ポリコリック相関係数を計算する方法
こちらのノートでは、ポリコリック相関係数の計算方法を紹介いたします。
ポリコリック相関係数の概要
そもそも相関関係とは2つの変数のうち、1つの変数の値が変わるともう1つの変数の値も一定の規則を持って一緒に変わる関係のことを言います。
例えば、消費者満足度が高まると売上が増えるなど、変数間の関係を捉えることができれば、売上を増やすために、顧客満足度を高める施策の実施を検討することができるわけです。
そこで、変数間の関係を測るために利用されるのが相関の強さを表す指標の「相関係数」です。相関係数は1または-1に近づくほど、相関が強いことになり、0に近いほど相関が弱くなる特徴があります。
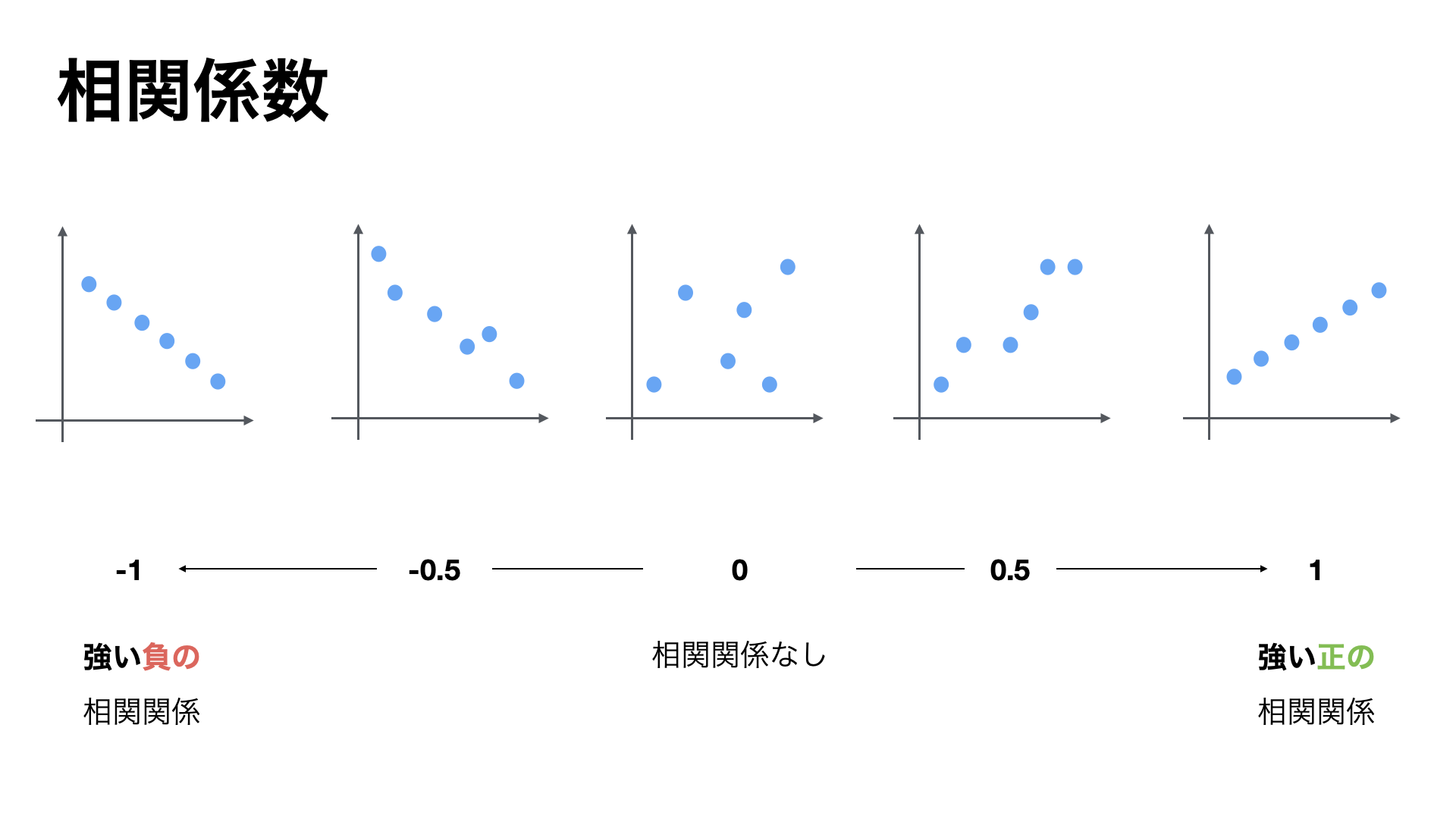
また相関係数にはいくつかの種類があり、もっとも頻繁に利用されるのは「ピアソンの相関係数」です。ピアソンの相関係数は、2つの変数が連続的かつ正規分布に従うときに最も正確に相関の強さを測れます。
一方で、アンケートデータなど5(あるいは10)段階の順序関係を持つデータ間の相関を計算する際には、「ポリコリック相関係数」の方が、回答に隠れた連続性や偏りを考慮した相関係数を計算できるため、より正確に相関の強さを測ることができる場合があります。
Exploratoryでは、「polycor」パッケージのpolycor関数を利用することで、この「ポリコリック相関係数」を計算できますので、このノートではそちらの計算を方法を紹介します。
