データサイエンティスト協会 構造化データ前処理 100 本ノック with Exploratory
問11〜問20 の答案
答案全体を通して
Exploratory では R 言語が動いていますが, 解答やコード参照の説明では Python言語 のものでやります。
SQL的な視点や考え方が入るときもその都度書きたいと思います。枠の色使いは以下のような形を意識しています。
オレンジ枠 :
あか枠 :
あお枠 :
みどり枠 :
問11 : データの後方一致で条件指定する

答案・解説はこちら
問10 では、store_id の中から「"S14" で始まる」というフィルターをしました。
今回の問11 では、customer_id の中から「"1" で終わる」というフィルターをしなさい、と問題文を解釈することができます。
なので、問10 とほぼ同じ操作だということになります。
早速やっていきましょう。
まずは df_customer のデータを開いて、customer_id の列を選択しましょう。
そこから、フィルター→「この文字列で終わる」とします。 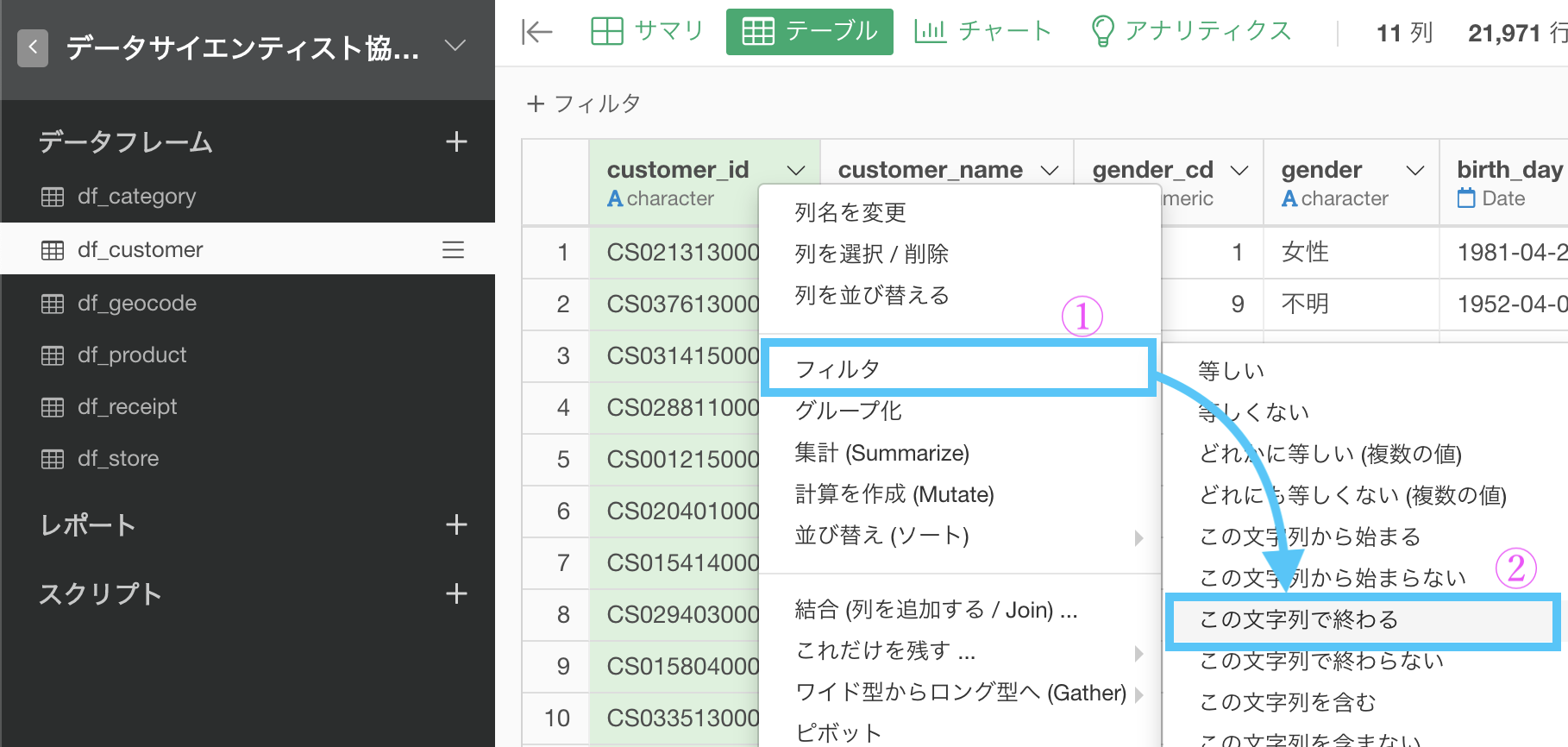
するとこのような画面が開くので、値の中に「1」と入力すればOKです。 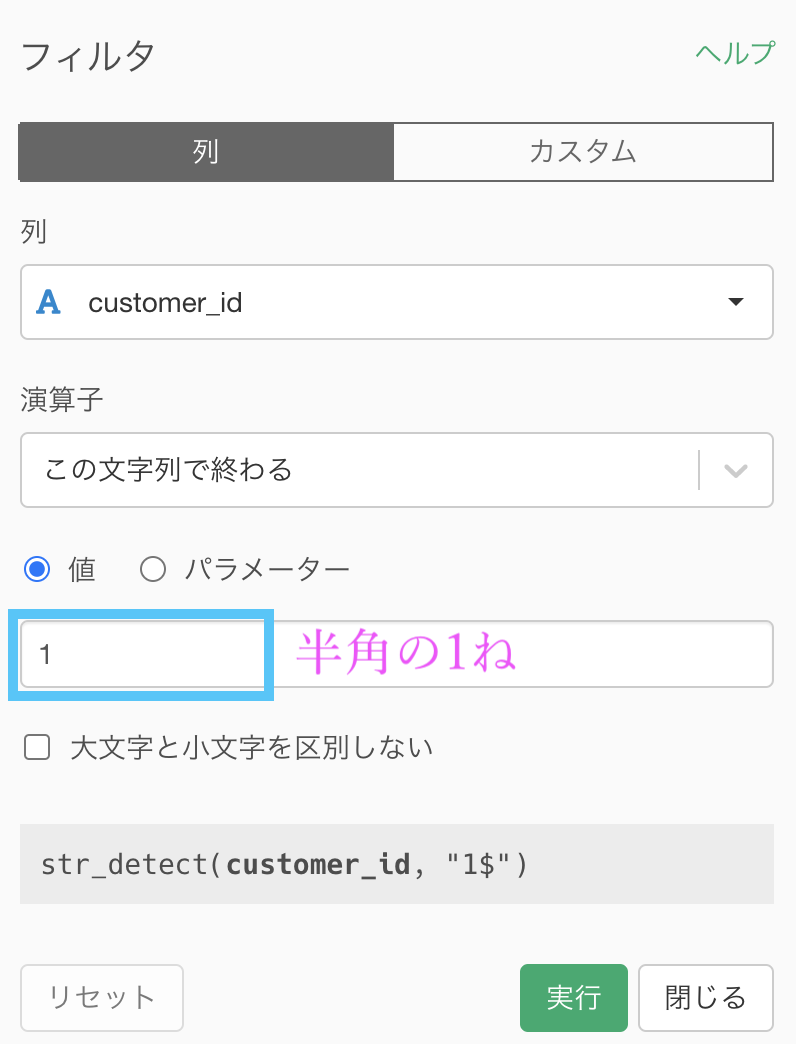
これで実行すれば次のような結果が得られたでしょう。解答と確認してみてください。 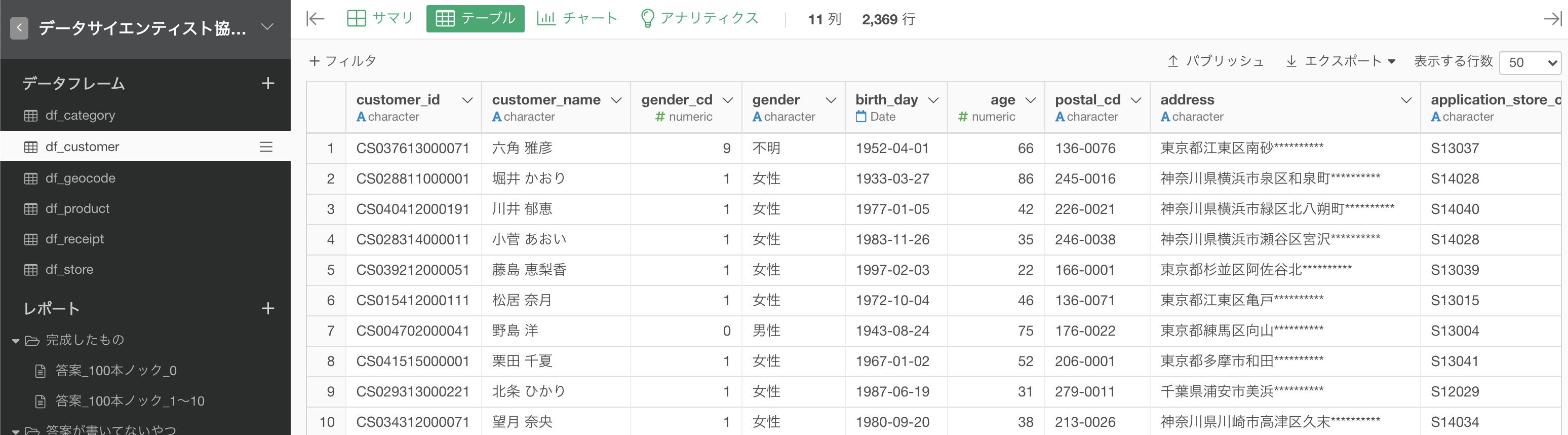
Python 解答コードはこちら
解答コードはこのようになっています。
