LightGBMの紹介:ランダムフォレストやXGBoostとの違いとは
金融やビジネスにおける表形式のデータに対して予測モデルを構築する際に、おそらく以下の3つの主要な機械学習アルゴリズムのうちどれかを使ったことがある人は多いのではないでしょうか。
- ランダムフォレスト
- XGBoost
- LightGBM
これら3つはいずれも決定木(Decision Trees)に基づいており、どれも非常に強力な予測モデルを構築することができます。しかし、これらはそれぞれ異なる優先事項を念頭に設計されています。
ランダムフォレストはシンプルさと堅牢性を重視しています。XGBoostは高度に最適化された勾配ブースティングに焦点を当てています。そしてLightGBMは、ブースティングをより高速でスケーラブルにすることを重要としています。
それでは、どのモデルを使えばよいのでしょうか。
それは、ランダムフォレストからXGBoost、そしてLightGBMへのアーキテクチャの進化を理解すれば、自分の抱えている課題に対して適切なツールを選べるようになります。
LightGBMが解決するために設計された課題
2010年代半ばまでには、勾配ブースティング(Gradient Boosting)は表形式データに対する予測モデリングにおいて、最も強力な手法の一つであることがすでに証明されていました。
特にXGBoostは、多くの機械学習コンペティションを席巻した後、非常に高い人気を博していました。
しかし、データセットが拡大し続けるにつれ、データサイエンティストは新たな課題に直面し始めました。
- 数百万行に及ぶデータセット
- 数千の変数を持つ特徴量セット
- ワンホットエンコーディングによって生成される疎な(スパースな)特徴量
- 長い学習時間
勾配ブースティングは強力でしたが、計算負荷が非常に高いという側面もありました。
そこで、Microsoftの研究者たちは、大規模なデータセットをより効率的に処理できるようにアルゴリズムの一部を再設計することに着手しました。
