e-StatからAPIを使ってデータを取得する方法
政府統計の総合窓口(e-Stat)で提供している統計データを、Hiroaki Yutani氏が開発されたestatapiパッケージを使って取得する方法をご紹介します。
estatapiを使うことで、e-Statから下記のデータを簡単に取得することができます。
- 統計表情報: 提供されている統計表を検索します。
- メタ情報: 統計データのメタ情報を取得します。
- 統計データ: 統計データを取得します。
- データカタログ情報: 統計表ファイル(Excel、CSV、PDF)および統計データベースの情報を取得します。
今回はその中でも、統計表情報と統計データを取得する方法について紹介していきます。
estatapiの詳しい情報はこちらのドキュメントをご覧ください。
事前準備
e-StatのアプリケーションIDを取得する
e-StatのAPIを利用するには、アプリケーションIDを取得する必要があります。
こちらの手順に従って、アプリケーションIDの取得をしてください。
APIにアクセスする際は、appIdというパラメータに取得したアプリケーションIDを指定します。
Exploratoryにestatapiパッケージをインストールする
プロジェクトのメニューから、「R パッケージの管理」を選ぶと、パッケージをインストールすることができるダイアログが表示されます。
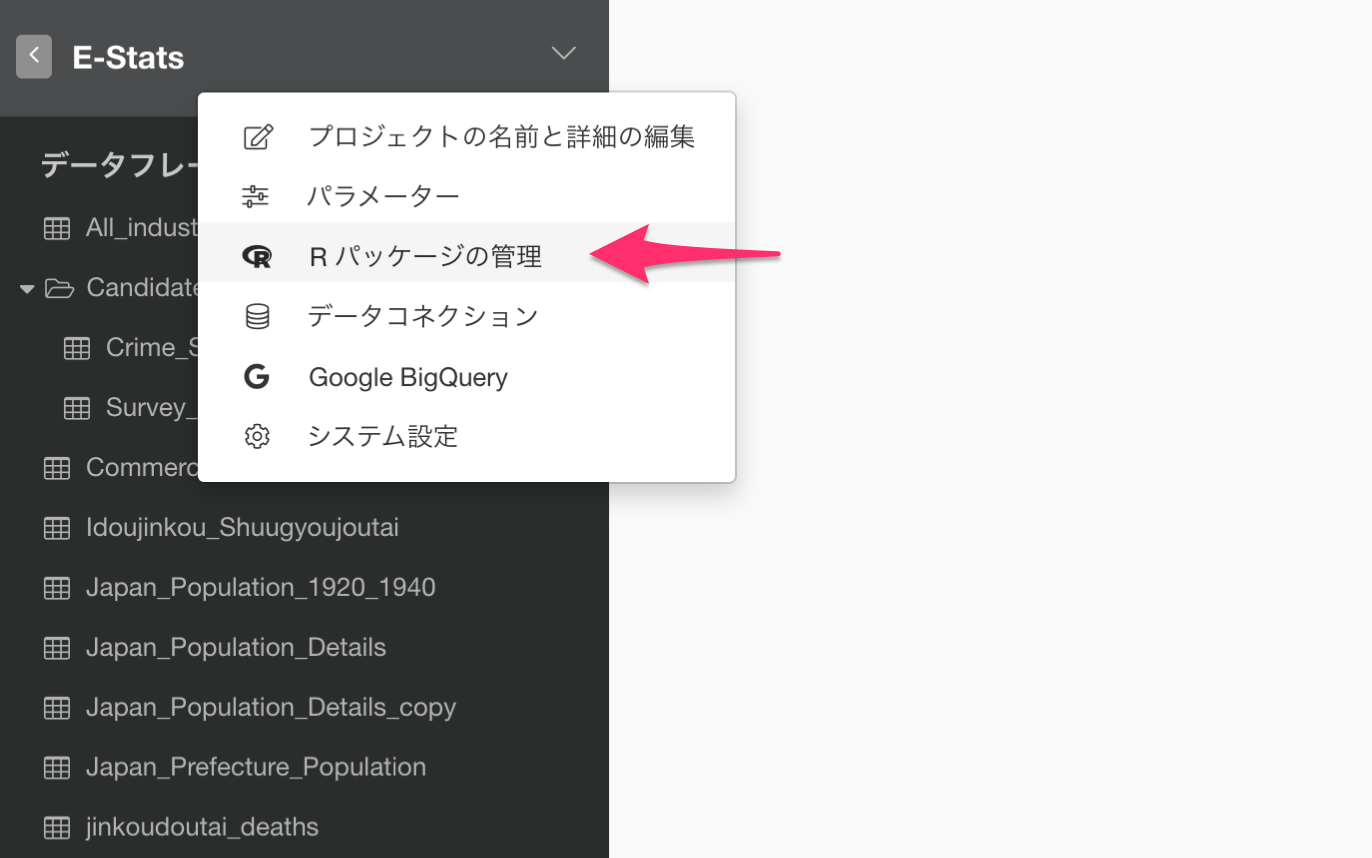
「パッケージをインストール」のタブを選んで、「estatapi」とタイプして、「インストール」ボタンを押します。
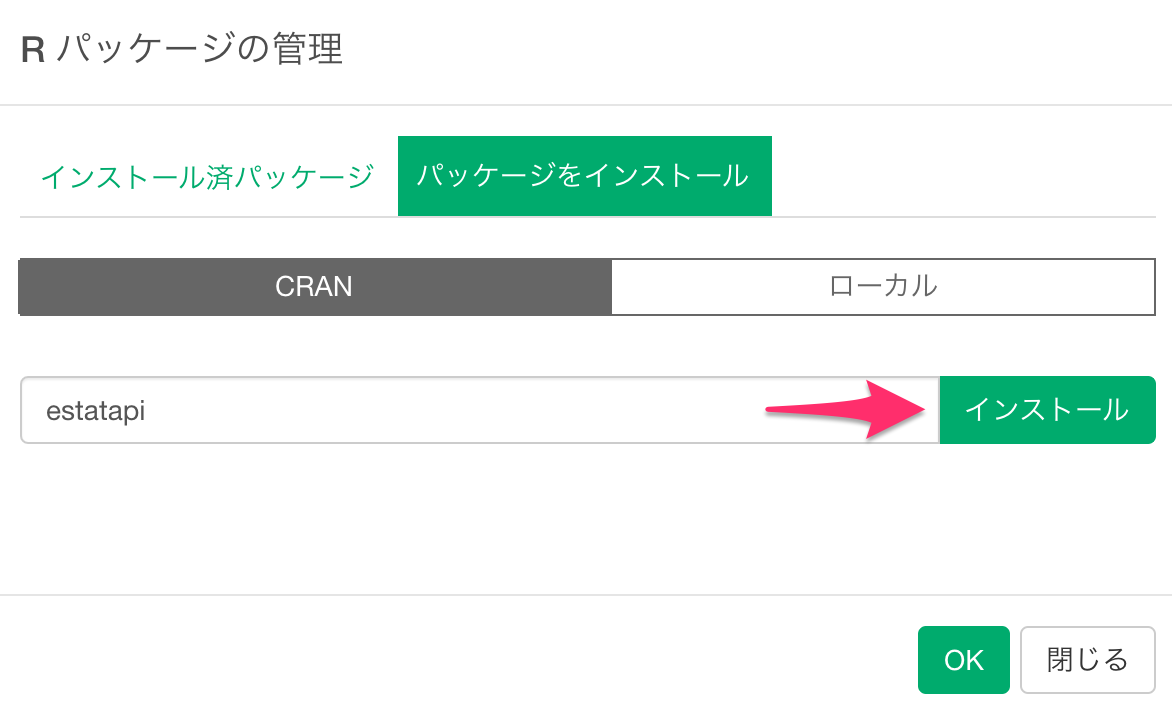
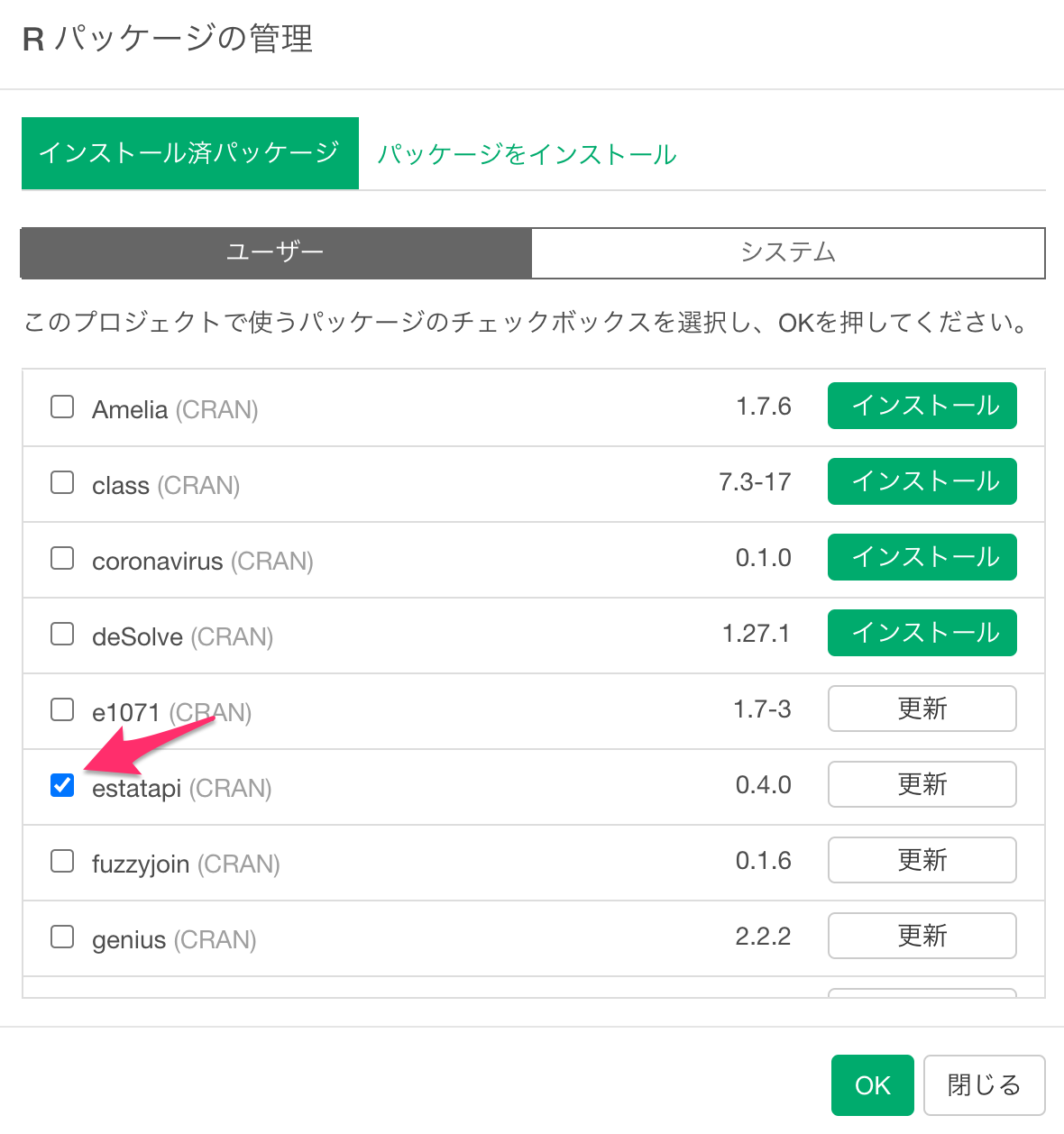
インストールが終わると、「estatapi」が「インストール済みのパッケージ」のリストに入っており、さらにチェックされています。ここでチェックされていると、そのパッケージの関数をそのまま使うことができます。
統計表情報を取得する
まずは自分が興味のあるキーワードからどういった統計表があるのかを取得します。
estatapiを使ってデータを取得するために、データフレームのプラスボタンから「Rスクリプト」を選択します。
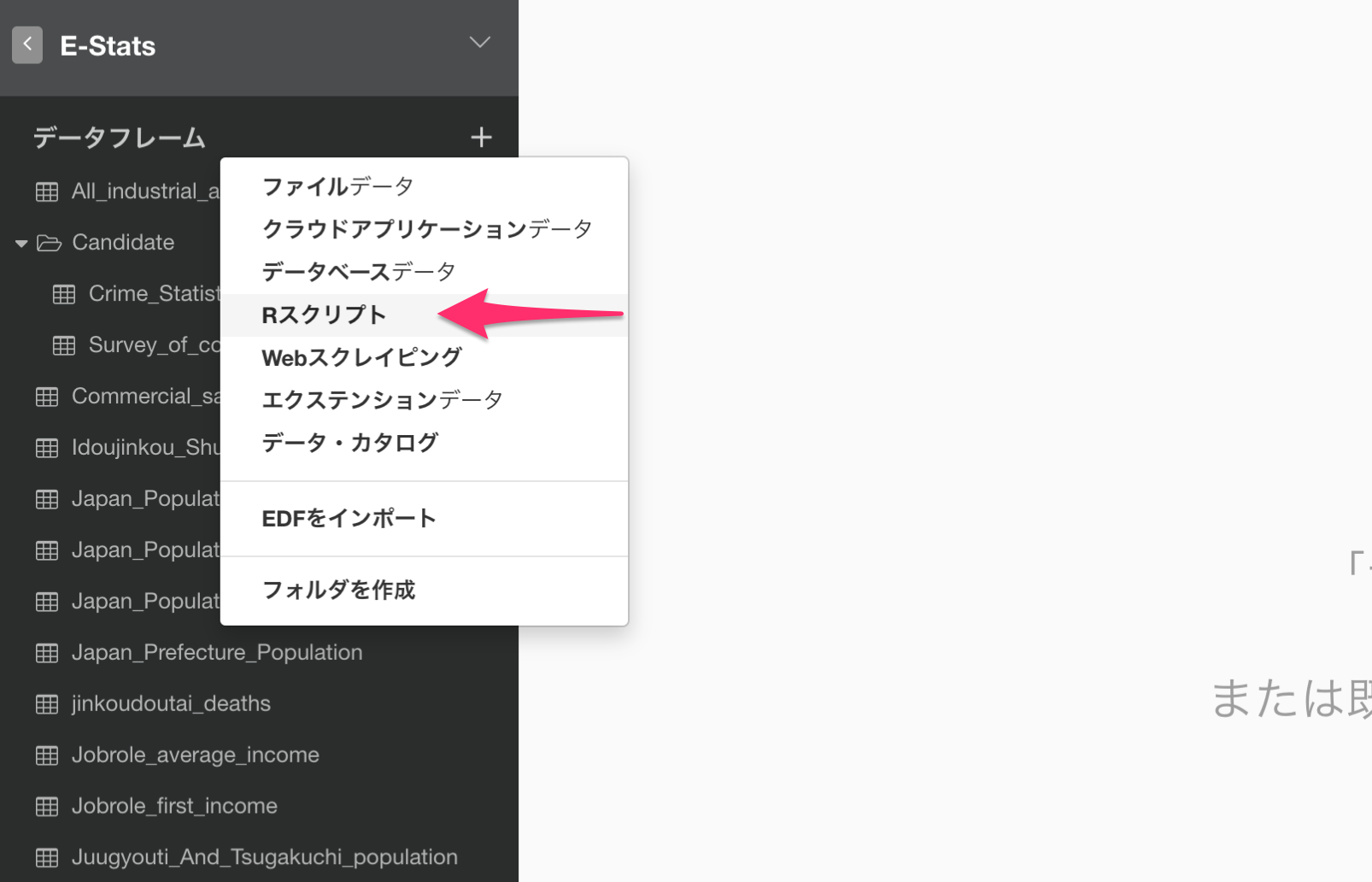
Rスクリプト・データフレームのダイアログが表示されるので、下記のスクリプトを入力して実行します。検索キーワードには自分の興味があるキーワードを入力してください。
estat_getStatsList(appId = <アプリケーションID>, searchWord = <検索キーワード>)実行すると、関連した統計表が表示されます。
