対応分析(コレスポンデンス分析)の紹介
対応(コレスポンデンス)分析はアンケートデータの分析をするときによく利用される手法の1つです。
対応(コレスポンデンス)分析を利用すると、順序関係がないカテゴリ型の回答を得られるアンケートの質問間の関係や、回答の特徴を直感的に理解することが可能です。
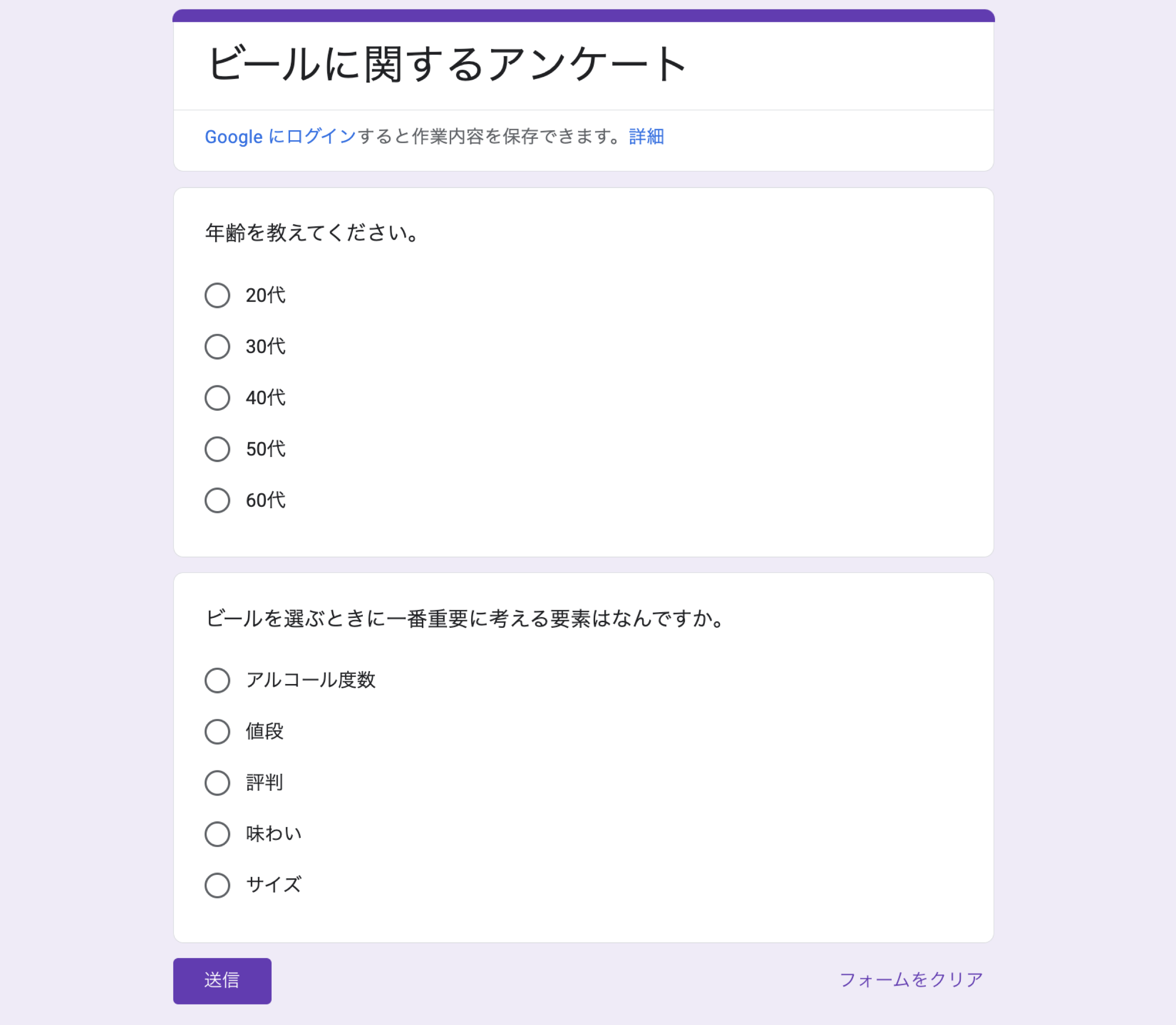
例えば、以下のようなアンケートを実施し、
以下のように年代ごとに回答の割合を可視化したとします。
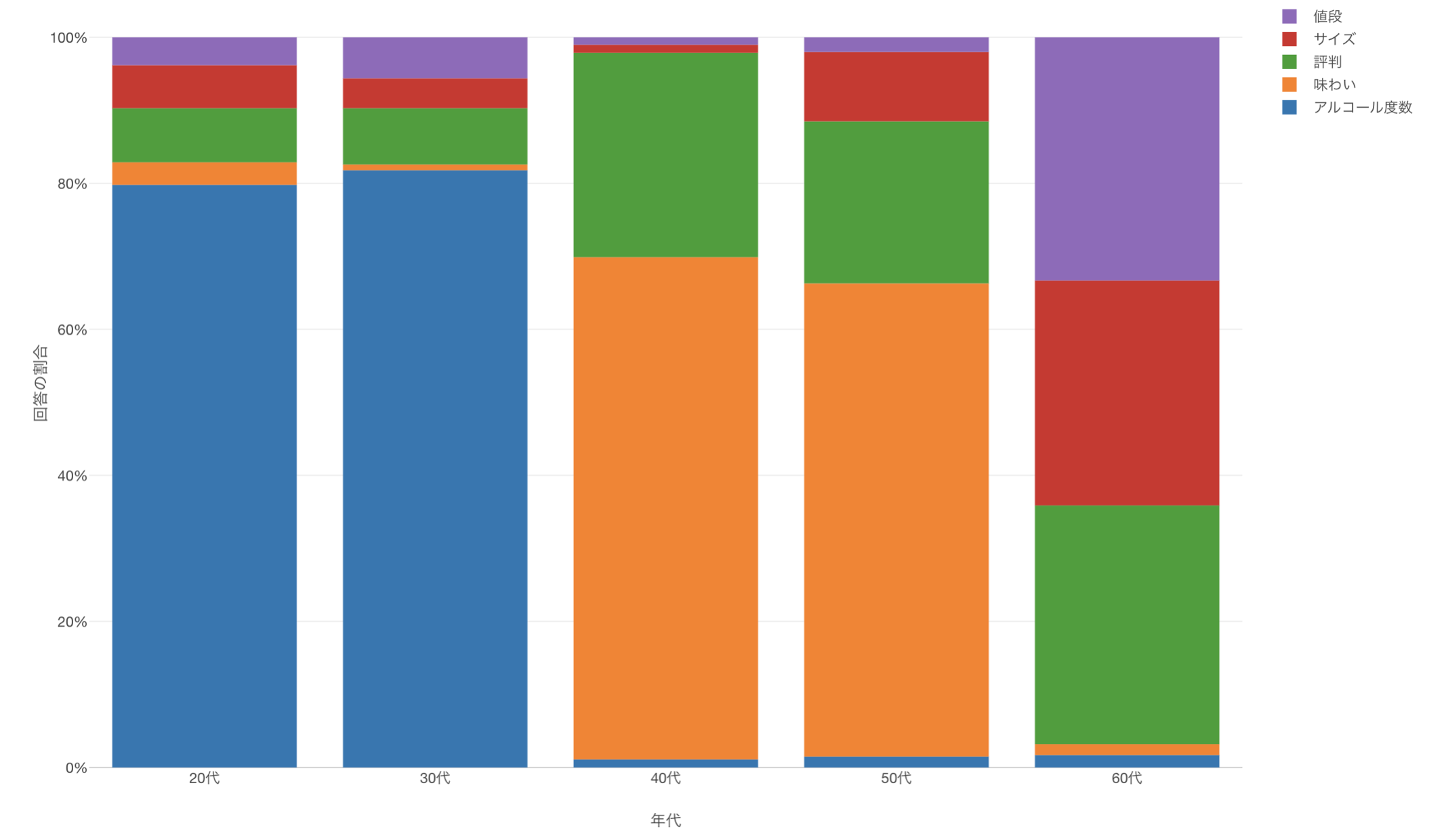
このチャートからは、20代、30代の回答の傾向は他に比べて似ていることや、「アルコール度数」を最も重要に考えていることや、
