ワードクラウドの作り方
テキスト分析で単語を可視化する際によく使われるワードクラウドの作り方をご紹介します。

サンプルデータとしてTwitter Searchからデータサイエンスのキーワードで取得したデータを使用していきます。事前にテキストの単語化を使って、ツイート(text列)は単語化しています。
今回は、単語化されたツイート(token列)をワードクラウドを使って可視化していきます。
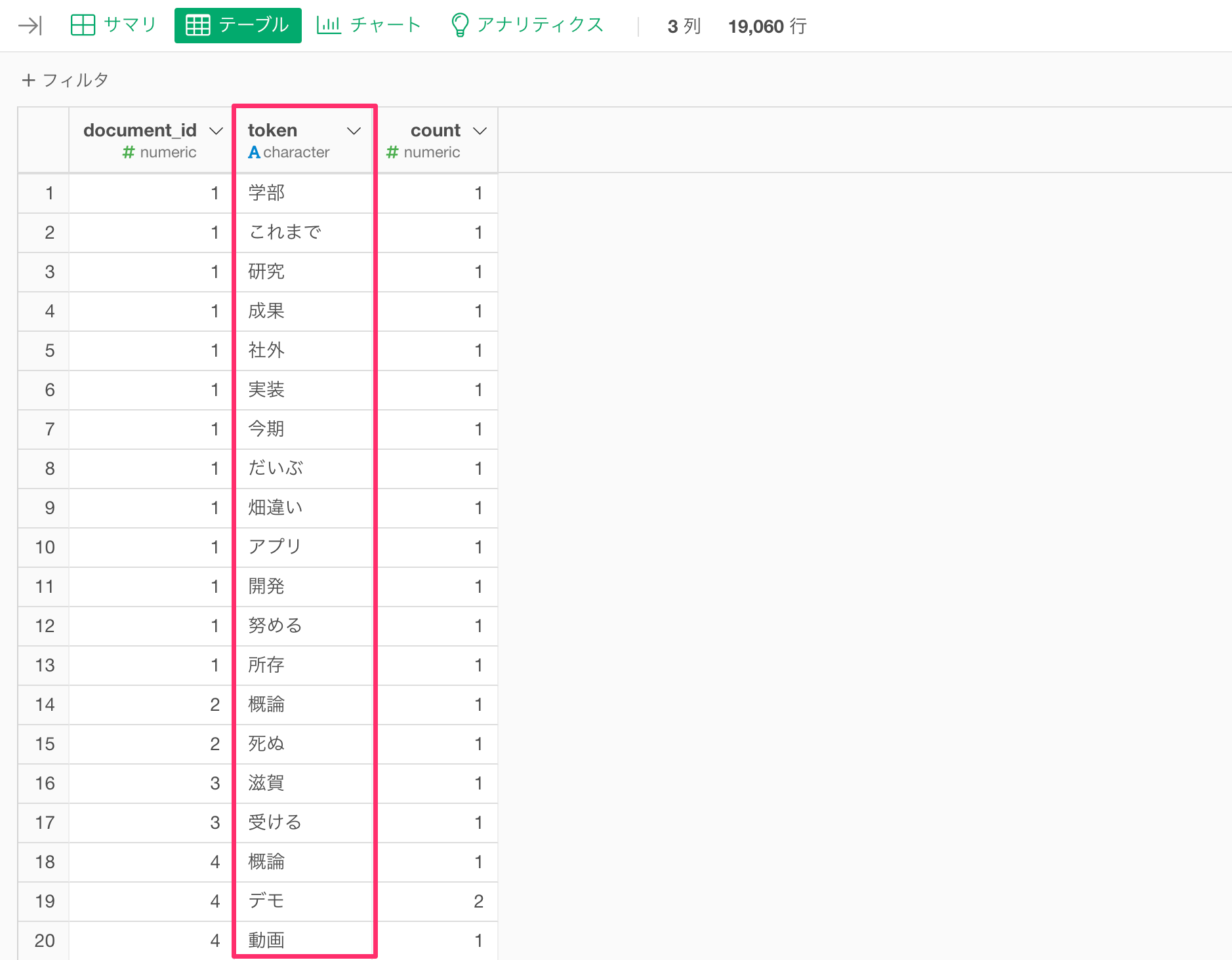
チャートビューからチャートを作成し、タイプにワードクラウドを選び、単語にtokenを選択します。
サイズのデフォルトでは行の数が選択されています。今回のデータの場合は、1行がdocument_idごとの出現した単語になるので、単語が文章で出現した回数となっています。

これをみるとaiや大学、課題、基礎などがよく出現していることがわかります。

色で分割にcountを選び、集計関数に合計値(SUM)を選択します。

countは文章に出現した単語の数になりますが、単語の出現回数ごとに5つのグループに色分けできました。
ai、大学、基礎、課題の次は、学や統計、講座などがよく使われているようです。大学にてデータサイエンスの授業があるのかもしれません。
今回のようにワードクラウドを使うことで、単語をサイズや色で可視化することができ、どの単語がよく使われているのかを理解していくことができます。