df_customer.query("customer_id.str.endswith('1')", engine='python').head(10)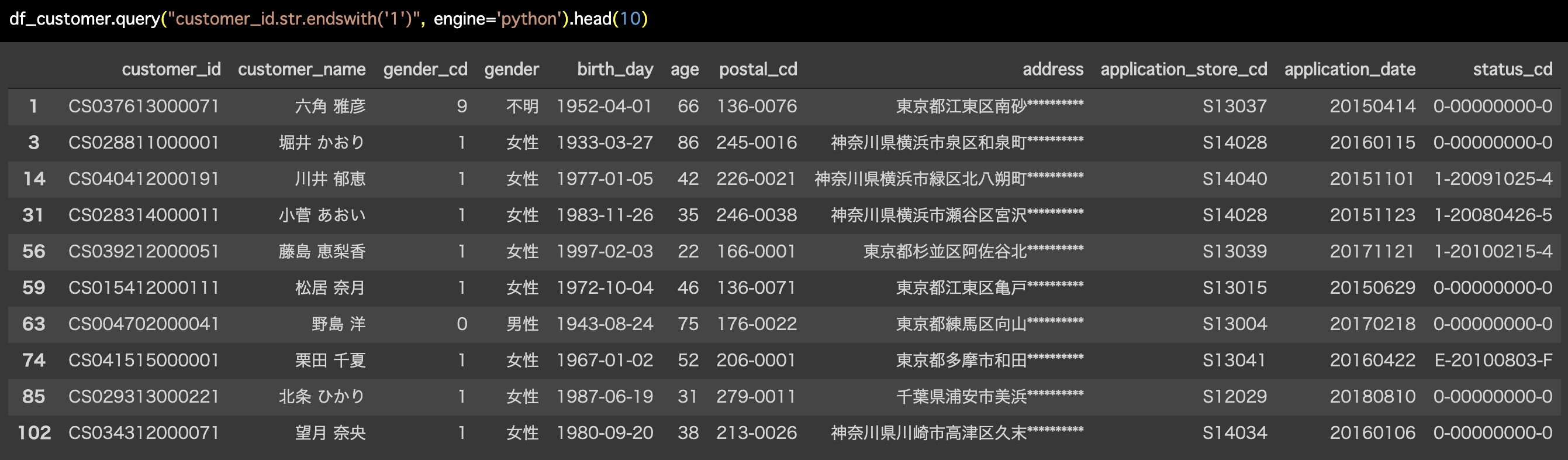
コマンドの話
いろいろ語る前に、とりあえず次の比較を見てください。 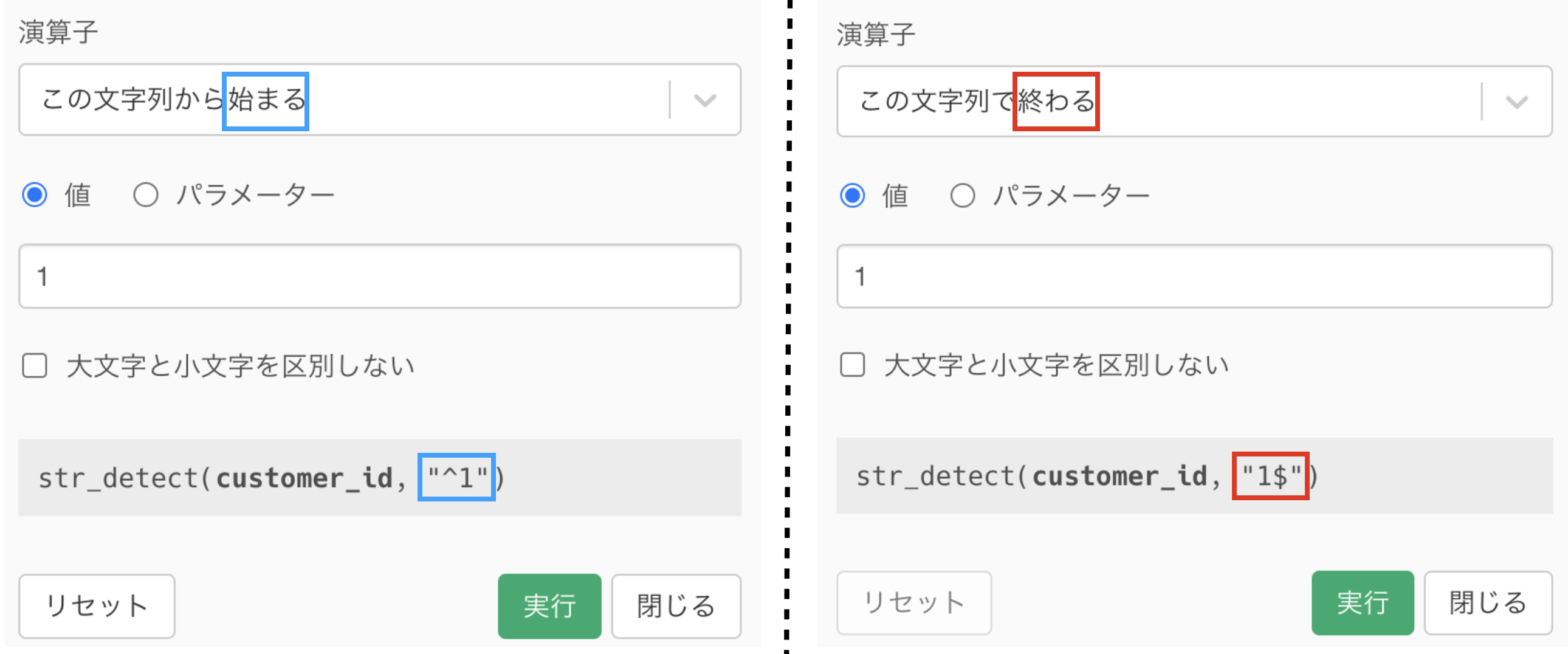
この文字列から「始まる」のか「終わる」のかでコマンドが異なるのはこの程度であることがわかるでしょう。
ここから先は物好きの話なので飛ばしても良いです。
さらにコマンドの話
折りたたむ内容 何度も言ったかもしれませんが、Exploratory は R言語 で動いています。
今回のフィルターは、カスタムRコマンドだと次のように実行できます。