Polycorのパッケージをインストールする
Exploratoryでpolycor関数を使うには、パッケージをインストールする必要があります。
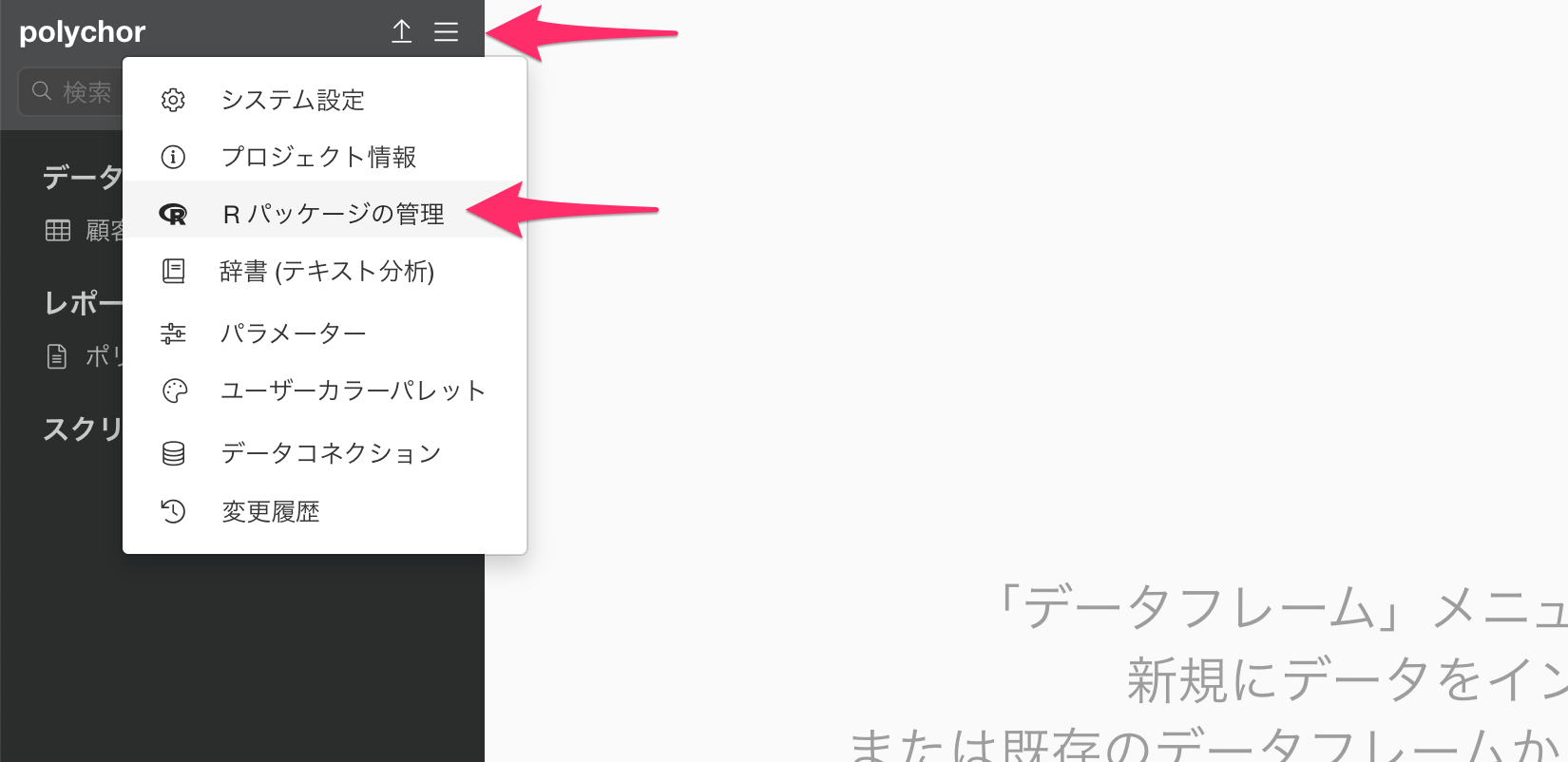
プロジェクトメニューから「Rパッケージの管理」を選択します。
「パッケージをインストール」の「CRAN」タブを選択し、polycorと入力してインストールをクリックします。
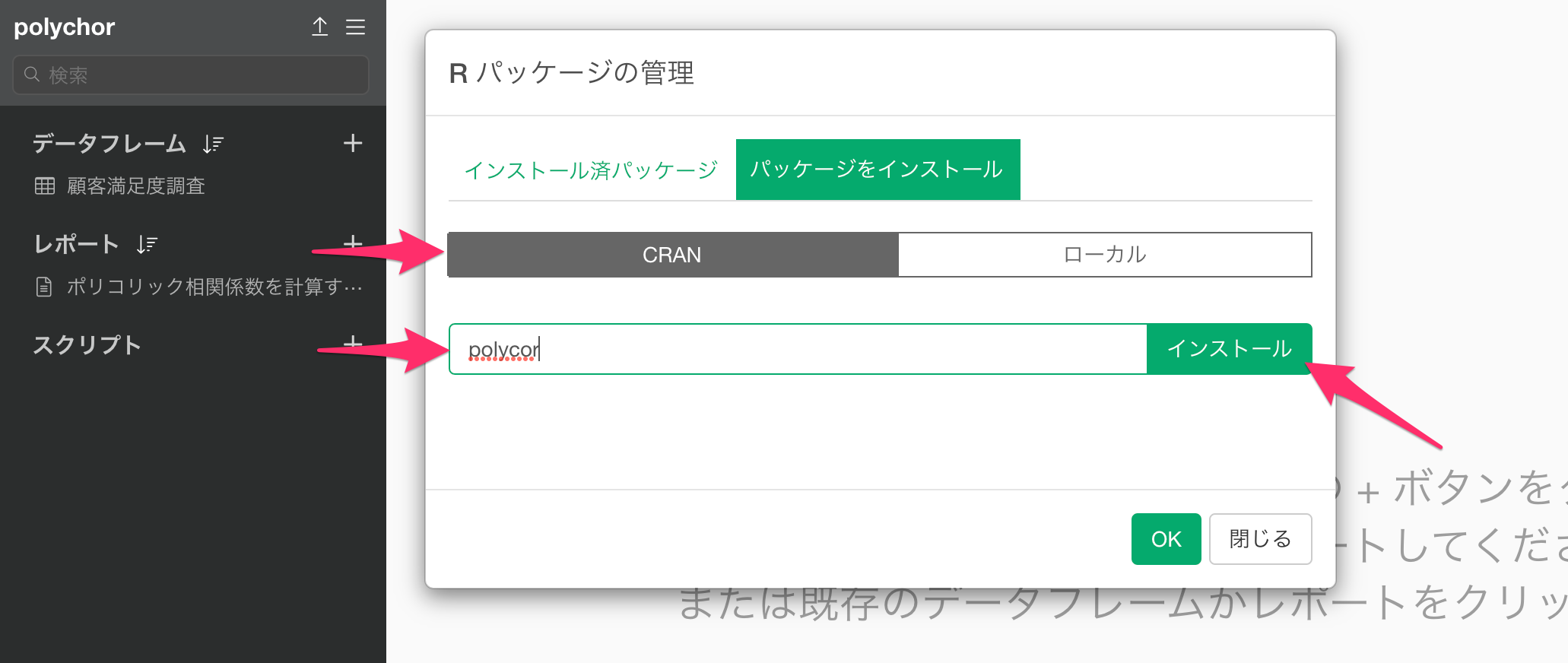
インストールが完了したら「polycorのインストールに成功しました」というテキストが表示されるので、「OK」ボタンをクリックします。
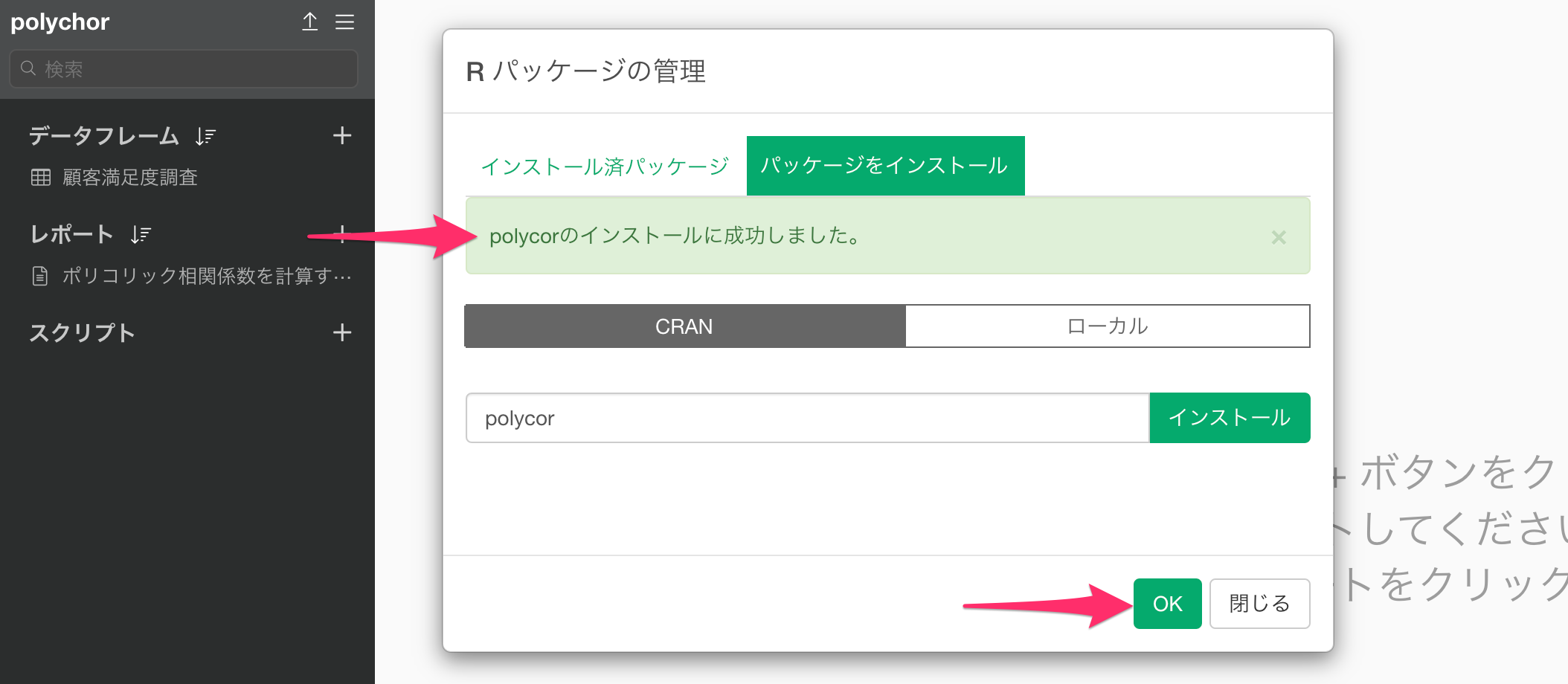
これでploycorパッケージをExploratoryにインストールすることができました。
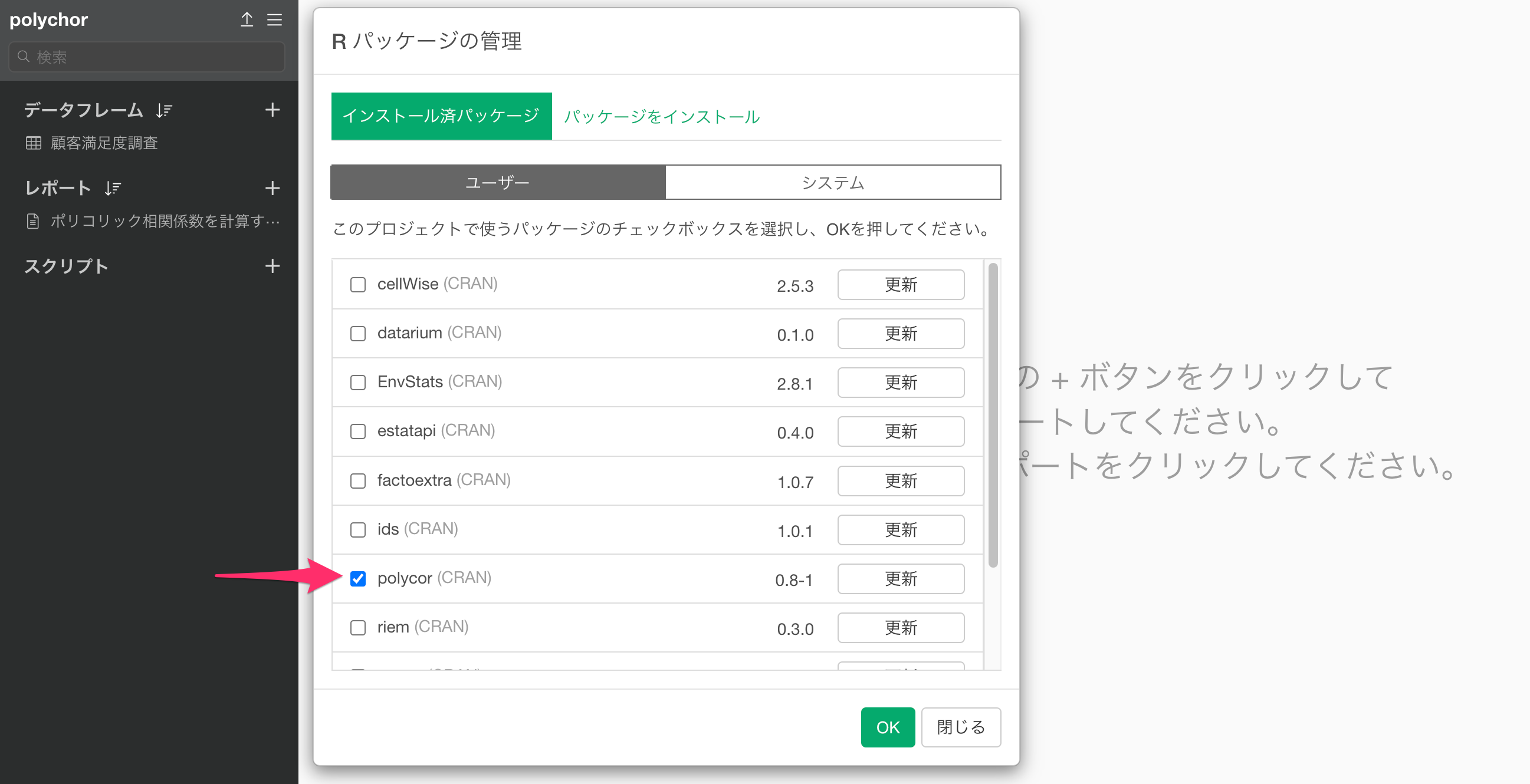
もし異なるプロジェクトでploycorパッケージを使用したい場合は、プロジェクトのメニューから「Rパッケージの管理」を開きます。
プロジェクトにploycorのパッケージにチェックをつけてOKボタンをクリックすることで、そのプロジェクトでploycorパッケージを使用できるようになります。
利用データ
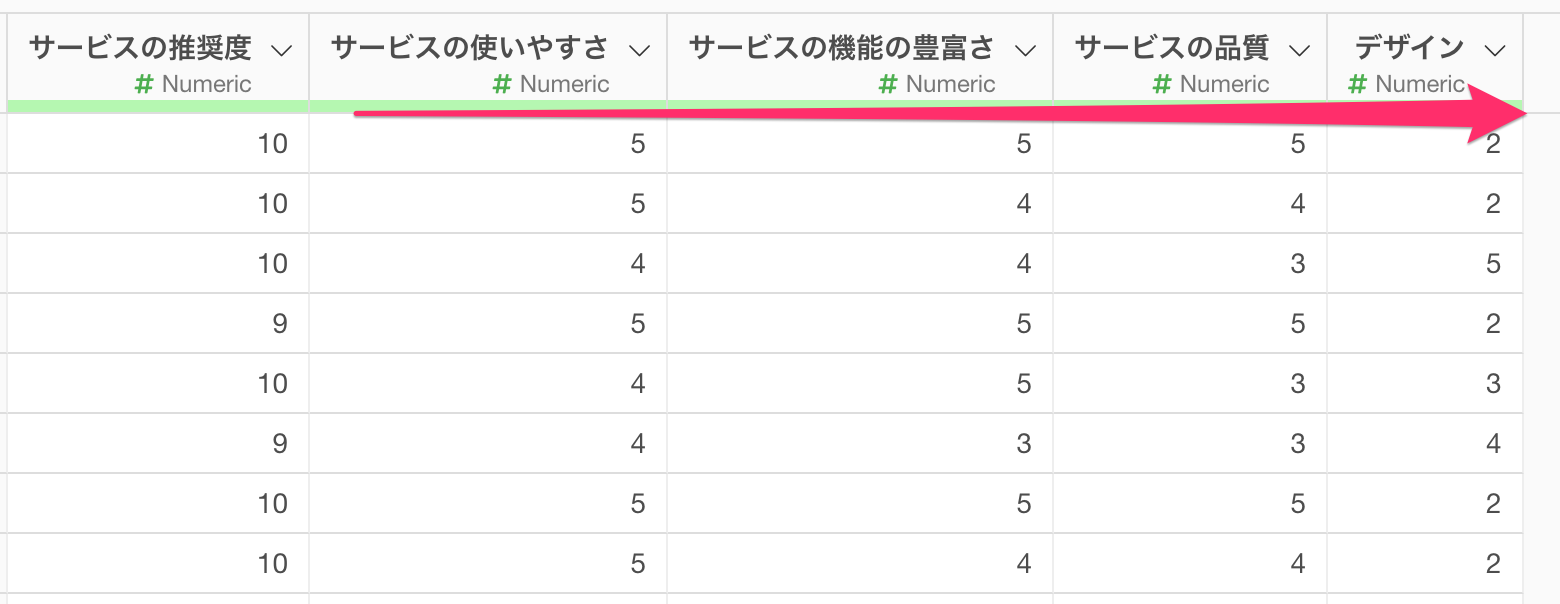
