グループごとに最後の行のデータのみを残す方法
1行が1つのアンケート回答や何らかのログを表すデータがあったとします。
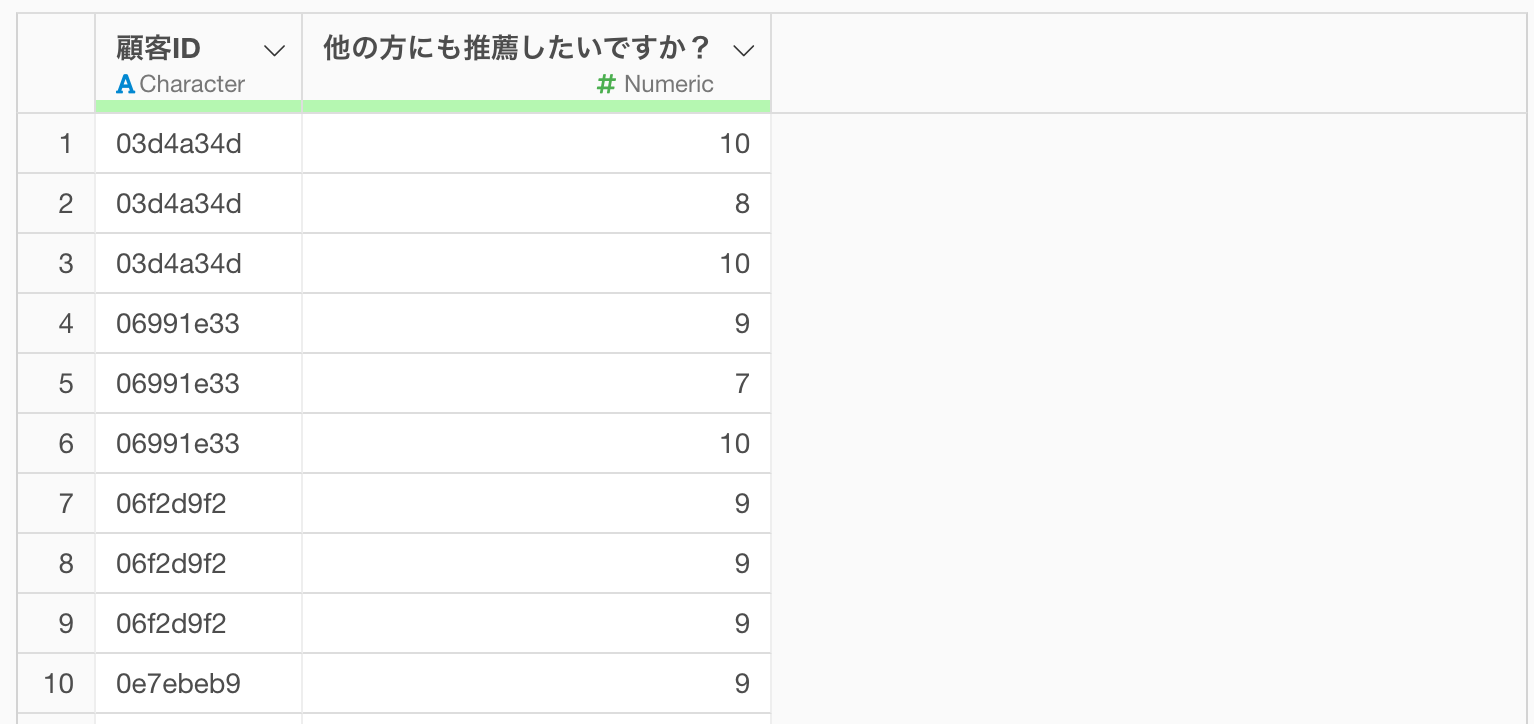
そのようなタイプのデータには、回答日やそのログを記録をした日の情報を持つ列があることが多いですが、そのような日付の情報がなく、新しいデータにななればなるほど、より下の行にデータが追加されていくだけのタイプのデータも存在します。
