
データドリブンになろうとするからデータドリブンになれない、目指すはデータインフォームド
今回は、データが中心で人間を不幸にするデータドリブンな文化と、人間中心でデータを道具としてデータインフォームドな文化の違いの話をします。今回の記事を書くにあたって、「Becoming Data Driven, From First Principles」(リンク)を大きく参考にさせてもらっています。
データドリブンという言葉は日本でもだいぶ浸透していますね。
私はふだんアメリカに住んでいるのですが、仕事の関係でたまに日本に行きます。そのタイミングでExploratoryのお客様の方たちとお話をさせていただくのですが、そのさい「データドリブン」になりたいが、うまくいかないという話をよく耳にします。
ここで質問ですが、みなさんはなぜ「データドリブン」になりたいんでしょうか?
こんな質問をすると、今さら当たり前のことを聞くのはやめてよ、
と言われるかもしれません。
今となってはどんなビジネスでもデータドリブンになるべきだというのは当たり前の話になっていますし、企業の内部でも上に行けば行くほど、「データドリブンなビジネスにトランスフォームする!」と言わざるを得ないというのが現状でしょう。
しかし、それでは「データドリブンなビジネス」とはいったいどういうことなのでしょうか。
おそらく多くの人たちはもっと単純に「データを見ることは良い」というかんじで、「民主主義は良い」という感覚と同じようにどこかふわっとしたかんじでデータドリブンになるべきだと思い込んでいるのではないでしょうか。
ここで一歩下がって別の角度から考えてみましょう。
そもそもデータを使う目的とは何だと思いますか?
先に答えを言ってしまうと、データを使う目的は知識の獲得です。
ここで言う知識とは、あなたのビジネスにおける因果関係、つまり何らかの行動を起こせばある結果がもたらされるという因果関係を説明する理論やモデルのことです。
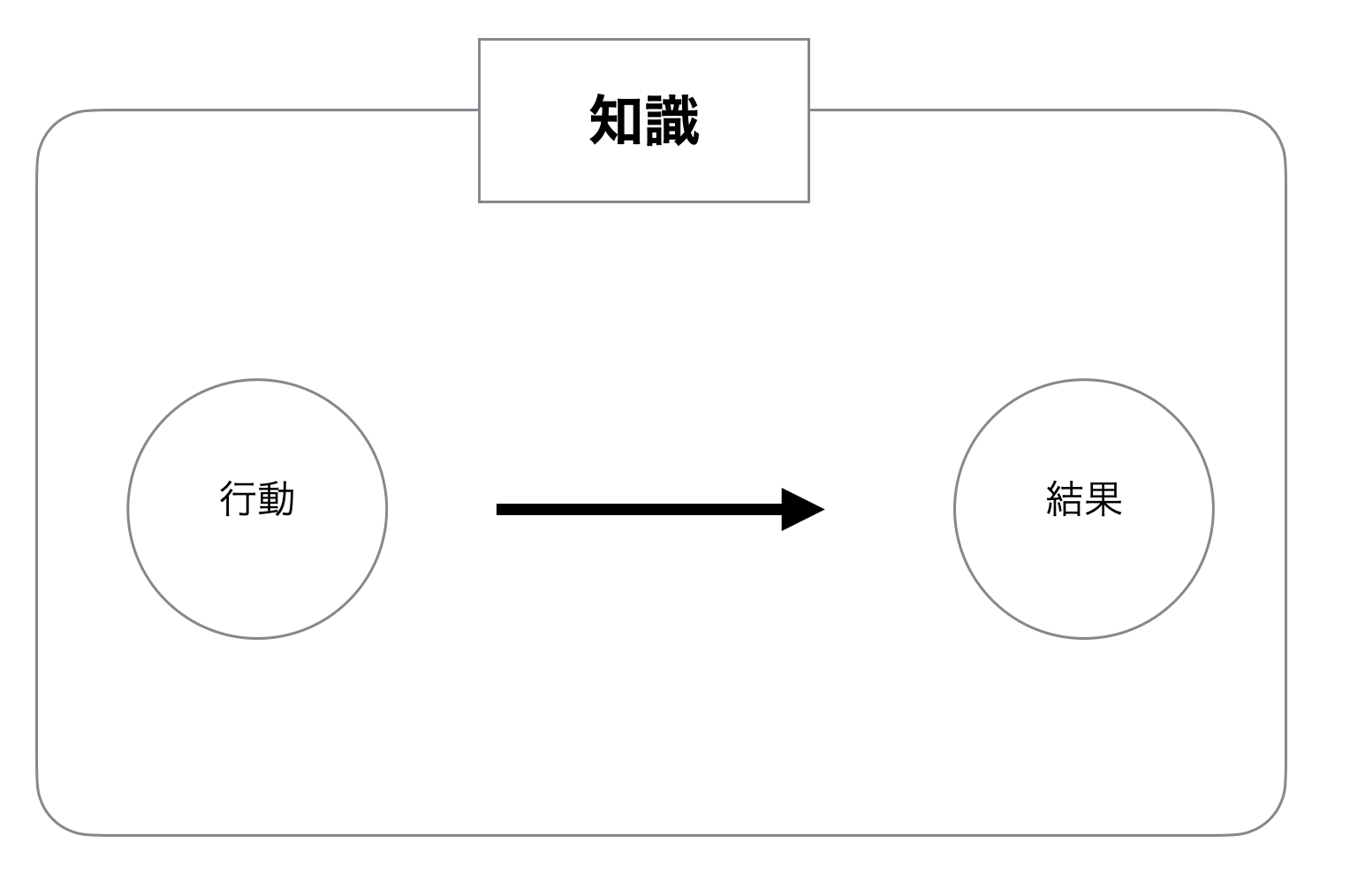
何が起きるか予測するために役立つのであれば、それは知識です。逆に、予測に役立たないのであれば、それはただの情報です。
データを使う目的は知識を得るため
ここで一つおさえておきたいのは、知識と真実は違うものです。
50年代に統計的品質管理という手法を日本に持ち込み、その後日本の製造業が凄まじい発展をしていく黄金期を形成することに貢献したエドワード・デミング氏は、ビジネスにおいて「真実」というものはなく、あるのは「知識」のみだと主張しました。
彼は多くのビジネスが潰れてしまうのは、そうしたビジネスのリーダーたちが何かを真実だと信じてしまっていたからだと言います。もちろん、そうした真実だと信じていたものは間違っていたのです。
真実とは変わらないはずのものですが、それに対して知識は絶えず変わっていくものです。今持っている知識が正しいのかどうか、それはその知識を使った予測がどれだけ正しかったのかによって評価されます。予測に役立たないのであれば、その知識は棄てられるか、または更新、修正されるかして進化していくものなのです。
こう言うと、この世の中に予測できるものなんてないという人達もいるでしょう。もちろんだれにも完璧な予測なんてできません。
それでも、例えばあなたが新しいソフトウェアエンジニアを雇うとき、新しいマーケティングキャンペーンを始めるとき、セールスインセンティブの計画を変えるとき、実はあなたは「こうした変化が良い結果につながる」と予測しているのです。気づいているかどうかにかかわらず。
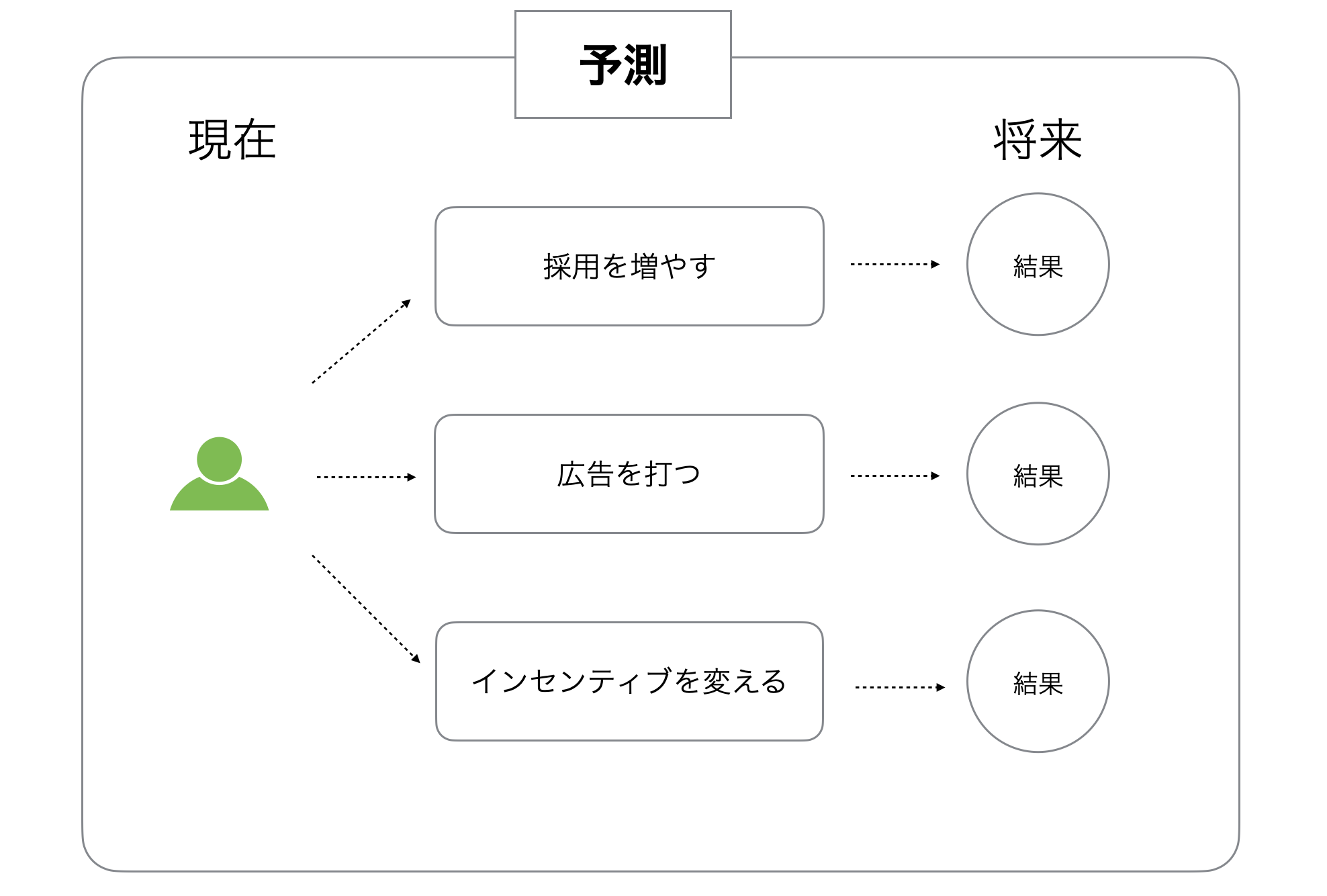
しかし、そんなことがどうして分かるというのでしょうか?