今回は1行が1回答になっているアンケートデータを使って、「サービスの推奨度」と他の列の「ポリコック相関係数」を計算します。
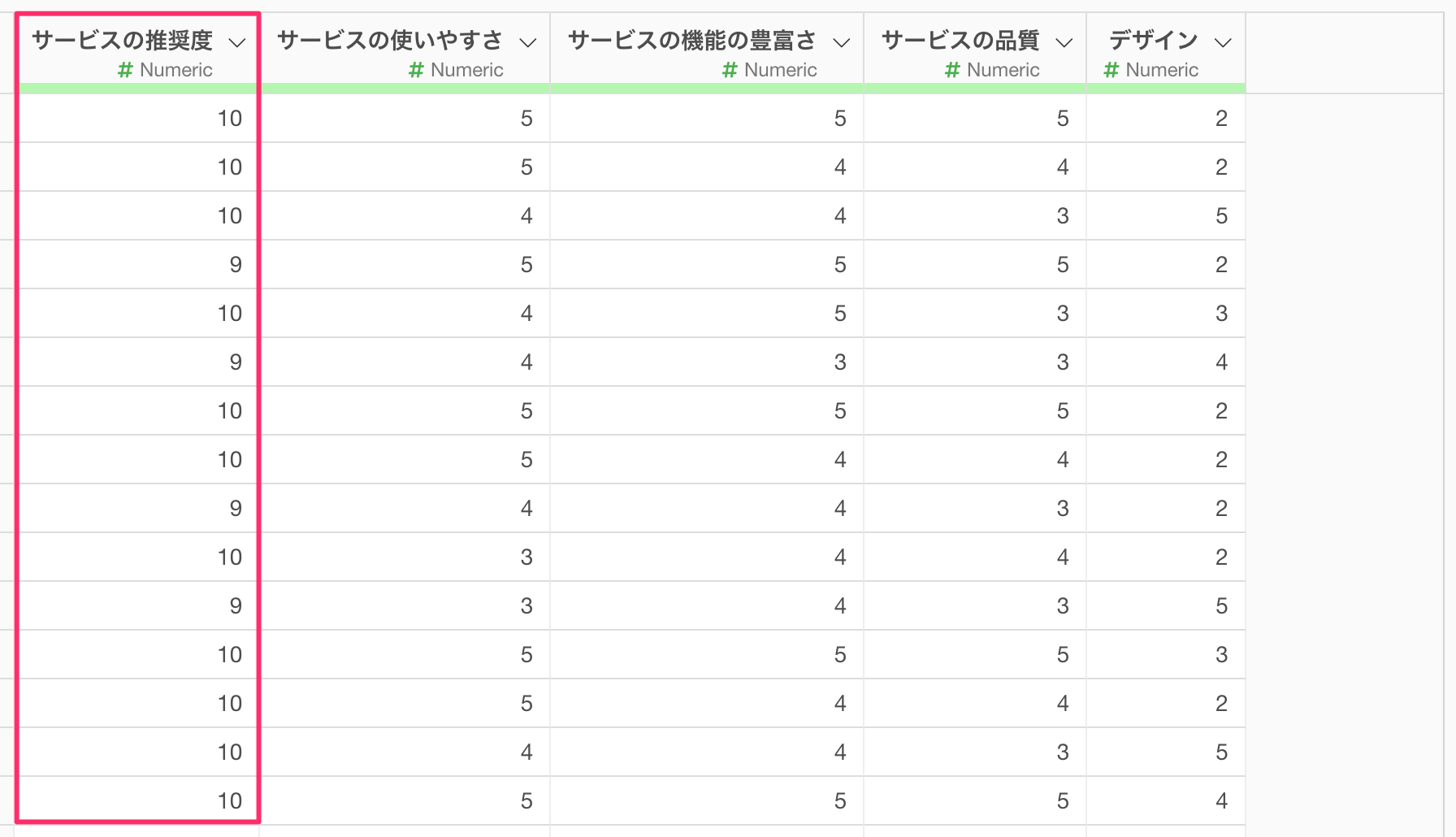
なお今回紹介する方法は、一番最初の列に相関を調べたい列(「サービスの推奨度」)を配置しておく必要があります。
また、データフレーム内の列はすべて数値型である必要がありますので、そのような形式になっていない場合、列の並び替えや、列の削除のステップを追加してデータを整える必要があります。
ポリコリック相関係数の計算
ポリコリック相関係数を計算するには、ステップメニューの「カスタムRスクリプト」を選択します。
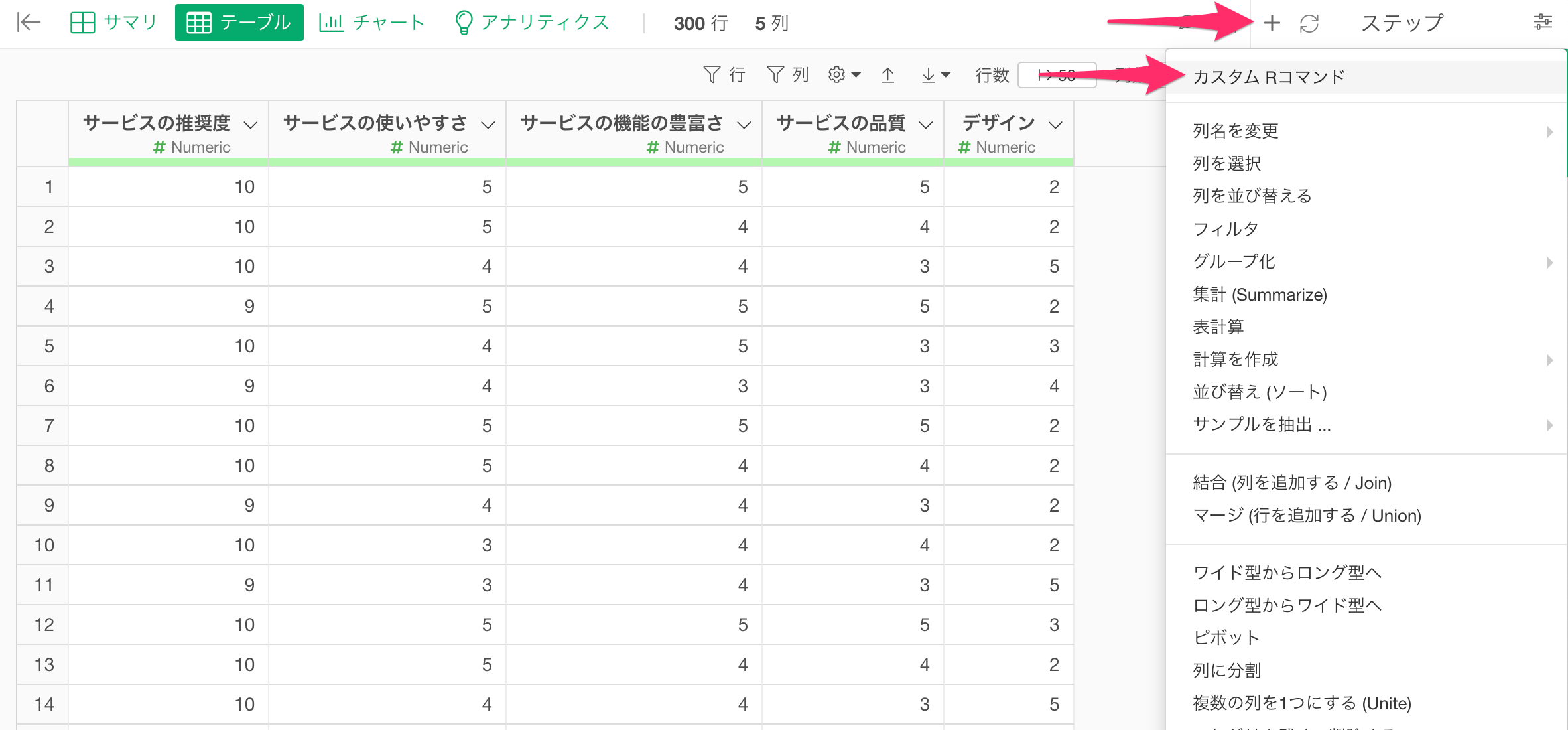
カスタムRコマンドを入力するためのダイアログが開いたら、ポリコリック相関係数を計算するための以下のコードをコマンドエディタに入力して実行します。
(function(df) {
df <- data.frame(df)
ポリコリック相関係数 <-c()
for(i in 2:ncol(df)) {
ポリコリック相関係数 <-c(ポリコリック相関係数, polychor(df[,1],df[,i]))
}
as.data.frame(ポリコリック相関係数)
}) カスタムRコマンドのステップが追加され、1列目である「サービスの推奨度」と各列の相関係数を計算できました。
カスタムRコマンドのステップが追加され、1列目である「サービスの推奨度」と各列の相関係数を計算できました。
