テキスト分析 - トピックモデル(単語化済み)の紹介
このノートでは、テキスト分析 - トピックモデル(単語化済み)についてご紹介します。
アンケートでは、5段階評価などではわからない回答者が持っている具体的な考えを引き出すために、自由記述の質問を設定することはよくやることの一つです。
しかし、自由記述のテキストのように定性データの解釈は人によって異なるため、全体的な特徴や傾向を客観的に捉えにくいために、うまく活用しきれないという声をよく耳にします。
今回紹介するトピックモデルを使うことで、文章の中で似たような単語が使われている傾向からいくつかのグループ(トピック)に分け、どういったトピックがあるのかを把握することができるようになります。
トピックモデルでは、それぞれの文章で使われている単語を元にして、それぞれの文章でのトピックごとの確率を出します。トピックの確率が高い単語や文章を見ることで、そのトピックは政治である、スポーツであるといった形で判断していくことができます。

そのため、上記のトピックモデルを使うときには一般的に1行が1観察対象(例:1行が回答者)となっている下記のようなデータを利用しますが、

以下のように手元にあるデータが、既に文章を単語に分けられているものである場合もあります。
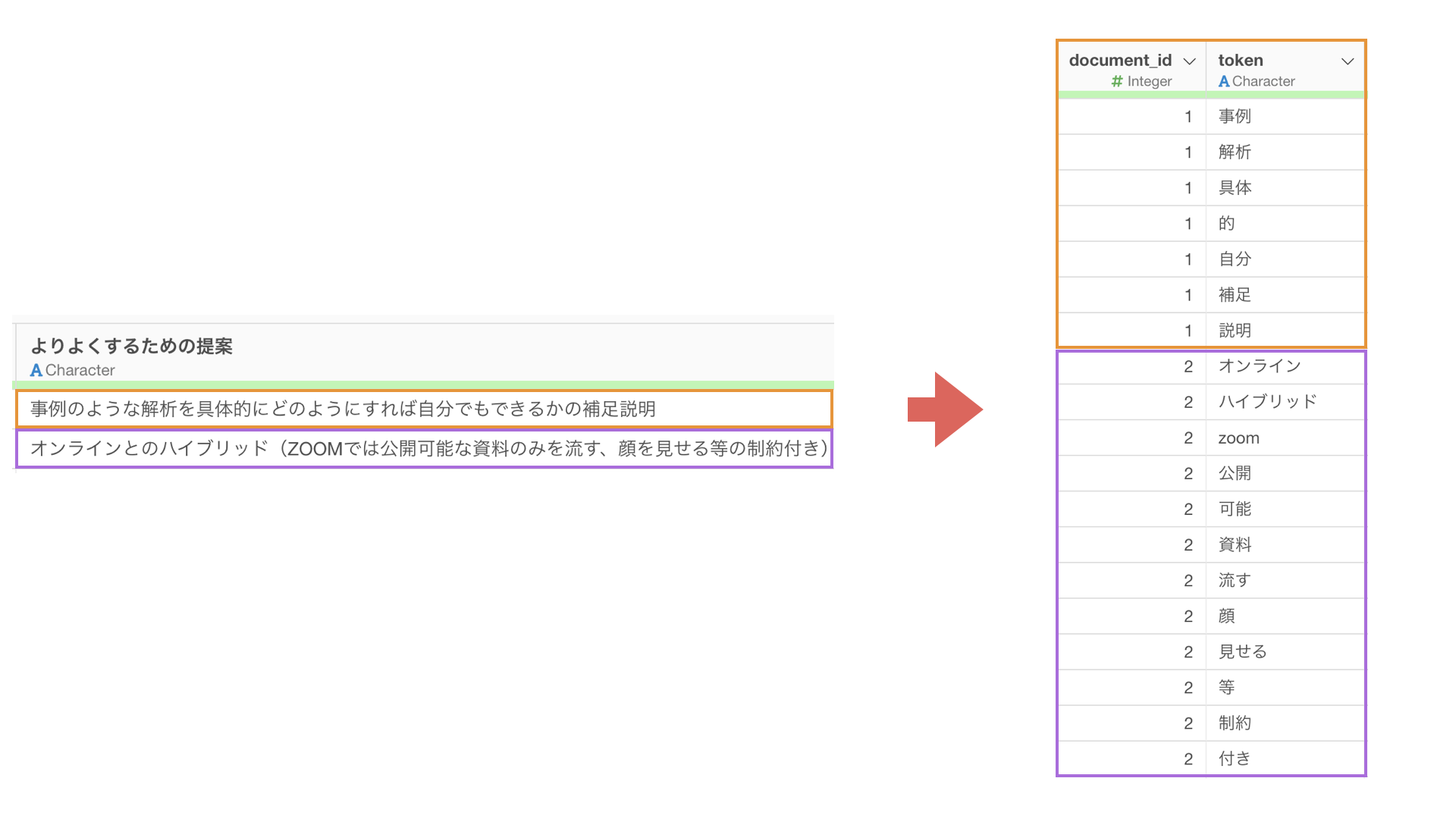