その結果、2017年にリリースされたのがLightGBMです。
なぜ「LightGBM」と呼ばれるのか?
LightGBMは以下の略称です。
Light Gradient Boosting Machine
ここで使われている「Light(軽い)」という言葉は、光の速さを指しているわけではありません。
実はこの「Light(軽い)」というのは、このアルゴリズムが計算量とメモリ使用量の面で軽量であることを意味しています。
この新しいアルゴリズムを開発するにあたっての目標は、以下のような問題を解決することができる新しいタイプの勾配ブースティングアルゴリズムを作ることでした。
- より速く学習できる
- メモリ使用量を抑える
- より大規模なデータセットに対応できる
これらを実現しながら、強力な予測性能を維持することを目指したのです。
LightGBMの革新的な機能に深く踏み込む前に、これら3つ、ランダムフォレスト、XGBoost、そしてLightGBMのアルゴリズムの概念的な違いに触れてみたいと思います。
ランダムフォレスト:多数の独立した木
ランダムフォレストは、多くの木を独立して構築します。
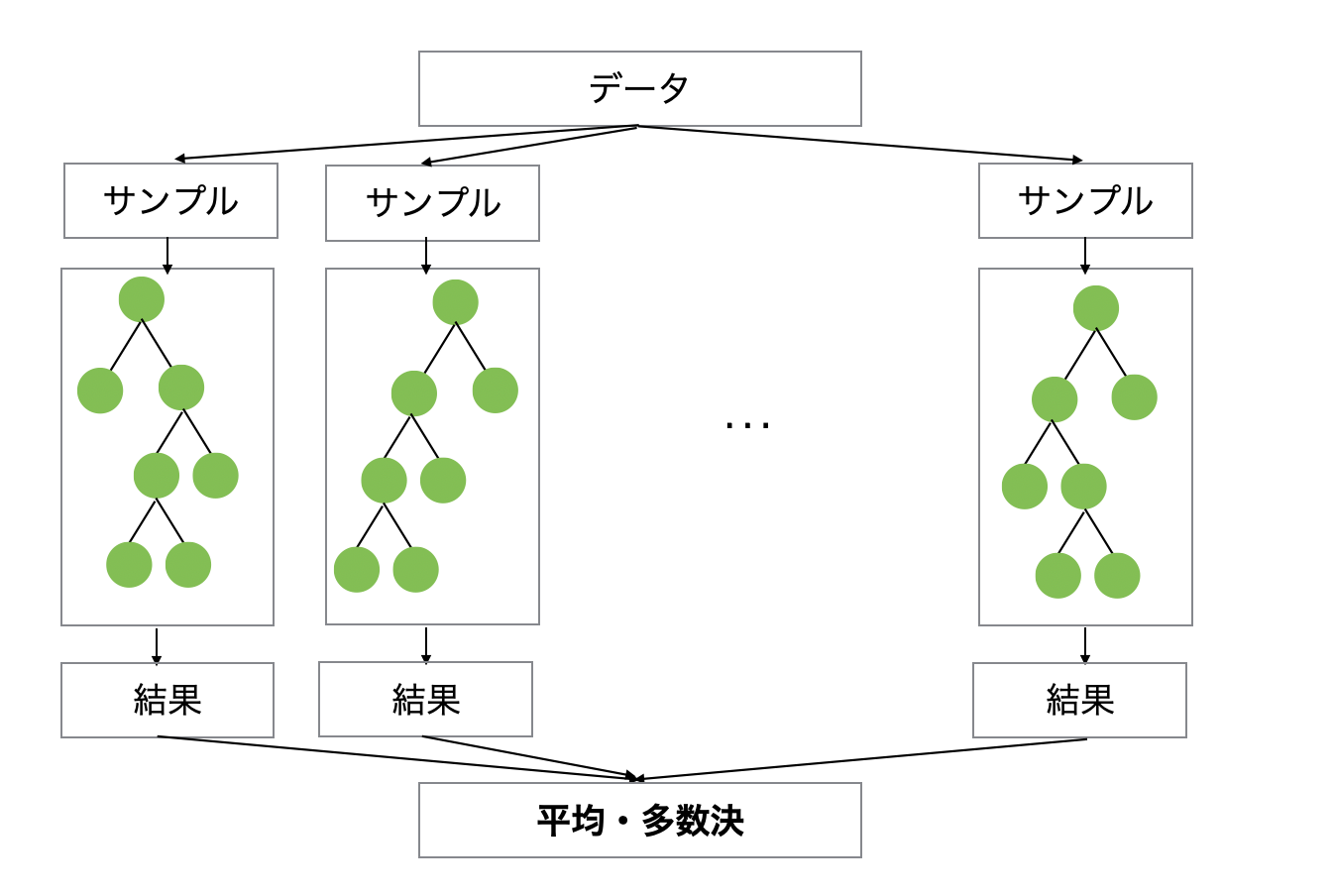
それぞれの木は以下のステップを踏みます。
- データセットをランダムにサンプリングする
- 分割時に変数(特徴量)をランダムに選択する
- それぞれの木は独自の予測を出力する
最終的な予測は、単にそれらの平均(回帰の場合)または多数決(分類の場合)によって決まります。
重要な考え方は、多数の独立した木を用いることで、単一の木(決定木)と比較して分散を抑え、安定性を向上させるという点にあります。
ただし、それぞれの木が互いに学習し合うことはありません。
XGBoost:間違いを修正する木
XGBoostは勾配ブースティング(Gradient Boosting)という手法を使用します。独立した木を構築する代わりに、前の木が犯した間違い(エラー)を修正するように、逐次的(シークエンス)に木を構築していきます。
