特定の列の欠損値を最頻値で埋める方法
特定の列の欠損値を最頻値などで埋めたい時には、「欠損値の加工」にある「欠損値を最頻値で埋める」といった機能を使うことで簡単に埋めることができます。この機能を使うと、欠損値を埋める際に便利なimpute_naといった関数を使用することとなります。
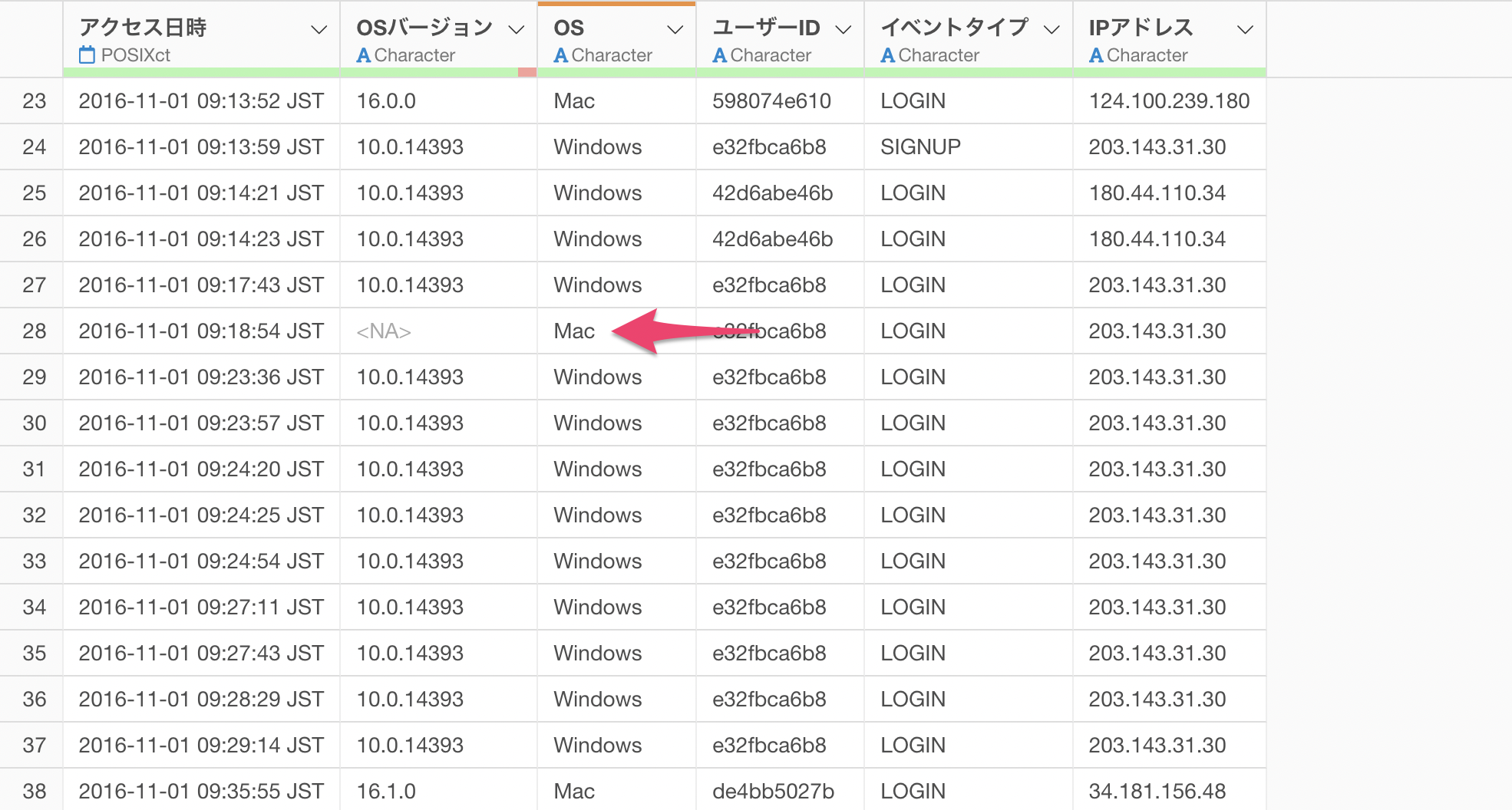
例えば、以下のようにアクセスログのデータがあったとします。
