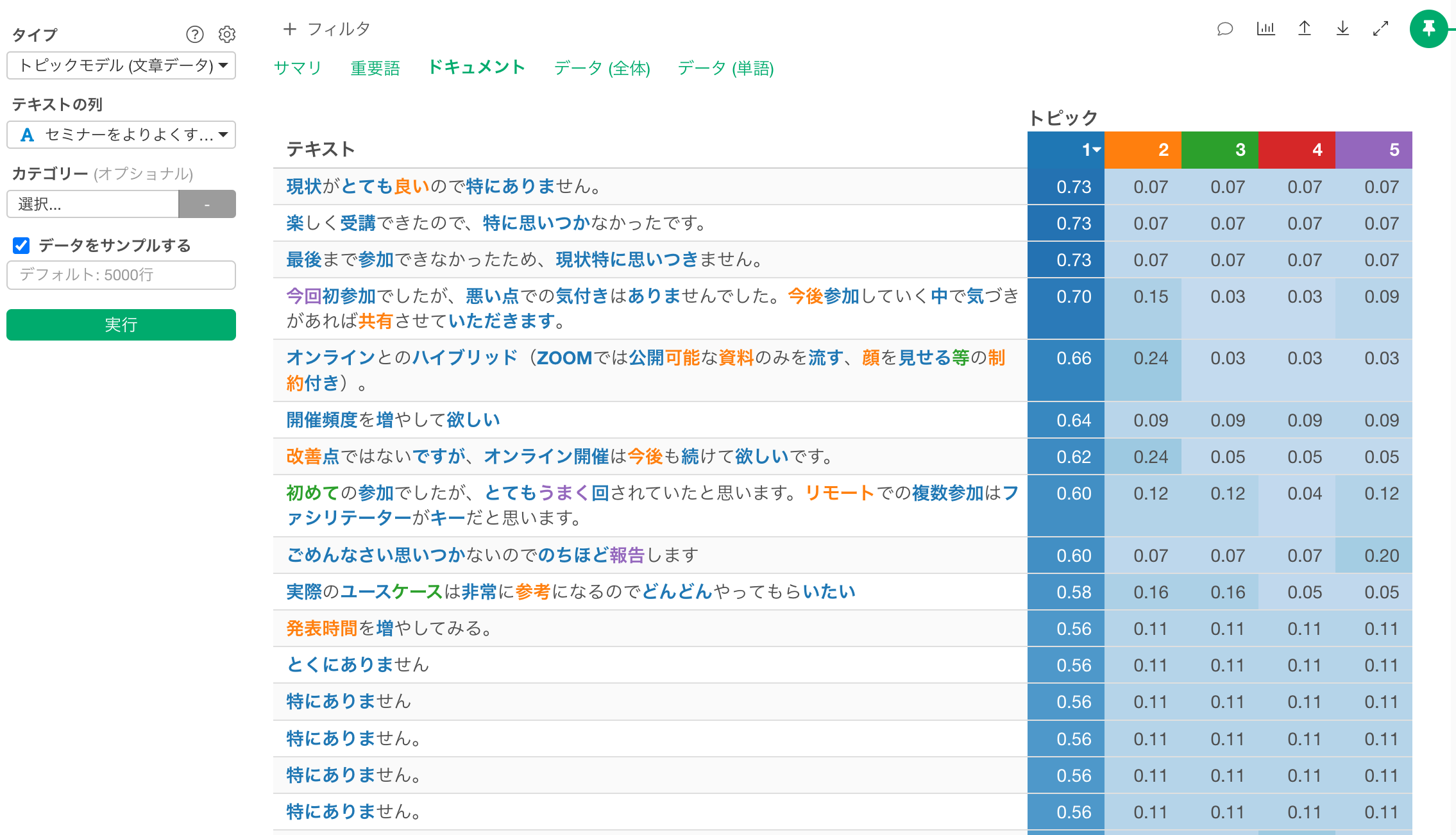
また、ドキュメントのタブでは以下のような結果が表示されています。
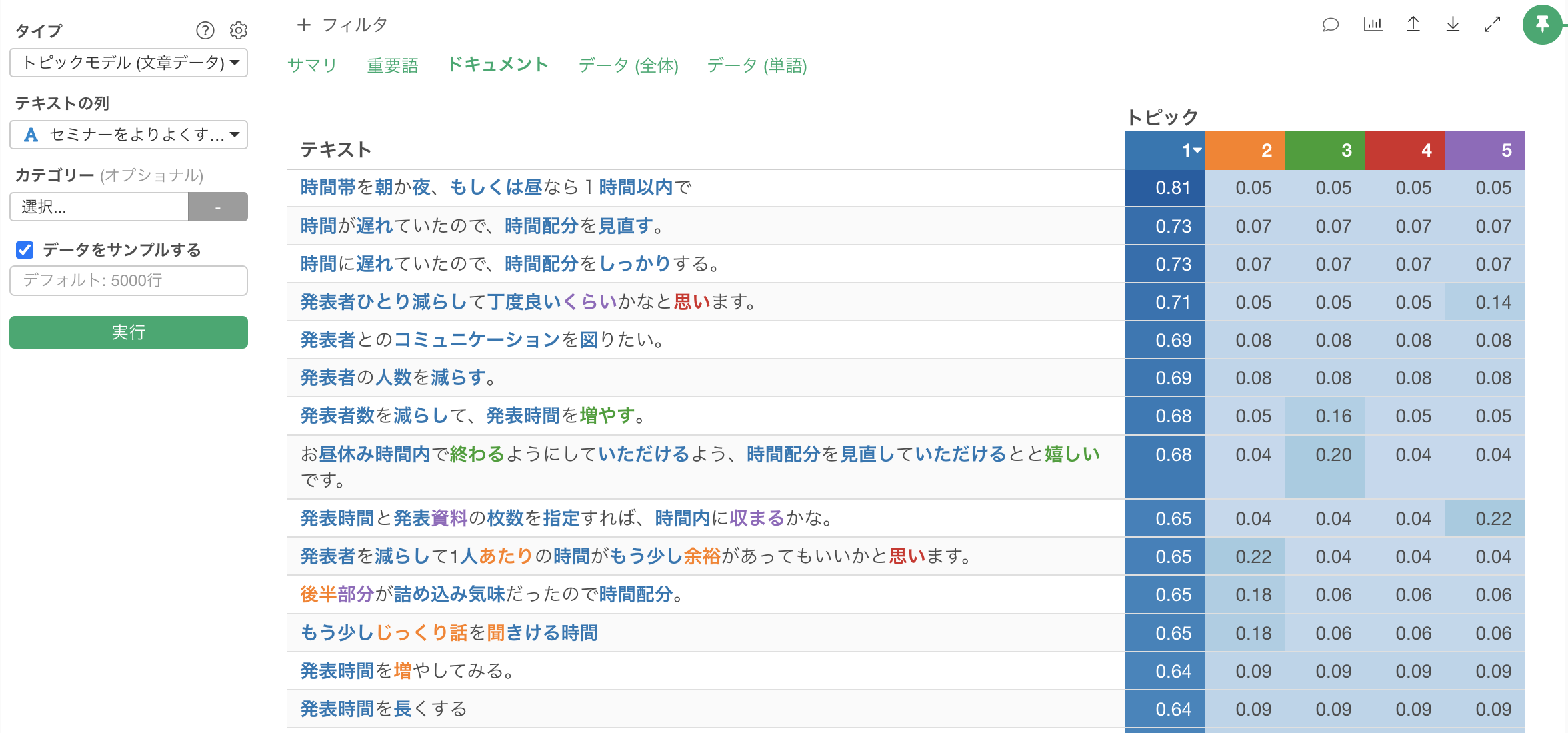
これらの情報をもとに、各トピックがどのようなものであるかは断片的に想定できるものの、それぞれのトピックがどのようなものでるあるかの確信が持てないこともあるかもしれません。
つなぐ単語やストップワードを適切に設定できていない
例えば、「者」という単語は、「発表者」として使われているのかもしれませんし、「思い」という単語はトピックを分類するうえでは、役に立たない情報かもしれません。
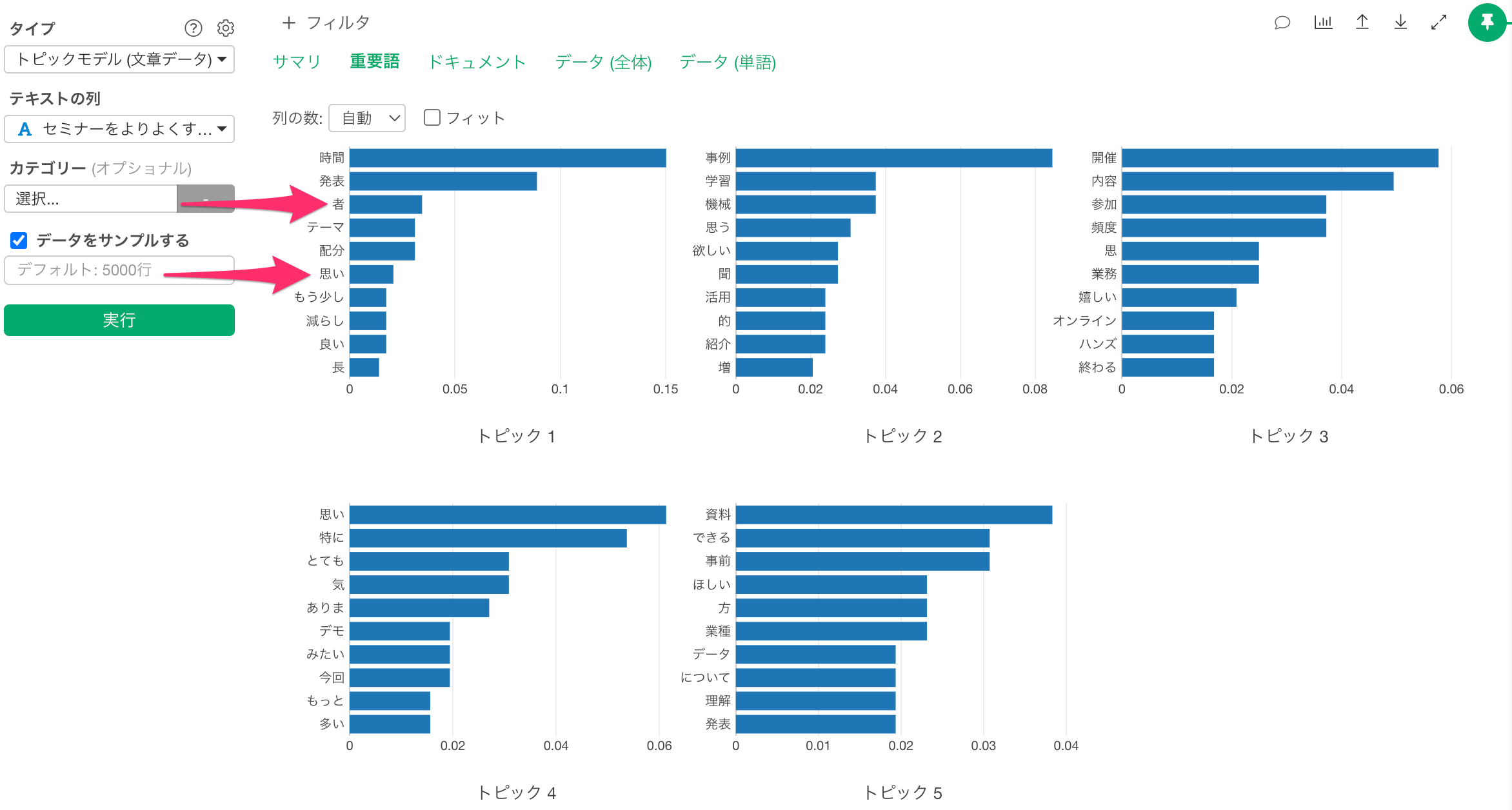