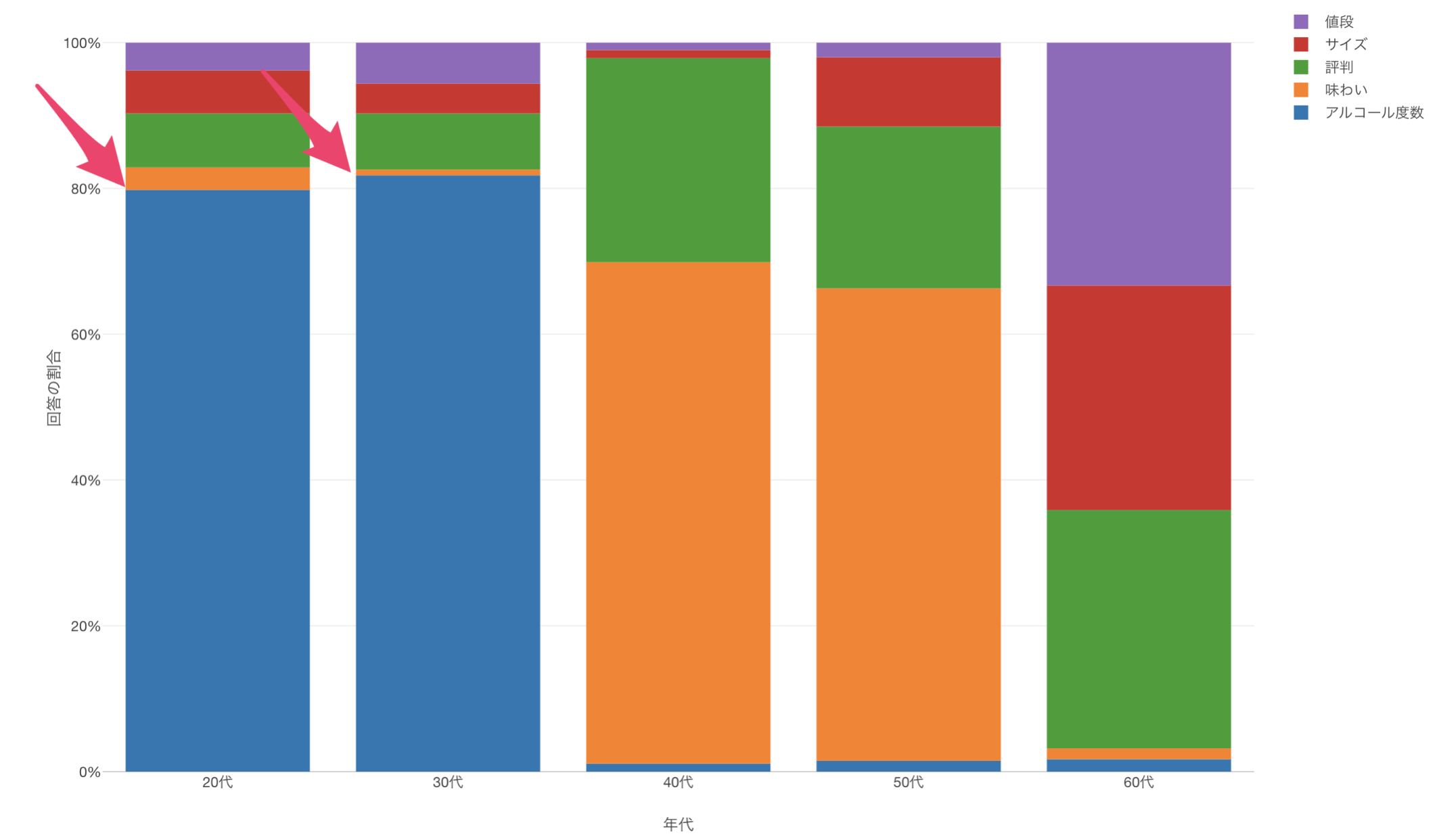
40代、50代の回答の傾向は似ていて、「味わい」を最も重要に考えていることがわかります。
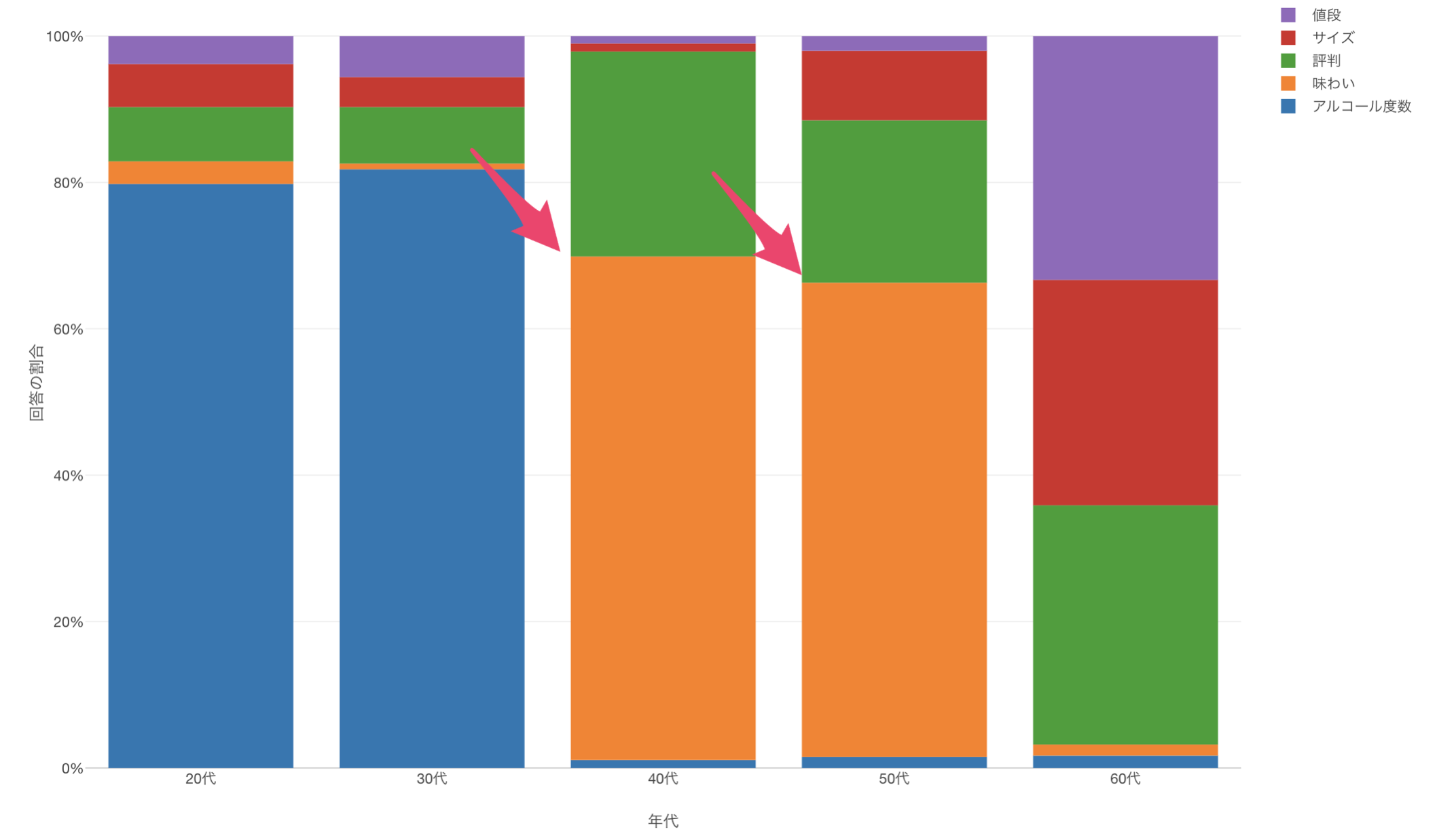
最後に、60代に注目すると他の世代と比べて回答傾向が異なり、「サイズ」や「値段」に対する評価が他の年代に比べて高いことがわかります。
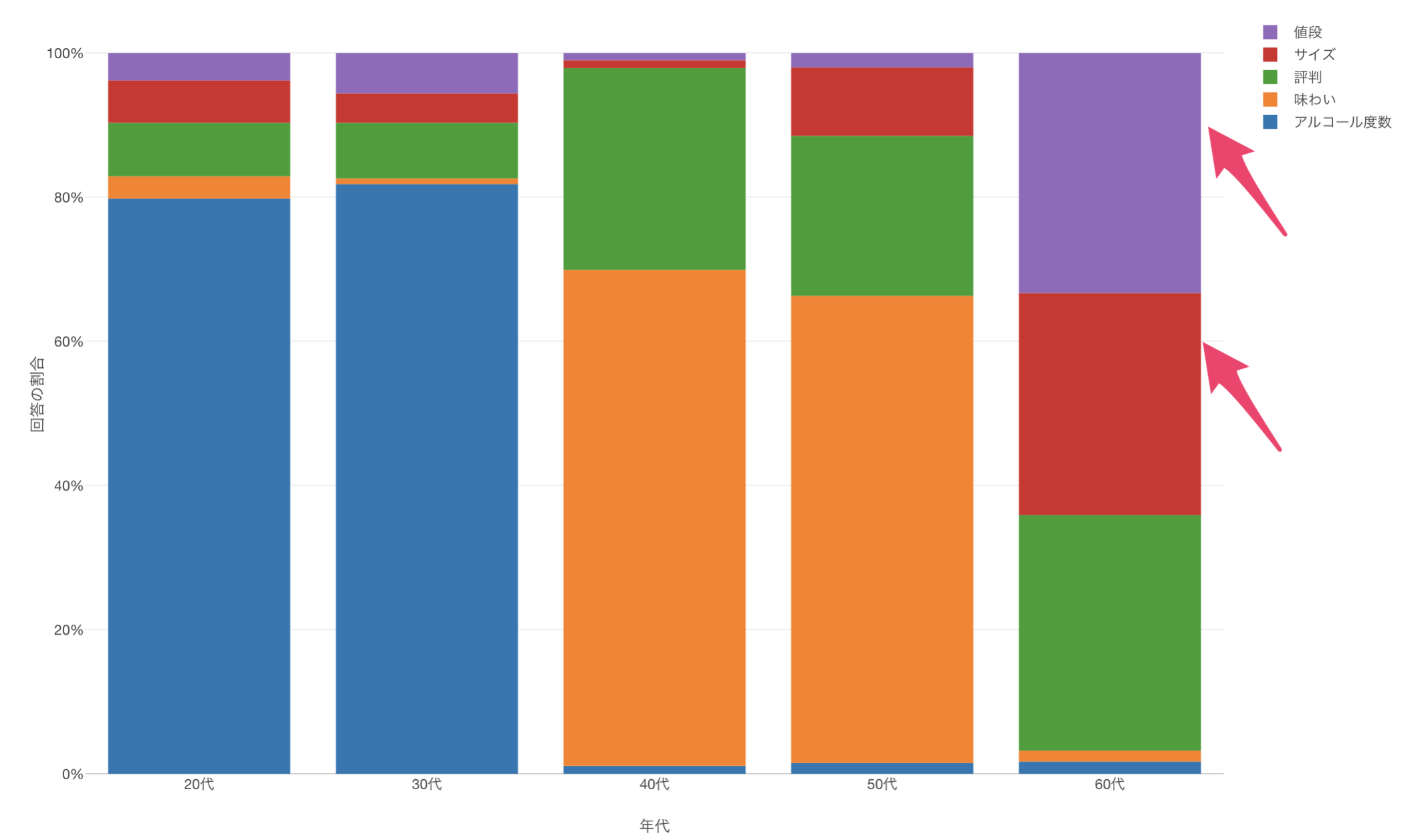
対応(コレスポンデンス)分析を実施すると、こういったことをより直感的に理解できるようになります。
必要なデータの形式