そういったときに使えるのが、こちらで紹介する「テキスト分析 - トピックモデル(単語化済み)」です。
必要なデータ
テキスト分析 - トピックモデル(単語化済み)を実行するためには、単語の列が必要です。さらに、各単語がどの文書(グループ)で使われるいるのかを特定できる列が必要で、1行が1観察対象(例:1行が1つの文書の1単語)となっている必要があります。
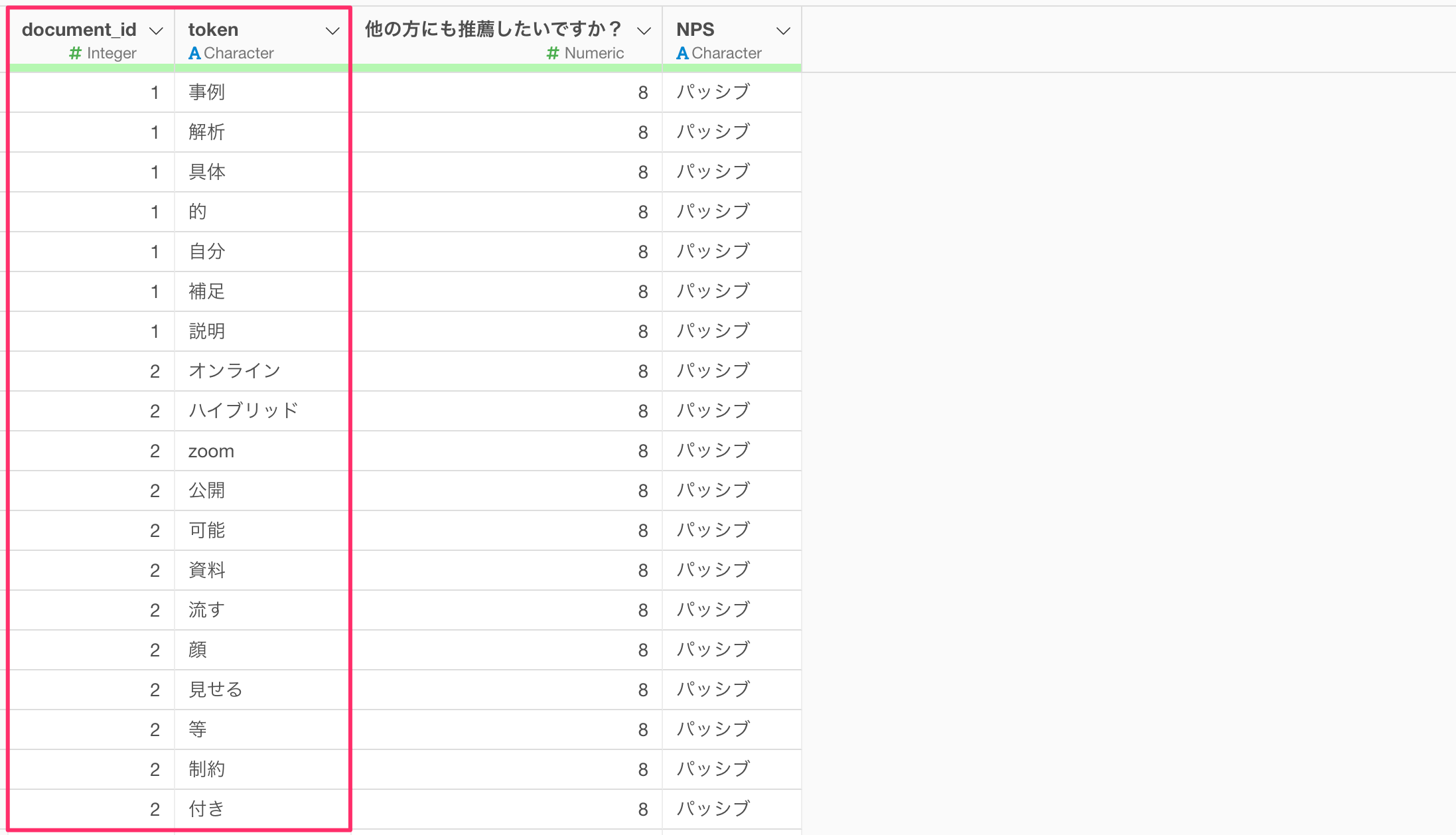
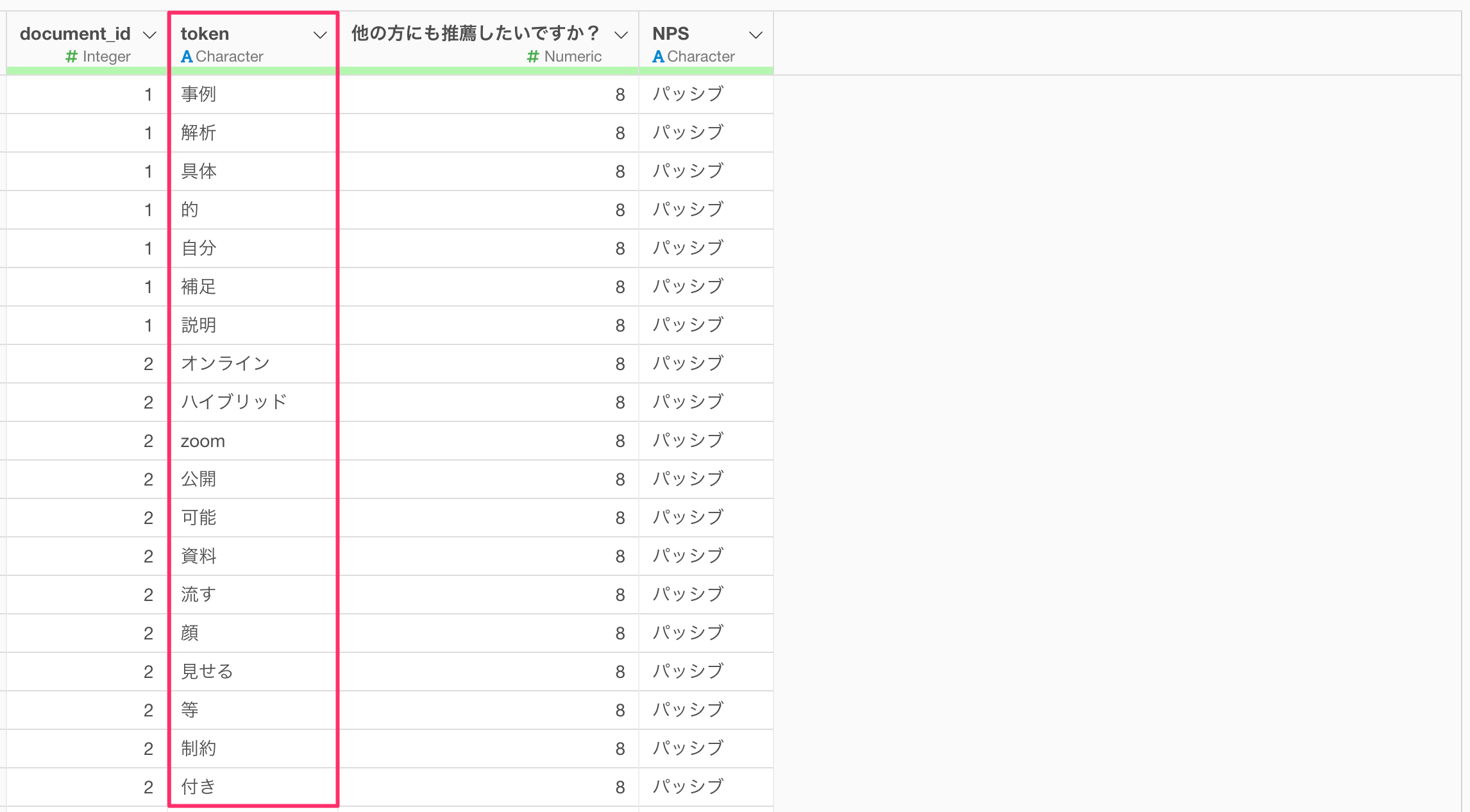
サンプルデータ
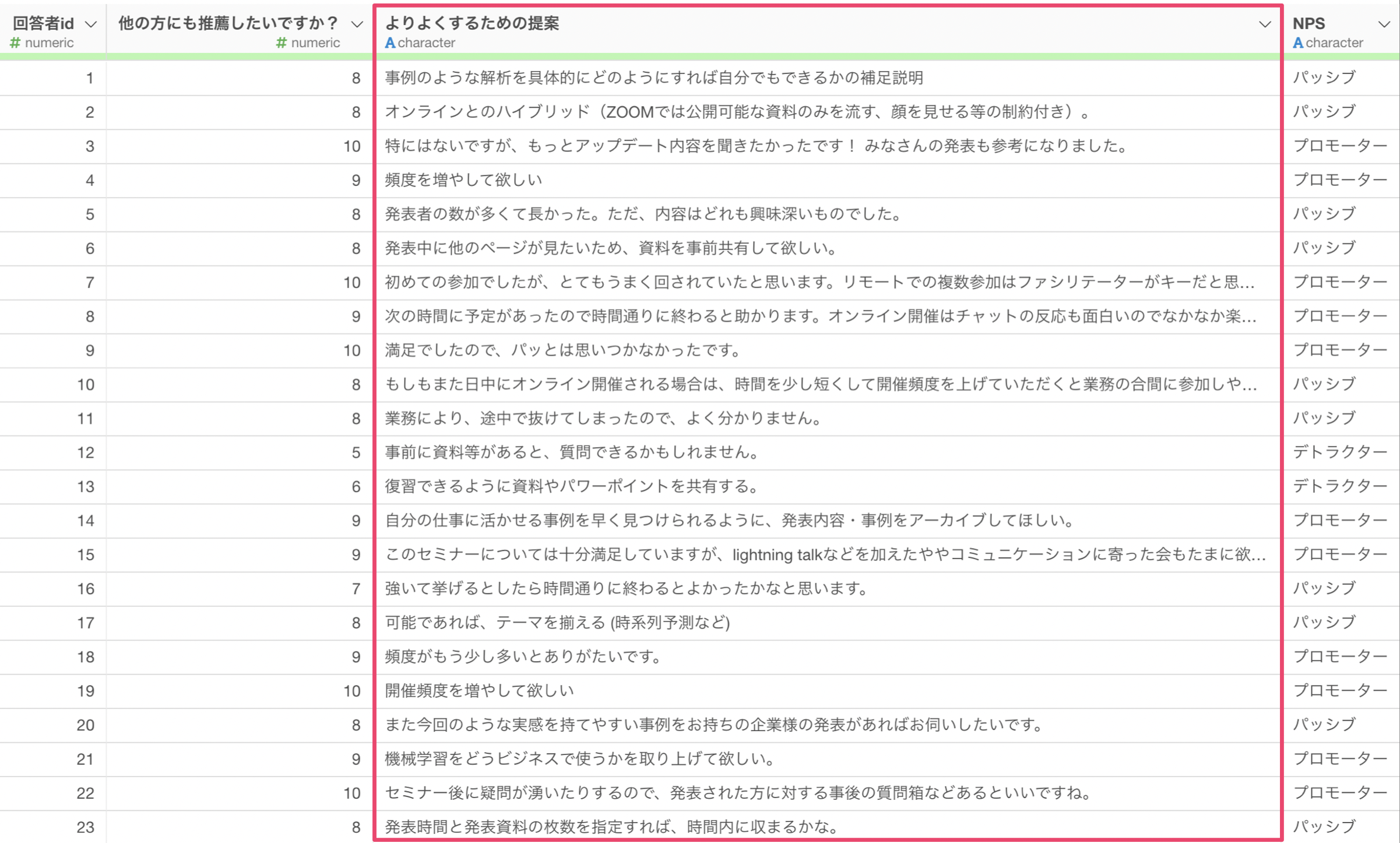