filter(
str_detect(customer_id, "^1")) # これが「始まる」フィルター
filter(
str_detect(customer_id, "1$")) # これが「終わる」フィルター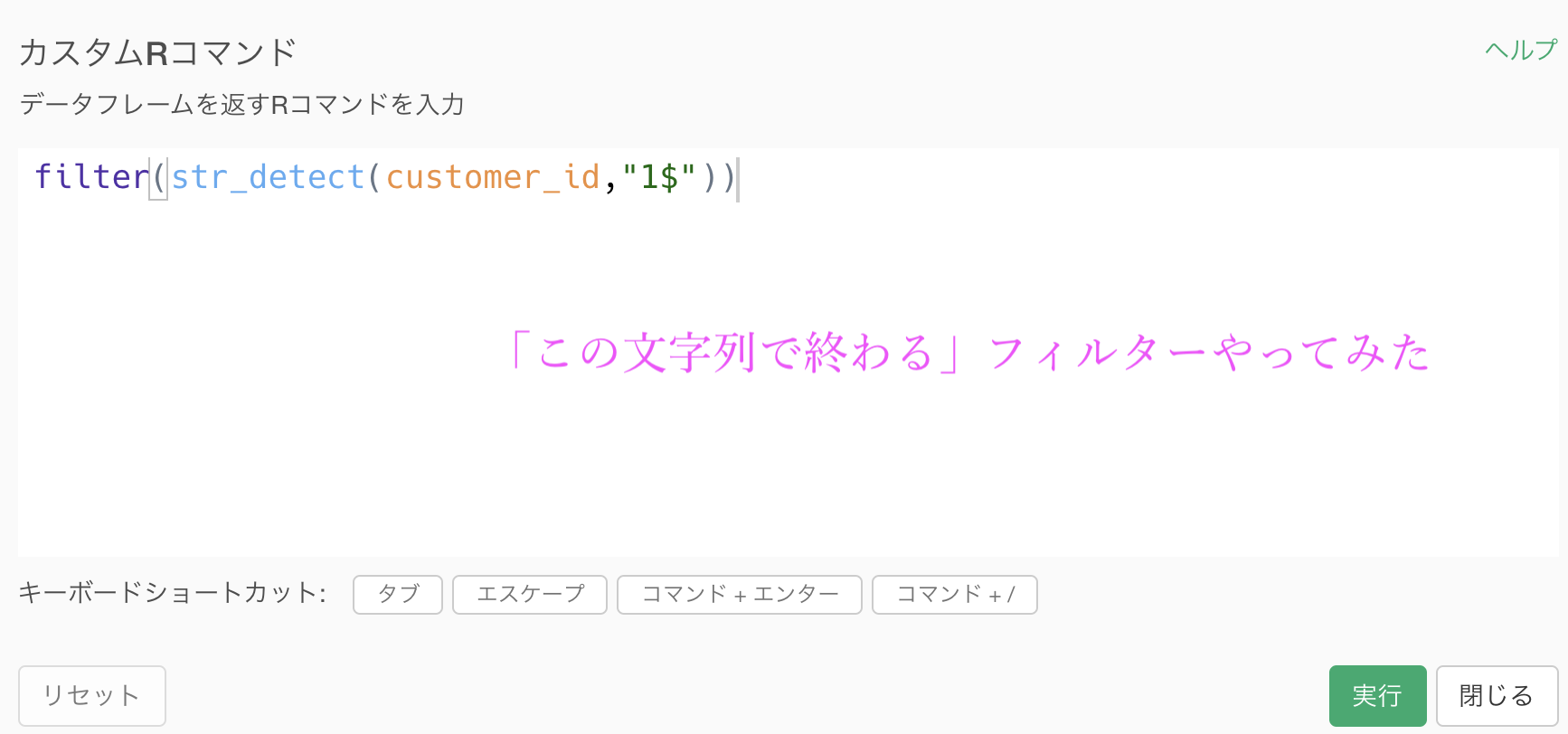
一方で Explroatory では実装できませんが、Python の解答コードから、同じ処理だと次のように表現されます。
df_store.query("store_cd.str.startswith('1')", engine='python').head(10)
df_store.query("store_cd.str.endswith('1')", engine='python').head(10)Python