たいていの場合は「悪い結果になることはない」と信じているので、間違っていたのかどうか後で評価することはありません。たまたまうまくいけば、自分の予測がうまくいったと思い込むでしょうし、うまくいかなければそのことに目をつぶるか、他の人や環境のせいにしてしまうことでしょう。
そもそも、自分が予測しているという感覚もありませんから、後でその予測が正しかったかどうかを判断するための明確な基準もありません。
こんなことでは、そもそもうまくいったのか、いかなかったのか判断できませんし、うまくいかなかった場合に何がまずかったのかと、後で学ぶこともできません。
実はこれこそがデータを使う理由なのです。
データを使えば、あなたが予測をする際に必要となる相関または因果関係についてのモデルを構築していくことができるようになります。もしこうしたモデルによる予測が間違っていれば、その前提やロジックを検証し、間違った原因を突き止める手掛かりを得ることができるのです。
もし現実世界のビジネス環境が変わったのであれば、それまで通用したモデルは機能しなくなり、予測がうまくいかなくなるでしょう。しかしそのことで、あなたは自分たちの持っている因果関係に関する知識を更新しなくてはいけないことに気づくことができるのです。
データはまさにこうした知識を得るために必要な道具なのです。これを、データから必要な知識を得るという意味で、データインフォームドと言います。
しかし、ほとんどの人たちはただデータを集め、何らかの指標を定義し、あとはチャートをただ毎日眺めるだけです。そうした指標がターゲットとして設定された数値を達成できなければ、根拠のない言い訳をするか、他の人や外部環境のせいにするだけです。逆にターゲットを達成してしまったとしたら、そんなターゲットは十分に大きくないということで、さらに大きなターゲットが与えられたりします。
これがよくあるデータドリブンの姿です。データにドライブされているのです。せっかくデータを使っても、たいていの場合はデータを見て一喜一憂するだけで、データから何も知識を得ることができないのです。
デミング氏は、こうしたデータドリブンな人たちを、自分たちのビジネスを迷信によって運営していると言っていました。
「目に見える数字を使って会社を回してる人たちは近いうちに会社を失い、目に見える数字も無くなってしまうだろう」
もちろん彼はデータを使うな、数値を見るなと言っていたわけではありません。
「神以外、他のものはみんなデータを持って来い。」
と言っていたくらいですから。
デミング氏はデータを盲目的に使うこと、データが間違った使われ方をすることを批判していたのです。
そして彼はデータドリブンではなく、データインフォームドになるための実現可能な方法を知っていました。実際デミング氏は長年にわたり日本でもアメリカでも彼の教えを請うたくさんの人たちに基本的なデータリテラシーを教え、ビジネスを改善するために必要なデータの使い方を教えました。
日本でもPDCAやQC活動として知られるものです。にも関わらず、デミングが教えたデータの使い方を実行する人たちは少なく、ビジネス改善のためのチャートの見方を学校で教わることすらありません。
データに関する本やセミナーでも、人気があるのは最新のAIなどのアルゴリズムの話、またはデータベースやデータ基盤構築などテクノロジーに関する話で、デミングが教えたデータの見方やその裏にある彼の哲学の話をするものはあまり人気がありません。
ビジネスを改善するために、どのようにデータを見るべきなのか、この話がほとんどないのです。
なぜでしょうか?
一番大きな理由は、日本でもそうですが、デミングの教えはPDCAやQC活動という形になってしまい、そこで使われるデータを使った改善手法は、製造業における品質改善、例えばネジの大きさや品質を改善するということには使えるが、例えばユーザーのサインアップ数、コンバージョン率、キャンセル率、在庫数、受注率、といったオペレーションまたはビジネスのデータには使えないと勘違いされてきたからだと思います。
しかしそんなことは全くありません。
例えば、Amazonのような企業では会社のありとあらゆる部門において、データを使ってビジネス、オペレーションの改善が日々行われていますが、そこにはまさにデミング流のデータの使い方、そしてその裏にあるデミング哲学が浸透しているのです。
彼らは昔の日本の製造業のようにPDCAだとかQCサークルだといった名前を使うことはありません。しかし名前が重要なのではありません。重要なのはその裏にある考え方、そしてデータを使った改善のプロセスです。
それでは、データインフォームドになるには、どうやってデータを見ればよいのでしょうか?ビジネスを改善するためのデータの使い方とは具体的にどういうことなのでしょうか。
そのためには、まずはばらつきを理解することが何よりも重要です。データのばらつきを理解して、それに対処できるようにならなくては、データを見ても意味がありません。
データはばらつく
先ほども述べたように、多くの人たちはデータを手にするとすぐにデータドリブンに走ってしまいます。せっかくデータを使っていても、たいていの場合チャートをただ毎日眺めるだけで、何をしたらいいのか途方に暮れるだけになってしまいます。
なぜでしょうか。
これからデータを使っていこうとする人が期待するのはこういったチャートです。
このチャートを見れば、今自分たちがやってることは間違ってない、うまくいっているではないか、と実感することができますね。
または次のようなチャートです。
このようなチャートを見れば、あるグループではうまくいって、別のグループでは悪くなっていると。なのでうまく言ってるグループのやり方を他のグループでも行えばいいのだと。
しかし、実際のビジネスではこんな都合のいいチャートはなかなか出てきません。
そこで実際にデータを取得して、チャートにすると、たいていの場合目にするのはこんなかんじのチャートです。
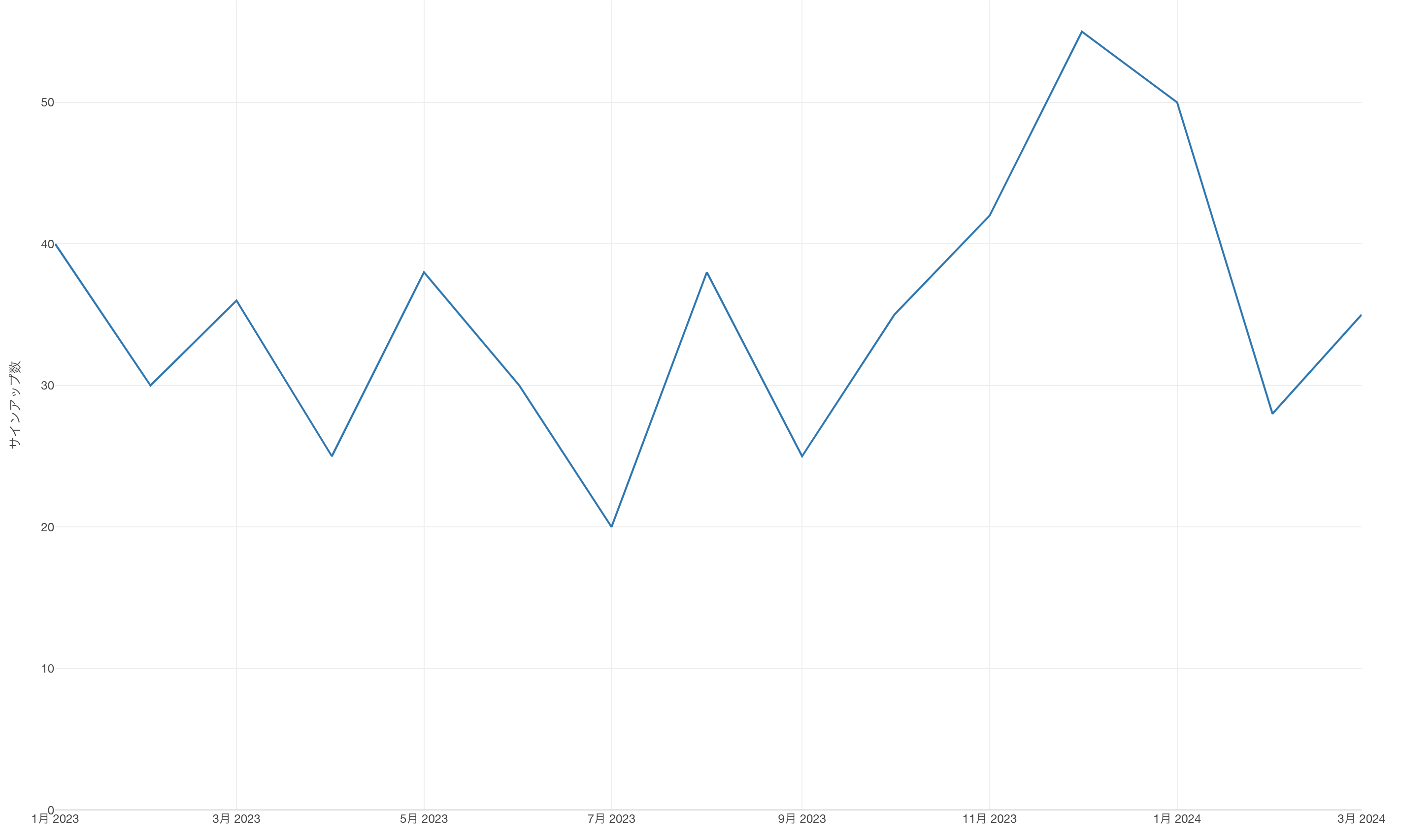
これはあなたのメルマガに対するサインアップ数の推移だと想像してみて下さい。
このチャートからわかるのは、あるときは上がり、あるときは下がるということです。これを眺めてうまくいっている、もしくは悪くなっていると思う人はいないでしょう。
いいときもあれば悪いときもあると言った感じです。
これがデータのばらつきです。
これはデータの活用、分析において最も重要なことなのですが、なぜか多くの人はこのことを知らないか、知っていてもすぐに忘れてしまいます。
ばらつきというのはみなさんの周りにある現象です。例えばあなたの体重を考えて下さい。
毎日測ってみると毎日値が違うのがわかります。平均体重よりも上のときもあれば下のときもあるでしょう。もちろん食べたり飲んだりする量を増やし、特に運動もしなければ長期的には上がっていくでしょう。しかし、そういった特別なことがなくても、あるときは体重が平均より重く、あるときは軽かったりするものです。
にも関わらず、あるとき体重を測ってみたらいつもよりもちょっと重かった場合、昨日食べたものが悪かったとか、悲観になってもしょうがありません。また、特にいつもと何か変わったことをしてないにも関わらず、ある日体重が軽かったとしても、おれ今日はがんばったなー、なんていう人はいないでしょう。(ということを願います)
ビジネスも一緒です。
データを取得し、チャートにしてみると、たいていの場合はばらついているものです。そして、そのばらつきは繰り返され、まるでそれが当たり前かのようです。
それでは、このようにばらついたチャートを見たところで、ビジネスを改善するためにいったい何をすれば良いというのでしょうか?