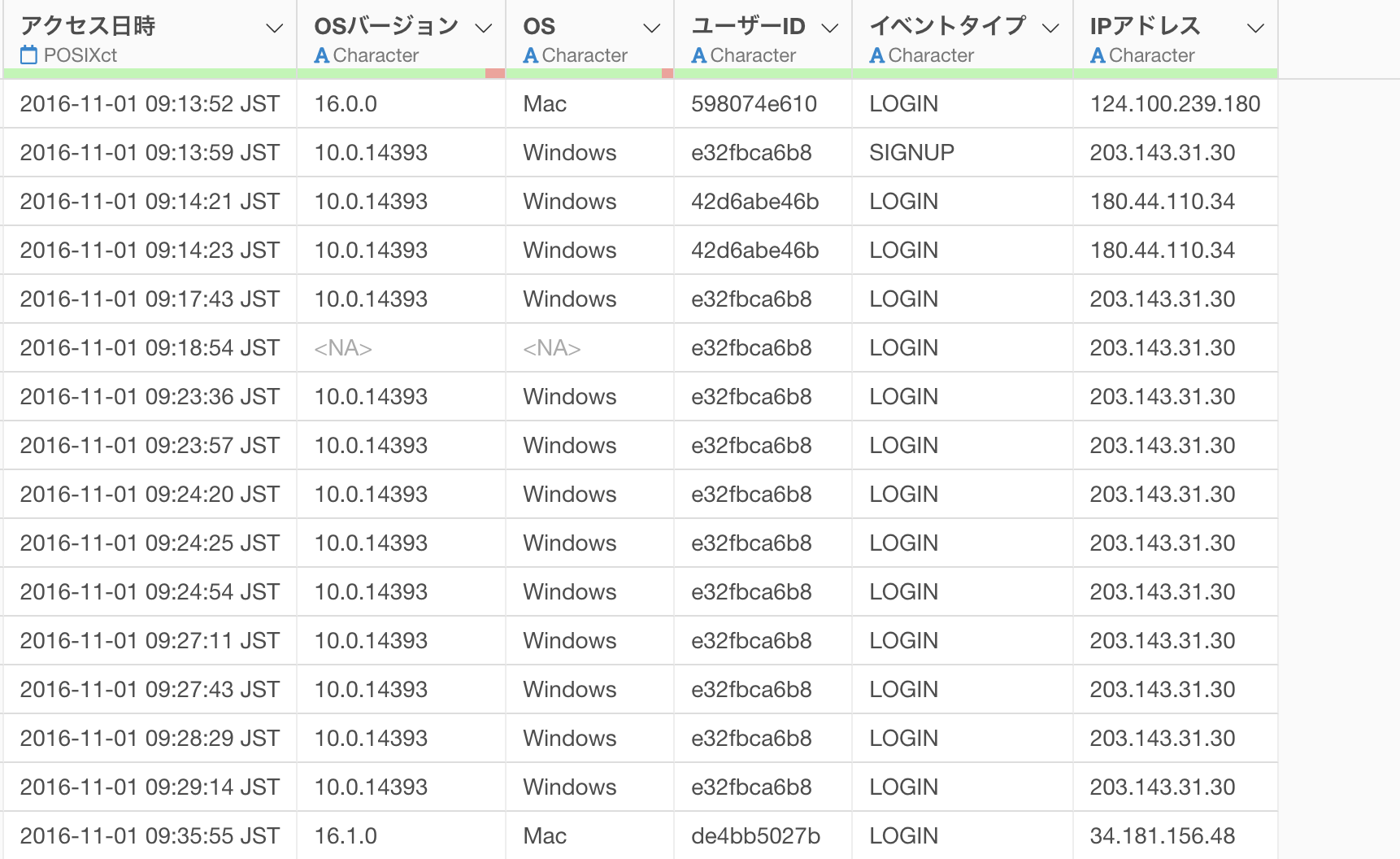
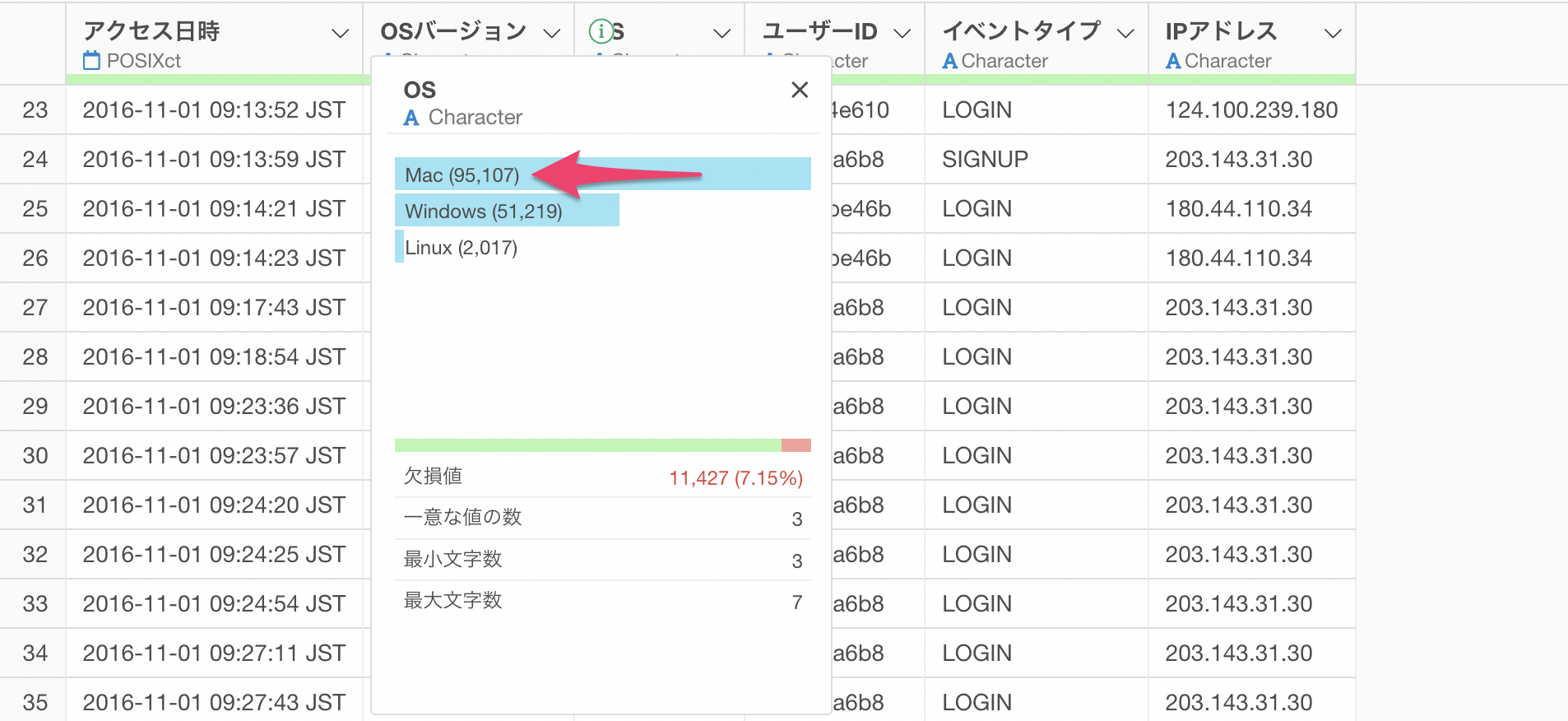
OSの列には欠損値があるため、これをOS列の最頻値(最も出現する値)で埋めたいとします。
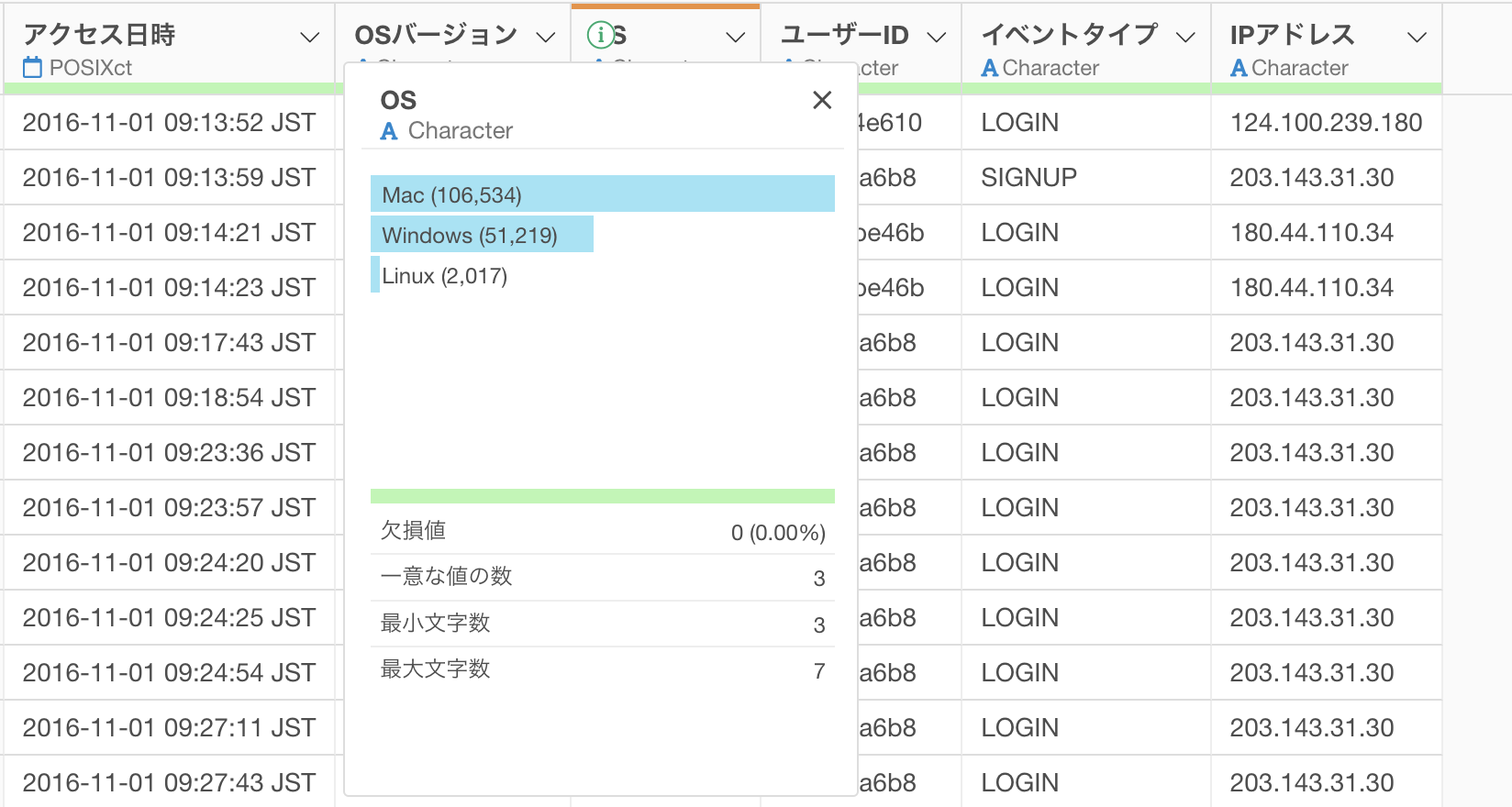
OS列の最頻値はMacであることがわかります。