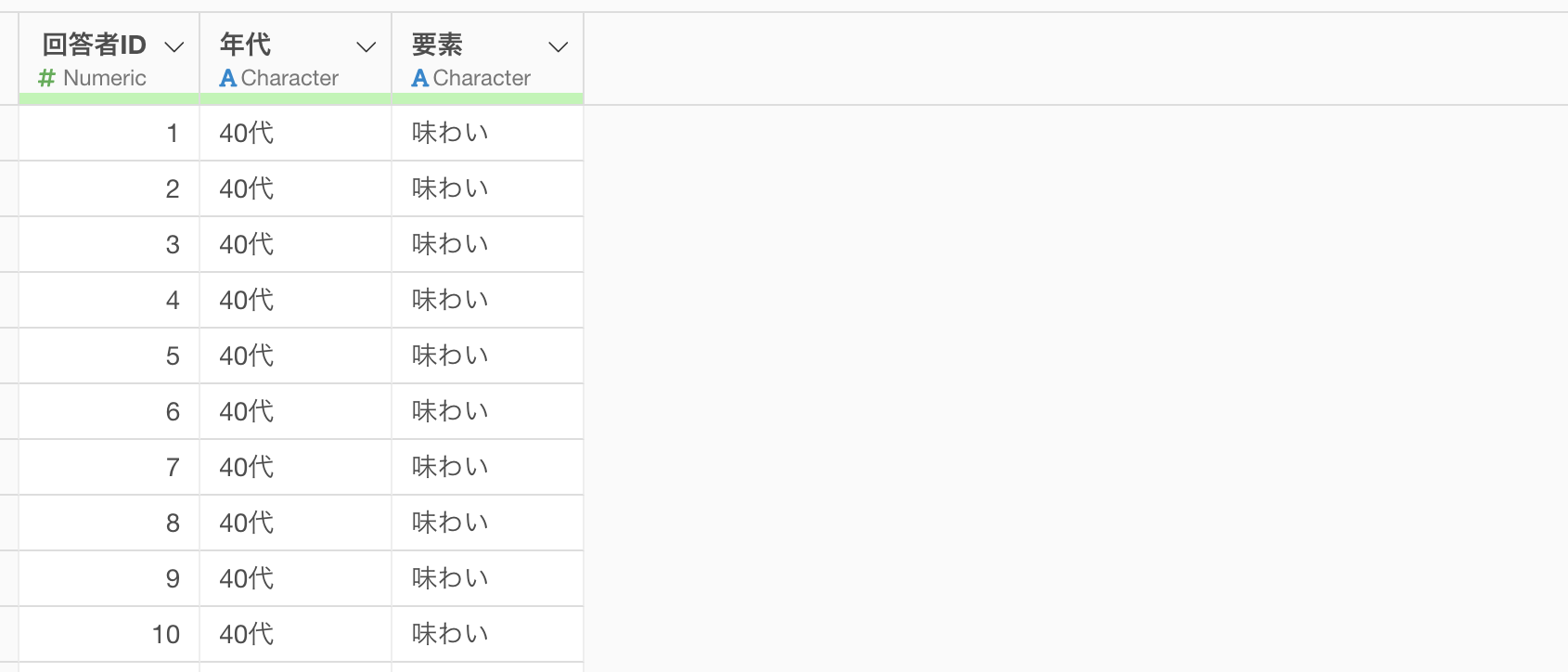
対応分析(コレスポンデンス分析)には、1行が1人の回答者の1つの事柄(例: 製品・サービス・会社など)への評価となっているようなデータが必要です。また変数には文字列型のデータ型のみを選択できます。
今回はサンプルデータとして、「ビールを購入するときに最も重要に考えること」に関するアンケートのデータを使用します。このデータは、1行が1人の回答者を表していて、列には年代や最も重要に考える要素があります。
対応(コレスポンデンス)分析を実行する
アナリティクスビューを開き、タイプに「対応分析」を選択します。
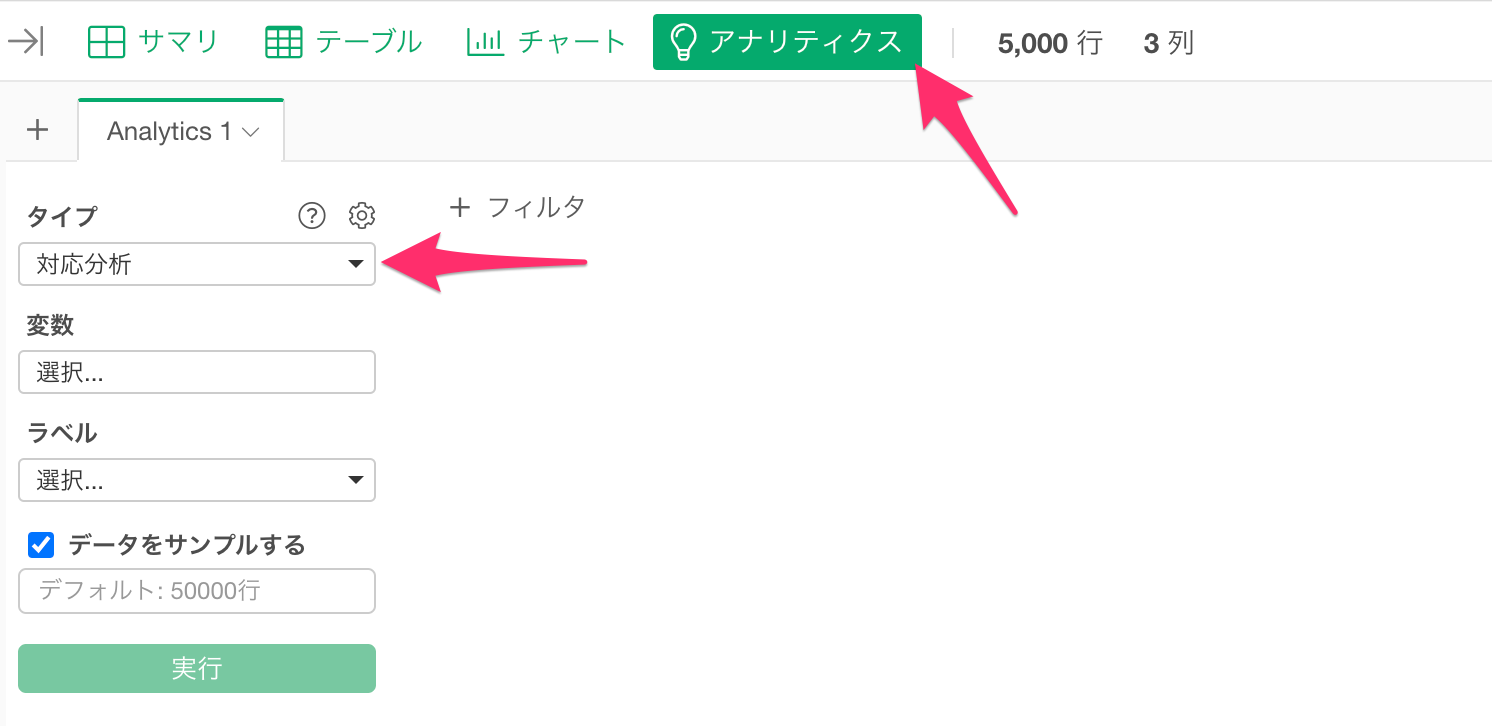
