データサイエンティスト協会 構造化データ前処理 100 本ノック with Exploratory
問1〜問10 の答案
答案全体を通して
Exploratory では R 言語が動いていますが, 解答やコード参照の説明では Python言語 のものでやります。
SQL的な視点や考え方が入るときもその都度書きたいと思います。枠の色使いは以下のような形を意識しています。
オレンジ枠 :
あか枠 :
あお枠 :
みどり枠 :
問1 : 全項目を指定行数抽出する

答案・解説はこちら
まず、サイドバー(左の黒いところ)から、df_receipt をクリックしましょう。
何もしてないとサマリー・ビューが表示されますが、テーブル・ビューに切り替えるとデータが表示されます。
クリックで表示させましょう。
問題文は 10件 表示せよとのことですが、データが見れればOKです。
記念すべき1問目がコレである理由
なぜ前処理の問題で最初にデータを見るだけの問題なの?
そう思った方はいるかもしれません。
データを見ること
という人は少なくないのです(特に社会人で)。
大学生の方に向けてですが、データ分析を主としている会社や部署などのインターンシップにいくとこのようなことは初めに言われると思います。
そのくらい大切なことなのです。
ちなみにデータを入れてまず最初に、散布図で可視化しようとか、間違ってもデータを入れてすぐに線形回帰分析なんか行おうとしている方...いずれコードを書くだけのコードランナー(コード駆動者)なデータサイエンティストになってしまいます。
既にサイエンティストですらありません。
ちなみに偏差値が日本でトップクラスに高い大学で統計科学を専攻している学生さんであっても、データを入れてまず最初に何をするの?と質問しても、統一的に同じ答えは帰ってきませんよ。
なぜなら統計科学を専攻していたとしても、誰もが学ぶことじゃないからです。
Python 解答コードはこちら
解答コードはこのようになっています。
df_receipt.head(10)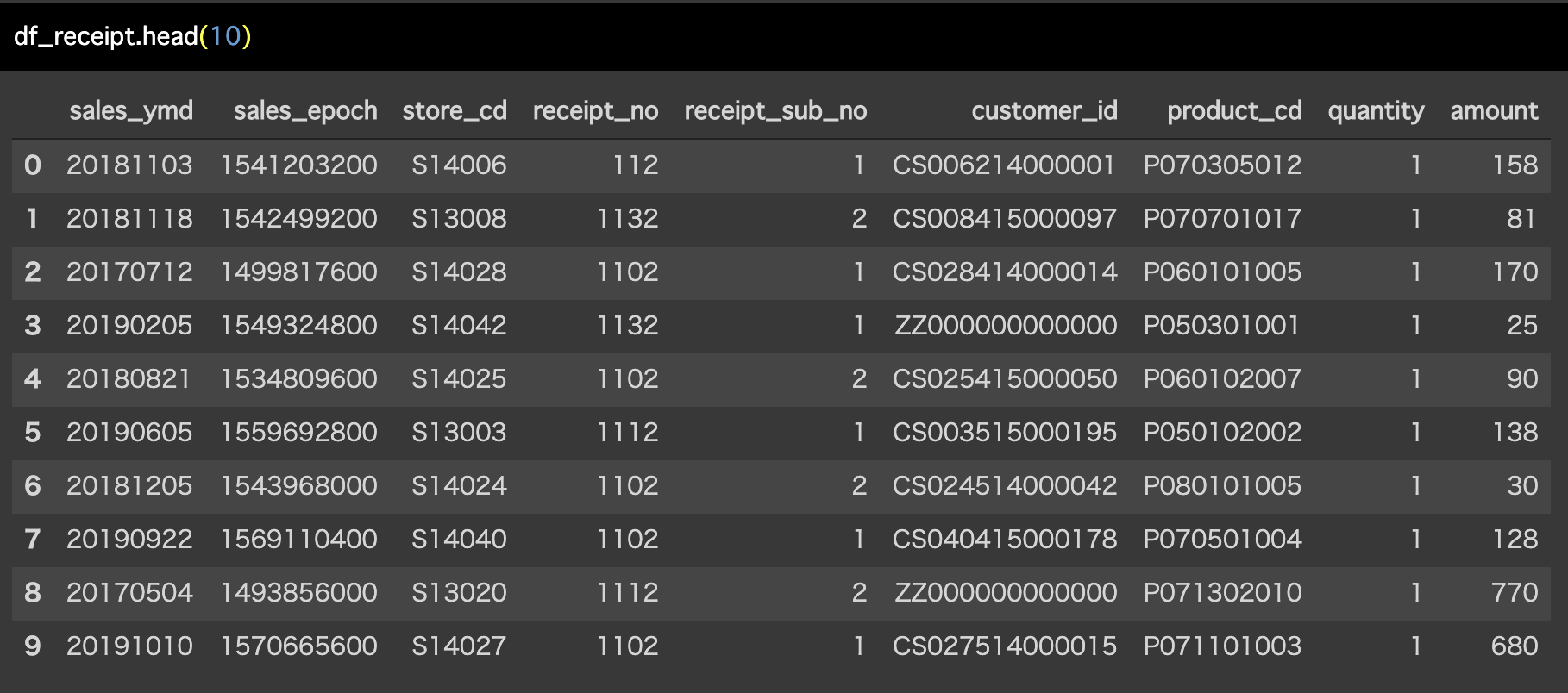 ちなみに head を tail に書き直すと末尾になります。
ちなみに head を tail に書き直すと末尾になります。
問2 : 特定の列を抽出する

答案・解説はこちら
ということです。
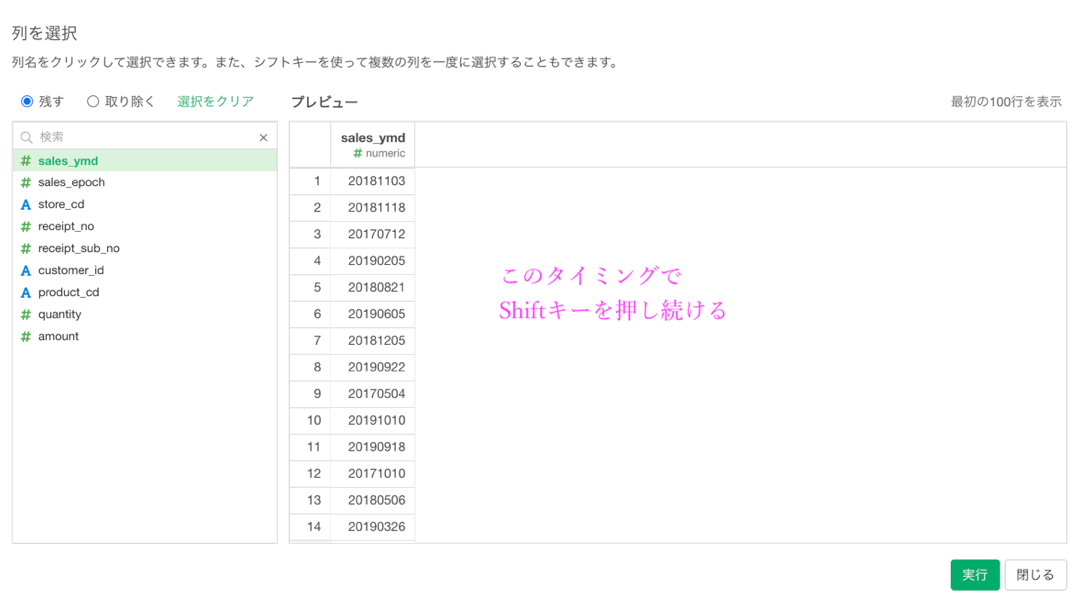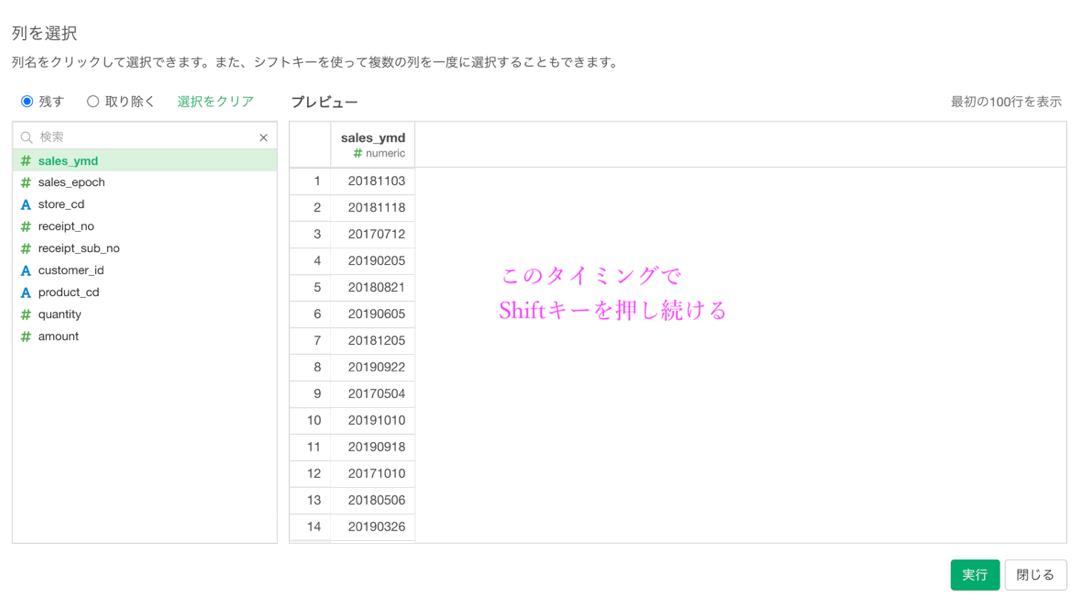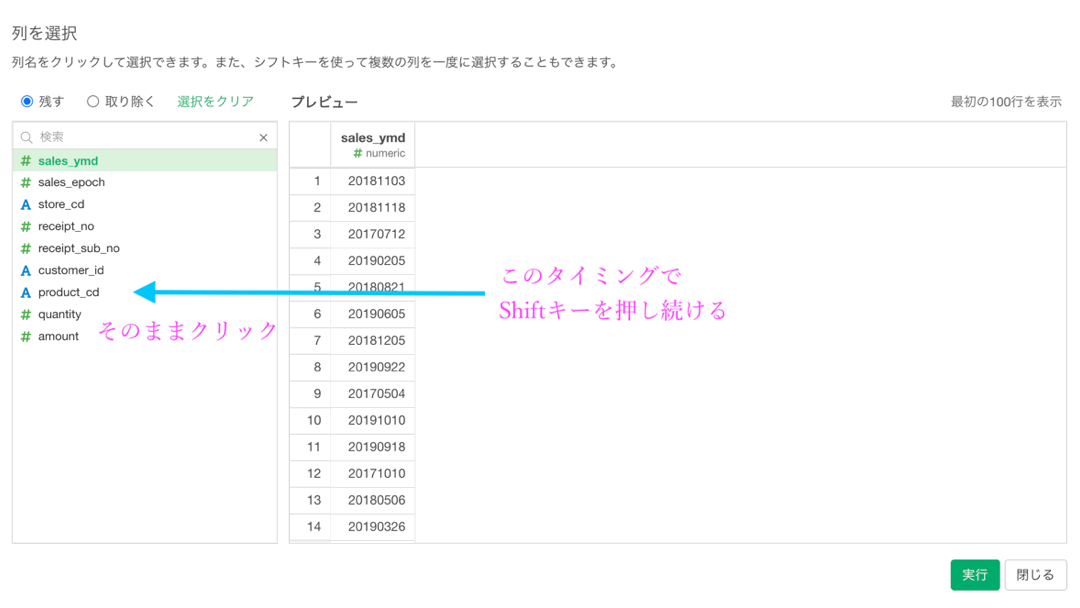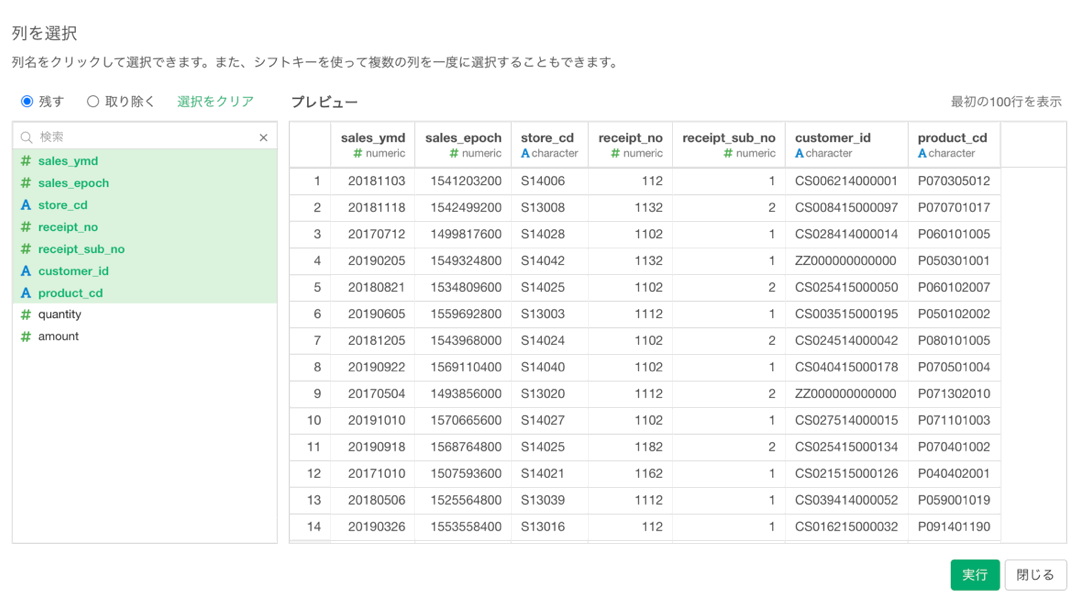
まずは以下のようにして「列を選択」というステップを追加しましょう。 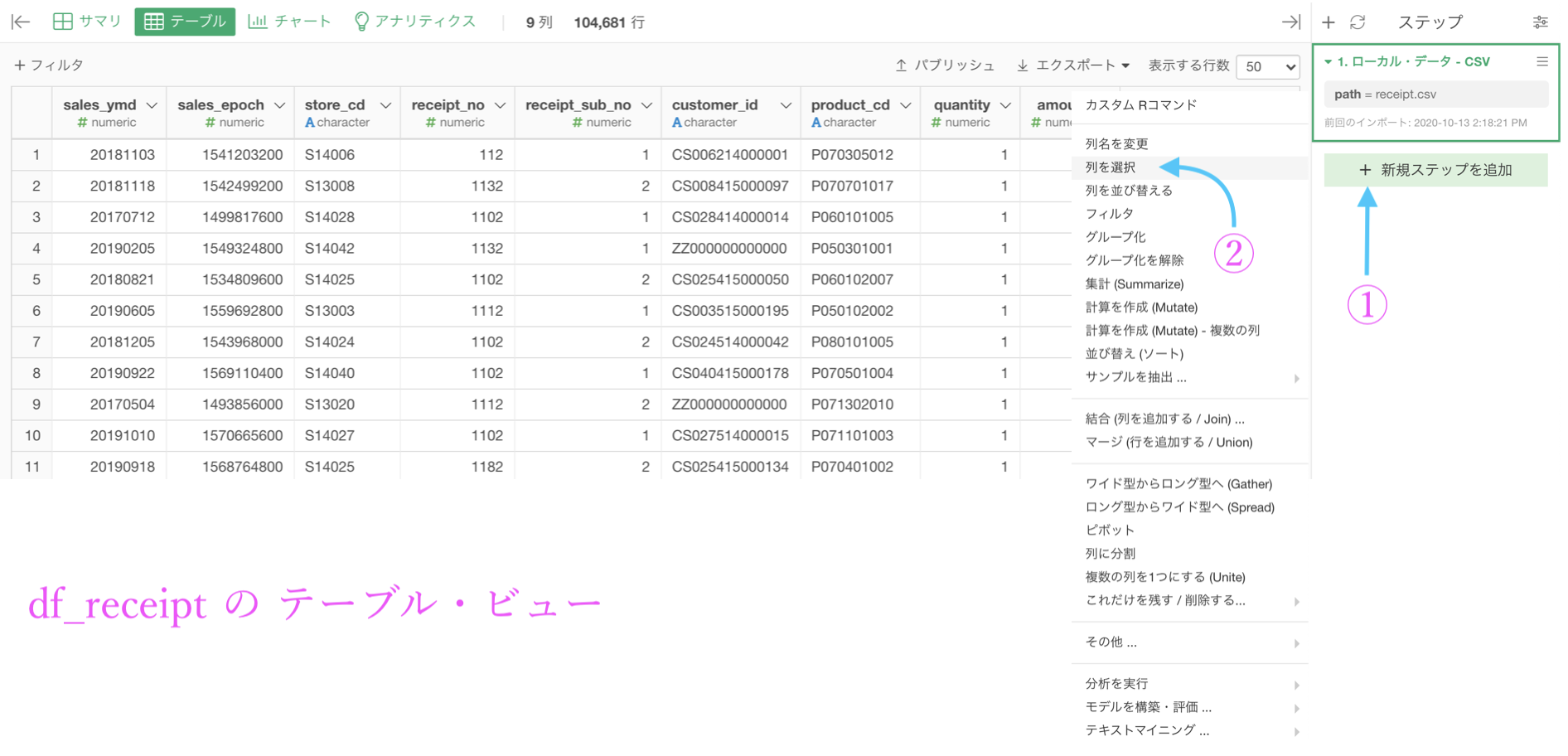
すると、新たに画面が登場するので、クリックで列を選択しましょう。 プレビューが表示されるので、何が出てくるかを予め確認しながら操作することができます。 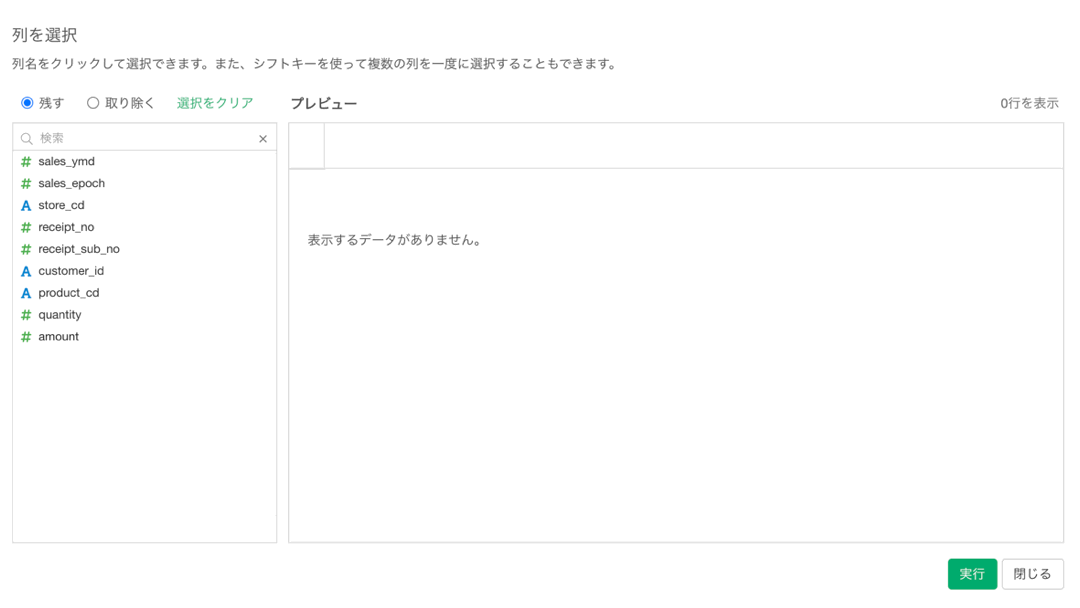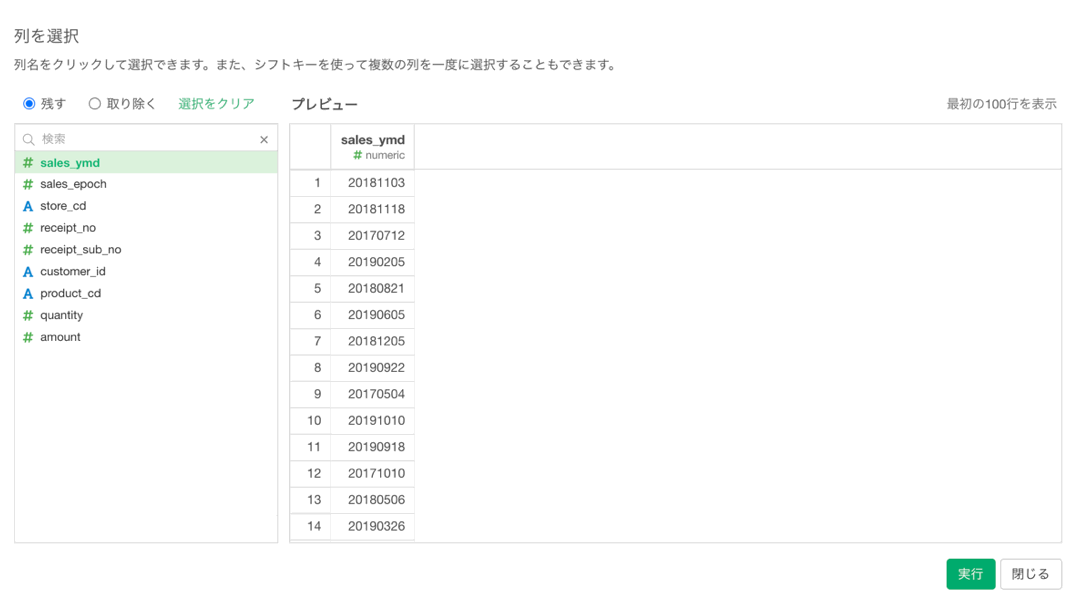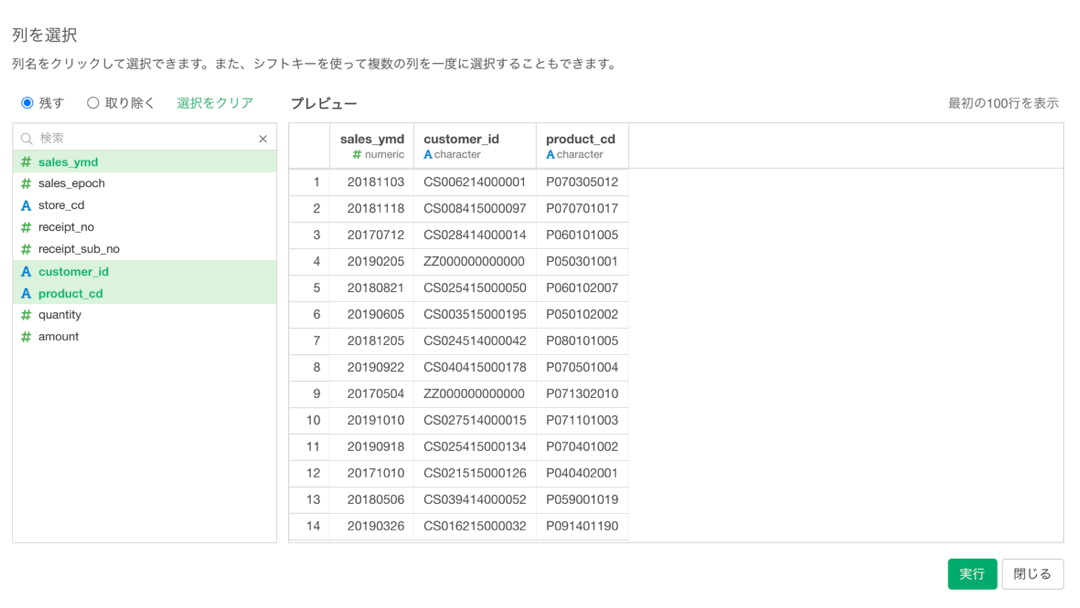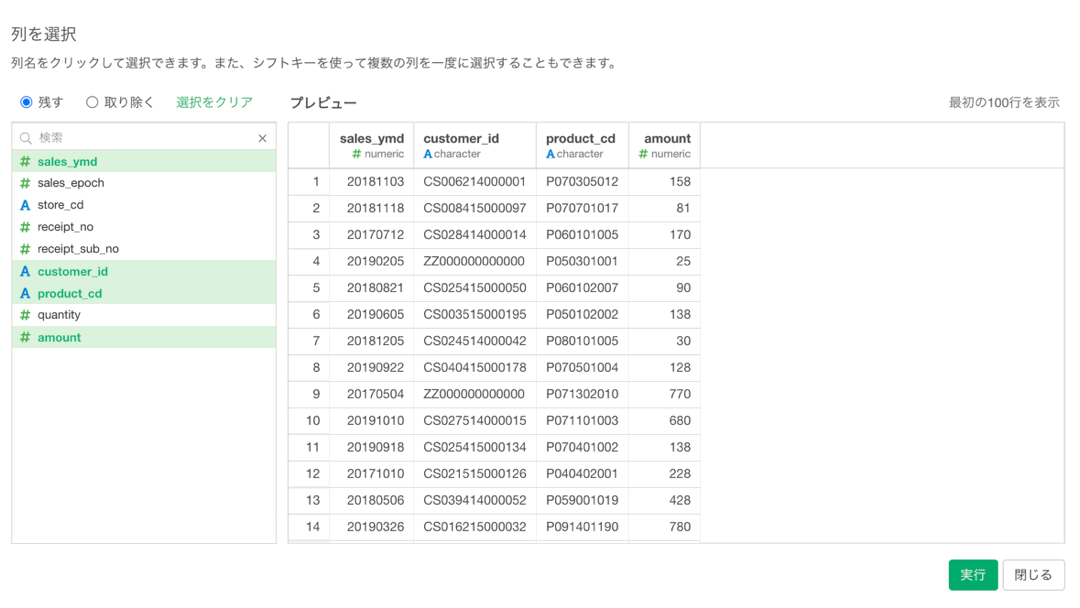 全て選択肢終わったら、左下の実行ボタンを押します。
全て選択肢終わったら、左下の実行ボタンを押します。
これで新しいステップが追加され、4列だけになりました! 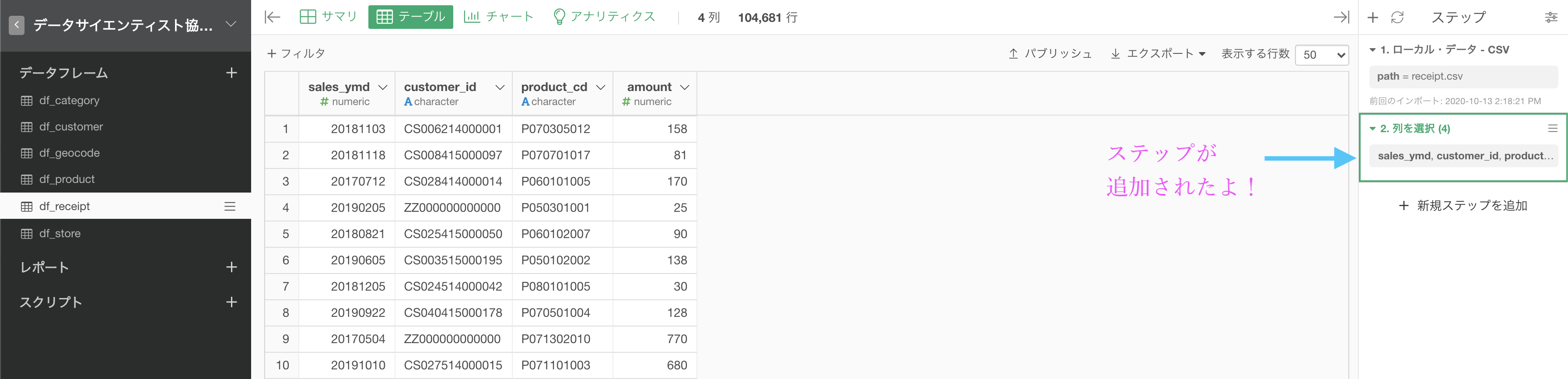
追加情報
今回の場合なら4列だけなので良いのですが、例えば連続して 10列や20列...と選びたいときはクリックしていると手が疲れてしまいます。
その際には、一気に選んでしまいましょう。
Shift キーを押しながら、端までクリックすることで間の項目も全て選択してくれます。
ステップの右上にマウスを持っていくと、画像のようにゴミ箱ボタンが出てきます。
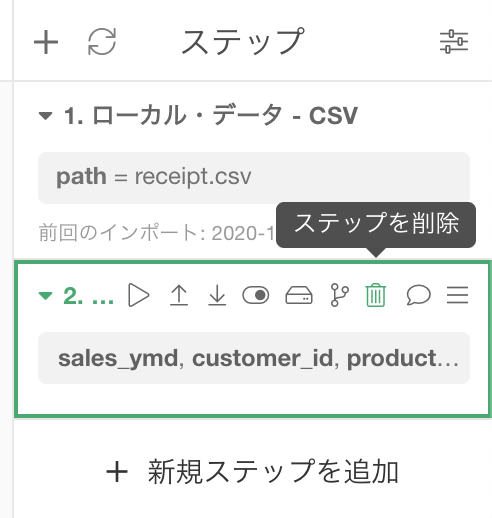
(Cmd + Z や Ctrl + Z ができない)のでご注意ください!