そこで、このノートでは、1行が1人のあるタイミングにおけるアンケートの回答を表し、列には顧客IDや、アンケートの回答スコアの情報を列に持つデータを使って、顧客(顧客ID)ごとに最後の行のデータのみを残す方法を紹介します。
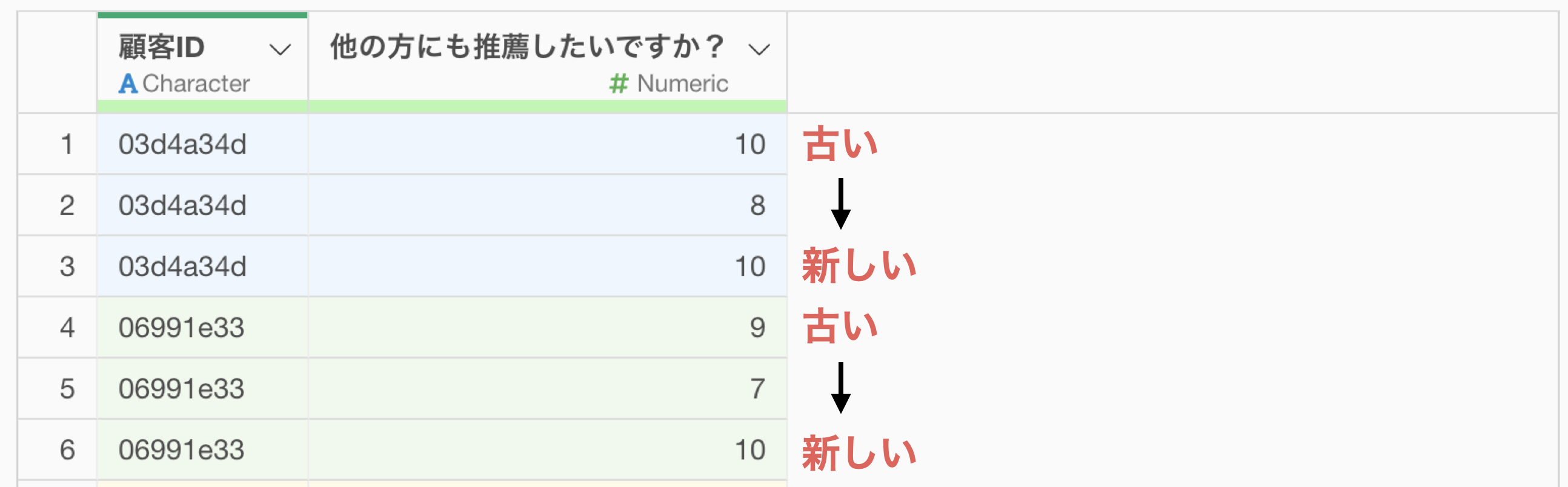
今回のようなデータがあったときに、一番簡単にデータをフィルタをする方法は、顧客ごとに上から順に行番号の列を追加することです。