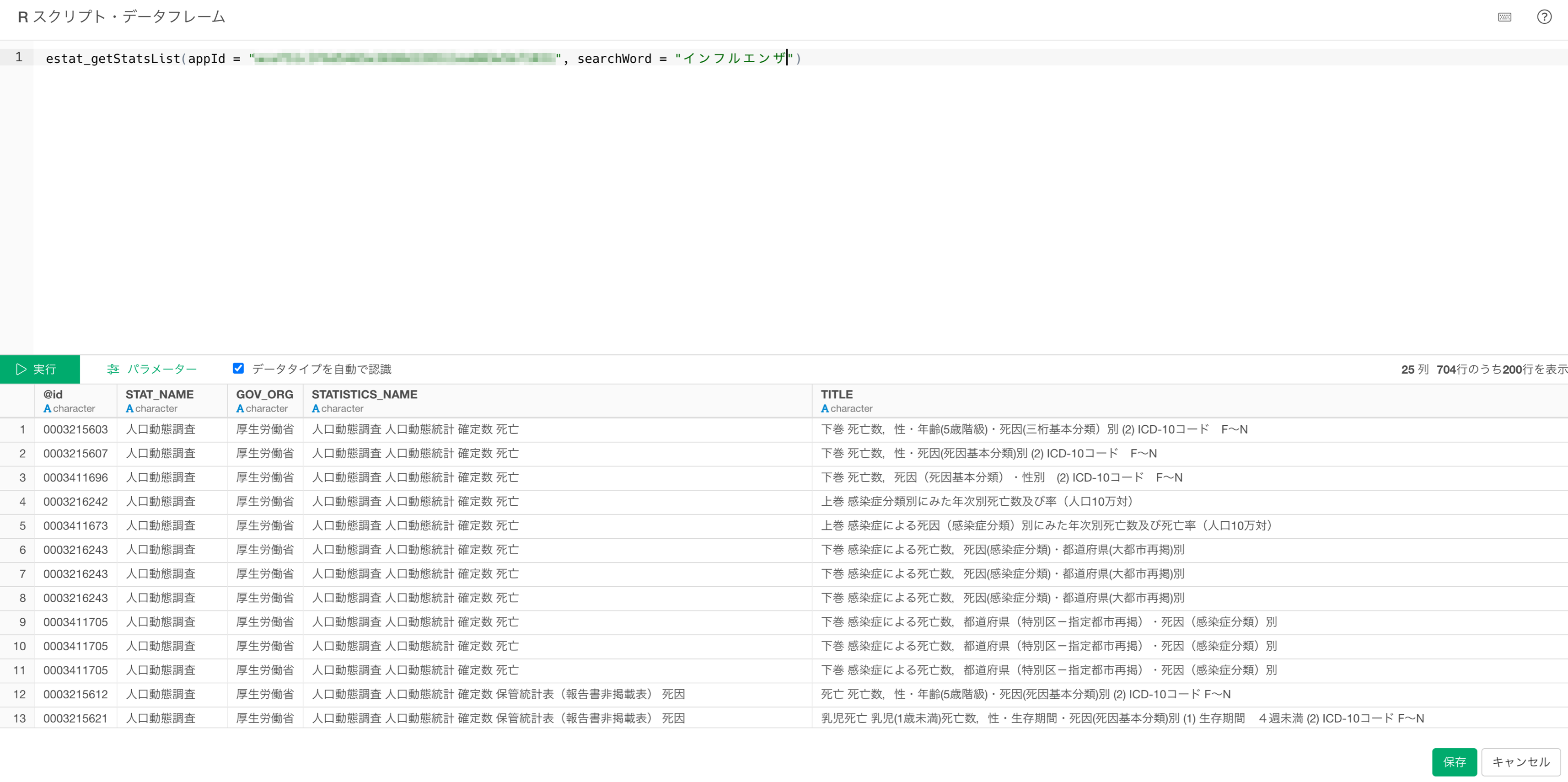
e-Statから統計表を取得してデータフレームとして保存することができました。今回は、「インフルエンザのキーワードで」統計表を取得しています。
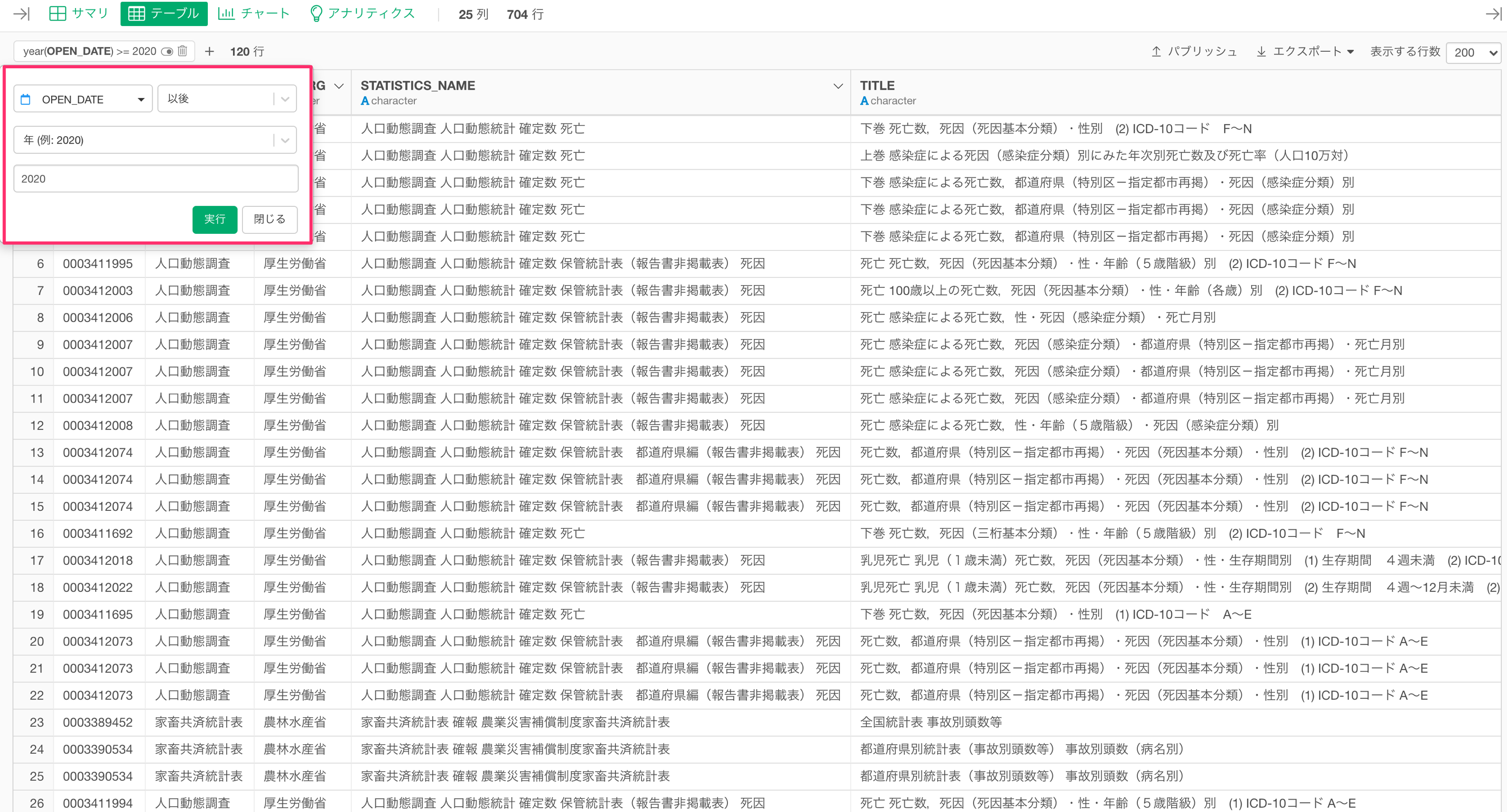
キーワードによっては取得される統計表の数が多くなってしまうので、テーブルビューで使えるフィルタ機能を使って絞り込むことができます。
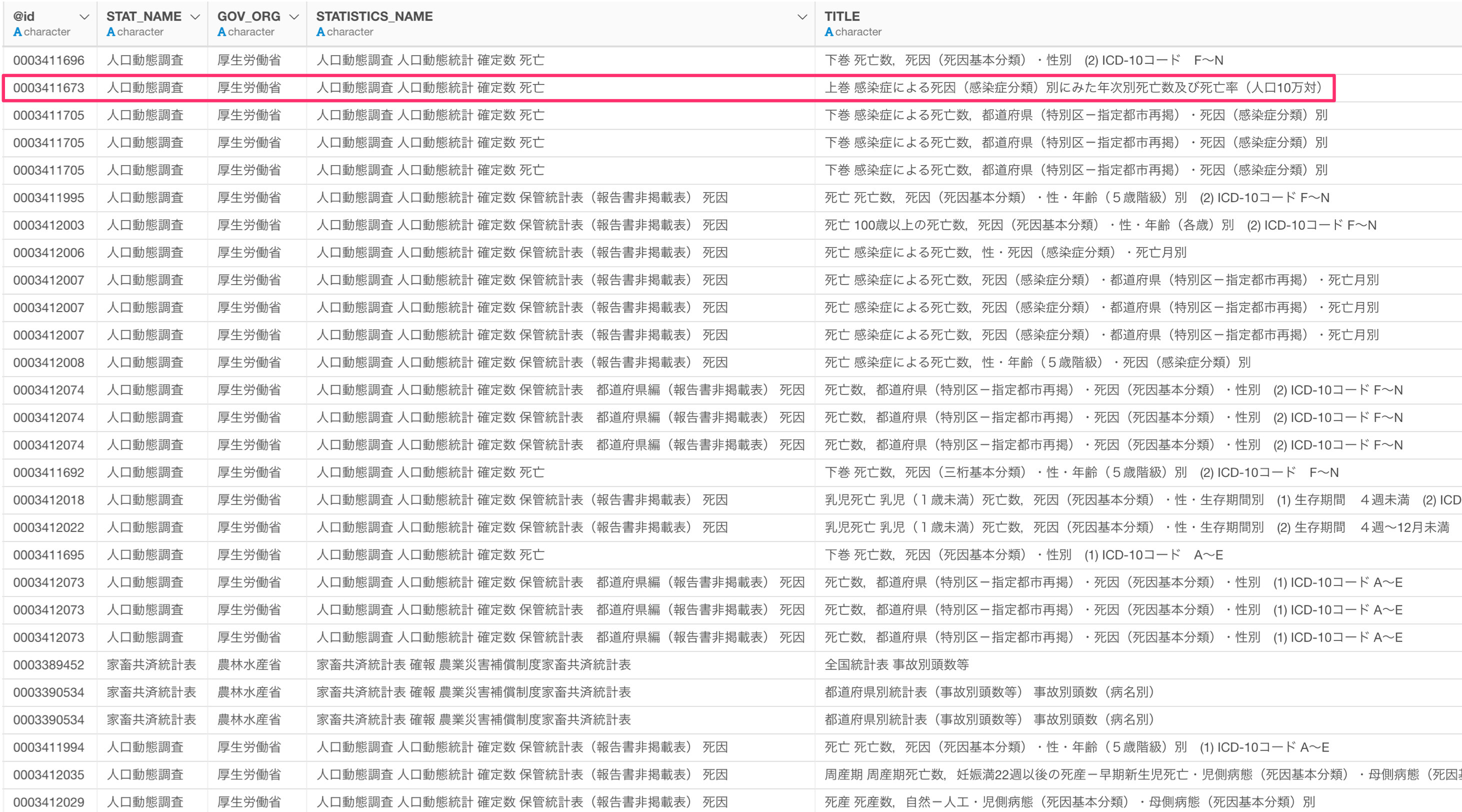
また、統計表の@id列が統計データの一意なIDになり、統計データを取得する際に必要になります。
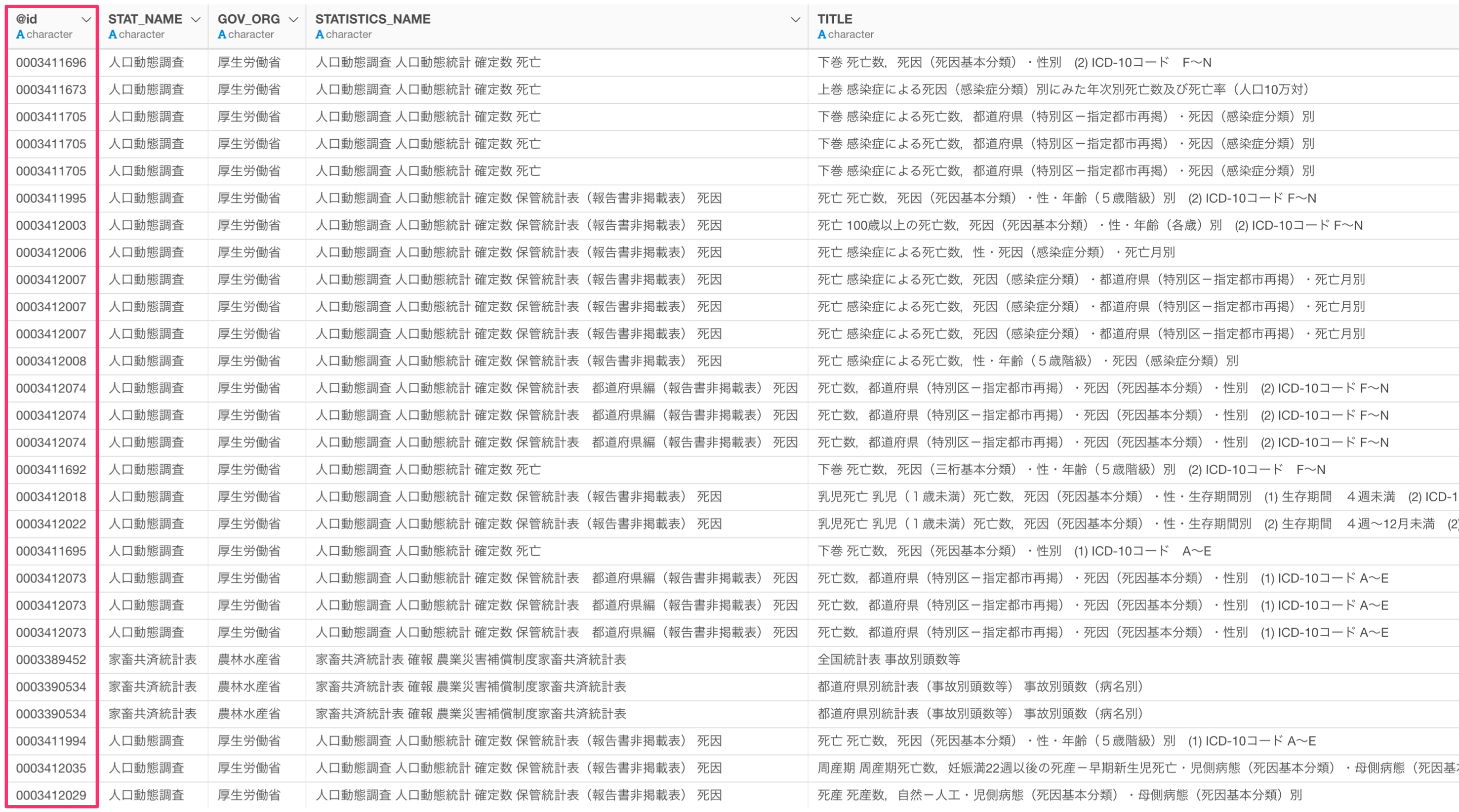
今回は、厚生労働省が公開している「人口動態調査の感染症による死因」のデータを使用したいため、@id列にある「0003311673」をコピーしておきます。
統計データを取得する
統計表から気になるデータを見つけた次のステップとして、実際に統計データを取得していきます。
データフレームのプラスボタンから「Rスクリプト」を選択します。
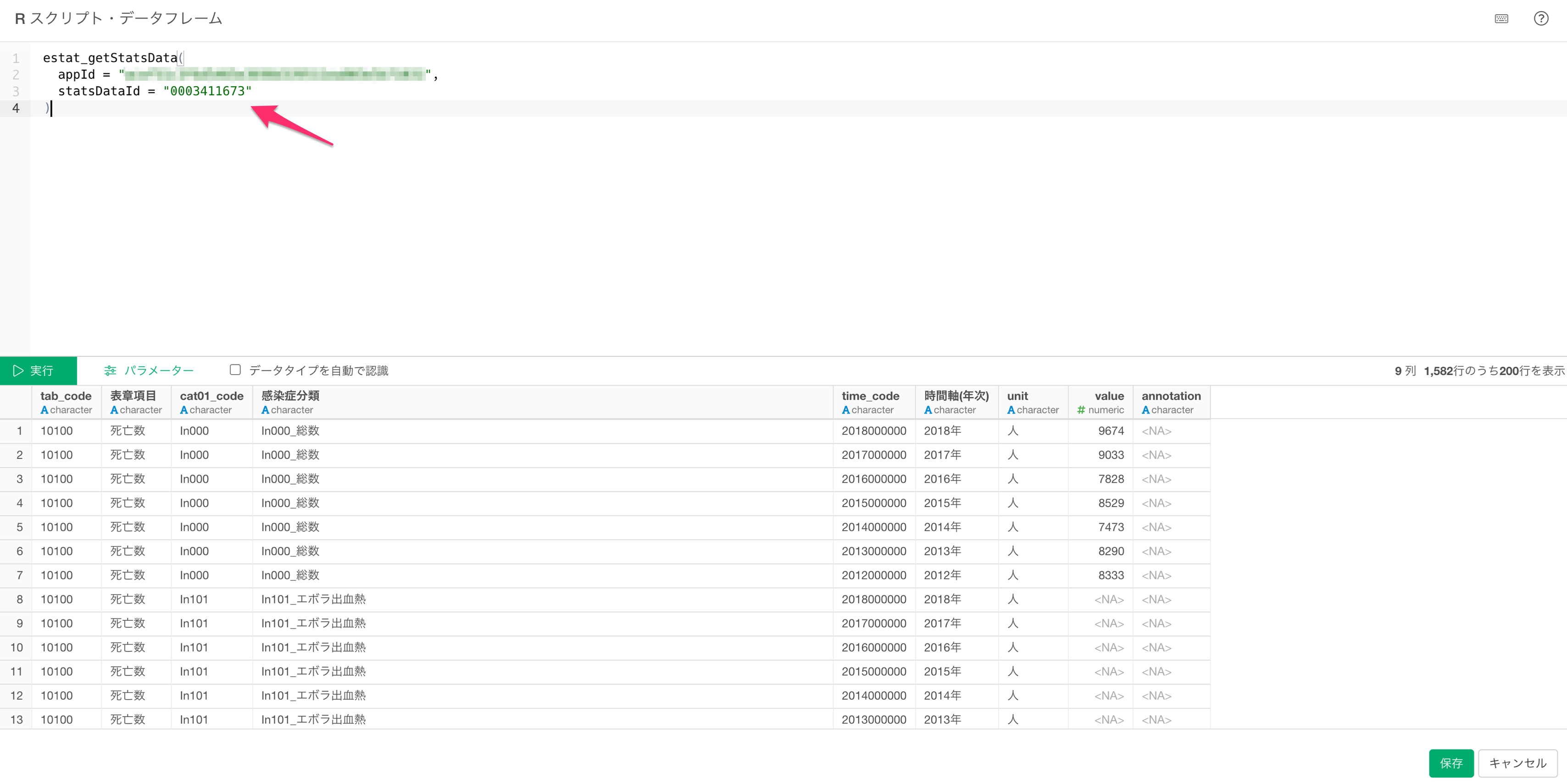
Rスクリプト・データフレームのダイアログが表示されるので、下記のスクリプトを実行します。