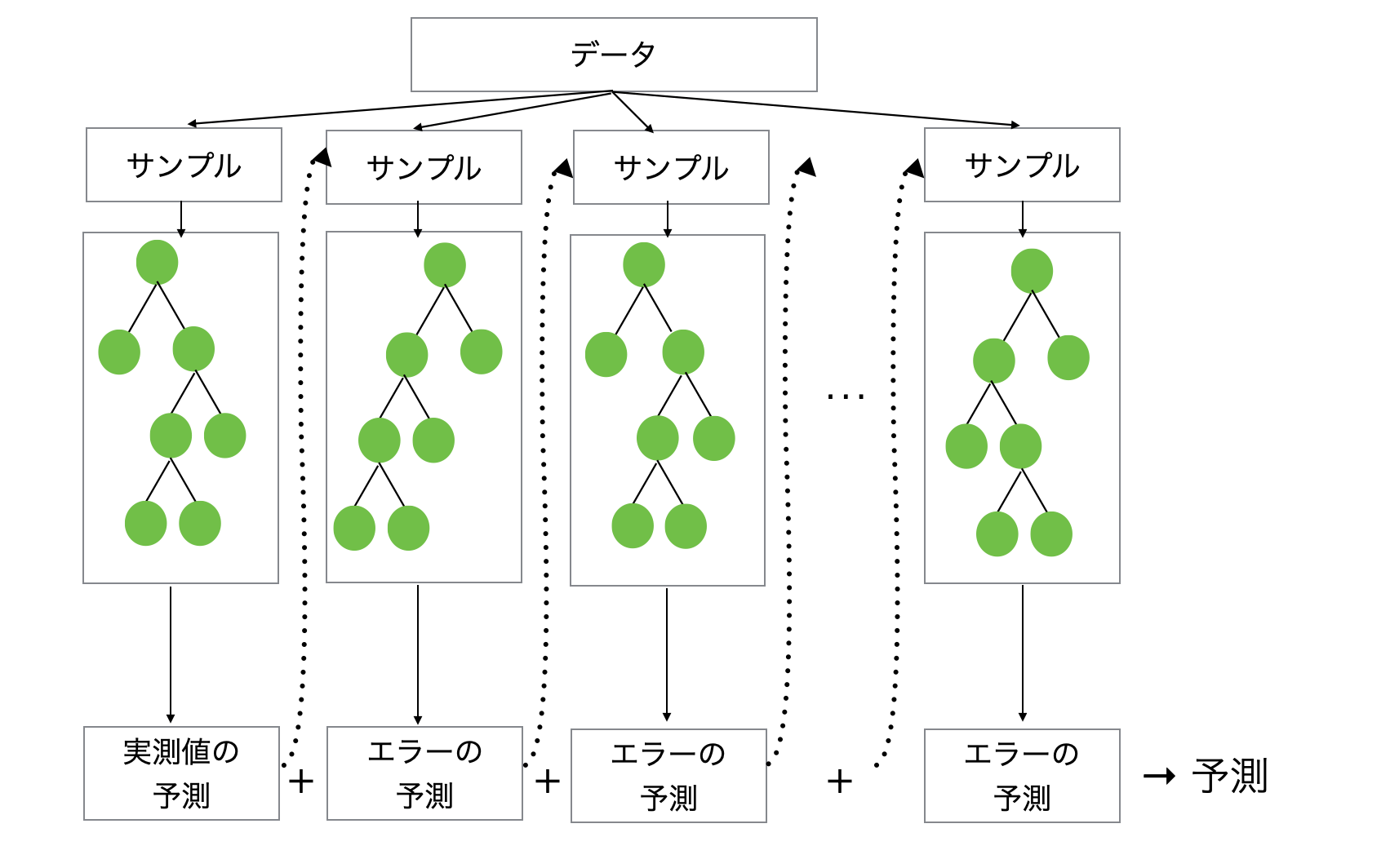
ブースティングアルゴリズムは、実質的に関数空間における勾配降下法(Gradient Descent)を実行します。
まず最初の木を構築して予測を行い、誤差(または損失)を計算します。もしそれが回帰問題であれば、誤差は実測値と予測値の差である「残差」となります。これが「勾配(Gradient)」と呼ばれます。
| 行 | 実測値 | 予測値 | 勾配(残差) |
|---|---|---|---|
| 1 | 10 | 7 | 3 |
| 2 | 15 | 14 | 1 |
| 3 | 8 | 9 | -1 |
次の木は、実測値そのものではなく、この勾配の値を予測するために構築されます。なぜなら、勾配は損失を減らすために予測をどのように動かすべきかをモデルに教えるからです。
そして、最初の木の予測値と2番目の木の予測値を組み合わせることで、モデルとしての新しい予測値とします。
prediction_new = 1つ目の木の予測結果 + 学習率 × 2つ目の木の予測結果概念的には、モデルは以下のように進化します。
1本目の木 → 最初の予測
2本目の木 → 最初の木の予測の間違いを修正
3本目の木 → これまでの木による予測の間違いを修正
4本目の木 → 継続して修正このプロセスにより、ランダムフォレストよりも一般的には精度の高いモデルが得られることが多いです。
しかし、データセットが大きくなるにつれ、このようなブースティング型の学習方法、つまりたくさんの木を一本一本順次作っていくやり方は、非常に高い計算コストがかかります。
そこで登場するのがLightGBMです。
LightGBM:スケールするための設計
LightGBMは、勾配ブースティングの基本的な考え方を変えるものではありません。
その代わりに、ブースティングアルゴリズムの以下の要素を最適化しています。
- 木の成長方法
- 行のサンプリング方法
- 分割の評価方法
- 変数(特徴量)の表現方法