問題が変わるとその処理を用いることはしないケースが多いので、削除してもらって構いません。
地続きの問題でない限りは、問題毎にステップを真っ白にして解説します。
Python 解答コードはこちら
解答コードはこのようになっています。
df_receipt[['sales_ymd', 'customer_id', 'product_cd', 'amount']].head(10)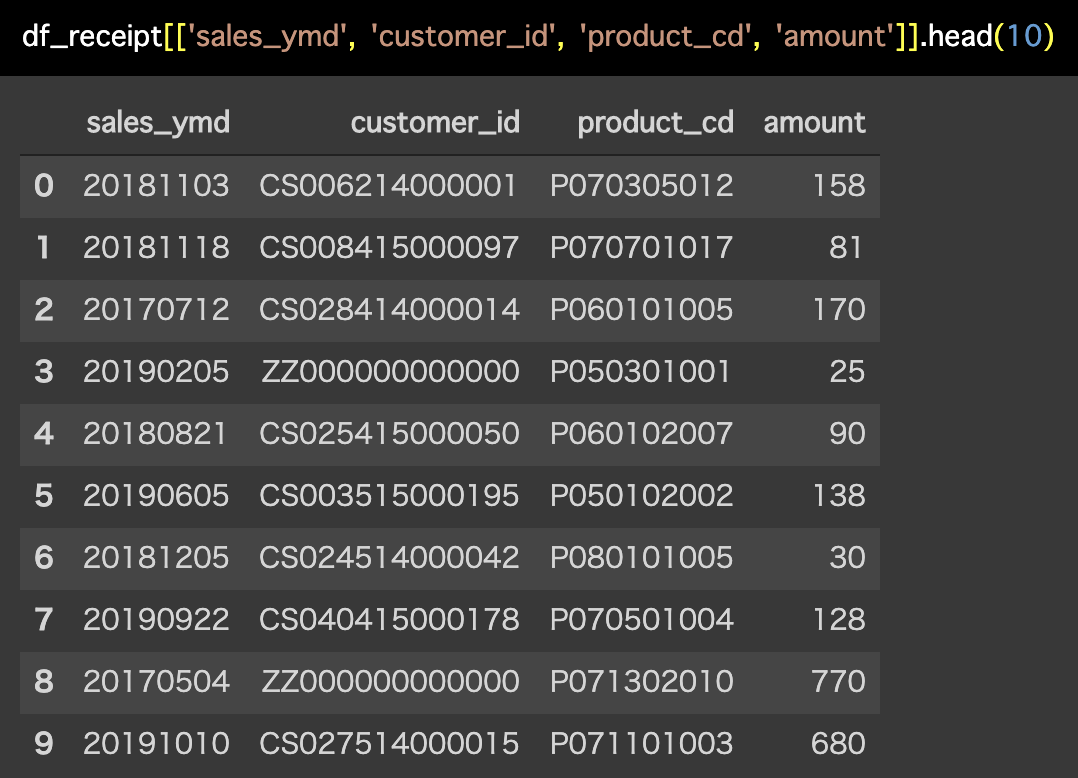
問3 : 指定列の列名を変更する

答案・解説はこちら
具体的には以下のようなことをしたいです。
sales_ymd を sales_date に変更これを行うためには、以下のようにして「列名を変更」というステップを追加しましょう。 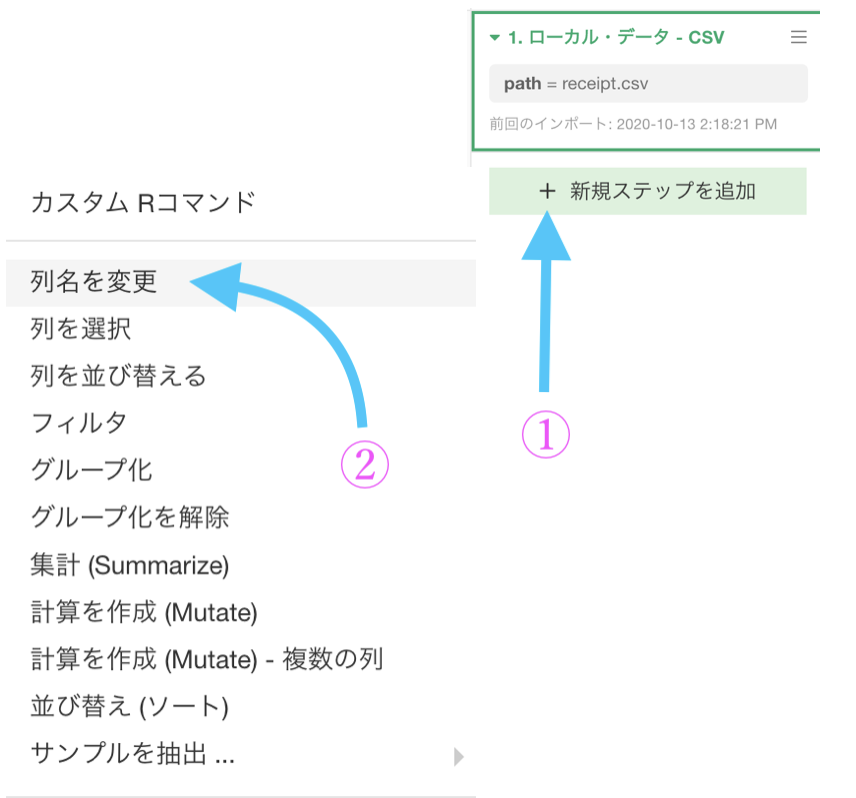
すると、新たに画面が登場するので、sales_ymd の変更後を記入する右の欄をクリックし、sales_date と入力しましょう。

以下のようになったと思います。列名が変わっていることを確認しましょう。 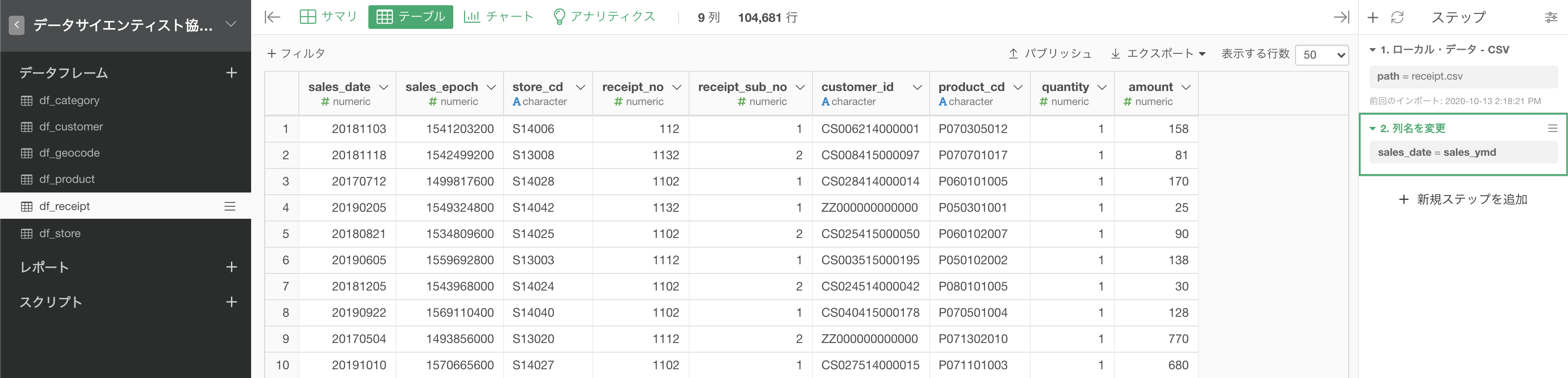
あとは問2と同じやり方で4列にすれば以下のような答案になると思います。 
追加情報
ステップは木構造であることが書かれていたのは1つ前の記事で最後に書きました。イメージは掴めているでしょうか。
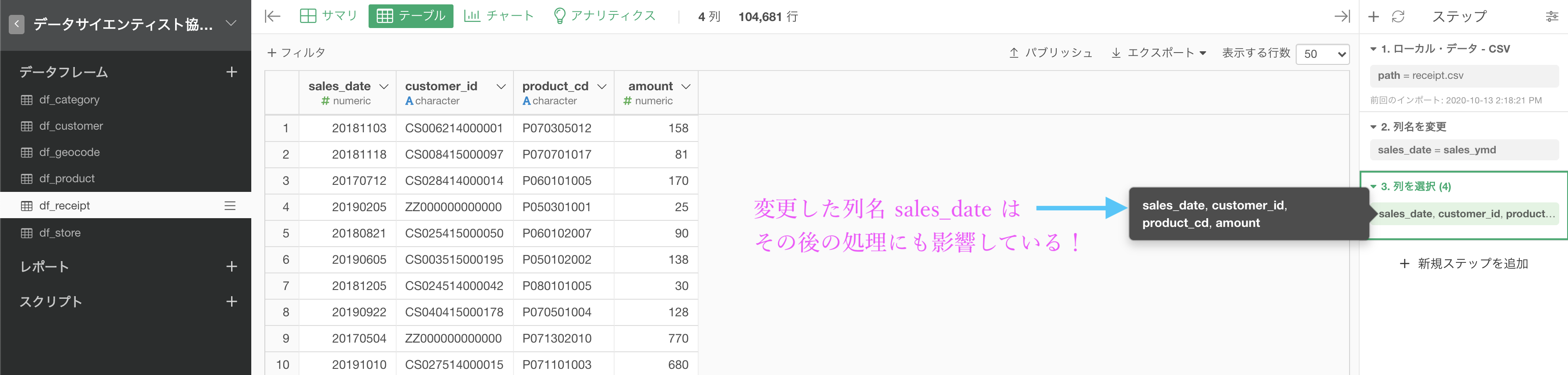
問2と同じ操作をしても、ステップの内容と異なるところとしてはその後のステップに影響しているところです。
そして、もっと大事なことは
...かもしれない(状況による)ということです。
実際は R 言語のコードが裏で動いています。
今回の場合、4列にする処理は列名を変更した後のものを使ったままなので、列名を変更したステップを消すと、そこから後ろのコードは残ったままとなり「4列にしたいけど列名が違うよ!」とエラーになります。
そこまで戻ったらまた全部のコードを打ち直さないといけない
ステップが木構造なので、振り出しに戻って打ち直しということはなくなるのです。
また、追加の処理を挟みたいときは本当によくあります。
そのときもこの木構造がなくしてはやがて非現実的になります。
木構造が頭の中でイメージできているかが決め手!
Python 解答コードはこちら
解答コードはこのようになっています。
df_receipt[['sales_ymd', 'customer_id', 'product_cd', 'amount']].rename(columns={'sales_ymd': 'sales_date'}).head(10)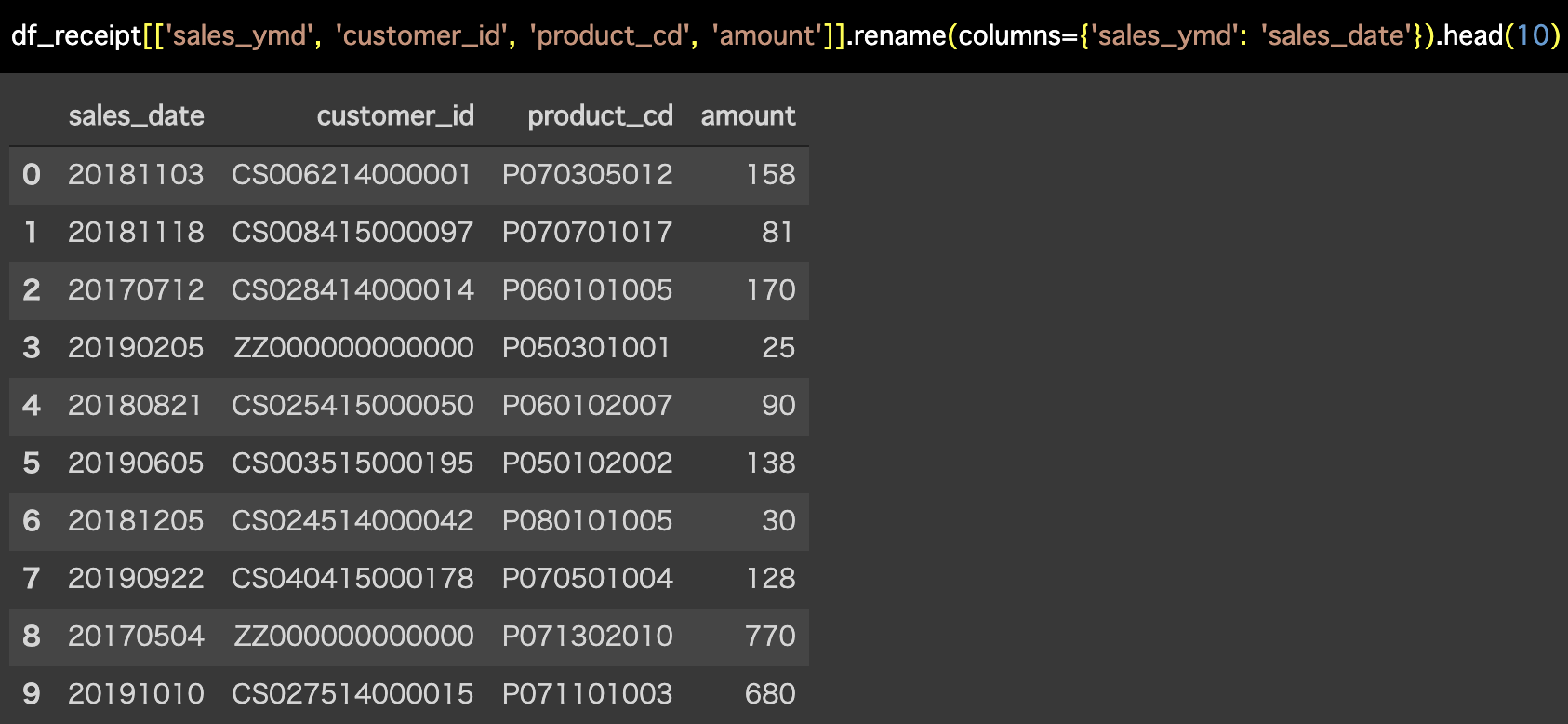
どこが大事なポイントのコードなのかがわからなくなってしまいますね。