そもそもこれはいいことが起きていることを示すのでしょうか?それとも心配すべき何か悪いことが起きていることを示すのでしょうか?何かアクションをとるべきことが起きているのでしょうか?
データを見ているのであれば、これこそがほんとうに知りたいはずですよね。
しかし、もしデータがばらつくということを知っていたのであれば、このチャートは特に何か変わったことが起きていることを示しているわけではありません。むしろ、想定内の動きをしているだけで、正常運転だということを示しているのです。
こうした想定内であることを示しているもの、特に注意を払う必要のないものをデータの世界ではノイズと言ったりします。逆に、注意を払うべきもの、何かアクションを取ったことがいいことを示すものをシグナルといいます。
上記のチャートから言えるのは、何か注意を払うべきことは今のところ起きていない、つまり特に何もアクションを取る必要はないということです。つまりこれらのばらつき、データが日々上がったり下がったりしているのはただのノイズだということです。
ノイズを追うのは時間の無駄
しかし、こういったチャートを見てデータドリブンの人たちがやることは決まっています。
先月のサインアップは12%ダウンだった、どうなってるんだ、これじゃ今期のターゲットに到達できない!
とミーティングで誰かが怒鳴り始めることになります。
そしてどうにかしろ、と言われたあなたはいろいろ調査をしてみたが、特に何か問題があるわけではありませんでした。これまでとなにか変わったわけでもなければ、むしろ全てのことは計画通りに進んでいたことが確認されたのです。
そこで適当な言い訳を作り上げて、次のミーティングをなんとかしのぐことになりました。
そうこうしているうちに次の月がやってきました。すると、今度はサインアップの数が上がっていました。
この結果を発表するミーティングでは、みんなが笑顔でお互いを褒め称えることになりました。
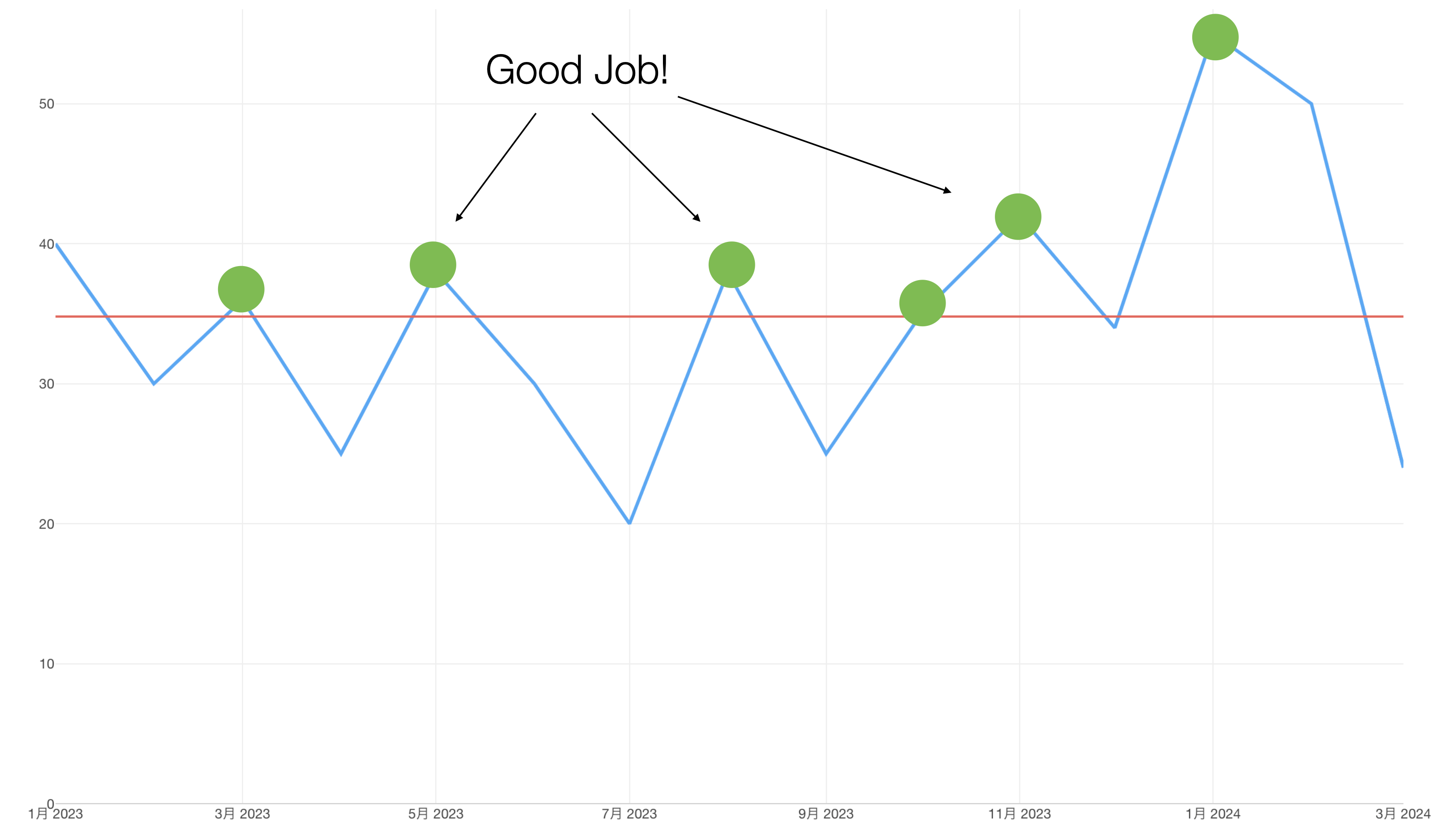
ところが、もちろんそんな幸せはずっと続くわけはありません。次の月になるとまた、サインアップの数は減るのでした。
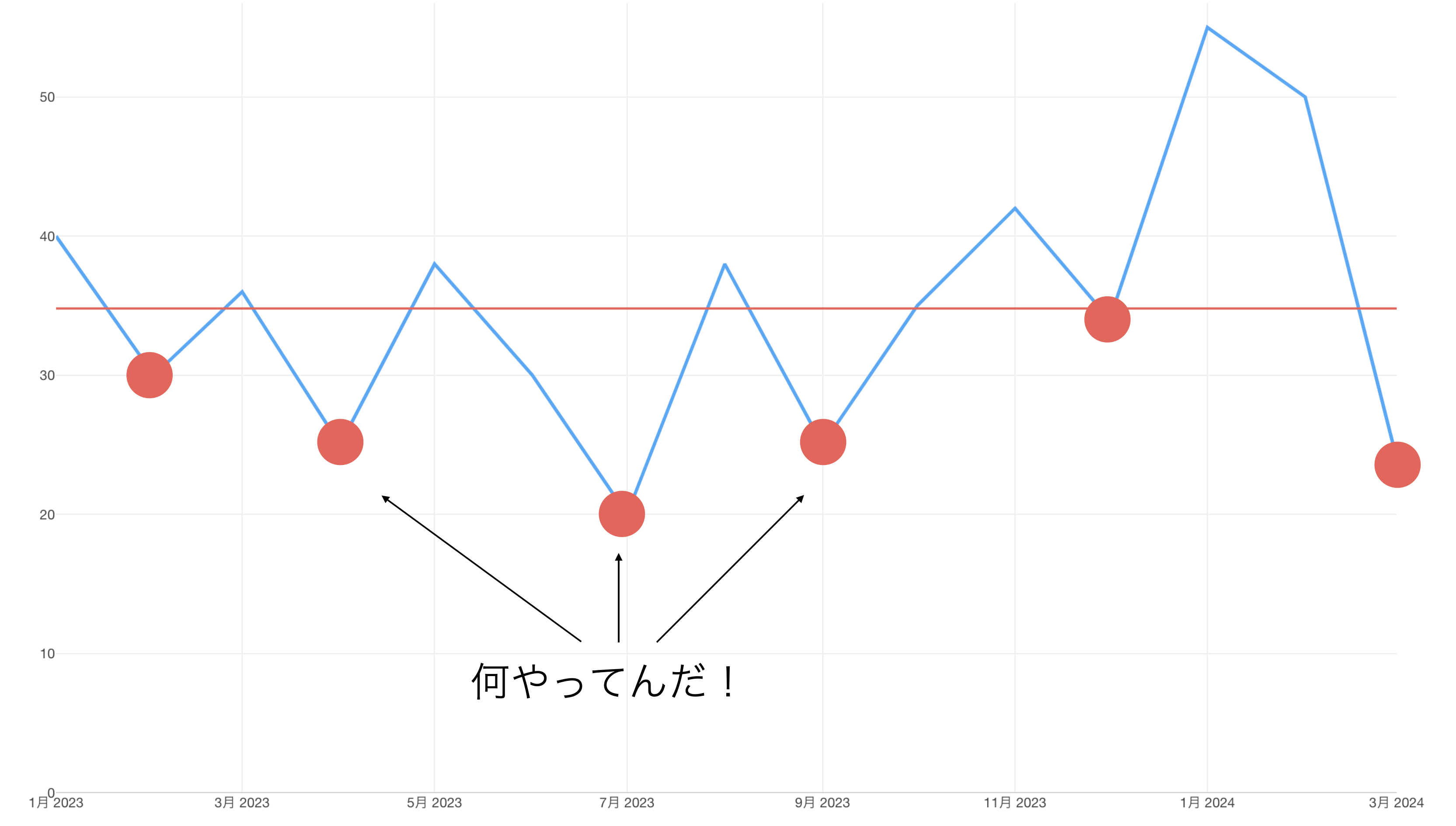
もちろんたまには、なにかうまく行かなかった原因を突き止めることができるかもしれません。特定の商品に欠陥があり、大型のキャンセルが出た。ある大きな取引先が倒産した。新しく入ってきた営業社員による仕事の引き継ぎがうまくいっていなかった。など。
