Rスクリプトを使ったチャートとアナリティクスの作成
「Rスクリプトを使ったチャートとアナリティクスの作成」のセミナーで実施したRスクリプトを紹介しています。
このノートは右上にある「ダウンロード」ボタンからEDF形式でダウンロードすることができ、使用しているデータとRスクリプトを元に、手元のExploratoryデスクトップで再現することが可能です。
ベン図 - VennDaiagramパッケージ
VennDiagramパッケージを使ったベン図の作り方の詳細は、こちらから確認いただけます。
コード
library(VennDiagram)
# 新しい画像を作成
grid.newpage()
# ベン図の描画
draw.triple.venn(
area1 = vote_venn$USA, # 円1の大きさ
area2 = vote_venn$CAN, # 円2の大きさ
area3 = vote_venn$RUS, # 円3の大きさ
n12 = vote_venn$USA_CAN, # 円1と2の重なっている部分の大きさ
n23 = vote_venn$CAN_RUS, # 円2と3の重なっている部分の大きさ
n13 = vote_venn$USA_RUS, # 円1と3の重なっている部分の大きさ
n123 = vote_venn$USA_CAN_RUS, # 円1と2と3の重なっている部分の大きさ
# カテゴリーの文字
category = c("United States", "Canada", "Russia"),
lty = "blank", # 円の枠線を消す
# 塗りつぶしの色
fill = c("light blue", "#99ff99", "pink"),