変数の列をクリックして、対応分析に使用する列を選択します。シフトキーを押すことで、複数の列を一気に選択できます。
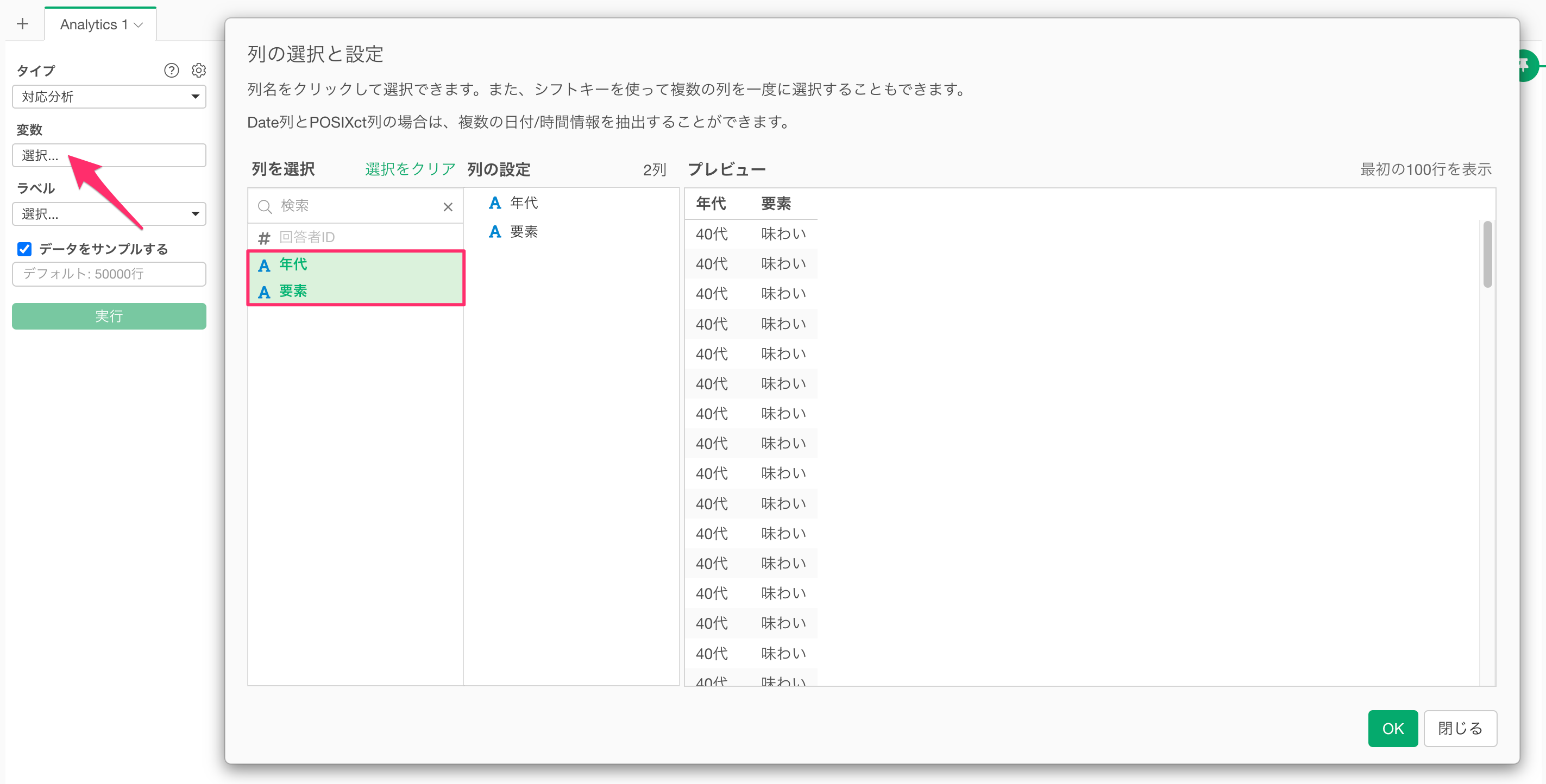
列の指定が完了したら実行することで、対応(コレスポンデンス)分析の結果が表示されます。
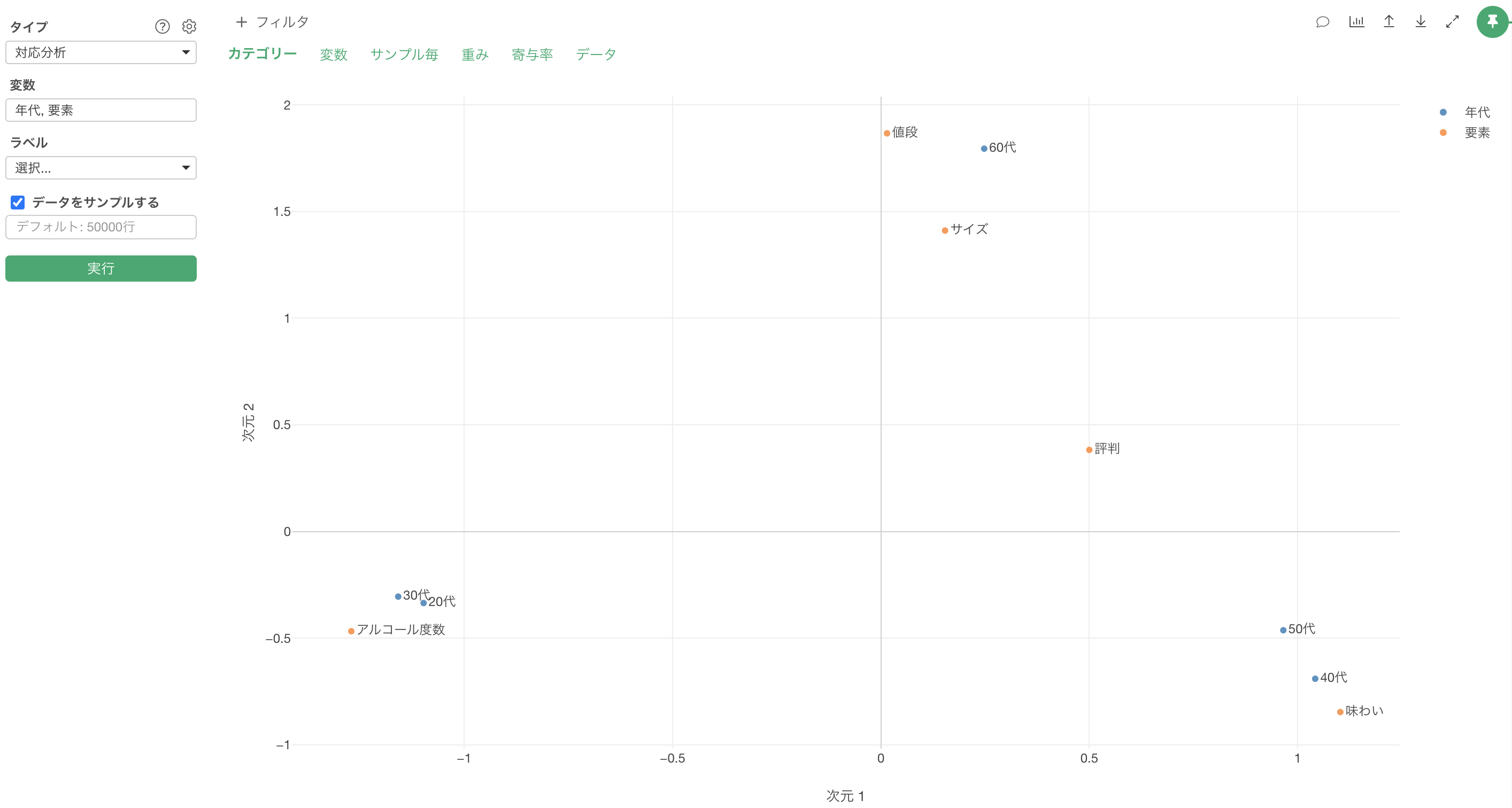
結果の解釈
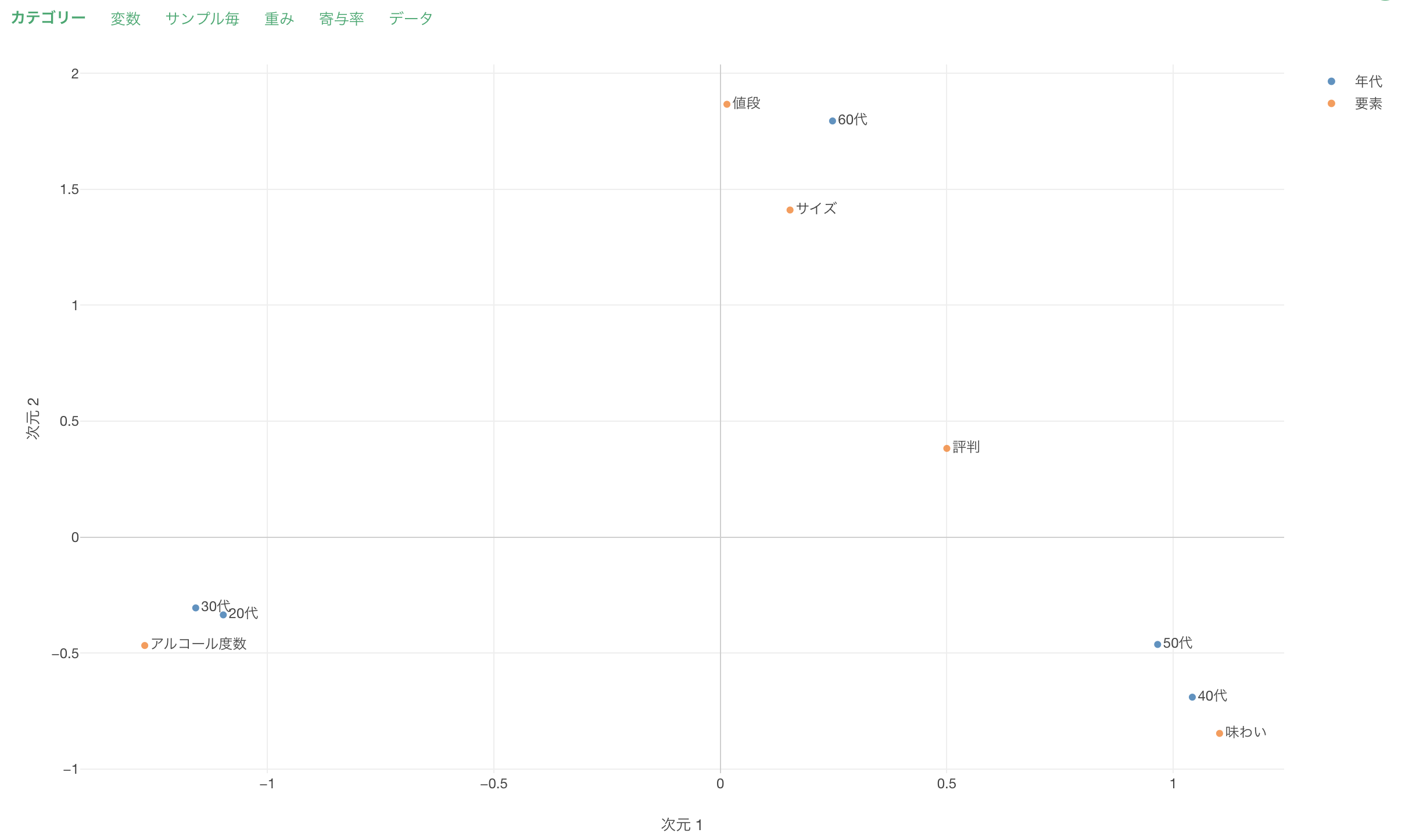
カテゴリー
カテゴリーのタブでは、2つの次元(次元1、次元2)によって、各変数のカテゴリの関係を可視化したチャートが表示されます。