しかし、そういったことは稀であり、想定内のばらつきにはそういった特別な理由が見当たらないことがほとんどです。
にも関わらす、このチームはみんなで最新のデータが出てくるたびにこうした想定内のばらつき、つまりノイズによって一喜一憂するのです。
そして、データを使わなくなる
そうこうしてるうちに、みんなデータを見なくなります。
というのも、数値がよかったときにみんな自分に都合のいいことを言うだけで、ほんとうは何がうまくいってて、何が影響しているのかは曖昧となったままなのです。
逆に、悪かったときも、みんな人のせいにするだけで、ほんとうは何がうまくいってないのか、何を変えればよくなるのかがよくわからないのです。
毎回、まるでおみくじを引くようなものになってしまい、結果が良いか悪いかは運まかせで、その数値を元になにか特別にやることが変わるわけでも、なにかが改善するわけでもないので、みんなデータに対する信頼を失ってしまうのです。
当初抱いた「データを元にビジネスを改善する」という話は遠い夢の話となってしまいました。
人工的なターゲット
指標の値を、例えば前年、前月、平均、ターゲットなど、何か恣意的に決めたものと比べても、それはただのノイズでしかないのです。
つまり、データドリブンになろうとして、色々指標をつくり、見始めたところ結局その数字の変化に毎月追っかけ回され、ノイズをシグナルだと勘違いして無意味な対策を立てたり、適当な言い訳に追われることになってしまい、そのうちだんだんと追い回されることに嫌気が差し、多くの人が肝心の指標を見なくなるようになってしまうのです。
ゴール、ターゲット、指標を与えられると人々は次の3つのうちのどれかの行動を取るようになると言われています。
- システムを改善するためにがんばる
- システムをごまかす、または改竄する
- もしくは、データを改竄する
そしてデータドリブン、つまりばらつきを理解しないまま毎月指標のばらつきに追いかけ回されていると、人々は2または3の行動を取るようになってしまうのです。
これが99%のデータドリブンプロジェクトが失敗する理由です。
シグナルとノイズを切り分ける
これまでに、現実の世界はばらつきで溢れているという話をしてきました。そうしたばらつきは想定内であり、特に注意を払うことはないと。
それでは、データはいつもばらついているのは想定内なので、データを見る必要はないのでしょうか?
もちろんそんなことはありません。
データを見るときの2つの大罪というのがあります。
- ノイズをシグナルだと勘違いして余計な行動を取ってしまう
- シグナルに気づかず必要な行動を取らなかった