顧客ごとに行番号を追加できれば、顧客ごとに最大の行番号にデータをフィルタすることで、最後の行にフィルタができるわけです。
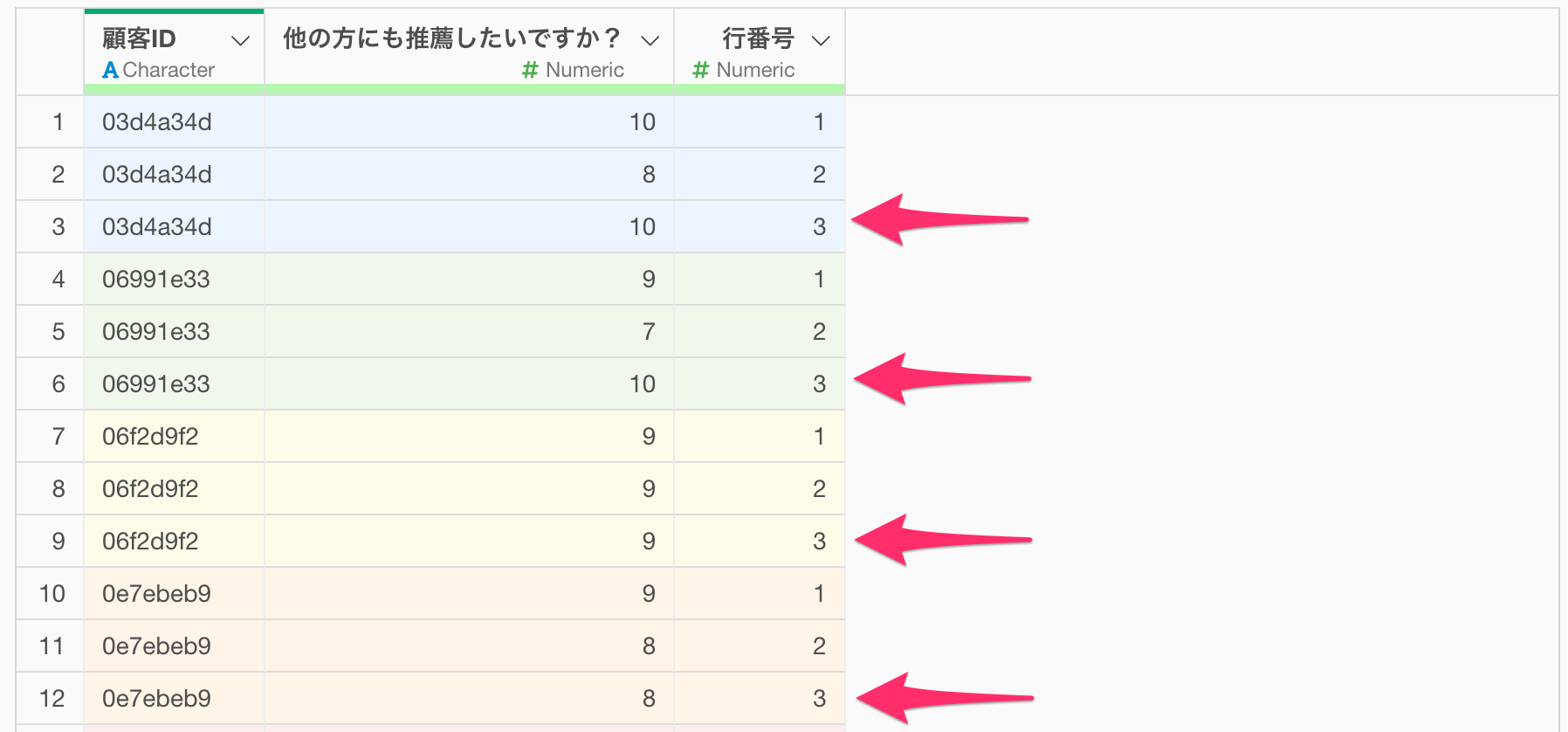
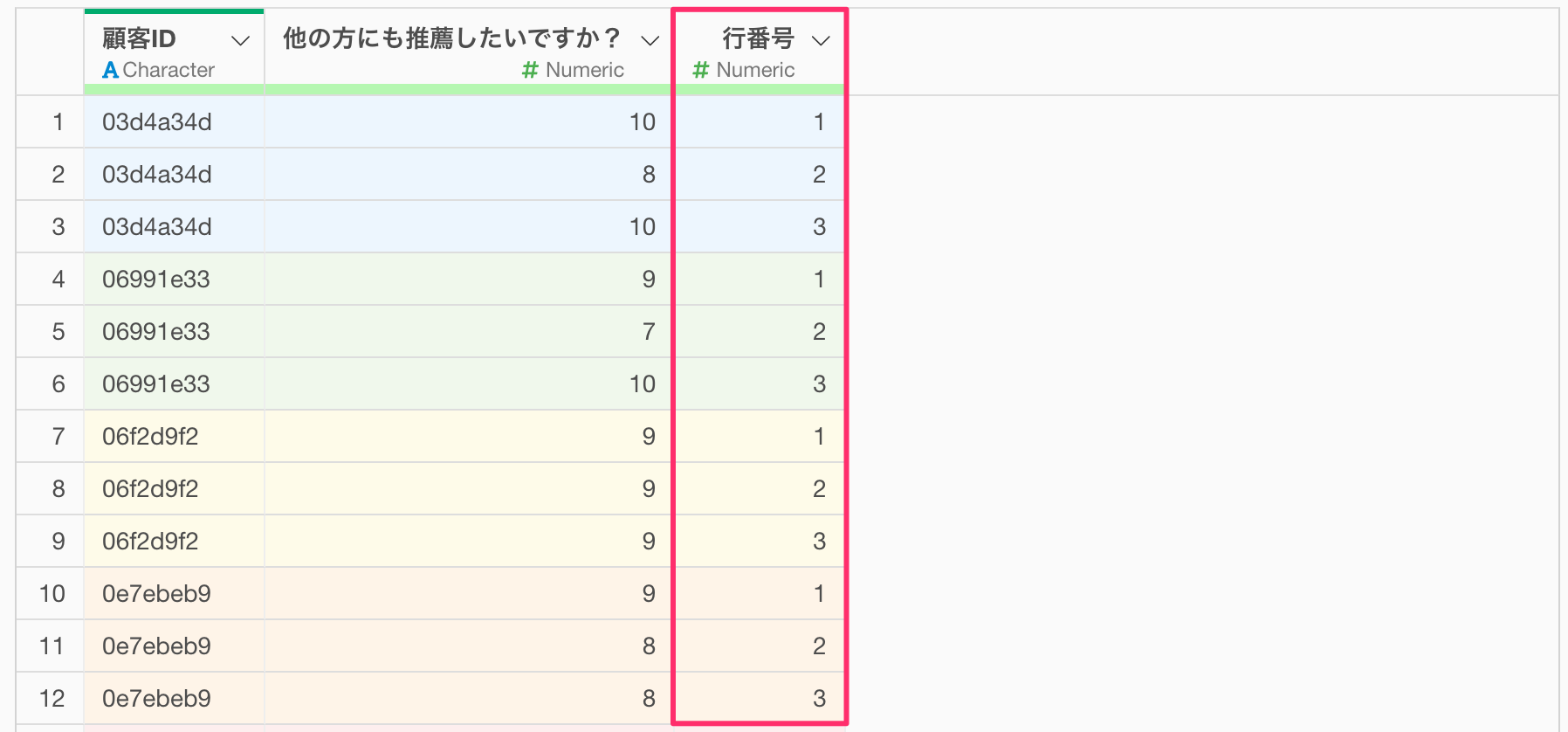
そこでまずは顧客ごとの行番号の情報を追加するために、任意の列ヘッダーメニューの「表計算」から、「行番号」を選択します。