fontfamily = "Arial", # 円の中の数字のフォント名
cat.fontface="bold", # カテゴリーのフォントスタイル
cat.fontfamily ="Arial" # カテゴリーのフォント名
)実行結果
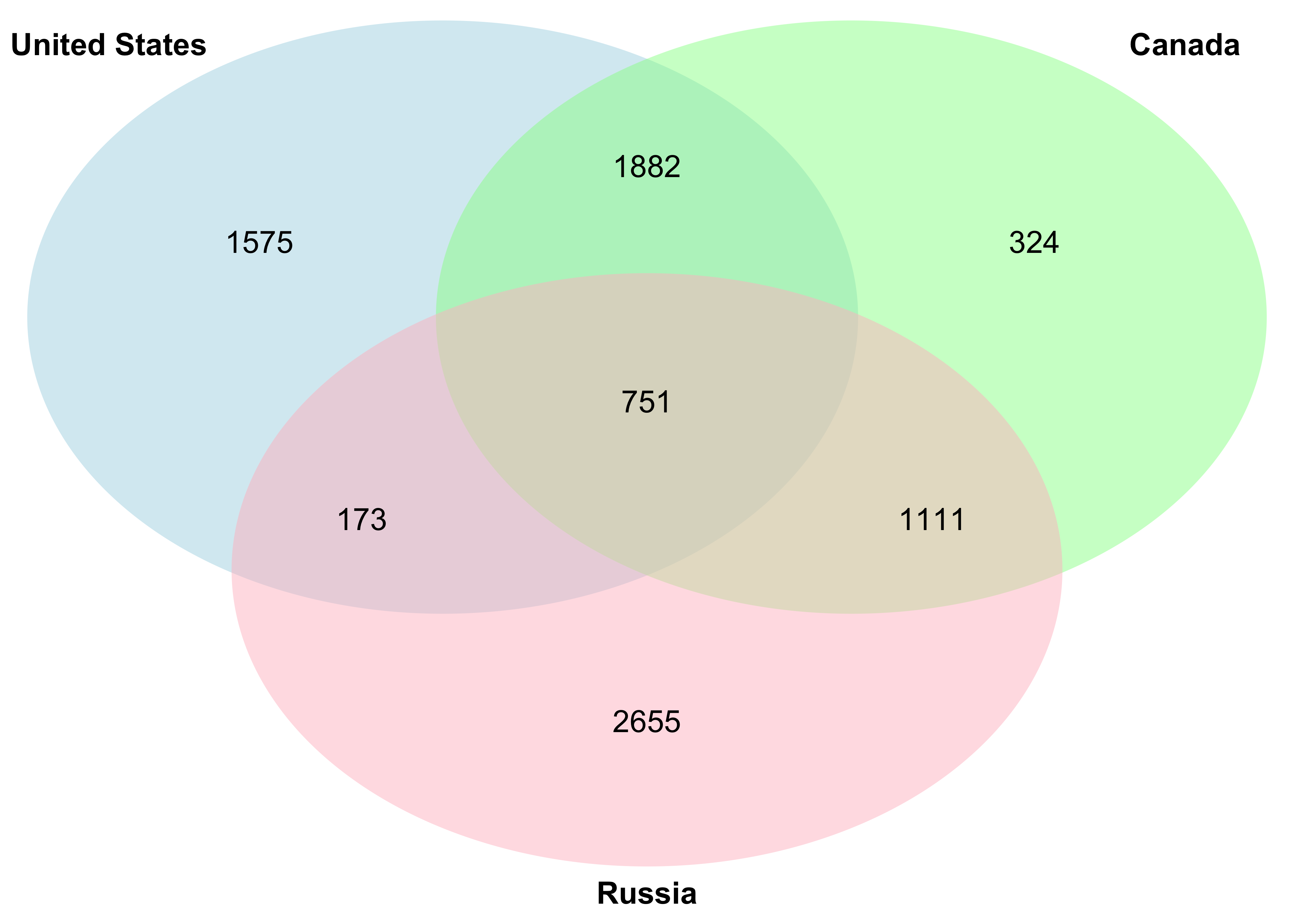
(polygon[GRID.polygon.11], polygon[GRID.polygon.12], polygon[GRID.polygon.13], polygon[GRID.polygon.14], polygon[GRID.polygon.15], polygon[GRID.polygon.16], text[GRID.text.17], text[GRID.text.18], text[GRID.text.19], text[GRID.text.20], text[GRID.text.21], text[GRID.text.22], text[GRID.text.23], text[GRID.text.24], text[GRID.text.25], text[GRID.text.26]) ベン図 - eulerrパッケージ
コード
library(eulerr)
# vote_eulerの1行目の数値を取得し、それに対応する名前をセットして、euler関数に渡す
data <- euler(setNames(as.numeric(vote_euler[1, ]), names(vote_euler)))
# プロット時に使用する色を定義
col <- c( "#E56997", "#FBC740", "#66D2D6")
plot(data,
quantities = TRUE,