データドリブンだと1番目の「ノイズをシグナルだと勘違いして余計な行動を取ってしまう」という罪を犯してしまいます。そして余計な行動を取ってしまったせいで、余計に事態は悪くなったりします。
そして、時間が経つとだれもデータを見なくなり、今度は2番目の「シグナルに気づかず必要な行動を取らなかった」という罪を犯すことになってしまうのです。
実はデータを見る理由はばらつきというノイズデータの中から、状況が良くなっている、または悪くなっているというシグナルを見つけ出し、適切な行動をとるためです。
それでは、どのようにノイズの中からシグナルを見つければよいのでしょうか。
ここで統計学に詳しい人であれば、ばらつきがある一定の水準よりも大きければそれがシグナルだと言うでしょう。それは半分合ってて、半分間違っています。
というのも、たとえばらつきが大きかったとしても、それがいつも繰り返されているのであれば、それは通常運転、つまり想定内ということです。
ある特定の時点のばらつきが他の期間のばらつきに比べていかに例外的なものであるのか、またはどこかの時点でこれまで想定されていたばらつきとは違う傾向を持つばらつきに変わり始めたのか、これこそが私達が注意を払うべきことなのです。
つまり、そのばらつきは自分たちのビジネスに何らかの変化が起きていることを示すシグナルなのか、それともただの想定されたいつものばらつき、つまりノイズなのかということです。
もしシグナルなのであれば、あなたは何か行動を起こす必要があるかもしれません。少なくともその原因が何なのか調査する必要があります。しかしそれがノイズなのであれば、つまり通常のばらつきということなのであれば、とくに調査も行動も起こす必要はありません。
そこで、次の質問です。
「それでは、シグナルとノイズをどうやって見分ければいいのでしょうか?」
そうです、これこそがばらつきに関して正しく、そして最も重要な質問です。
そして、まさにこの質問に答えるために大変便利な道具がXmR(エックス・エム・アール)チャートと呼ばれるものです。これは統計的品質管理やシックスシグマの世界で管理図(コントロールチャート)と呼ばれるいくつかあるチャートのうちの一つです。
管理図(コントロールチャート)とはもともと1920年代にウォルター・シューハートによって作られたもので、その後1950年代以降日本の製造業に統計的品質管理を教えることになったデミング氏によって日本にも持ち込まれました。ところが、当時の管理図のいくつかのチャートにはこのXmRチャートは入っていませんでした。