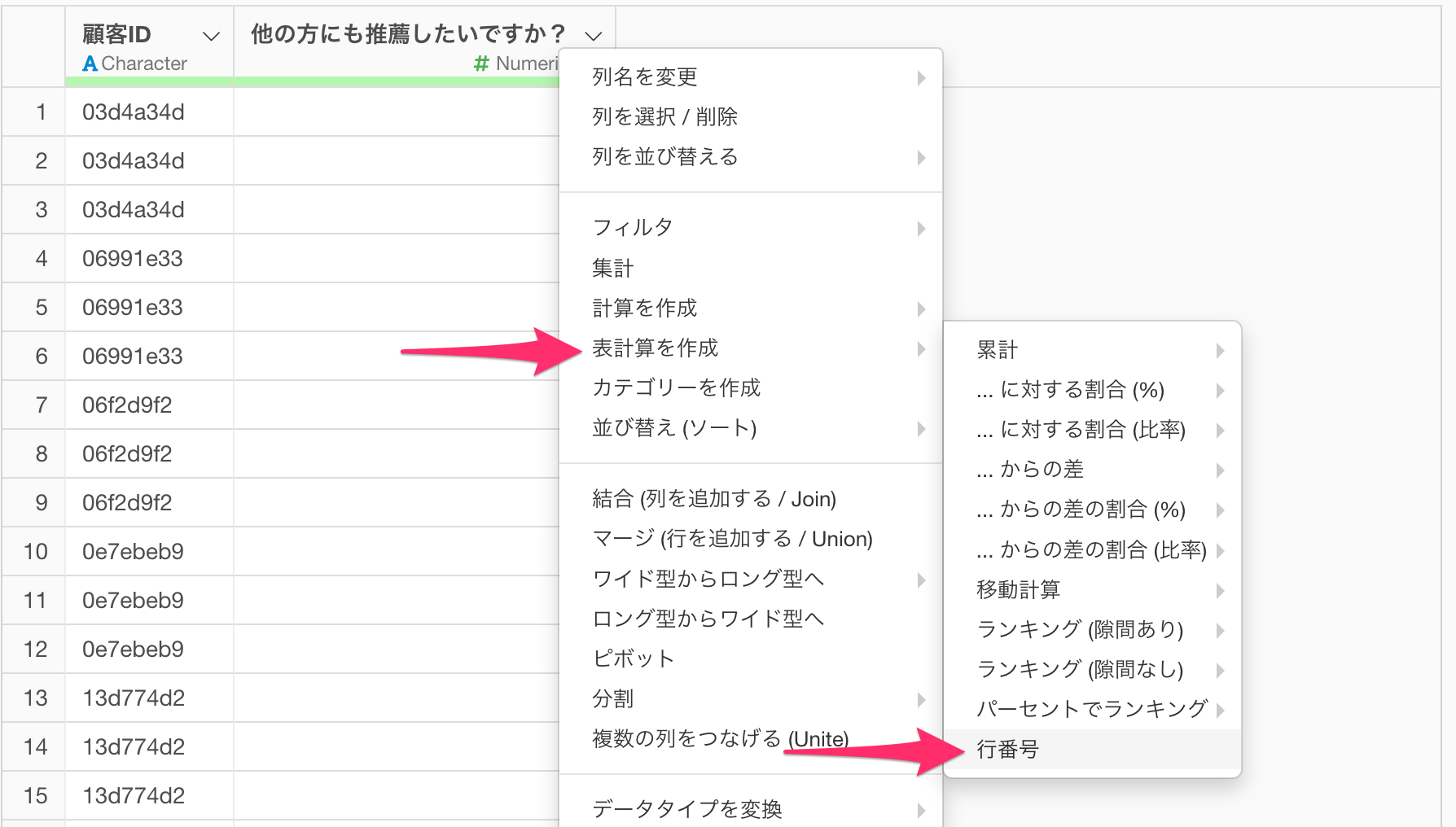
すると表計算のダイアログが表示されますので、グループに「顧客ID」を選択し実行します。
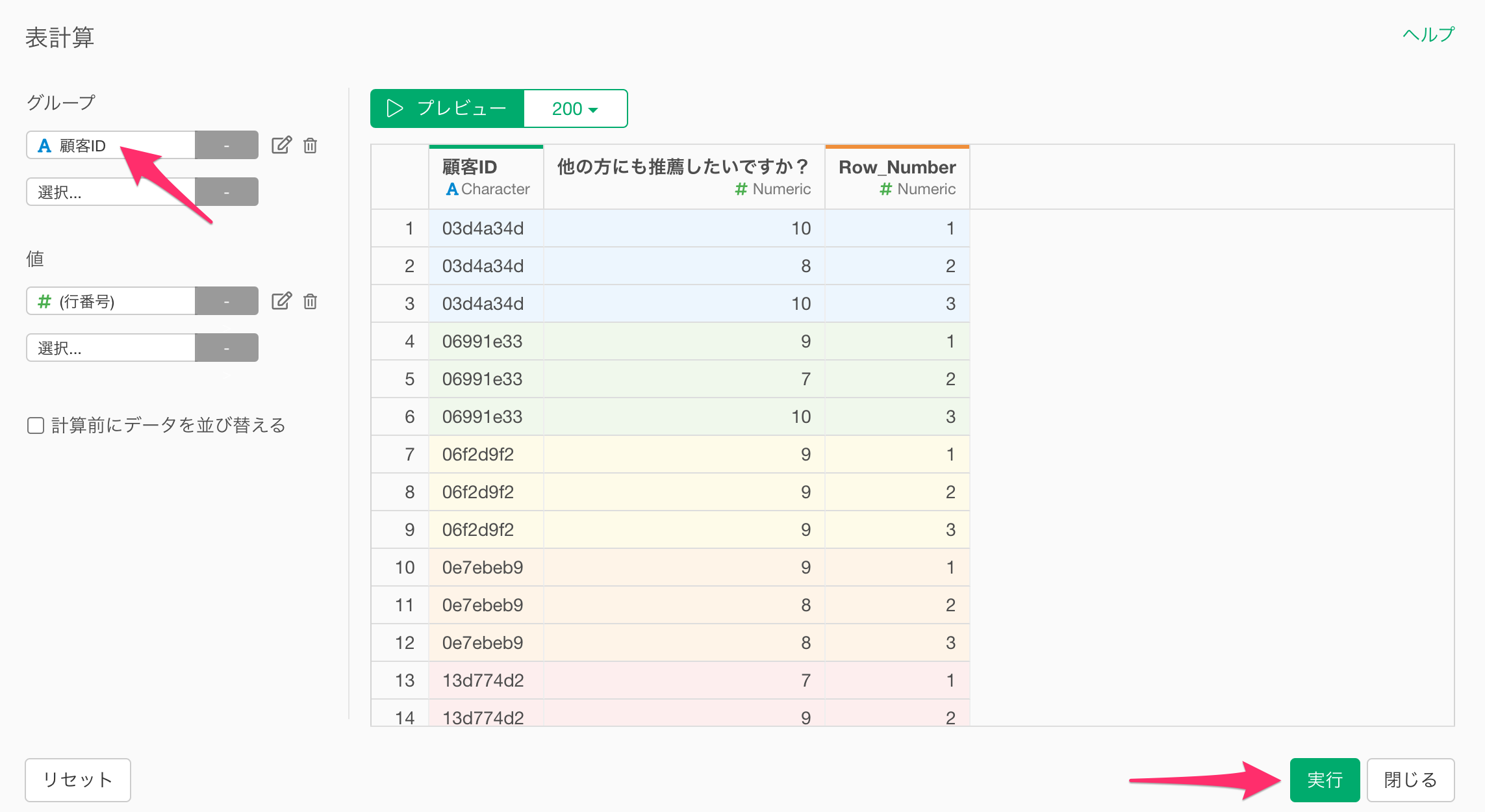
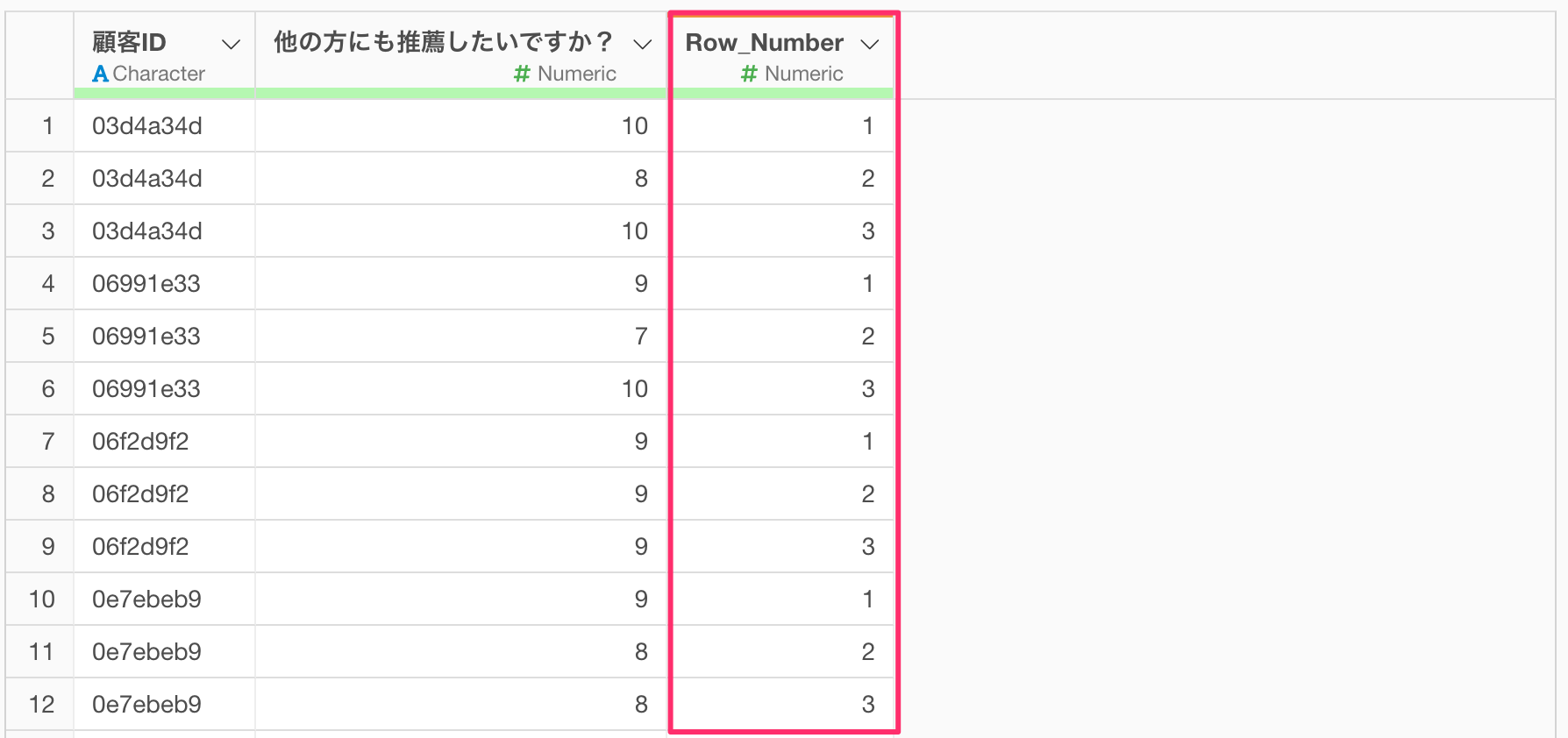
行番号を表す「Row_Number」列が追加されました。