fills = list(fill = col, alpha = 0.8),
edges = "black",
labels = list(fontsize = 12))実行結果
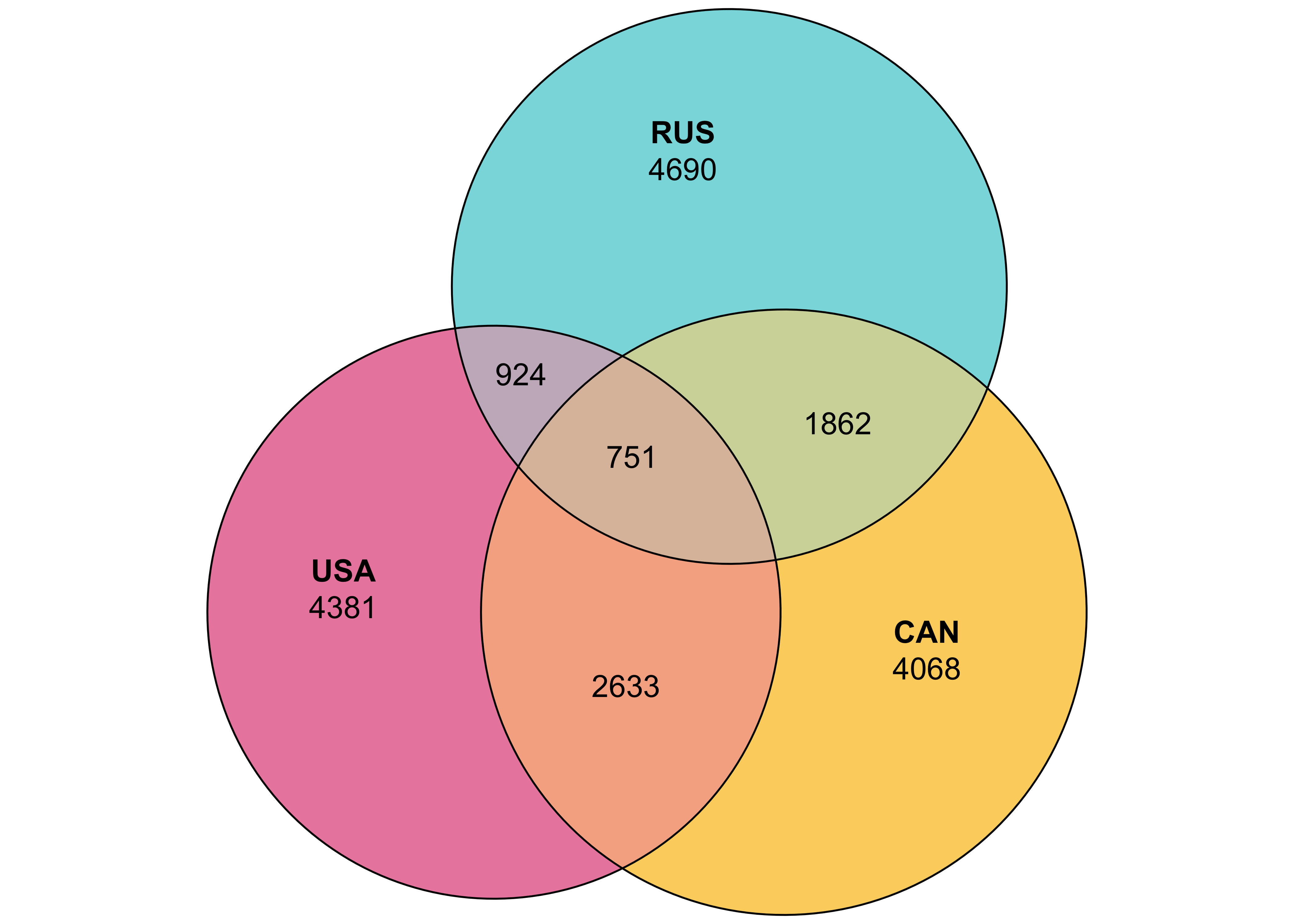
ツリーマップ
ツリーマップの作成方法の詳細は、こちらから確認いただけます。
コード
library(treemap)
treemap(売上データ,
index=c("マーケット", "国"), #グループ分けする列の指定
vSize= "売上", # 値を指定
type="index", # ツリーの色分けの方法を指定
palette = "Set1", # カラーパレットの選択
title="マーケット、国別の売上", # チャートタイトルを設定
fontsize.labels=c(16,11), # ラベルサイズの指定
fontcolor.labels=c("white","black"), # ラベルの色の指定
bg.labels=c("transparent"), # ラベルの背景色の指定
align.labels=list(
c("center", "center"),
c("right", "bottom") ), # ラベルの表示位置の指定
fontfamily.labels = "HiraKakuProN-W3", # 日本語をラベルに利用したい時に指定
fontfamily.title = "HiraKakuProN-W3", # 日本語をラベルに利用したい時に指定
fontfamily.legend = "HiraKakuProN-W3", # 日本語をラベルに利用したい時に指定
)実行結果