これらにより、高い精度を維持しながら、非常に大規模なデータセットへのスケーリングを可能にしました。
これらの改善は、主に4つの主要な革新から生まれています。
- リーフワイズ(Leaf-wise / 葉単位)の木の成長
- ヒストグラムベースの分割
- GOSS(Gradient-based One-Side Sampling)
- EFB(Exclusive Feature Bundling)
これらを一つずつ見ていきましょう。
1. リーフワイズ(Leaf-Wise / 葉単位)の木の成長
LightGBMの最も特徴的な機能の一つが、リーフワイズ(葉単位)の木の成長です。
ランダムフォレストやXGBoostなどの従来のツリーアルゴリズムは、木をレベル(階層)単位で成長させます。
木の各レベルにおいて、同じ数のノードが展開されます。
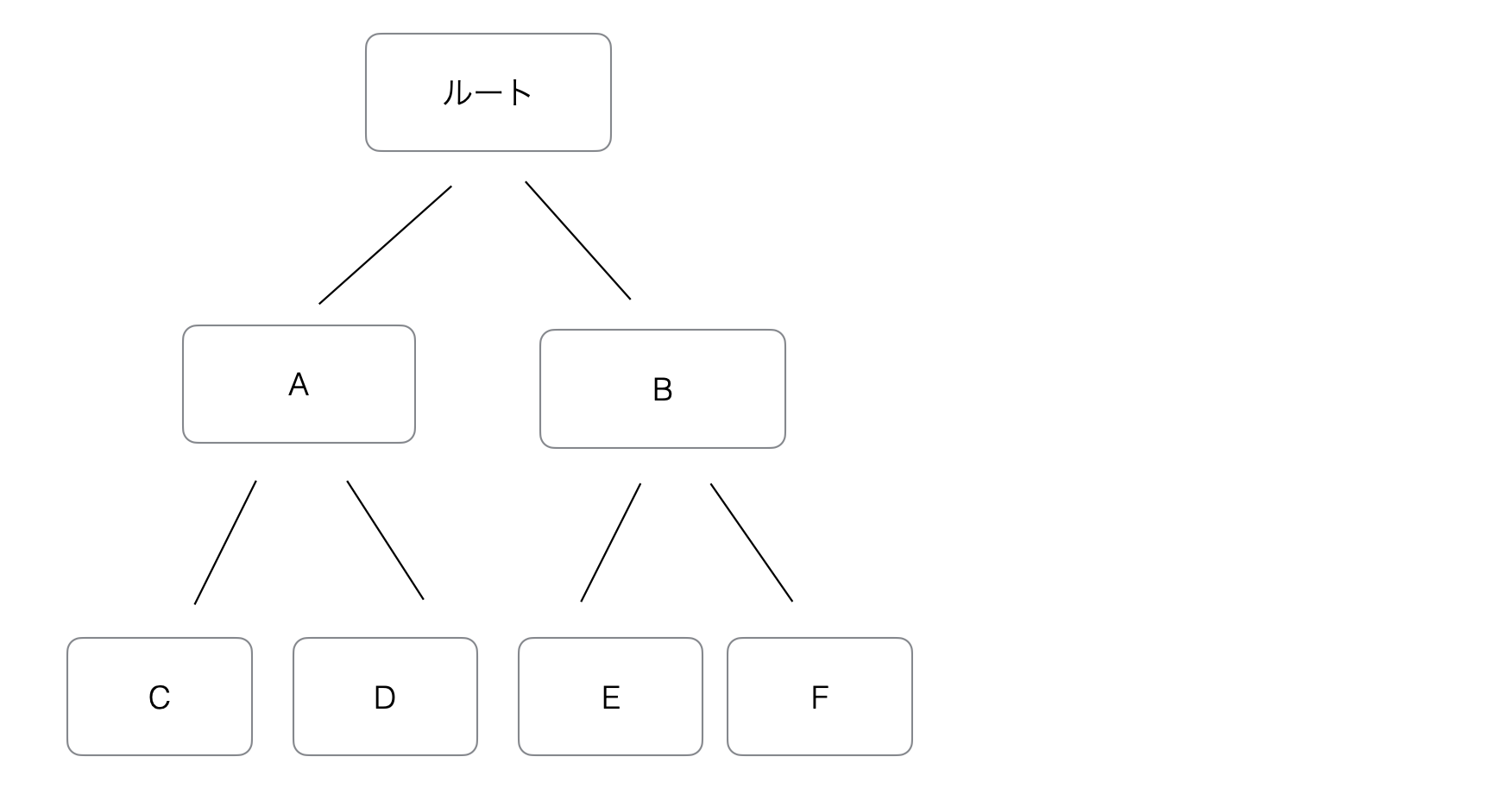
木のすべてのレベルが均等に展開され、バランスの取れた木が生成されます。これは安定しており予測可能ですが、予測の改善にあまり寄与しない枝まで展開するために計算資源を浪費する可能性があります。
LightGBMは異なるアプローチを取ります。同じ深さのすべてのノードを展開するのではなく、ロス(損失)を最も減少させる葉(リーフ)のみを展開します。
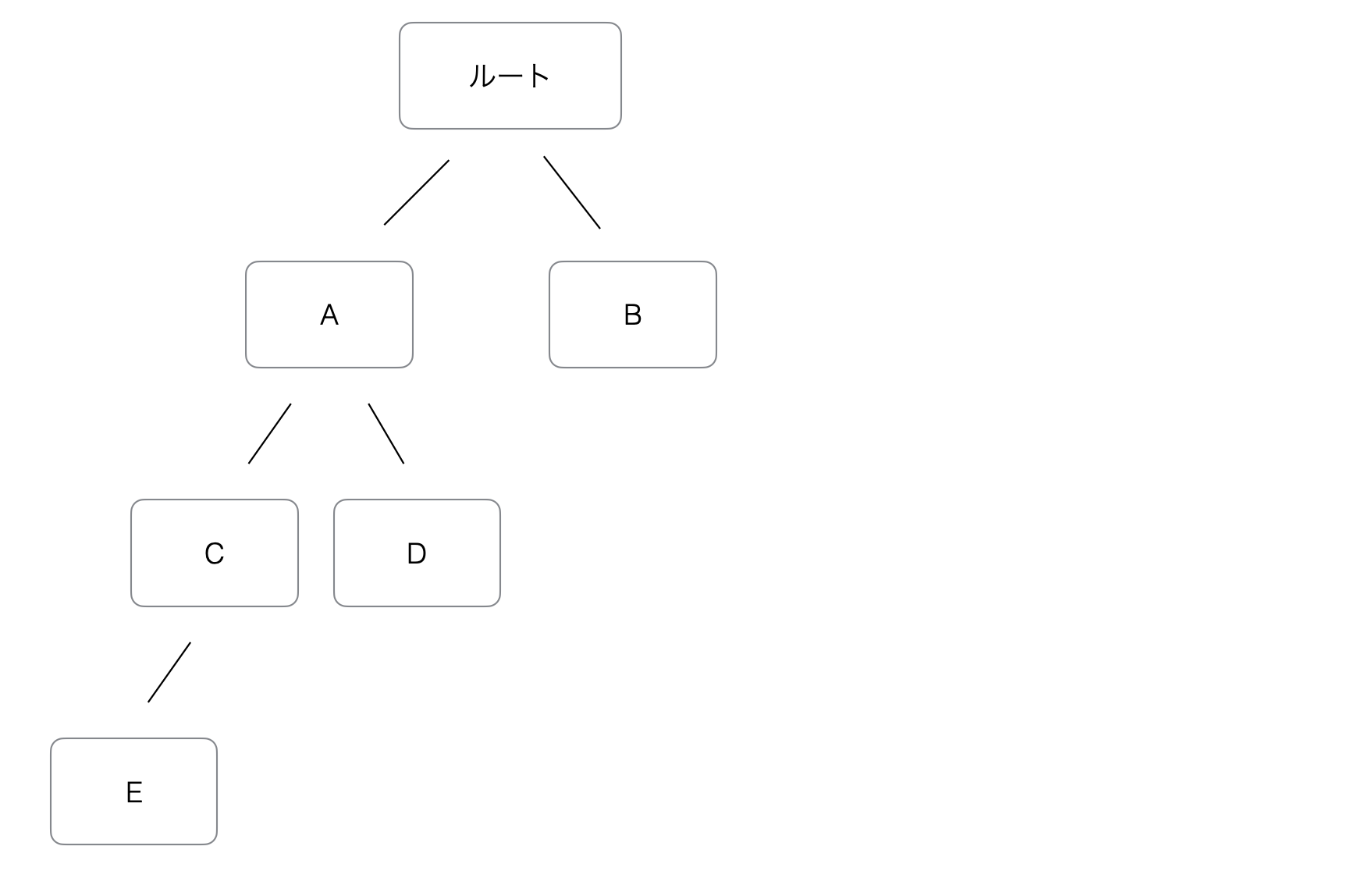
そのため、木はモデルが最も改善される場所に向かって成長することになります。
このアプローチにより、LightGBMはより少ない分割回数で高い予測性能を実現することができるようになります。
ただトレードオフとして、特定の枝が非常に深くなり過学習の可能性があるため、モデルの複雑さを制御するための
max_depth (木の深さ)や num_leaves
(葉の数)といったパラメータを調整する必要があります。
2. ヒストグラム的な分割
LightGBMにおけるもう一つの重要な最適化は、ヒストグラム的な分割です。