続いて、顧客ごとにフィルタを実行する必要があるため、ステップメニューから「グループ化」を選択します。
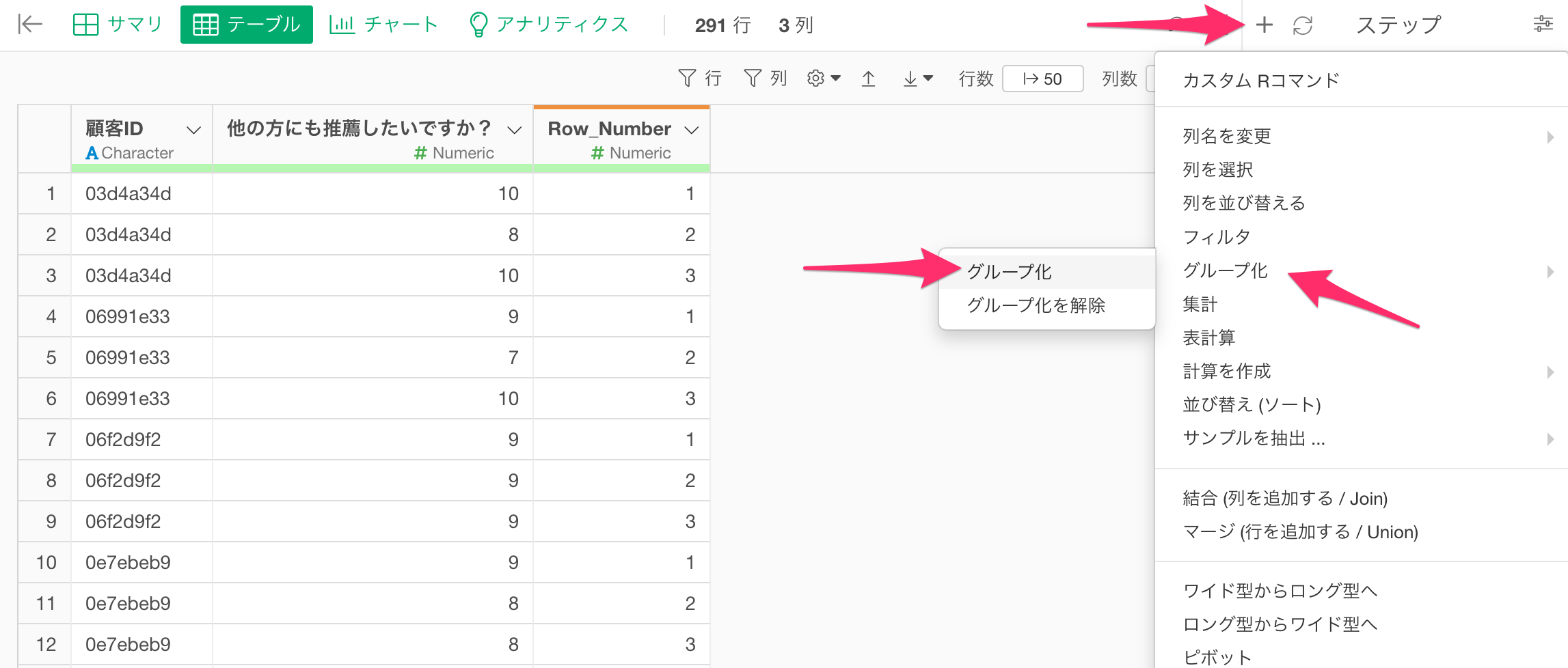 すると、グループ化のダイアログが表示されるため、顧客を識別できる「顧客ID」の列を選択します。
すると、グループ化のダイアログが表示されるため、顧客を識別できる「顧客ID」の列を選択します。
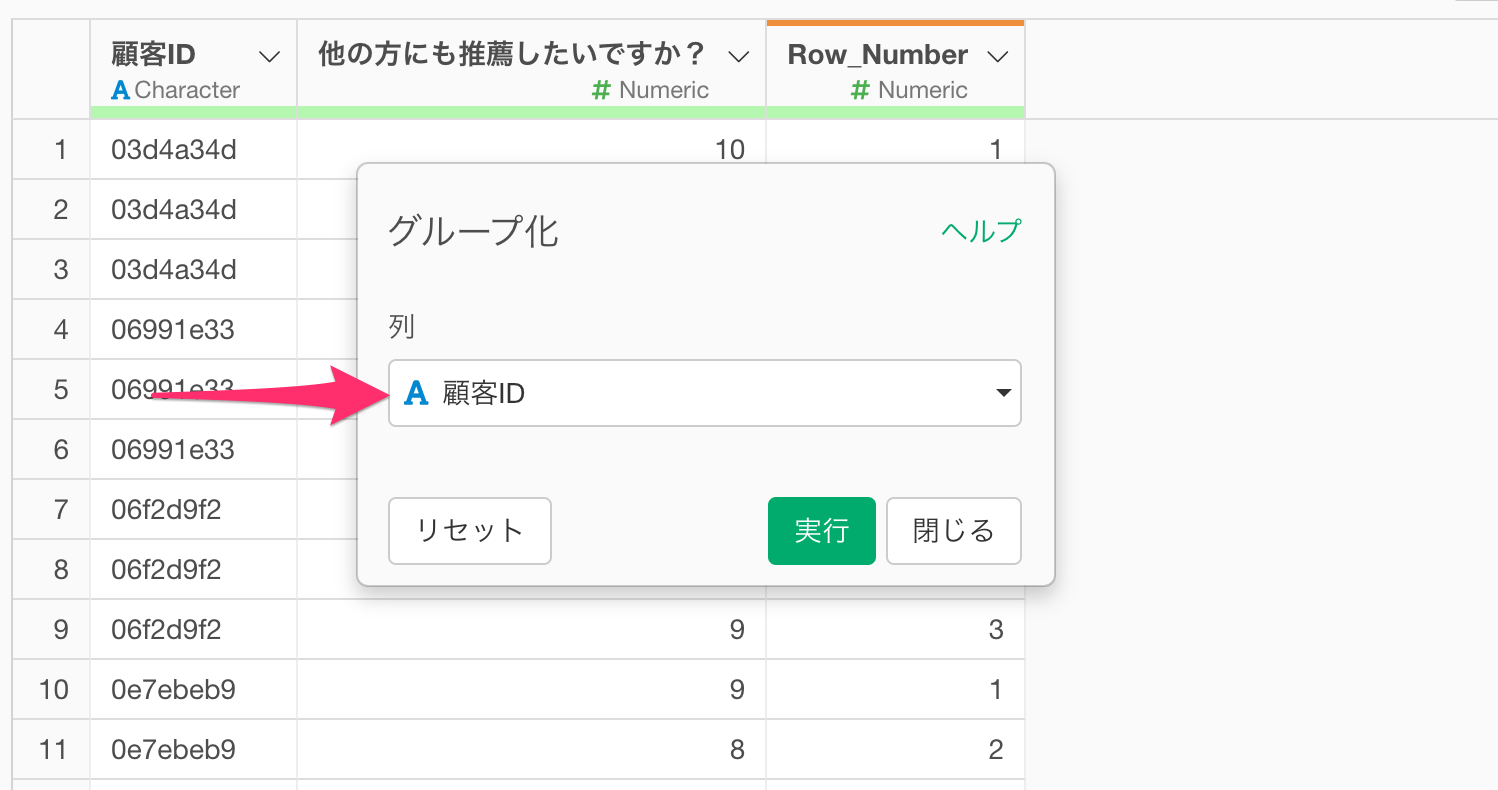