estat_getStatsData(
appId = <アプリケーションID>,
statsDataId = <統計データのID>
)statsDataIdには統計表の@id列にある値を入力します。この例では、厚生労働省が公開している「人口動態調査の感染症による死因」のデータを取得するためstatsDataIDに"0003311673"を指定しています。
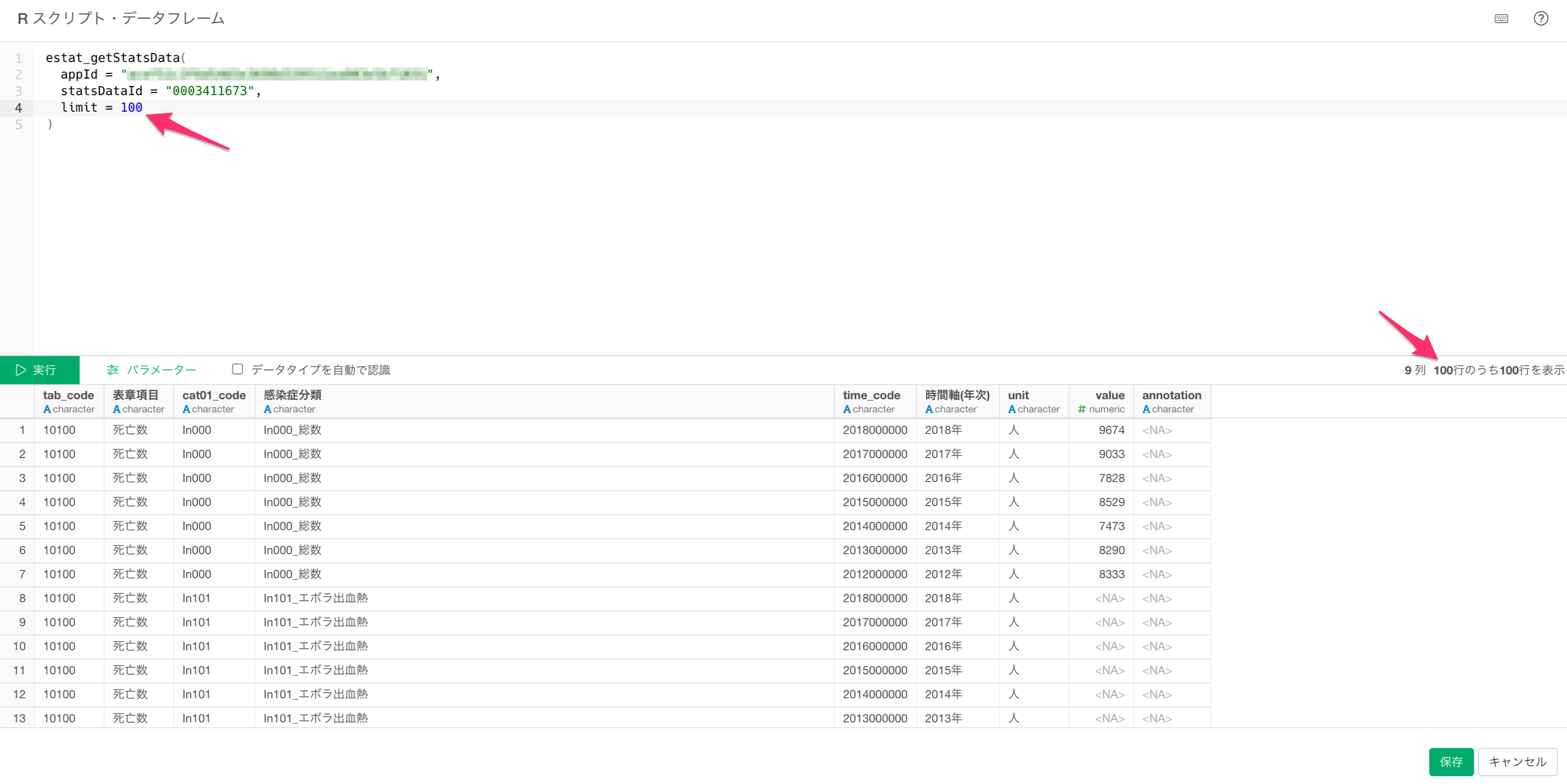
もし取得されるデータの行数が多い場合は、limitを使うことで取得する行数を制限できます。その場合は下記のように入力します。
estat_getStatsData(
appId = <アプリケーションID>,
statsDataId = <統計データのID>,
limit = <取得する行数>
)
また、データの中にはカテゴリーごとに分類したコードがあるため、特定のデータのみ取得したい場合には、cat01_codeの値を使うことになります。
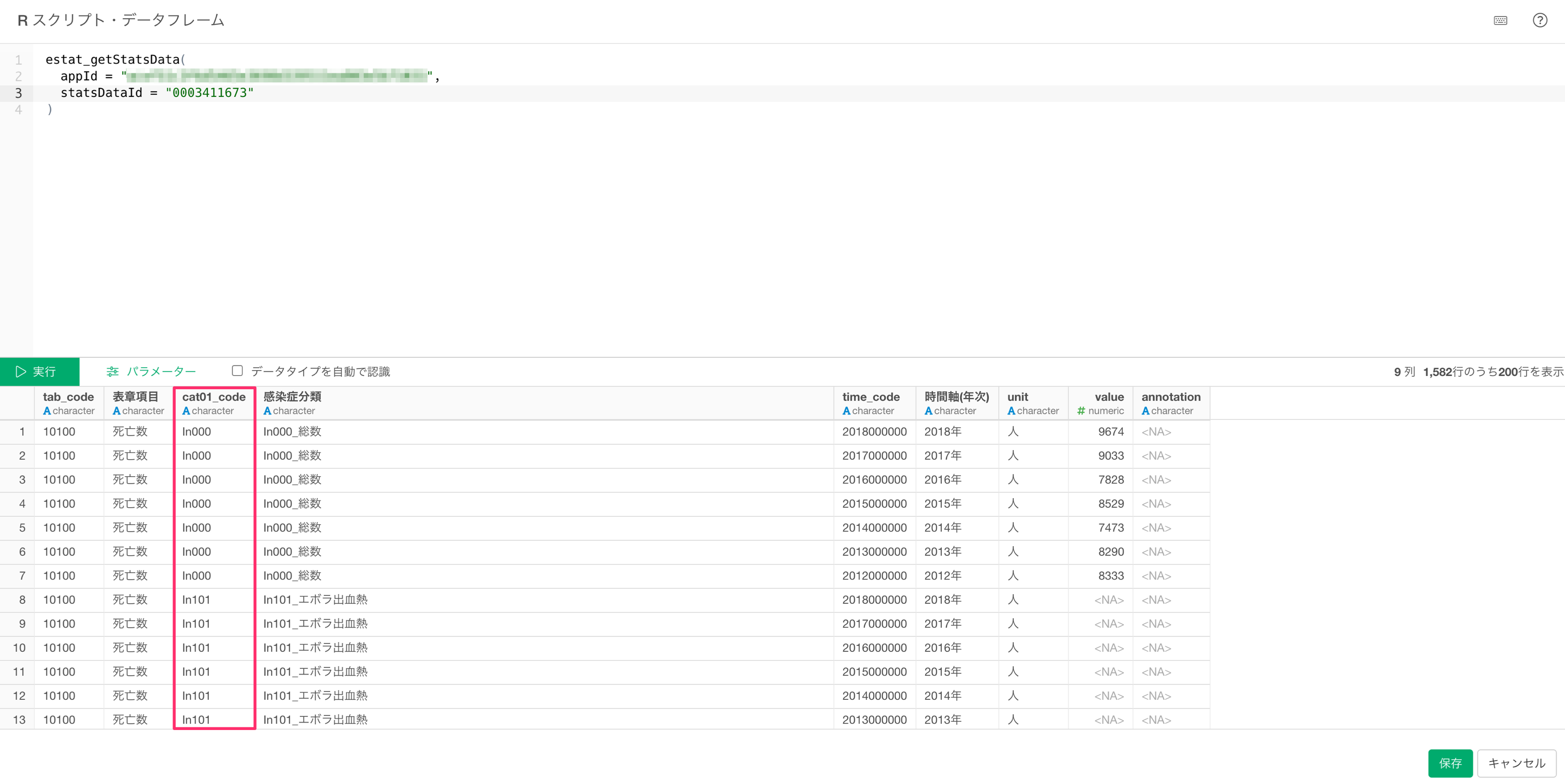
カテゴリーコードを指定してデータを取得する場合は下記のように記述します。
estat_getStatsData(
appId = <アプリケーションID>,
statsDataId = <統計データのID>,
cdCat01 = c(<カテゴリーコード1, カテゴリーコード2>)