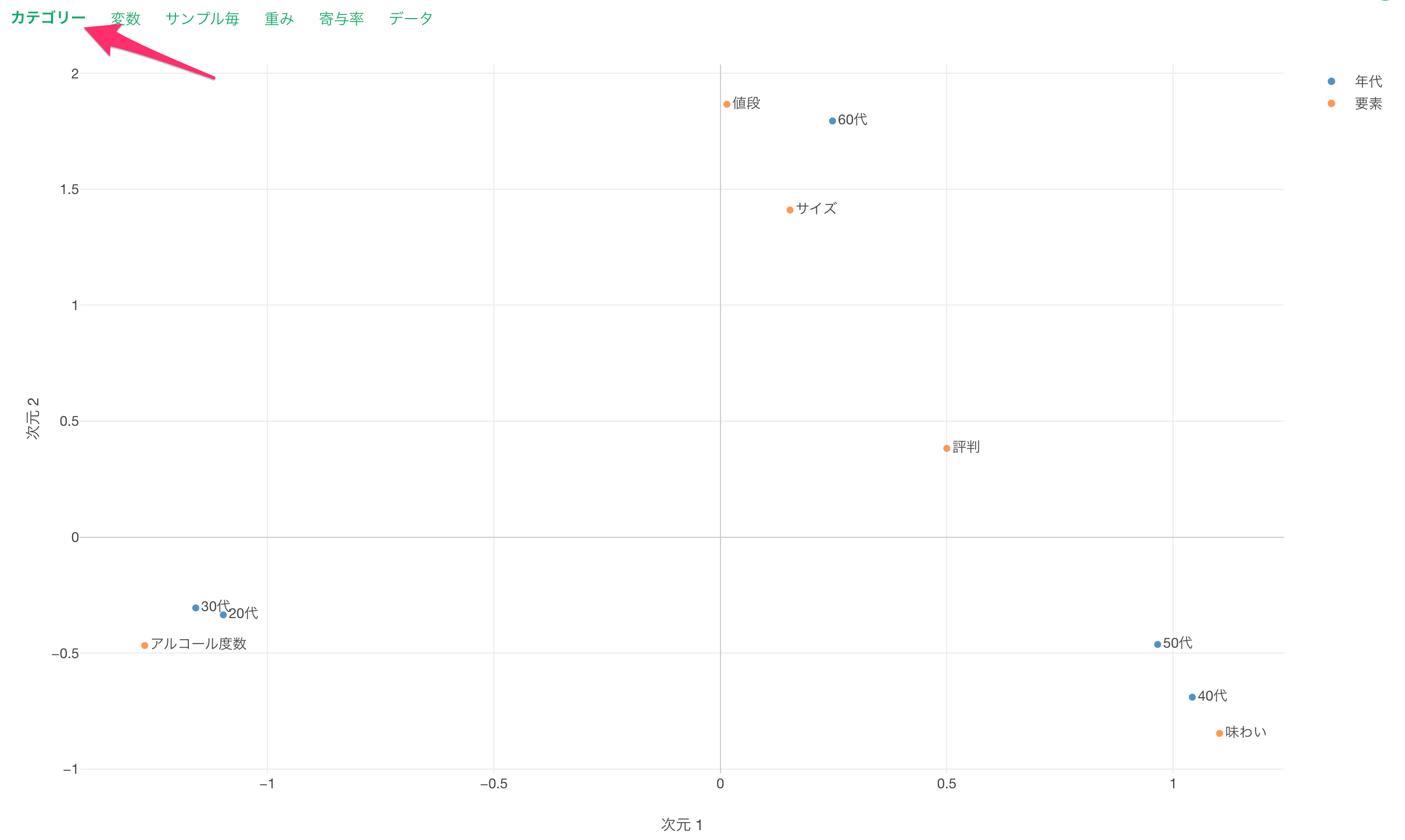
点は1つ1つの変数のカテゴリーを表しており、色はそれぞれの変数(列)を表しています。
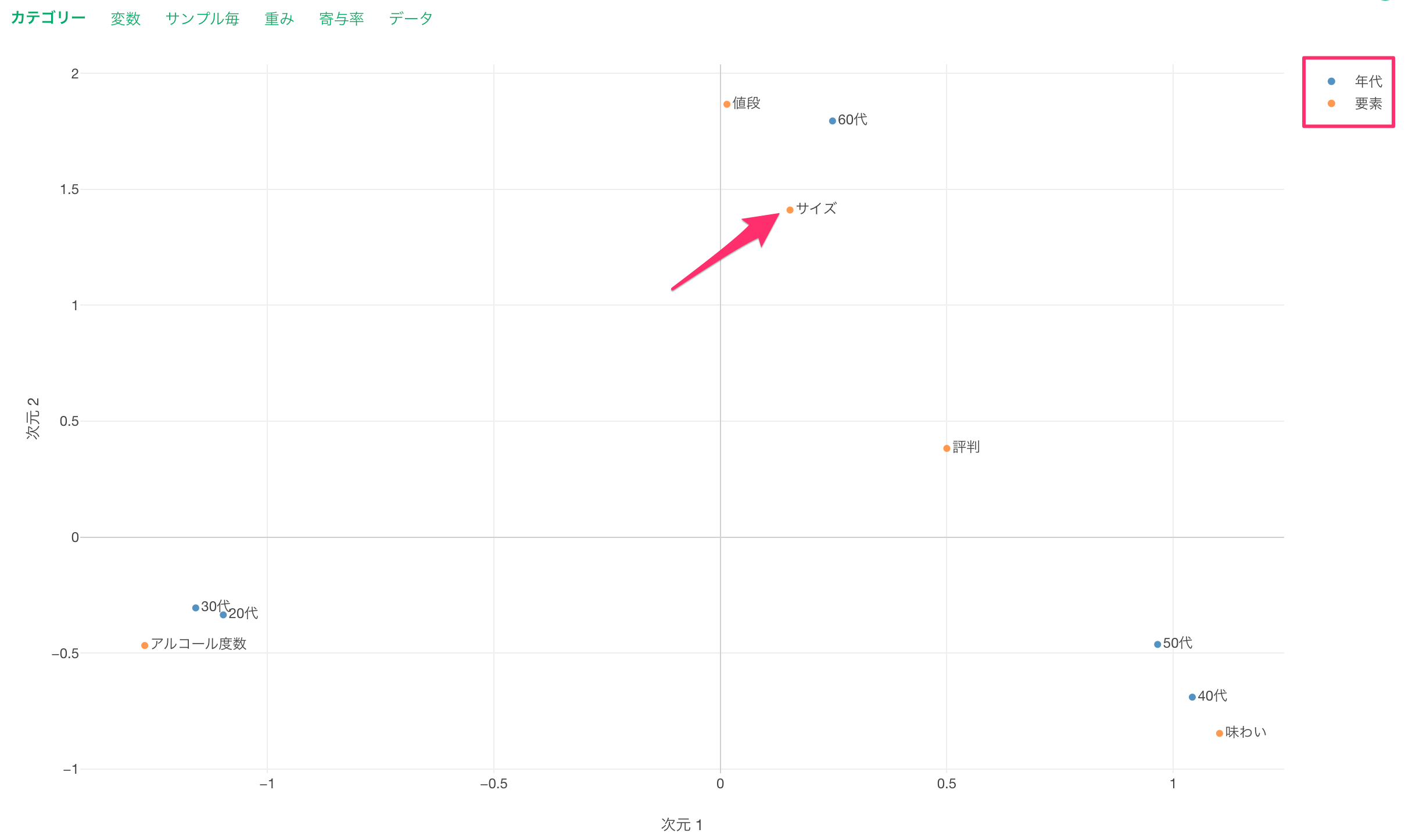
例えば、青色の「年代」に注目すると、20代、30代の回答の傾向は似ているため近いことが分かります。
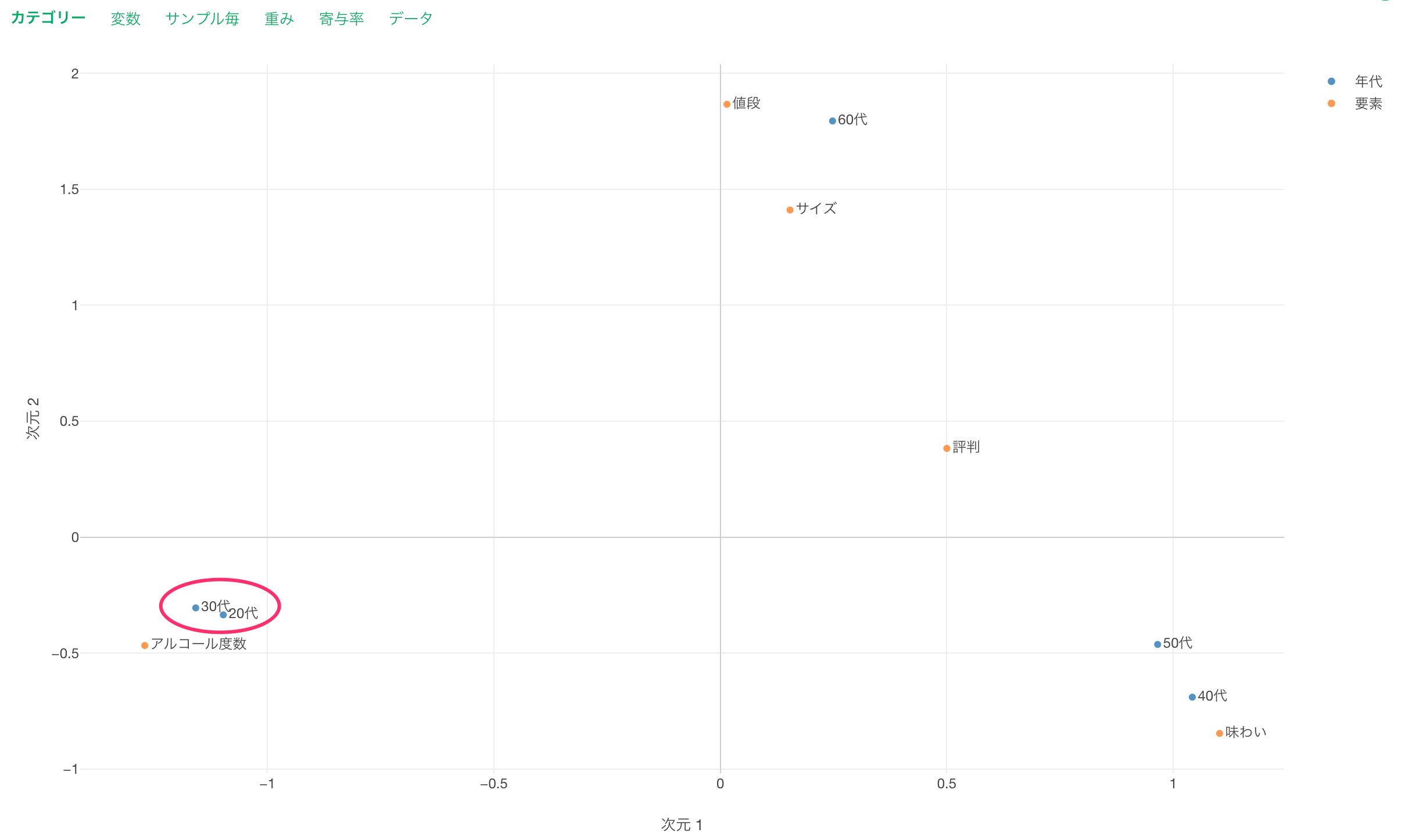
また「年代」と「要素」の関係に注目すると、「20代と30代」は「アルコール度数」の近くに表示されているため、これらの世代の特徴は「アルコール度数」を重要と考えている(アルコール度数と回答する人の割合が大きい)ことがわかります。