今回はサンプルデータとして、セミナーのアンケートデータ(単語化済)を使用していきます。このデータは1行が1つの文書の1単語のデータで、列にはセミナーをよりよくするための提案という質問への回答を単語化した「token」の列があります。
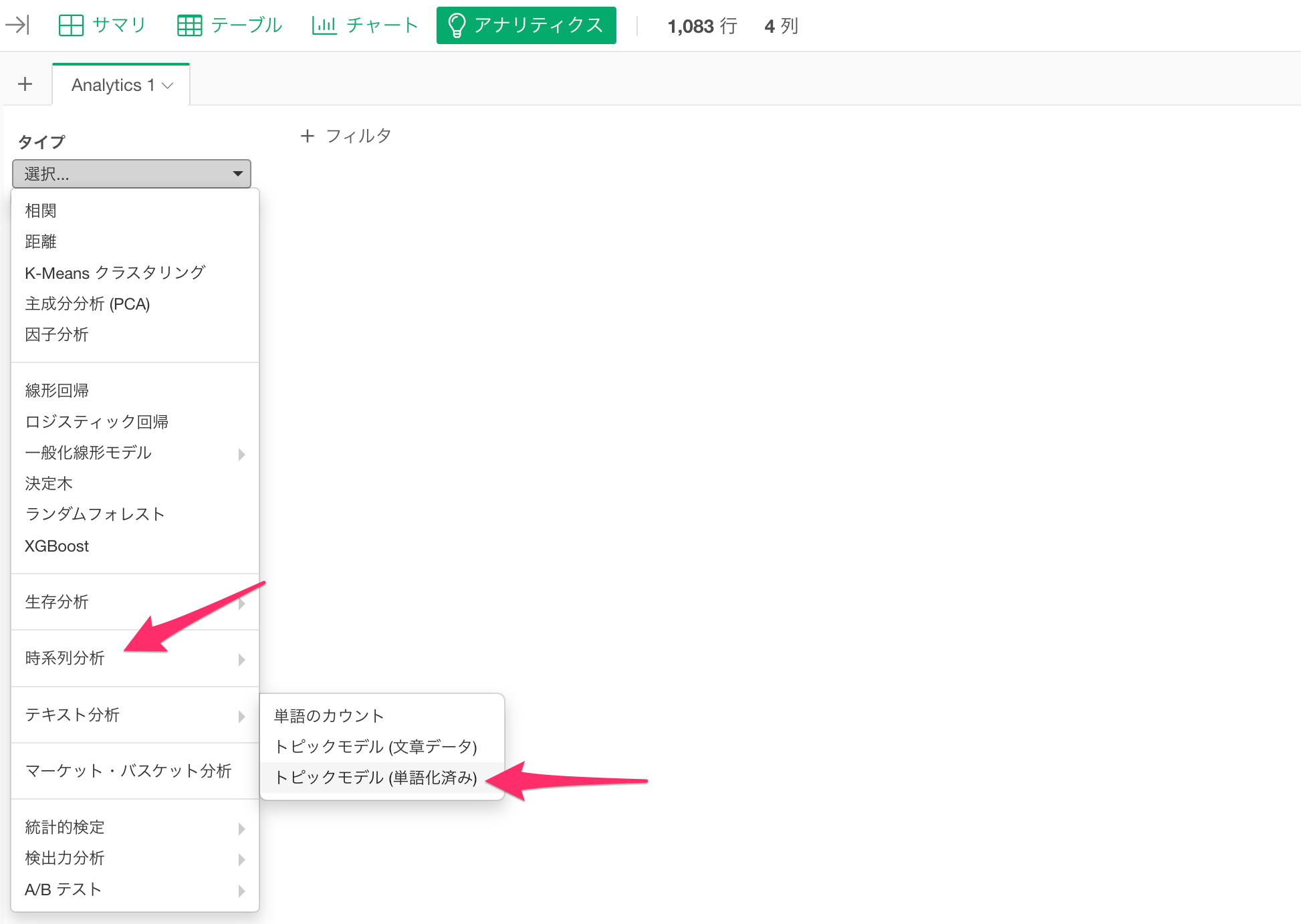
テキスト分析 - トピックモデル(単語化済み)を実行する
アナリティクスビューを選び、タイプに「テキスト分析」の「トピックモデル(単語化済み)」を選択します。
単語に「token」、グループに「document_id」を選択します。
