
クロンバックのアルファ(α)係数の求め方
クロンバックのアルファを使うことでアンケートの複数の質問間の内的整合性(Internal Consistency)に対する信頼を検証することができます。
ところで、内的整合性とは何でしょうか?
**内的整合性** とはあなたのアンケートの質問があなたが計測したいと思っていることを計測できているかということです。
例えば3つの質問があって、そのうちの2つの質問に対して高い値の答えを出している人は、残りの1つの質問に対しても高い値を出しているはずだとします。
そこで、この3つの質問の回答データに対してクロンバックのアルファを求め、アルファの値が高ければこれら3つの質問の答えは整合が取れているということで、このアンケートの回答への信頼が高まります。逆にアルファの値が低ければ、これらの質問に対する答えのデータへの信頼は低くなります。
クロンバックのアルファは内部的には質問または変数どうしの相関を計算しています。
アルファの値は0から1で高ければ高いほどアンケートに対する信頼が高くなります。
以下はアルファ係数の解釈におけるガイドラインです。
| クロンバックのアルファ係数 | 内的整合性 |
|---|---|
| 0.9 ≤ α | Excellent |
| 0.8 ≤ α < 0.9 | Good |
| 0.7 ≤ α < 0.8 | Acceptable |
| 0.6 ≤ α < 0.7 | Questionable |
| 0.5 ≤ α < 0.6 | Poor |
| α < 0.5 | Unacceptable |
クロンバックのアルファ係数をノートを使って求める
Exploratoryの中でクロンバックのアルファ係数を求めるにあたり、最も簡単な方法はノートの中で数行ほどのRのスクリプトを書くことです。
そしてRの’psych'というパッケージの中にある’alpha’という関数を使うとアルファ係数を求めることができます。
ExploratoryはRの実行環境の上で動いているため、どんなRの関数でも、その関数を含むパッケージがインストールされている限り、実行することができます。
幸いなことに’psych’というパッケージが、Exploratoryのインストールとともにすでにインストールされているため、いきなり使い始めることができます。
こちらがサンプルのスクリプトです。
library(psych)
data = Beer_Survey %>% select(COST, SIZE)
alpha(data)
一行目は’psych’というパッケージを呼び出し、プロジェクトの中で'psych'の中にある関数を使えるようにしています。
二行目は「Beer_Survey」というデータフレームを呼び出し、さらにその中から「COST」と「SIZE」という列のみを選択しています。