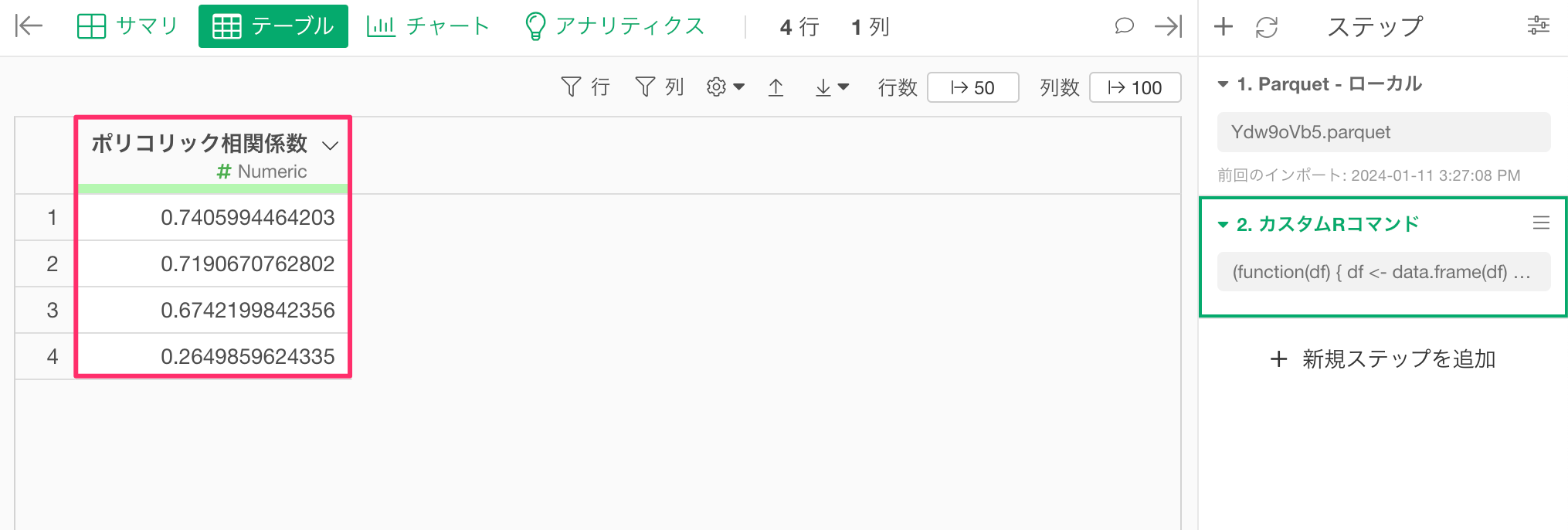
上記の実行結果からは、各行のポリコリック相関係数が「サービスの推奨度」がどの変数(列)との相関係数を表しているかがわかりません。
実はこちらの実行結果は、「サービスの推奨度」を除く、元の列の順番を表しています。
そこで、元の列名をロング型に変換したデータを新たに用意して、元のデータに列を追加していきます。
ポリコリック相関係数を計算する前のステップに移動して、ブランチを作成します。
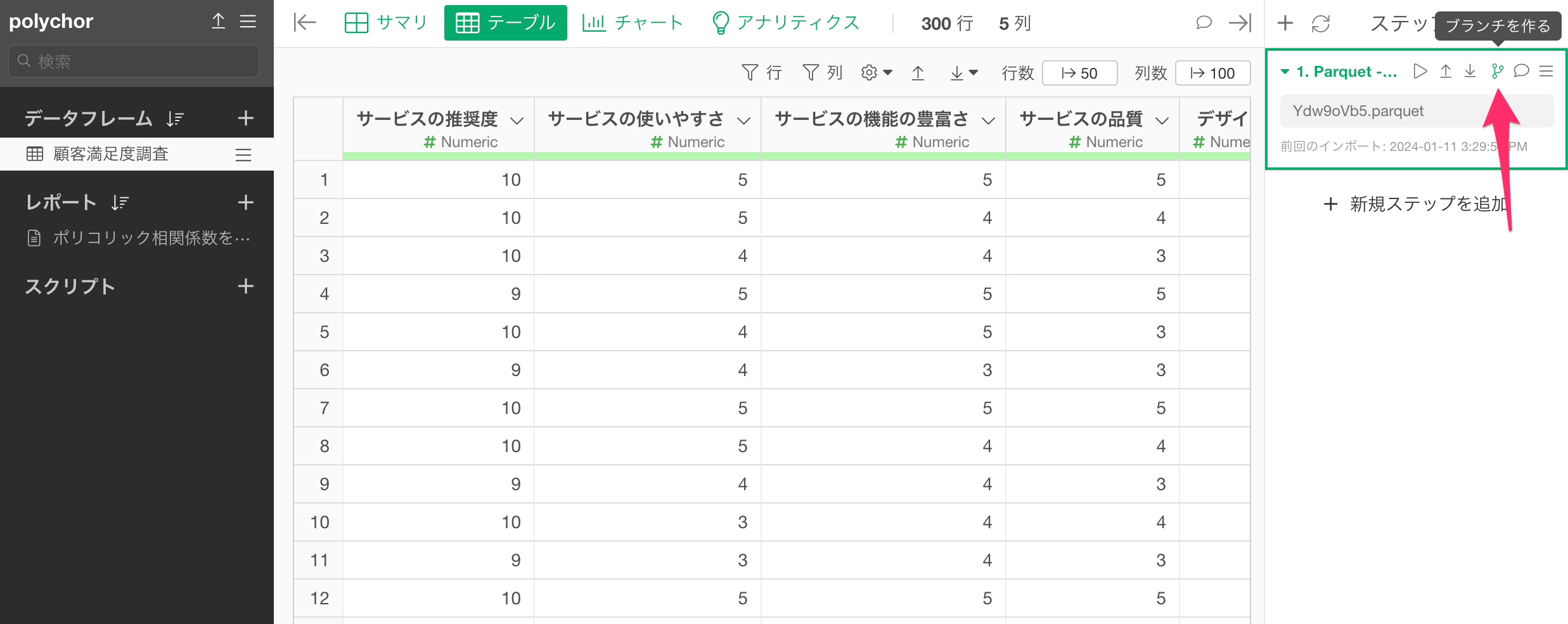
ブランチが作成できました。
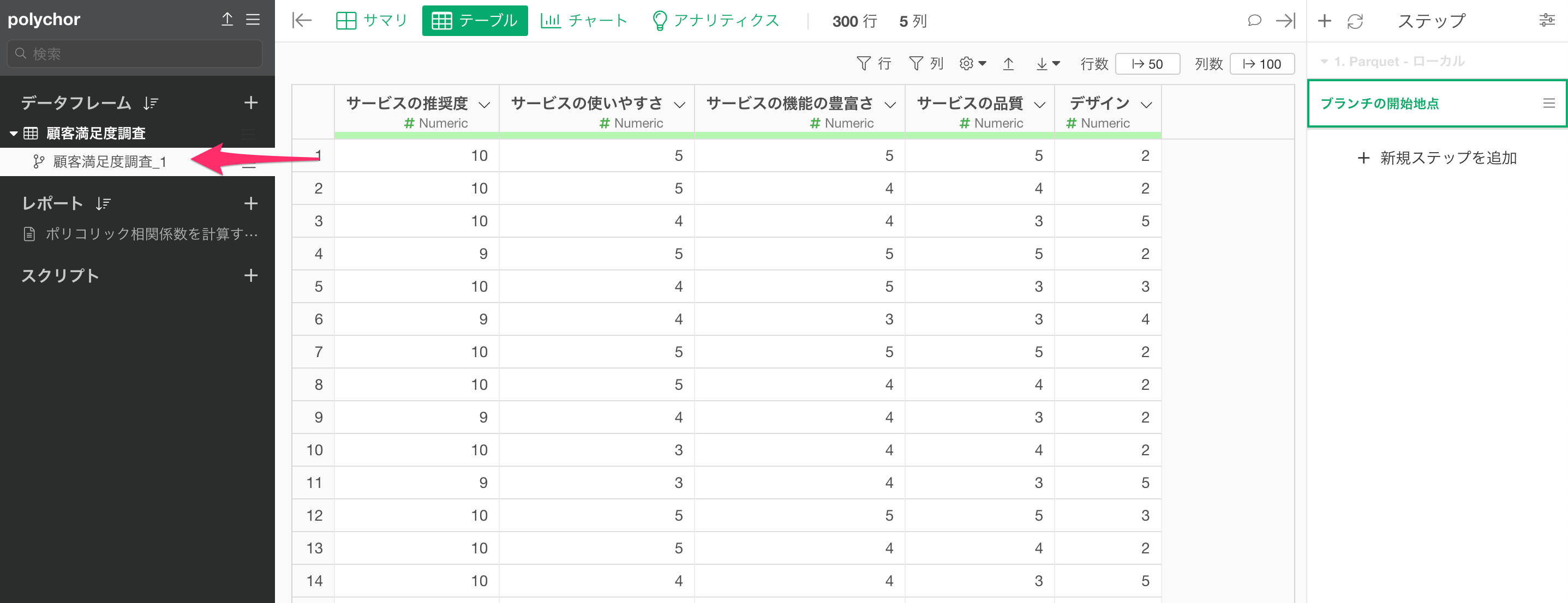 今回はサービスの推奨度の列は不要なので、任意の列から「列を選択/削除」を選択します。
今回はサービスの推奨度の列は不要なので、任意の列から「列を選択/削除」を選択します。
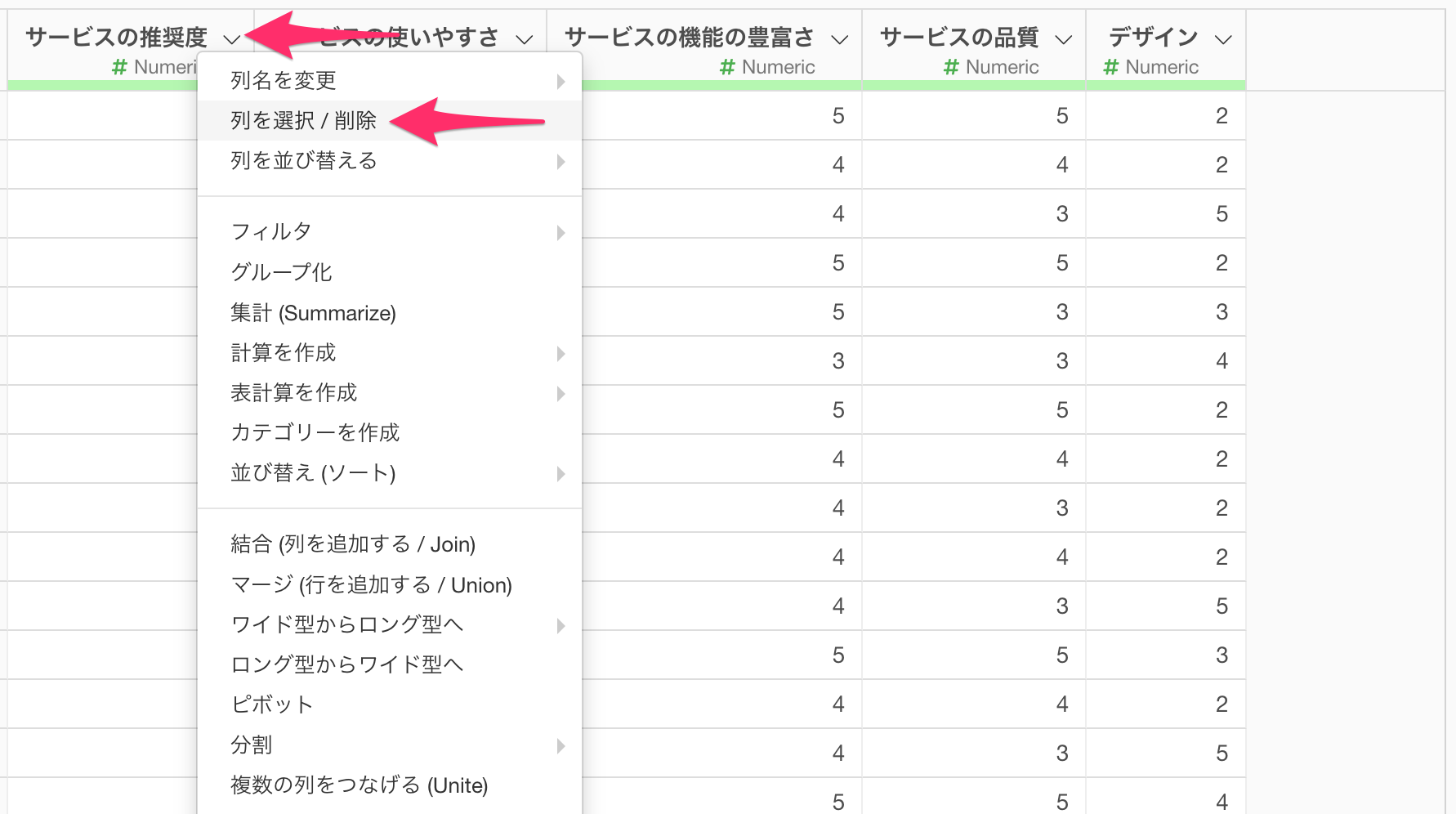
列を選択するダイアログが開いたら、「取り除く」にチェックを付けて、「サービスの推奨度」を選択し、実行します。
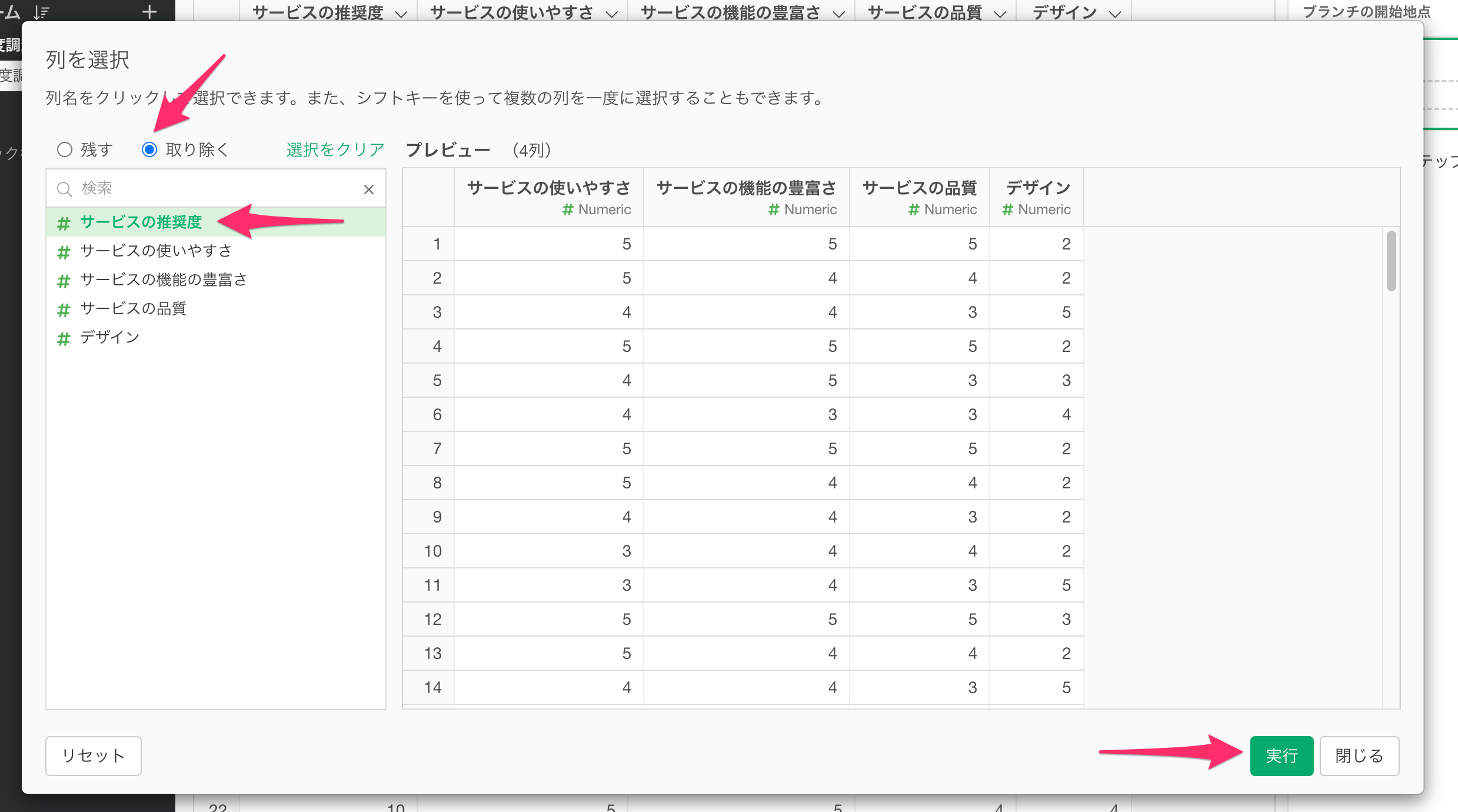
「サービスの推奨度」の列を取り除けました。
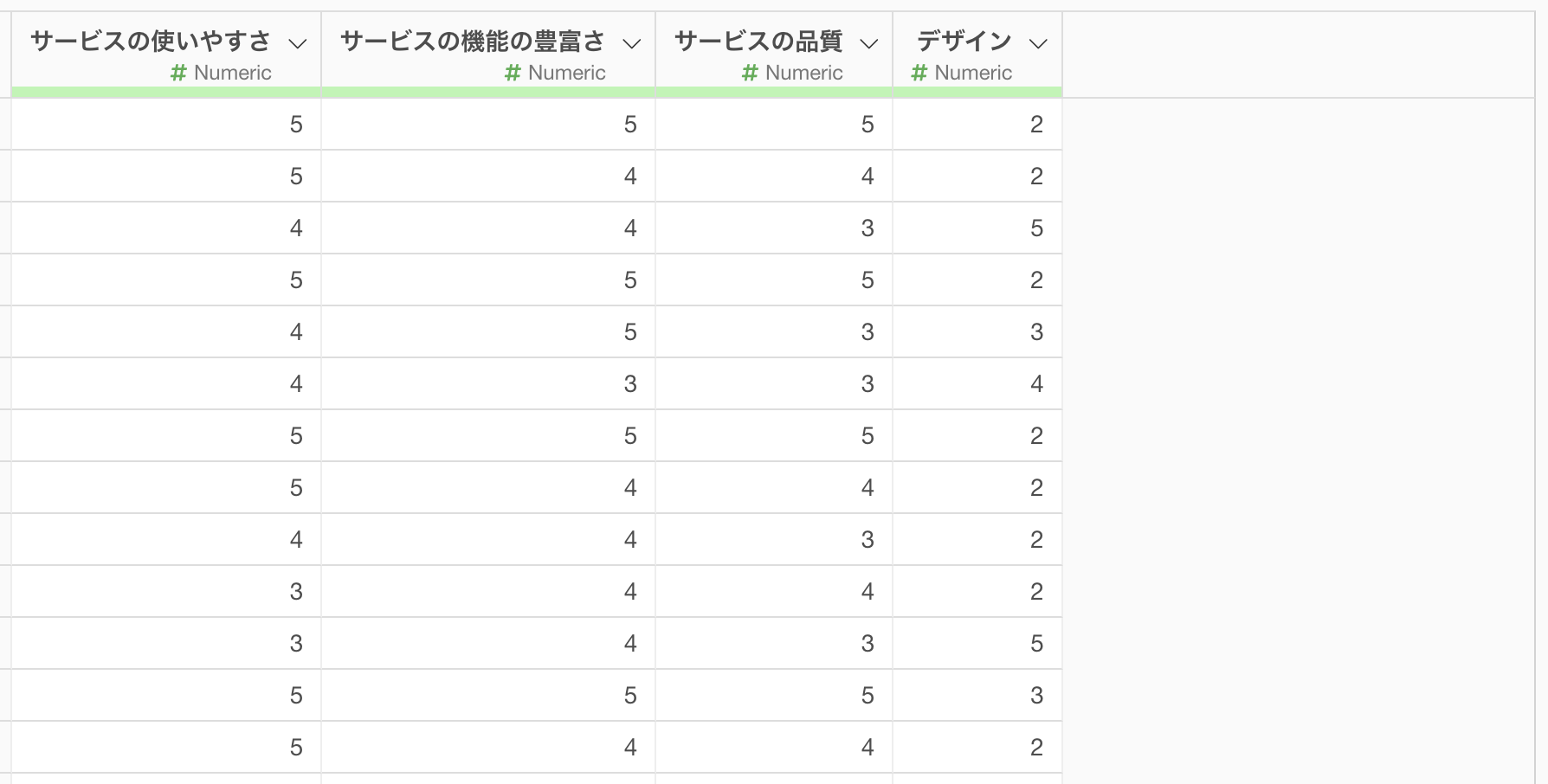