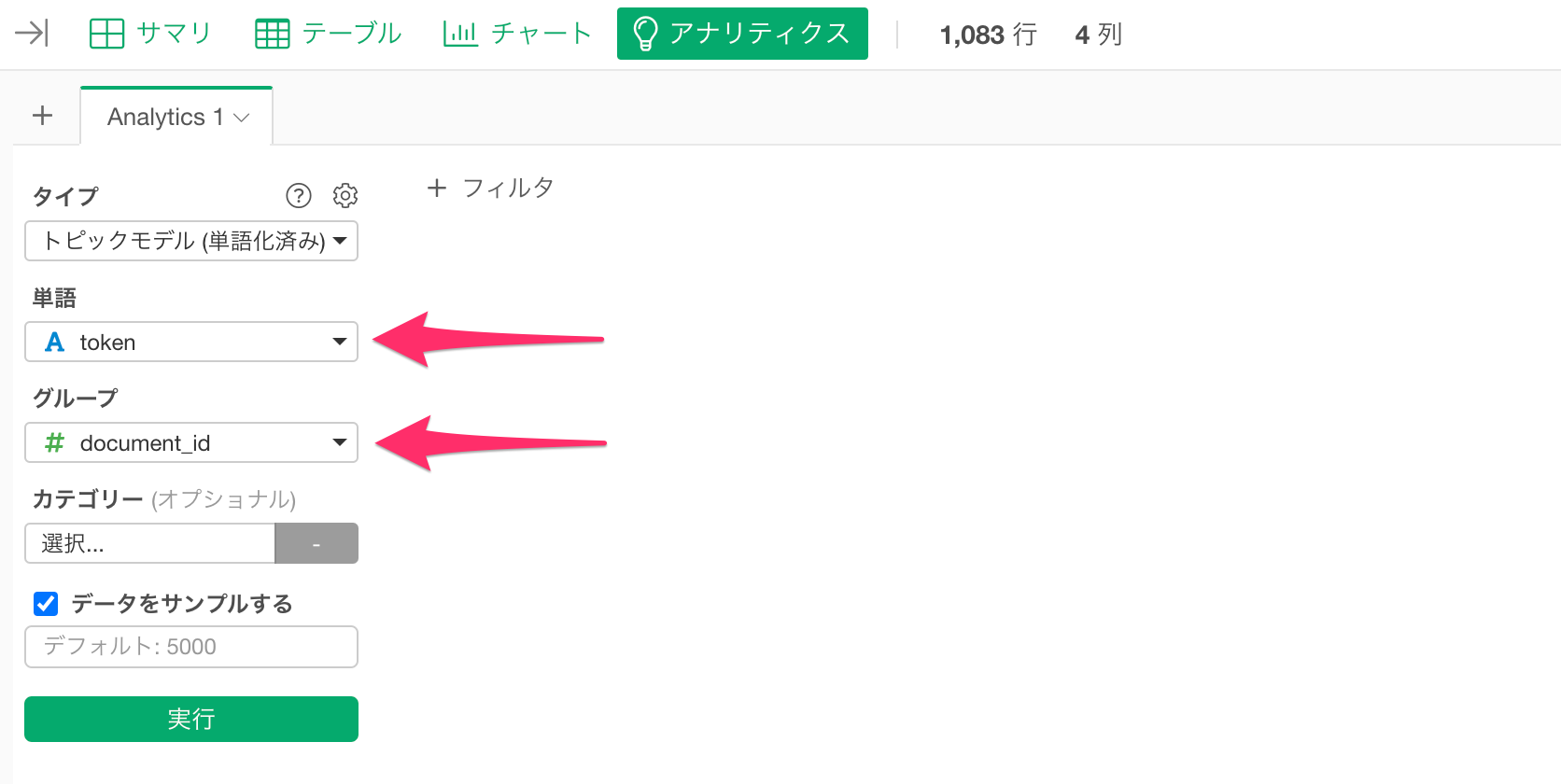
もしデータが「5000行」以上の場合、全てのデータを使いたい場合は「データをサンプルする」のチェックを外してください。しかし、データの行数によっては実行までに時間がかかってしまうために、デフォルトでは「5000行」でサンプルされていることになります。
設定ができたら、「実行」ボタンをクリックします。
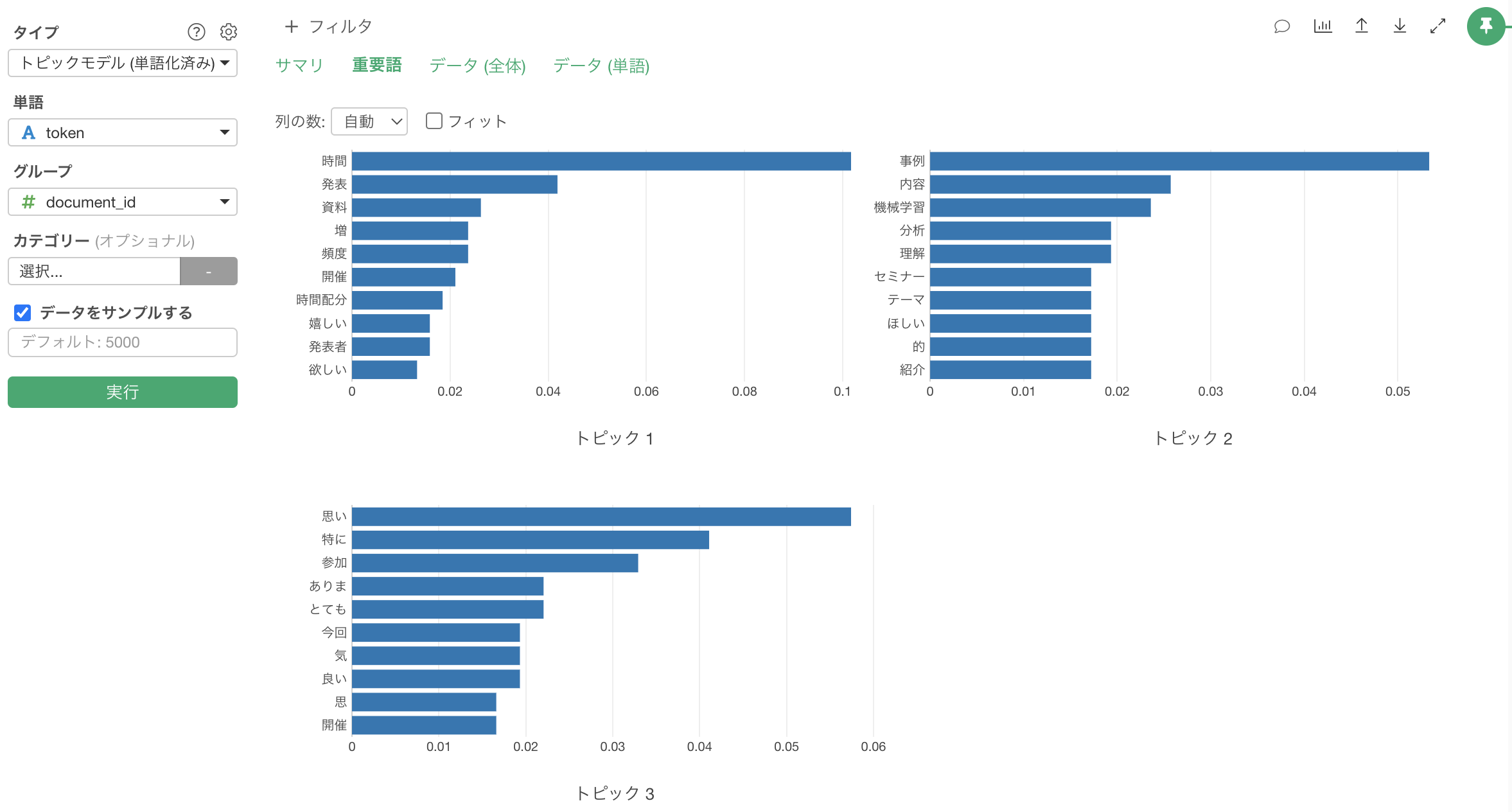
テキスト分析の「トピックモデル」が実行されました。
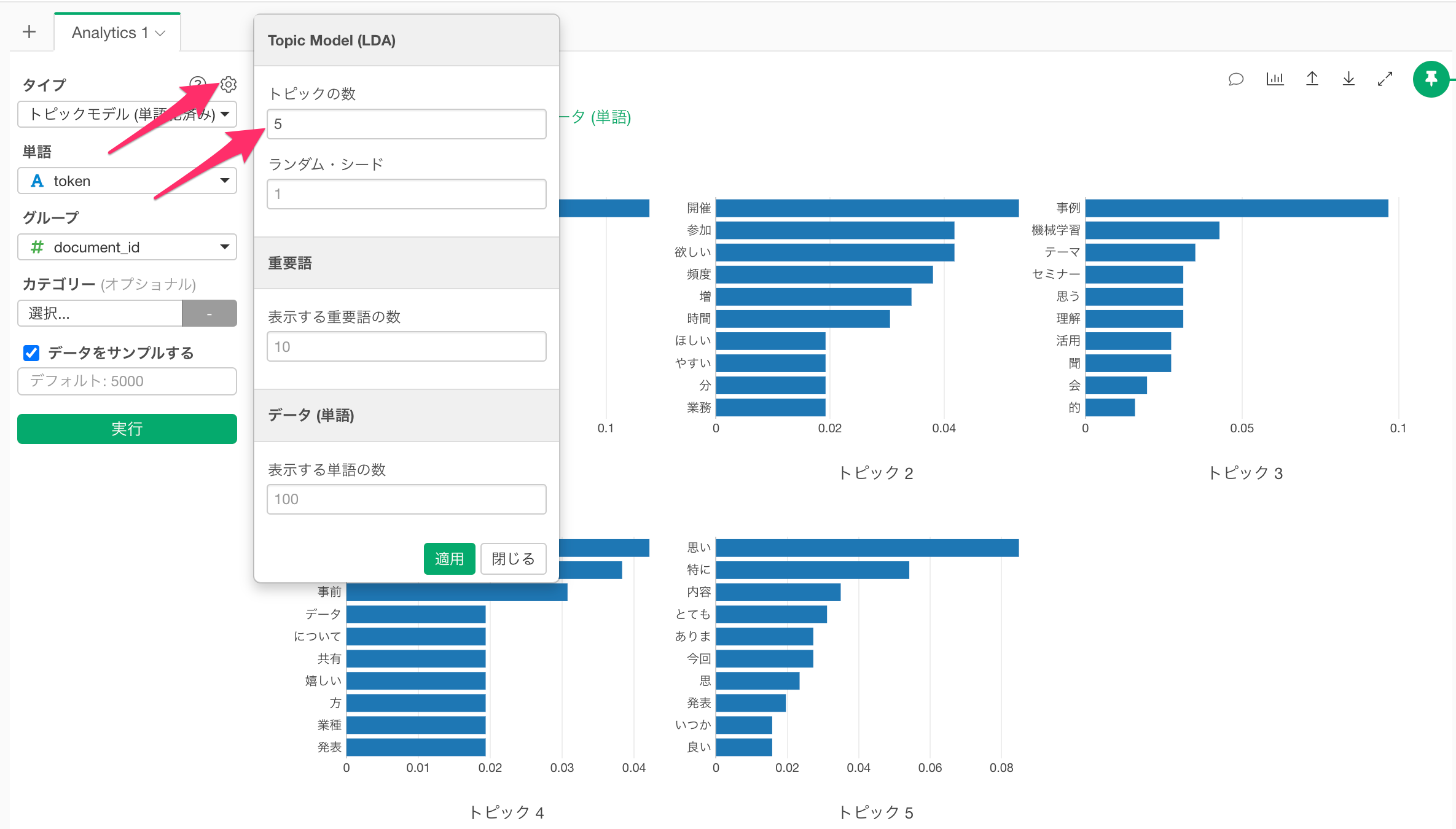