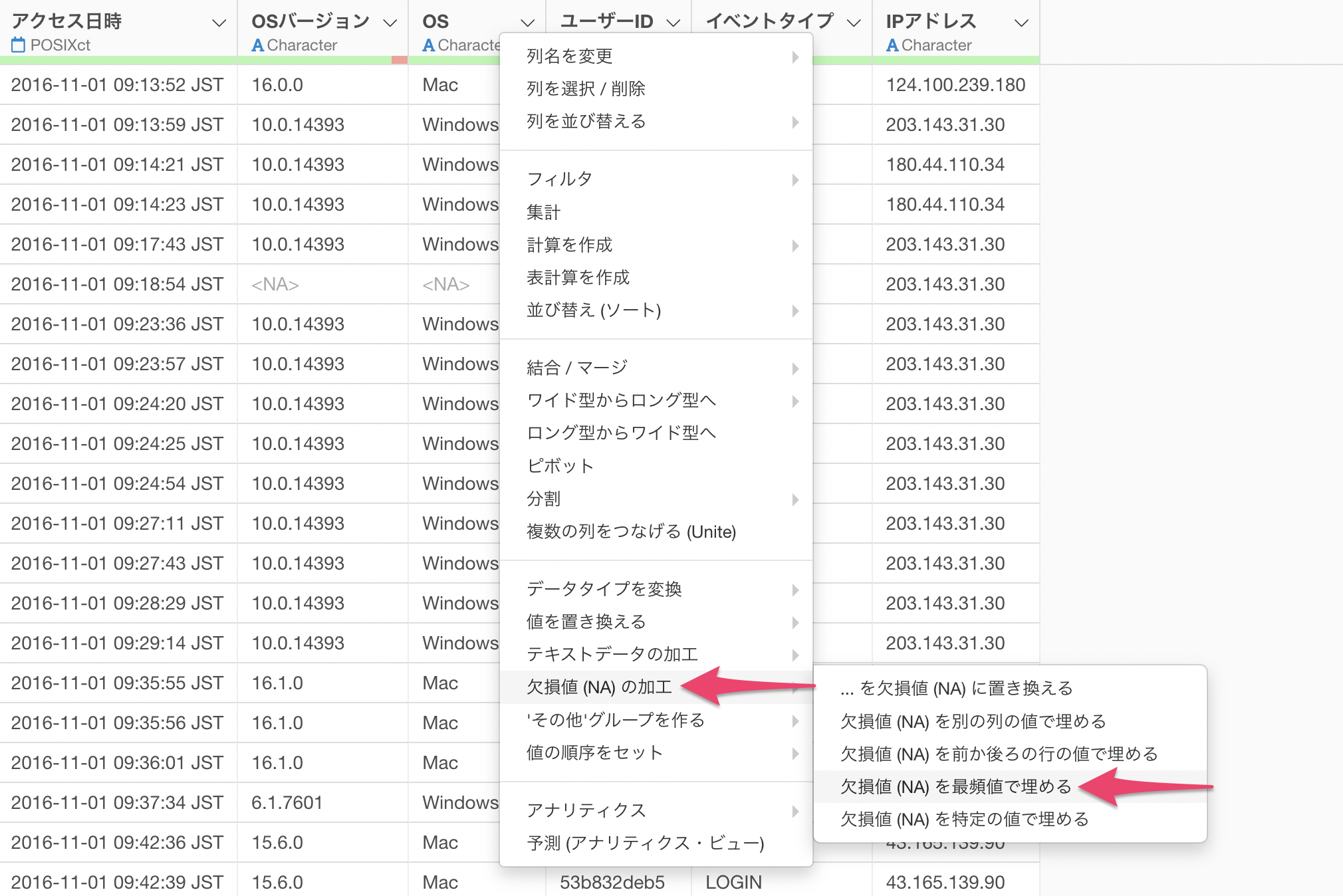
列ヘッダメニューから「欠損値(NA)の加工」の「欠損値(NA)を最頻値で埋める」を選択します。
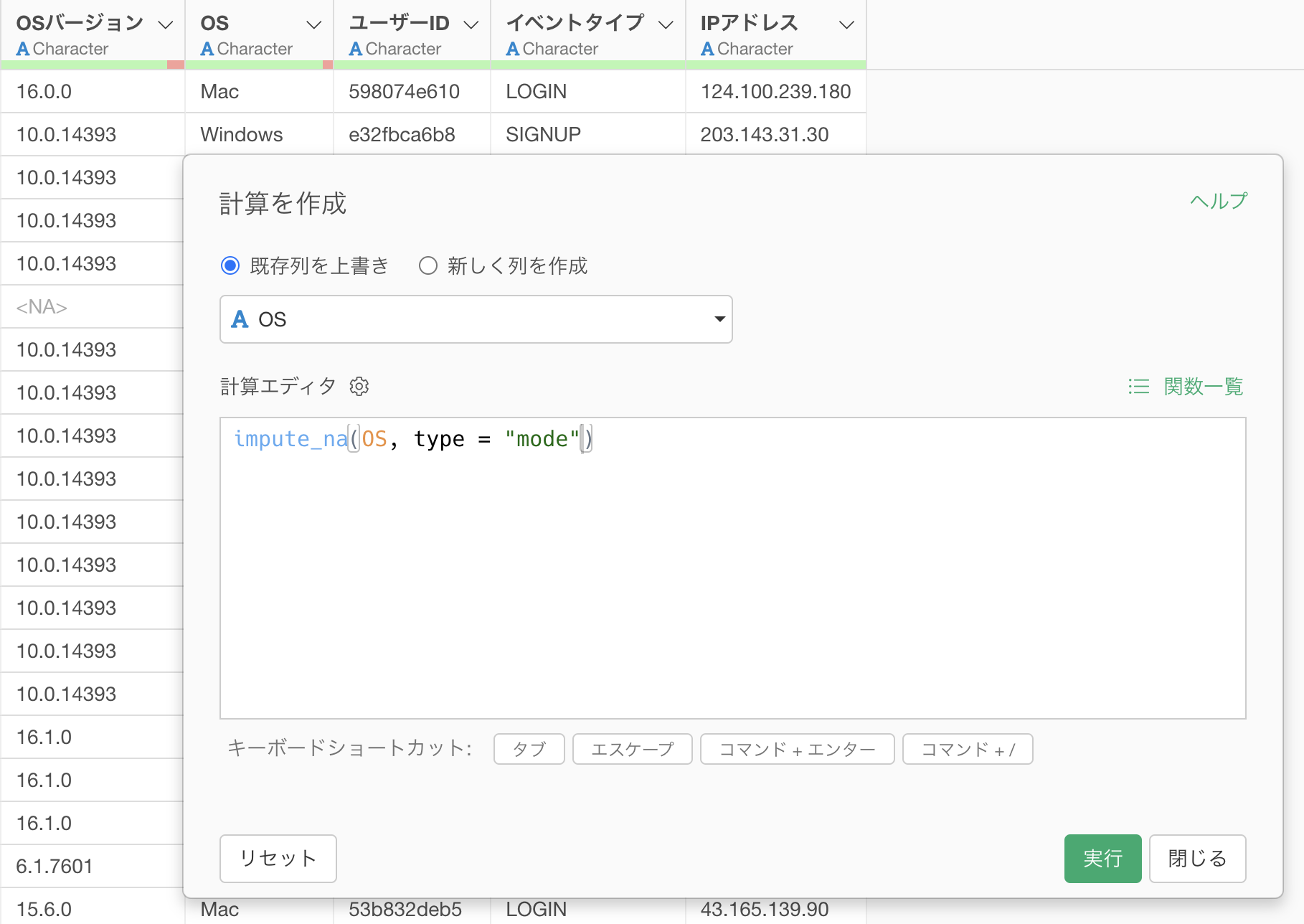
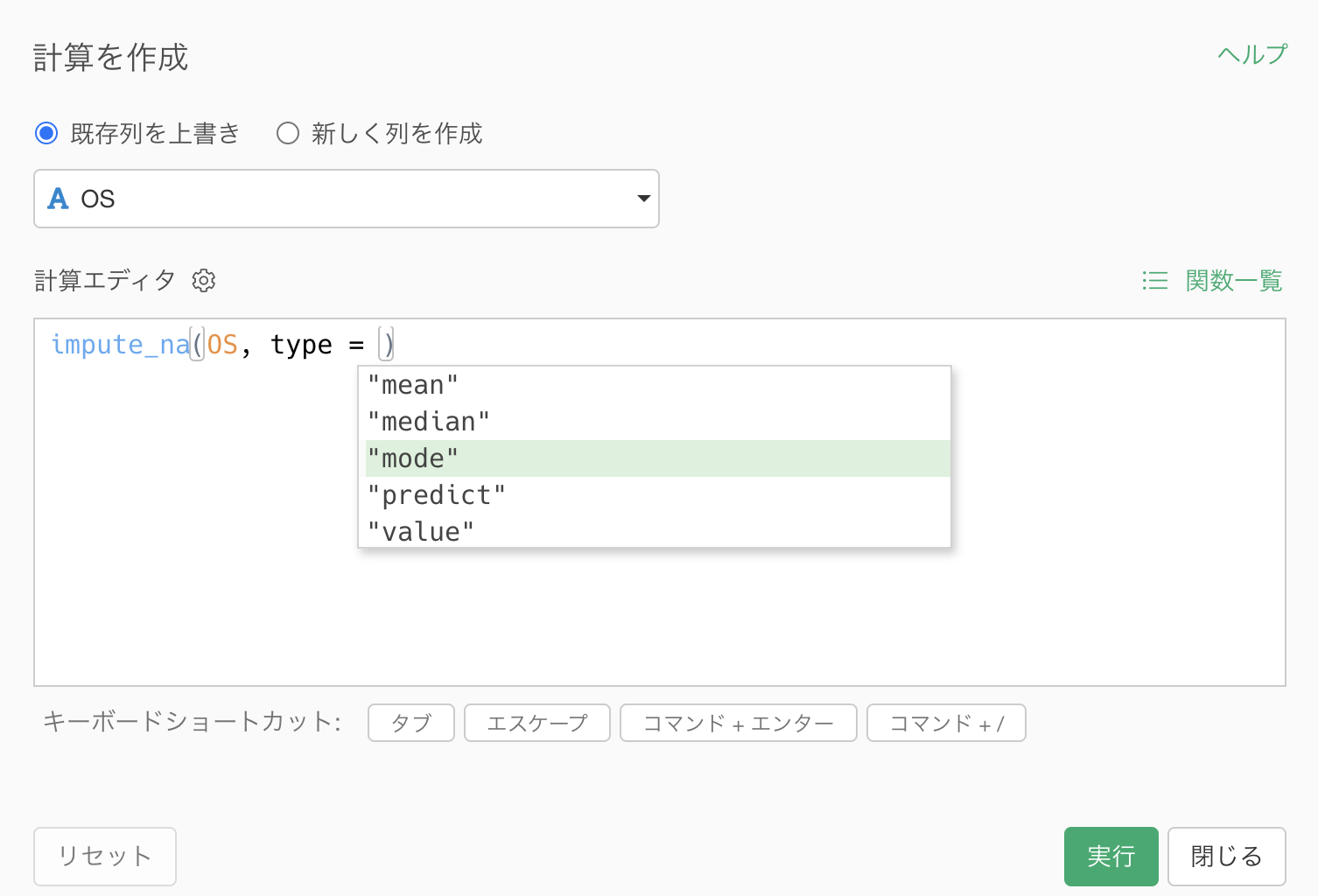
これによって計算を作成のダイアログが表示され、計算エディタの中にはimpute_naといった関数が使われていることがわかります。