ちなみに大事なコードは rename と head 次に rename の中身の書き方です。
ここでは詳しく触れませんので、他の解説サイト・動画などをご参考ください。
問4 : 特定条件に合致する行を抽出 (=, >, <)

答案・解説はこちら
問3と同じような文構造なので、
具体的には以下のようなことをしたいです。
customer_id という列の値が CS018205000001 だけのデータを抽出 つまり、customer_id が CS018205000001 の人だけの行(1行が1枚のレシート)をみたいです。
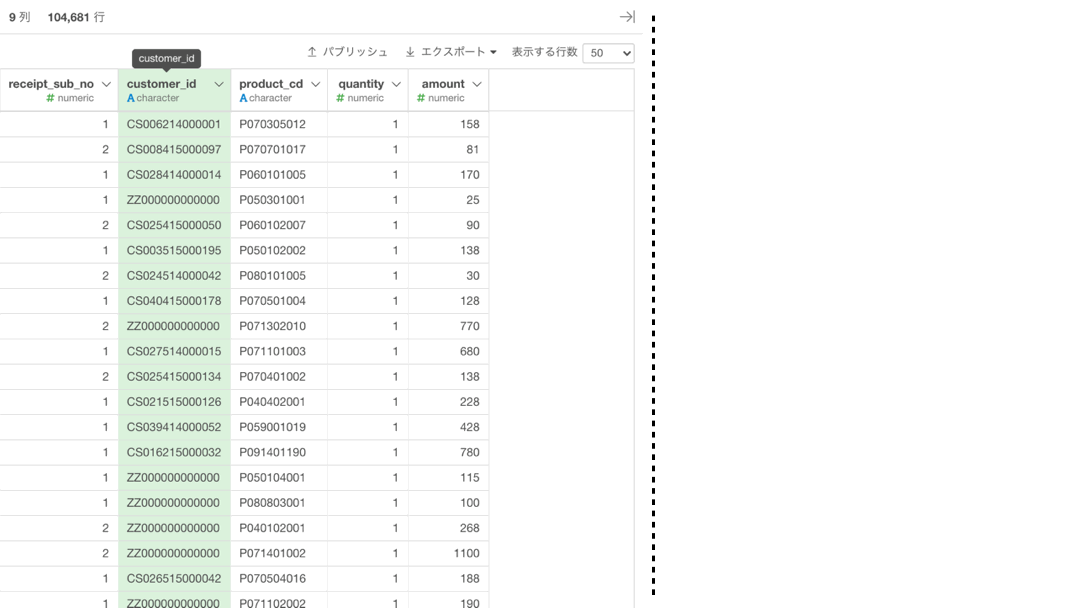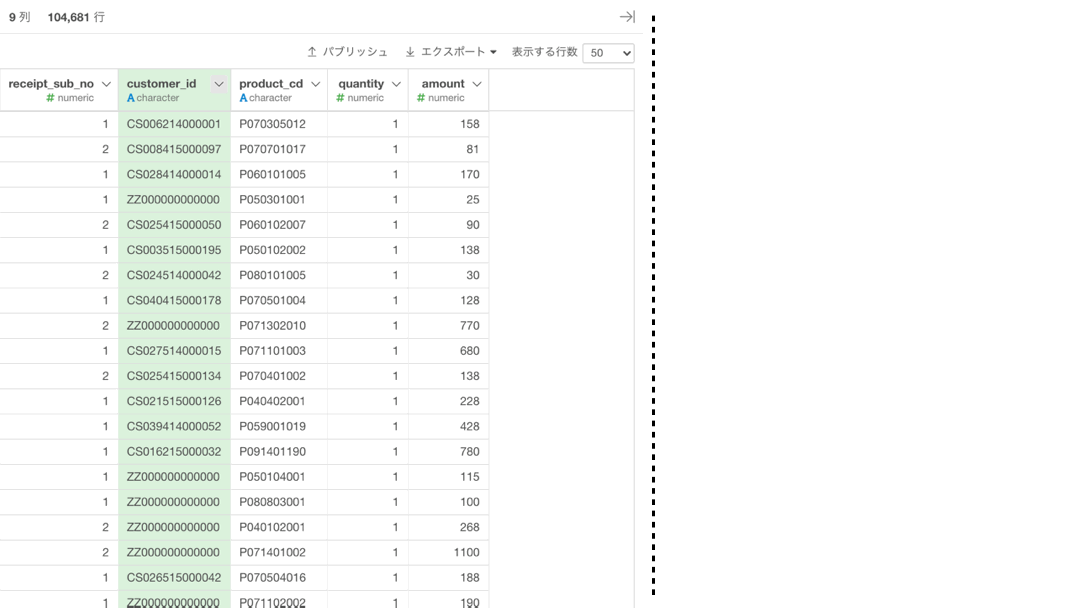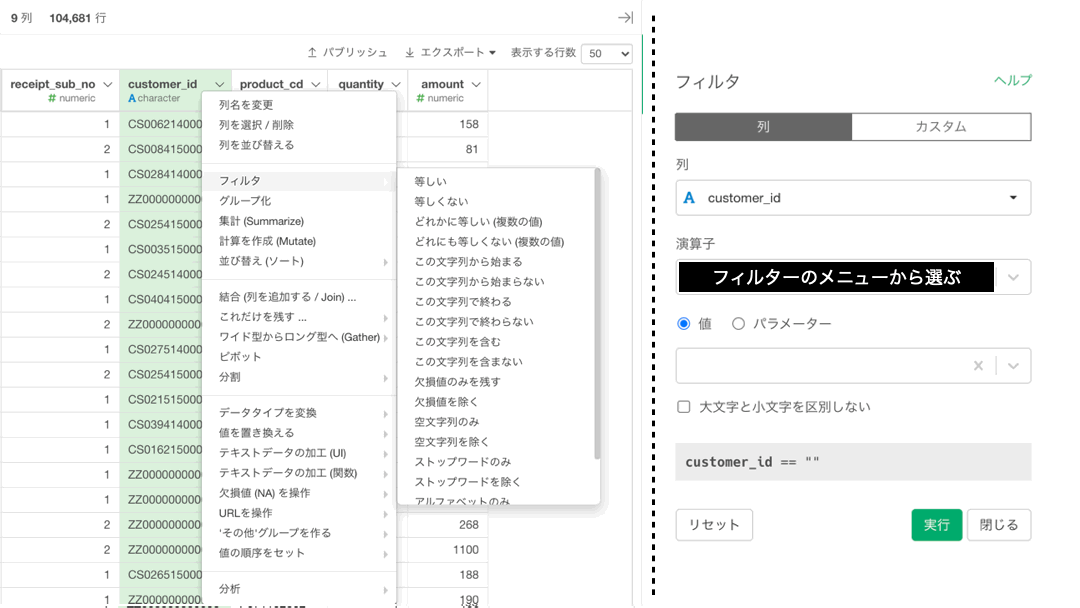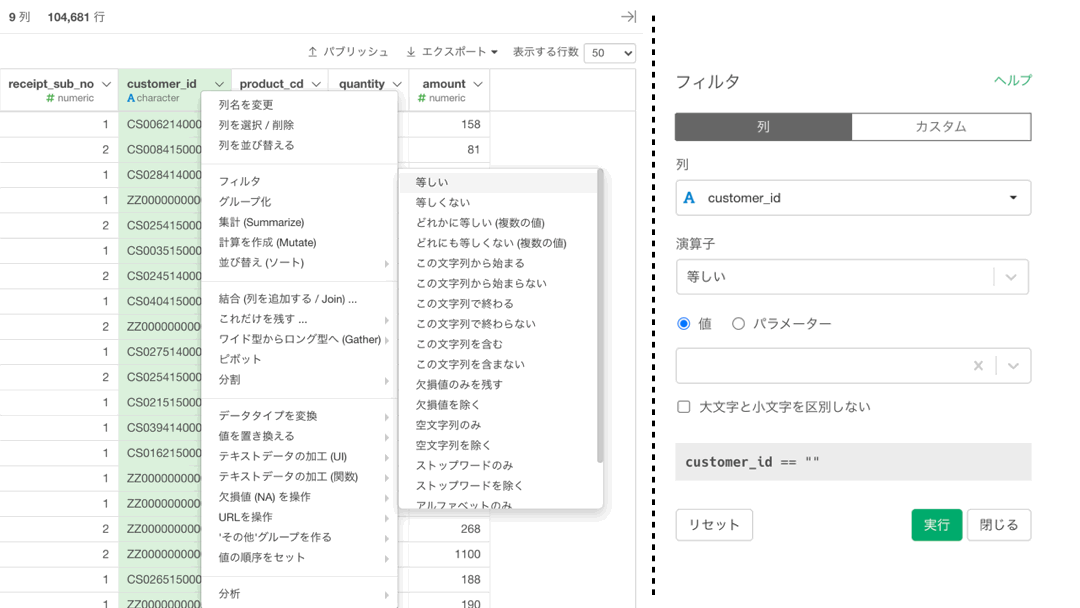
いつものように新規ステップを追加としても良いのですが、customer_id だけに処理を注目したいのであればまずはその列を直接クリックしてしまいましょう。一気に緑色になると思います。
そのあと、すぐ左のプルダウン(▽ みたいなやつ)を押してステップメニューを開きましょう。
あとは以下のように「フィルター」→「等しい」をクリックします。 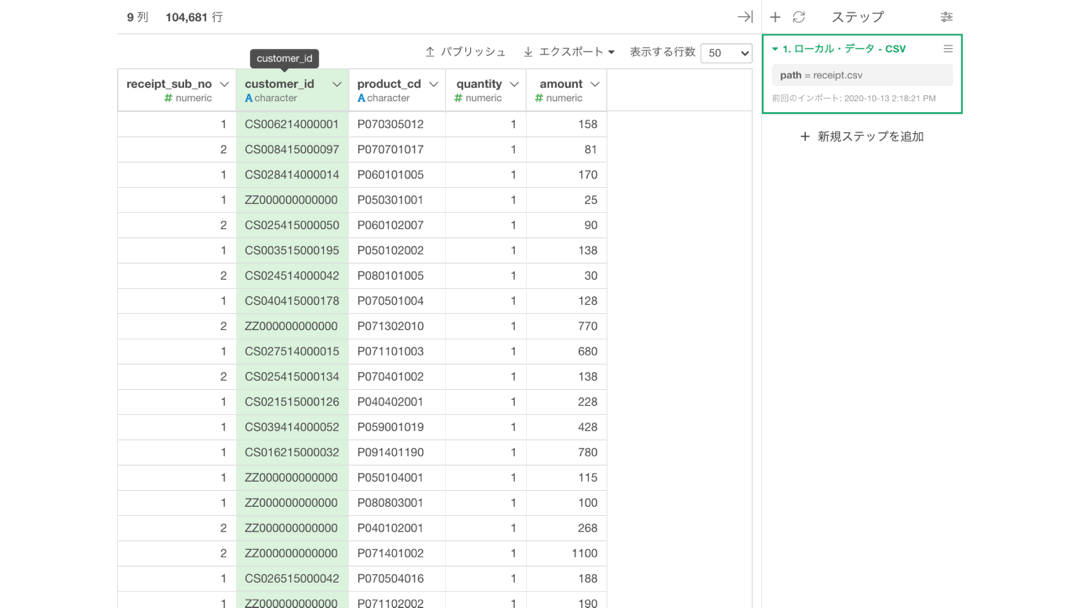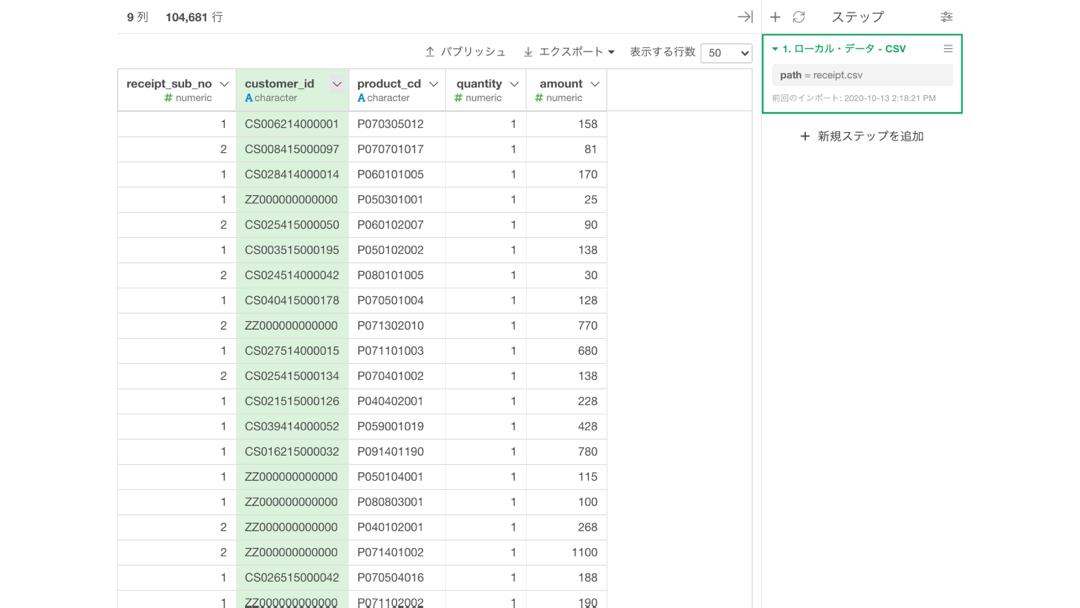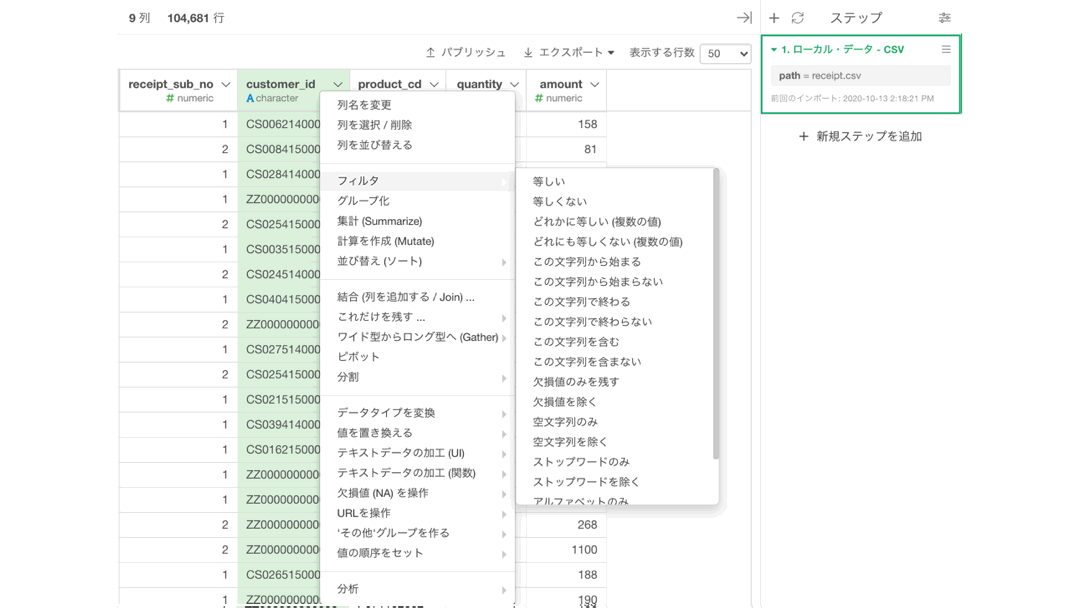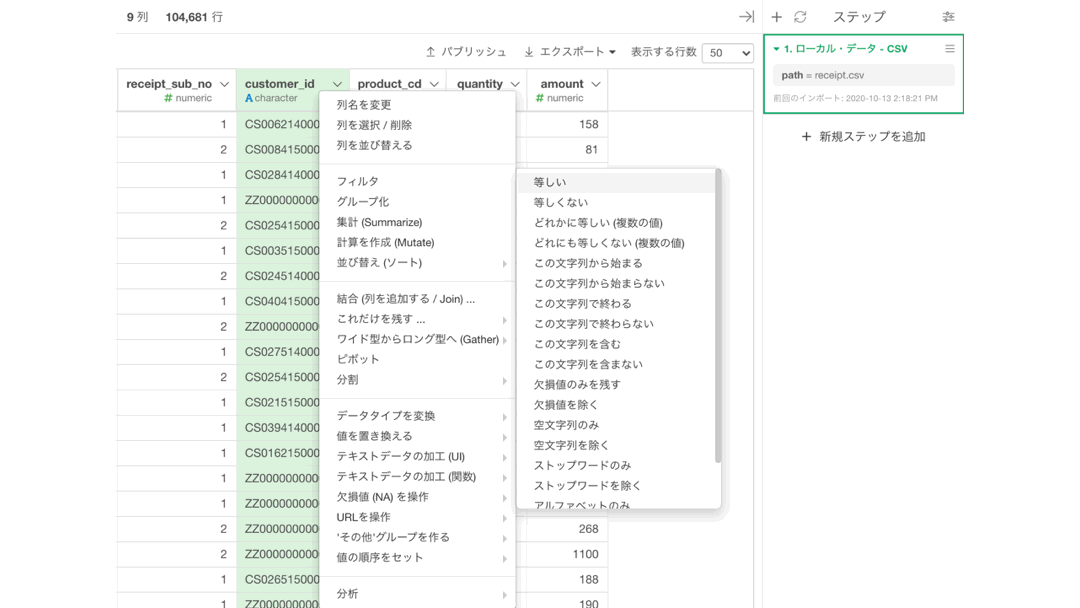
すると以下のような画面が出てくると思いますので、クリックしてから入力しましょう。 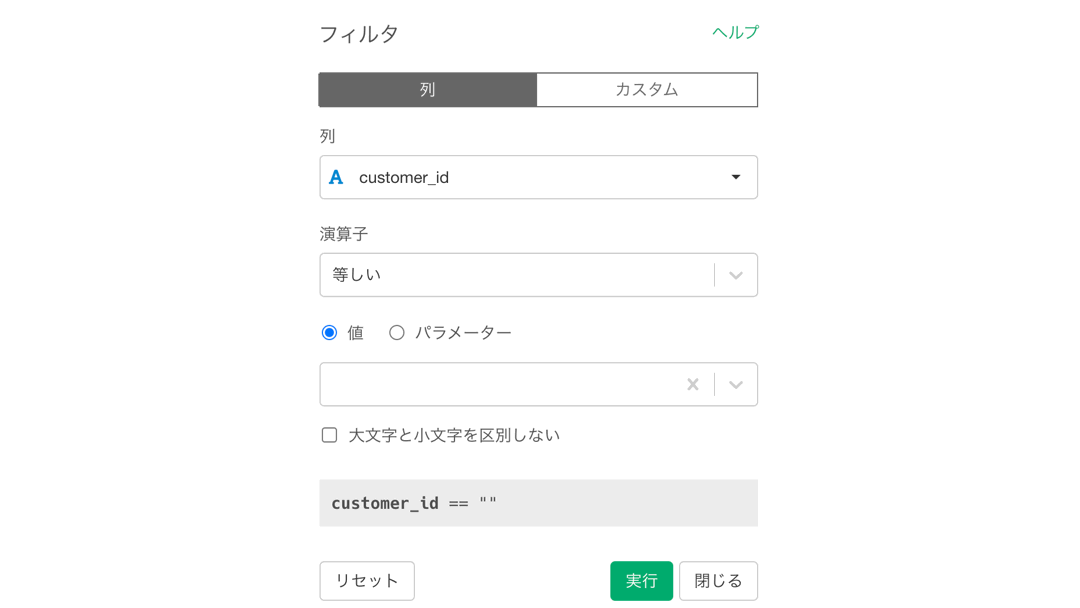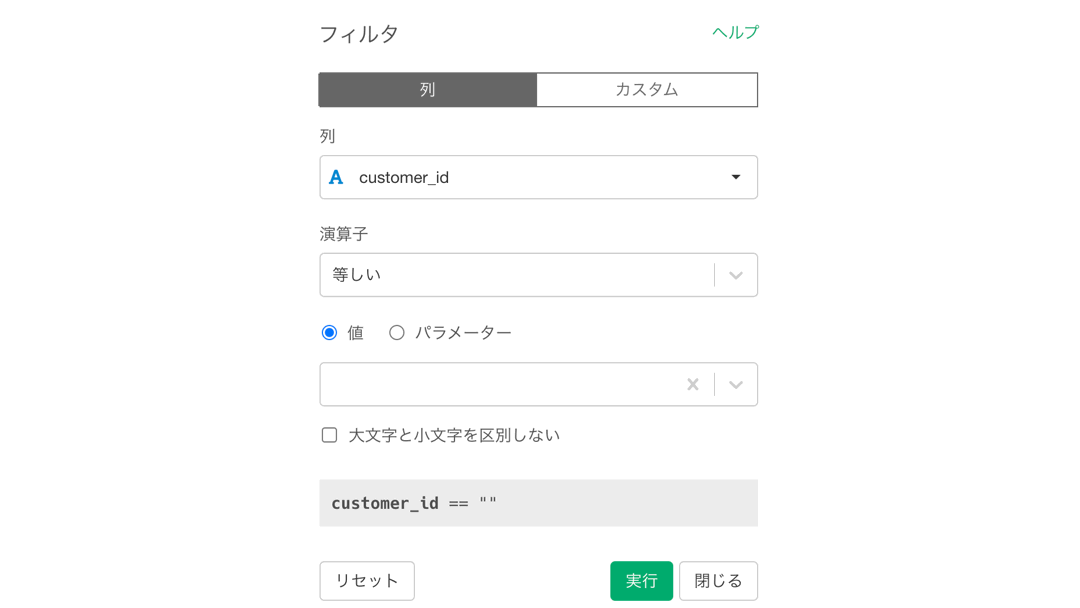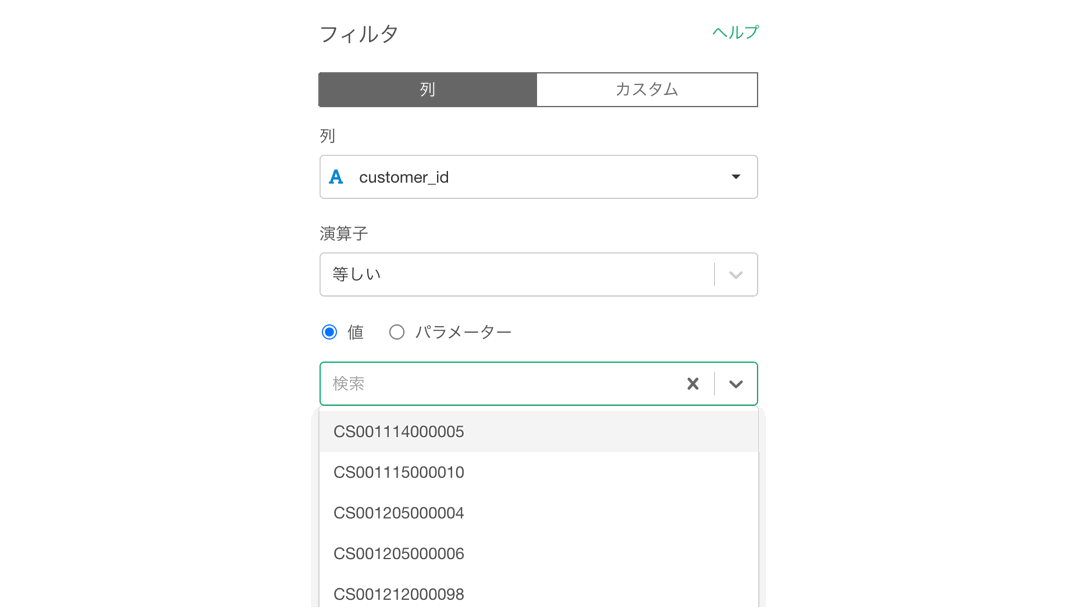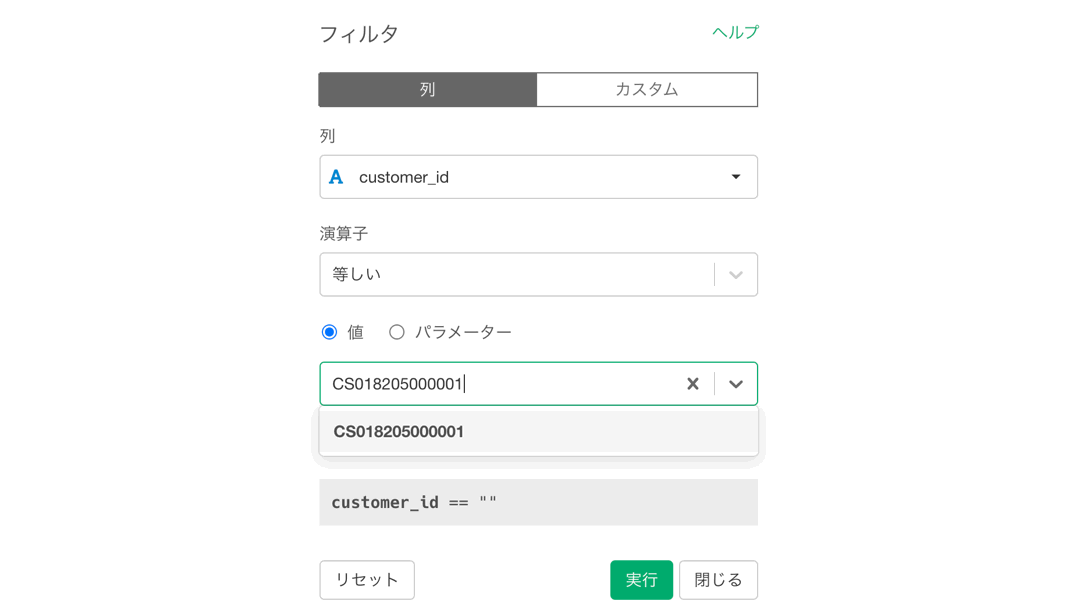
CS018205000001 は 問題文に記載されていますので, コピペしてください。終わったら実行ボタンを押してください。
以下のような画面になったかと思います。 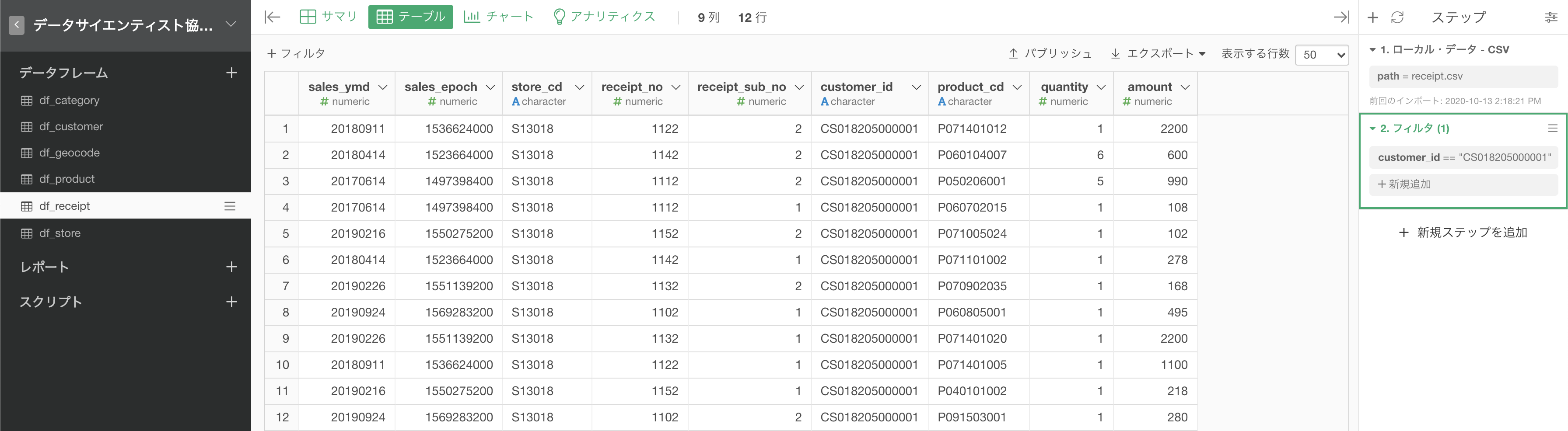
customer_id が CS018205000001 だけなのもそうですが、行数が12行に減っていることも確認しましょう。
あとは問2と同じ手続きで 4列 にすれば答案が完成します。 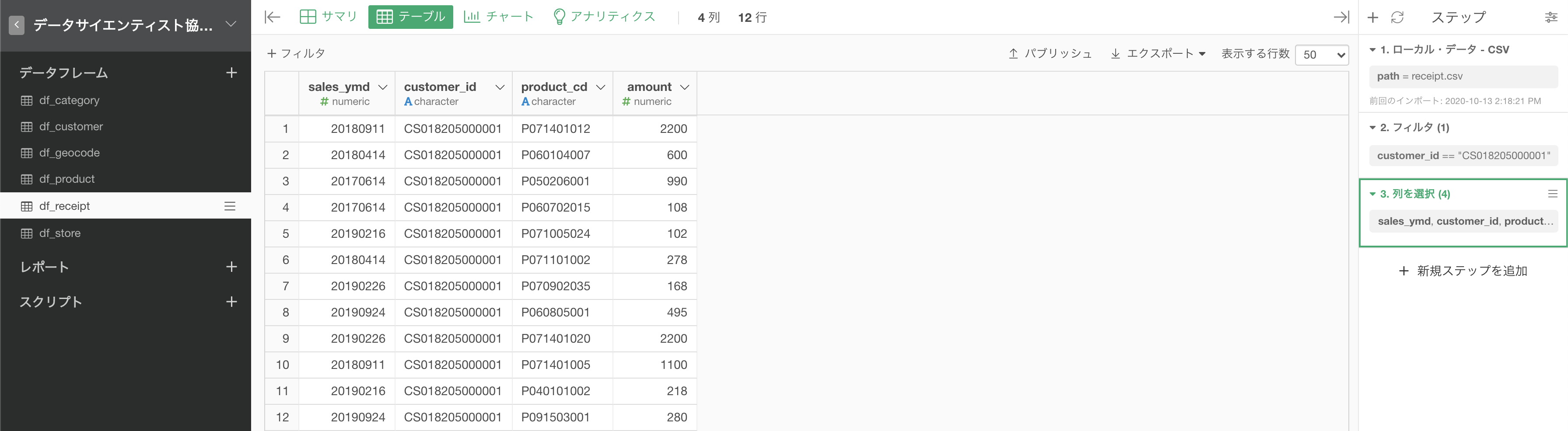
メニューの多さとイメージのカンタンさ
フィルターの中にあるメニューが多くて、一見すると全部違うように見えませんか?