もしあなたのデータフレームの名前にスペースや日本語が入っている場合は「バックティック」で囲んであげて下さい。
library(psych)
data = `ビール 調査` %>% select(`コスト`, `サイズ`)
alpha(data)その結果を「data」という別のデータフレームとして作っています。この「data」という名前は何でも構いません。
三行目は、前段で用意された「data」という「COST」と「SIZE」の2列からなるデータフレームを'alpha'という関数に渡し、アルファ係数を含む結果を返します。
あとはこの上記のスクリプトを「R Script」のブロックに貼り付けるだけです。
以下のように、’R Script’ タブの下に書き込み(貼り付け)ます。
結果を確認するために’Preview’をクリックしてみて下さい。
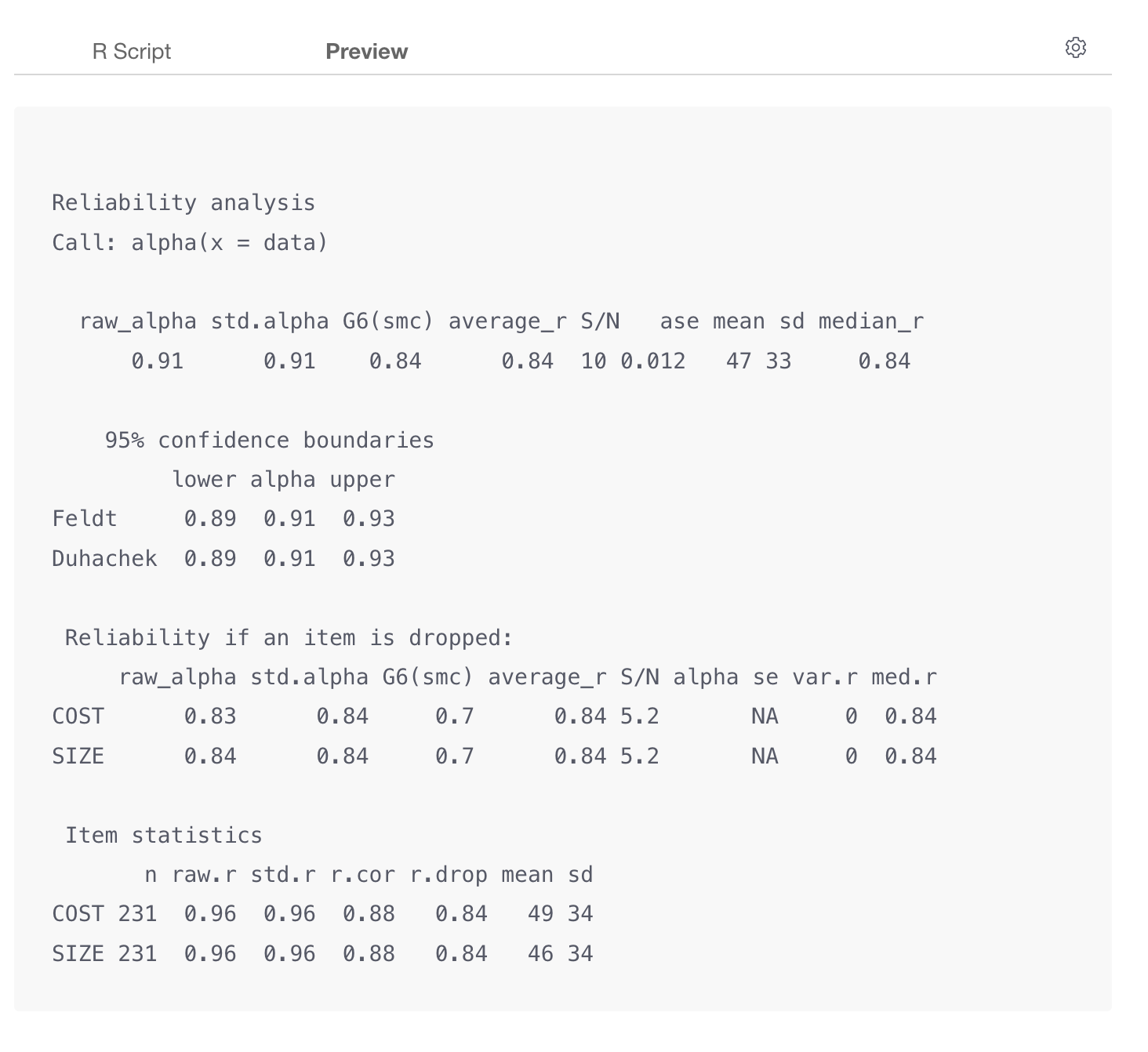
すると結果が出力されます。この場合はアルファ係数は0.91で高い数値になっているため、この2つの質問の内部的整合性は高いと言えます。
プレビュー、またはパブリッシュ
ノート・エディターの上部にある「プレビュー」ボタンを押すか、または「パブリッシュ」ボタンを押してサーバーにパブリッシュすると、ノートの中のRスクリプトのブロックは出力結果だけを表示します。
以下は、実際にこのノートに上記のスクリプトをRスクリプトのブロックに貼り付けた結果です。
Reliability analysis
Call: alpha(x = data)
raw_alpha std.alpha G6(smc) average_r S/N ase mean sd median_r
0.91 0.91 0.84 0.84 10 0.012 47 33 0.84
95% confidence boundaries
lower alpha upper
Feldt 0.89 0.91 0.93
Duhachek 0.89 0.91 0.93
Reliability if an item is dropped:
raw_alpha std.alpha G6(smc) average_r S/N alpha se var.r med.r
COST 0.83 0.84 0.7 0.84 5.2 NA 0 0.84
SIZE 0.84 0.84 0.7 0.84 5.2 NA 0 0.84
Item statistics
n raw.r std.r r.cor r.drop mean sd
COST 231 0.96 0.96 0.88 0.84 49 34
SIZE 231 0.96 0.96 0.88 0.84 46 34