標準的なツリーアルゴリズムは、連続値(数値型)の変数に対して、考えられる多くの分割しきい値を評価します。
例:
Age ≤ 21
Age ≤ 22
Age ≤ 23
Age ≤ 24LightGBMは、すべてのユニークな値を評価する代わりに、ヒストグラムで使われる「等幅」を使って複数のグループに分類します。
例:
元の値:
23, 25, 27, 29, 35ビンに変換後:
20–25
25–30
30–40これにより、アルゴリズムは分割後のグループの境界でのみ木の分割に使うかどうかを評価することになります。これは、分割候補の数を劇的に減らし、学習時間が大幅に高速化することを意味します。
3. GOSS(Gradient-Based One-Side Sampling)
大規模なデータセットでブースティングモデルを学習させるには、通常すべての行を処理する必要があります。
LightGBMは、学習に使用する行数を減らすためにGOSS(Gradient-based One-Side Sampling)という手法を使います。
先程見たように、ブースティングアルゴリズムは、各行はモデルが予測をどれだけ調整する必要があるかを示す勾配値を持っています。
| 行 | 実測値 | 予測値 | 勾配(残差) |
|---|---|---|---|
| 1 | 10 | 7 | 3 |
| 2 | 15 | 14 | 1 |
| 3 | 8 | 9 | -1 |
- 大きな勾配を持つ行は、モデルが大きな誤差を出している予測を表します。
- 小さな勾配を持つ行は、すでにうまく予測されています。
XGBoostを含む一般的なブースティングアルゴリズムはデータをランダムにサンプリングしますが、LightGBMはこの勾配情報を使ってデータをサンプリングします。
- 大きな勾配を持つすべての行を保持する
- 小さな勾配を持つ行に対しては一部(サブセット)のみを保持する
例えば、100,000行のデータがあったとすると、勾配値の上位20%にあたる20,000行のデータは全て保持し、残りの80,000行についてはそのうちの10%(8,000行)のデータをサンプルします。