実はこのXmRチャートはシューハートのチームによって1940年代に考案された後、世界からは忘れ去られていました。そしてそれから40年ほどの年月を経た1985年、デミング氏、そして彼と長年にわたりセミナーやコンサルテーションをしてきたドナルド・ウィーラー氏によって再発見されたのです。
彼らは、これまでの管理図のチャートと違い、このXmRチャートは様々なタイプのビジネスまたはオペレーションに関するデータに使える汎用性に感激し、特にウィーラー氏はこのチャートをプロモートしていくこととなりました。
当時デミング氏はすでに日本を去り、その後アメリカでセミナーやコンサルテーションに集中していくことになりました。実はこれが日本ではXmRチャートもウィーラー氏の名前も、あまり知られていない大きな理由なのではないかと思っています。
それはおいておいて、これからノイズの中からシグナルを見つけ出すための道具、XmRチャートの話をします。
XmRチャート
まず、XmRは「X」と「mR」の2つのチャートからなります。
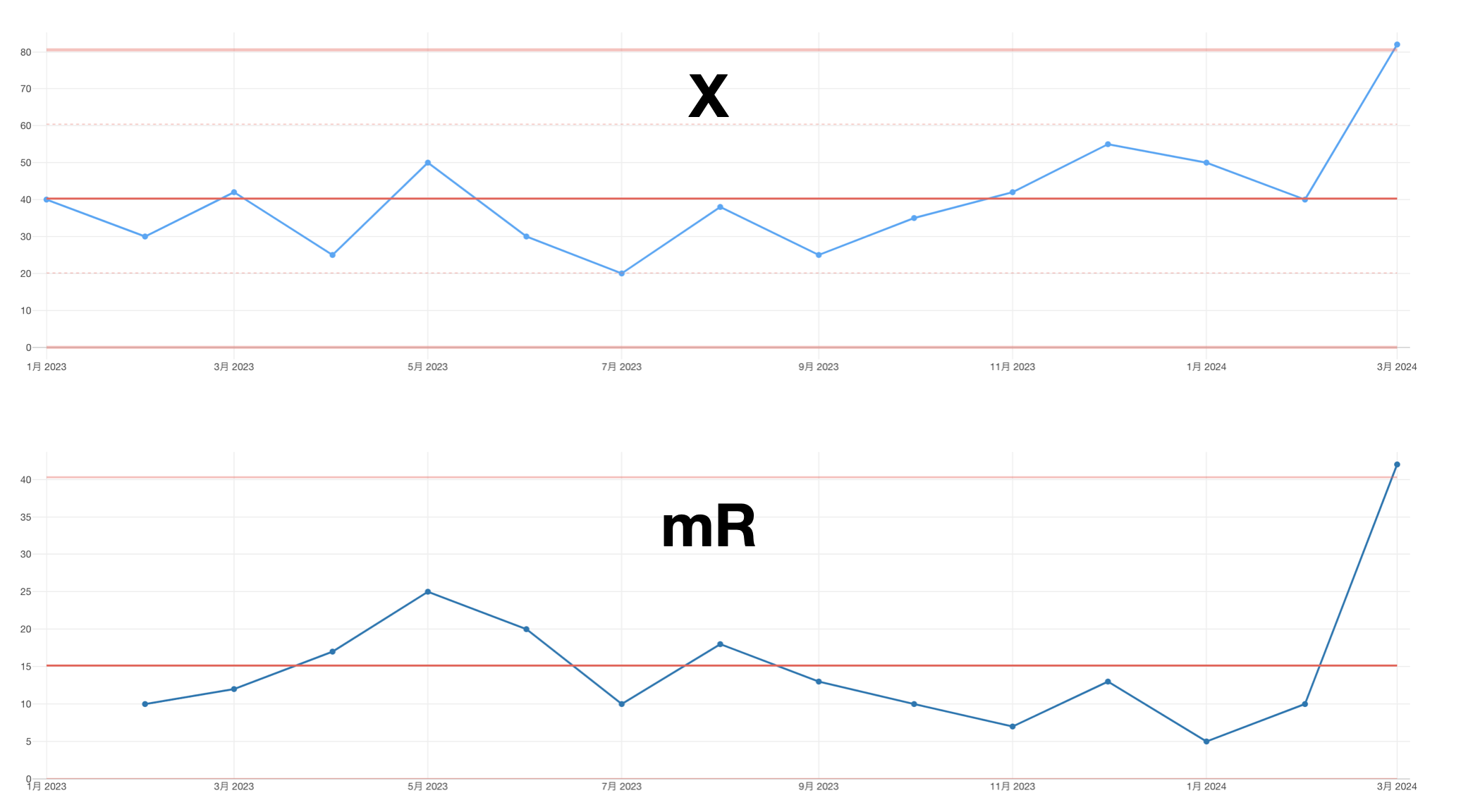
Xとはあなたの興味の対象となる変数です。例えば、サインアップ数、コンバージョン率、在庫数、売上、などのことです。
そしてmRとはMoving Range(移動範囲)のことで、要はXのそれぞれの値とそれぞれの1つ前の値との差を計算し、それらを並べたものです。
XmRチャートの細かい定義や使い方はこちらのセミナーで解説していますので、ここでは具体的にこのチャートを使ってどのようにデータから知識を得ていくことができるのか、この点について話したいと思います。
XmRチャートを使ったビジネスの改善
例えば、以下のようなチャートを使ってサインアップ数を見ていたとします。
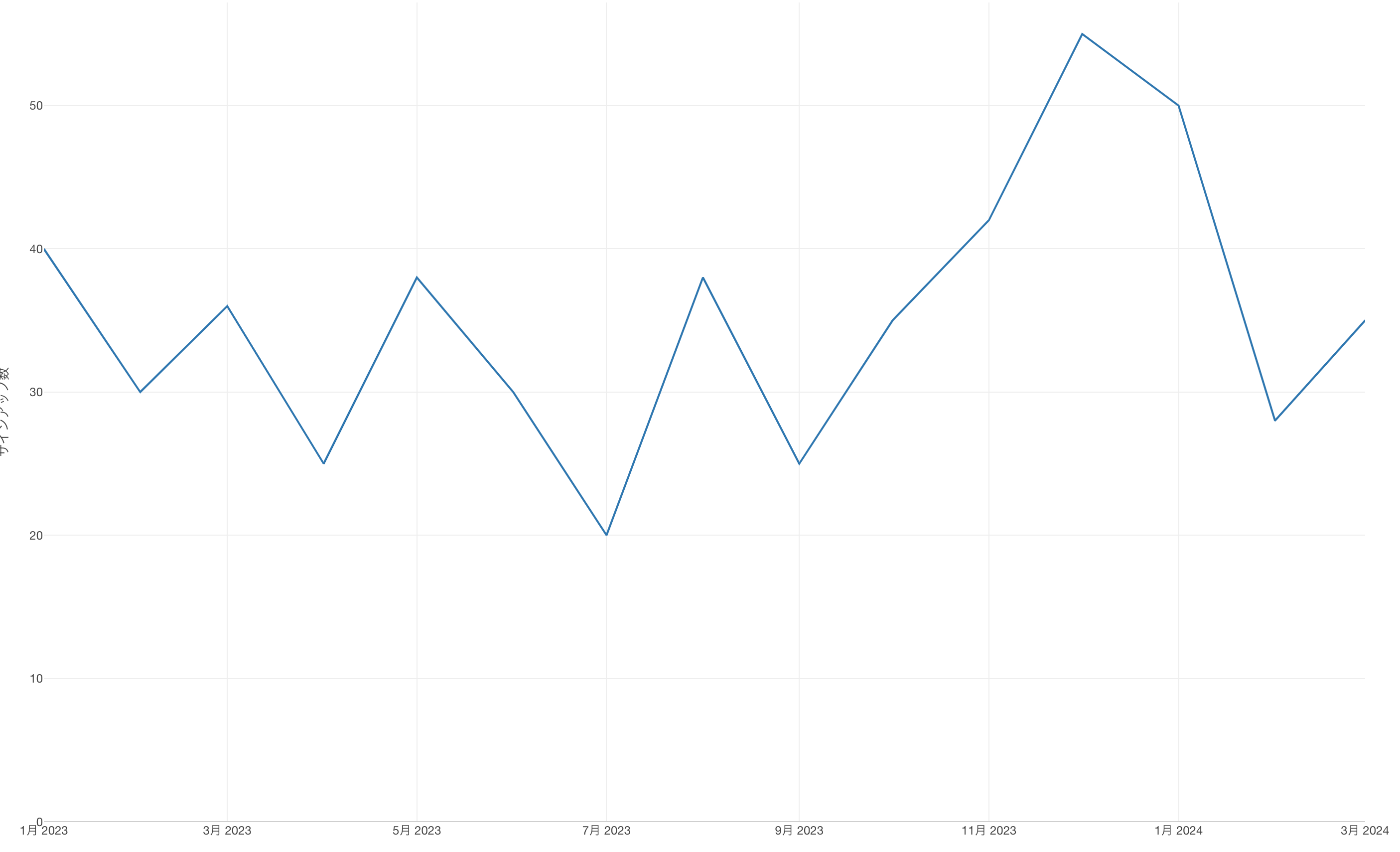
これをXmRチャートで表すと以下のようになります。
真ん中の赤い横線サインアップ数の全期間の平均値を表しています。そして、上下の赤い線は管理限界というのですが、例の「通常のばらつき」が想定される幅を表しています。
サインアップ数は毎月ばらついていますが、それらはどれも管理限界と呼ばれる区間に収まっているため、これらサインアップ数の変化は想定内だということを示しています。つまり特にシグナルと呼べるような動きはここでは見られないということです。
サインアップ数を上げるためにこれまで様々な施策を打ってきたとしても、このXmRチャートを見る限りシグナルは出ていない、つまりこれまでに比べて注意すべき変化が見られないというのであれば、そうした施策はサインアップ数を上げるという意味で、効果がなかったということになります。