上記にあげたのは一例ですが、つなぐ単語やストップワードが適切に設定されていないと、トピックモデルの結果や、その解釈がわかりづらくなることがあります。
文書全体の特徴を把握できていない
今回利用しているデータは比較的にわかりやすい結果が出るようになっていますが、それでもトピック3の重要語を見るだけでは、うっすらとしかトピックのイメージがわかないかもしれません。
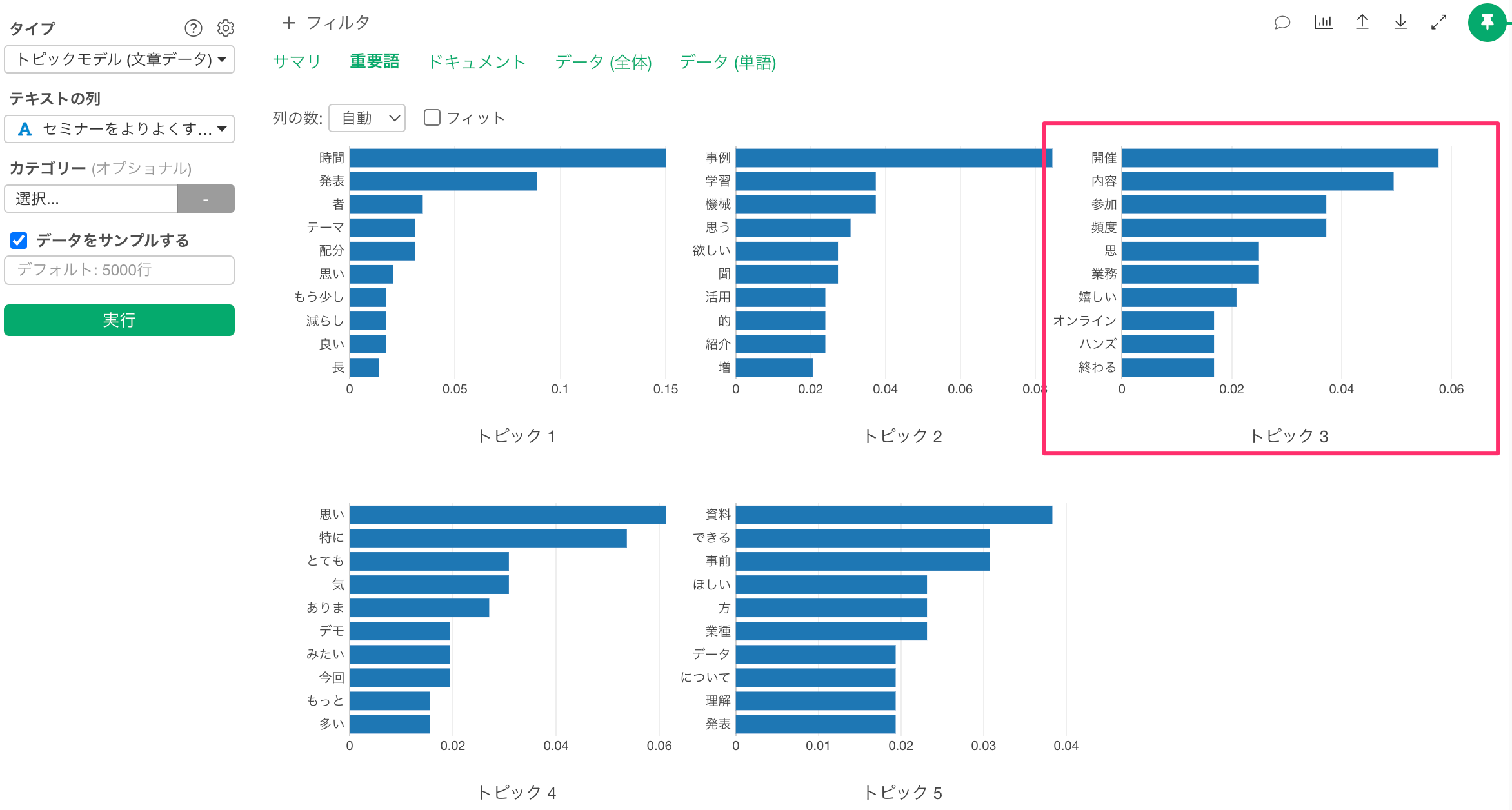
あるいはドキュメントタブを確認することで、「開催頻度」に関する話題が多いということは分かるものの、それ以外の話題も含まれているようにも見え、トピックに対する理解をさらに深められる余地がありそうです。
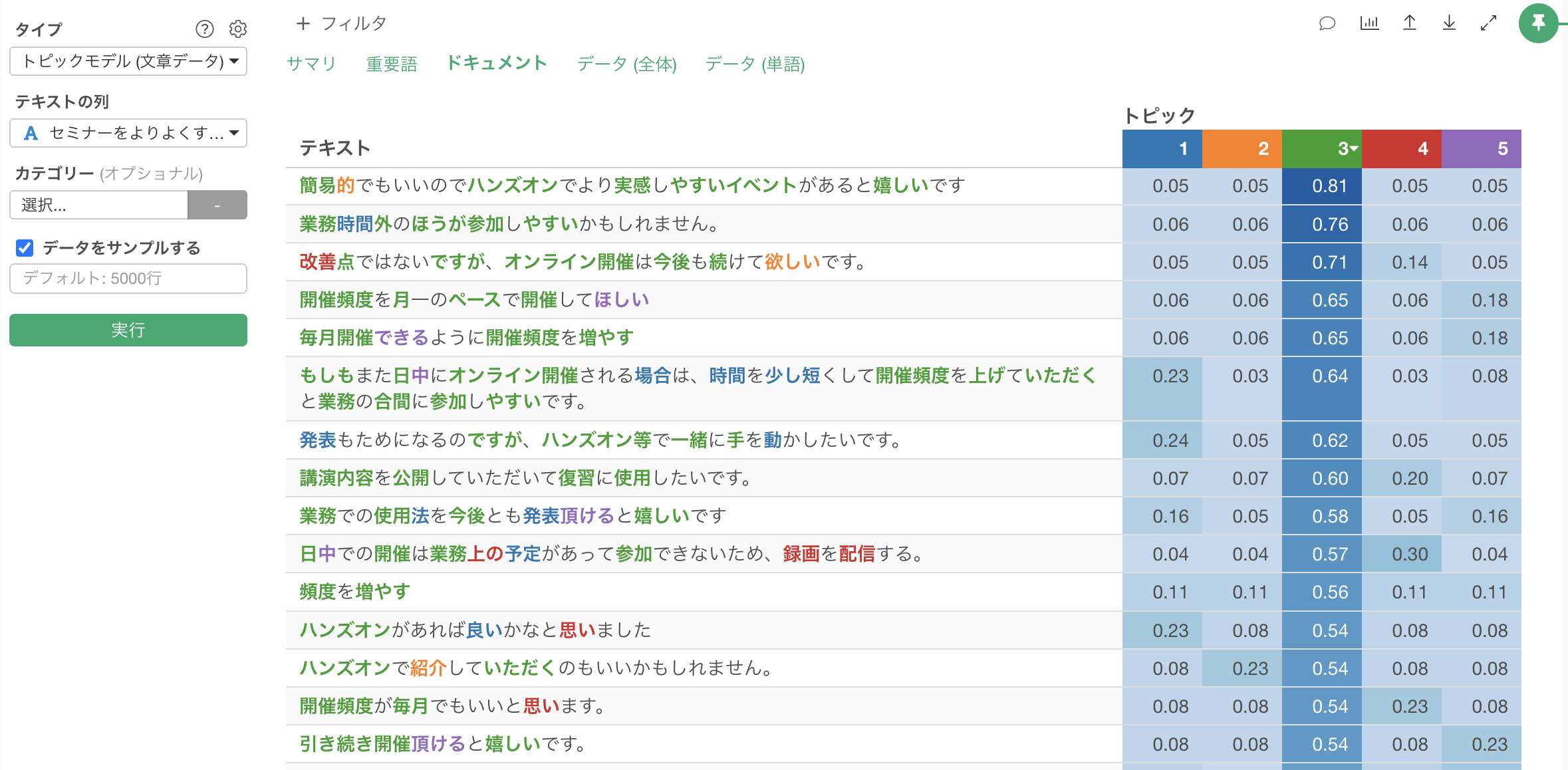