でもこれらは、先ほど選択した流れ(一気に緑色 → フィルター → 等しい)が以下のようにフィルターの画面の構成と対応しているんだ考えましょう。
フィルターのメニュー(演算子)の多さなんて正直関係ありません。
それぞれがどういう役割かということを少しずつ使って学べばいいのですし、我々は スマホ で既にそれを達成してきたはずです。
Python 解答コードはこちら
解答コードはこのようになっています。
df_receipt[['sales_ymd', 'customer_id', 'product_cd', 'amount']].query('customer_id == "CS018205000001"')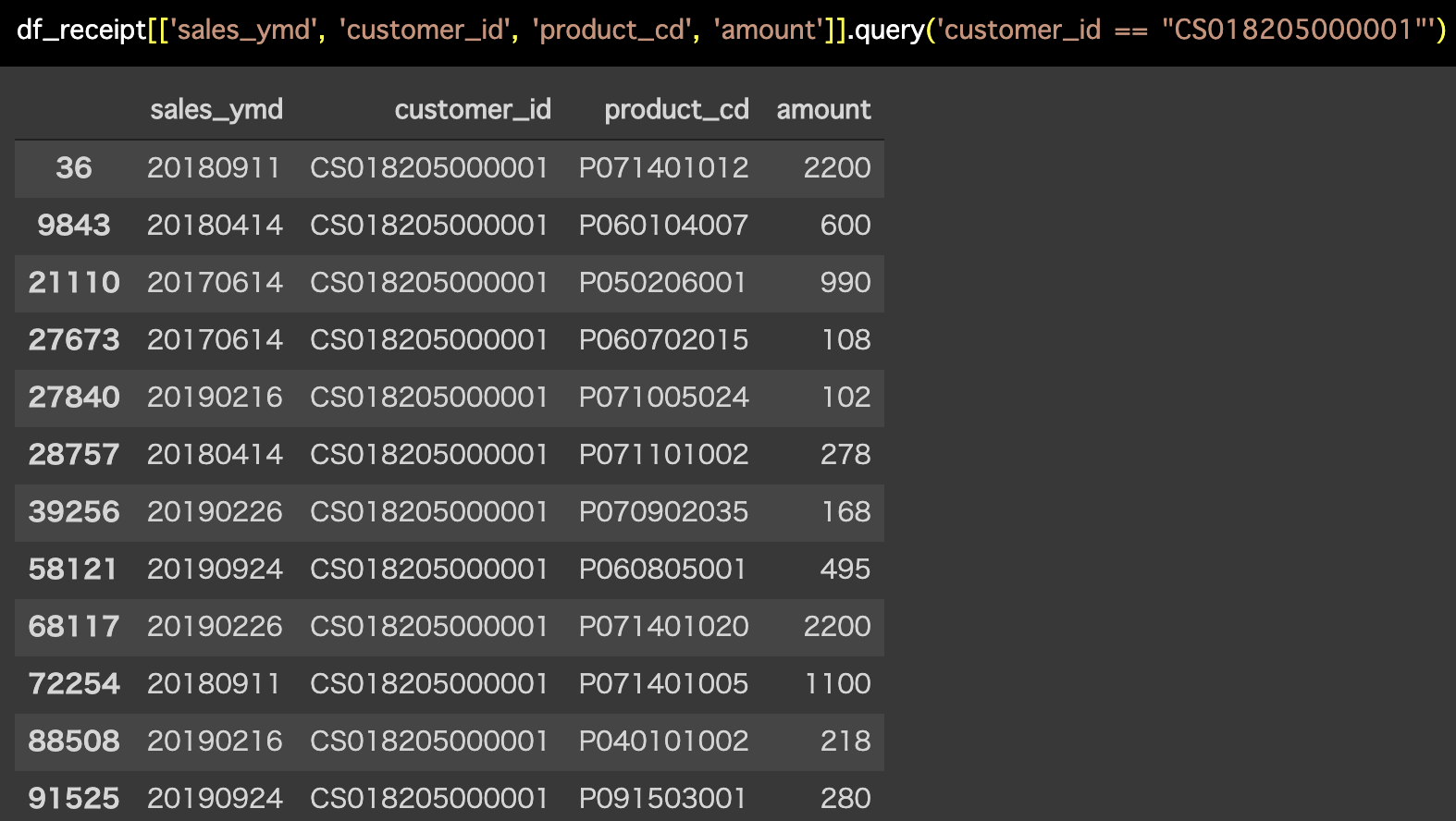
SQL の Q でもあります。
条件を引っ張ってきてねという解釈の問い合わせです。
Exploratory では フィルター と呼びましたが、一般的にどちらもよく使う言葉なので知っておくと良いと思います。
問5 : 複数条件に合致する行を抽出する

答案・解説はこちら
今回の条件は以下の2つ
- customer_id が CS018205000001(問4と同じ)
かつ
- amount が 1000 以上
です。
問4で customer_id が CS018205000001 だけにフィルターするやり方は既に説明しました。
問4 のステップに続けて、amount が 1000 以上 のフィルターを一緒にやっていきましょう。
問4 と同じフィルターの機能なので、フィルターメニューを出すところまでは同じ → 「以上」と選択(問4では「等しい」だったところ)します。 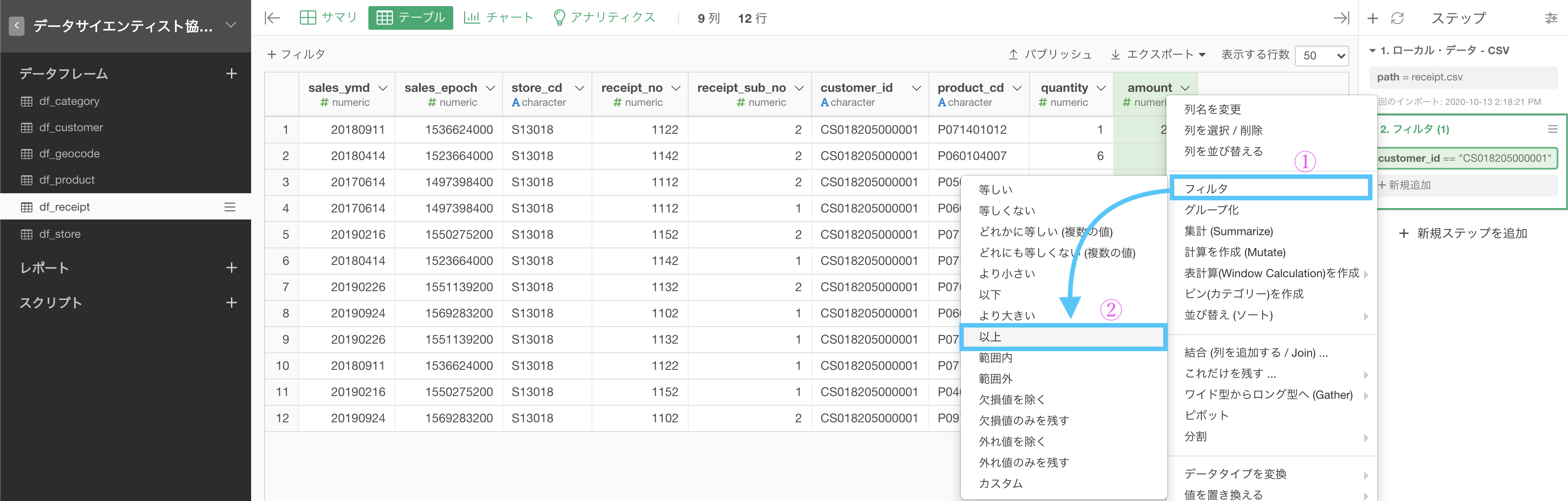
すると以下のような画面が新しく出てきました。
問4 で説明した通りですが、演算子のところをフィルターメニューから選ぶので、等しいから以上に変わっていることを確認してください。
あとはノリで1000と入力すればOKです。 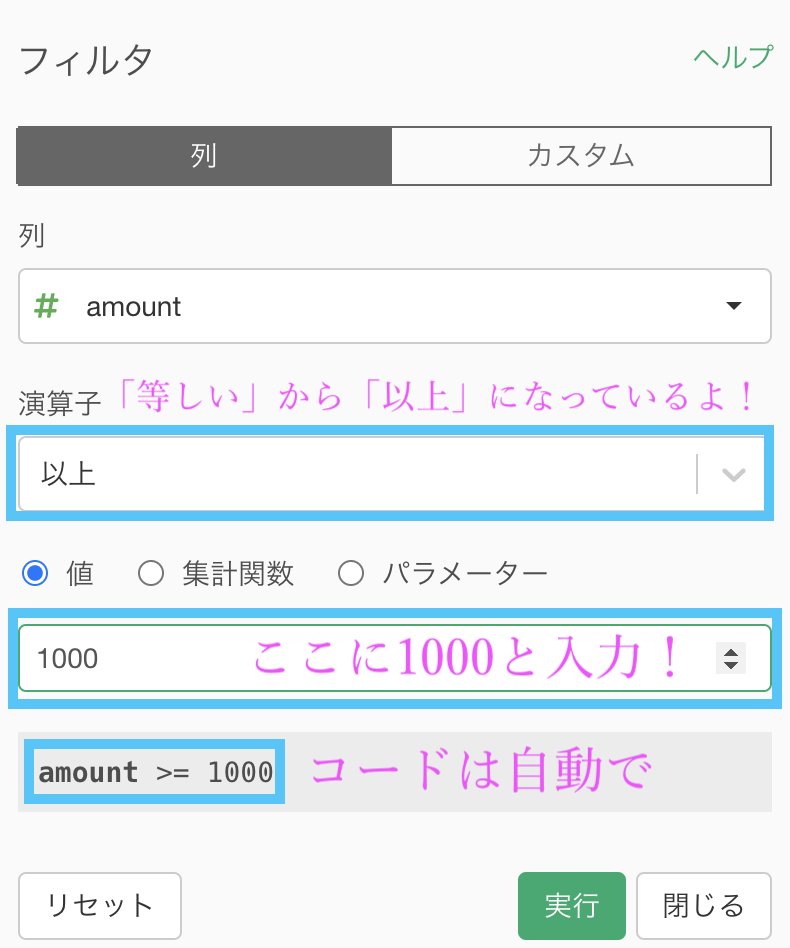
実質やることは1000と入力するだけでしたね。実行ボタンを押しましょう。
これで以下のような画面になっていると思います。 
もうほぼ終わっているようなものなのですが、問題文には4列にしなさいとあるので、問2と同じように列を選択しておきました。 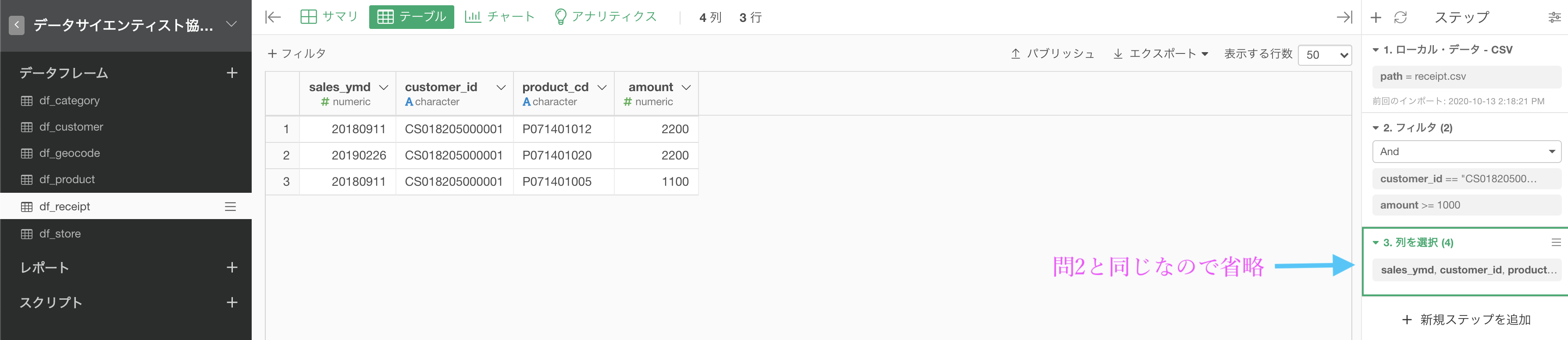
Python 解答コードはこちら
解答コードはこのようになっています。
df_receipt[['sales_ymd', 'customer_id', 'product_cd', 'amount']] \
.query('customer_id == "CS018205000001" & amount >= 1000')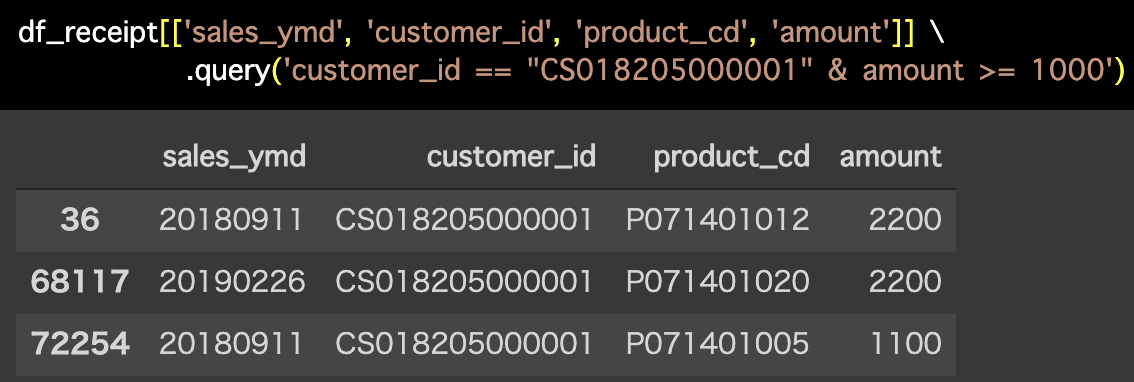
ちなみにコードの中の
- バックラッシュ \ は 地続きだよ〜
- & は「かつ」で、「customer_id が CS018205000001」 と 「amount が 1000 以上」を同時に満たすよ〜
という意味です。
「かつ」と「または」を知っておきましょう。
or の縦棒は Shift キーを押しながら右上の方にある¥キーを押すと出ます。
Exploratory での「かつ」と「または」の切り替え
問4 と同じように amount に 1000以上 のフィルターをかけると、同じステップの中にフィルターの条件が取り込まれていると思います。 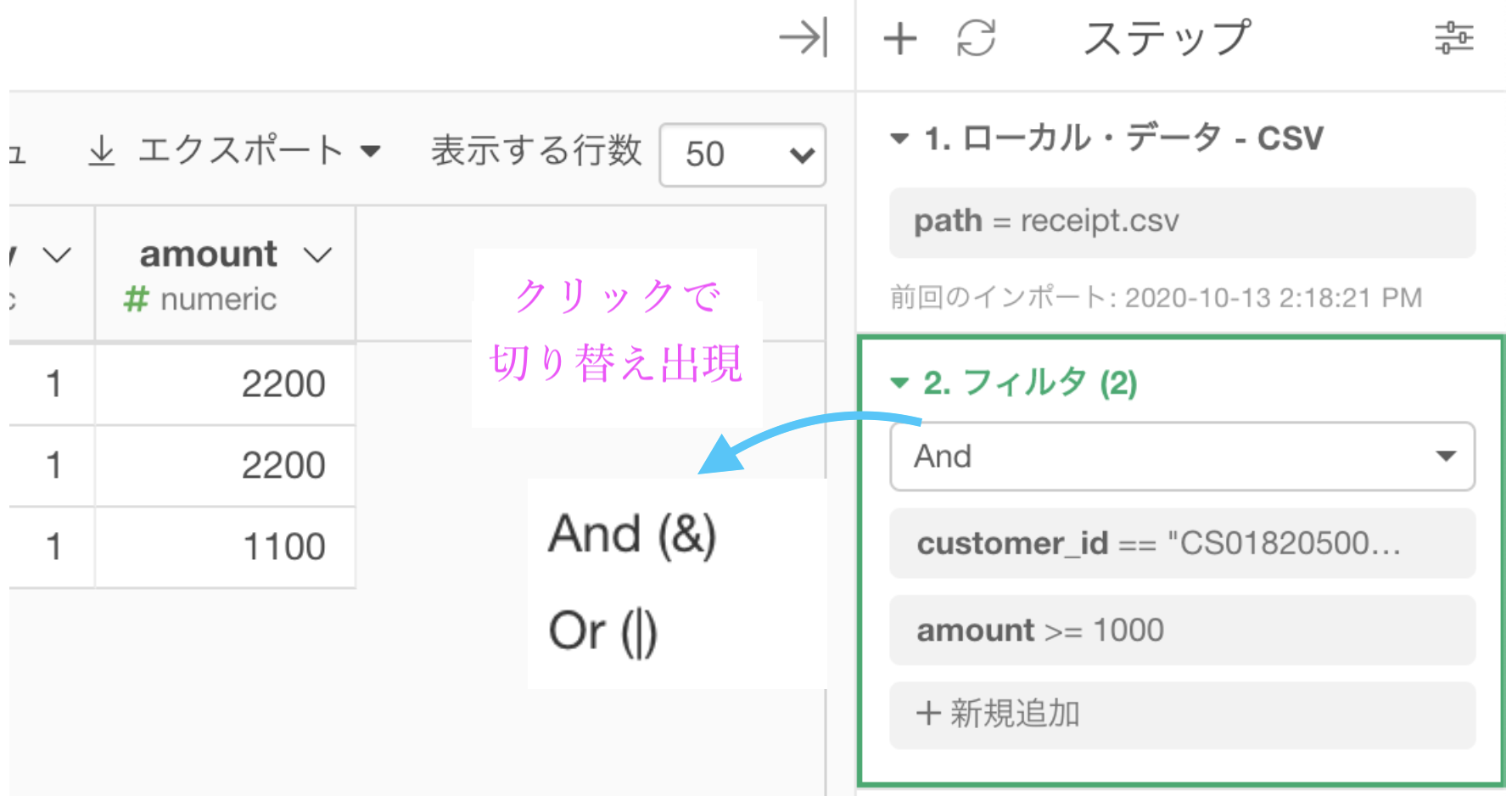