)cdCat01のc()の中にはcat01_codeから参照したコードを入力します。複数指定したい場合は、コンマ区切りで入力することができます。
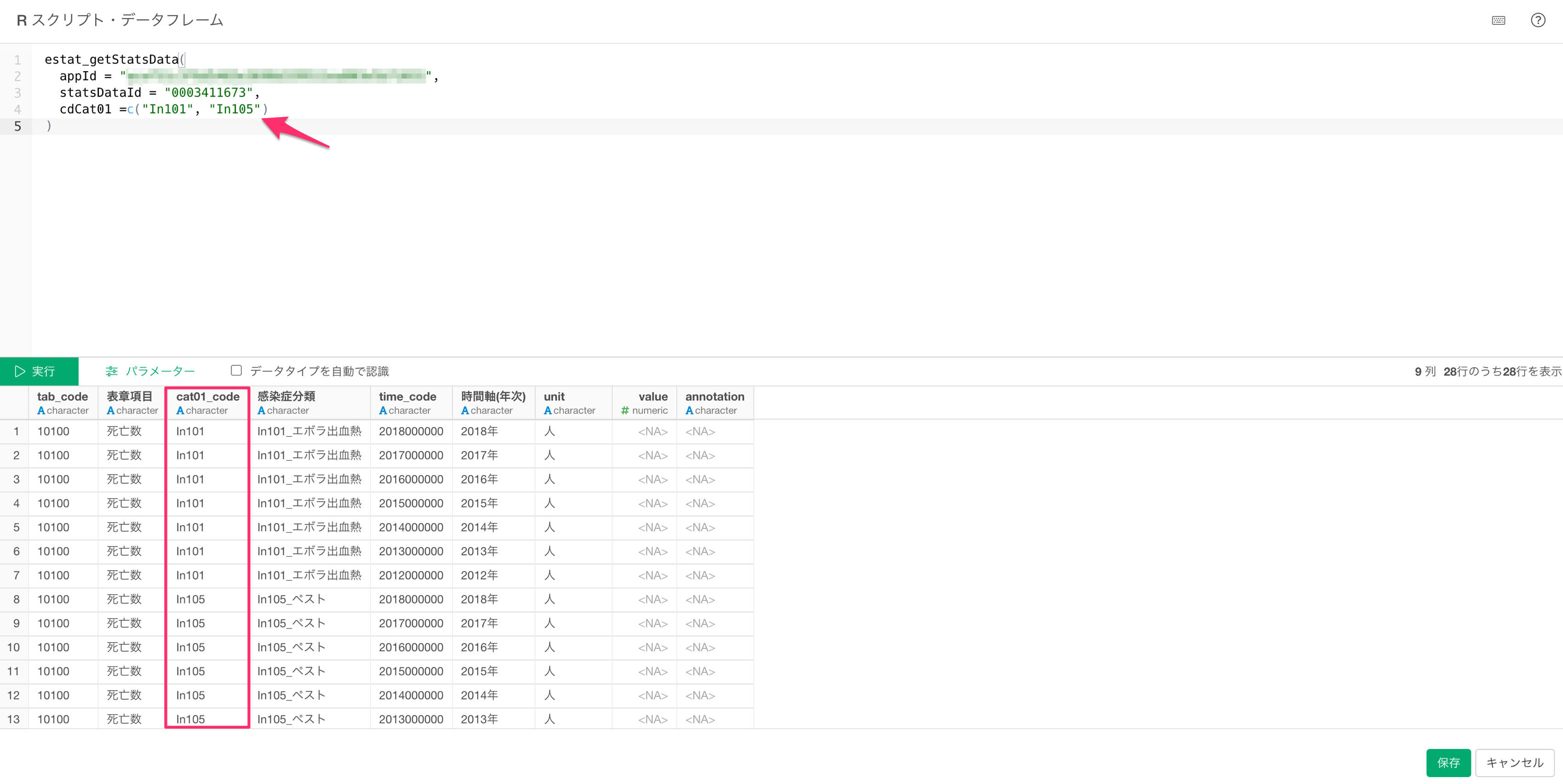
今回は、limitもカテゴリーコードも使用せずに、統計データをインポートしていきます。
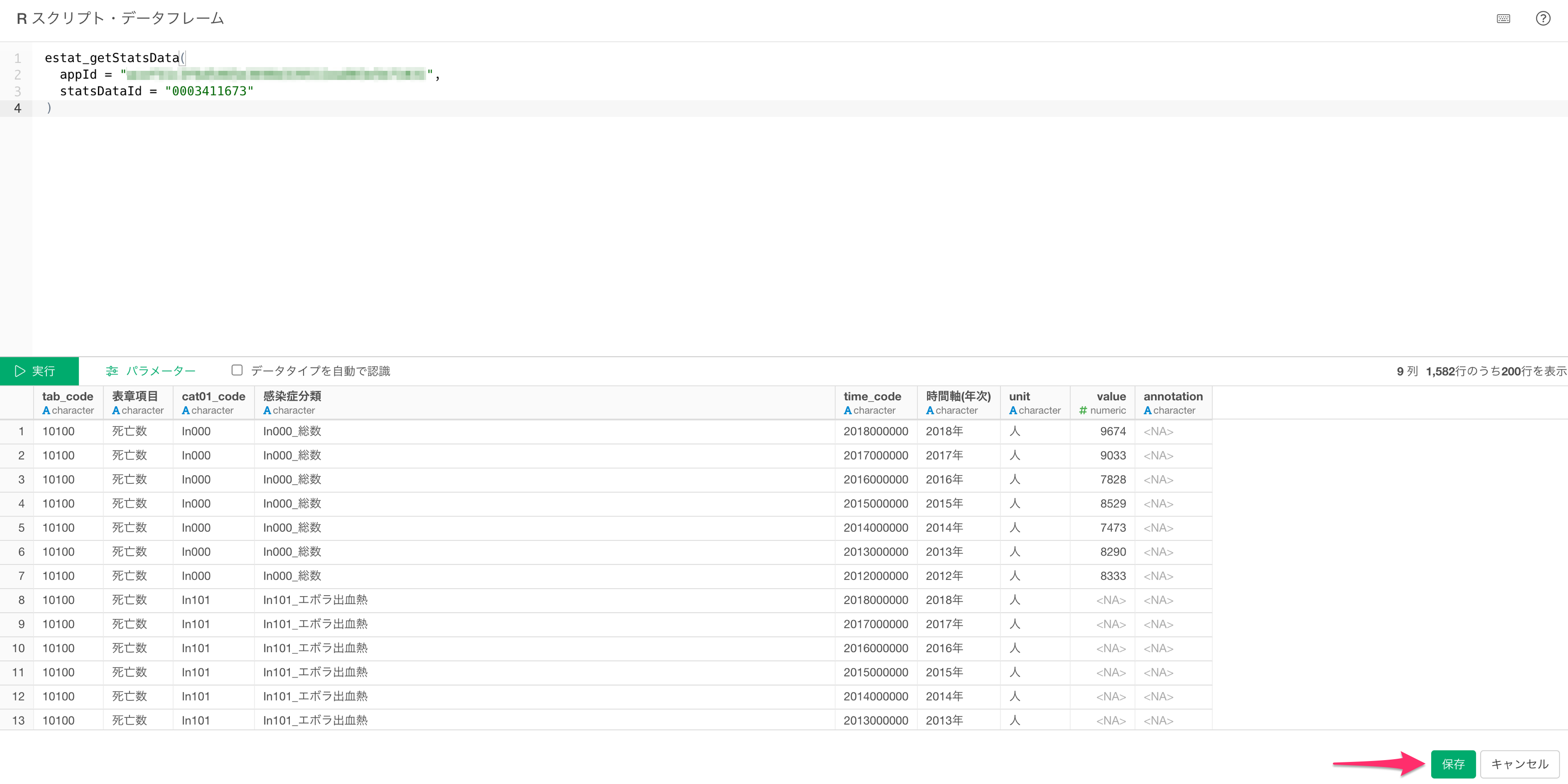
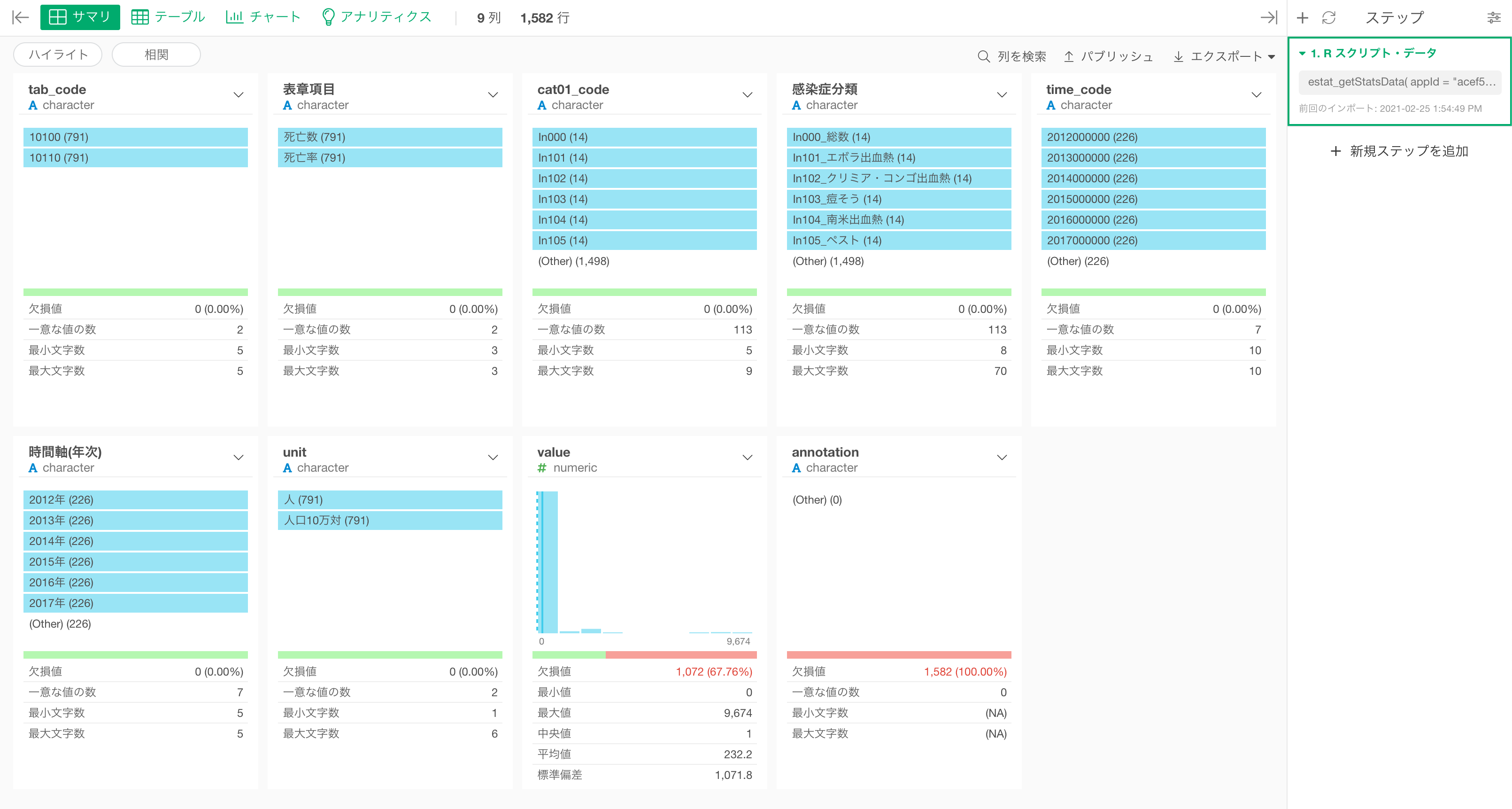
e-Statから統計データを取得することができました。サマリビューから基本統計値やデータの分布、欠損値の数などを把握することができます。
データを使える形に加工・整形する
データはインポートできましたが、多くの場合は可視化やアナリティクスで使える形になっていません。
このデータではいくつかの問題があります。例えば、感染症分類の列に、カテゴリーの分類コードと感染症名がまとめられていたり、時間軸(年次)の列は数値型になっていません。
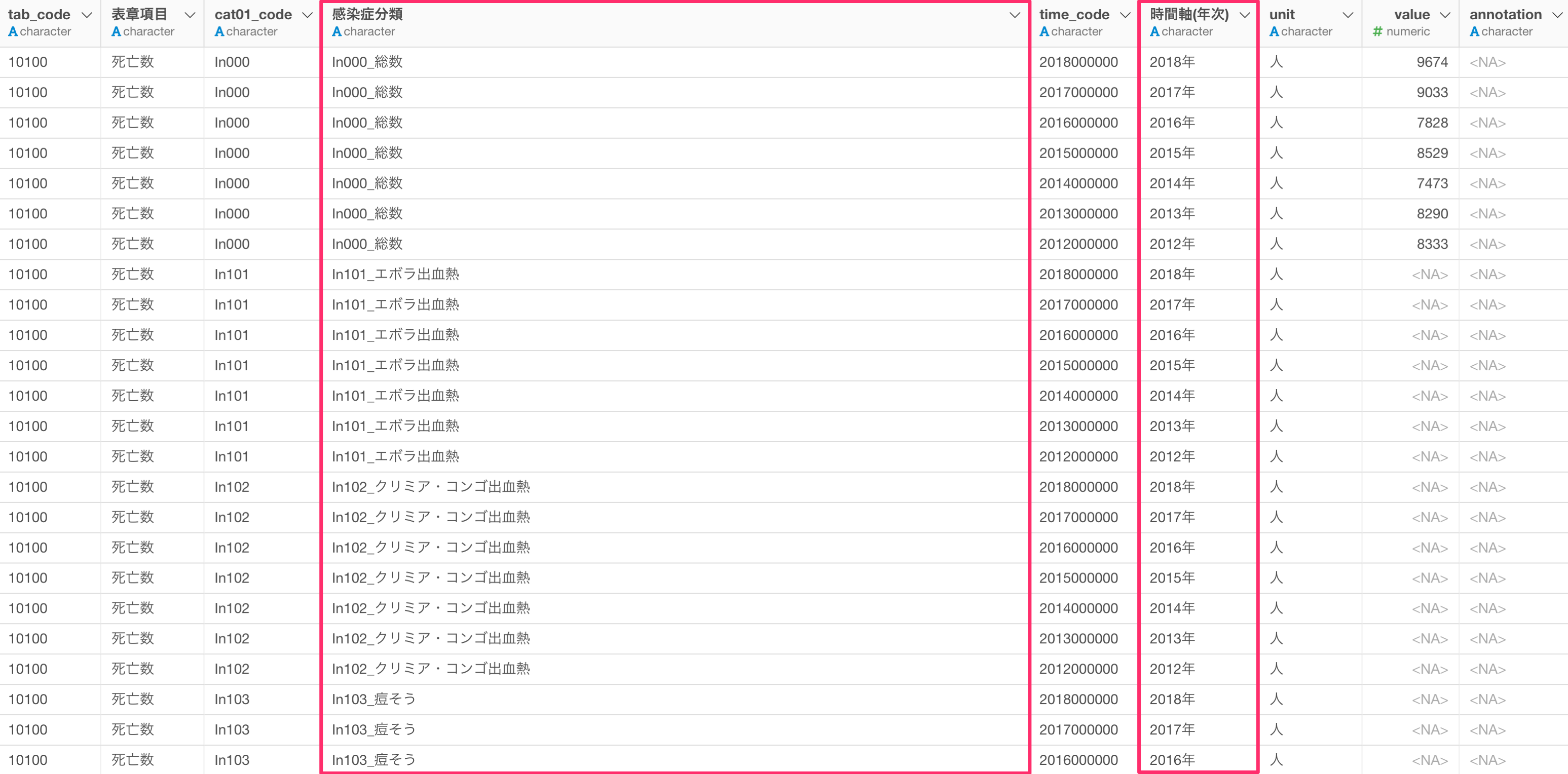
そして、死亡者数と人口10万人あたりの死亡率が同じ列にまとめられており、死亡者数と死亡率をいっしょに可視化してしまう可能性があります。