同じデータで「単語のカウント」を実行する
前述したように、トピックモデルに対する理解を深めたいときには、同じデータで「単語のカウント」を実行することが有用です。
そのため、事前に実施しているトピックモデルを複製します。
既存のトピックモデルを複製できたら、アナリティクスのタイプを「単語のカウント」に変更し、実行します。
単語のカウントの実行結果が表示されました。

「単語 - バー」タブに移動すると「思い」といった単語が全体を通して非常に多く利用されていることがわかります。
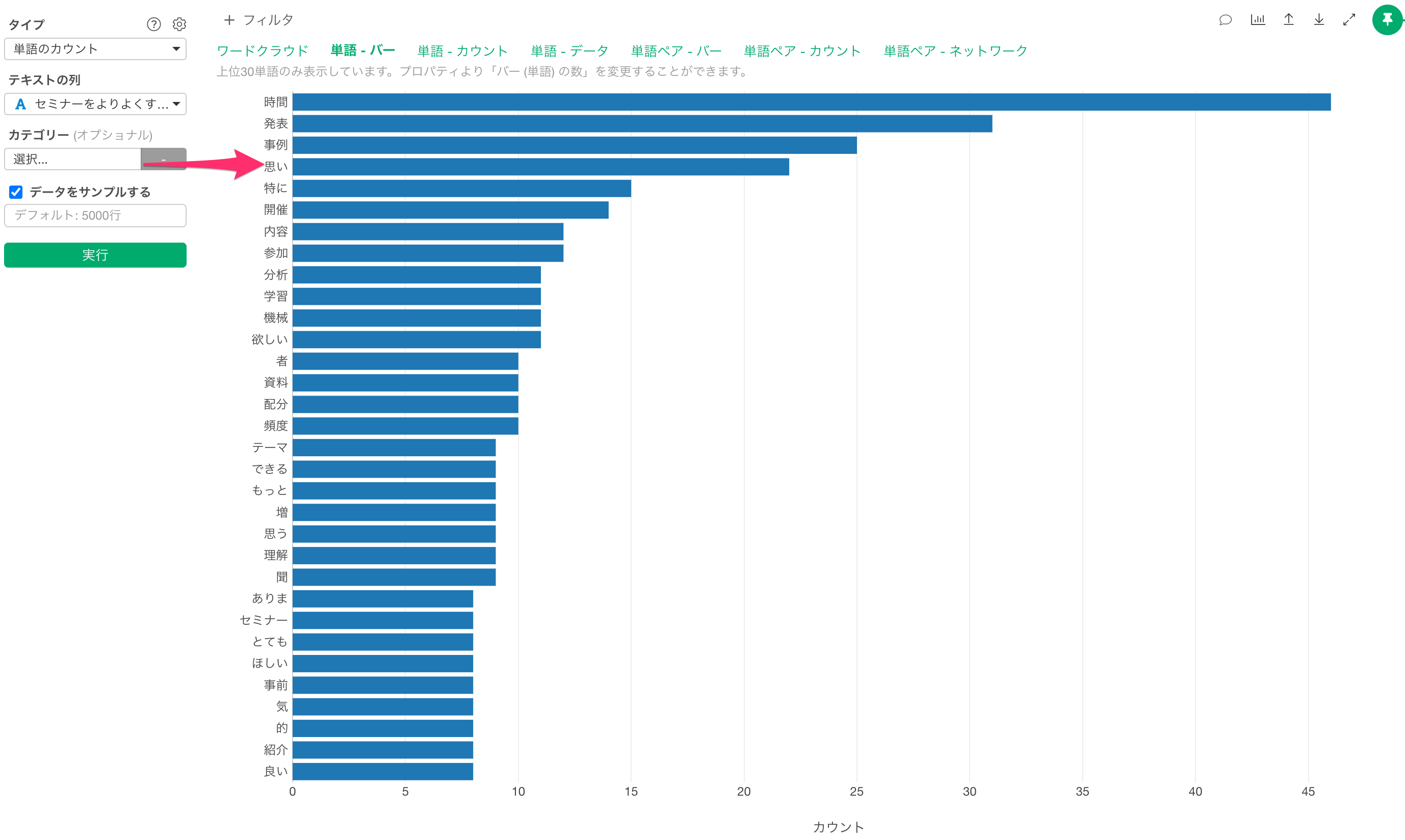
しかし、そもそも質問に対して、「〜と思います」と回答するのは一般的な回答パターンになるため、「思い」という単語自体は、あまり分析に役立つようなものではない、と想定できます。