トピックの数を増やしたい場合は、プロパティから変更することができます。
結果の解釈
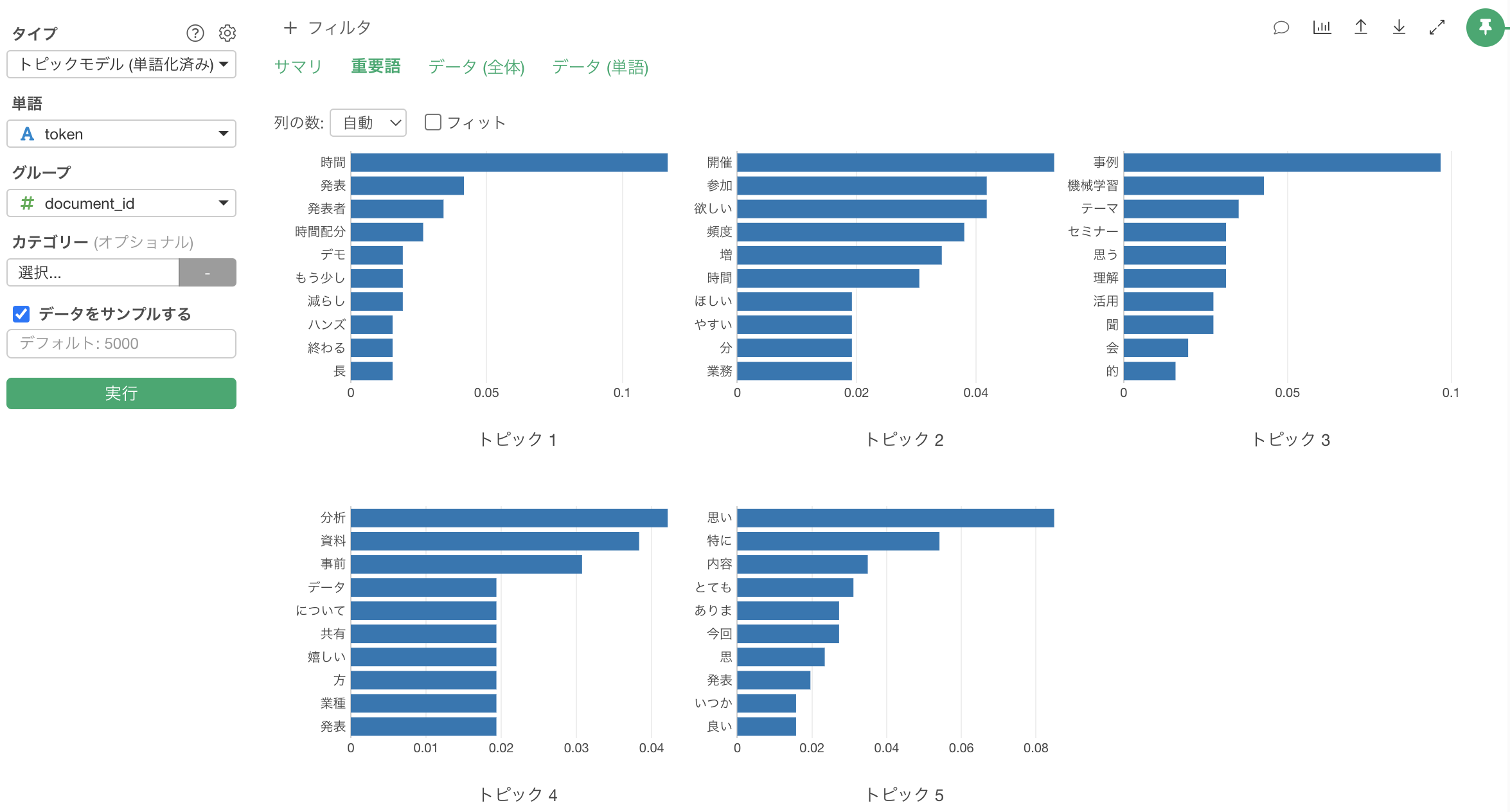
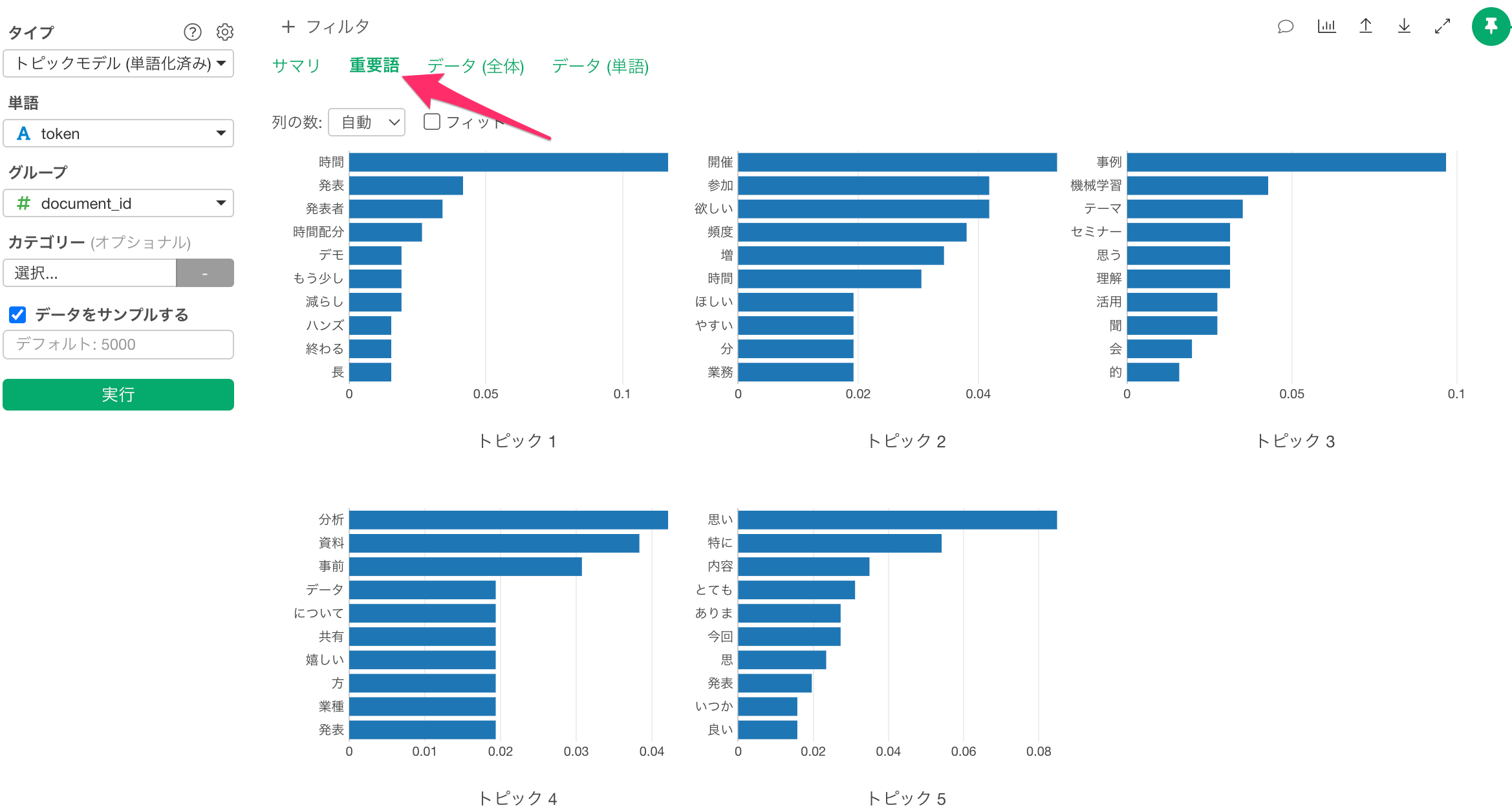
重用語
「重要語」のタブでは、それぞれのトピックごとで、そのトピックの確率が高い重要となる単語がバーチャートとして表示されます。
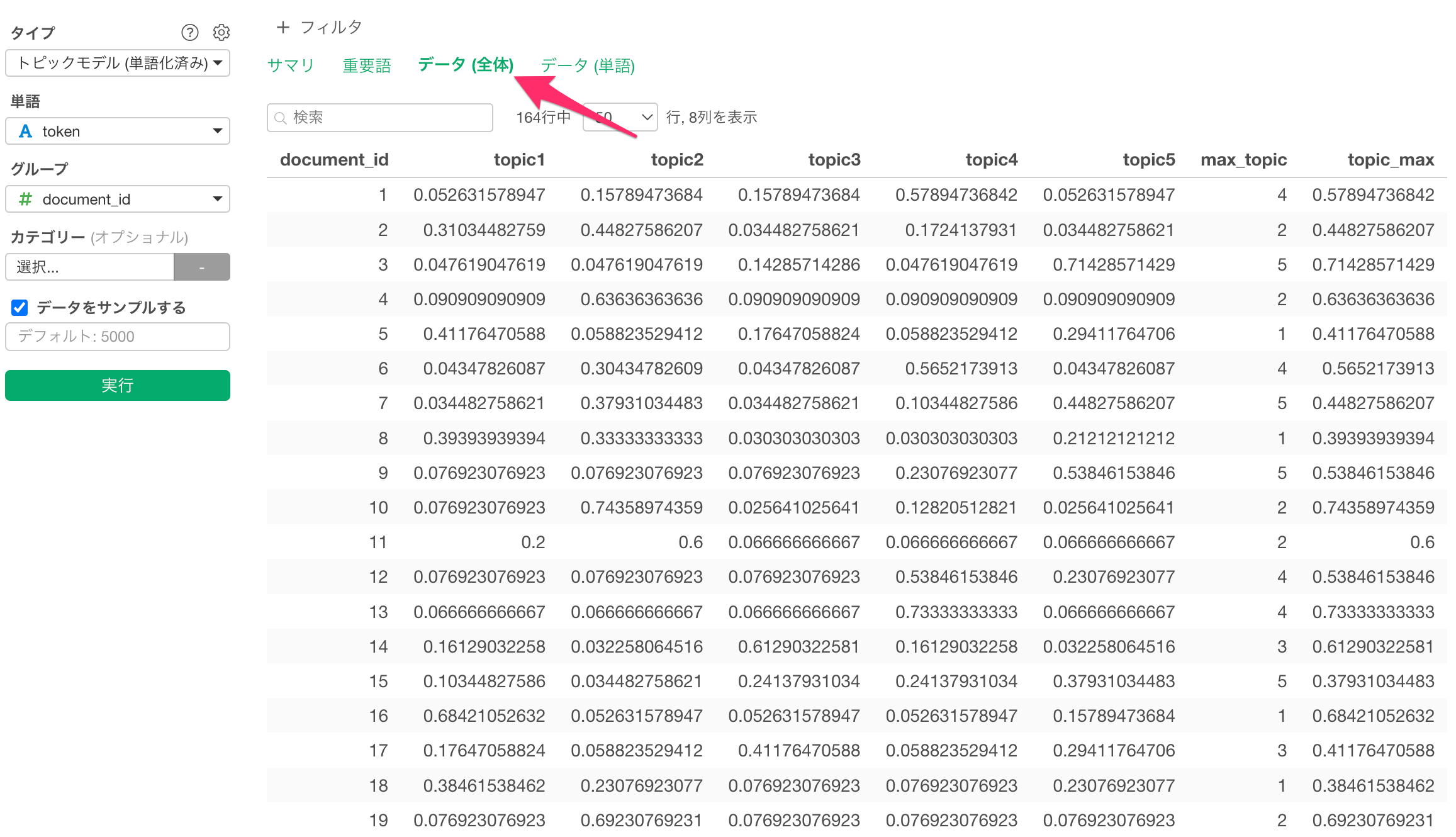
データ(全体)
「データ全体」のタブでは、元のデータでの文章ごとのトピックの確率をテーブル形式で確認できます。また、それぞれの文章の中で最も確率が高かったトピックをmax_topicとなっています。