クリックした先で Or(|) にすると、次の条件でフィルターされることになります。
- customer_id が CS018205000001
または
- amount が 1000 以上
実行すると、(customer_id が CS018205000001 の12行) + (amount が 1000以上 の 8448行) がまとめて一気に 算出されます。
問6 : 複数条件に合致する行を抽出する

答案・解説はこちら
つまり、「かつ」のなかに「または」が入るフィルターを実行しましょうということです。
これができれば「かつ」と「または」はクリアと思って良いでしょう。
まず問4と同じく customer_id が CS018205000001 のフィルターをしました。 ここからまたフィルターのステップを追加するのですが、問5と同じようにやると失敗します。
理由は以下のように、ステップのある位置が違うからです。 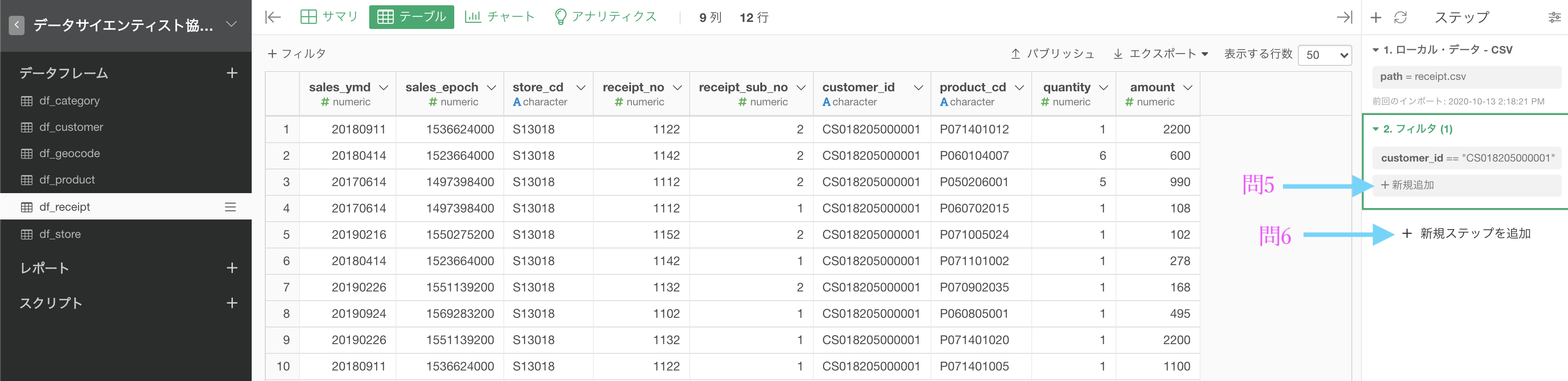
すぐあとで比べるとして、とりあえずここは新規ステップを追加からフィルターのステップを追加しましょう。クリックしてください。 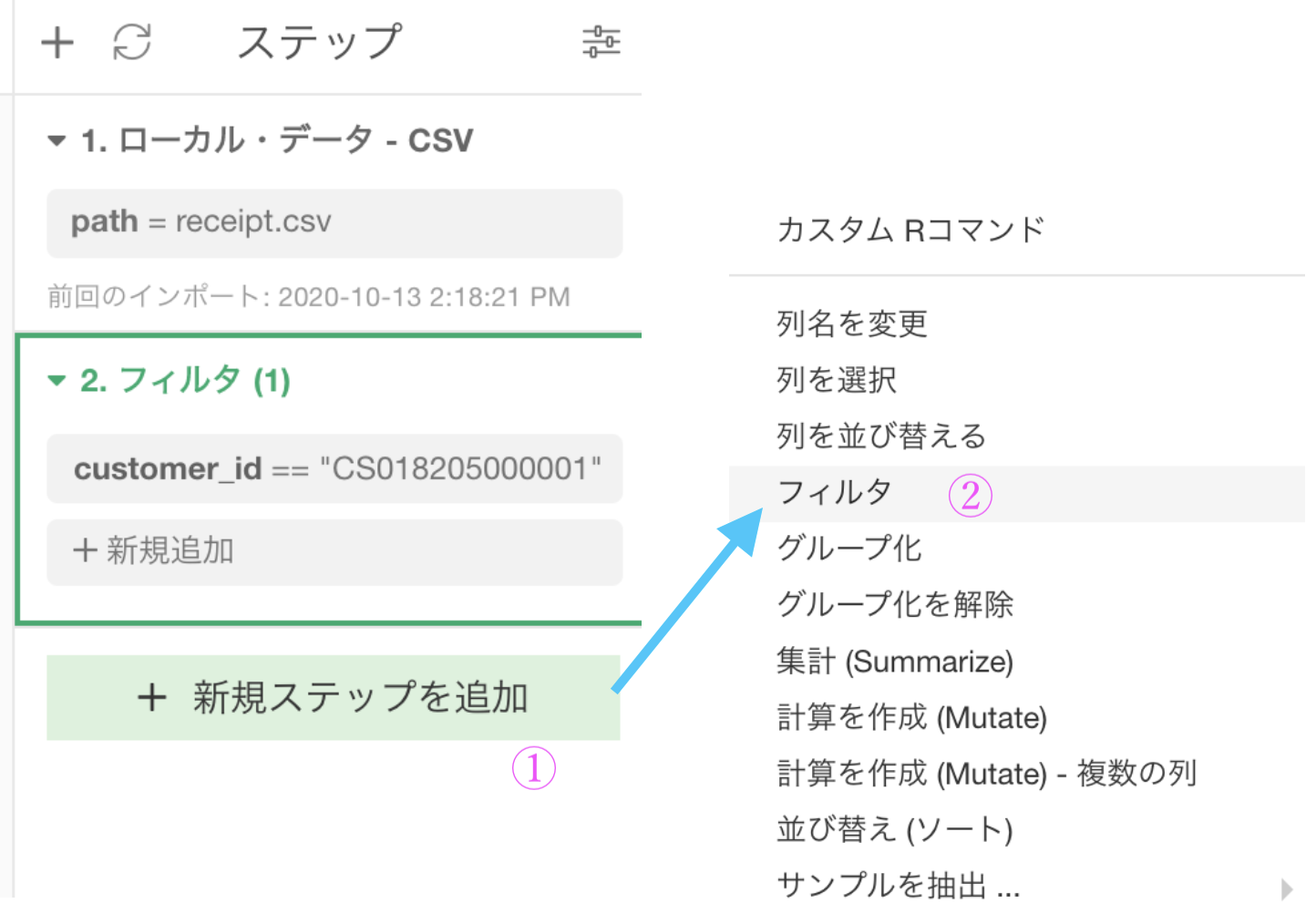
今度は押した途端にフィルターの画面が出てきますので、amount が 1000以上のフィルターを目指して変更しましょう。 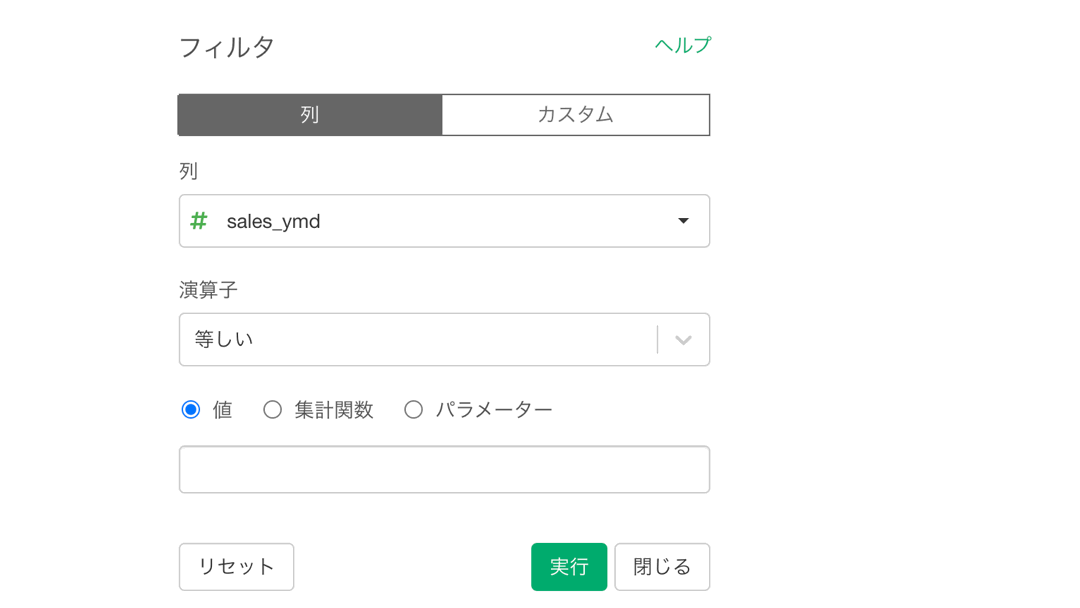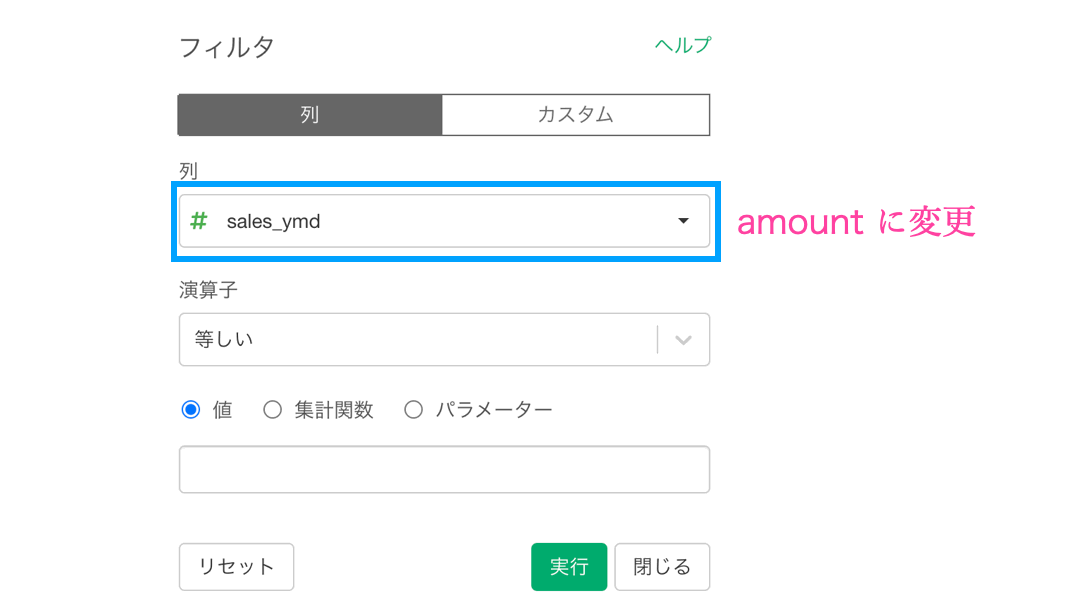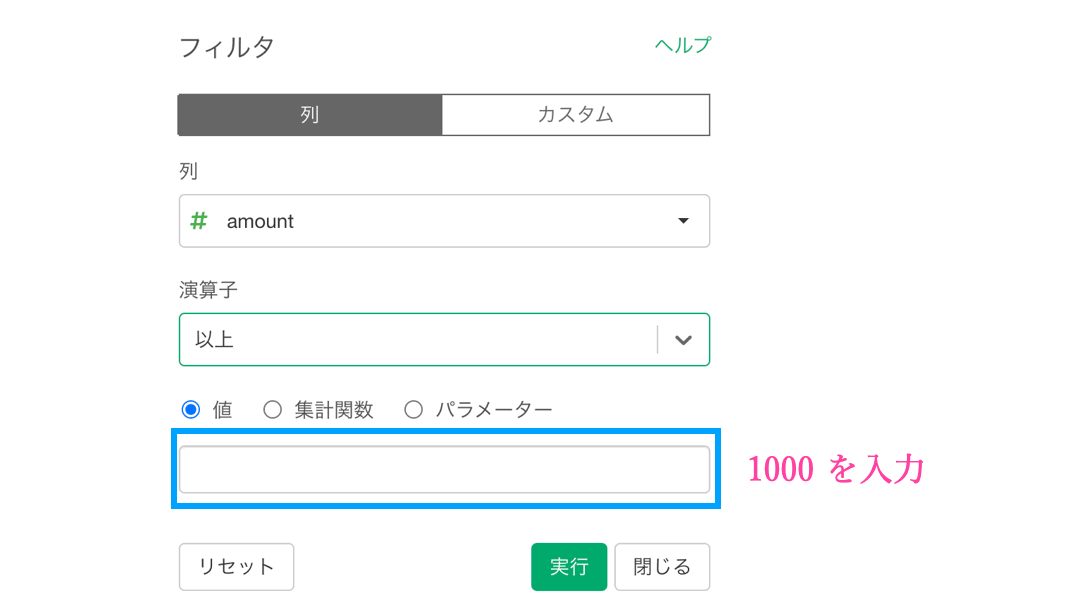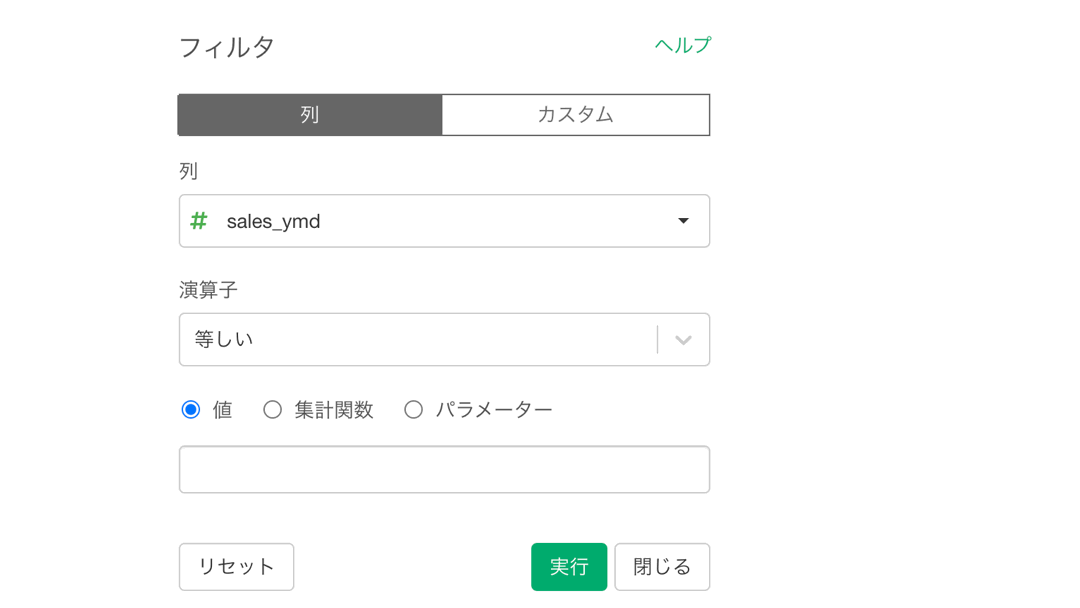
このような画面になれば成功です。
問5と比較すると、別枠になっていることがわかるかと思います。 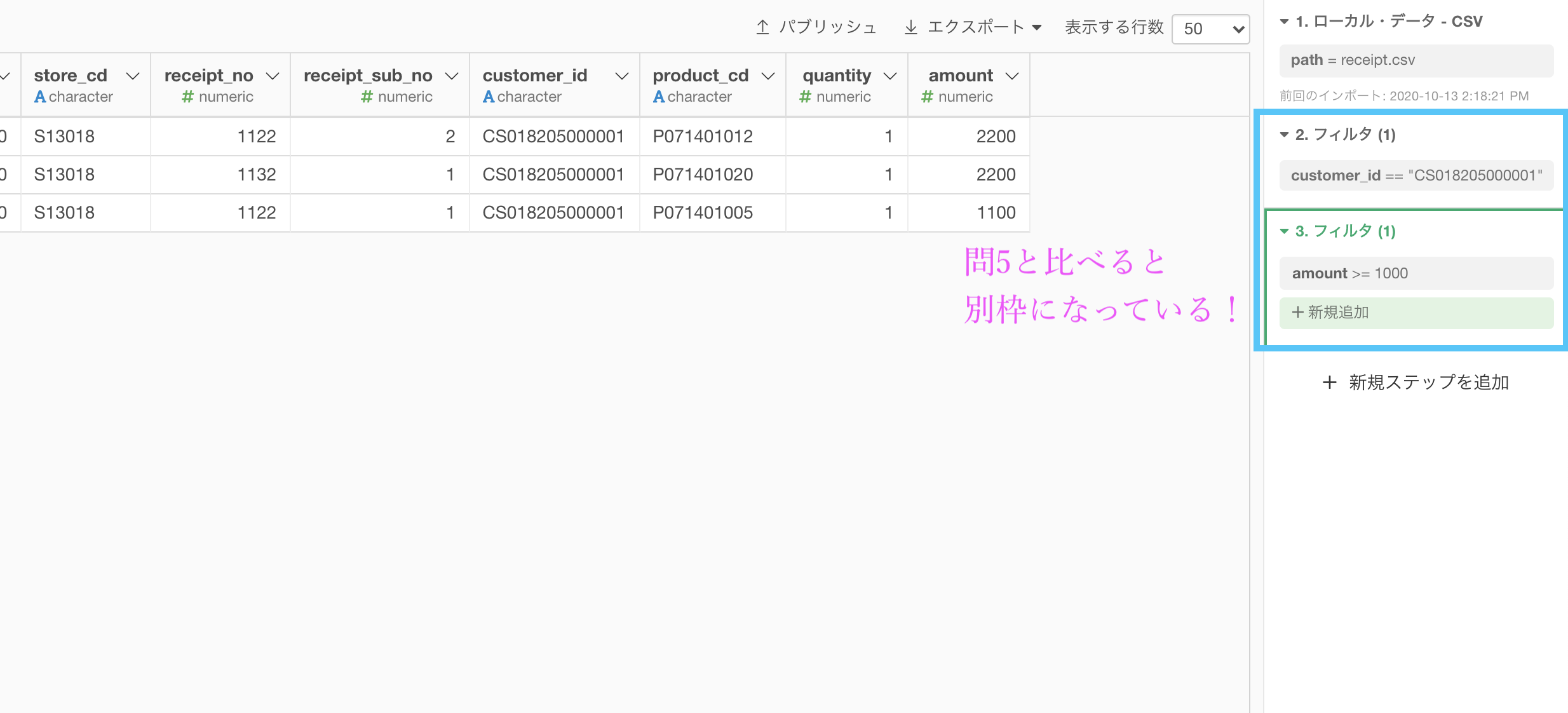
こうなればあとは quantity のフィルターです。amount とは Or で結びたいので、以下のようにして操作していきましょう。 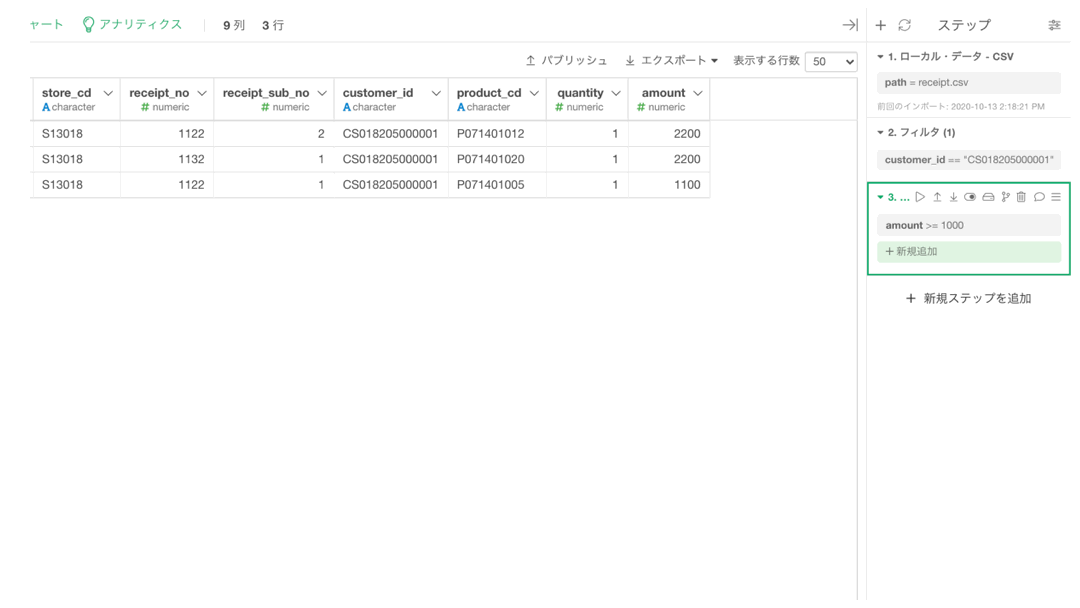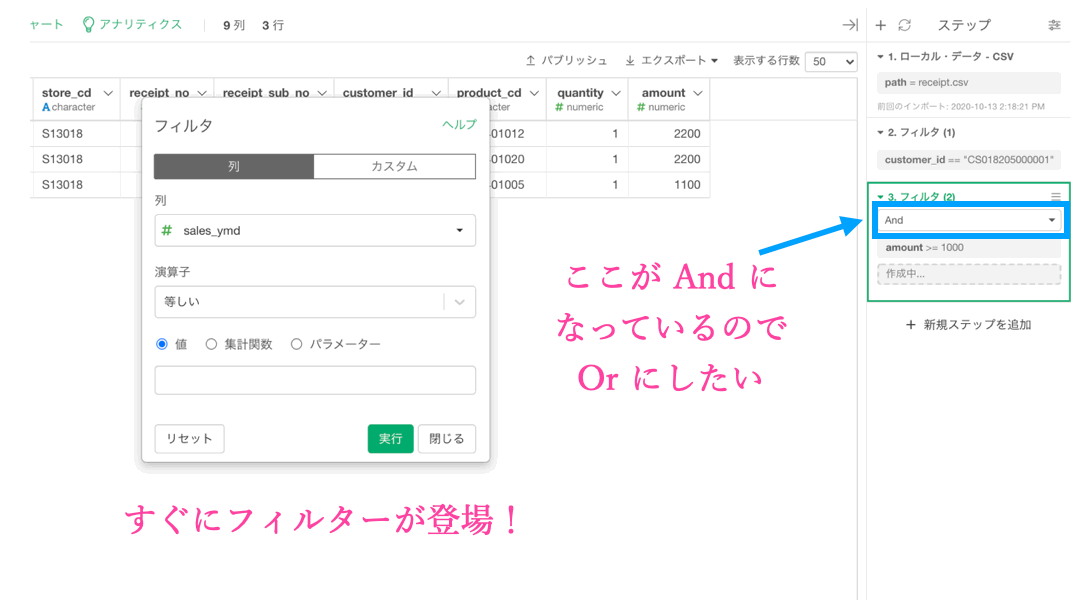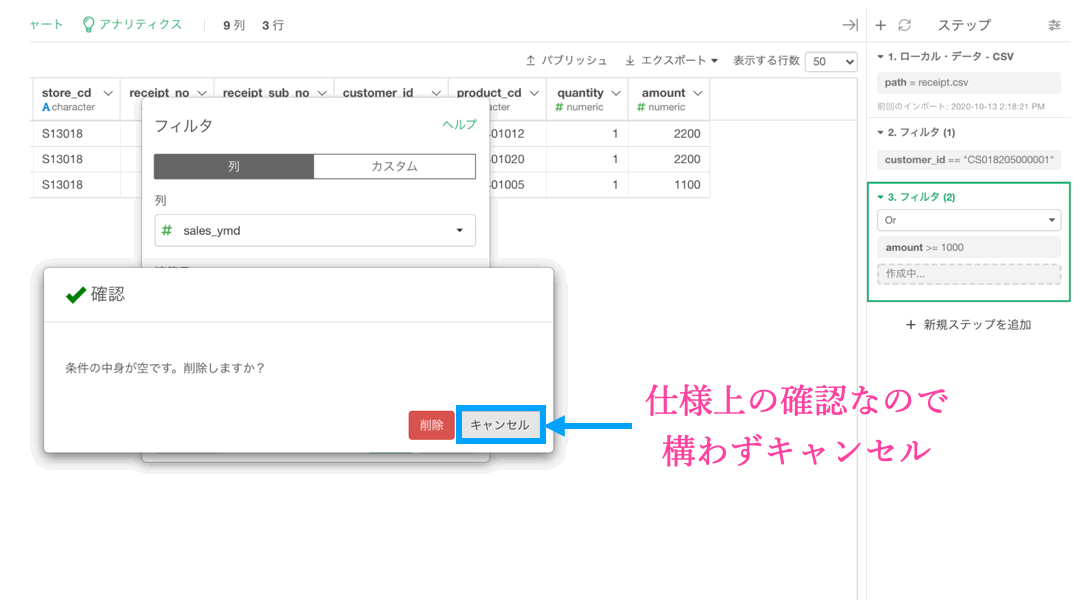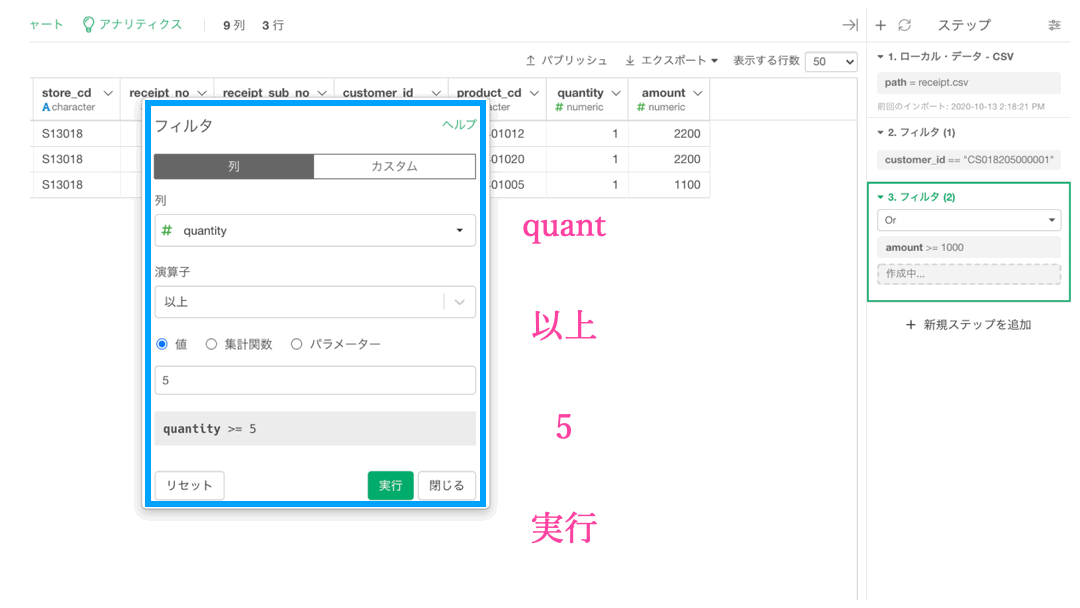
結果が以下のようになっていればOKです。 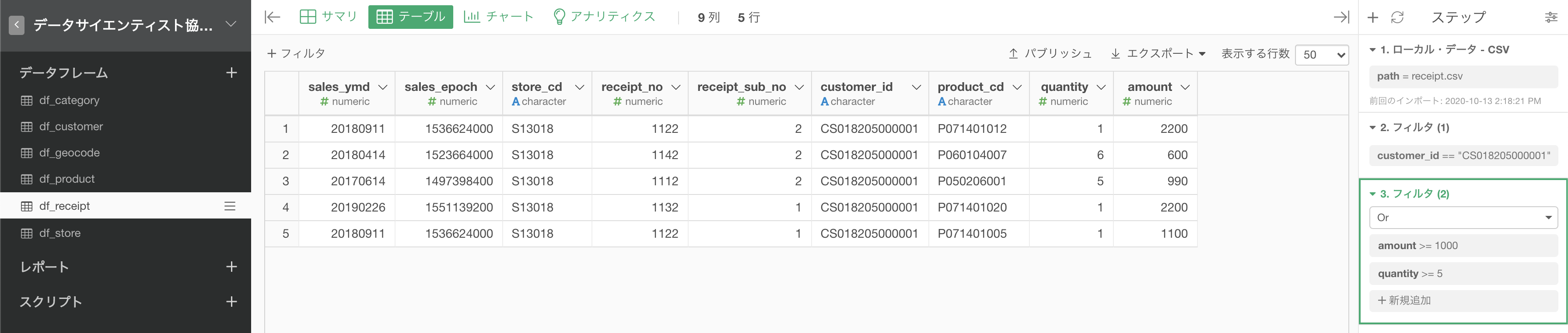
問題文には5列にせよとあるので、最後に問2と同じように列を選択します。
quantity が加わっただけです。 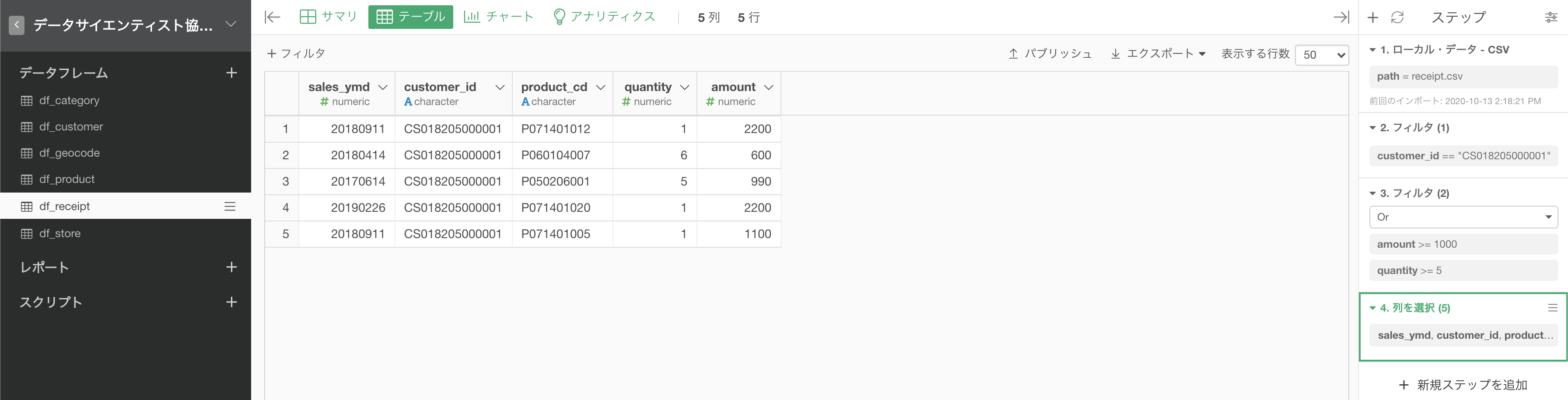
Exploratory でもコードは書ける
Exploratory は R 言語で動いています。
ということは、プログラムのコードは書けるわけです。
いつものフィルターの画面を出したら、上のところに「カスタム」とあるのでクリックしましょう。 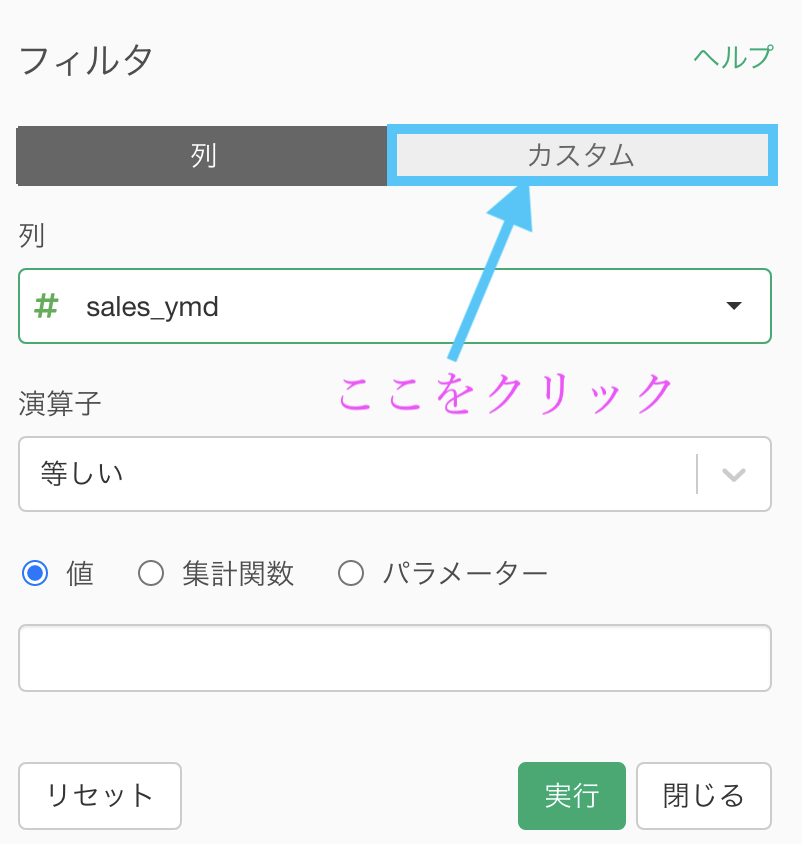
条件のコードを書き込みました。右にある [Code] を押すとコマンドがでます。
# amount >= 1000 | quantity >= 5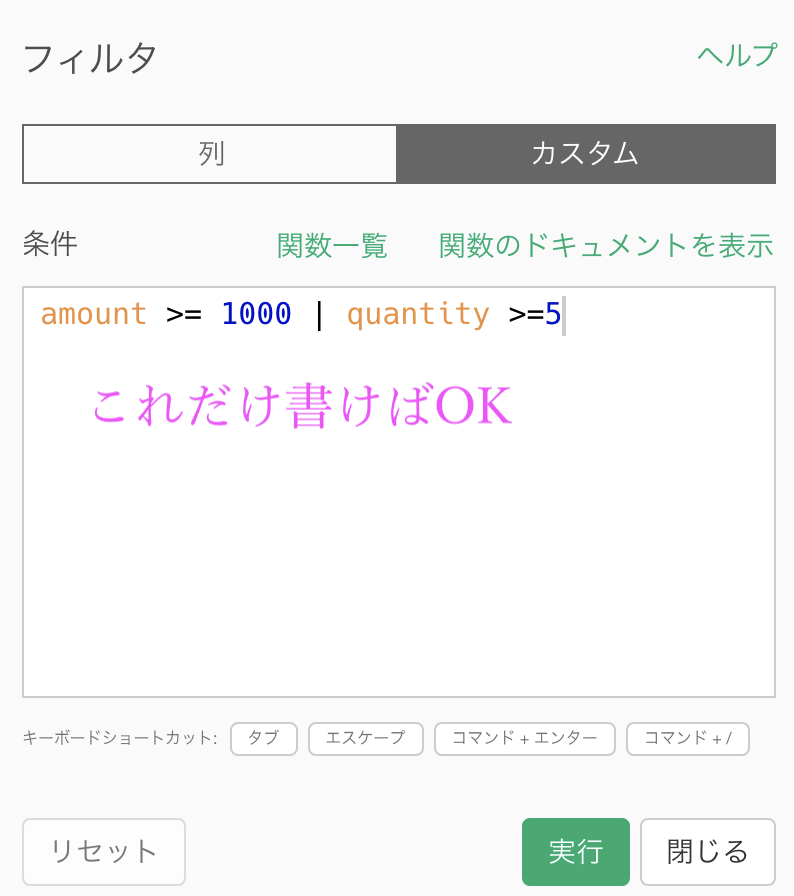
これで実行すればステップとして成立するのです。 
物好きな人向け(先に行きたい人は Python 解答コードで答えを確認!)