typeには”mode”が指定されているため、OS列の欠損値を最頻値で埋める設定になっています。
実行することでOSの列の欠損値を最頻値であるMacで埋めることができました。
サマリ情報を確認してみても、欠損値がなくなりOS列の最頻値であるMacの件数が増えていることが確認できます。
列の欠損値を最頻値で埋める際のRのコード
列の欠損値を最頻値で埋める際のRのコードは以下となります。計算を作成は裏では、mutateといった関数が使われていることとなります。
mutate(OS = impute_na(OS, type = "mode"))impute_na関数の他の欠損値を埋めるオプション
impute_naの関数を使用すると欠損値を様々なタイプで埋めることができます。最頻値による補完はその一つの手法ですが、他にも平均値、中央値、指定値、予測値など複数の補完方法を状況に応じて選択できます。
impute_na関数のシンタックスは以下となっています。
impute_na(<欠損値を埋めたい列>, type = <欠損値を埋めるタイプ>, val = <値または列>, <予測変数の列>)impute_na関数の引数の説明
typeには欠損値を補完方法を設定でき、デフォルトは「平均(mean)」です。以下にリストされているタイプで欠損値を補完することができます。
- “mean” - 平均値
- “median” - 中央値
- “mode” - 最頻値
- “value” - valで指定した値で欠損値を補完する。
- “predict” - 他の列に基づいて予測をした値で欠損値を補完する。
もし、type = valueを指定した場合は、valの引数に欠損値を埋めたい値を直接指定します。予測値を使って欠損値を埋めたい場合は、type = predictを指定した場合は、コンマ(,)区切りで予測変数を指定します。