このようなときには、「思い」といった単語はストップワードとして設定しても良いかもしれません。
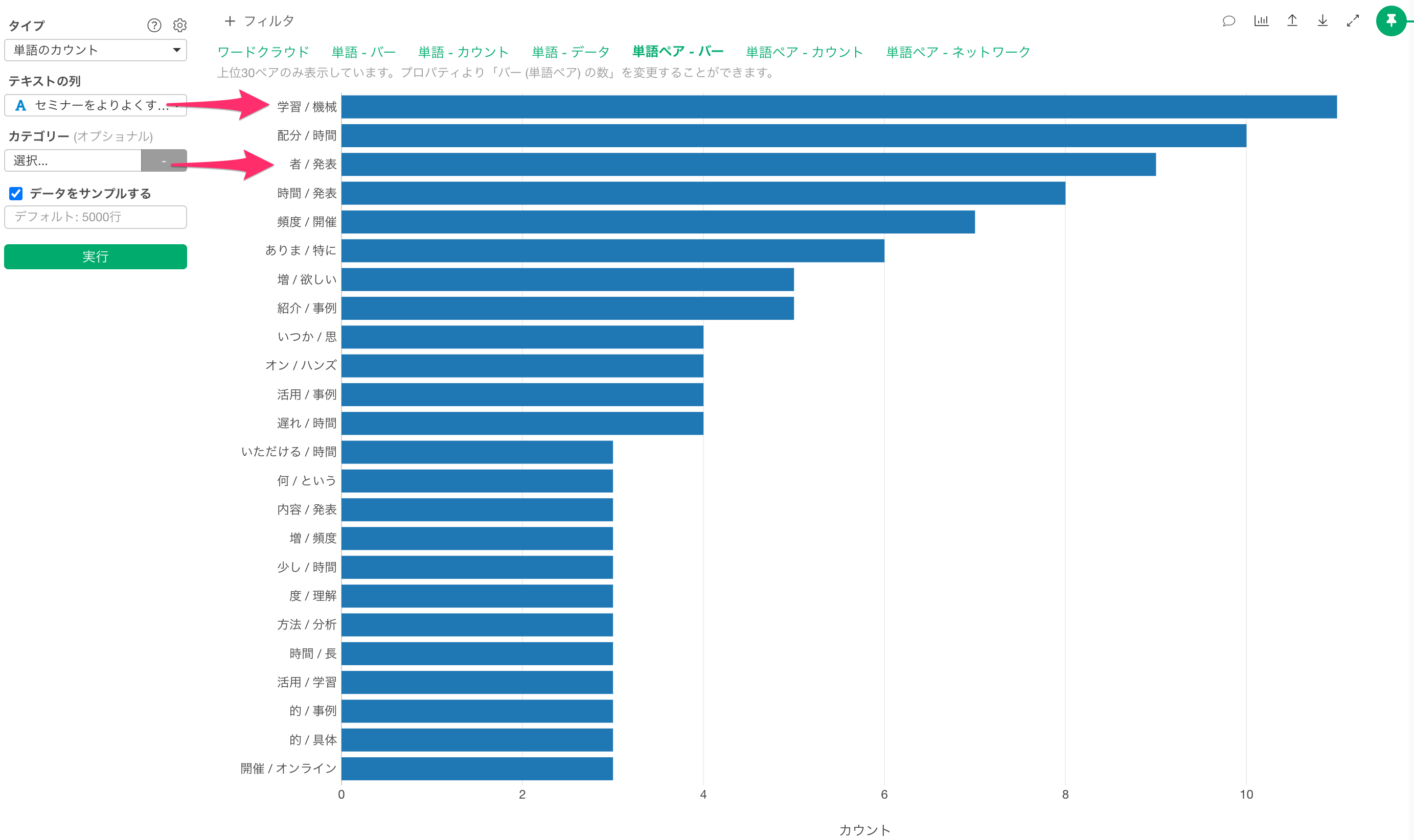
また、「単語ペア - バー」を見ることで、つなぐべき単語のヒントを得ることができます。例えば、「学習/機械」「者/発表」は「機械学習」や「発表者」といった形で1つの単語として扱った方が適切と言えそうです。
これらの情報をもとに、設定内の「ストップワード」や「つなぐ単語」を整理し、「単語のカウント」を再実行します。(今回は処理内容をわかりやすくするために、単語を直接追加していますが、実際に作業を行うときには辞書機能を利用することをおすすめします。)
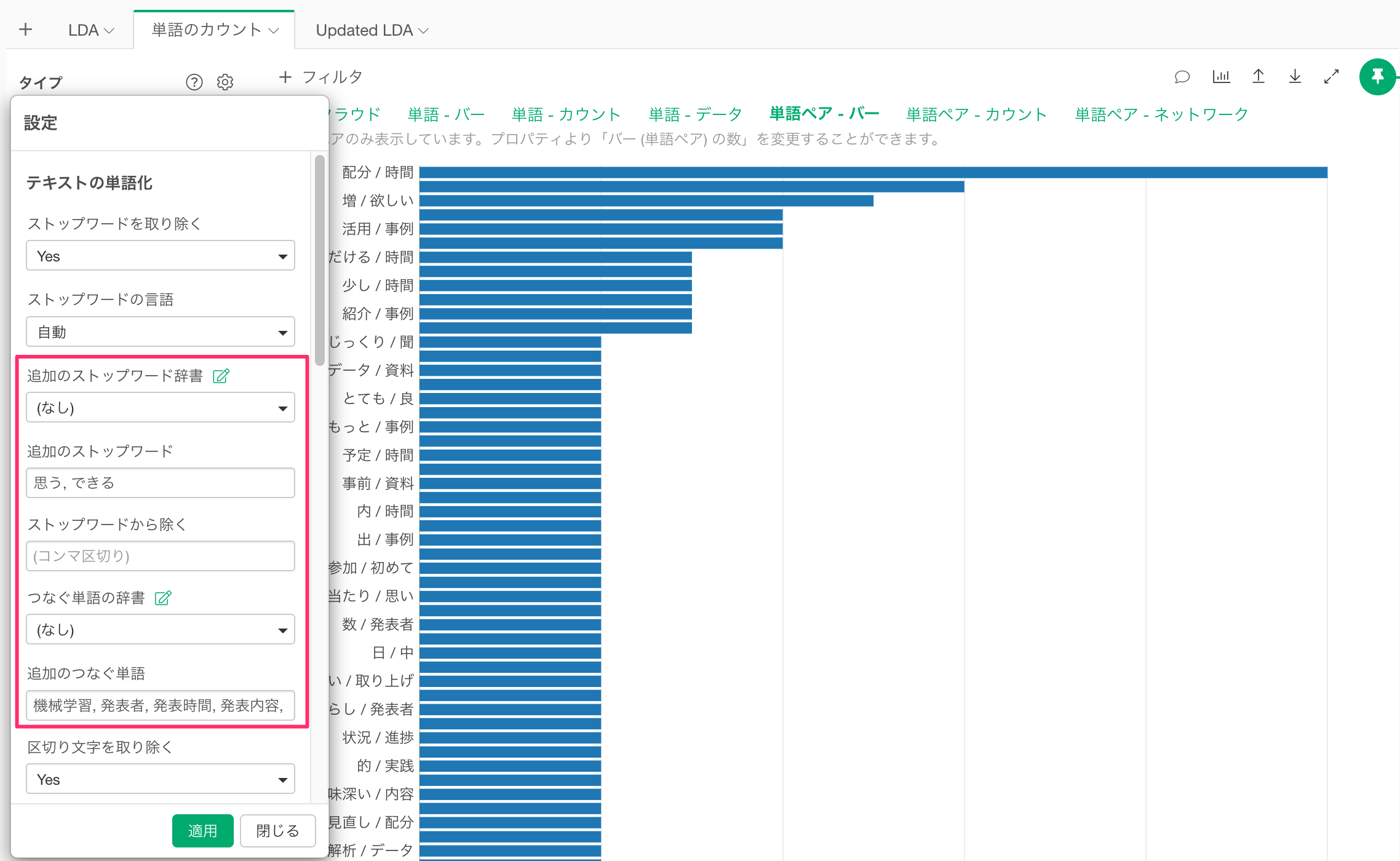