おそらく、普段 R言語 を書いている人や、少しでもプログラミングに触れたという記憶がある方なら、「あれ?関数とかどこ行ったの?」となるかもしれません。
プログラミング言語はいわば「関数で動く生き物」みたいなものなので、R 言語 が裏で動く Exploratory でも、直接関数を打ち込みたくなる人はいるでしょう。
そのためには、いつものように「新規ステップを追加」からステップメニューを開き、「カスタム R コマンド」を選択してみましょう。 
さっきと同じ動作をしたいときはこのように filter 関数を使って書きます。
# filter(amount >= 1000 | quantity >= 5)
これで実行すれば同じ結果が得られることでしょう。
このカスタム R コマンドの注意点は・・・
になります。
既に df_receipt を選んでテーブル(あるいはサマリー)をみながらカスタム R コマンドですので、問6 の 解答コード(Rの方)をみるとわかるのですが 
df_receipt[...] %>%
filter(customer_id == "CS018205000001" & amount >= 1000)となっています。
R のモダンな書き方である %>% : パイプ演算子を用いた書き方に慣れるまで R 言語をやらないと、Exploratory のカスタム R コマンドを使いこなせないかもしれません。
ここでは解答コードは Python を載せています(答案との比較の観点からも説明しやすかったので恨まないでください...学びにもなると思って...汗)。
Exploratory を使いこなすために R 言語を学ぶのであれば、そのモチベーションはとても良いことだと思います!(というか楽しいので、ここまで開いたあなたは是非本家の R や RStudio もやってください!)
僕の R 言語のオススメ書籍はこちら です。知っている方も多いかと思います。
Python 解答コードはこちら
解答コードはこのようになっています。
df_receipt[['sales_ymd', 'customer_id', 'product_cd', 'quantity', 'amount']].query('customer_id == "CS018205000001" & (amount >= 1000 | quantity >=5)')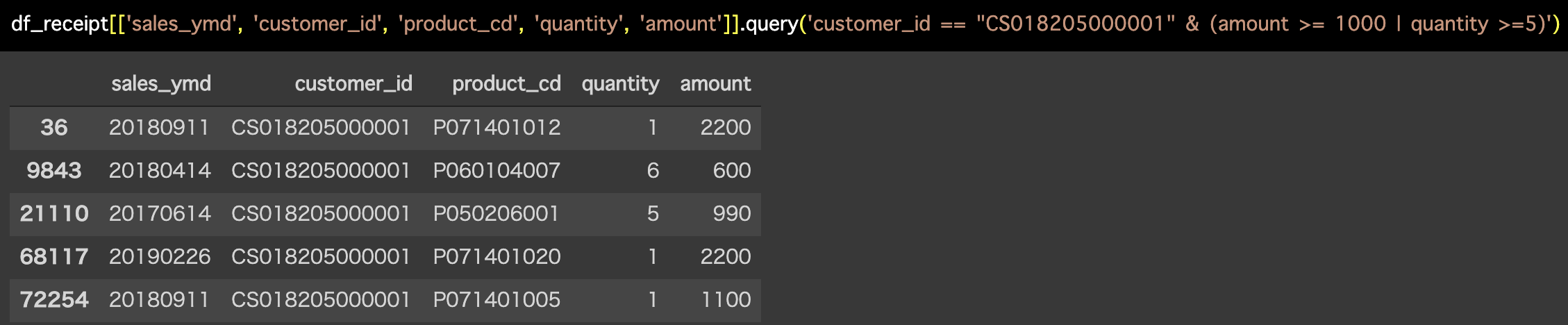
ステップとコードの対応を見やすくする
今回のステップと、解答のコード(大事なところだけ)を比べてみましょう。 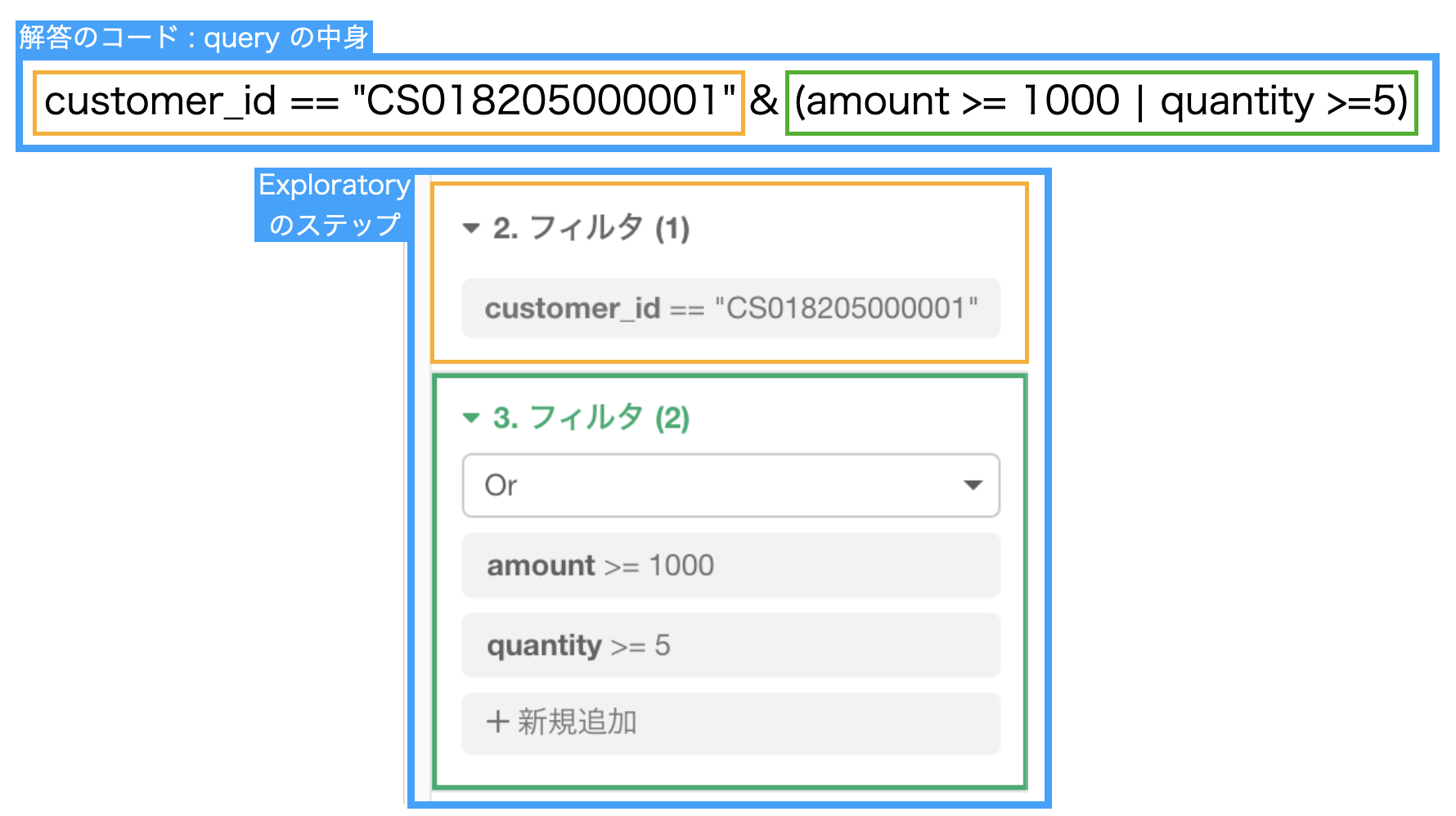
青枠が全体の And で、緑枠が小さな Or になっています。
入れ子が実装できたことになります。
コードを書き慣れている人にとっては、3×(2+1) のように見えているかもしれませんが、誰しも最初は呪文に見えたことでしょう。
問7 : 複数条件に合致する行を抽出する

答案・解説はこちら
というノリでやっていただければ良いかと思います。
答案も多少...雑になり始めます...(笑)
まずは customer_id を CS018205000001 だけに制限します。
問4の解答と同じ状態ですね。 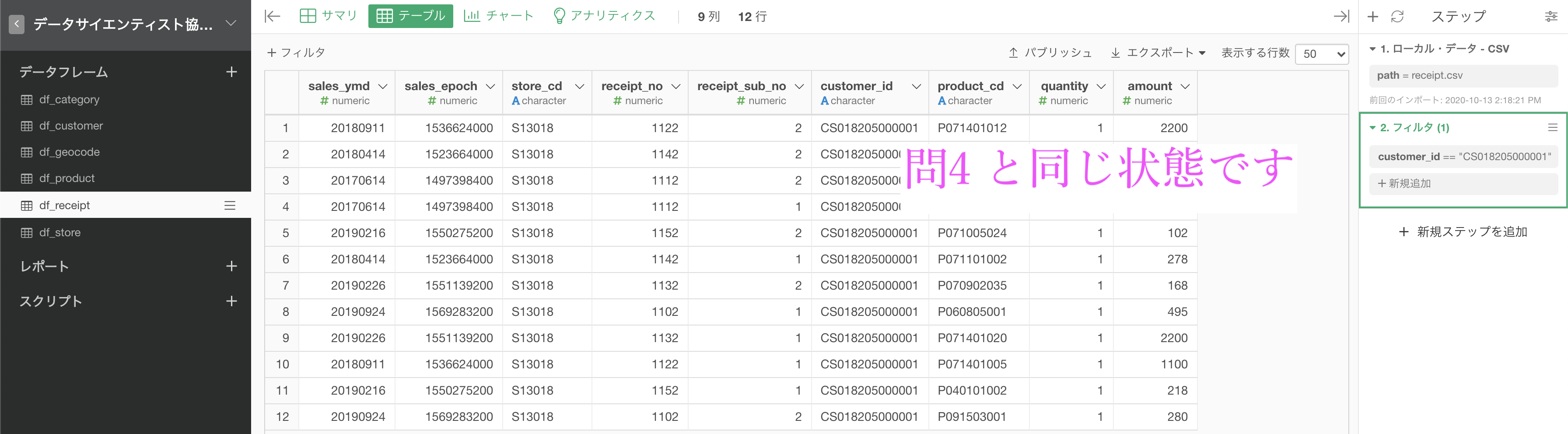
amount の列に対して1000以上2000以下 というフィルターを「かつ」で追加すれば問題は解決しそうです。
以下のように、フィルターメニューから「範囲内」を指定しましょう。 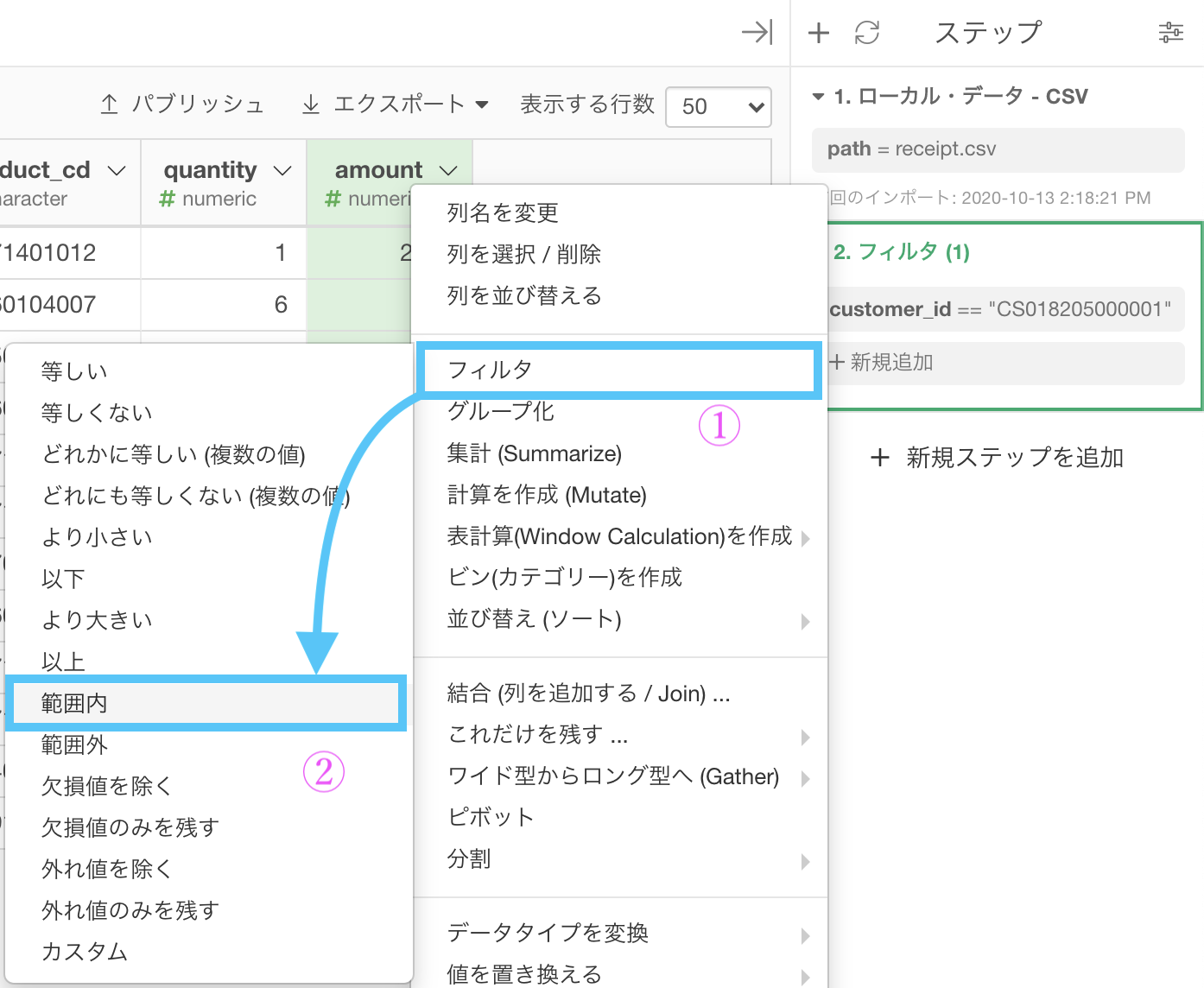
値のところに 開始 : 1000, 終了 : 2000 を入れれば「1000以上 2000以下」という意味になります。 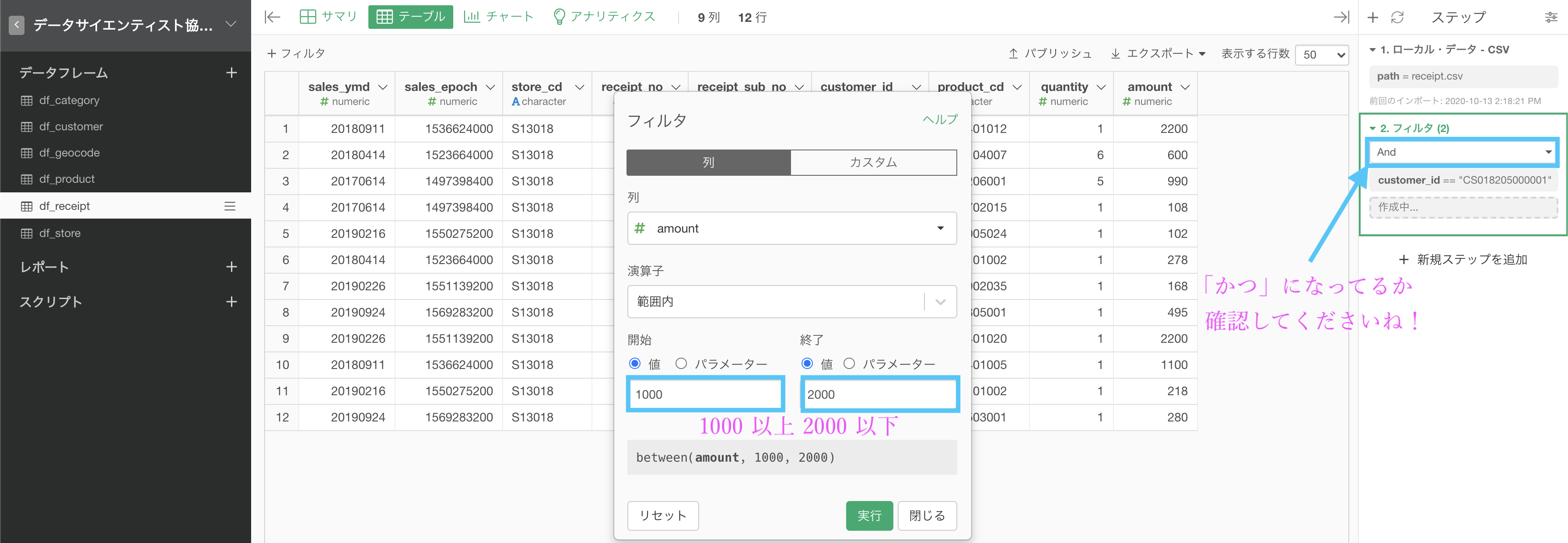 ちゃんと「かつ」(And) になっていることも確認してくださいね!
ちゃんと「かつ」(And) になっていることも確認してくださいね!