続いて、ワイド型のデータをロング型に変換します。最初の列から最後の列を選択した状態で、任意の列ヘッダーメニューから、「ワイド型からロング型へ」の「選択された範囲」を選択します。
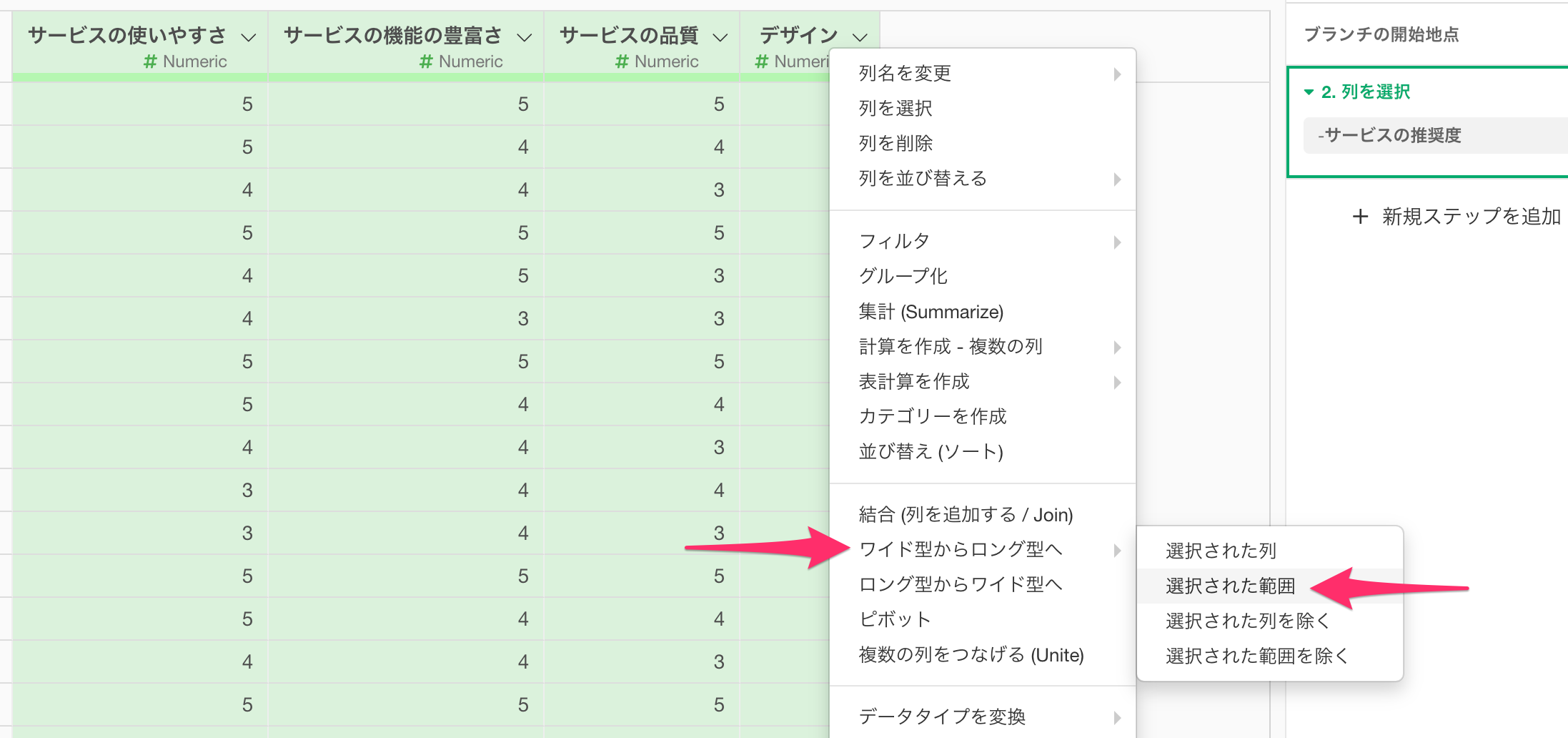
ワイドからロング型へのダイアログが開いたら、新しい列名の「キー列」に「質問」、値の列は今回は使わないので、「value」のまま実行します。
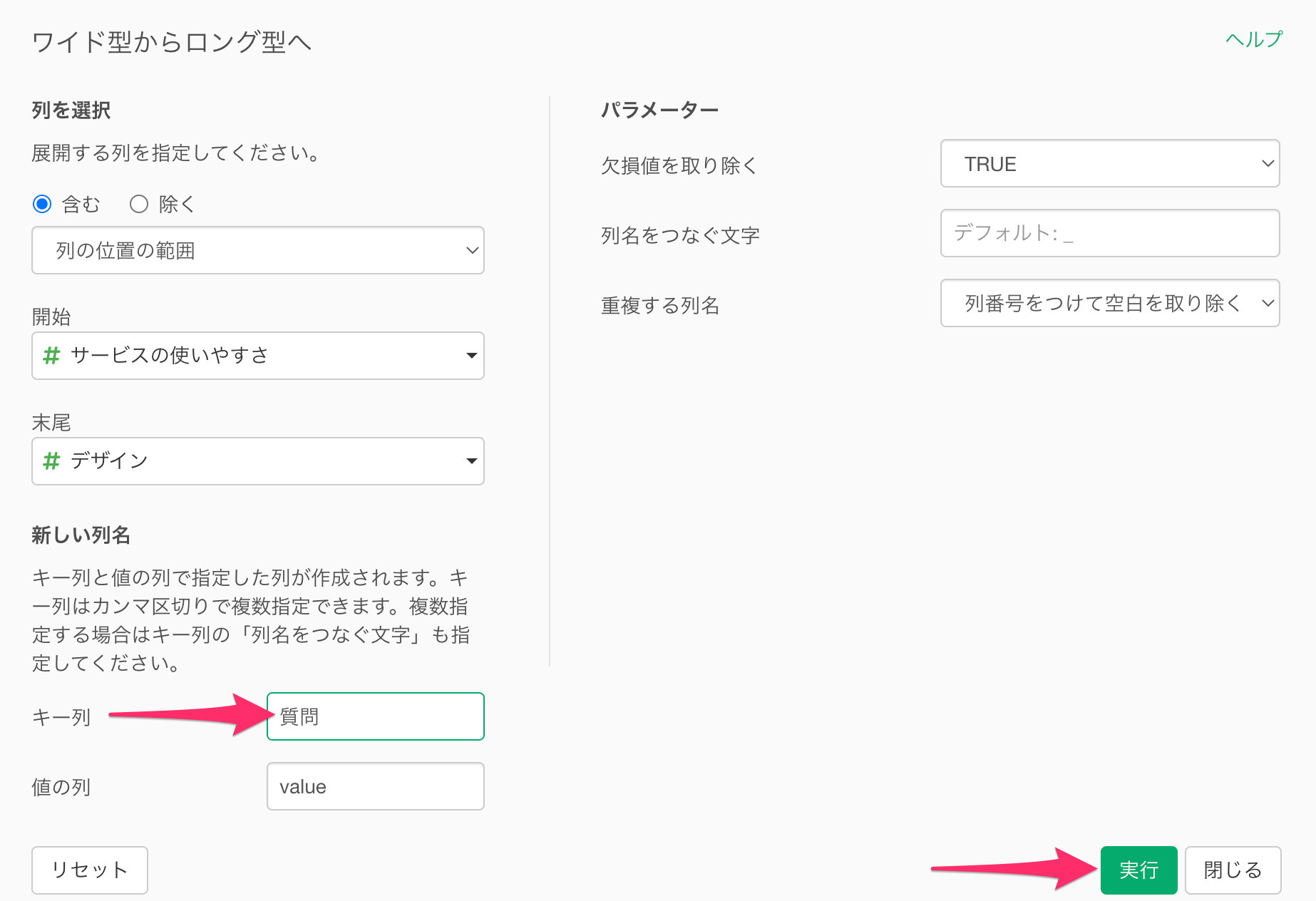
ワイド型のデータをロング型に変換できました。
今回のvalueの列は特に必要ないので、valueの列ヘッダーメニューから「列を選択/削除」を選択し、valueの列を取り除きます。
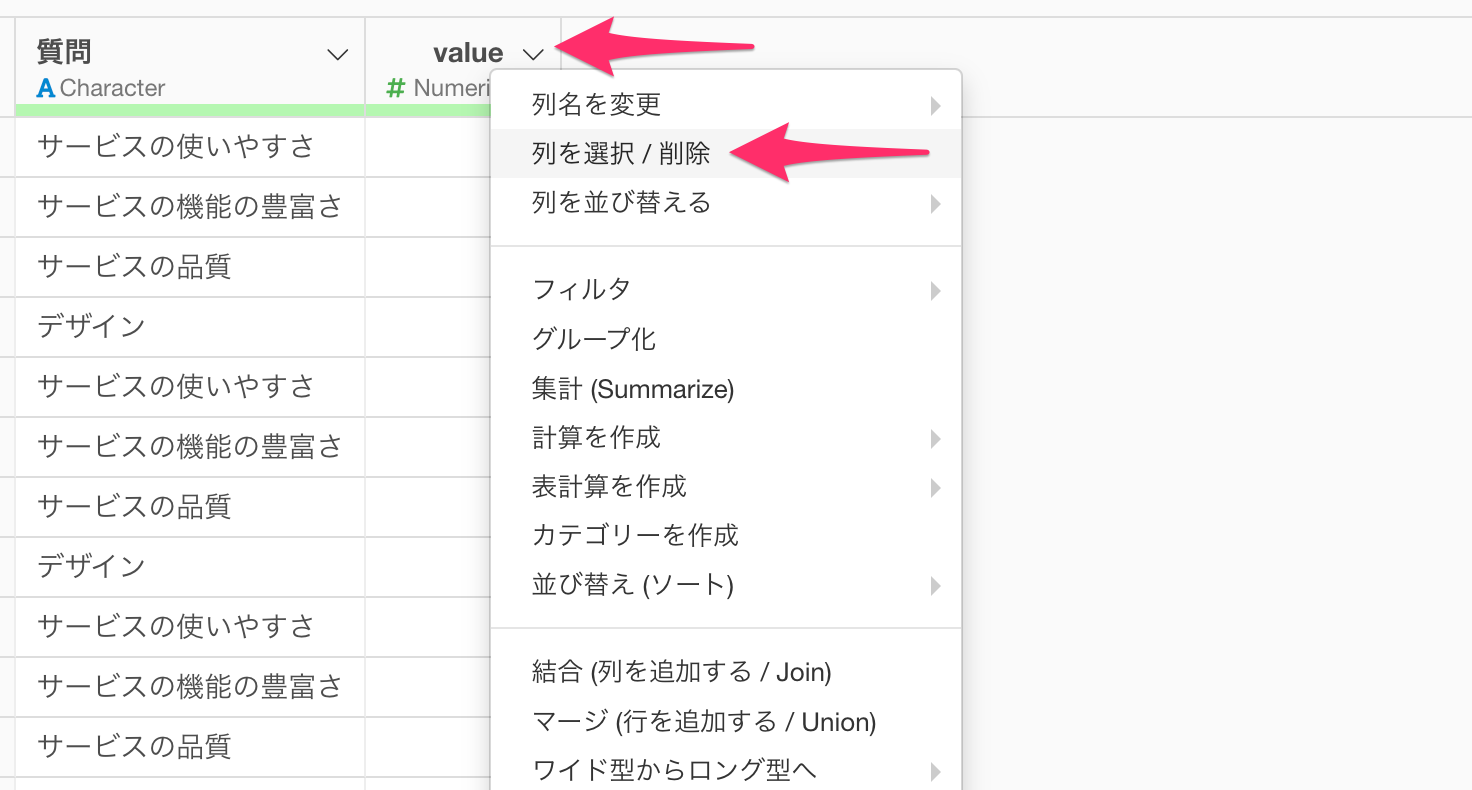
valueの列を取り除けました。
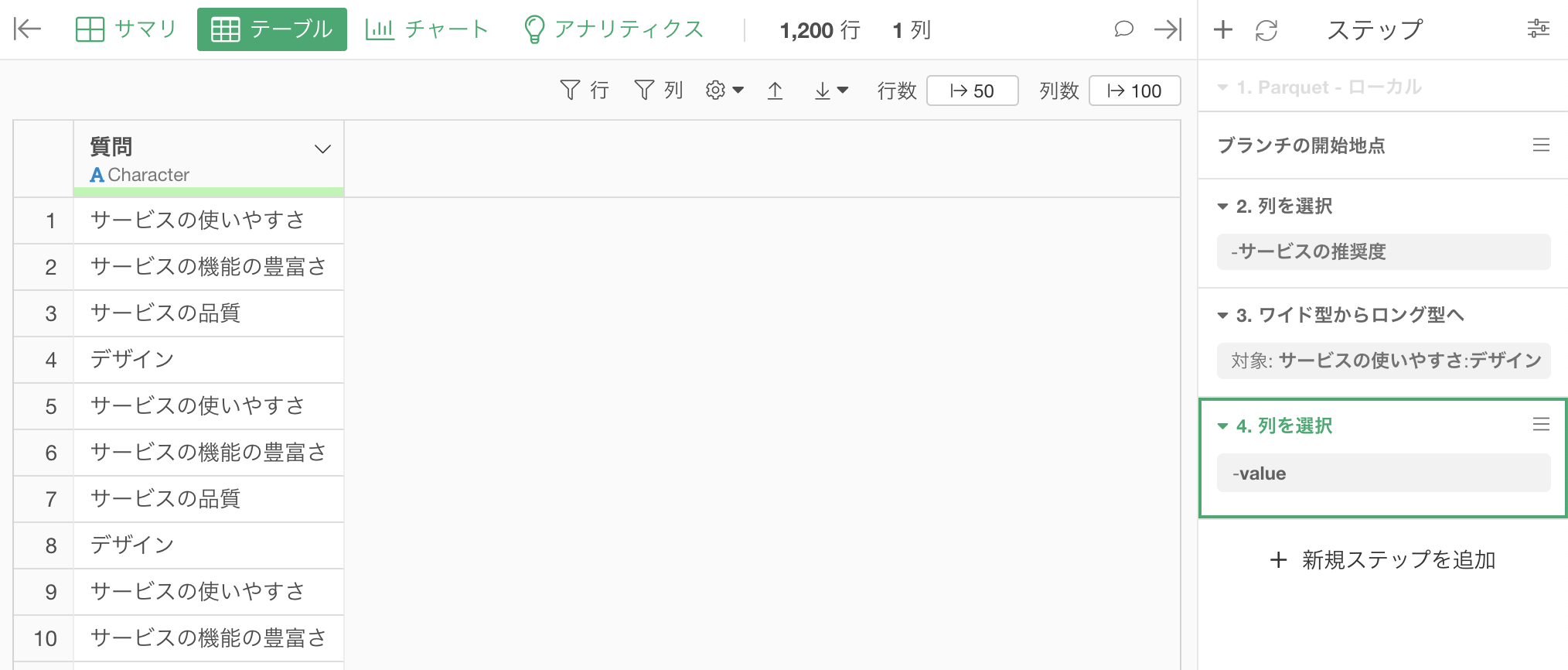
最終的に必要なのは一意な質問の情報(1行目から4行目)だけですので、データをフィルタして元の列の順に、一意な情報だけにデータをフィルタします。
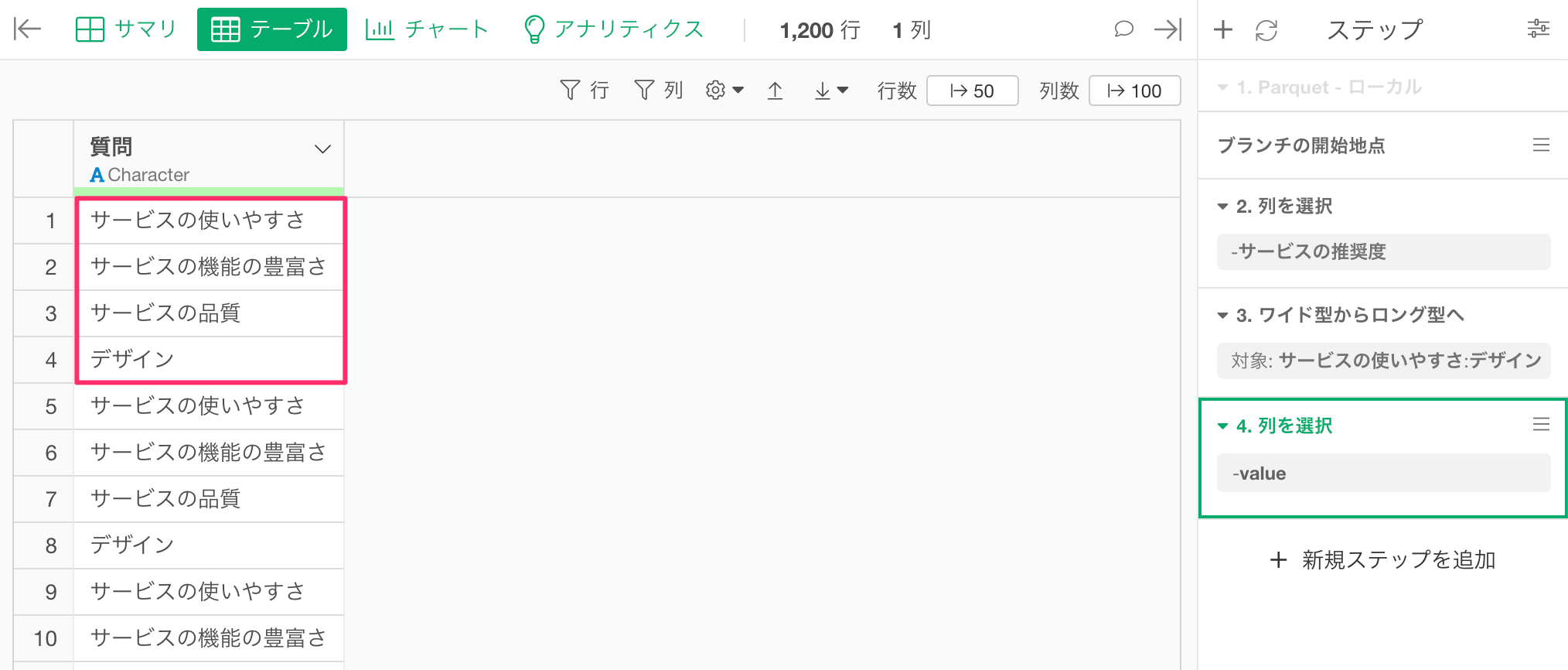
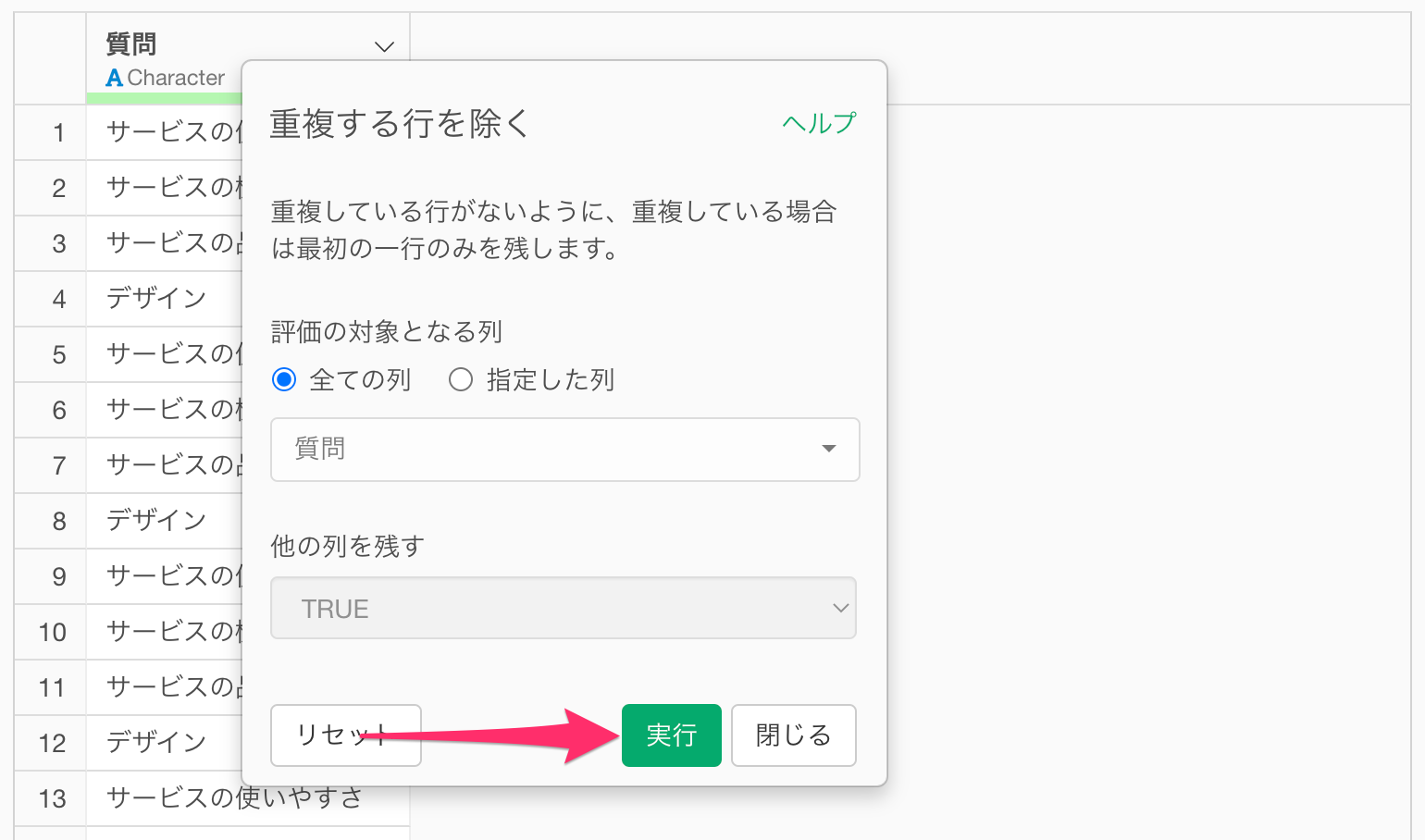
「質問」の列ヘッダーメニューから「フィルタ」の「重複する行を除く」を選択し、
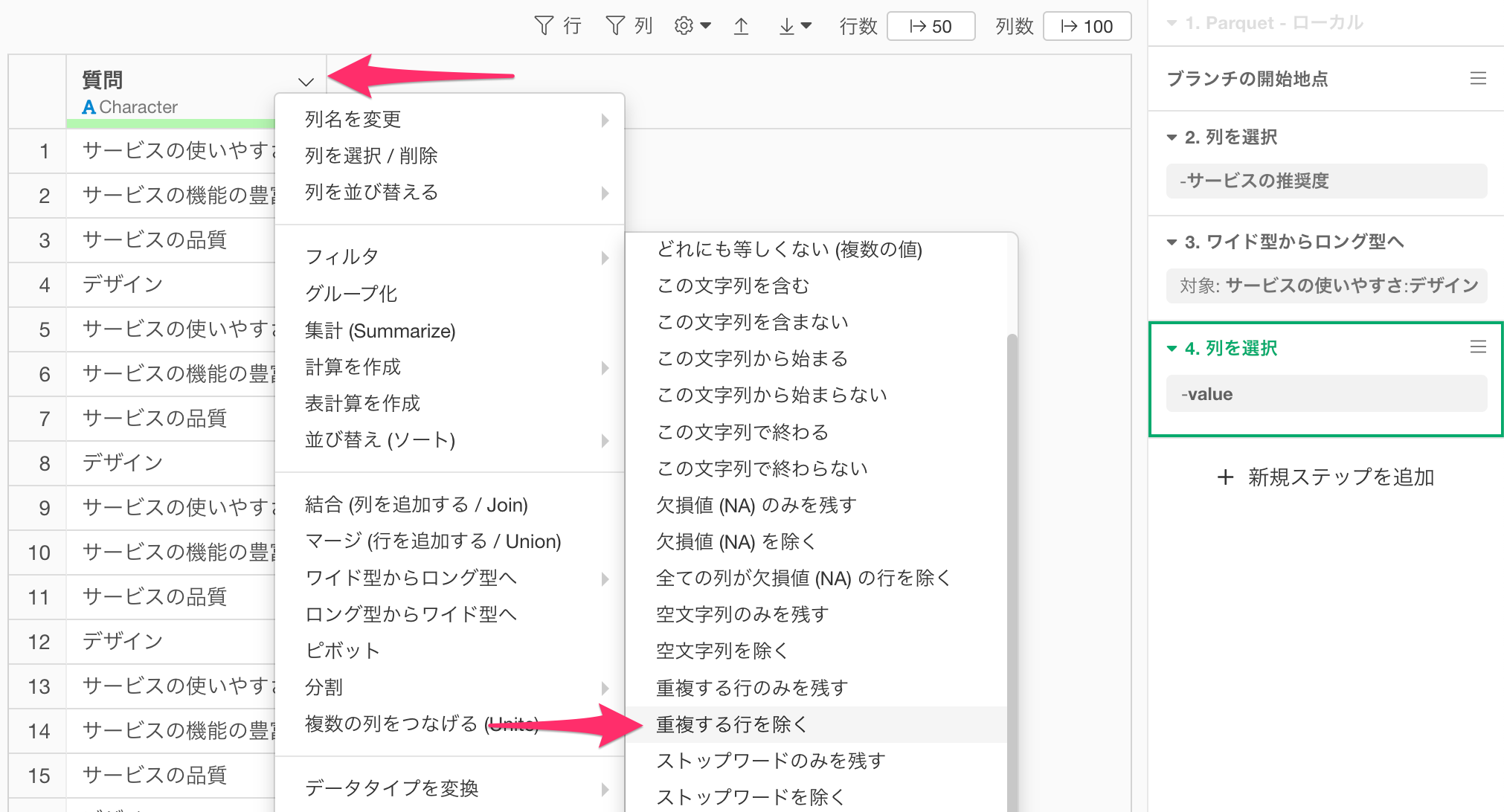