結果が更新されるので、「単語ペア - ネットワーク」を確認します。

すると、以下のような趣旨の文章が多いのではないか、ということを想定できます。
- オレンジ: 時間が長い、時間配分、発表を減らす
- 赤: 特にない、良い
- 緑: 機械学習の活用事例の紹介
- 紫: 資料の(事前)共有
- 茶: 開催頻度を増やして欲しい
- ピンク: もっとデモをみたい
- 黒: オンラインの開催希望
上記を踏まえたうえで、改めてトピックモデルを実行していきます。
今回は、つなぐ単語やストップワードの情報を更新していますので、単語のカウントのタブを複製します。
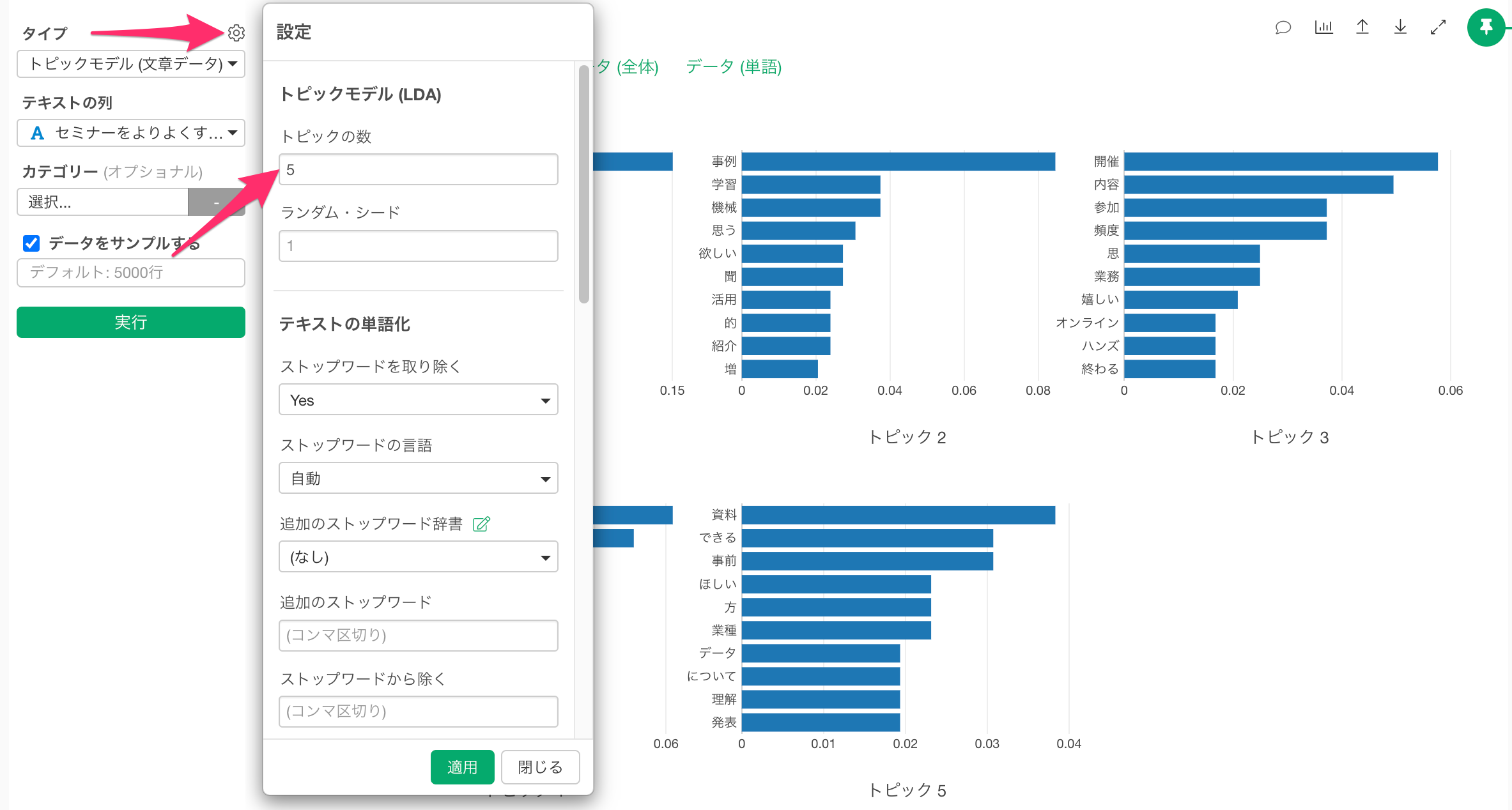