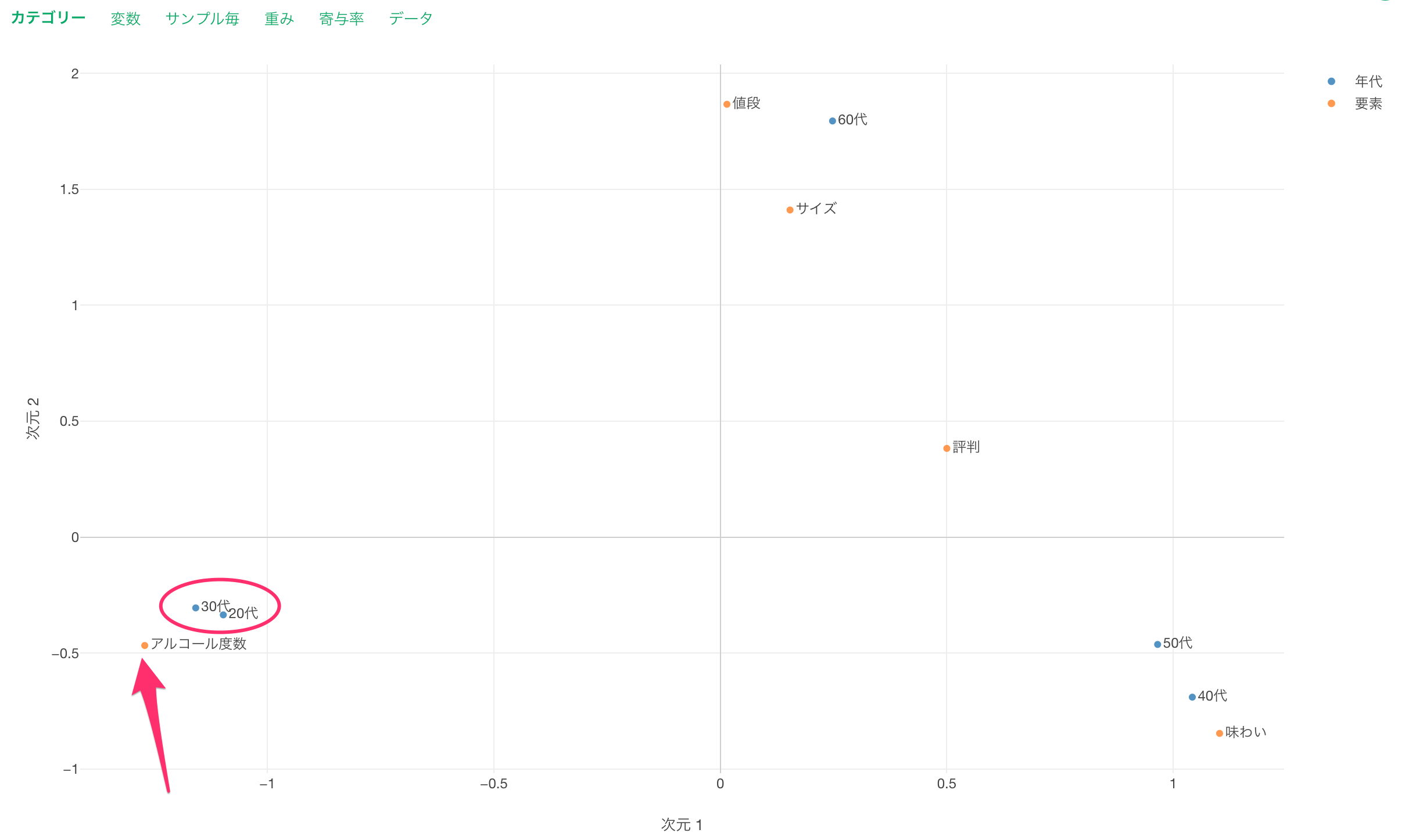
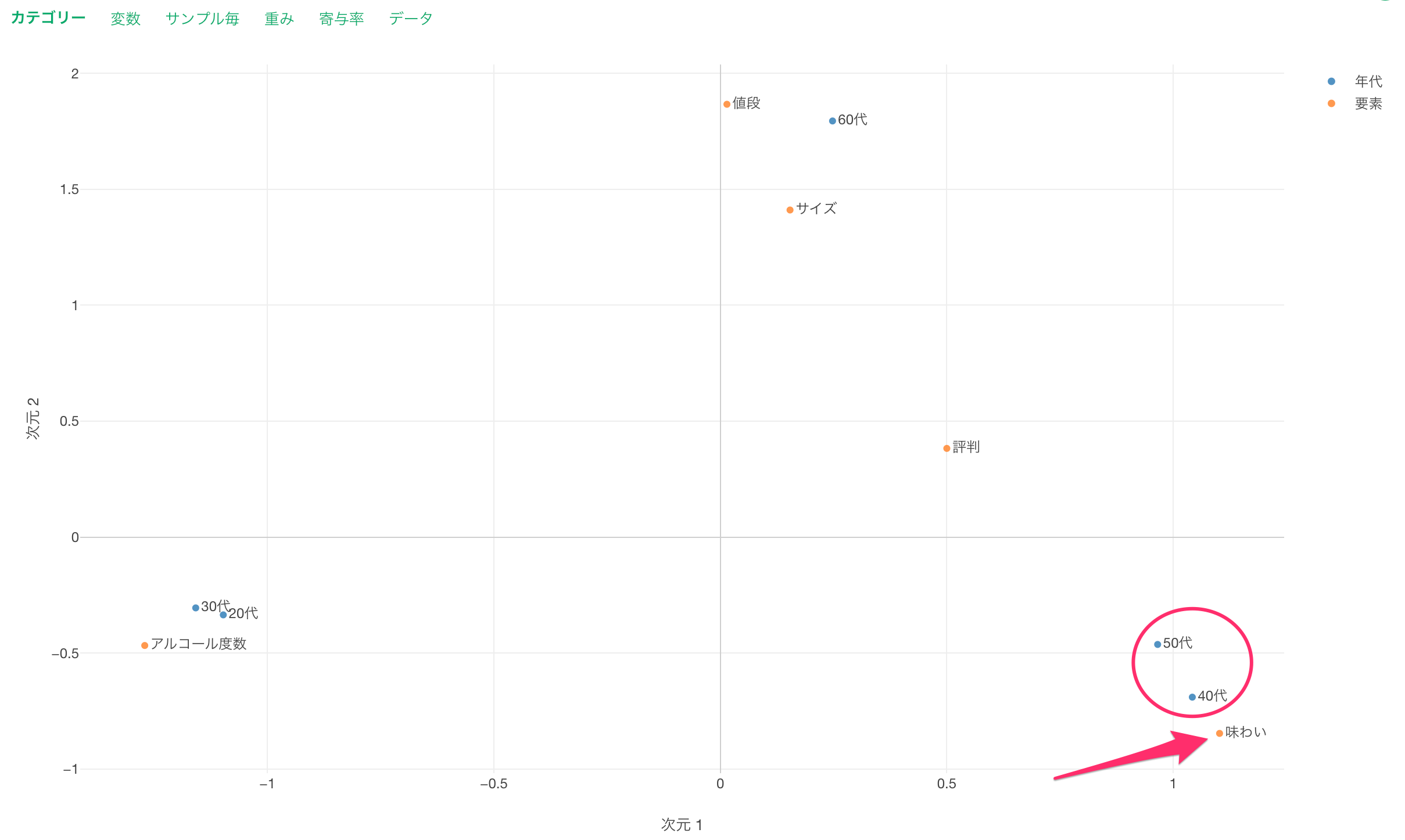
続いて「40代」や「50代」に注目すると両者の回答の傾向は似ているため近くに表示されています。この世代の特徴は「味わい」を重要と考えていることであるため、「味わい」の近くに表示されるわけです。
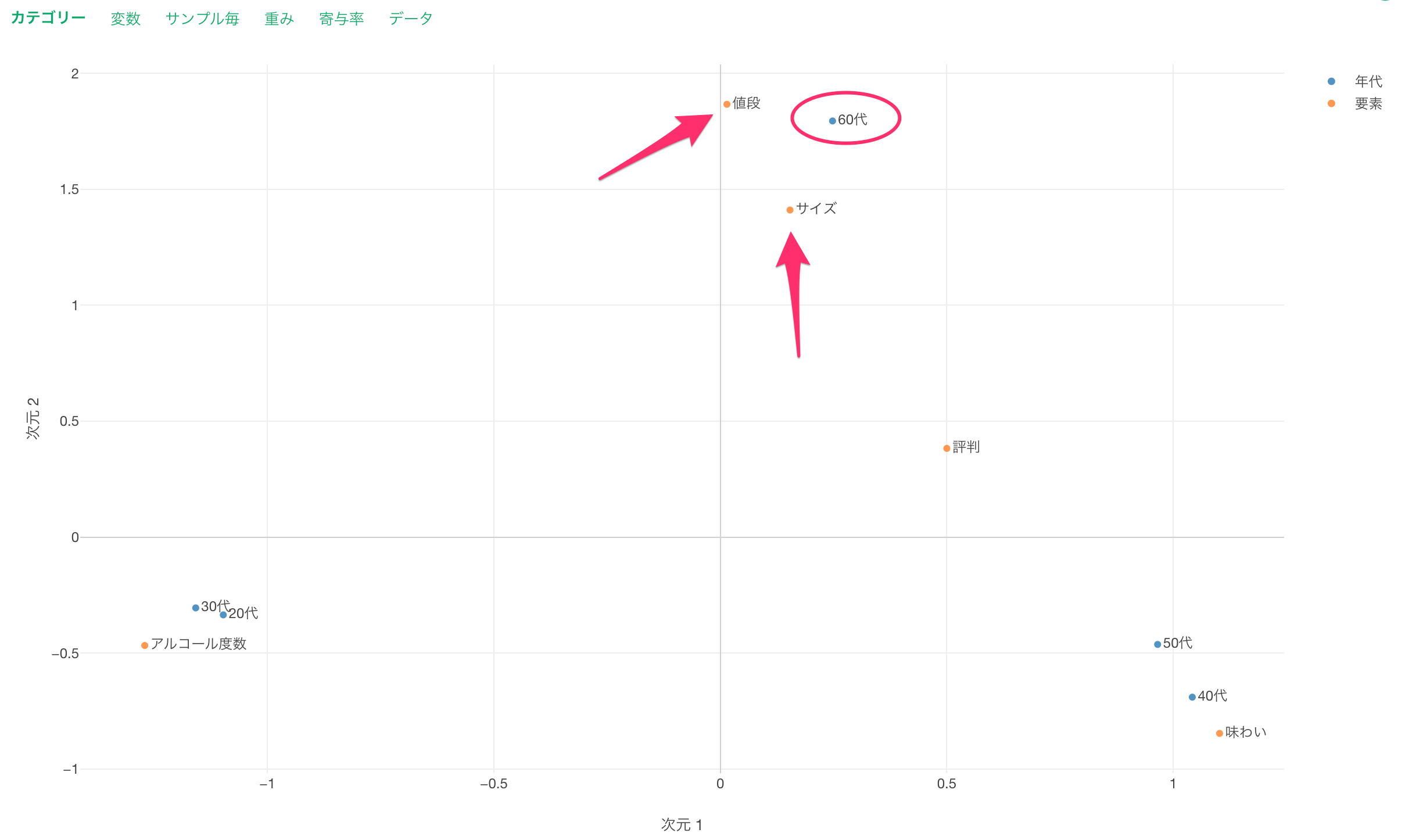
最後に60代に他と比べて回答傾向が異なるため他の世代とは離れて表示されています。この世代の特徴は「サイズ」と「値段」を重要と考えていることであるため、近くに表示されるわけです。