だと startswith か endswith かの違いということですが、R の方は ^1 か 1$ かの違いということでした。
R の方が短くて読みやすいと言えば読みやすいかもしれません。
問12 : データの部分一致で条件指定する

答案・解説はこちら
df_store の中にある adress という列は文字型ですが、この中から "横浜市" という文字を含むものをフィルターせよ、という問題の読み方です。
すると、文字列で「始まる」と「終わる」をやったんだから「含む」もできそうだ!という思考ができてくるわけです。
そして実装するときも同じメニューのところから選びますので、問10 や 問11 と同じレベルの問題なのです。
まず、df_store のデータから adress を選択し、
フィルター →「この文字列を含む」を選択しましょう。 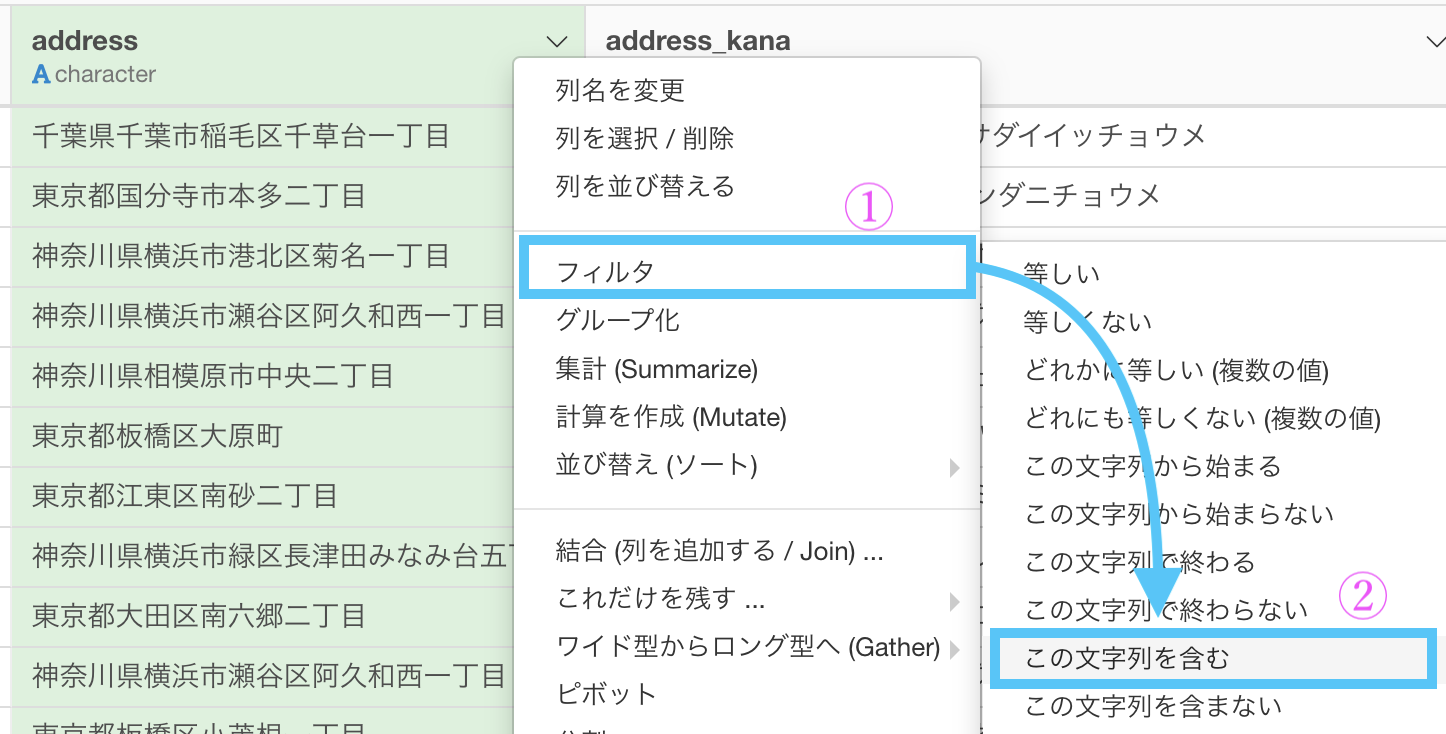
そして値の中に「横浜市」と入力して実行しましょう。 
このような結果になったかと思います。解答と照らし合わせてみましょう。 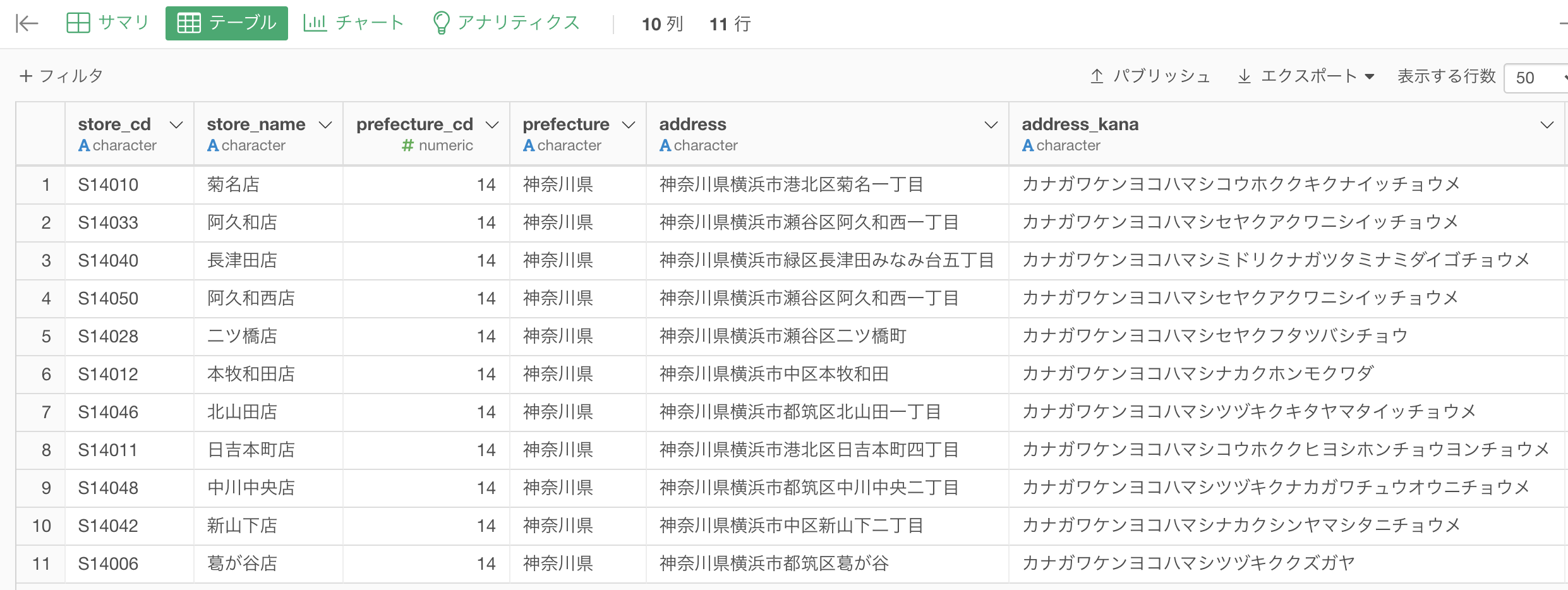
文字型のフィルターを得意になる意味
文字列のフィルターの問題がこのあとも何個か続きます。
フィルターを得意とする理由はいくらかあるのですが、大きな理由として思うのは、前処理(特に文字の変換)をすることがフィルターの先に待ち構えているのです。
文字型のデータは全角の「1」なのか半角の「1」なのかすら区別されます。