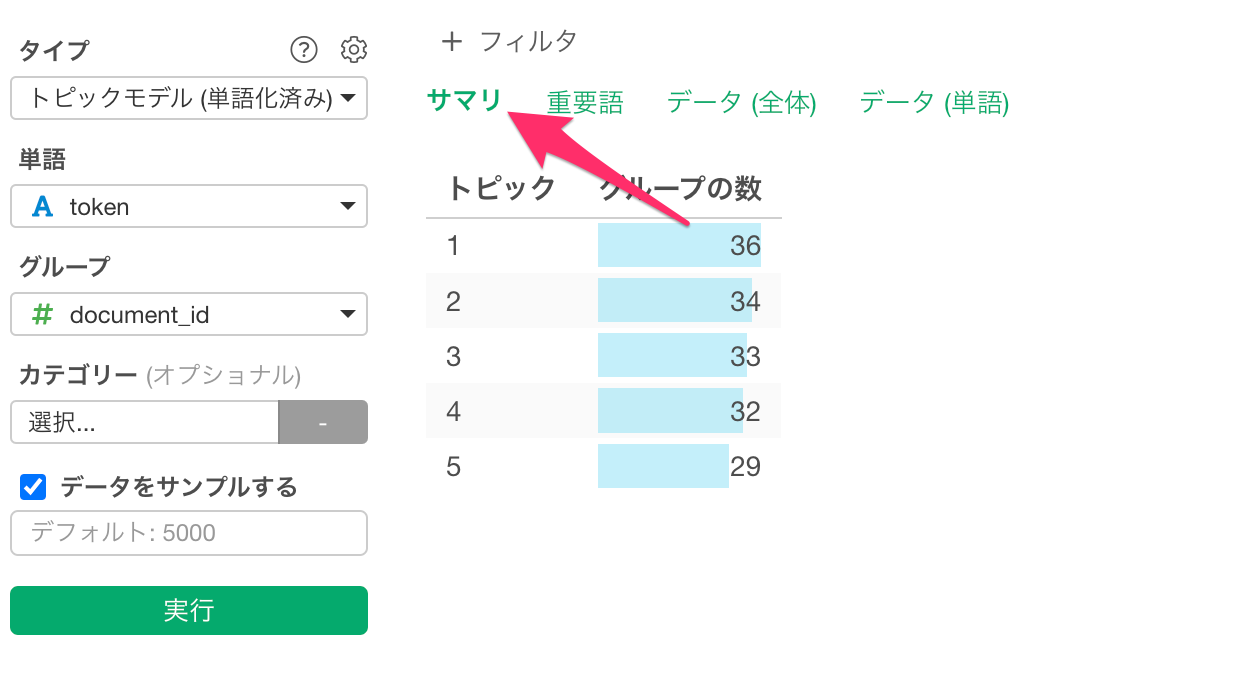
サマリ
「サマリ」タブでは、それぞれのトピックごとにどれだけの行数があるのかを確認できます。文章ごとのトピックの選定は、文章の中で最も確率が高かったトピックであるmax_topicをもとにしています。
トピックごとのカテゴリーの関係の可視化
データの中に性別や年代などのカテゴリーの列がある場合、それぞれの単語でカテゴリーの比率を見ていくことができます。
例えば、今回のデータにはNPSといったカテゴリー列があります。