寄与率
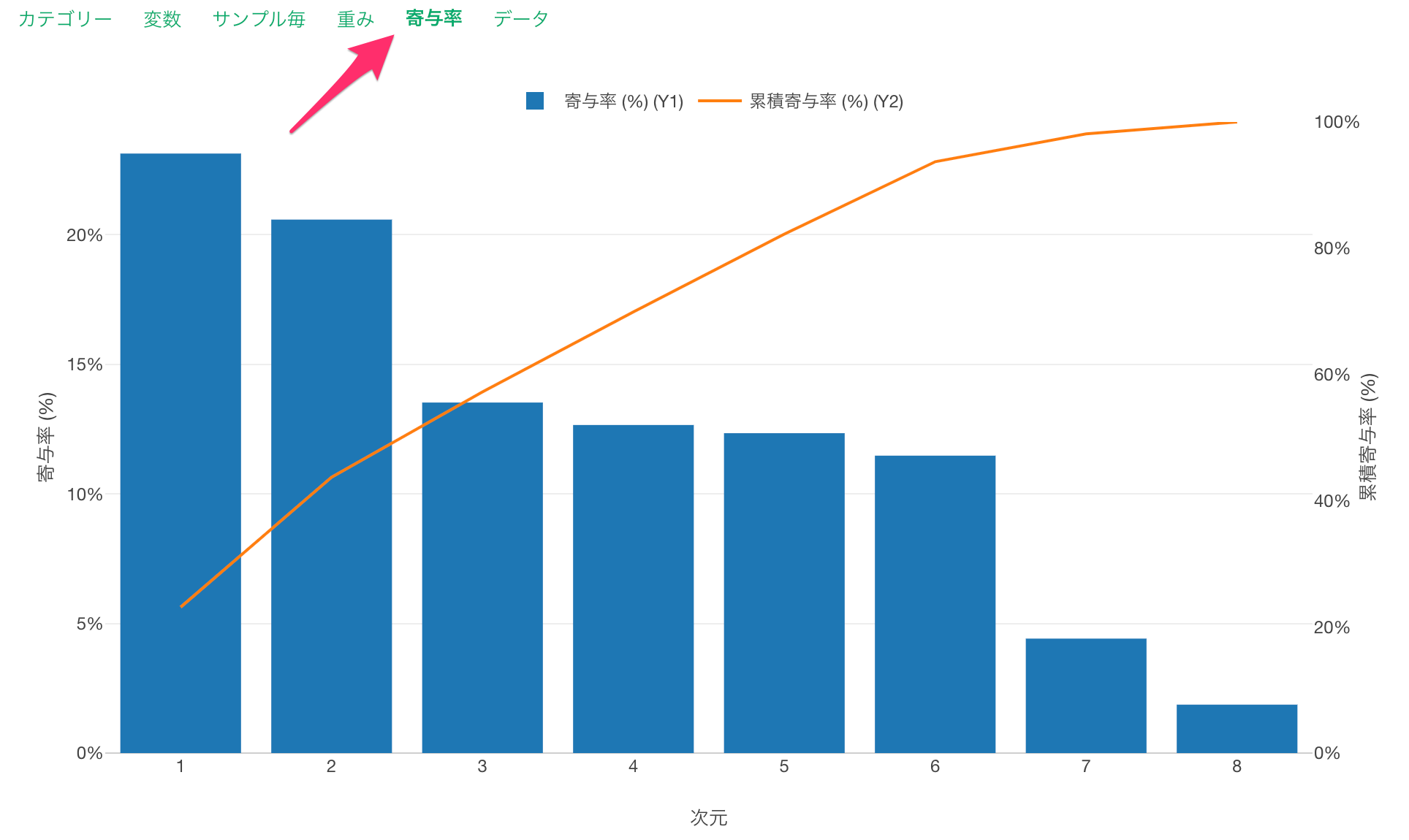
寄与率のタブでは、対応分析で作られた軸によって元データの情報量(ばらつき)をどれだけ表現できるかを確認できます。
寄与率はそれぞれの次元での情報量の表現できている割合で、累積寄与率はそれらの寄与率を足し上げて行った時にどれだけ表現できているのかがわかります。
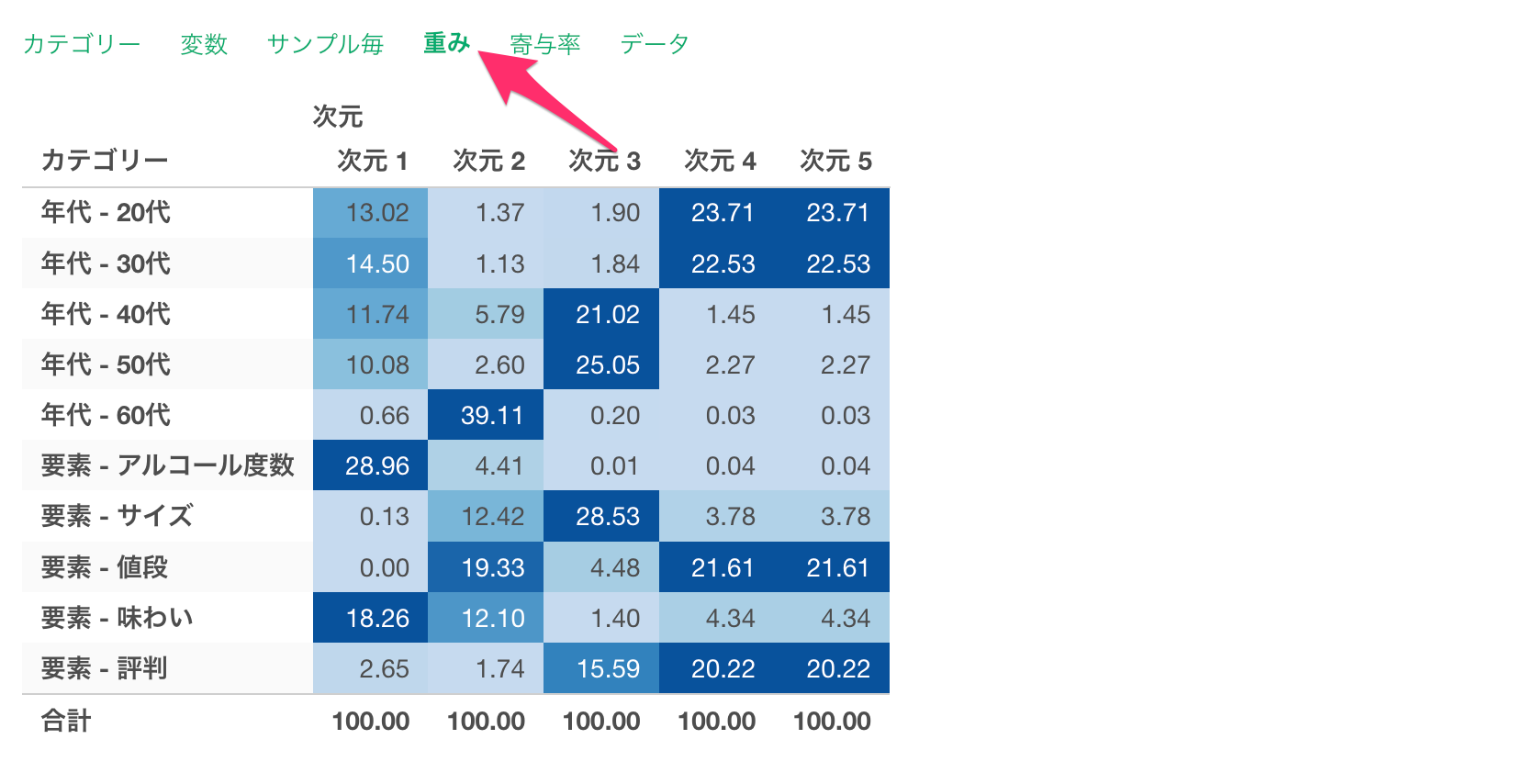
重み
重みのタブでは、次元ごとの各変数の重み(その次元が変数に与える影響の強さ)が表示されます。重みは0-100の間をとり、各次元のカテゴリーを全て足すと100になります。