複製したタブのアナリティクスを「トピックモデル(文章データ)」に変更し、設定からトピックス数を5つに設定して、実行します。
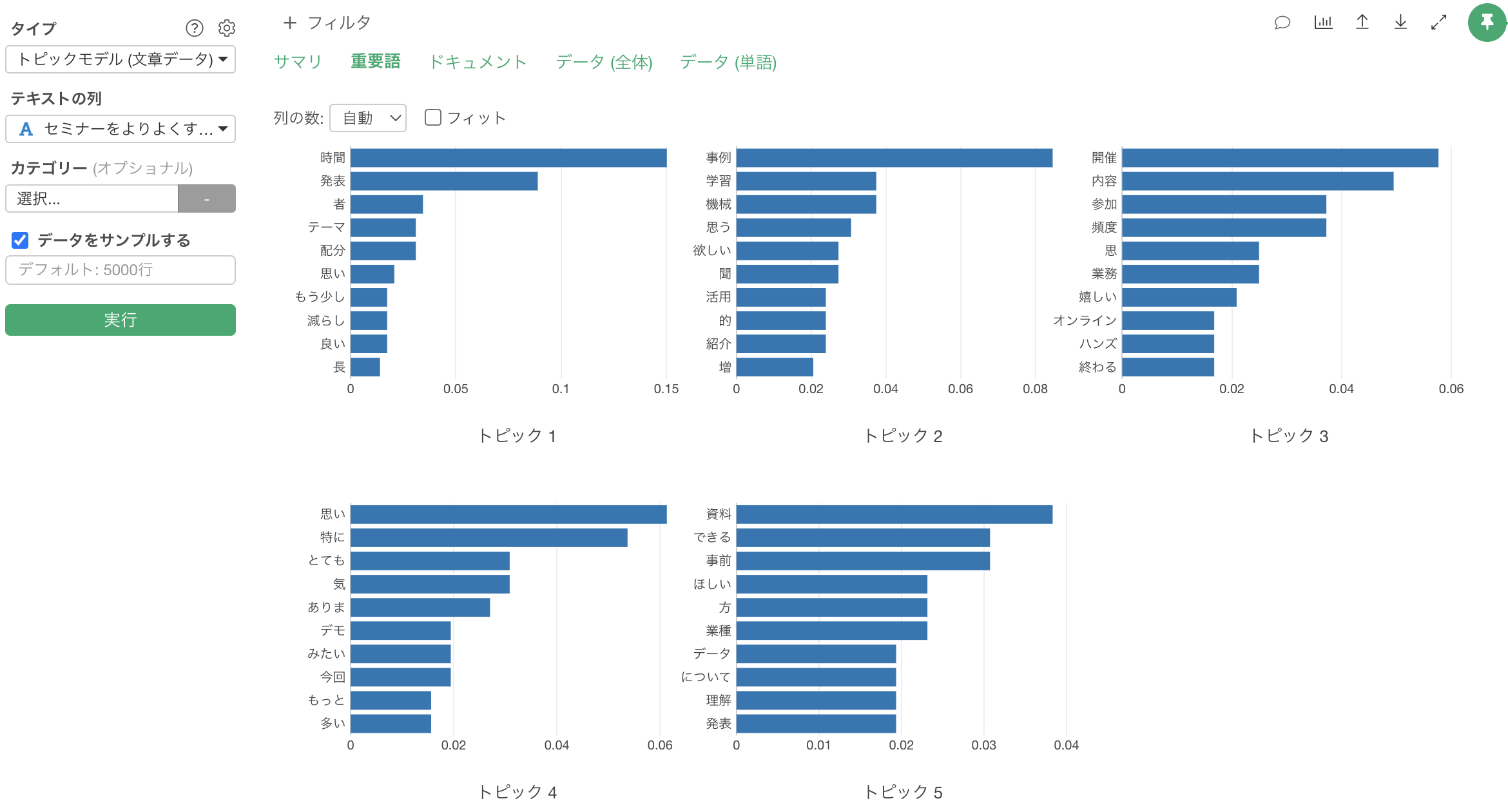
先程の結果を踏まえて、改めて重要度のタブを見ると、つなぐ単語やストップワードを変更した関係で結果が変わっていますが、各トピックにおける重要度が高い単語がどのような文脈で利用されていたのかのイメージが湧きやすくなります。
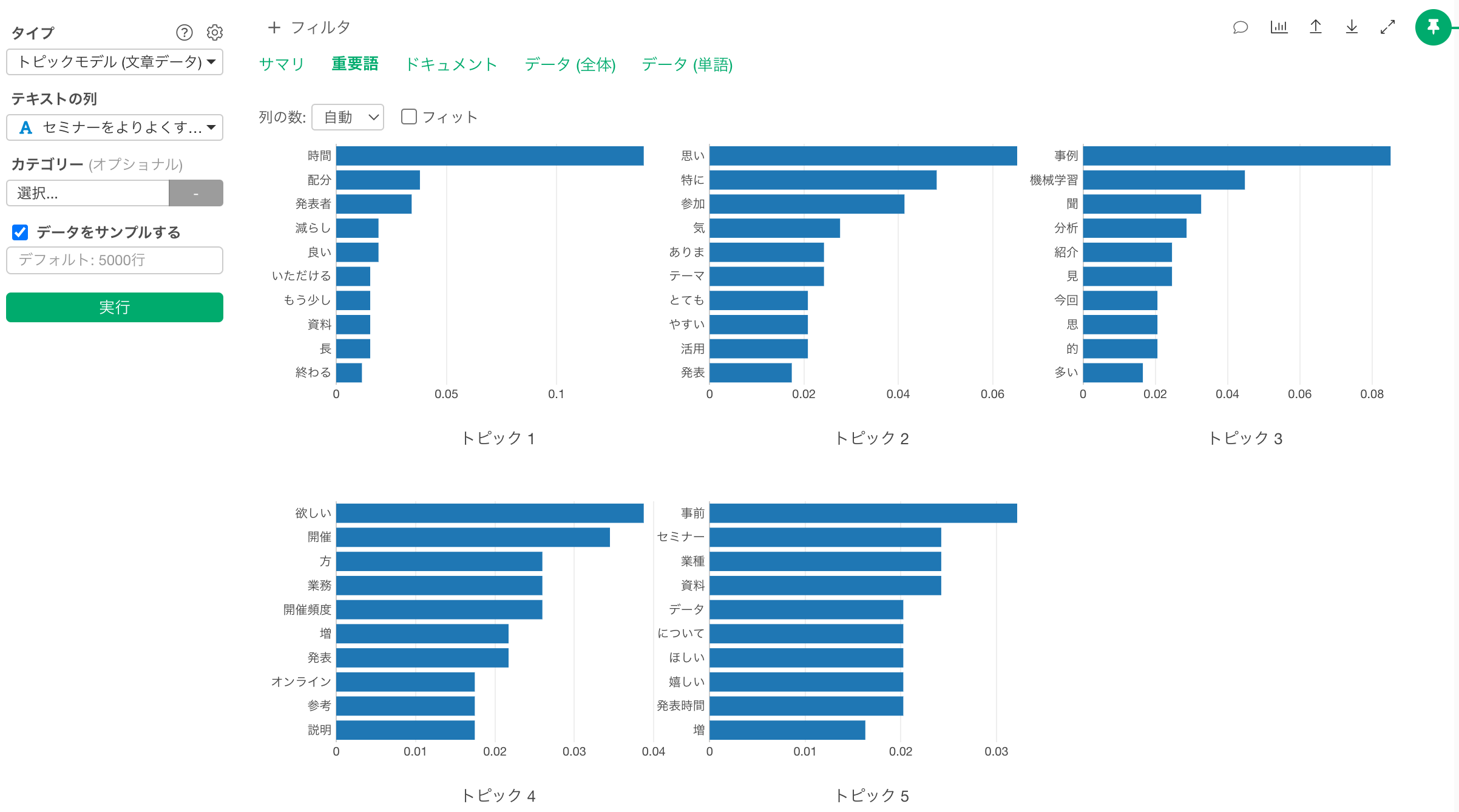
例えば、トピック1には単語のカウントでは「単語ペア - ネットワーク」タブでは赤色になっていた「特にない」という趣旨のトピック、あるいは、茶色になっていた「開催頻度を増やして欲しい」といった趣旨のトピックが含まれていることが想定できます。