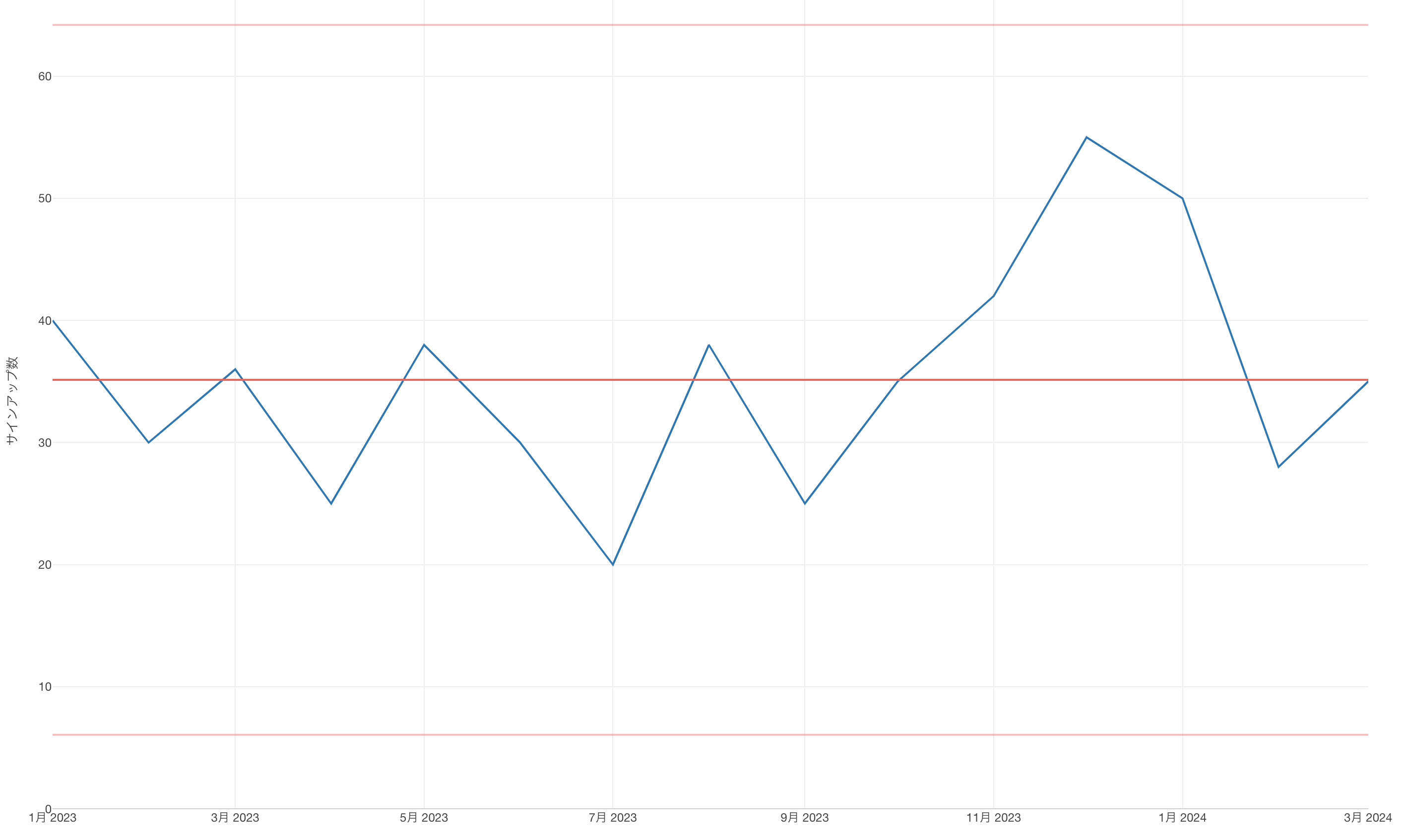
そこで、しばらくの間サインアップ数を上げるためにさらにいくつか新しい策を打ってみました。そして数ヶ月ほど毎月このXmRチャートを使ってサインアップ数を見続けたのですが、毎回「何も変わってない」ということが確認されるだけでした。
もちろん、これまでの平均に比べれば良いときはありました。そして前月に比べれば良くなっている時もありました。しかし、それらは想定されているばらつきの範囲に収まるばらつき、つまりノイズであって、あなたの注意しなくてはいけないようなシグナルではなかったのです。
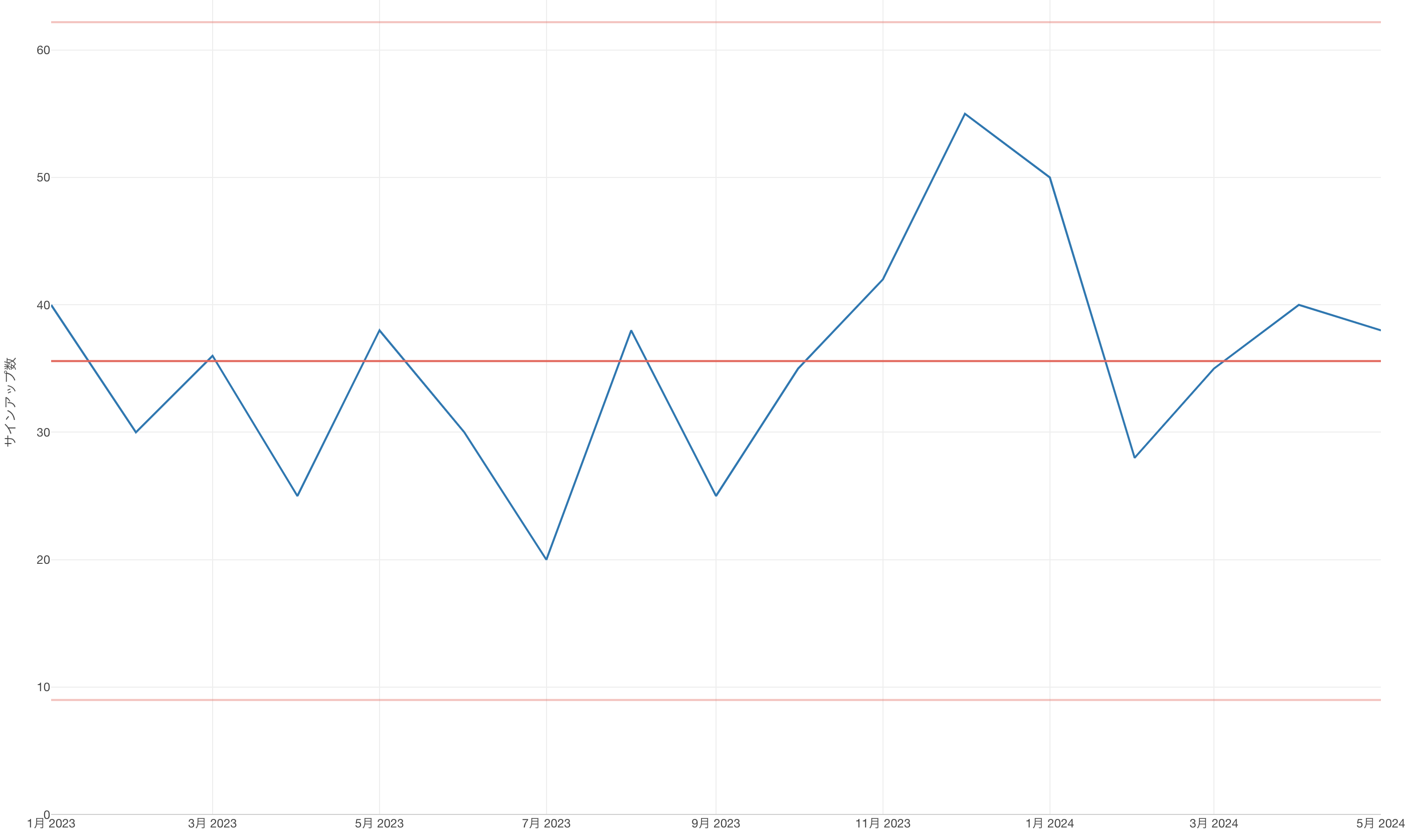
それでも、引き続きサインアップ数を増やすためにいくつかの施策を打ち続けたところ、翌月になるとサインアップ数がいよいよ想定される範囲(管理限界)を超えました。
つまりこのチャートが、ビジネスのプロセスに何らかの変化が起きている、と言い始めたのです。これまで想定されていたばらつきに比べて、今回の値は異常であると。これは何らかのシグナルだと。
ここで行動開始です。
つまり、何がこのシグナルの要因なのかを調べる必要があるということです。
そして早速調べてみると、最近始めたある施策と関係しているのではないかということになりました。
そこでその施策を行い続け、さらに観察を続けることにしました。
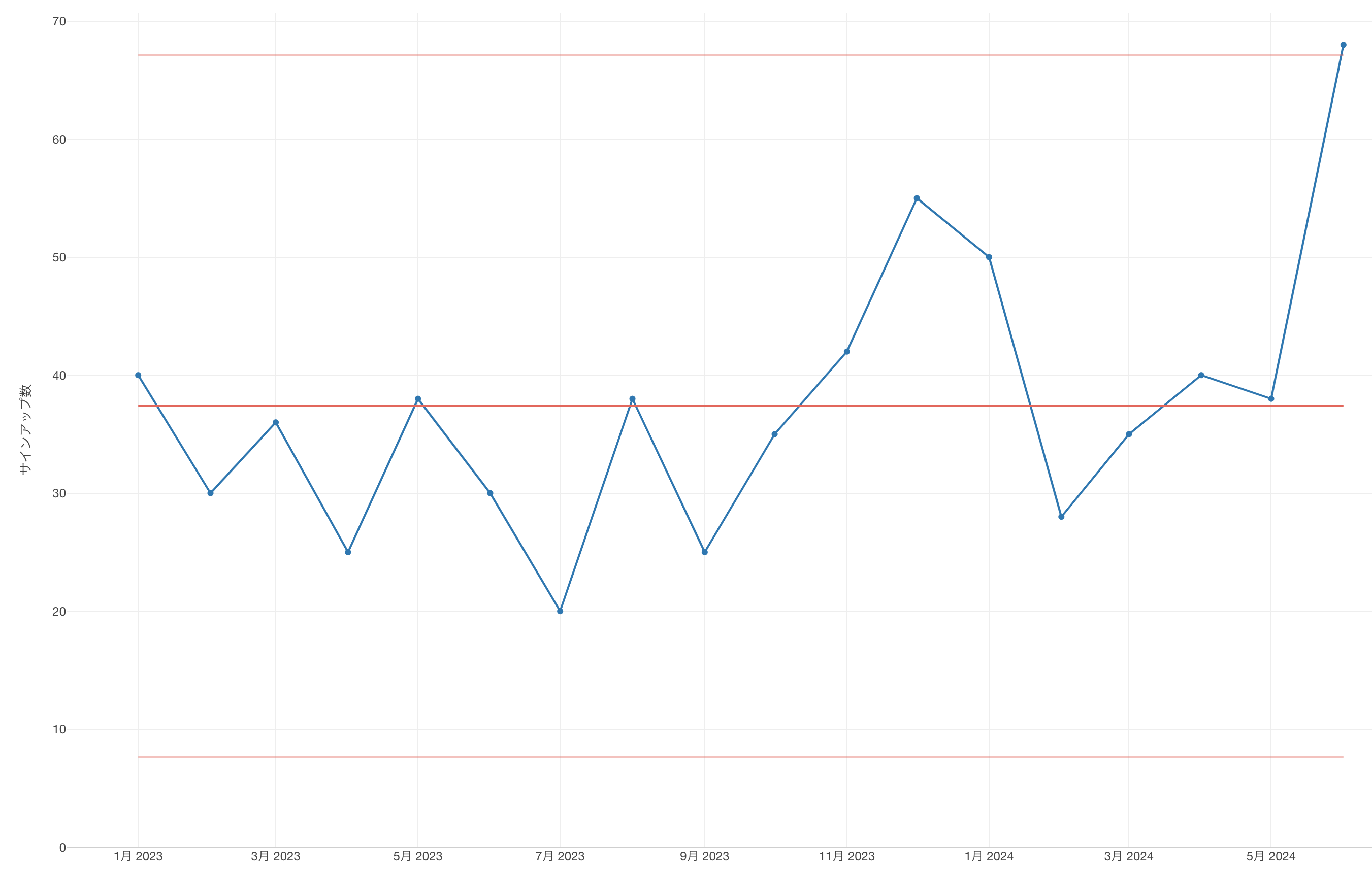
すると、翌月も同じようなシグナルがこのチャートによって観察されました。
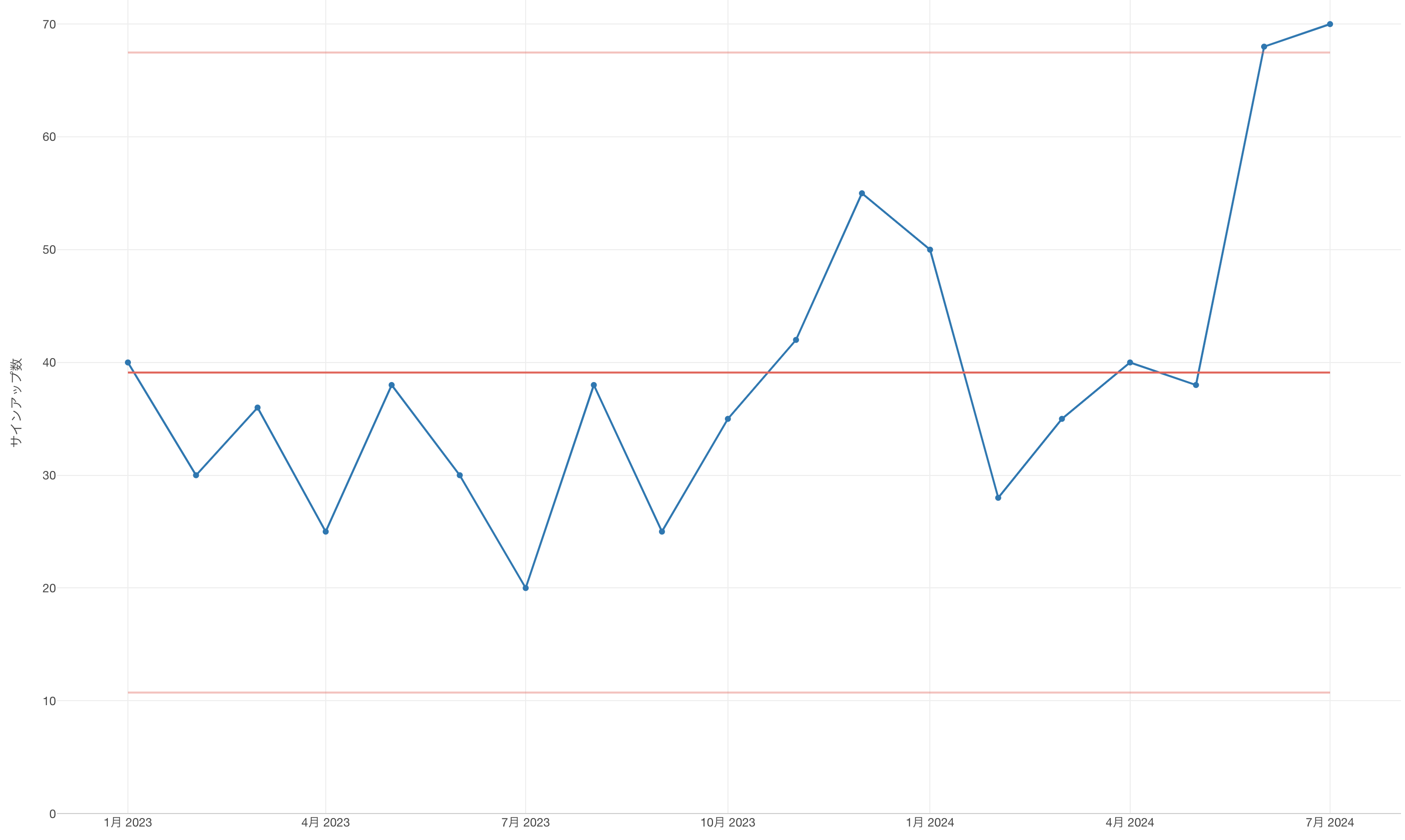
これで、最近始めた施策が効果を出し始めたということに対して、私達の自信が大きくなりました。
そこで、その施策を一度ストップして、データの観察を続けることにしました。すると翌月のチャートはサインアップ数が以前の「通常のばらつき」が想定される範囲に戻っていることが確認されました。
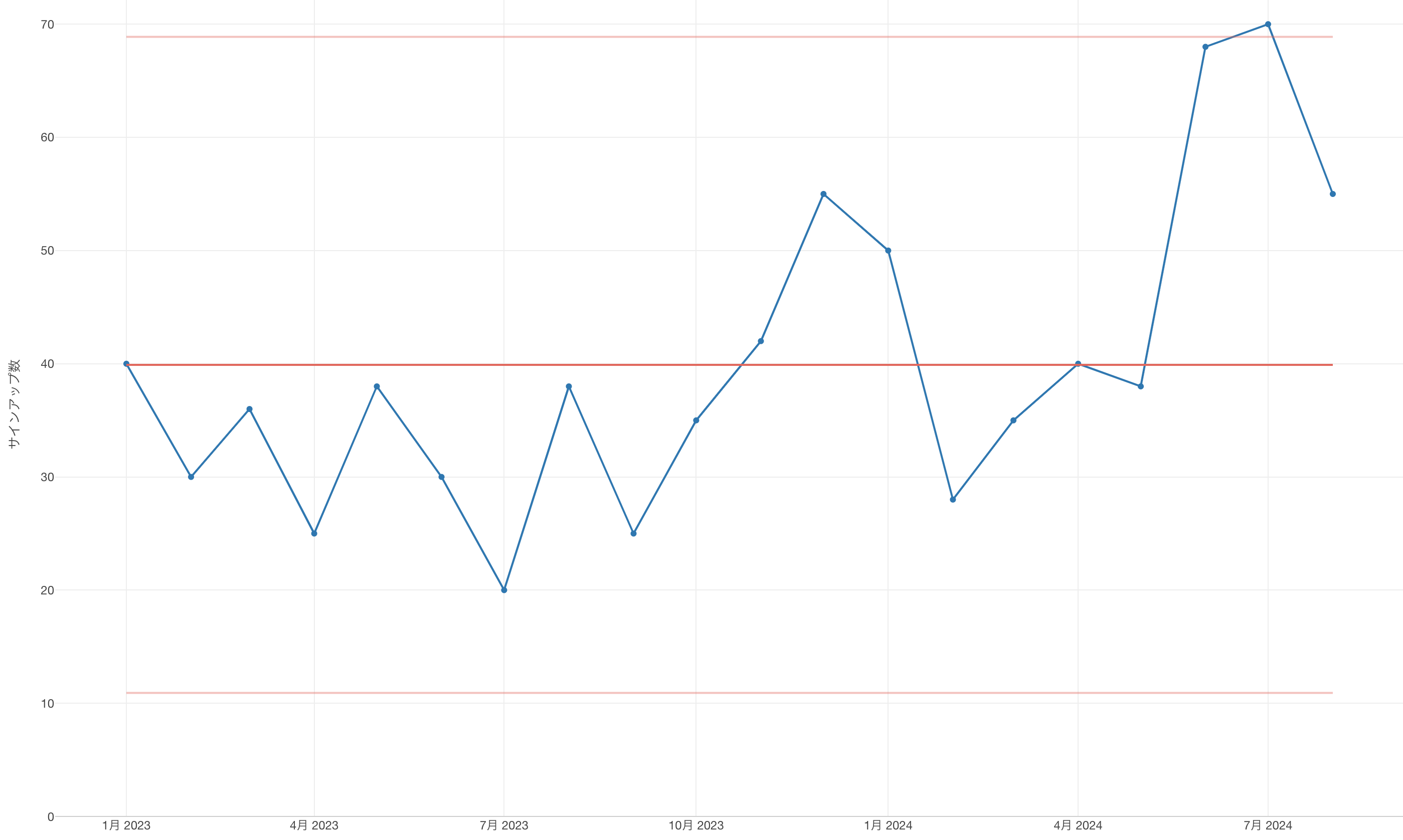
今、何が起きたのでしょうか。
これは、私達はついにコントロールすることができるインプット指標を見つけたということなのです。つまり、ある施策を行うとアウトプット指標であるサインアップ数が増えるということを発見したということです。
覚えてますか?