問6と地続きでやっていると, または (Or) となっていたりするので注意ポイントです。
確認が終わって実行すると、1行しか残りません。
ですが、これでフィルターは問題の通りにできているので、あとは問2のように列を選択して4列にすればOKです。 
Python 解答コードはこちら
解答コードはこのようになっています。
df_receipt[['sales_ymd', 'customer_id', 'product_cd', 'amount']] \
.query('customer_id == "CS018205000001" & 1000 <= amount <= 2000')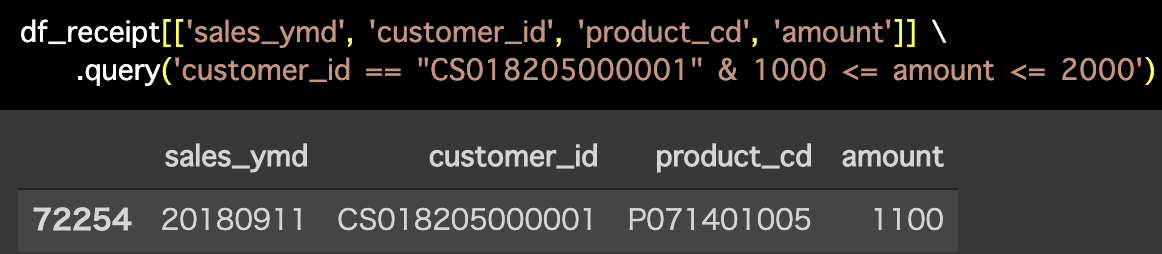
次につながる話
解答コードにもありますが、amount が 1000 以上 2000 以下 という意味のコマンドは
1000 <= amount <= 2000と書くので、Exploratory でフィルターのカスタムから打ち込んでみると良いでしょう。
また、Explroatory のフィルターメニューについて次のことにも注意したいです。また、ヒストグラムの階級の決め方などでよく用いられる言葉として「1000以上2000未満」ということを実現したい場合は以下のようなコマンドです
1000 <= amount < 2000Exploratoy ではこれを一発でやる方法はカスタムしかありません。
しかし、カスタムでやらなくても、「1000以上」かつ「2000より小さい」という意味なので2ステップで完了します。
次の問8につながるために言っておきますと、これは「1000以上」かつ「2000以下」かつ「2000と等しくない」という意味でもありますので、3ステップでも実装できます。
次の問8は「等しくない」を実装するものです。
問8 : 特定条件に合致しない行を抽出する (!=)

答案・解説はこちら
まずは customer_id を CS018205000001 だけに制限します。
問4の解答と同じ状態ですね。
ここから、product_cd(商品コード)が P071401019 ではないものというフィルターを作りましょう。(ちなみに cd は code の略) まずはいつも通り product_cd からフィルターメニューを開いて「等しくない」を選択します。 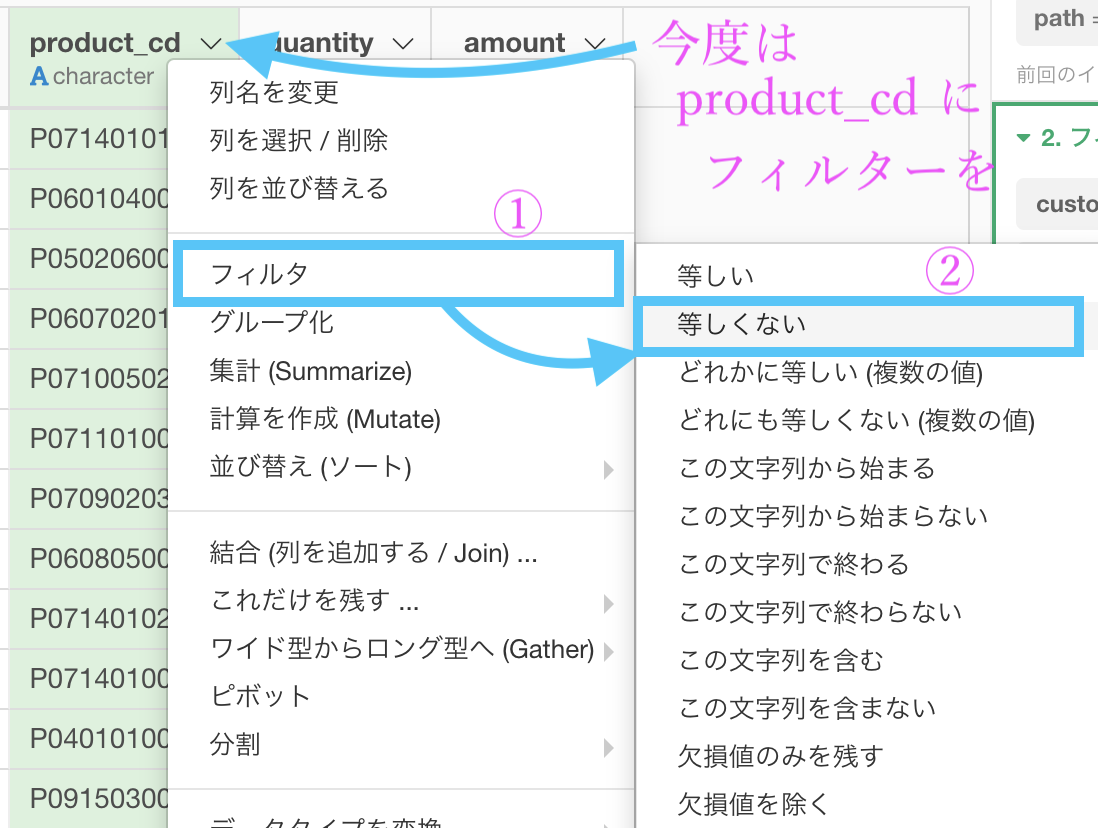
次に、値の中に P071401019 を入力します。 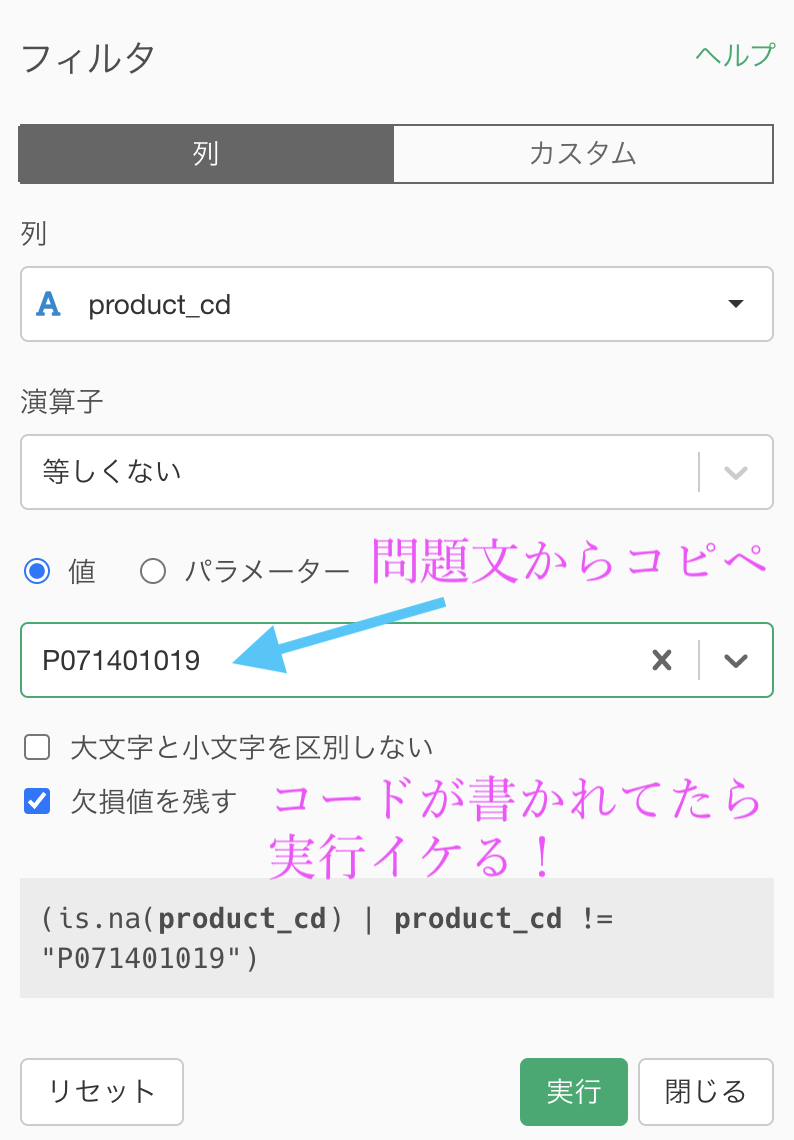
これで「product_cd が P071401019 と等しくない」というフィルターを作れたので、実行しましょう。
今回とは関係ないですが、is.na(product_cd) の部分が「欠損値を残す」のチェックボックスに対応しています。
あとは問題文で4列にしなさいと言っているので問2と同じ操作で列を選択すれば完了です。 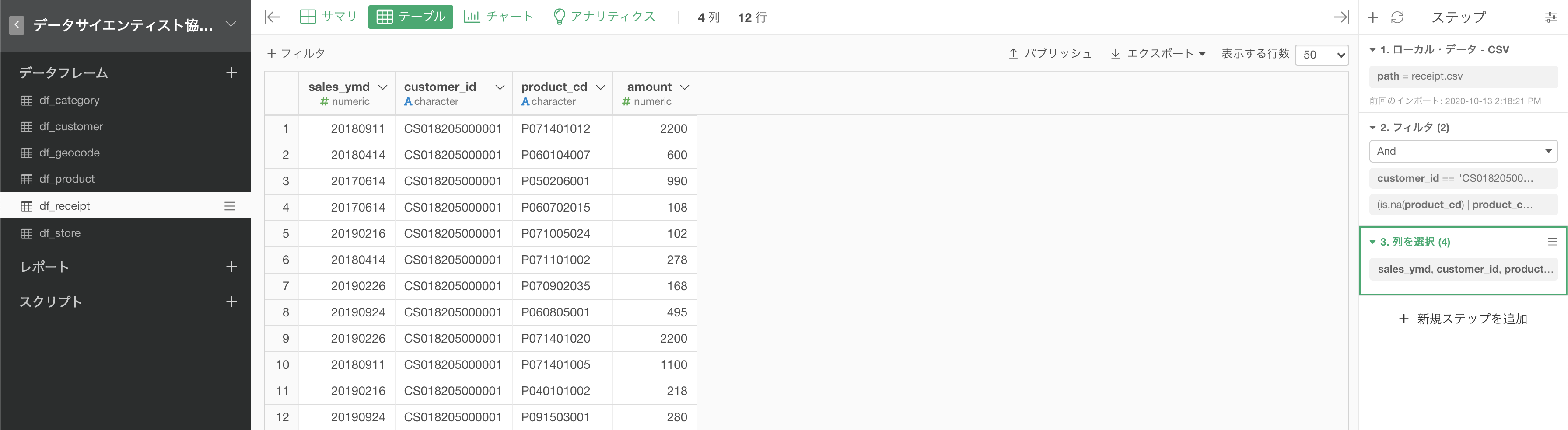
Python 解答コードはこちら
解答コードはこのようになっています。
df_receipt[['sales_ymd', 'customer_id', 'product_cd', 'amount']] \
.query('customer_id == "CS018205000001" & product_cd != "P071401019"')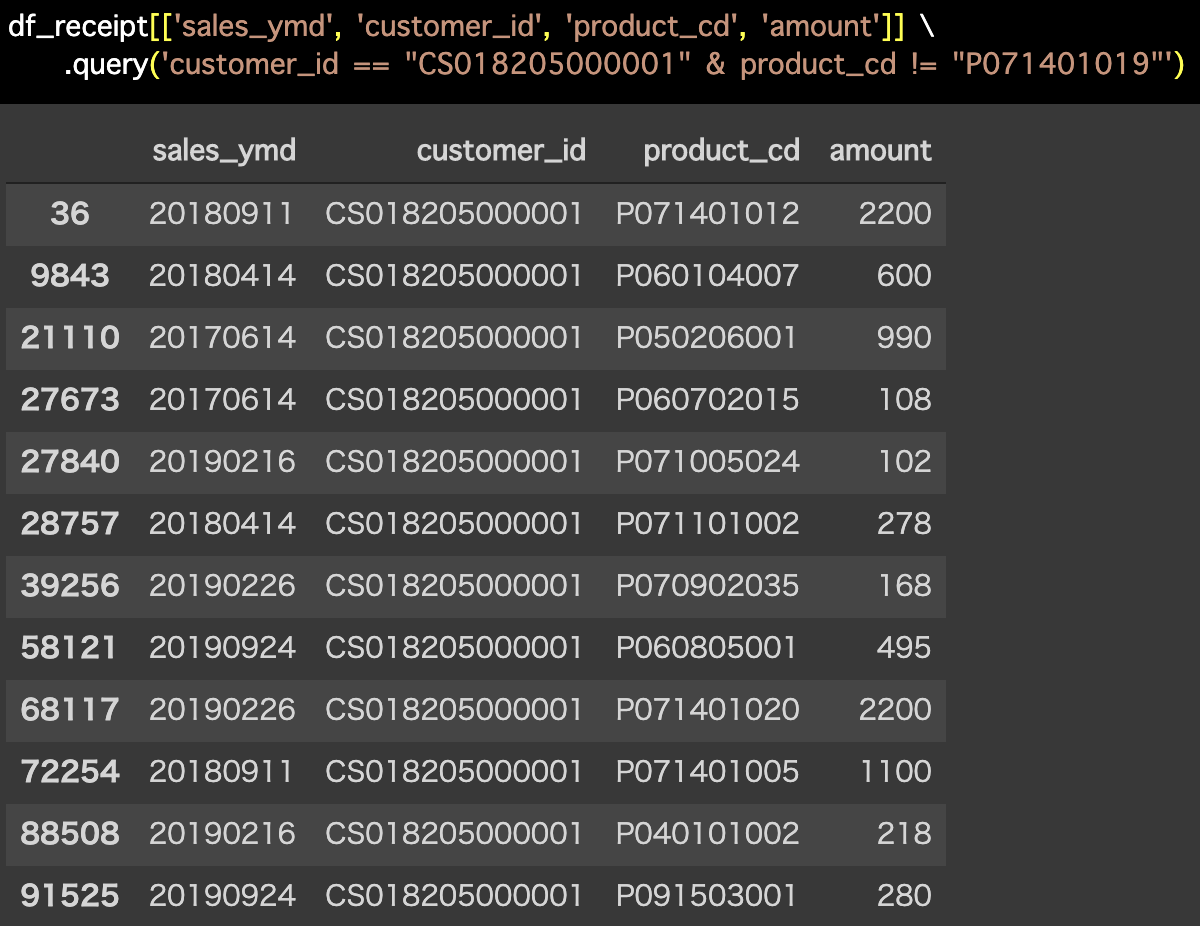
細かいけど大事な話
Exploratory はユーザーに優しいデザインになっているので、P071401019 と入力してもちゃんと反応しました。
つまり、product_cd ≠ P071401019 をフィルターできた!って皆さんは思っていることでしょう。
しかし、コードを打つときは、このような式ではエラーになります。
数学では等しくないことを ≠ で書きますが、プログラムのコードは != と書きます。
キーボードからすぐ打てないからこうしているのかもしれません。
「等しくない!」って、やっぱり「!」って感じしますよね。半角で書きますけど。
product_cd != "P071401019"と打たなくてはならないのです。
あれ? なんか、ちょんちょん " "(ダブルクォーテーション)ついてるよ?って思った方は鋭いです。
数値データのときは例えば
amount != 1000で良いのですが、product_cd は 文字列データなので、ちょんちょん " "(ダブルクォーテーション)が必要なのです。
Exploratory の文字列か数値かを判断するためには、ココを見ましょう。 
ここは データタイプ と呼ばれるものを教えてくれます。
よく使うデータタイプの一覧(忙しい人は見ないで!)
・numeric : 数値のデータです。読み方はニューメリックです。数値関数はほぼなんでも使えるという認識でOKです。
・character : 文字列のデータです。読み方はキャラクターです。テキストデータとはこのタイプのことです。テキスト分析の関数はほぼなんでも使えるという認識でOKです。
・Date : 日付のデータです。POSIXct は時間まで入っています。時系列の分析には欠かせません。
・logical : 論理値のデータです。読み方はキャラクターです。欠損値を除き、True か False の2つしか取りません。
・factor : 要因のデータです。読み方はファクターです。順番がついていますので、例えばソートすると、ちゃんと 1月, 2月, ... となります。factor型の 2, 3, 4, 5, ... を numeric型にすると 1, 2, 3, 4, ... となったりするようなマニアックなところは目を瞑るとすると、factor型は順番のついたcharacter型みたいなものだと思ってくれても良いです。
デフォルトでは辞書式で順番が振られます。
データタイプの名前を覚えようとする必要は全くありません。
だって変換できるデータタイプは Exploratory に書いてあるからです。 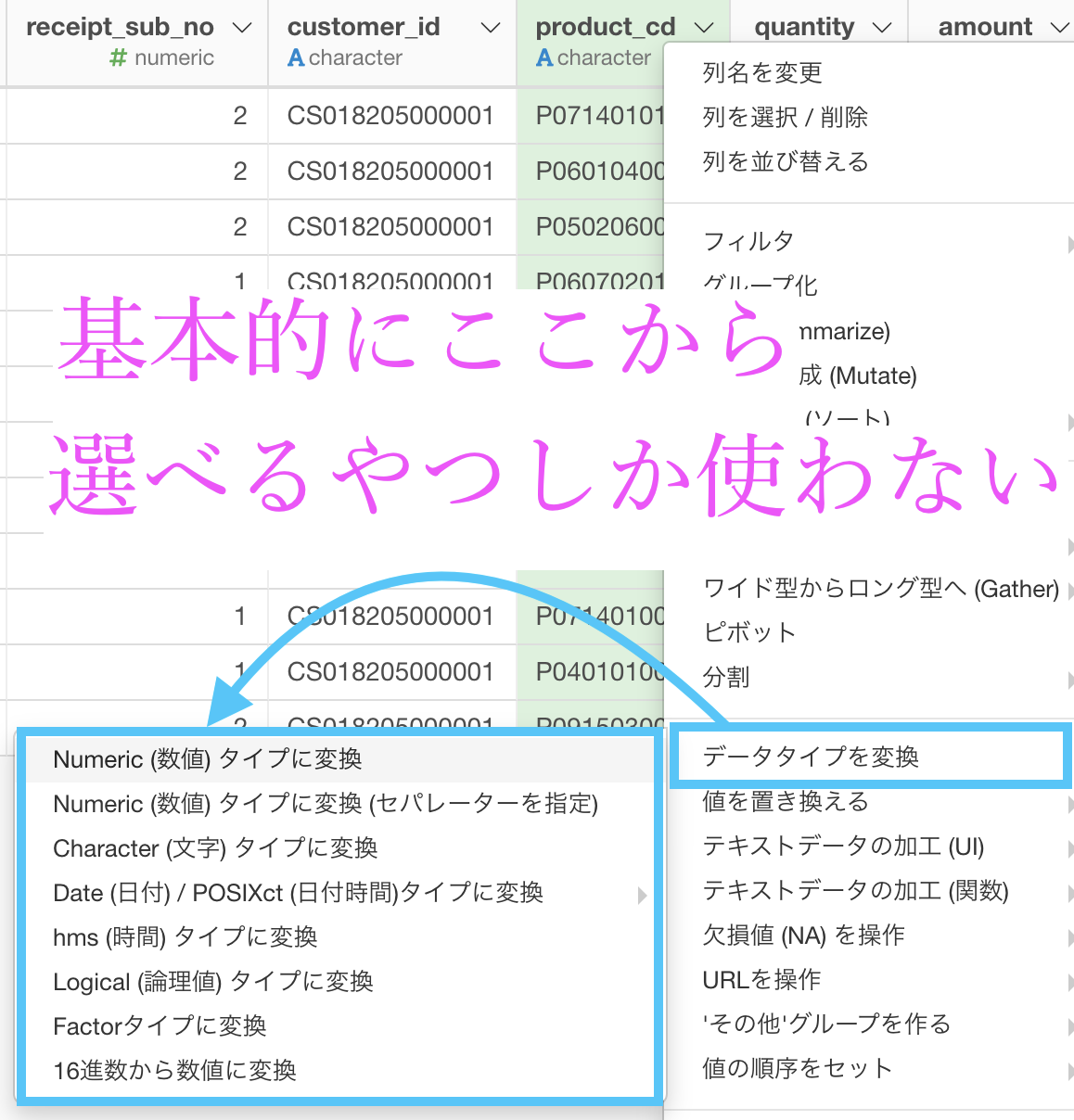
役割を知っておくことが重要です。
データタイプの役割は、おそらくこの100本ノックを通してだいぶ分かるのではないかと思います。