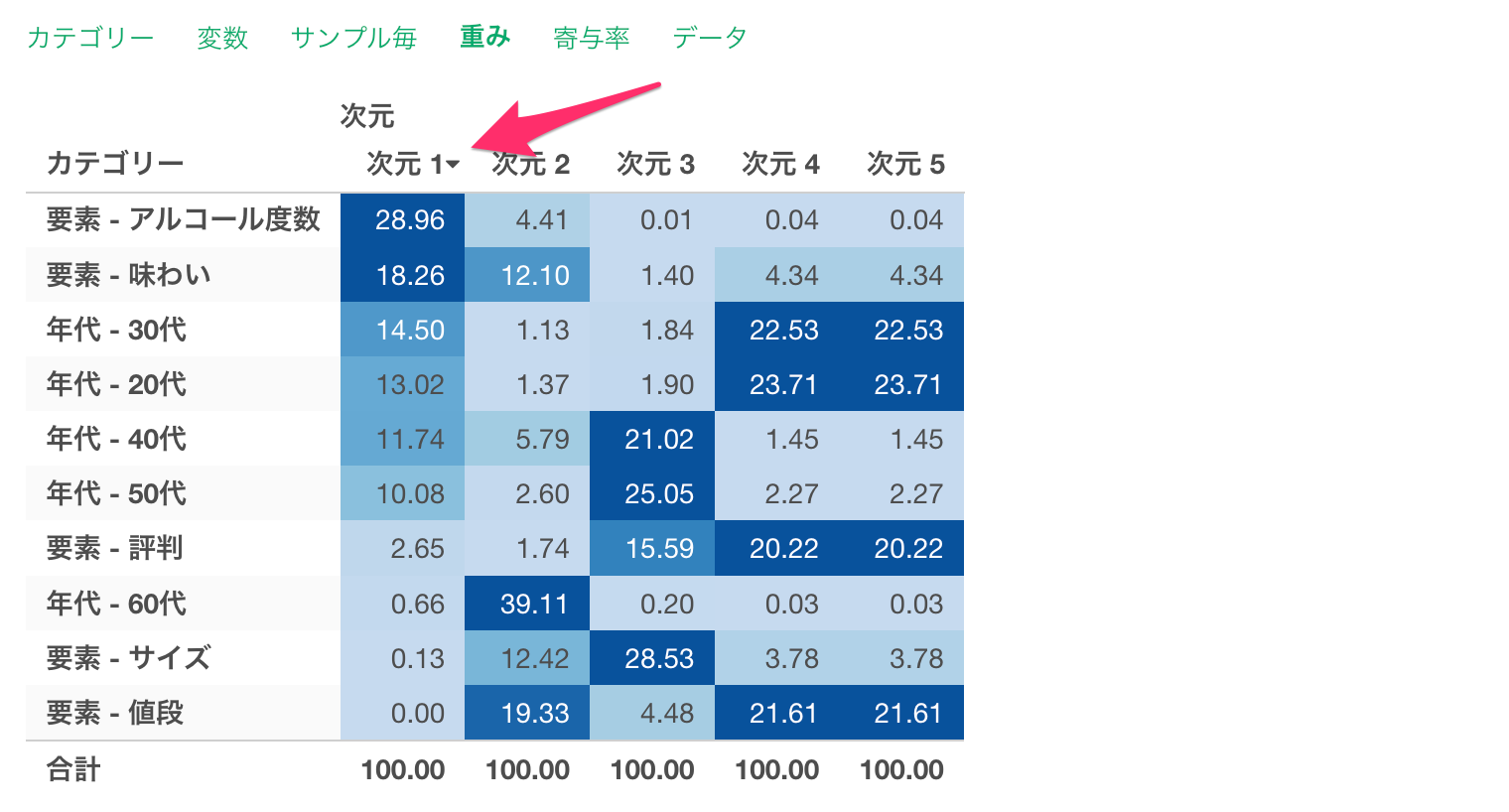
例えば、次元1でソートすると、「アルコール度数」や「味わい」の重みが大きくなっており、これはX軸である次元1において、それらのカテゴリーの特徴をうまく説明できていることがわかります。
対応(コレスポンデンス)分析に関するよくある質問
対応(コレスポンデンス)分析について、よくある質問とその答えをこちらにまとめました。
Q: 対応(コレスポンデンス)分析のカテゴリータブで表示される、各カテゴリーの座標はどのように計算されていますか?
各カテゴリーの座標は、カテゴリ間の距離を元に決まっています。詳細は、こちらのオンラインセミナーで紹介していますので、ご参考ください。