顧客IDごとにデータをグループ化できました。
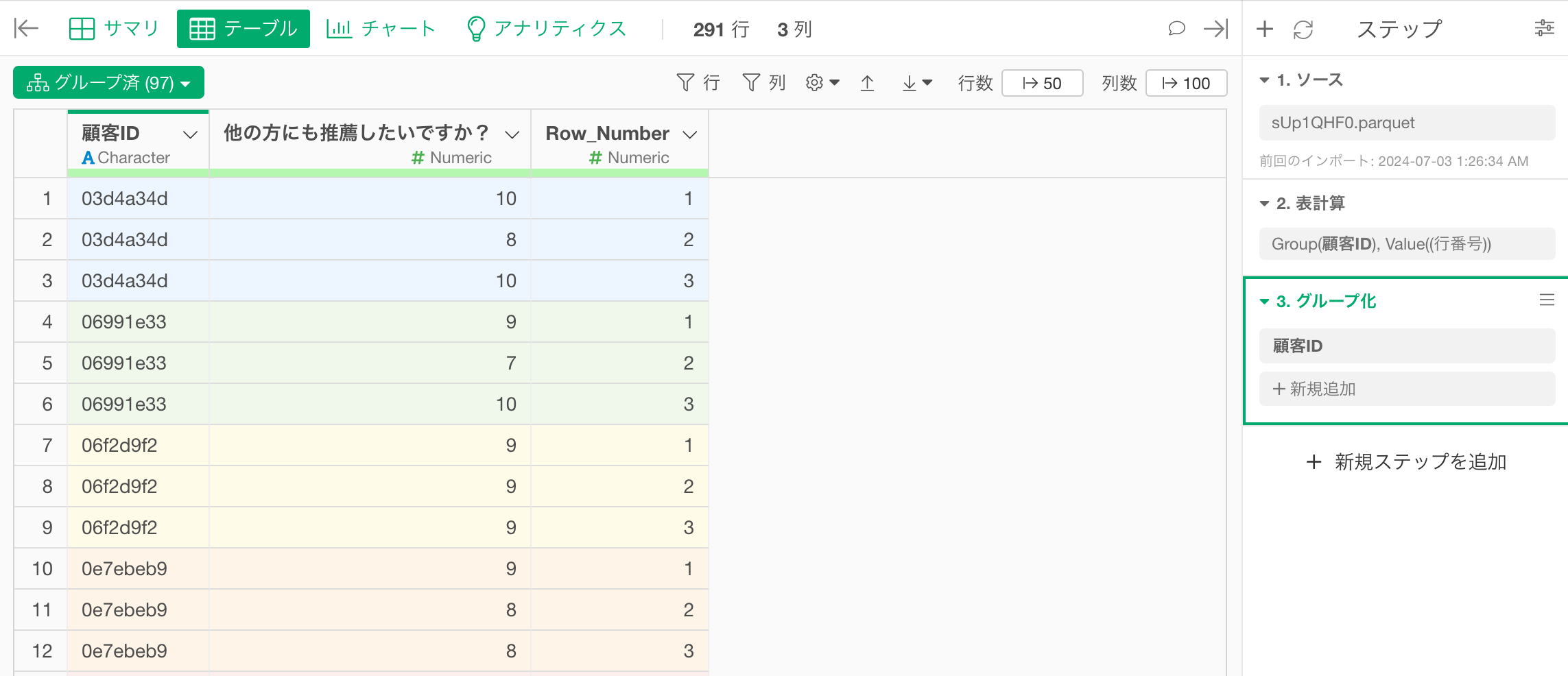
このように、グループ化をしていると、後続の「フィルタ」や、計算処理がグループ単位で行われるようになります。
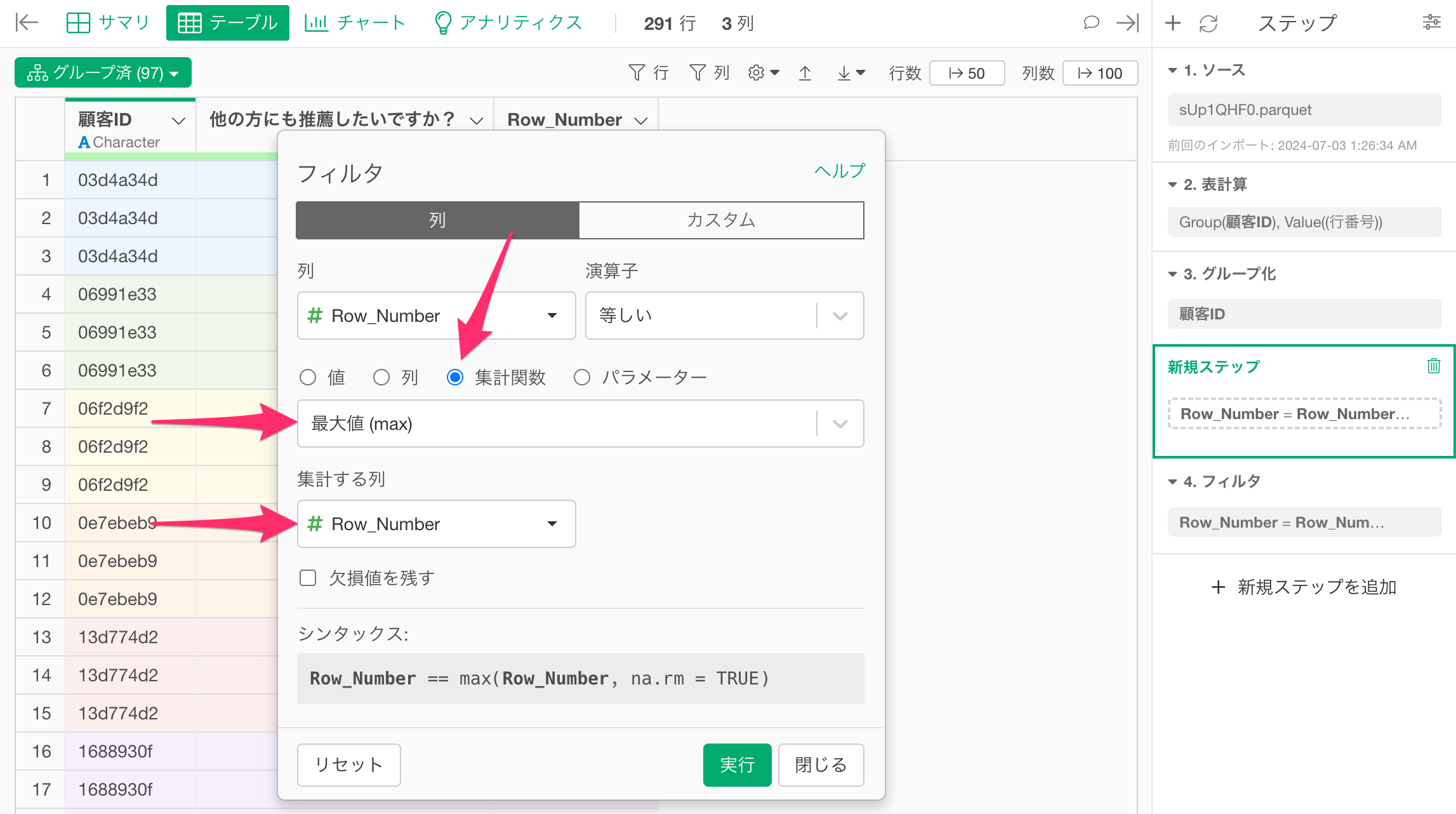
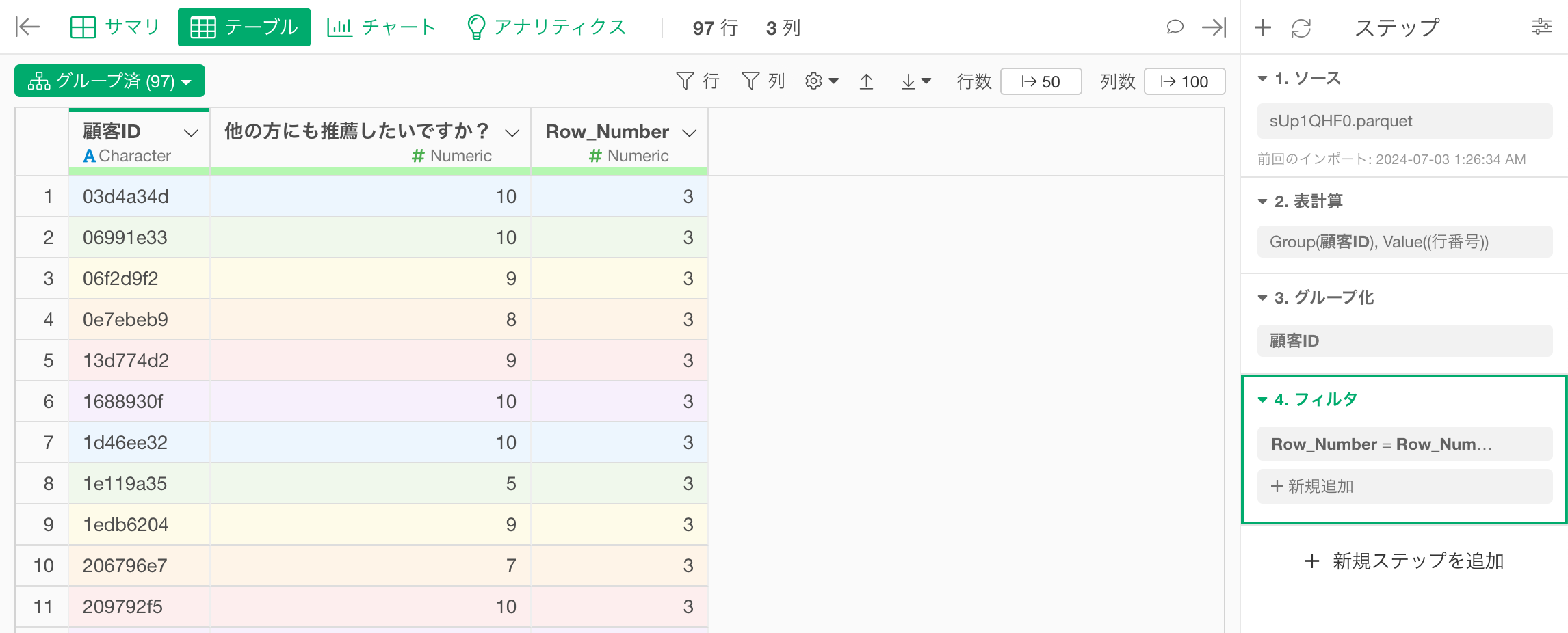