そのため、データラングリングをして可視化やアナリティクスで使えるように、加工・整形する必要があります。今回は下記のように、1行が感染症の分類と年ごとにして、死亡数と死亡率を別々の列にしたデータにしていきます。
感染症分類の列には感染症のコードと感染症名が一つの列にまとめられているため、感染症名だけを抽出したいです。
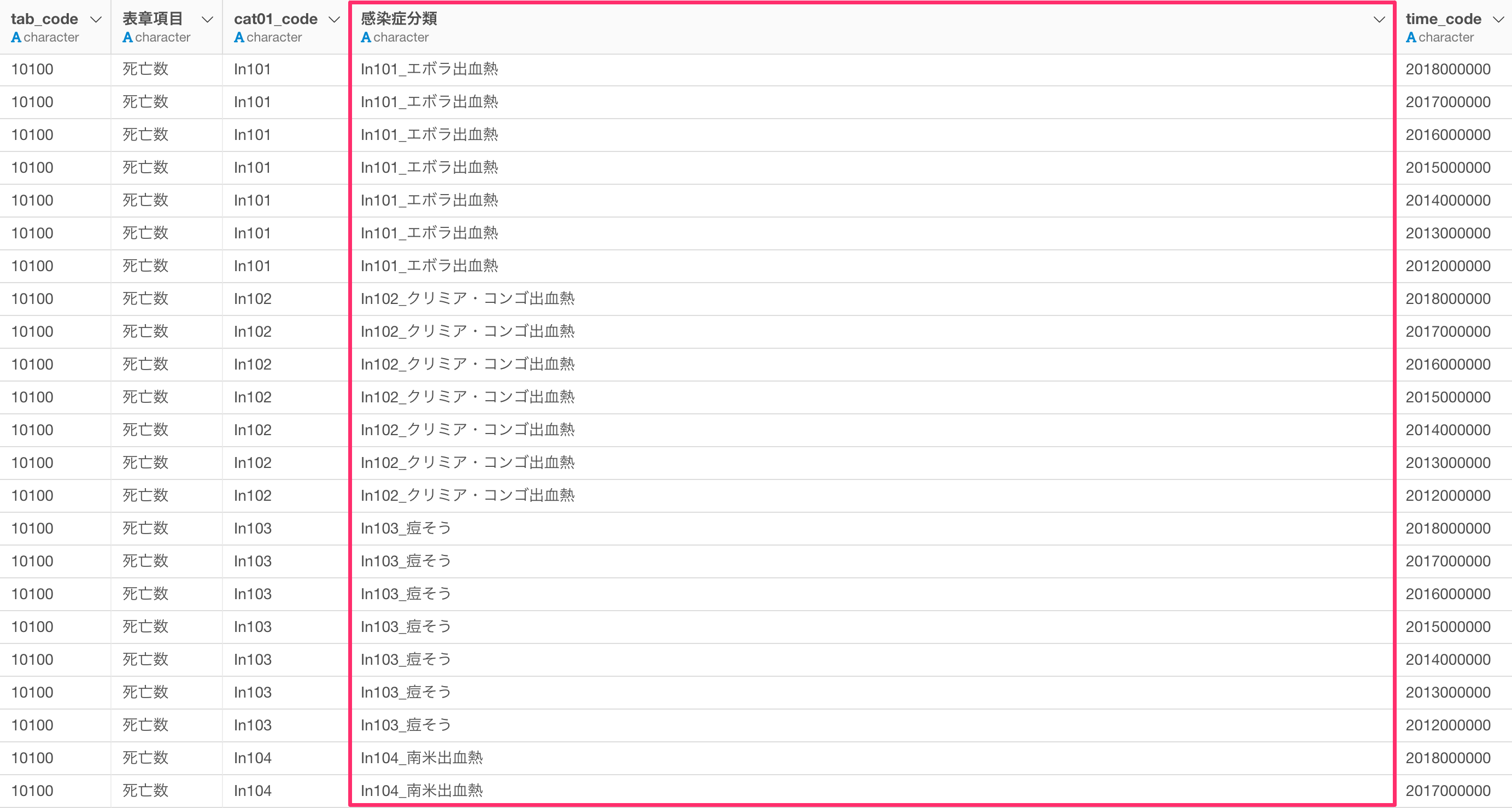
値には「感染症コード_感染症名」となっているため、テキストデータの加工の最後の単語を抽出することで、感染症名を取り出すことができます。
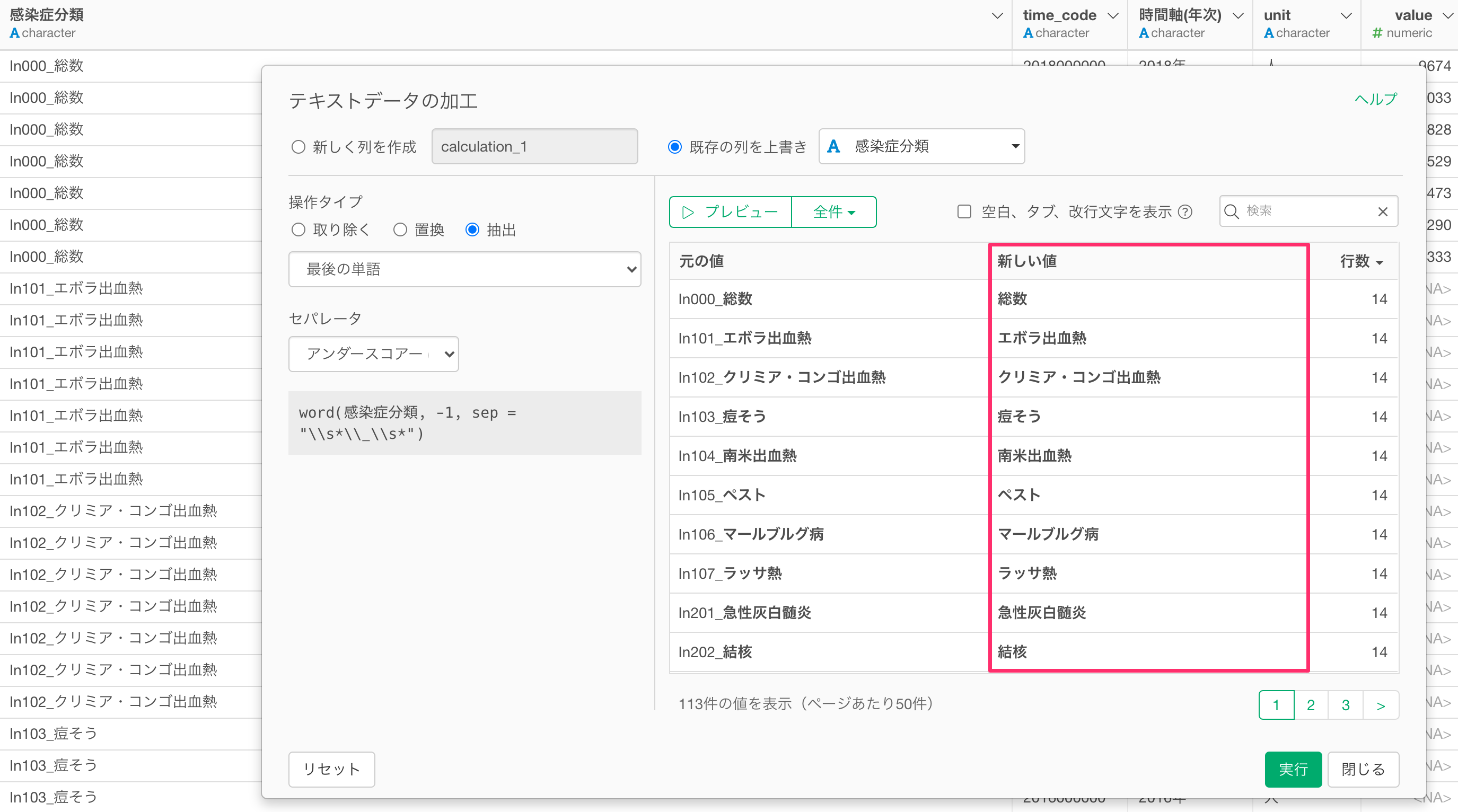
感染症の分類の列から感染症名だけを抽出することができました。
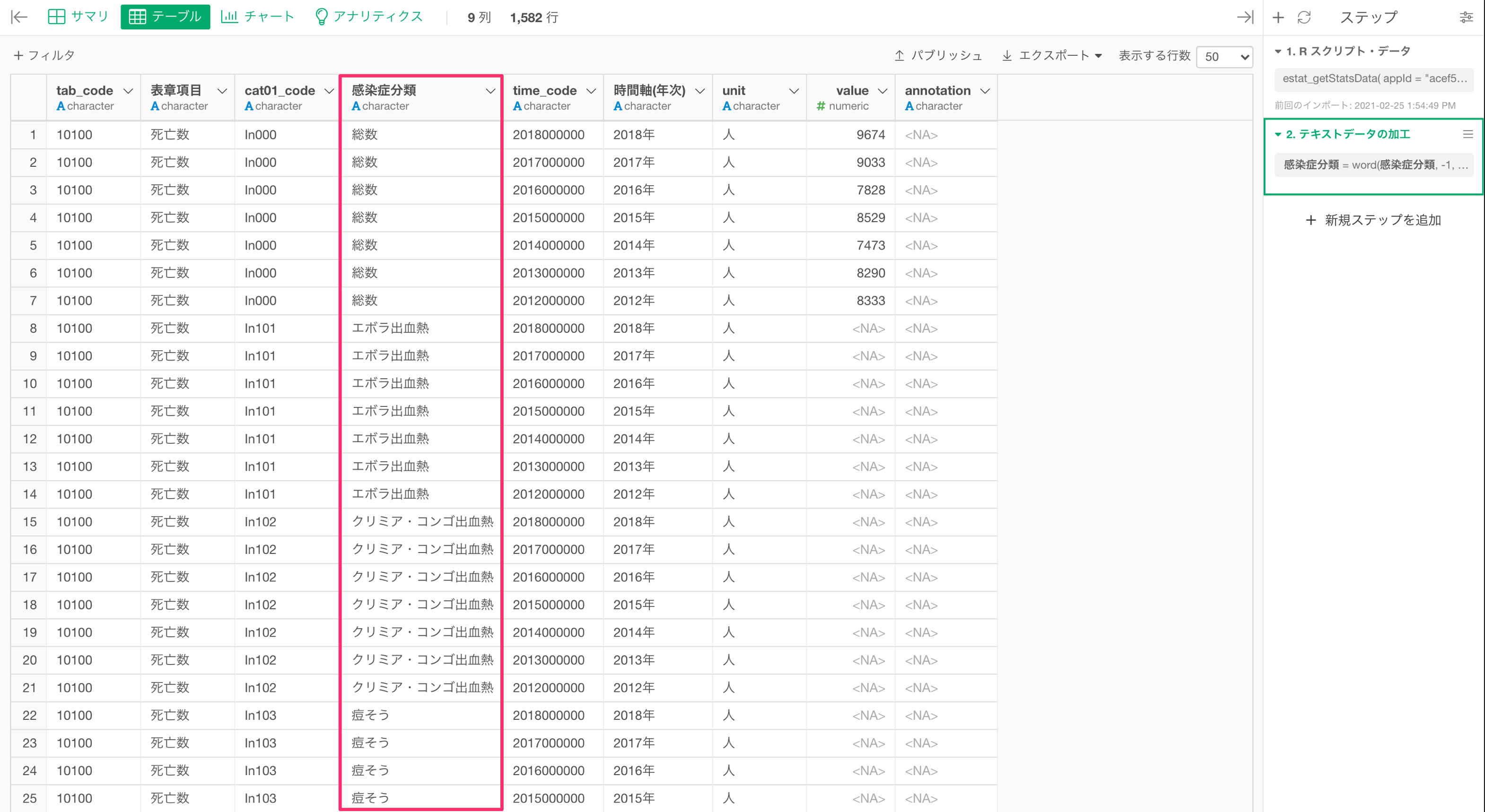
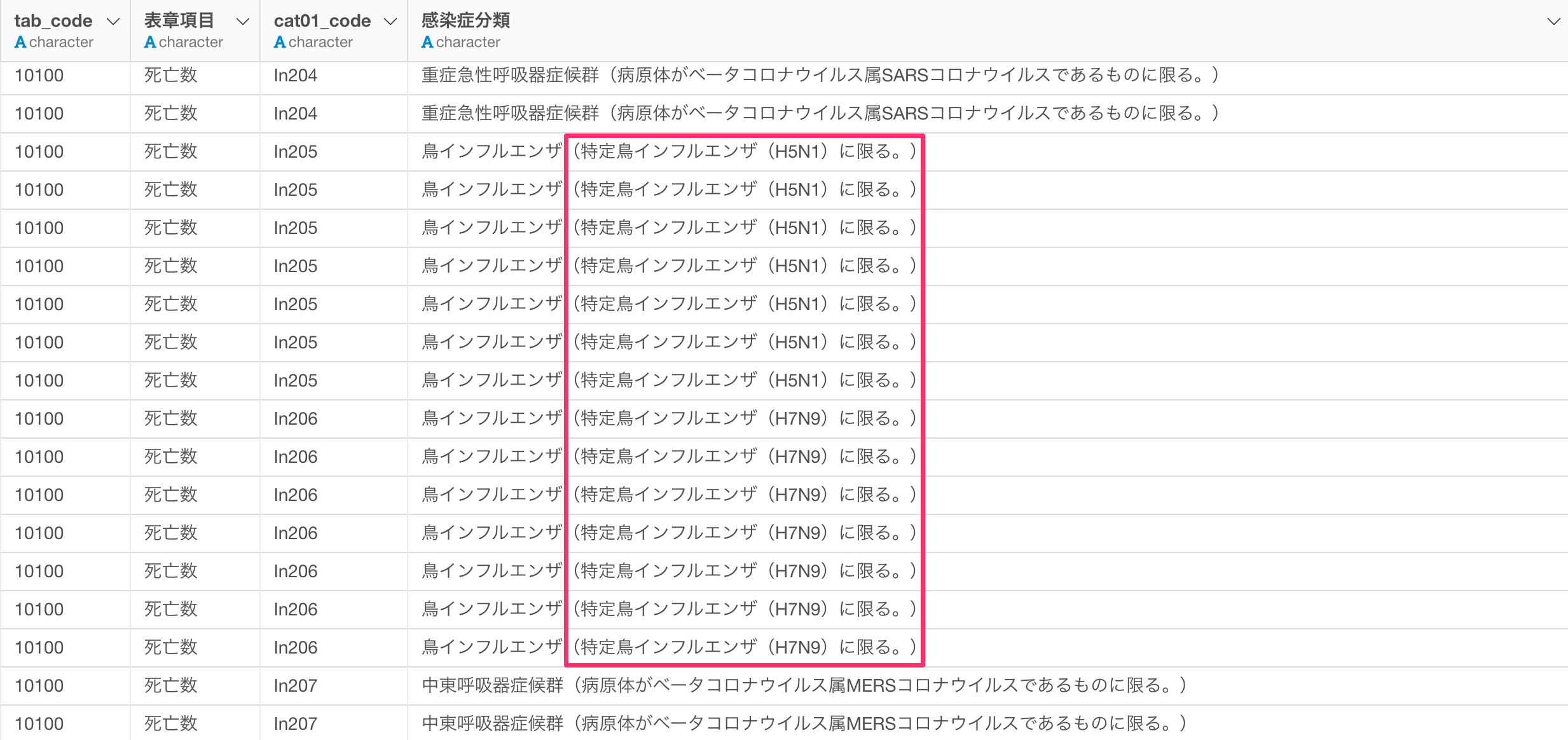
感染症分類の列にはまだ問題があり、鳥インフルエンザの中にも「H5N1」と「H7N9」で分かれているため、どちらも鳥インフルエンザとしたいです。
テキストデータの加工から記号の中の文字列を使うことで、括弧の中の文字列を取り除くことができます。
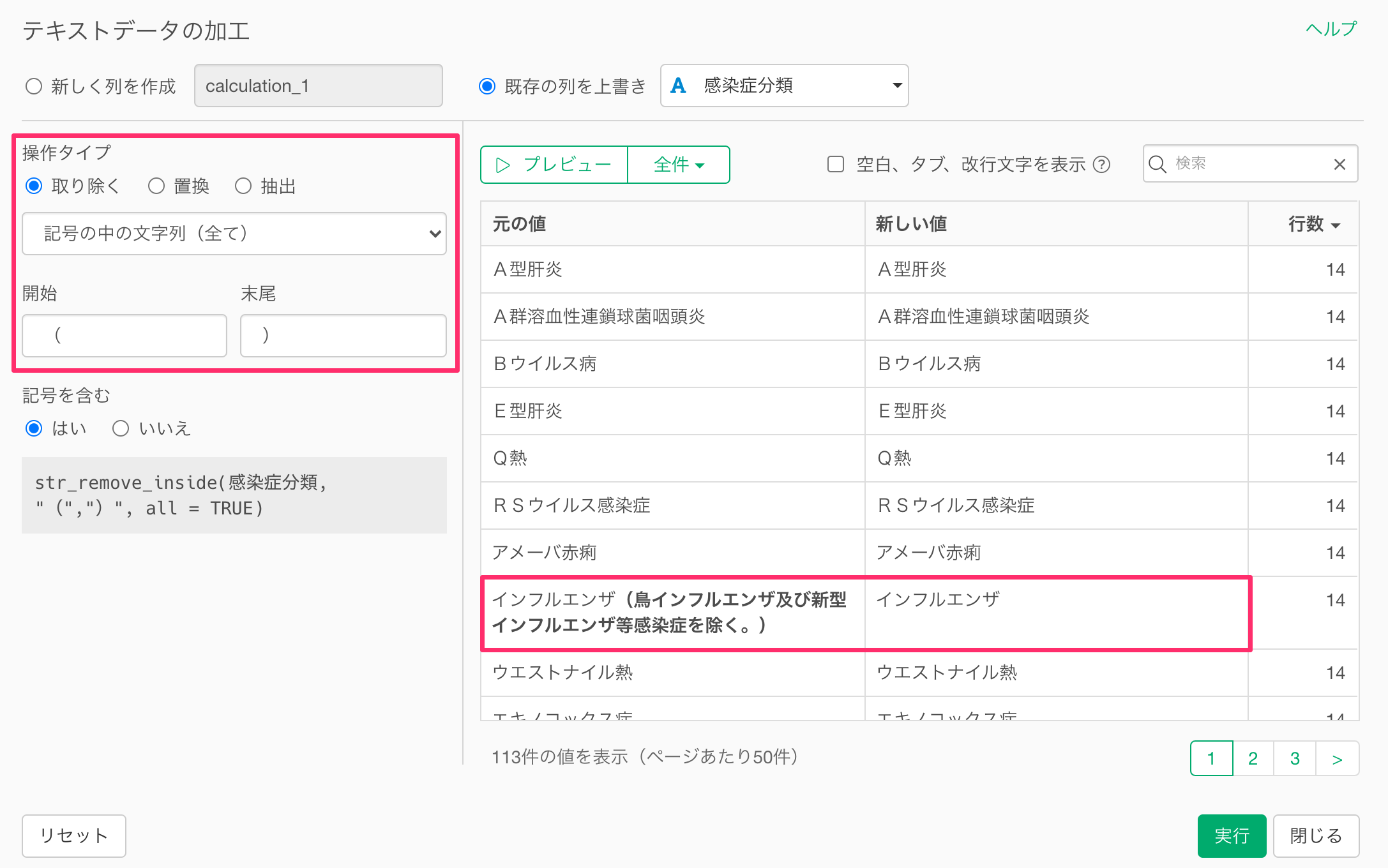
これにより感染症分類にあった括弧の中の文字を取り除き整えることができました。