このようにして、100,000行全てのデータを使う代わりに、サンプルした28,000行だけを使って学習することになるので、重要な学習シグナルを維持しながら、計算量を大幅に削減できるのです。
4. EFB(Exclusive Feature Bundling)
現実世界において使われるデータの多くは、カテゴリ変数を含みます。そしてその多くは、内部的にワンホットエンコーディングされることになるため、高次元で疎な(スパースな)変数となります。
例えば、赤、青、緑と言った値を持つ「色」という変数であれば、数値で表すために以下のように変換することになります。
| 行 | 赤 | 青 | 緑 |
|---|---|---|---|
| 1 | 1 | 0 | 0 |
| 2 | 0 | 1 | 0 |
| 3 | 0 | 0 | 1 |
それぞれの値が独立した変数(列)となるように変換されるます。
ただこれらの変数は排他的であり、各行で1がつくのはこれらのうち必ず一つだけです。
そこで、LightGBMはこれらを個別に扱うのではなく、一つの変数として束ねます(バンドル)。
元:
| 行 | 赤 | 青 | 緑 |
|---|---|---|---|
| 1 | 1 | 0 | 0 |
| 2 | 0 | 1 | 0 |
| 3 | 0 | 0 | 1 |
束ねた後:
| 行 | 色バンドル |
|---|---|
| 1 | 1 |
| 2 | 2 |
| 3 | 3 |
これで、アルゴリズムは3つではなく1つの変数に対して分割を評価すればよくなります。
これにより変数の次元が削減されるため、学習時間が高速化されます。
こうしてLightGBMがスケーリングと高速化を実現するための4つの手法を見てきましたが、その効率性とスケーラビリティにより、LightGBMは表形式データを扱う多くの機械学習タスクにおいて、今日でも非常に人気のある選択肢となっています。
どのモデルをいつ使うべきか?