今回は、顧客ごとに最後の行、言い換えれば、「Row_Number」の最大値の行を残したいため、「Row_Number」の列ヘッダメニューから「フィルタ」の「等しい」を選択します。
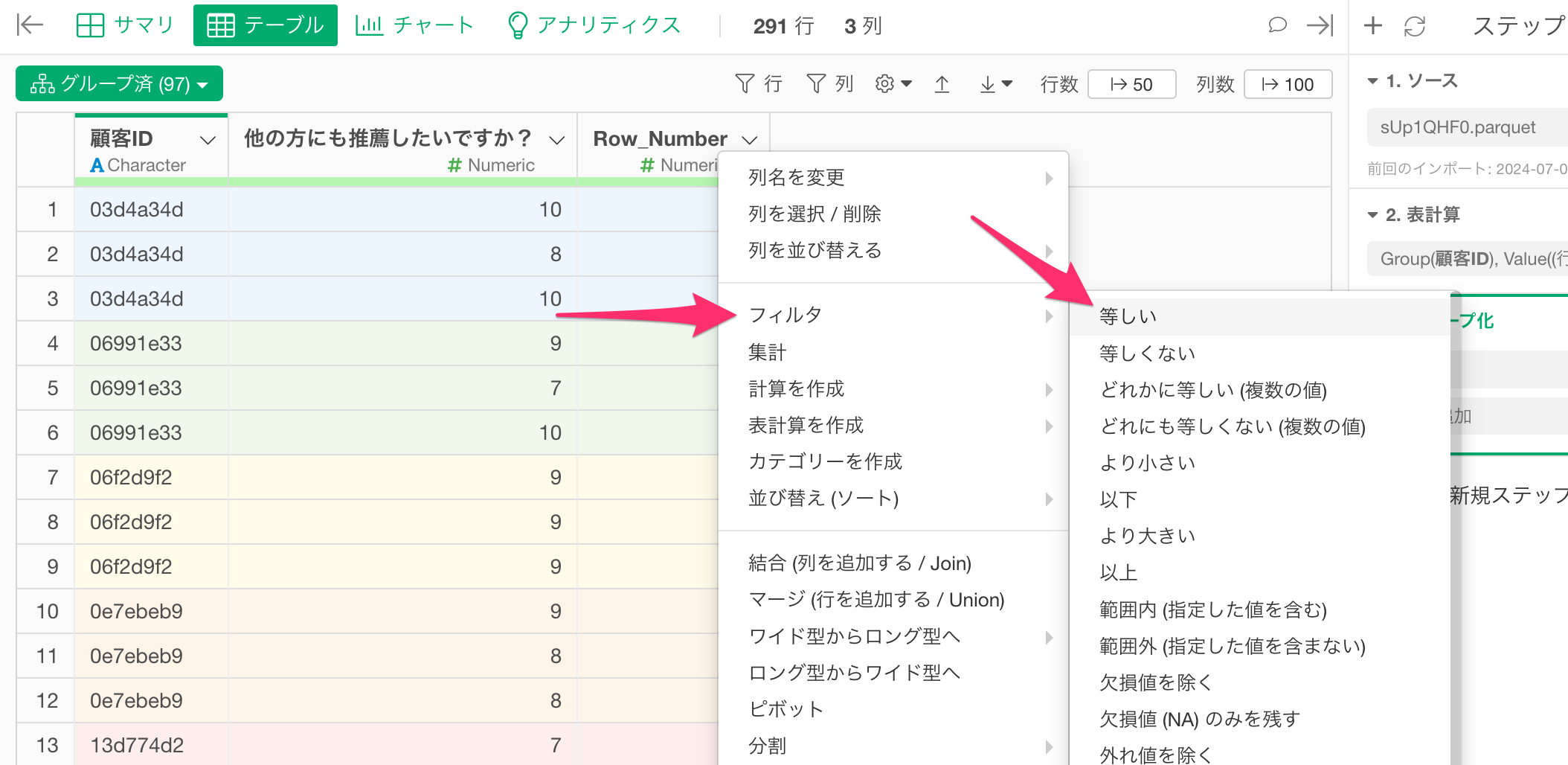
すると、フィルタのダイアログが表示されるので、「集計関数」にチェックを付けて、タイプに「最大値(Max)」を選択し、集計する列に「Row_Number」を選択したうえで実行します。