次に、時間軸の値には年がついているため、データタイプがカテゴリー型 (character)になっています。時間軸のように値に順序があるようなデータでは、データタイプがカテゴリー型になっていると可視化する際に年の並び順がおかしくなることがあります。
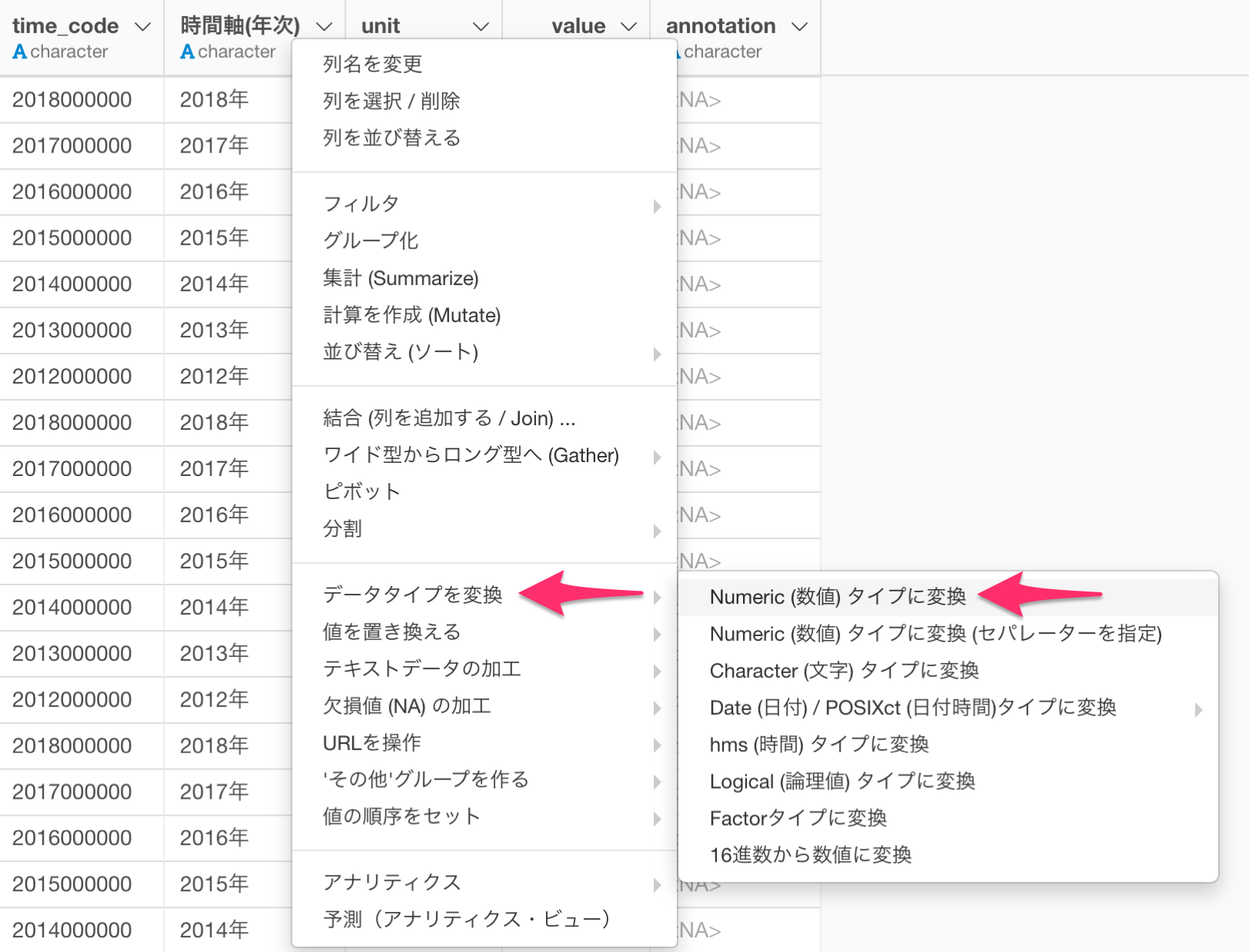
そのためデータタイプを数値型 (numeric)に変換する必要があります。Exploratoryでは、列ヘッダメニューから簡単にデータタイプを数値型に変換していくことができます。
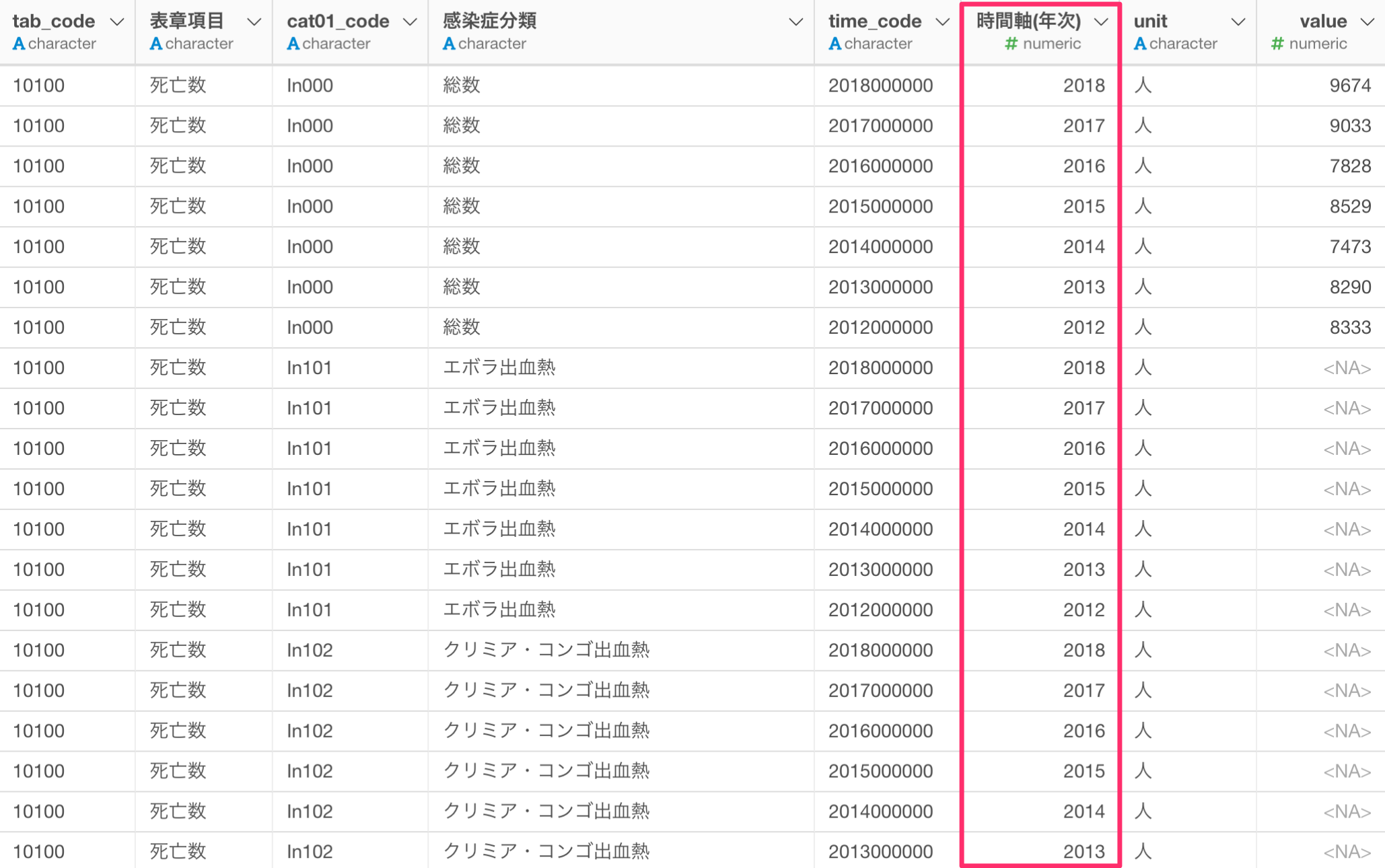
時間軸の列のデータタイプを数値型に変換することができました。
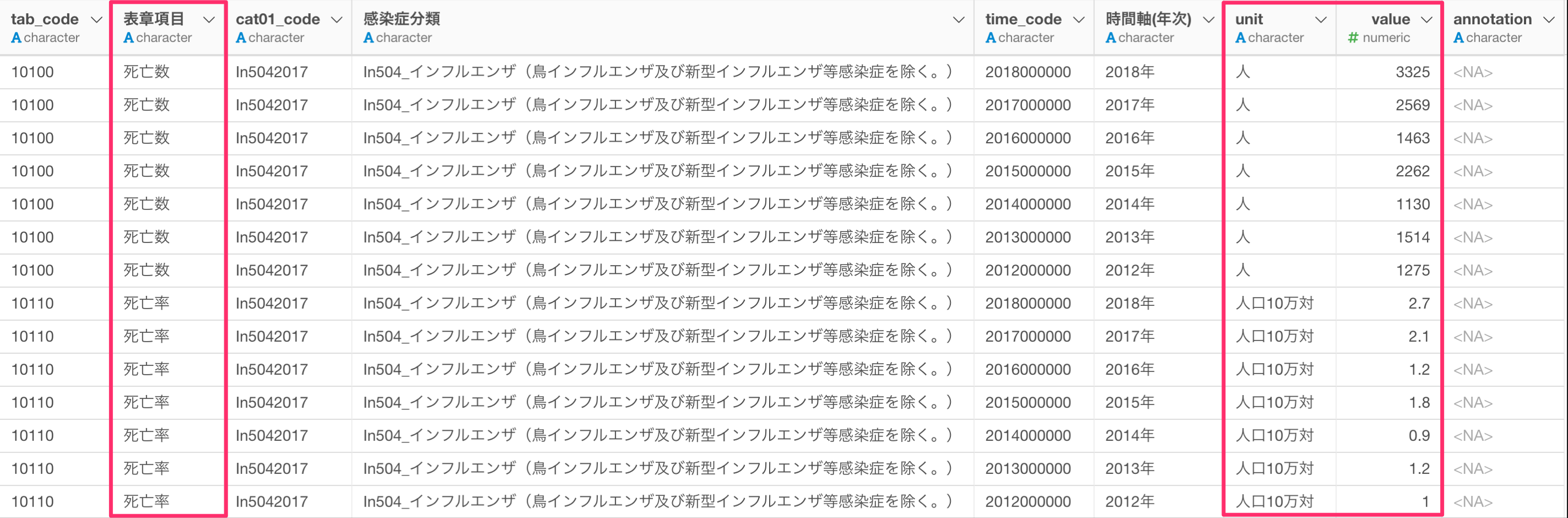
最後に、valueの列には死亡数と死亡率が一つの列にまとめられています。このように異なる値を持つ指標を一つの列にまとめてしまうと混乱を招き、死亡者数と死亡率をいっしょに可視化してしまう可能性もあります。そのため、死亡者数と死亡率の列を別々の列として分割していきます。
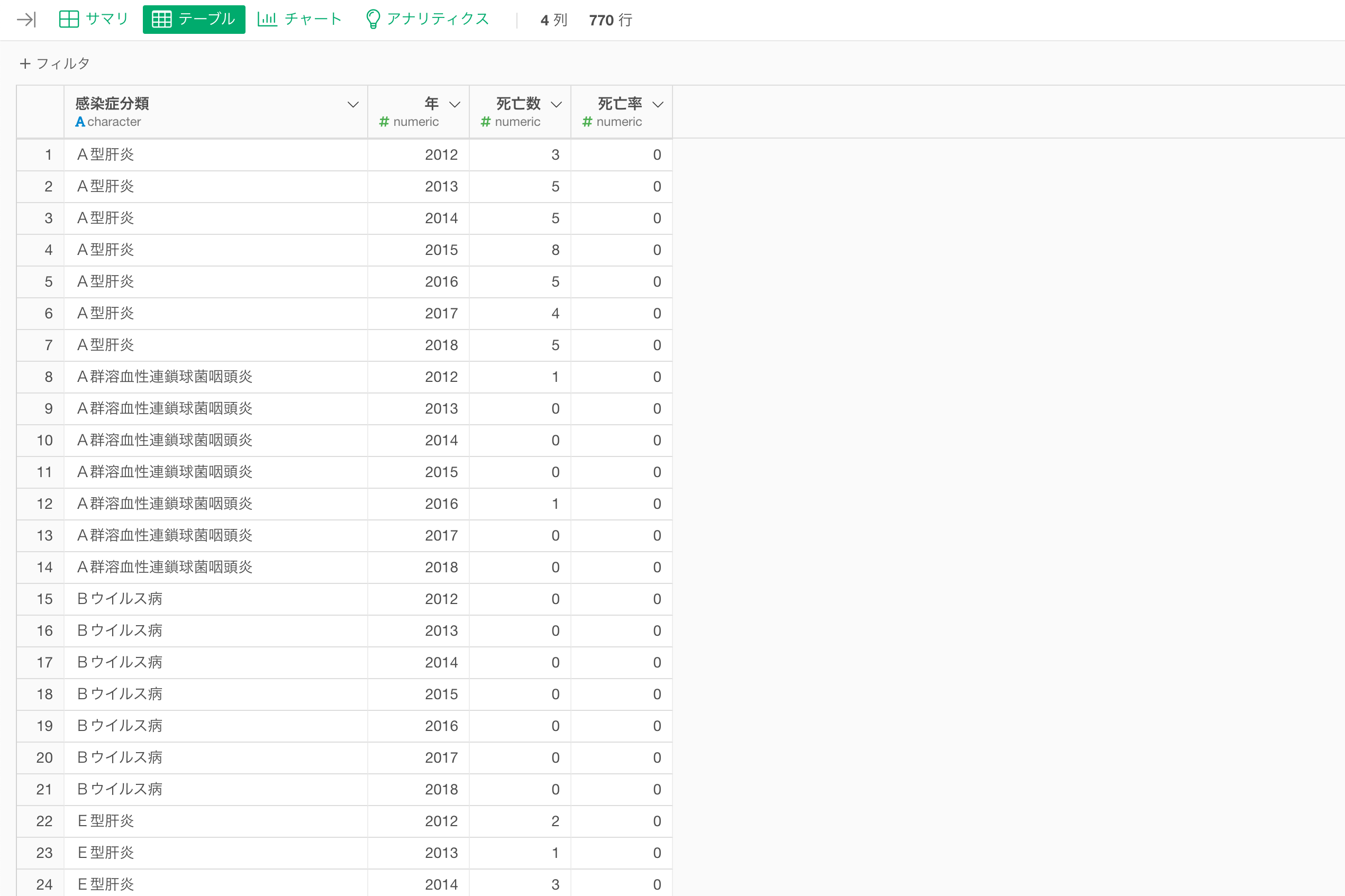
今回はピボットを使うことで、感染症の分類と時間軸ごとに行として割り当て、死亡数と死亡率の列を作成します。
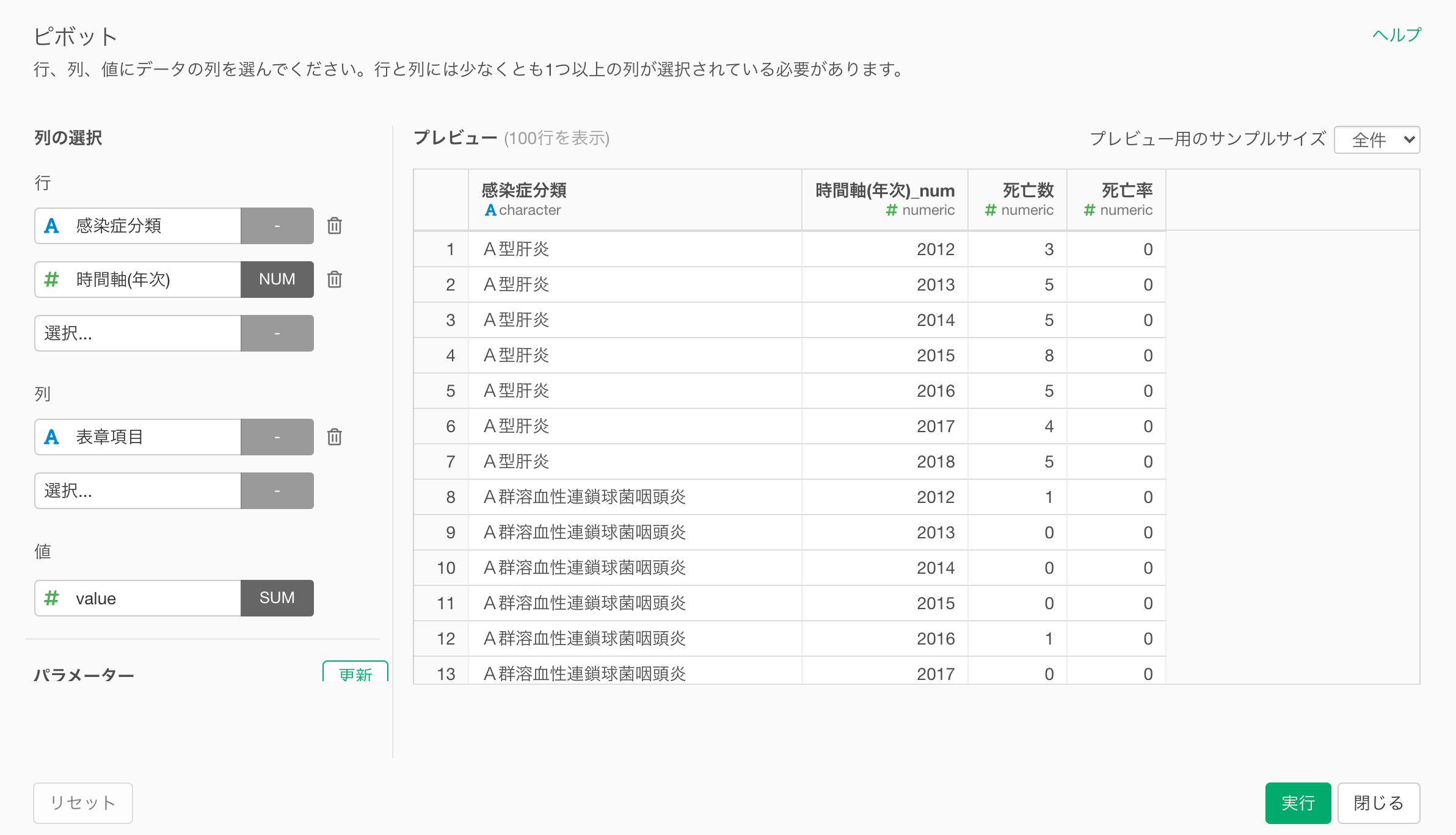