重複する行の除くダイアログが表示されたら、そのまま実行します。
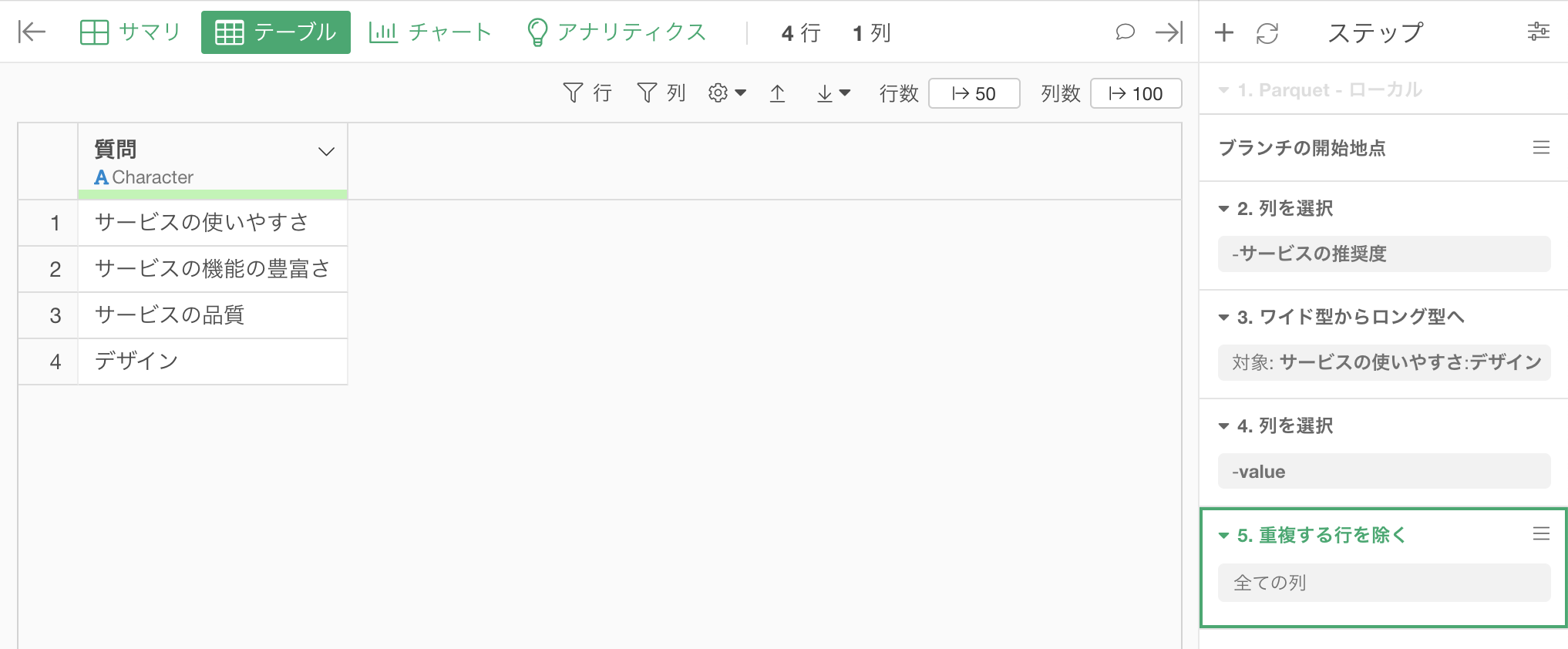
 これで期待しているデータを作ることができました。
これで期待しているデータを作ることができました。
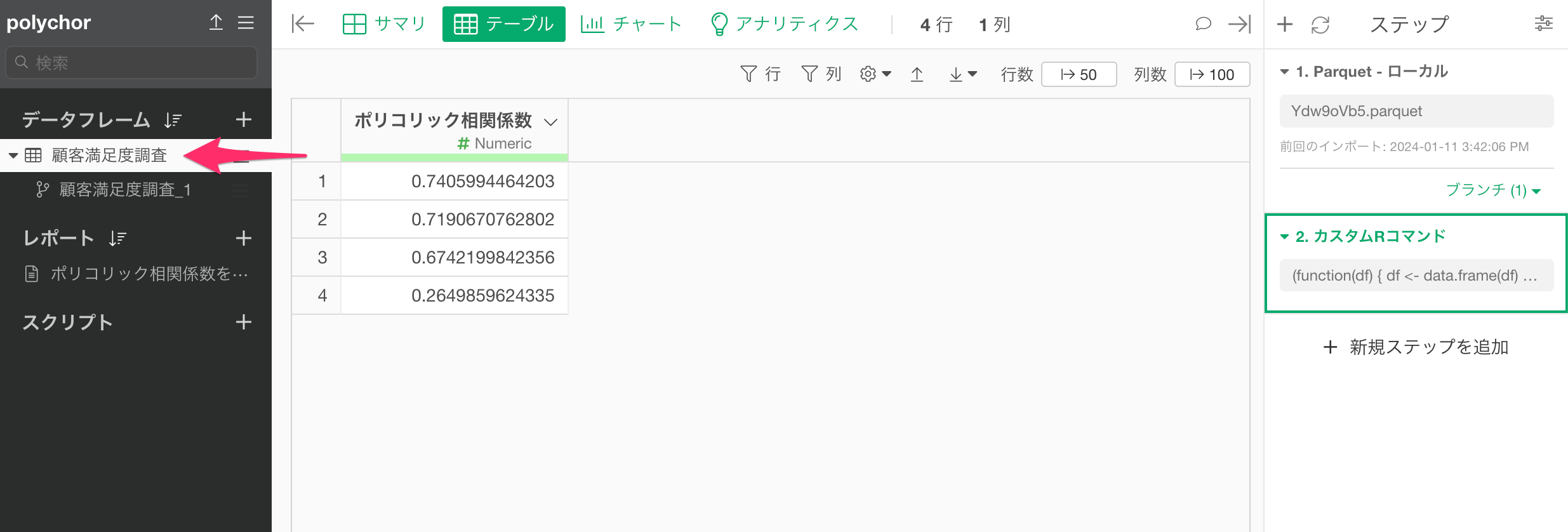
後は元のデータフレームに作成した列を追加します。
元のデータフレームに戻ります。
ステップメニューから、「他のデータフレームから列を追加(bind_cols)」を選択します。
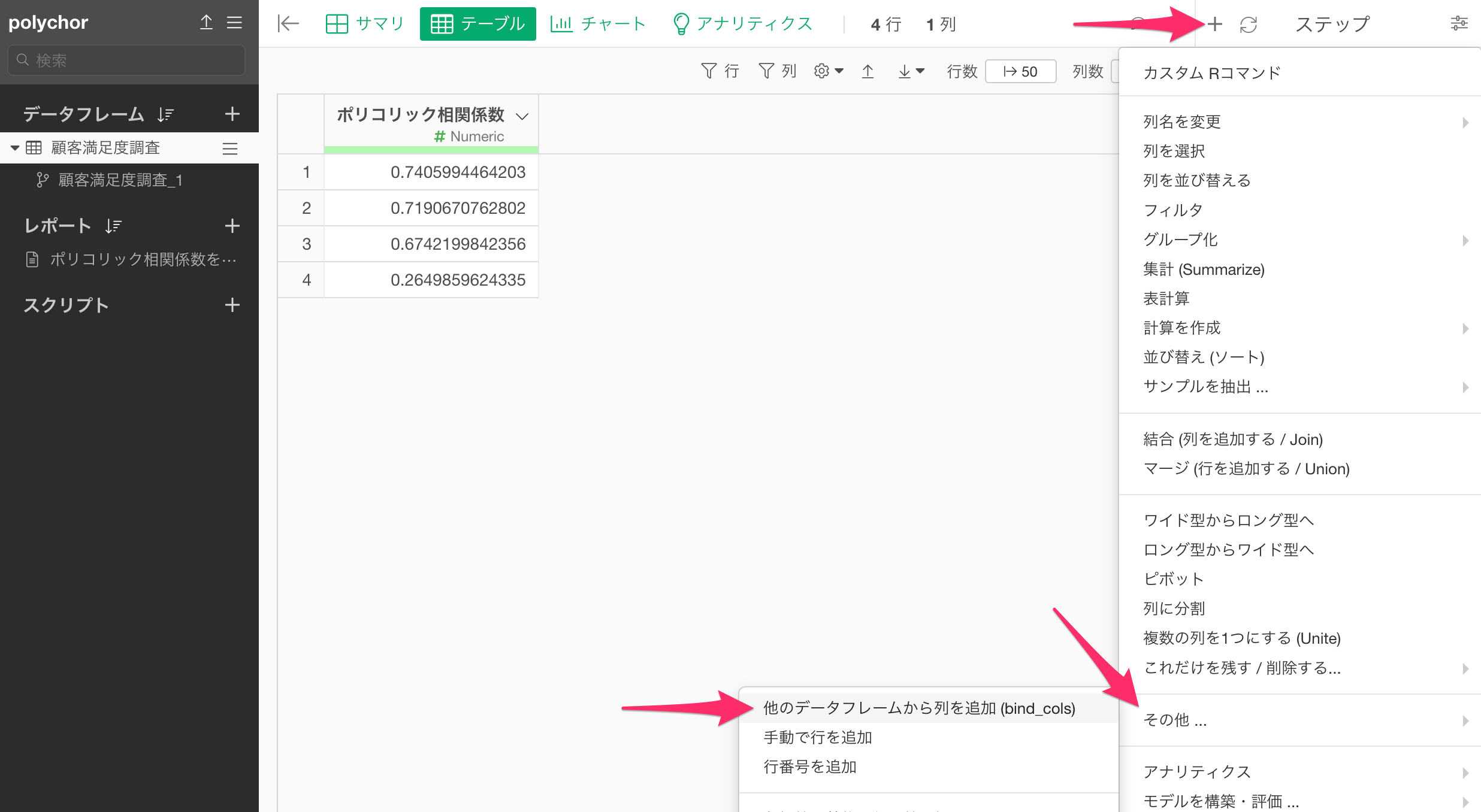
「他のデータフレームから列を追加(bind_cols)」のダイアログが開いたら、整えた列名の情報を含むデータフレームを選択し実行します。
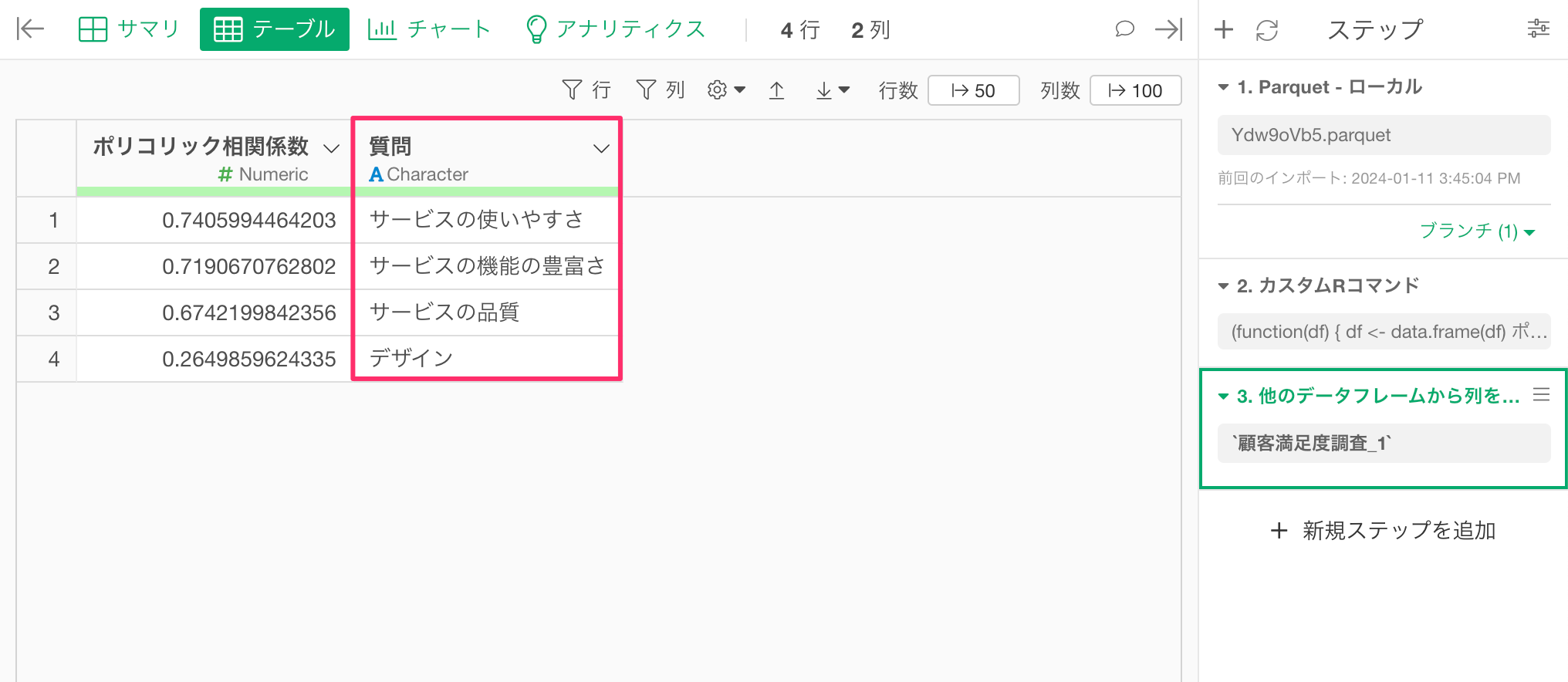
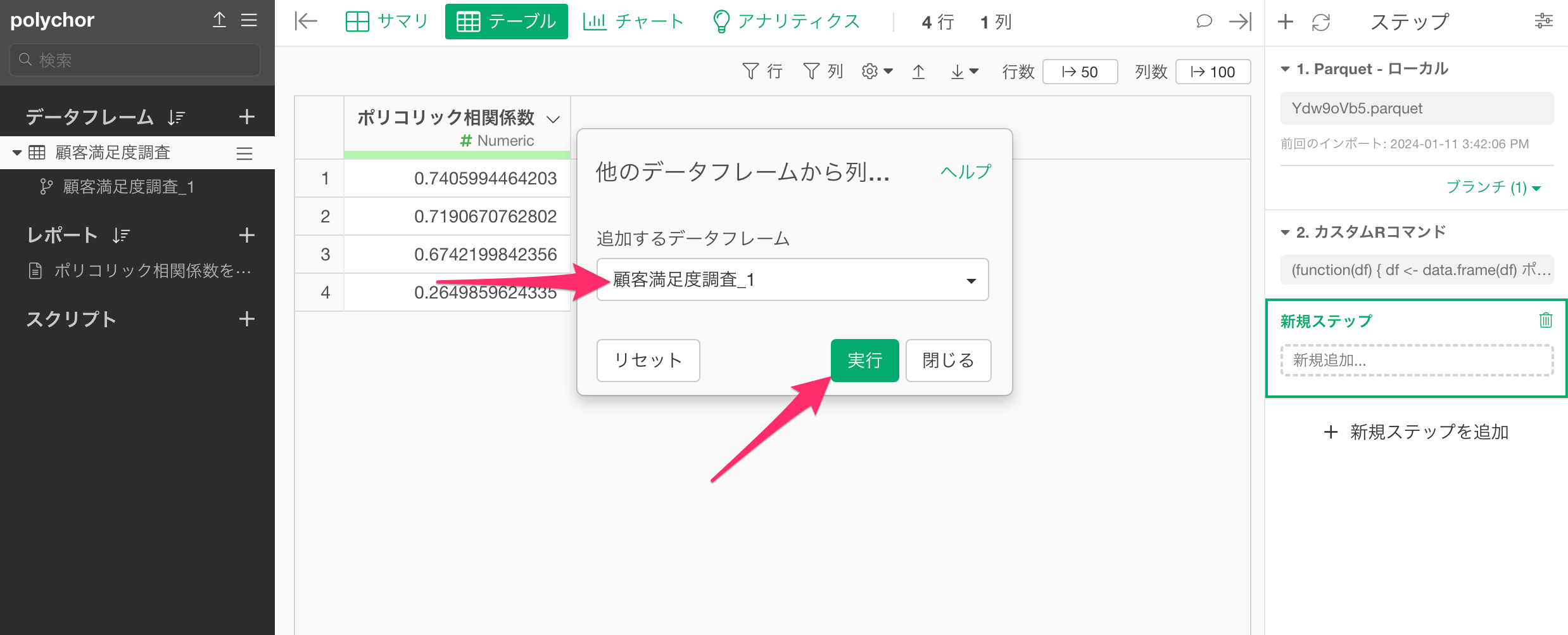 質問名を元のデータフレームに追加できました。
質問名を元のデータフレームに追加できました。
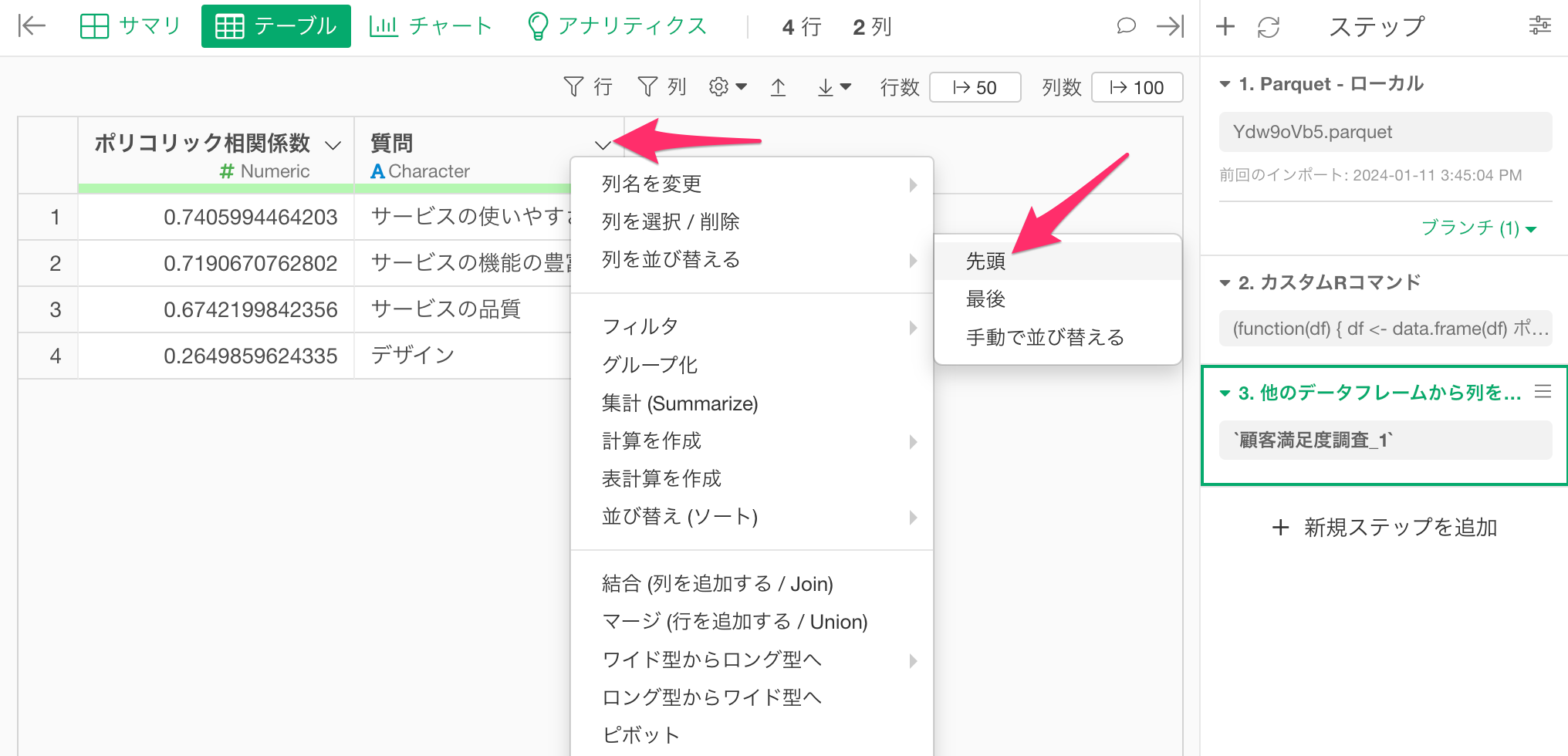
最後に質問名を先頭に並び替えます。
これで、質問ごとに「サービスの推奨度」との相関係数の情報をまとめたデータを作成できました。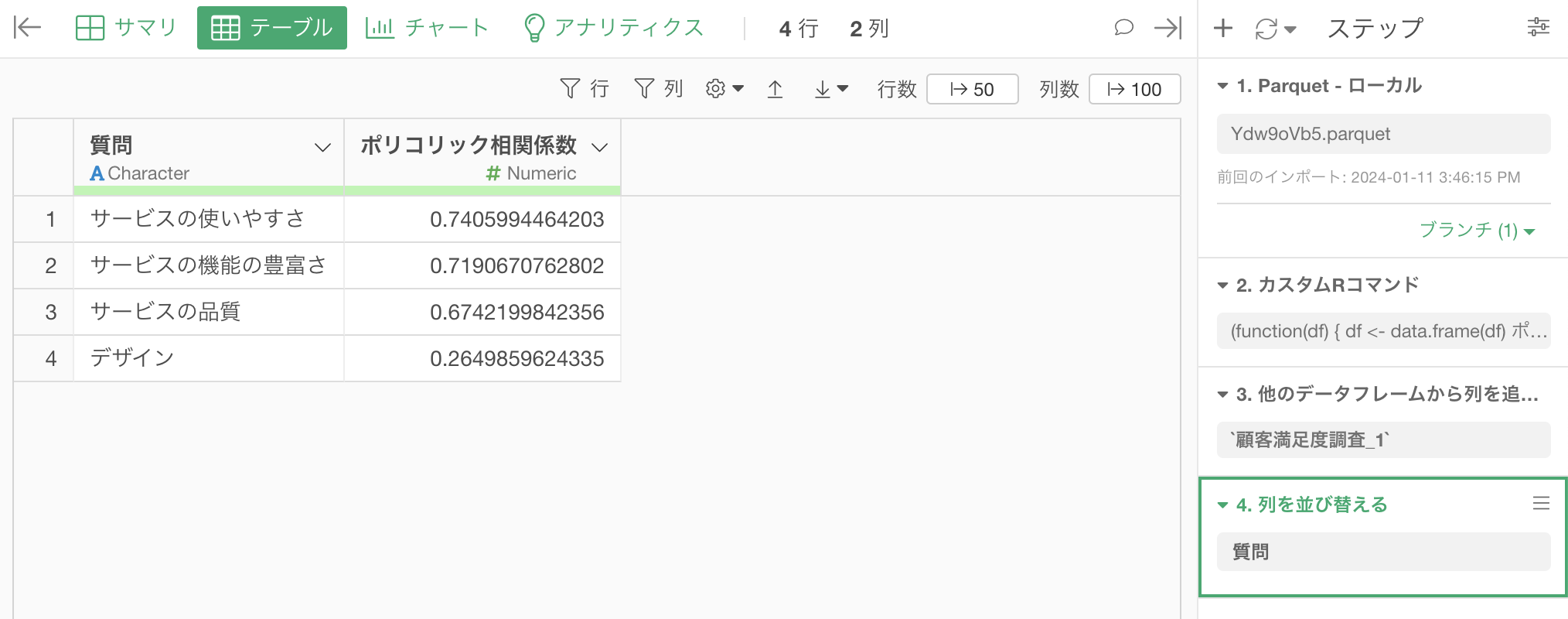
ポリコリック相関係数の相関行列を作る方法
ノートとして結果を確認する