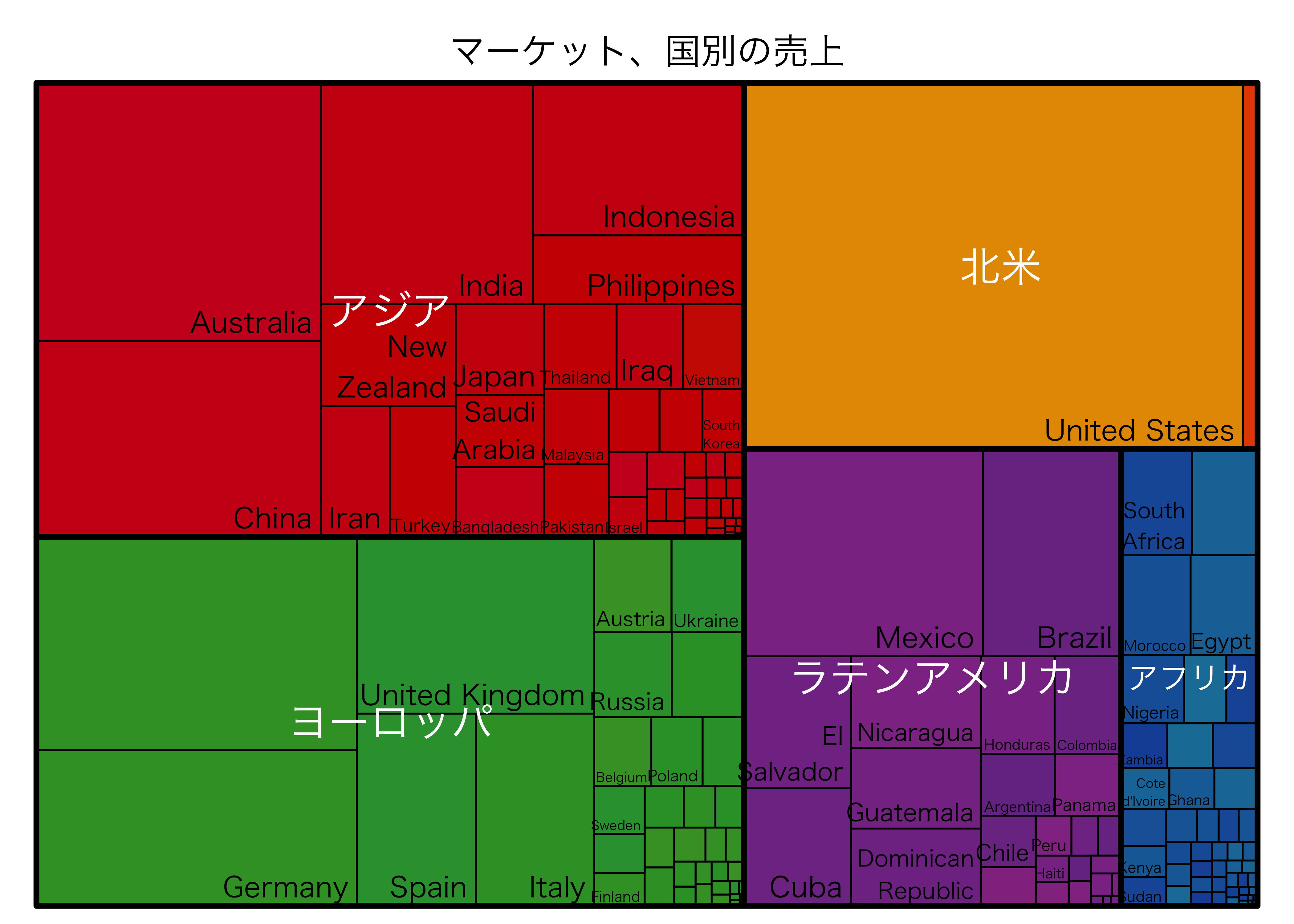
ウォーターフォール
ウォーターフォールの作成方法の詳細は、こちらから確認いただけます。
コード
#ライブラリの呼び出し
library(waterfalls)
library(ggplot2)
#文字化けが発生しないように日本語のフォントの情報を追加
theme_set(theme_gray(base_family = "HiraKakuProN-W3"))
#ウォーターフォール・チャートを作成する
waterfall(Plan, #データフレーム名を指定
rect_text_size = 1, #バー内のテキストサイズを指定
calc_total = TRUE, # 合算値を表示させるかを指定
total_axis_text = "Total", #合算値の名称を指定
total_rect_color = "dark grey", #合算値のバーの塗り潰し色の指定
total_rect_text_color = "white" #合算値のバー内のテキストの色の指定
)実行結果
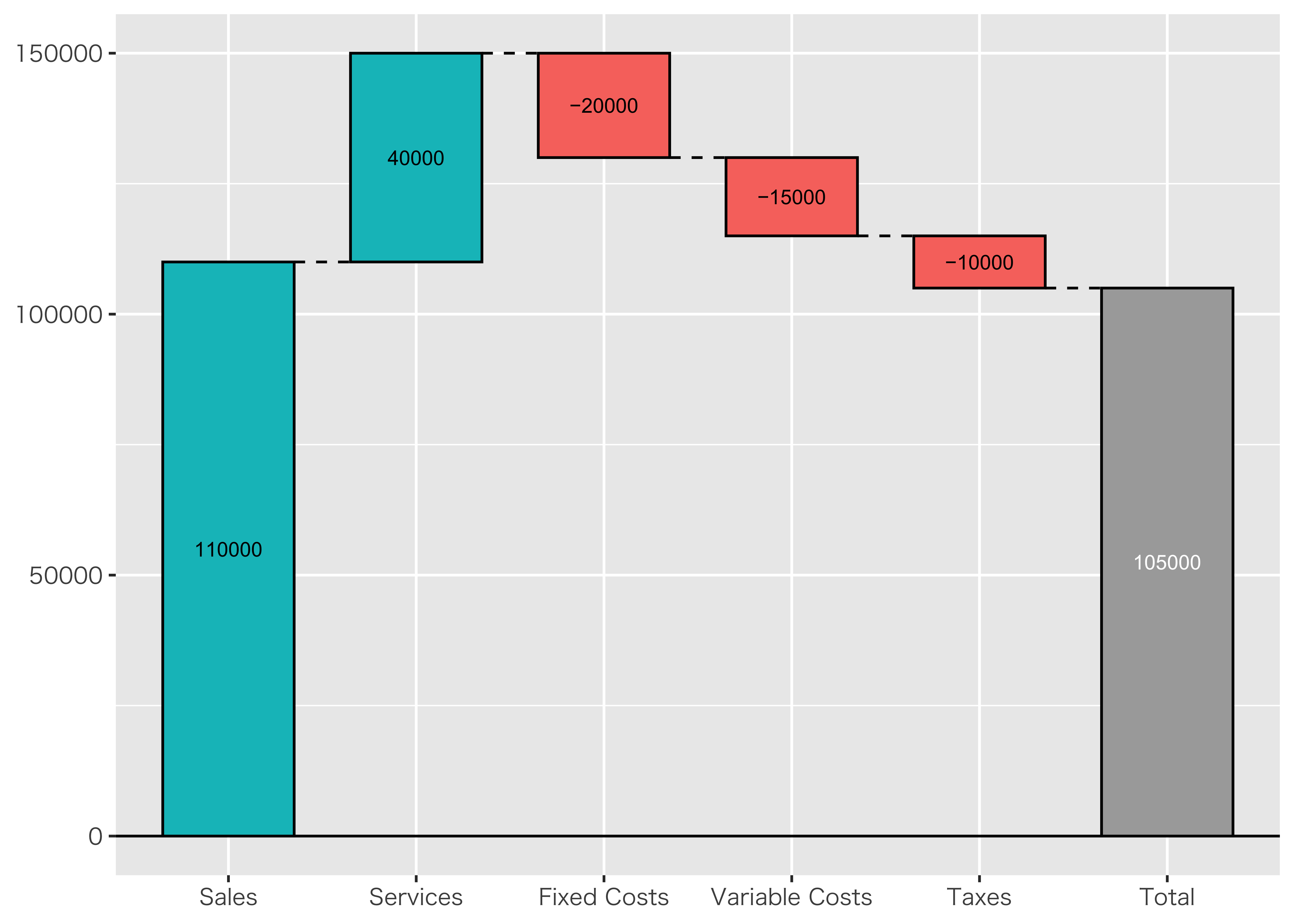
階層クラスタリング
#ユークリッド距離の計算
dist_matrix <- dist(University_Ranking, method = "euclidean")
#階層クラスタリングの実行
hc <- hclust(dist_matrix, method = "complete")
#階層クラスタリングのプロット
plot(hc, labels = University_Ranking$country) 
下記のピボットテーブルとレーダーチャートの結果は、階層クラスタリングの結果を元にクラスター番号の列を追加したものを元にしています。
階層クラスタリングのクラスター番号の列を追加してデータフレームを作るコードは下記となります。
dist_matrix <- dist(University_Ranking, method = "euclidean")
hc <- hclust(dist_matrix, method = "complete")
num_clusters <- 5
clusters <- cutree(hc, k = num_clusters)
University_Ranking$Cluster <- clusters
University_Rankingピボットテーブルでの結果
Loading...
レーダーチャートでの結果
Loading...
母比率の差の検定
95%信頼区間で可視化した時の結果
Loading...
コード
prop.test(Webページ_ABテスト$SignUp, Webページ_ABテスト$PageView)実行結果
2-sample test for equality of proportions with continuity correction
data: Webページ_ABテスト$SignUp out of Webページ_ABテスト$PageView
X-squared = 5.4316, df = 1, p-value = 0.01978
alternative hypothesis: two.sided
95 percent confidence interval:
-0.0072921848 -0.0006273474
sample estimates:
prop 1 prop 2
0.09697721 0.10093697