これによりデータを可視化しやすい形に整えることができました。
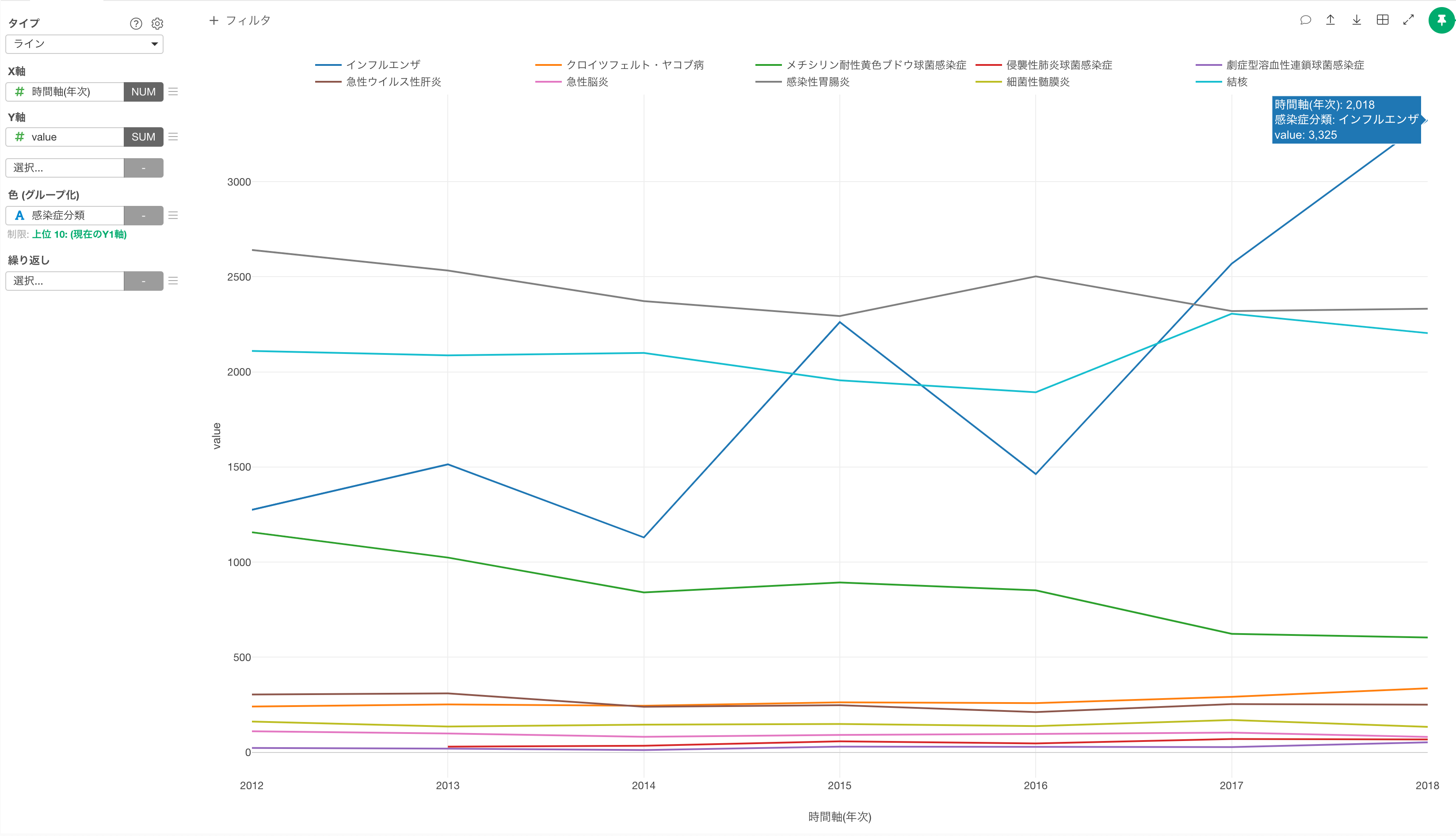
データラングリングをしてデータを可視化しやすい形に加工・整形することで、下記のように可視化していくことができます。
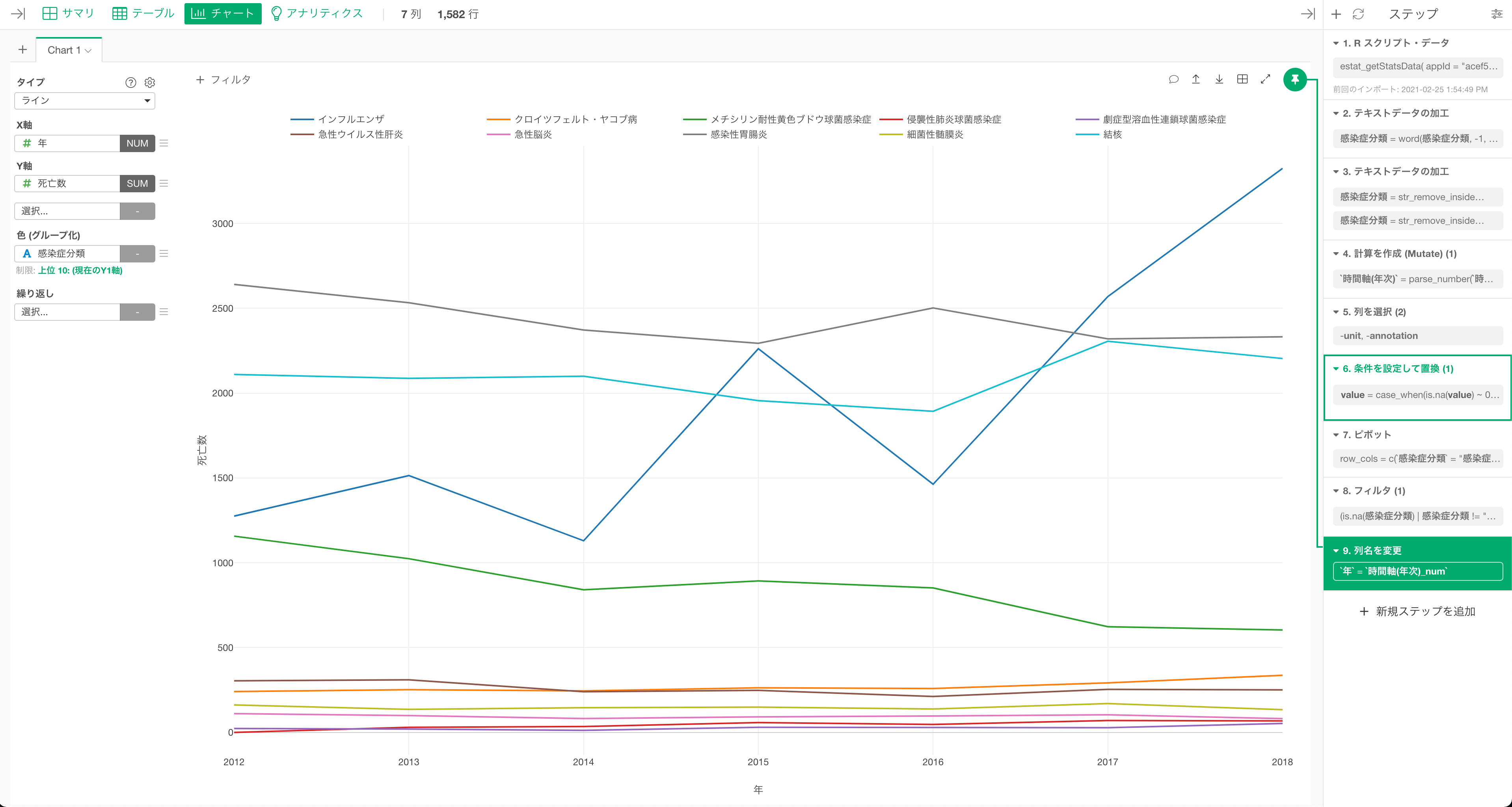
今回例にあげた感染症による死因のデータを使うと、インフルエンザによる死亡者数は毎年1000人以上報告されており、2018年には死亡者数が3,300人と多いことが確認できます。
データラングリング・トレーニング、5月開催決定!
データラングリング(データの加工)の手法を1から体系的に、そして効果的に身に着けていただくために、データラングリング・トレーニングを提供しています。
データを自由自在に操れることで、実は思った以上に役に立つデータが身の回りにあるということに気づかれるはずです。そして思った以上にデータを使って答えることのできる質問がこの世の中には多くあるということにも気づいていただけると思っております。
ぜひこの機会に参加をご検討ください!
開催要項
- 日時 : 2021年 5月13日(木),14日(金) 9:00-17:00
- 会場: オンライン (参加者には事前にZoomのURLが送付されます。)
詳細はこちらのページにあります。