 さらに、「ドキュメント」タブに移動することで、想定した内容と実際の文書が一致していることが確認できます。
さらに、「ドキュメント」タブに移動することで、想定した内容と実際の文書が一致していることが確認できます。
またこのような結果から、今回は2つの異なる話題が、1つのトピックにまとまっていると考えることもでき、よりわかりやすい分類を目指して、トピックを増やすことも検討できるようになるわけです。
単語のカウントとの使い分け
ここまで見てきた方は「単語のカウント」の「単語ペア - ネットワーク」タブの結果とトピックモデルの結果が似ていることから、使い分けが気になる方が多いかもしれません。
そこで、簡単に使い分けについて補足をすると、「トピックモデル」の特徴は、文書(データ上の行)ごとの各トピックの確率と、最も確率が高いトピックが計算されている点です。
このことは、「データ(全体)」タブからも確認が可能です。

今回のデータは1行が1回答者を表しているので、最も確率が高いトピックを回答者の所属するセグメントとして捉えることができるわけです。
そのため、エクスポートしたデータを使って、最も確率が高いトピック番号を顧客のセグメントとして捉えて、そのセグメントに最適なコミュニケーションも取れるようになります。

一方で、「単語ペア - ネットワーク」で確認できるのは文書全体の特徴に過ぎません。
また、ネットワーク図で適用されるサークルの色の数はコントロールできず、7つ、あるいはそれ以下の数しかサークルの数は色付けできません。
それに対して、トピックモデルは、以下のように設定画面から任意のトピック数を指定できる利点があると言えます。