さて、これまでランダムフォレスト、XGBoost、そしてLightGBMといったツリー系のモデルの進化を見てきたましたが、どのモデルを使うのが良いのでしょうか。
最新のLightGBMを使えばよいではないか、という意見もあるかもしれませんが、そう単純でもありません。というのも、それぞれのアルゴリズムにはそれぞれの強みがあるからです。
ランダムフォレスト
ランダムフォレストは以下のような場合に適しています。
- シンプルなベースラインが欲しいとき
- データセットが比較的小さいとき
- 最小限のチューニングで済ませたいとき
XGBoost
XGBoostは以下のような場合に適しています。
- データセットが中規模のとき
- 強力な予測性能を求めているとき
- 安定性と広範なチューニングオプションが重要なとき
LightGBM
LightGBMは特に以下のような場合に威力を発揮します。
- データセットが大規模なとき
- 変数の次元が高いとき
- 変数が疎(スパース)なとき
- 学習時間を削減したいとき
実践的な推奨事項
機械学習プロジェクトにおける一般的なワークフローは以下の通りです。
- まずはベースラインとしてランダムフォレストから始める。
- 性能を向上させるためにXGBoostまたはLightGBMを試す。
- データセットが大きくなったり、学習時間がボトルネックになったりした場合はLightGBMを優先する。
最後に
ランダムフォレスト、XGBoost、LightGBMはいずれも決定木に依存していますが、それぞれ異なる哲学を体現しています。
- ランダムフォレストは堅牢なアンサンブルに焦点を当てている