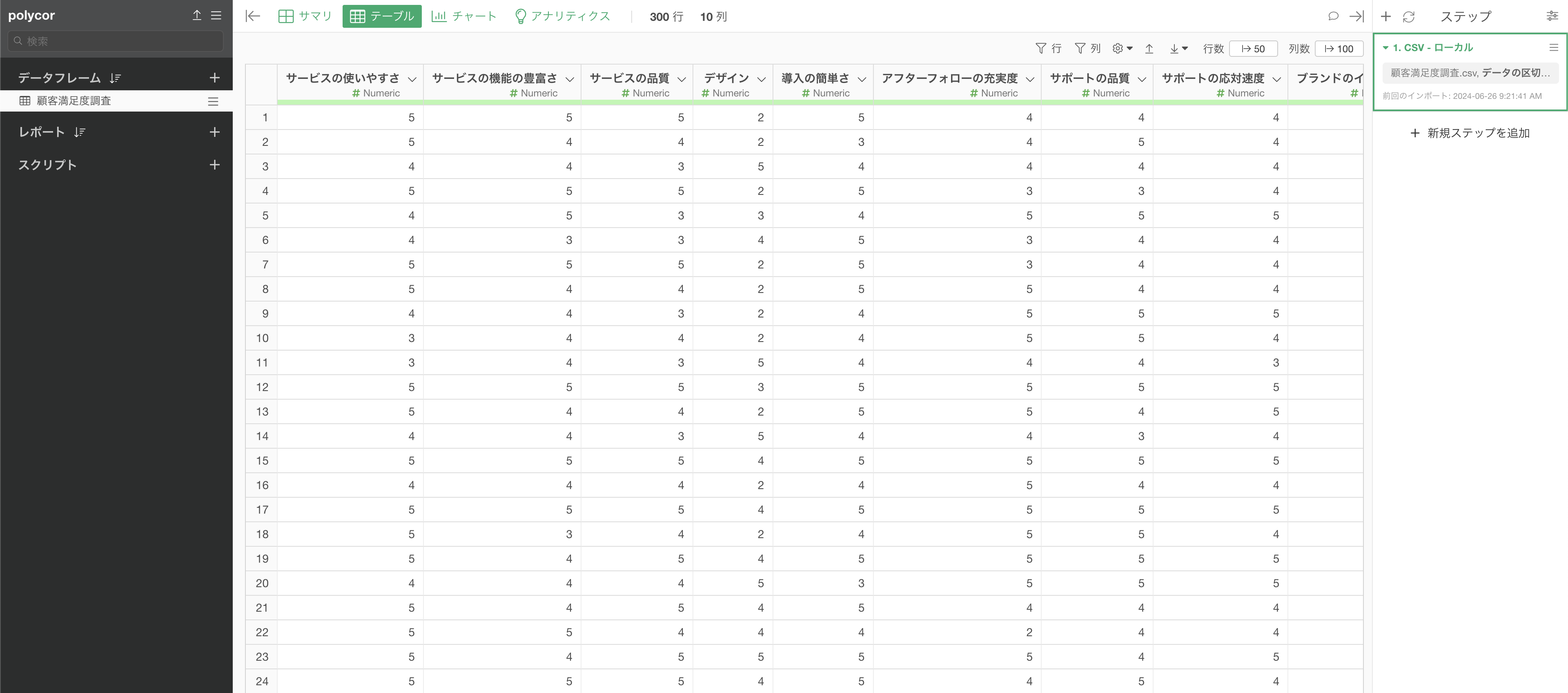
例えば、以下のように5段階評価のアンケートの回答を持つ数値列があったとします。このデータフレームをもとに、ポリコリック相関係数の相関行列を確認したいとします。
今回使用するpsychパッケージは、Exploratoryでデフォルトでインストールされているパッケージのため、新規のRパッケージのインストールは必要ありません。
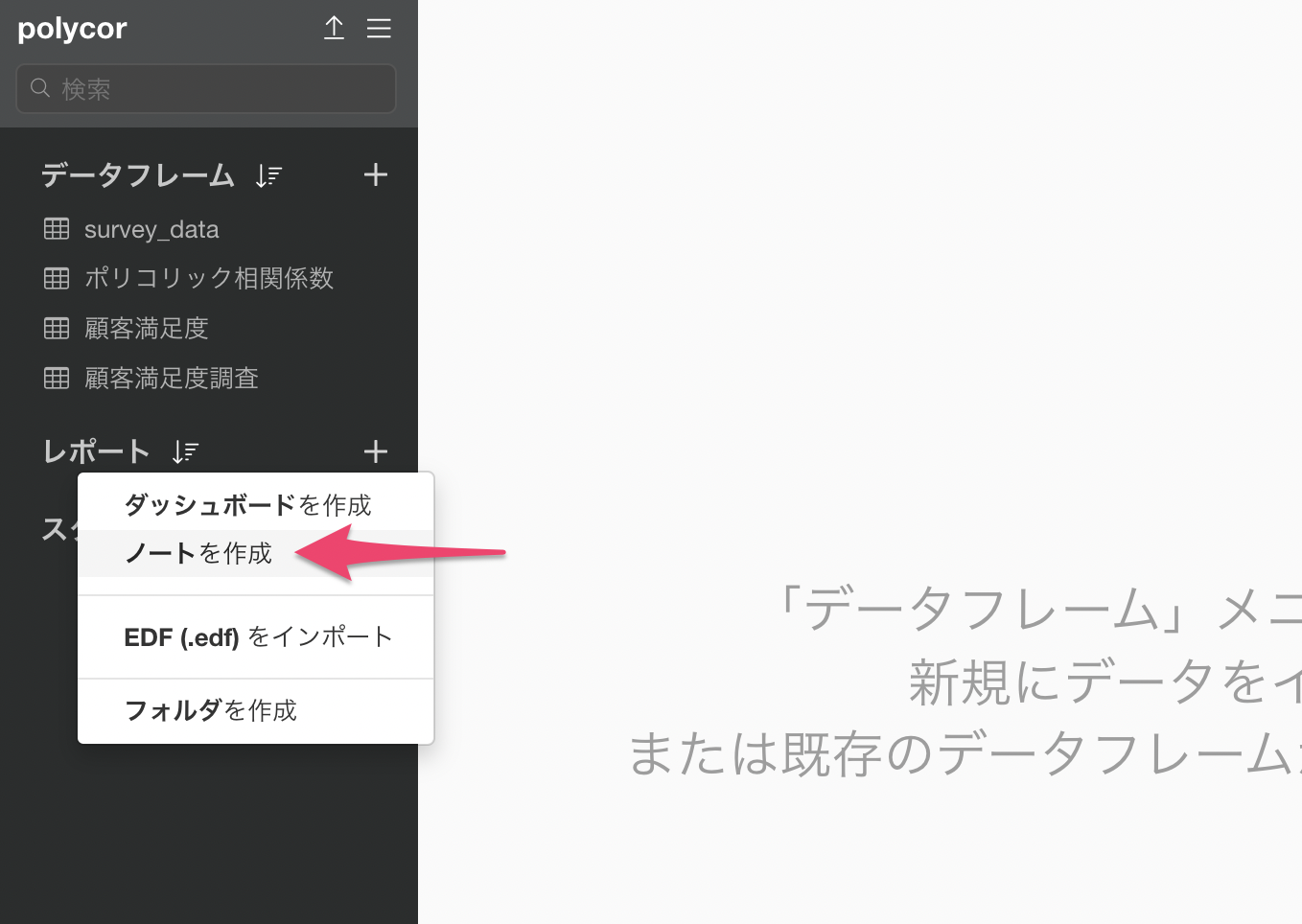
レポートのプラスボタンから「ノートを作成」を選択します。
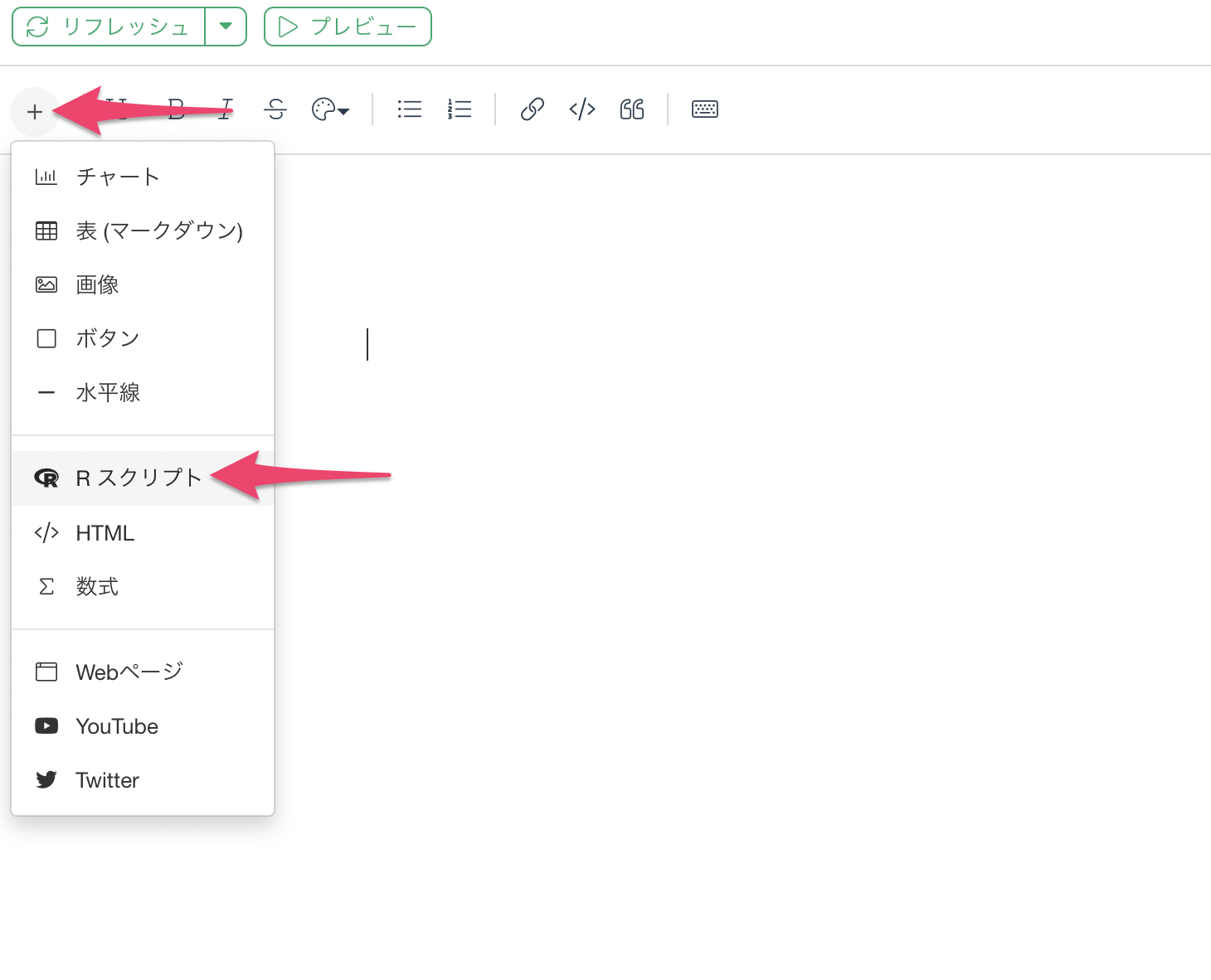
ノートのウィンドウが表示されるため、左上にあるプラスボタンから「Rスクリプト」を選択します。
Rスクリプトには以下のように指定します。2行目の「データフレーム名を指定」を変更してください。
# データフレーム名を指定
data <- データフレーム名を指定
# データフレームから列名を取得
col_names <- names(data)
# ポリコリック相関係数を計算
cor_matrix <- psych::polychoric(data[, col_names])
# 結果をデータフレームに変換して表示
data.frame(cor_matrix$rho)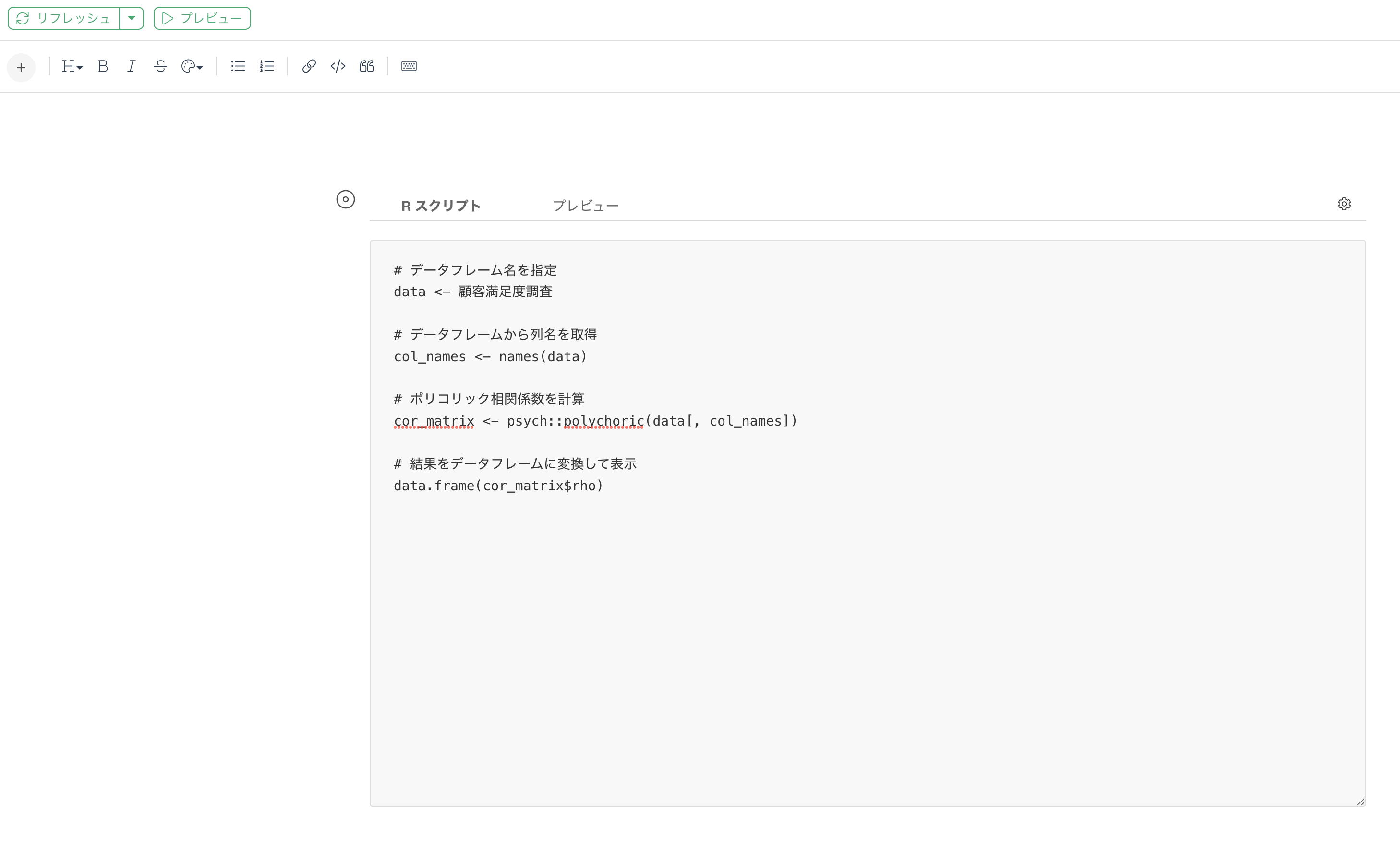