すると、顧客(顧客ID)ごとに最後の行のデータのみを残すことができました。
グループ化を必要とする処理が終了した場合、「グループ解除」を行なってください。
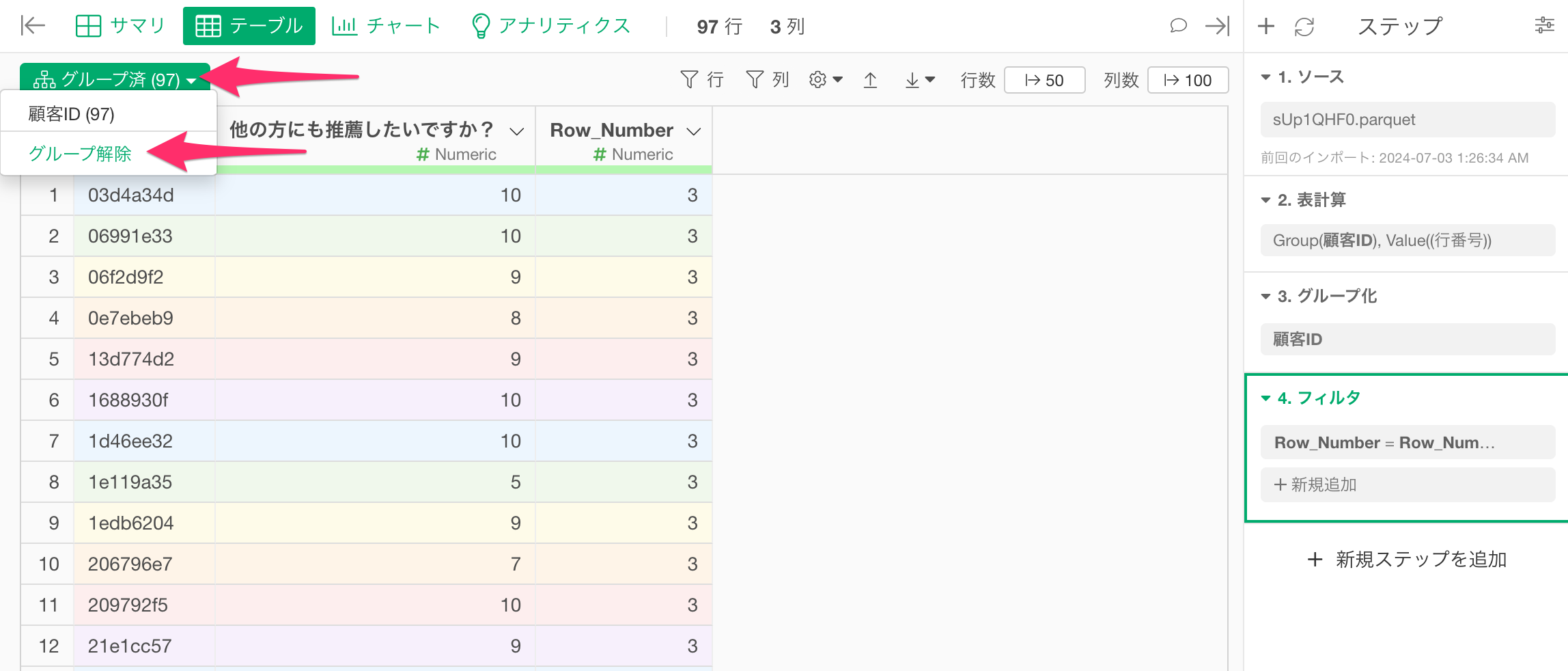
これは、グループ解除を行わずにステップを追加した場合、それぞれのステップにおける処理がグループごとに行われるため、処理に時間がかかってしまったり、意図しない結果をもたらす可能性があるためです。