- XGBoostは最適化された勾配ブースティングに焦点を当てている
- LightGBMは効率的でスケーラブルなブースティングに焦点を当てている
これらの違いを理解することは、適切なツールを選択する助けとなります。また、なぜLightGBMが現代の機械学習において重要なアルゴリズムになったのかも理解できるようになります。
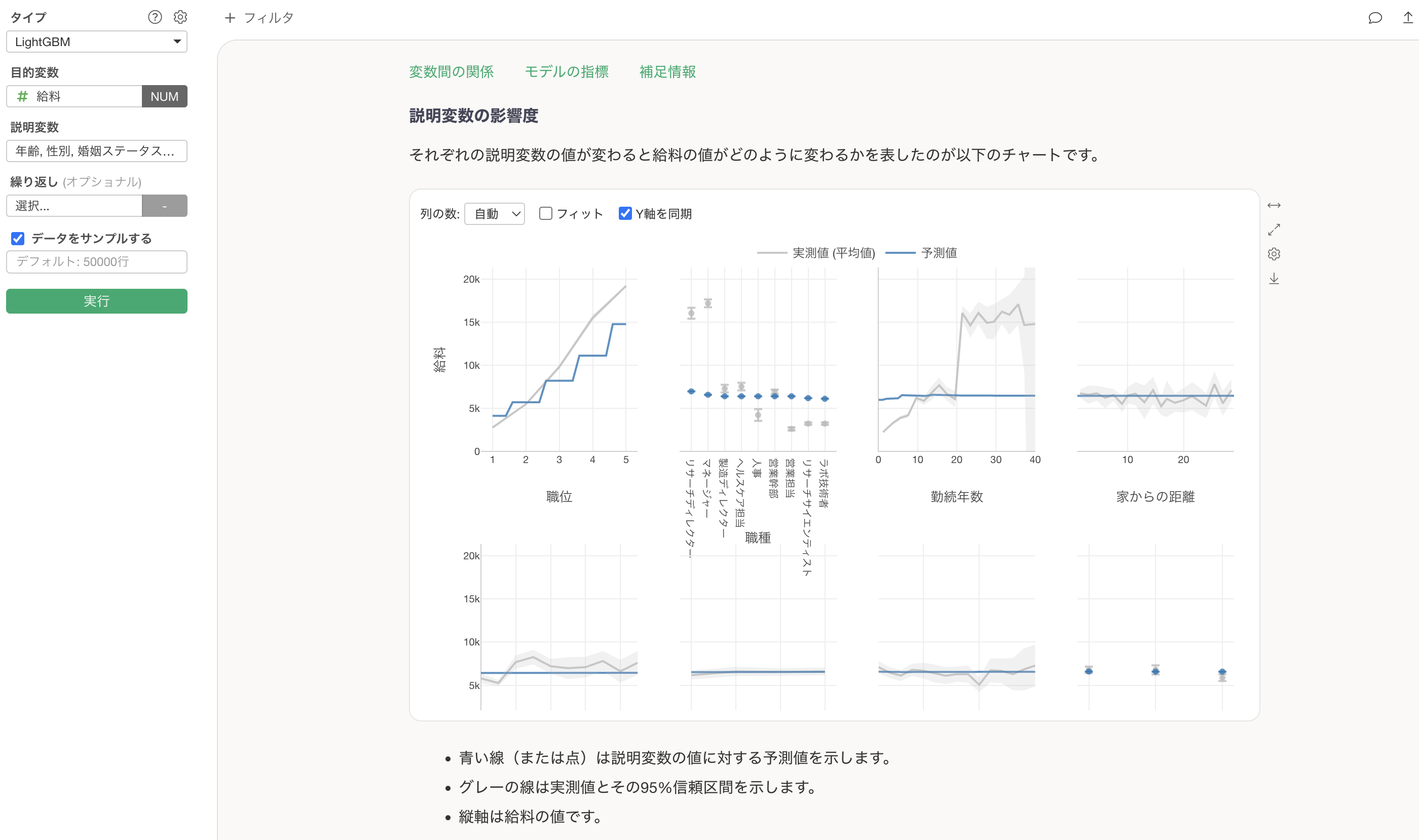
ExploratoryでLightGBMを試す
Exploratory v14.5以降のバージョンでLightGBMを試すことができます。
- アナリティクスビューに移動。
- 「LightGBM」を選択。
- 「目的変数」を選択。
- 「説明変数」を選択。
- 「実行」ボタンをクリック。
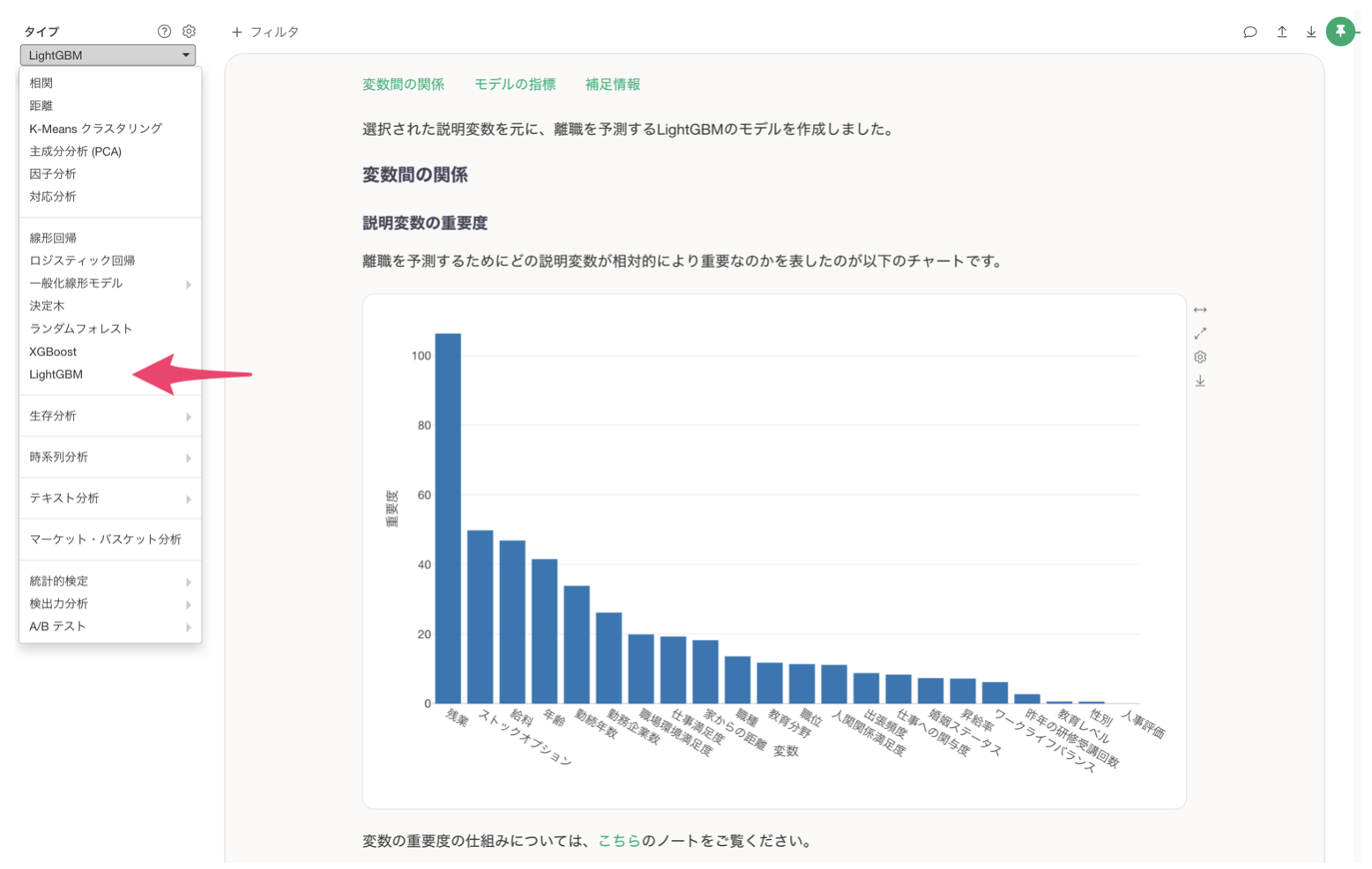
LightGBMの使い方の詳細はこちらのノートをご参照ください。
Exploratoryのダウンロード
Exploratoryの最新バージョンで、今すぐLightGBMを使い始めることができます。
👉 Exploratory v14をダウンロード
https://exploratory.io/download
まだアカウントをお持ちでない場合は、こちらからサインアップして30日間の無料トライアルを開始できます。
トライアル期間が終了している場合でも、最新バージョンを起動して「トライアルを延長」をクリックすることで、お試しいただくことができます。
ご質問やフィードバックがありましたら、お気軽に kan@exploratory.io までご連絡ください。
西田 勘一郎
Exploratory / CEO