特に numeric と character と Date は最低限は分かるようになると思います。
終わったら「numeric型だから数値関数はいつでも使えるな」とか「character型だからテキスト分析の関数は味方につけたな」とか思えるようになるかもしれません。
少しの意識で変われることだと思います。
問9 : AND、ORで抽出される結果の補集合を取得する

答案・解説はこちら
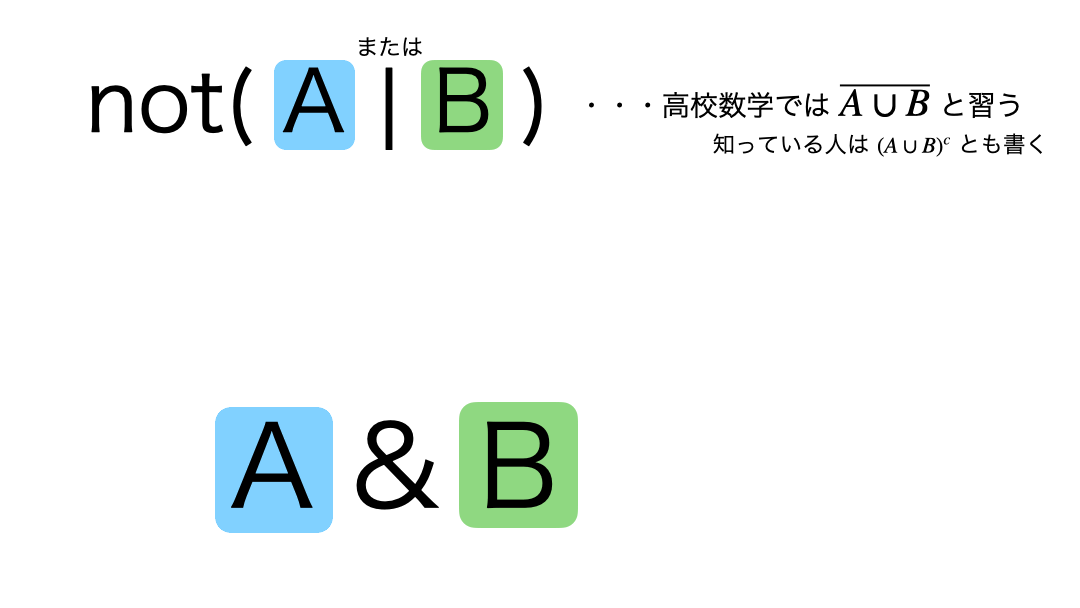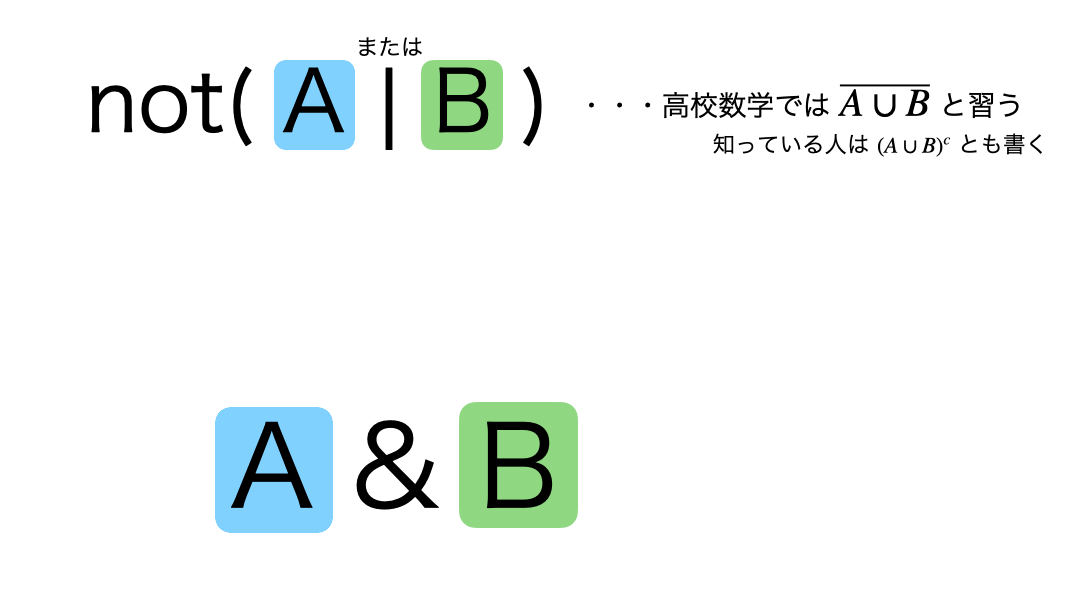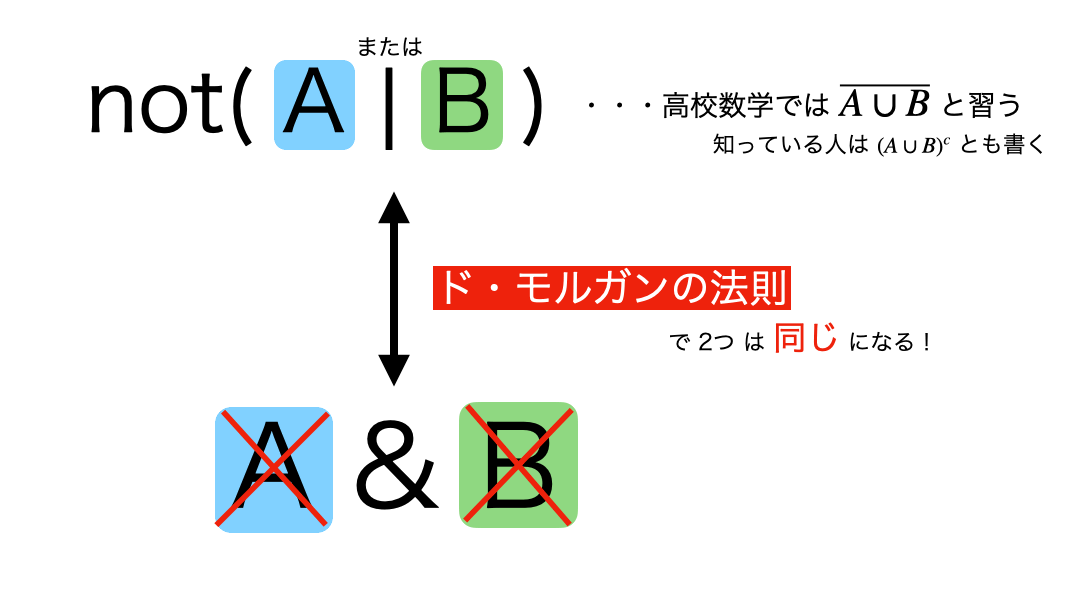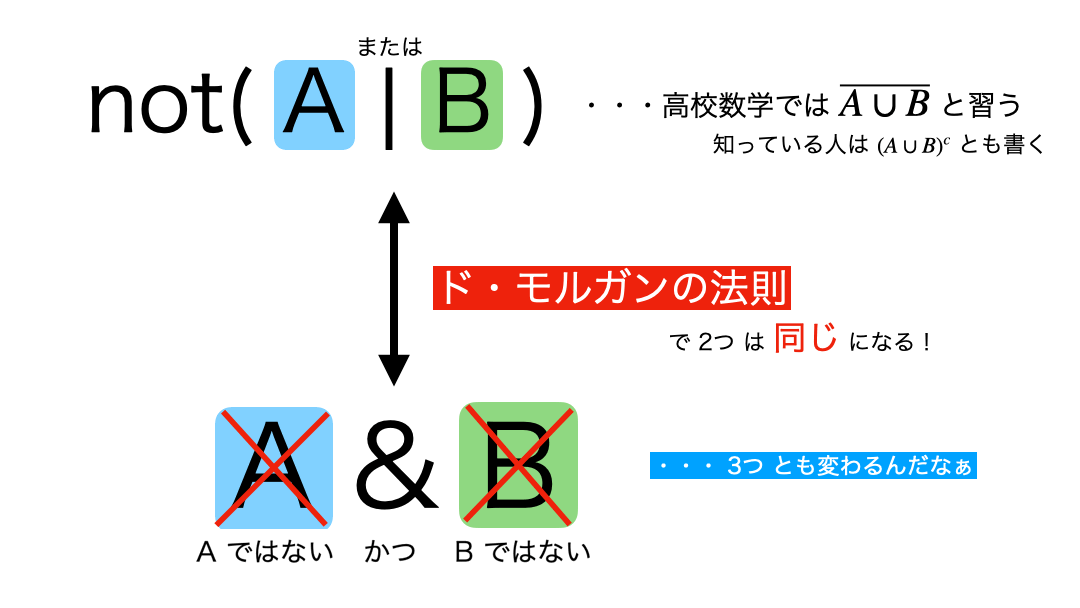
ん?「Aではない」「かつ」「Bでもない」なら・・・じゃあ結局なんなの? となってしまうのがこの法則の引っかかるところ。
それならデータに聞いてみましょう。
まず、問題のコードが何のフィルターをしたいのかを、ド・モルガンで確認します。  つまり今回の問題は、
つまり今回の問題は、
- prefecture_cd が 13
かつ - floor_area が 900以下
のフィルターを作れば良さそうだ!となるかと思います。
これなら今までの問題をクリアしてきた経験があるのでカンタンですね!(具体的には問5とほぼ同じ)
今回の問題は df_receipt から df_store にデータフレームが変わりますので注意してください。
df_store のフィルターとしては、
prefectured_id != "13" は 問8 のやり方を参照
floor_area <= 900 は「以下」であることに注意すればOKの2ステップを踏めば以下のような画面になると思います。 
Exploratory に助けられていること
df_store の prefectured_cd は、もともと character型(文字列)なので、問題文のコードには "13" としてダブルクォーテーションをつけて文字列に対するフィルターであるということをしっかり明示しています。
しかし、Explroatory で処理したときに、prefectured_cd が numeric型(数値)であったことに気付いた方は鋭いです。
これは、データを Exploratory に読み込ませ(インポート)したときに、以下のような画面で「データタイプを自動で認識」にチェックが入っていたためです。
わざとチェックを外して適応してみました。 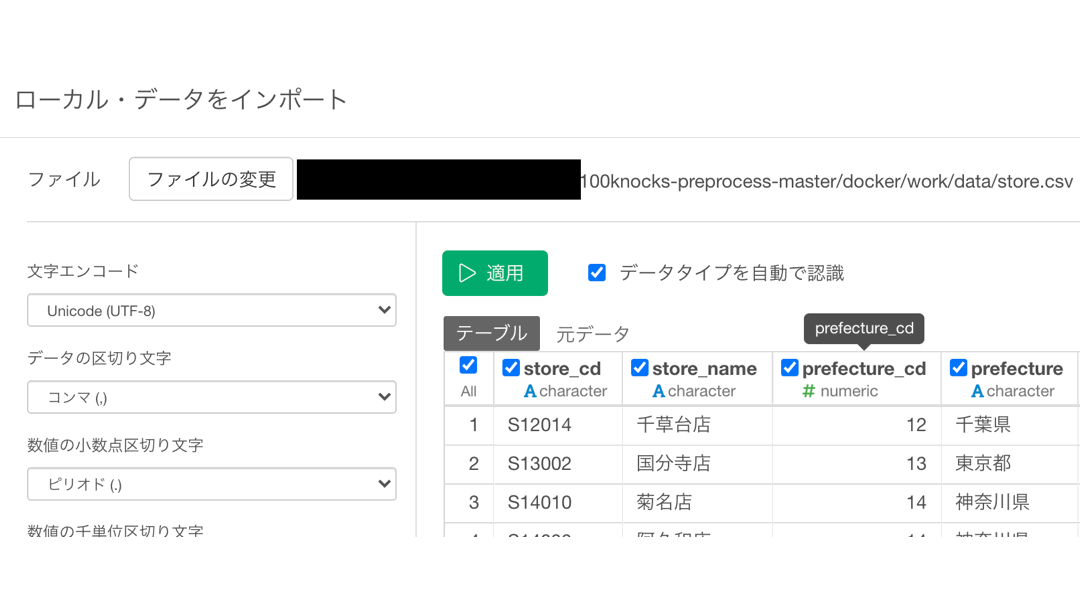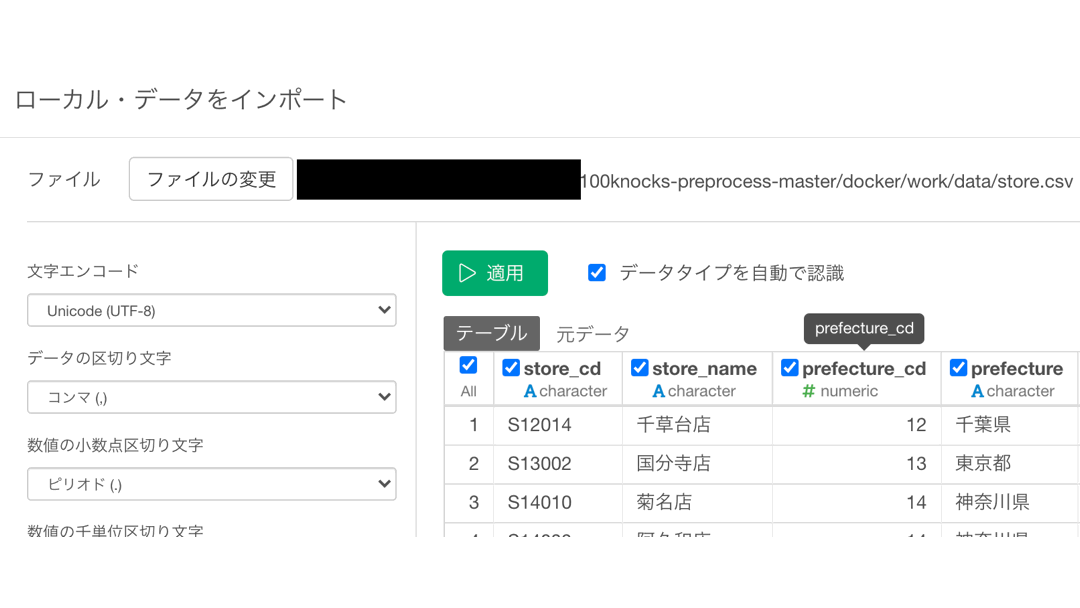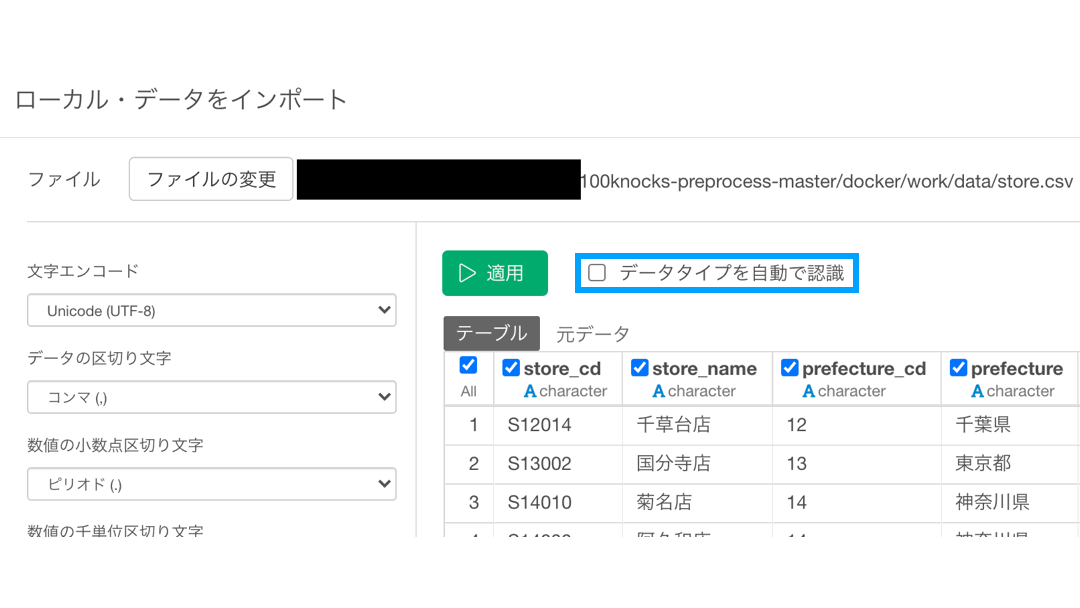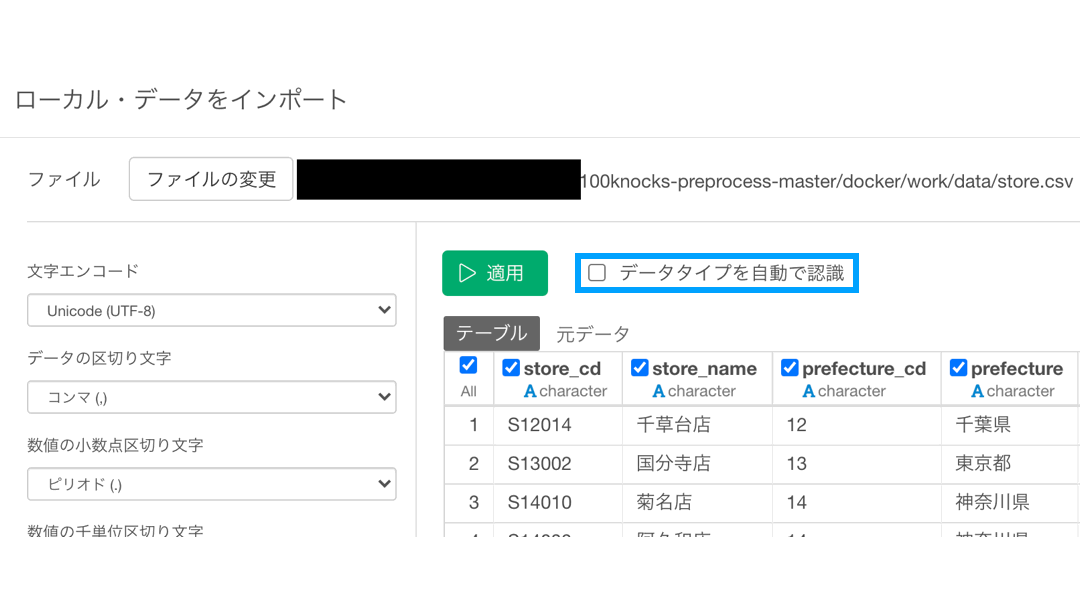 上の画面は、一番最初のステップであるココをクリックすると開きます。
上の画面は、一番最初のステップであるココをクリックすると開きます。 
データタイプを自動で認識する機能は当然ながら、データとして扱いやすく、しかも容量の軽い numeric型 が優先になります。
しかし、例えば numeric型 なのに 20181231 などのような、2018年12月31日を表す特別な数値データは、日付データにすることは見抜けません。
この場合は、こちら側で適切にデータタイプを変換してあげるなどの操作が必要になってきます。後の方で問題としてあります。
Python 解答コードはこちら
解答コードはこのようになっています。
df_store.query('prefecture_cd != "13" & floor_area <= 900')
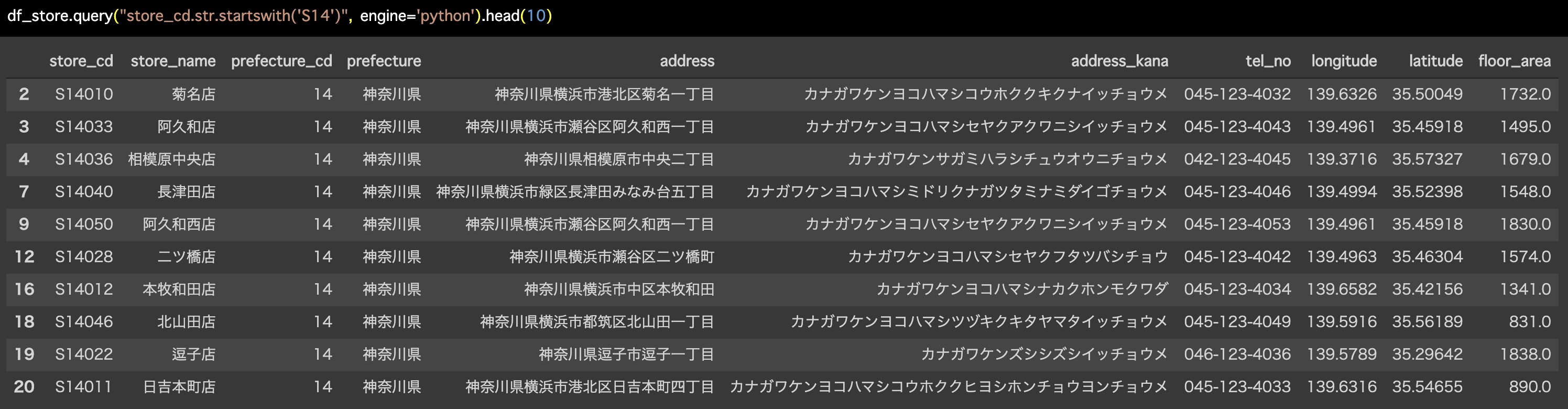
問10 : データの前方一致で条件指定する

答案・解説はこちら
だけじゃない!
文字型は、1000以上2000以下という操作はできず、「等しいか等しくないか」だけでやってきました。
しかし、文字列のフィルターには「〜から始まる」とか「〜で終わる」などのフィルターができるという、ある意味では数値データと一味違うフィルターができるはずです。
この問題で、この一味違うフィルターを体感して欲しいというのが10問目の大事なキーポイントだと思います。
・・・とは言っても、実は Exploratory のフィルターで一発解決 できます。
まずは store_cd を選択して、フィルターメニューを開きましょう。
そこから「この文字列から始まる」を選択します。 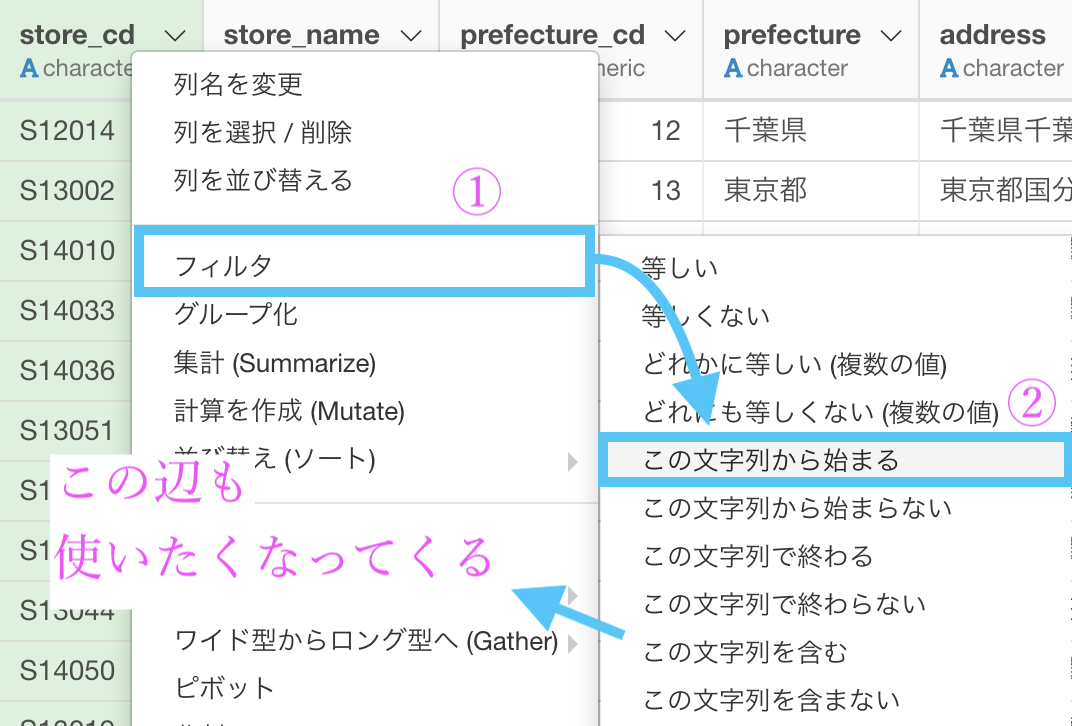
気付いた方も居るかもしれませんが、character型のデータをフィルターするので、「最初から以上や以下は選べない」ようになっています。
プログラミング言語でよくやる、つまらないエラーの防止策ですね!
なお、他のフィルターも別の機会で触っておくことをオススメします。
フィルターの画面が出てきたら、値のところに S14 を入力するだけで良いです。 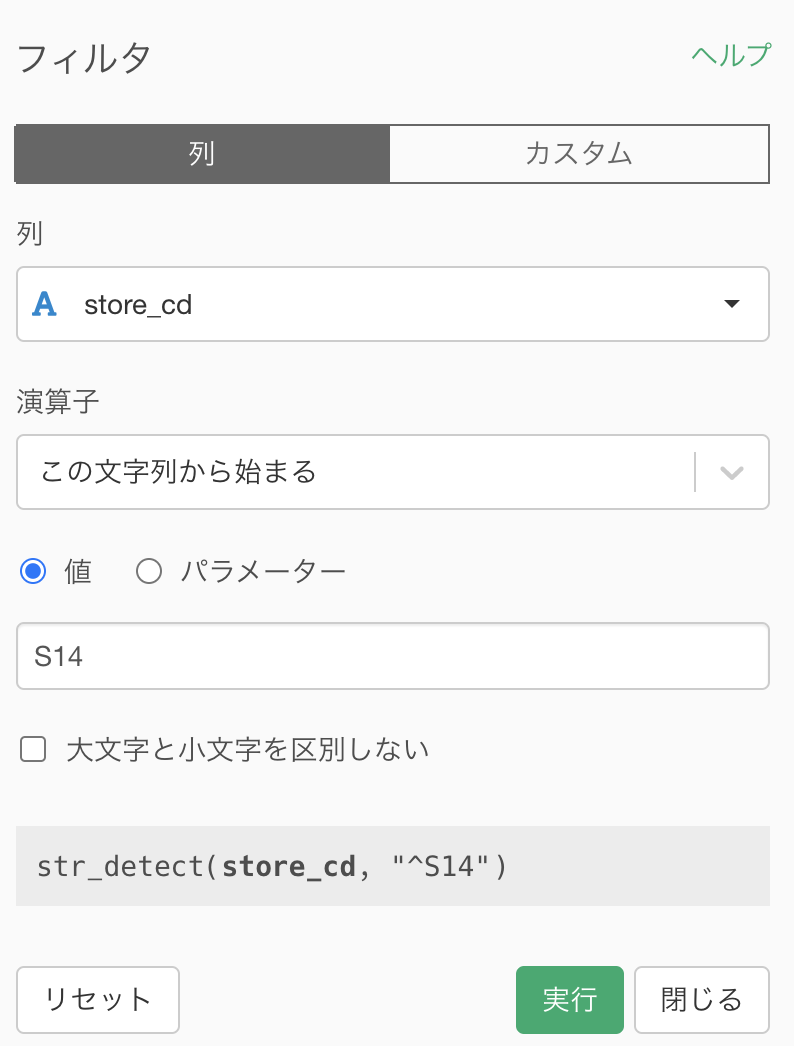
ちなみにコマンドを打ち込みたい人には以下のようにすれば良いです。
# フィルターからカスタム : str_detect(store_cd, "^S14")
# カスタム R コマンド : filter(str_detect(store_cd, "^S14"))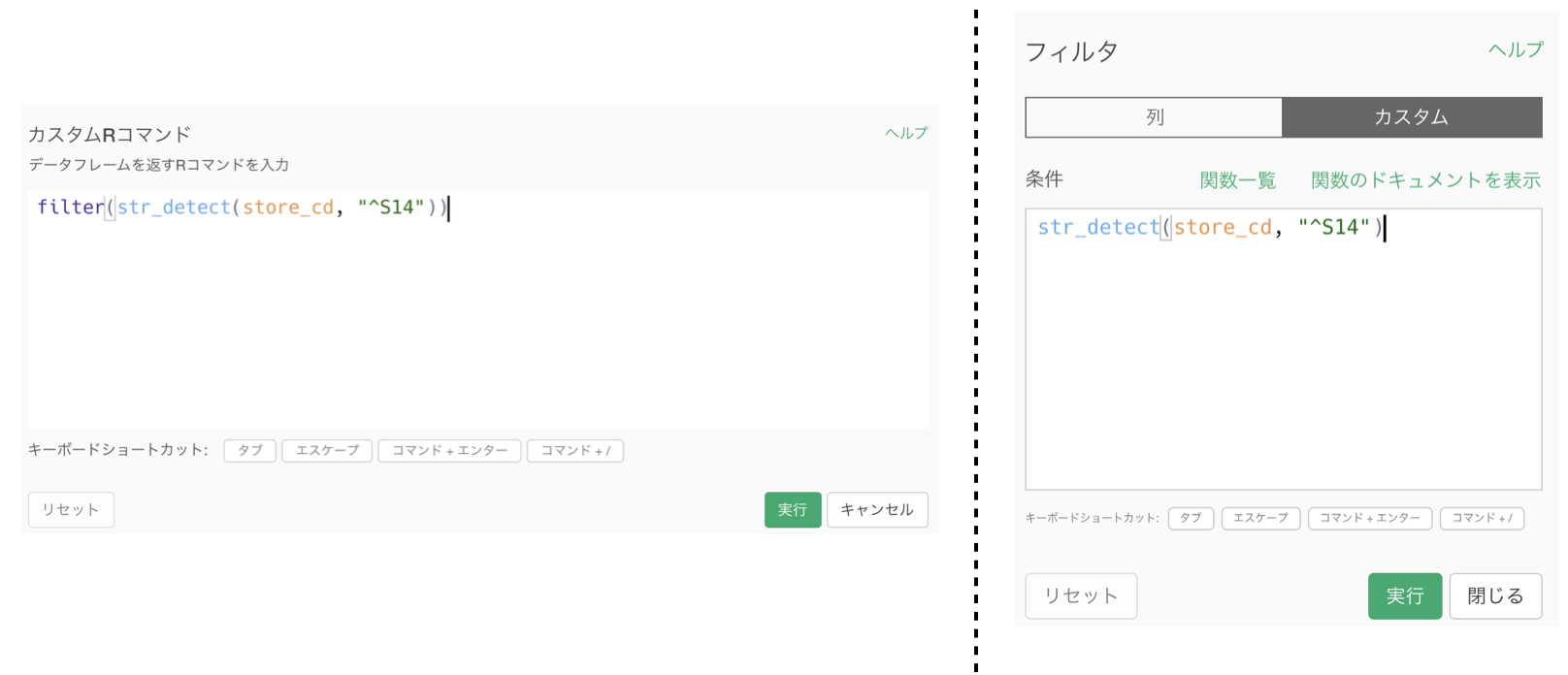
このような画面になっていればOKです。 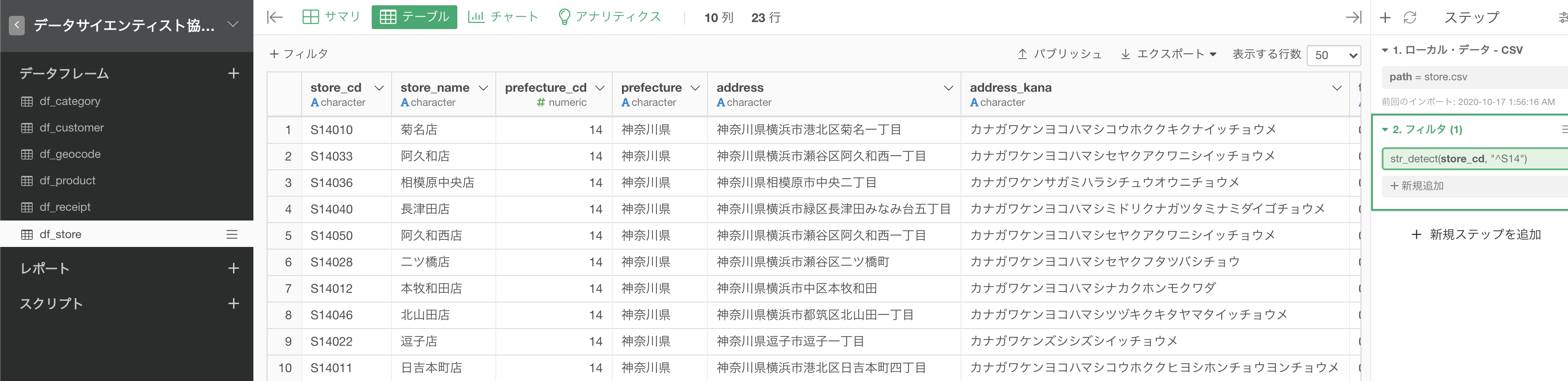
記念すべき10問目ということで・・・
今まで唯一、解答と一致させていないところとしては、10件表示させることでした。
もう最初の1問目から破ってました(笑)
ということで、カスタムRコマンドが使えるようになったのならば、実はかなりの自由を手にしています。以下のようにすれば良いです。 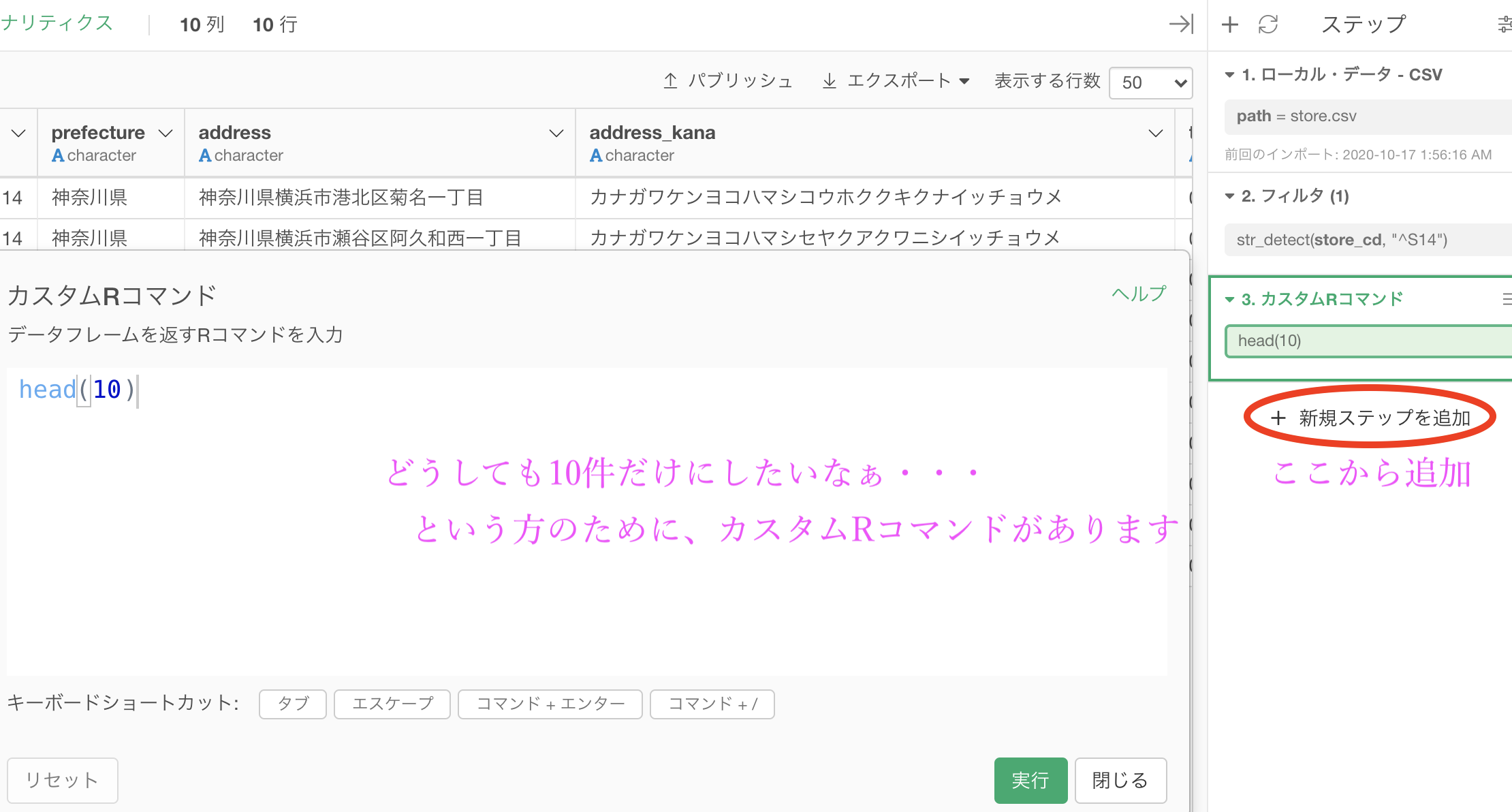
10問目で一旦ブレイク入れると良いかもしれません。
Python 解答コードはこちら
解答コードはこのようになっています。
df_store.query("store_cd.str.startswith('S14')", engine='python').head(10)