プレビューをクリックすることで、ポリコリック相関係数の相関行列を確認することができました。
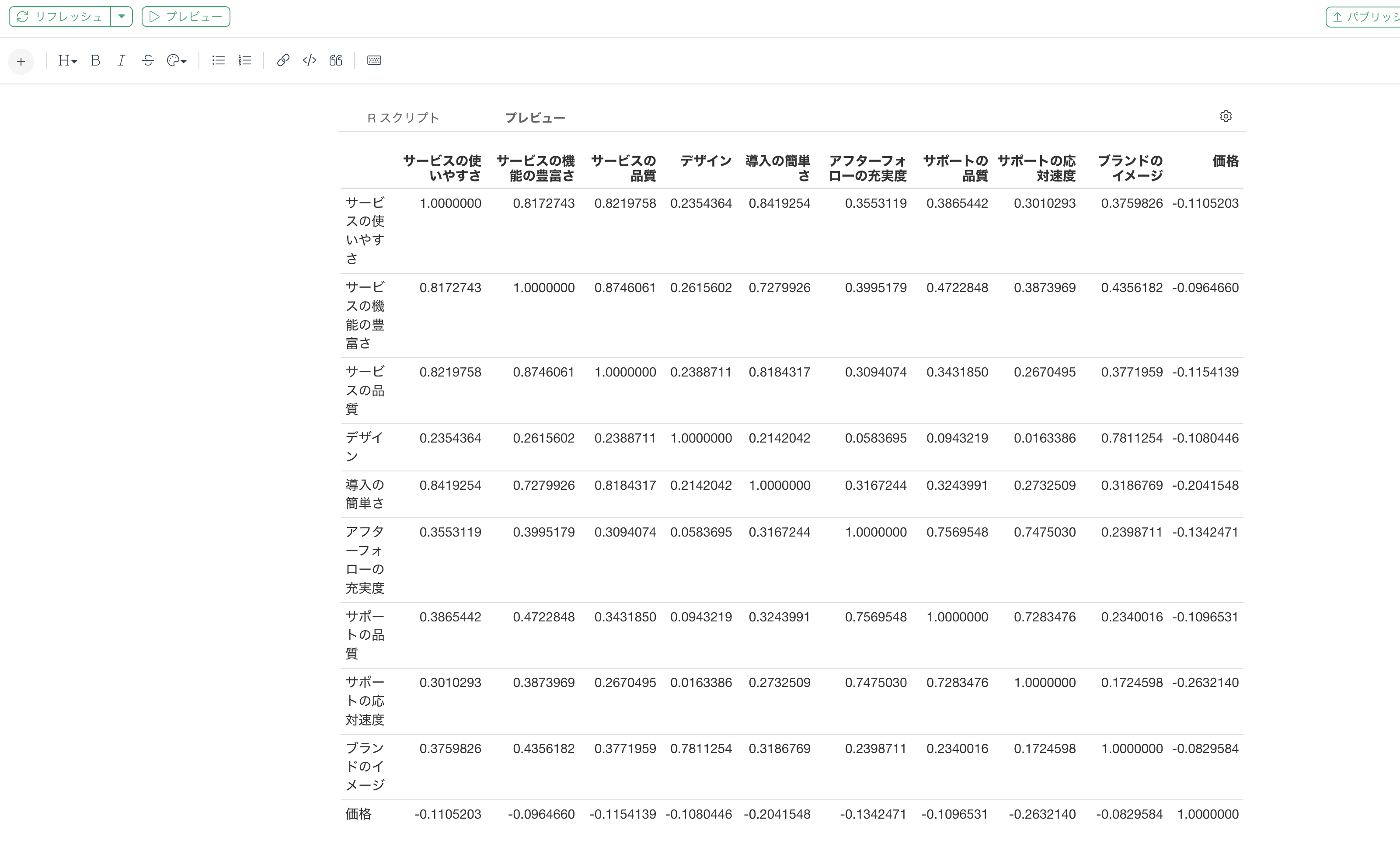
データフレームとして作成する
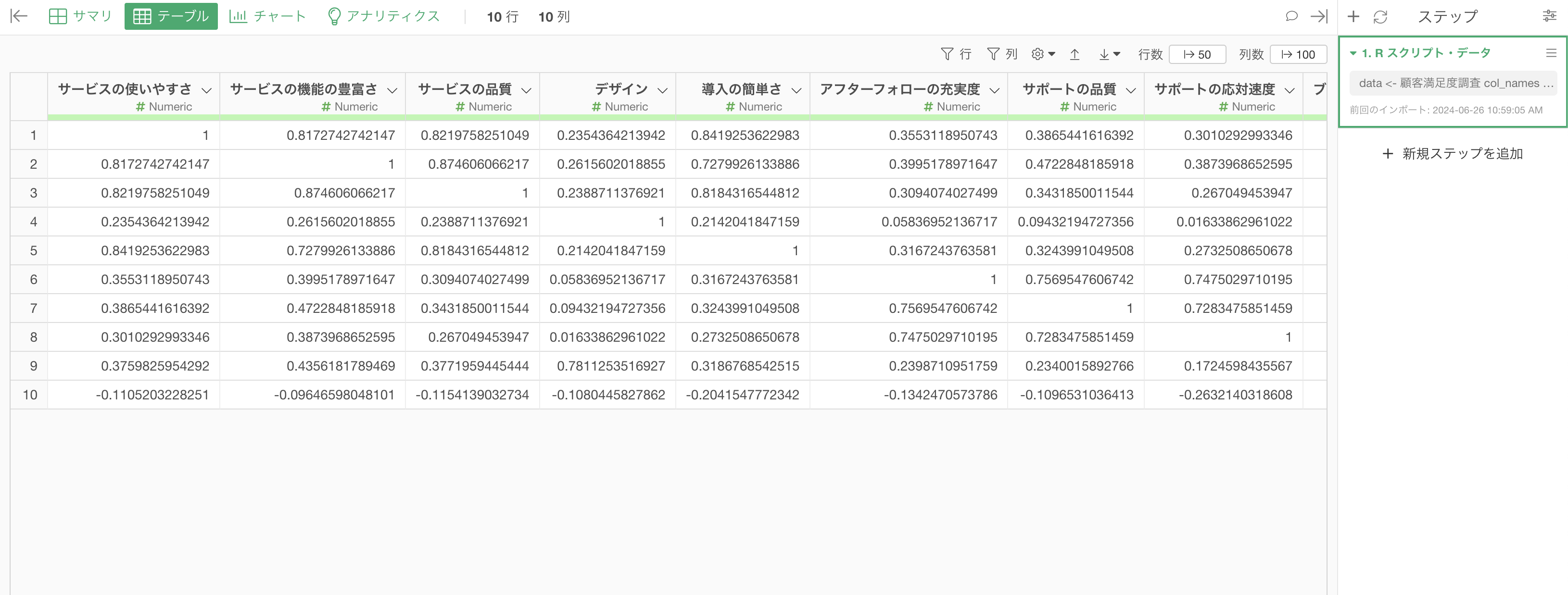
ポリコリック相関係数の相関行列の結果をデータフレームとして作成したいとします。
先ほどと同じく、5段階評価のアンケートの回答を持つ数値列があるデータフレームを使用します。
データフレームのプラスボタンから「Rスクリプト」を選択します。
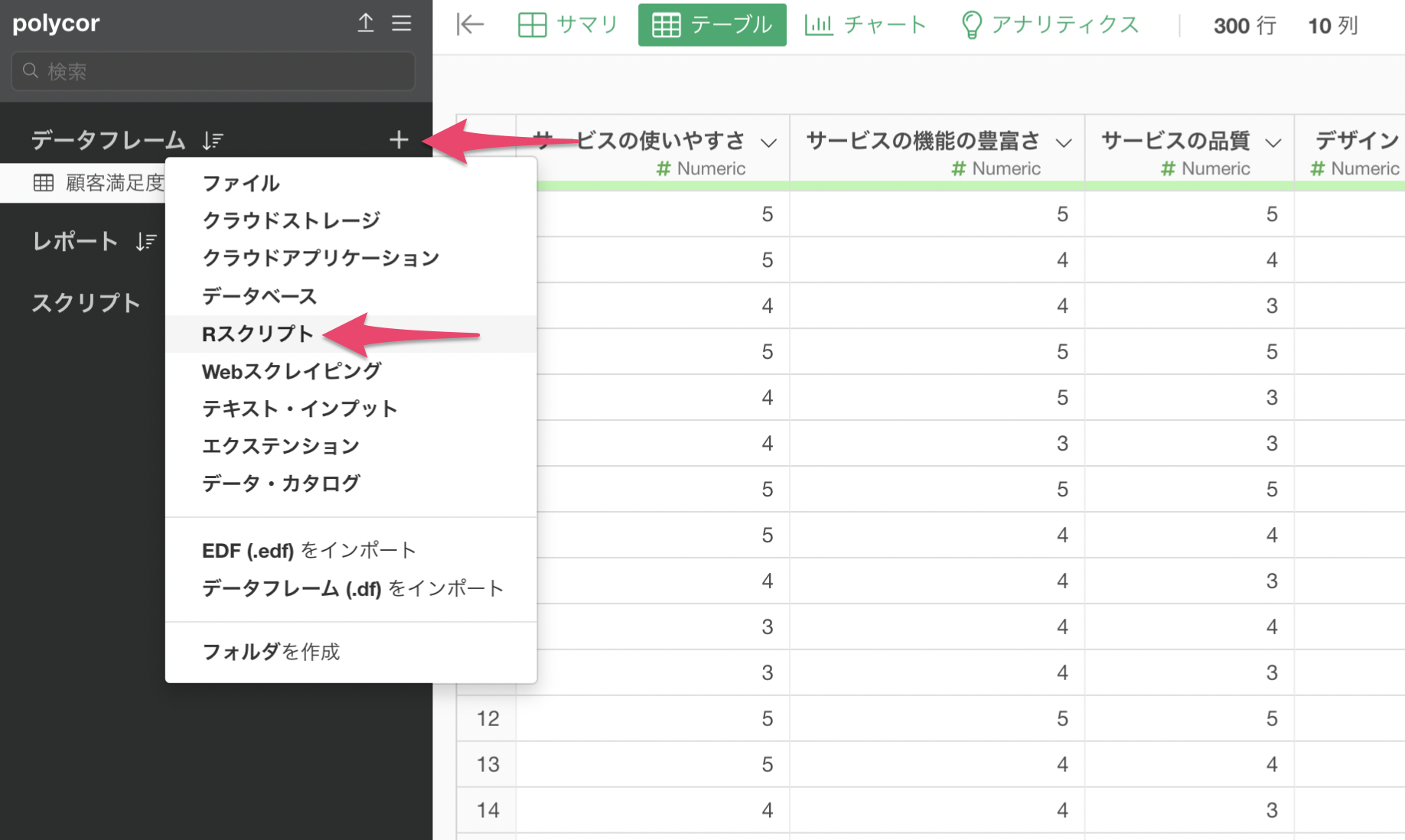
Rスクリプトには以下のように指定します。2行目の「データフレーム名を指定」を変更してください。
# データフレーム名を指定
data <- データフレーム名を指定
# データフレームから列名を取得
col_names <- names(data)
# ポリコリック相関係数を計算
cor_matrix <- psych::polychoric(data[, col_names])
# 結果をデータフレームに変換して表示
data.frame(cor_matrix$rho)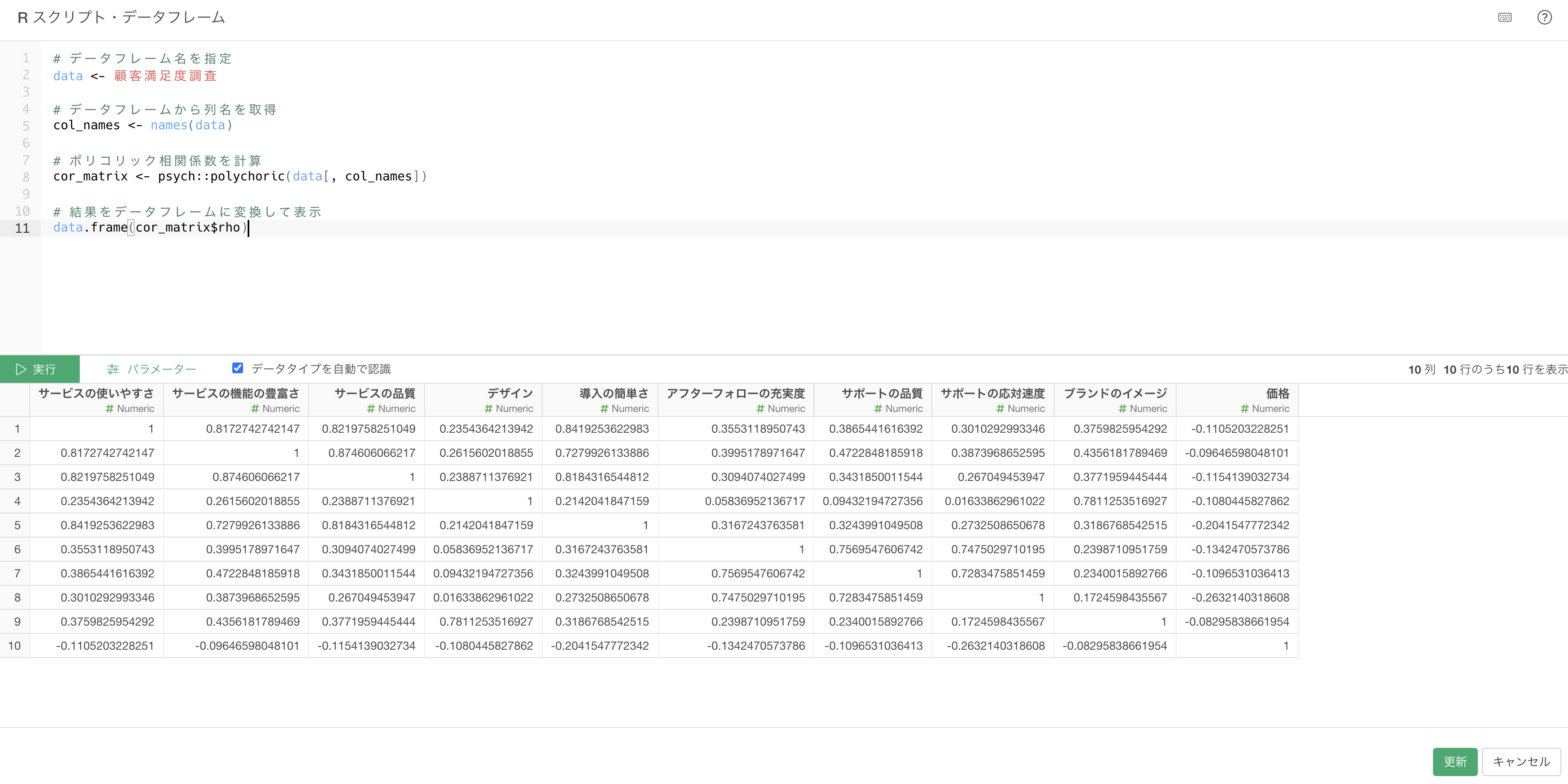 インポートを行うと、ポリコリック相関係数の相関行列をデータとして作ることができています。
インポートを行うと、ポリコリック相関係数の相関行列をデータとして作ることができています。