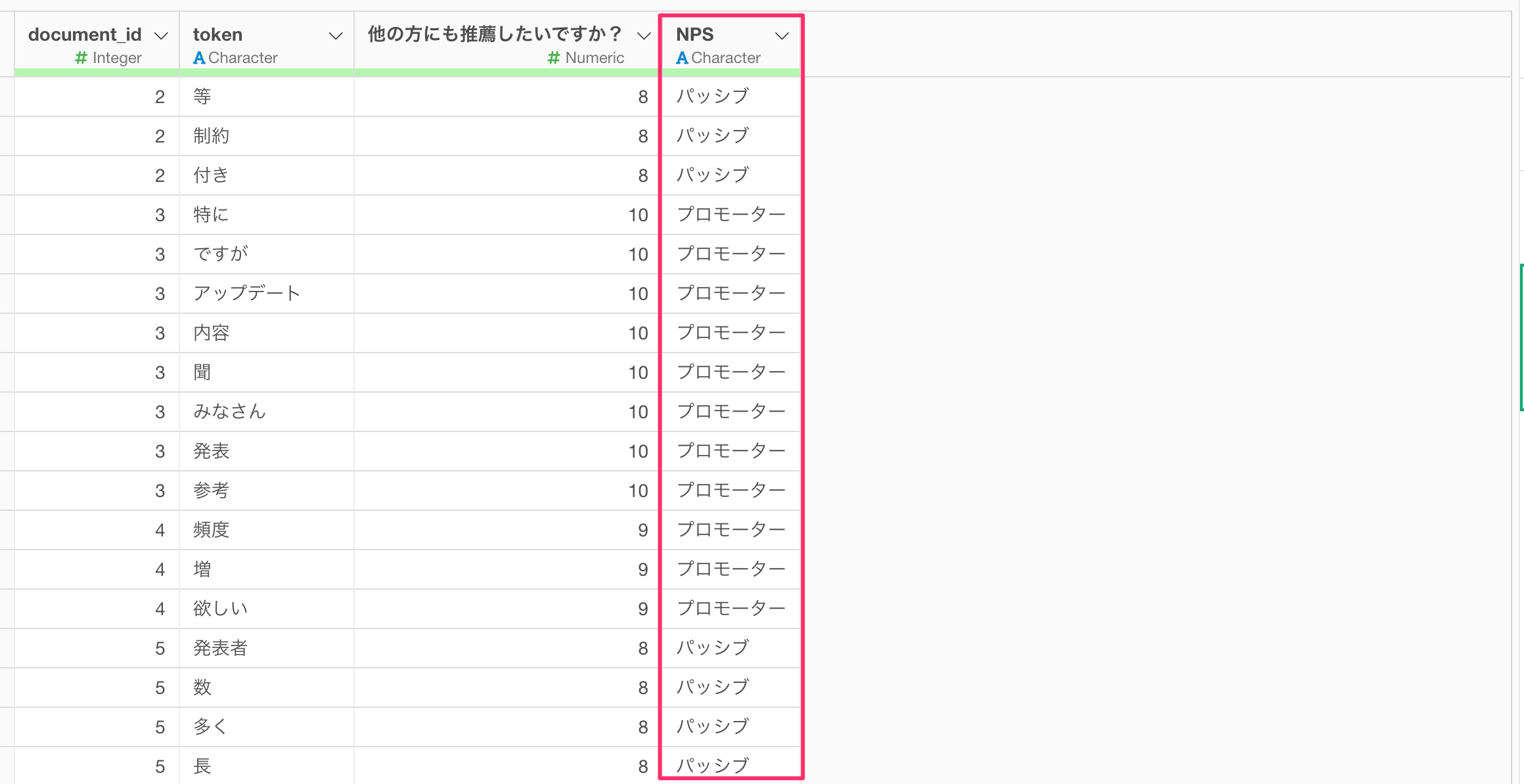
そこで、トピックごとにNPSグループ(カテゴリー)の比率を調べていきたいです。

「カテゴリー」に「NPS」の列を選択して実行します。
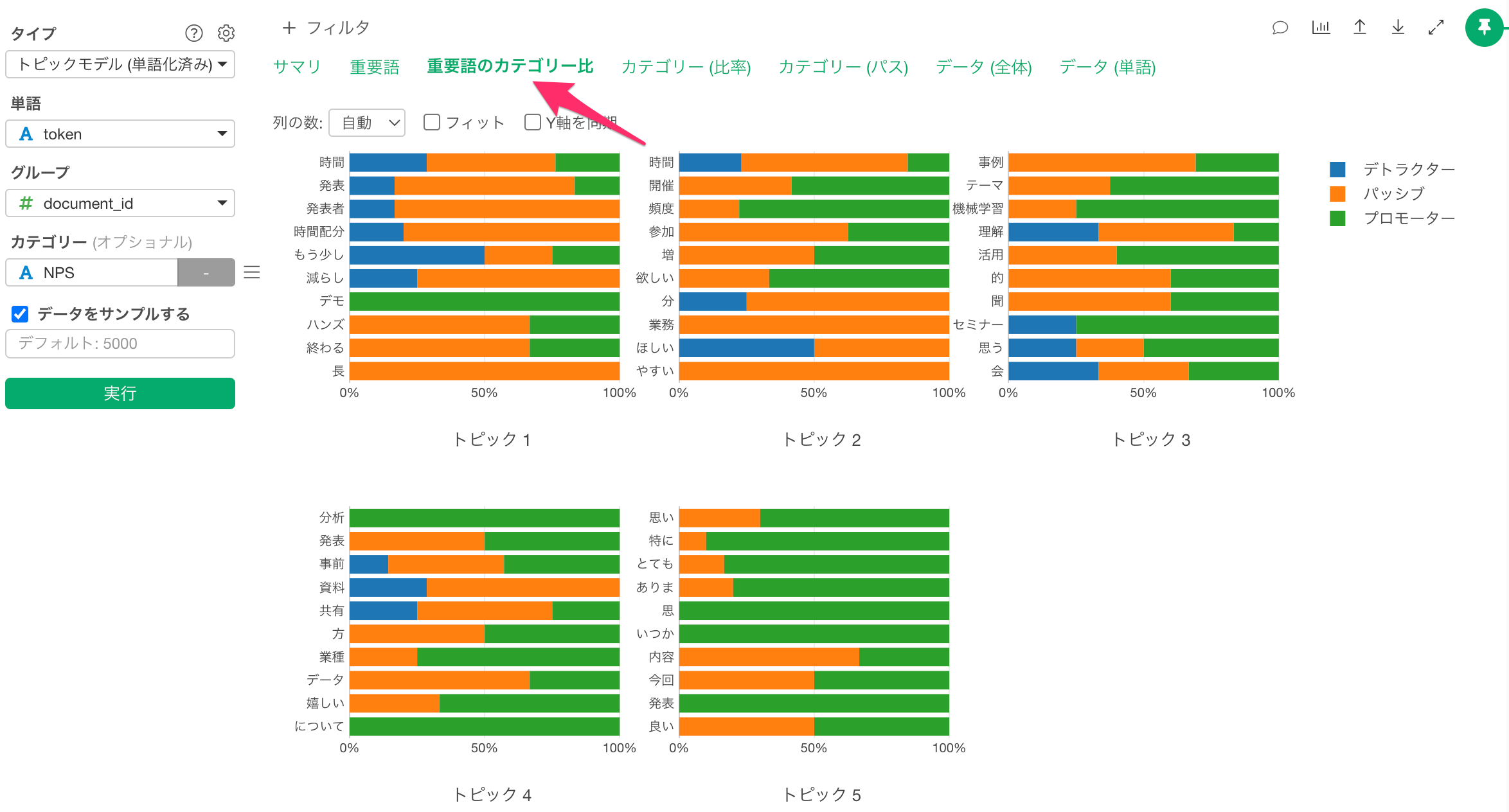
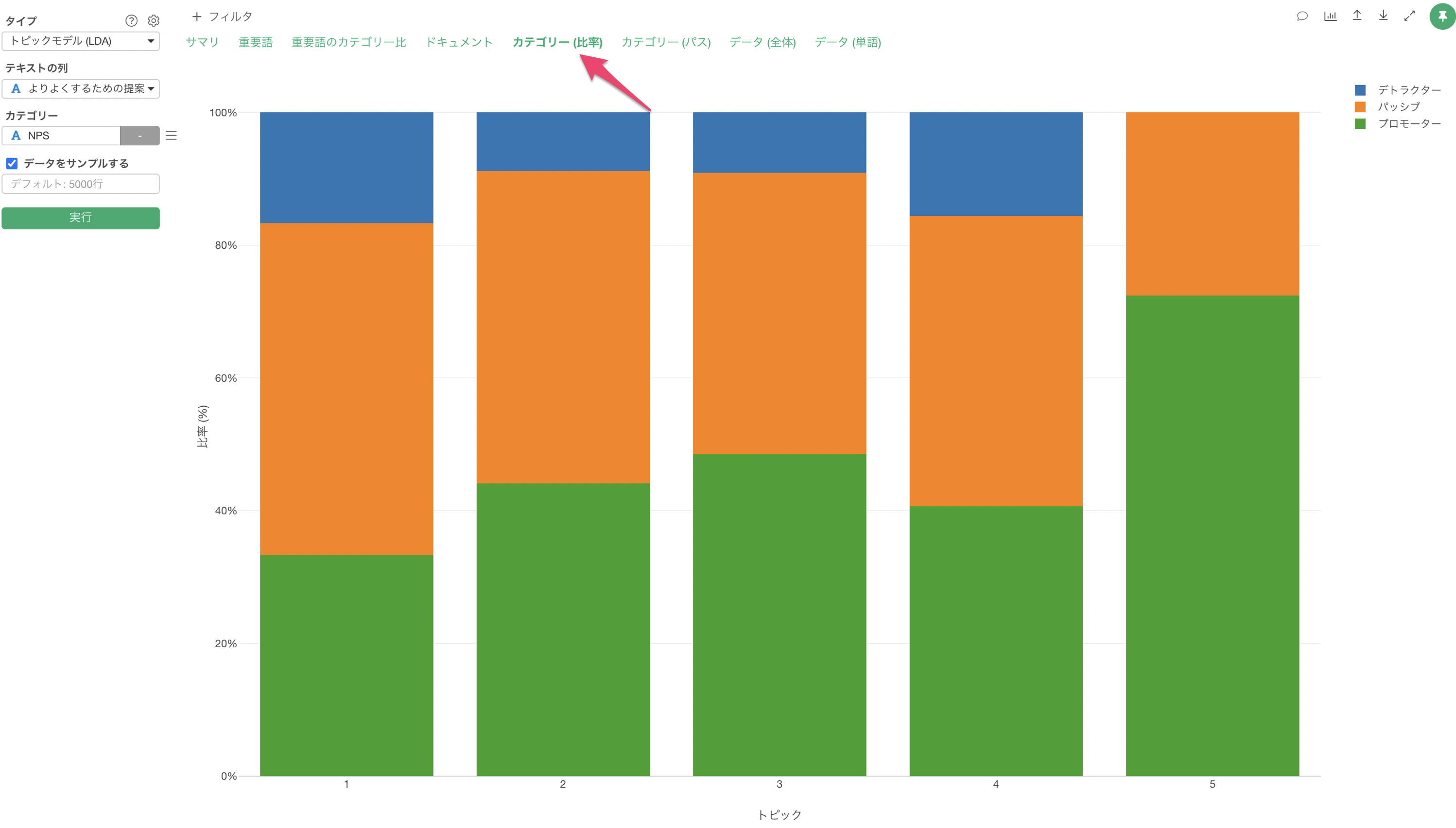
「カテゴリー比率」タブより、それぞれのトピックごとのカテゴリーの比率を確認できます。今回の場合はNPSグループの比率が可視化されています。
「重用語のカテゴリー比」タブからは、トピック別の重用語ごとにカテゴリーの比率を確認できます。