知識とは予測に役立つかどうかです。
私達は「ある施策Aを打つとサインアップ数が上がる」という関係をデータを使って確認することができたのです。そしてこの知識を使えば、私達がこの施策Aを行えば将来のサインアップ数は70を超えるだろうと予測できるようになったということです。
アウトプット指標に影響を与えるものは何か、何をすれば目的とする指標に影響を与えることができるのか、これこそがビジネスにおける知識なのです。
ただデータを見ても、結局何を示しているのか、何をしたらいいのかよくわからず、大抵の場合はかえって混乱してしまうものです。というのもそこで見ているデータはただの情報に過ぎないからです。知ってても知らなくても、あなたのビジネスは何も変わらないという類の情報ということです。
ただの情報ではなく、予測に役立つ、原因と結果に関する理解という意味での知識、これこそが私達がデータから得るべきものであり、データの見方さえ知っていればこれは可能なのです。
データを使った改善の文化
自分たちのアウトプット指標を動かすインプットが何であるか、データからつかむことができた私達は、このことを他の部門の人達にも伝えました。すると、彼らの見ているアウトプット指標でも同じようなことができないかということになりました。
これが、データインフォームドな文化、つまりデータを使ってビジネス改善のための知識を得ていく文化が組織の中にでき始めたシグナルです。
全てのビジネスはプロセスと言えます。もちろん1つの大きなプロセスがあるだけではなく、それを構成する小さなプロセスもたくさんあるでしょう。ここで重要なのはプロセスにインプットとなるみなさんの活動があって、そしてアウトプットとなる結果があるということです。知識とは、インプットとして何を行うと期待するアウトプットが得られるのか、これに関する理解です。

改善のために何でもかんでもやってみて、あとは祈るだけではいつになってもビジネスの改善に必要な知識は得られません。そういう意味で、データドリブンな世界は、まるで何かのカルトかのようです。
そういった世界ではMBO(Management By Objective)やOKR(Objectives and Key Results)など、何か指標を決めると、たいていの場合それらを改善するためには、まずは目標を決め、そこに向かって突き進めばよいのだと教えられます。どのようにゴールに向かうか、戦略なり計画なりは自分で考えろというのです。目標はでかければでかいほどいい、達成できるような目標はビッグな目標ではない、もっとビッグな目標を持て、などと言って目標の立て方ばかりが注目されます。
例えばサインアップ数を上げたいのであれば、サインアップ数の目標を決める前に、まずはユーザーがサインアップするまでのステップはどのようになっているのか、つまりプロセスをしっかりと理解する必要があります。しかし、ある程度既存のプロセスを理解できた気になったら、その後はみんなすぐに最適化モードに入ってしまいます。
サインアップ数をあと10%上げるには何をすればいいのかと。それで思いつくことをなんでもやってみて、その後うまくいったかどうか確かめようと。
そしてしばらくたったあとにデータを見ると、さきほどのばらついたチャートのようなっていて、たまたま先月に比べて5%上がっていればうまくいった、5%下がっていたら別のことやれというわけです。それらの数値はただの想定内のばらつきであるかもしれないにも関わらずです。
しかし、データインフォームドな文化のある組織は違います。
彼らは自分たちのサービスにおいて、ユーザーがサインアップするまでのプロセスはこうなっていると説明できるのはもちろんですが、さらに自分たちの仕事はこのプロセスに影響を与えることができるインプット要因、つまり自分たちがコントロールできる要因を探すことだと理解しています。
そのためには2つの方法のどちらかを取ることになります。1つはA/Bテストなどの実験を行い、それがうまくいったのかどうかをデータと統計的仮説検定や信頼区間などを使って判断する方法です。
しかし、ほとんどのビジネスや組織はこうしたA/Bテストを行うことができません。逆にほとんどのビジネスが持っているのはオペレーションデータです。例えばサインアップ、売上、新規顧客数、コンバージョンなどといった、ふだんのオペレーションに関するデータです。
しかし、こうしたデータでも自分たちのプロセスに影響を与えるインプット要因を探すことはできます。それがすでに見た、XmRチャートを使ってデータを観察するやり方です。
もちろんそのためには、サインアップ数を上げるための仮説を実行(実験)に移し、その結果を検証するためにXmRチャートを使ってサインアップ数のばらつきを観察します。目の前にある数値は通常のばらつきなのか、それとも例外的なばらつきなのかを確認するのです。
そして、もしシグナルが確認されたのであれば、自分たちの施策がうまくいった結果なのか、それともその要因が未知の場合は、もしかしたらそれまで把握できていなかった何か別のインプット要因があるのか、調査を開始することになります。
ターゲットという人参を目の前に吊り下げ、ノイズを追っかけていく文化と、データを使ってプロセスに関する知識を求める文化、この2つの文化はどちらもデータを使っていますが、その使い方には大きな差があります。マインドセットが全く違います。
データインフォームドな文化を持つ組織にとってデータを使う目的とは、自分たちのビジネスプロセスに関する因果関係に関する知識を獲得することです。なぜなら、こうして得られた知識こそが、あなたがビジネスの意思決定をするために必要なインプットとなるからです。
そしてこうした組織こそ、ビジネスを継続的に改善し続けていくことができるのです。こうした改善を実感できるこそ組織で働く人たちは、自分たちの仕事が改善に対して貢献していることを実感できるため、仕事にやりがいを見つけることができます。そして、改善するためには日々の学びが必要となるため、そうした学びを通して自分も成長していくことが可能となるのです。
データドリブンな文化の中心がデータだとすれば、データインフォームドな文化の中心は人間だということです。
これからデータを使っていこうとする方、またはこれまでデータを使ってみたがいまいち成果が出なかった、逆に混乱したという方、ぜひデータインフォームドを目指してみて下さい。
以上。
参考文献:
- How to become Data Driven - Link
- Understanding Variance - Link
- Deming's Journey to Profound Knowledge - Link
セミナー:デミング哲学 - 「深遠なる知識(知識の理論、ばらつきの理論、など)のシステム」

「データドリブン」な組織を作りたいが、うまくいかないという話をよく耳にします。
データドリブンな組織を作れないのは、本文でも述べたように「データドリブンな文化」を作ろうとするからです。データを使ってビジネスを改善したいのであれば、みなさんに目指してほしいのは「データインフォームドな文化」の形成です。
データドリブンな文化はうまくいったかどうかの判断をデータに委ねようとするのに対して、データインフォームドな文化は、自分たちのビジネスの継続的な改善のためのヒントを与えてくれる道具としてデータを使います。
データインフォームドな文化では、データを使った継続的な改善が可能となり、そうした改善を実感することでそれに携わる人間は成長を実感し、楽しくデータを使っていくことができるようになります。
それでは、どうやったら「データインフォームドな文化」を作れるのでしょうか。
実はその答えは、「統計的品質管理の父」として、日本では「デミング賞」で有名なエドワード・デミング氏が晩年書き上げた「Out of Crisis」という本の中に「System of Profound Knowledge(深遠なる知識のシステム)」としてまとめられています。
その哲学は、以下の4つからなるものです。
- 知識の理論
- ばらつきの理論
- 人間心理の理論
- システム的思考
今回のセミナーでは、データインフォームドな文化、組織を作るために知っておくべきであるこの「深遠なる知識」というデミング哲学について話をする予定です。
これから自分たちの組織にデータ文化を作りたいがどこから始めていいかわからない、またはこれまで試したがうまくいかなかった、といった悩みをお持ちの方、または、データを上手く活用できるようになりたい、データの使い方、見方を学びたいという方、ぜひご参加を検討下さい。
開催概要
日付:2024年6月19日(水)時間:18:30 - 20:00 - セミナー、20:00 - 懇親会
場所:東京丸の内
参加費:セミナー(無料)、懇親会(2,000円)
データサイエンス・ブートキャンプ・トレーニング

いつも好評のデータサイエンス・ブートキャンプですが、現在9月版への参加の申し込みを受付中です!
データサイエンス、統計の手法、データ分析を1から体系的に学び、ビジネスの現場で使える実践的なスキルを身につけていただくためのトレーニングです。
ビジネスのデータ分析だけでなく、日常生活やキャリア構築にも役立つデータリテラシー、そして「よりよい意思決定」をしていくために必要になるデータをもとにした科学的思考もいっしょに身につけていただけるトレーニングとなっています。
興味のある方は、ぜひこの機会にご参加検討ください!