当然のことながら、「Exploratory」と「EXPLORATORY」も区別されますし、あるいは「1ヶ月」と「1ケ月」もそうです。
あるいは「清水(しみず)」なのか「清水(きよみず)」なのかという読みの違いなどまで考えると、機械と人間の感覚の違いが少しずつ見えてくるかと思います。
見つかれば直そう!と次の段階に踏めますが、見つからない(知らなかった)場合は直せませんので確実にスルーなのです。
現実問題でも、知らなかったでは済まされない瞬間はやっぱりあるのです。
文字型のデータ(一般にテキストデータ)を扱う時には、前処理が非常に大事になってくるのです。他のデータよりも顕著です。
しかし、今あげたのも含めてほとんどの場合は Explroatory で完結するものばかりです。
逆に、どれだけ頑張っても Exploratory で処理できないテキストデータはかなりクセのつよいデータなので滅多に出会さないか、あるいは全体方針を見直すことになると思います。
なお、URLのデータもテキストデータですが、それも処理可能です。
Python 解答コードはこちら
解答コードはこのようになっています。
df_store.query("address.str.contains('横浜市')", engine='python')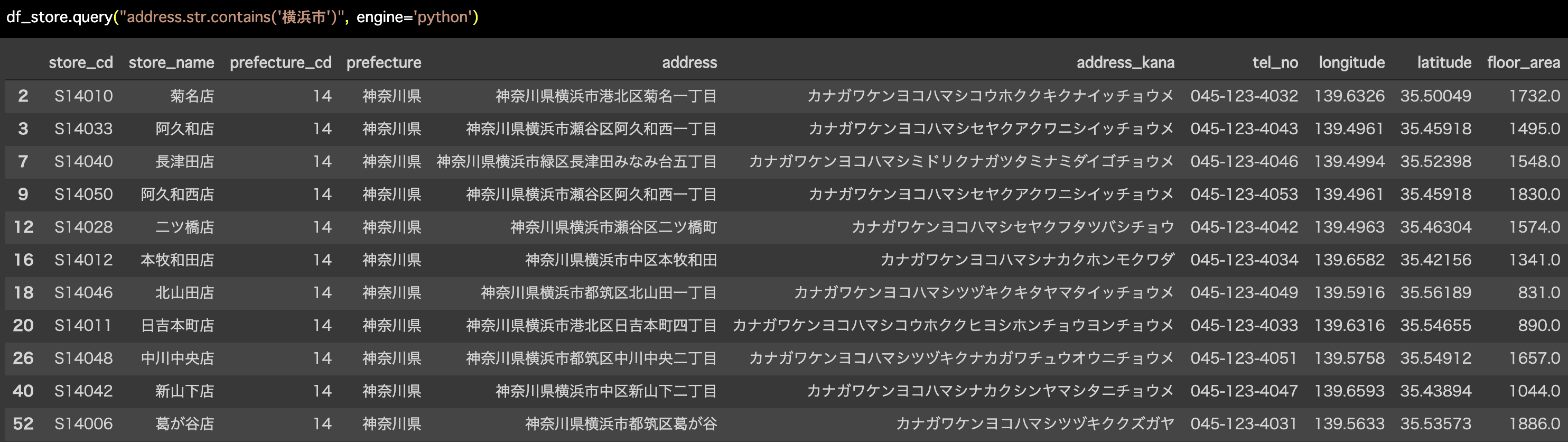
問13 : 正規表現の前方一致で条件指定する

答案・解説はこちら
本当かどうか、とりあえず一度やってみましょう。
まずはフィルター → 「この文字列から始まる」としましょう。 
値のところに、[A-F]と打ち込んでみました。
実行してみましょう。 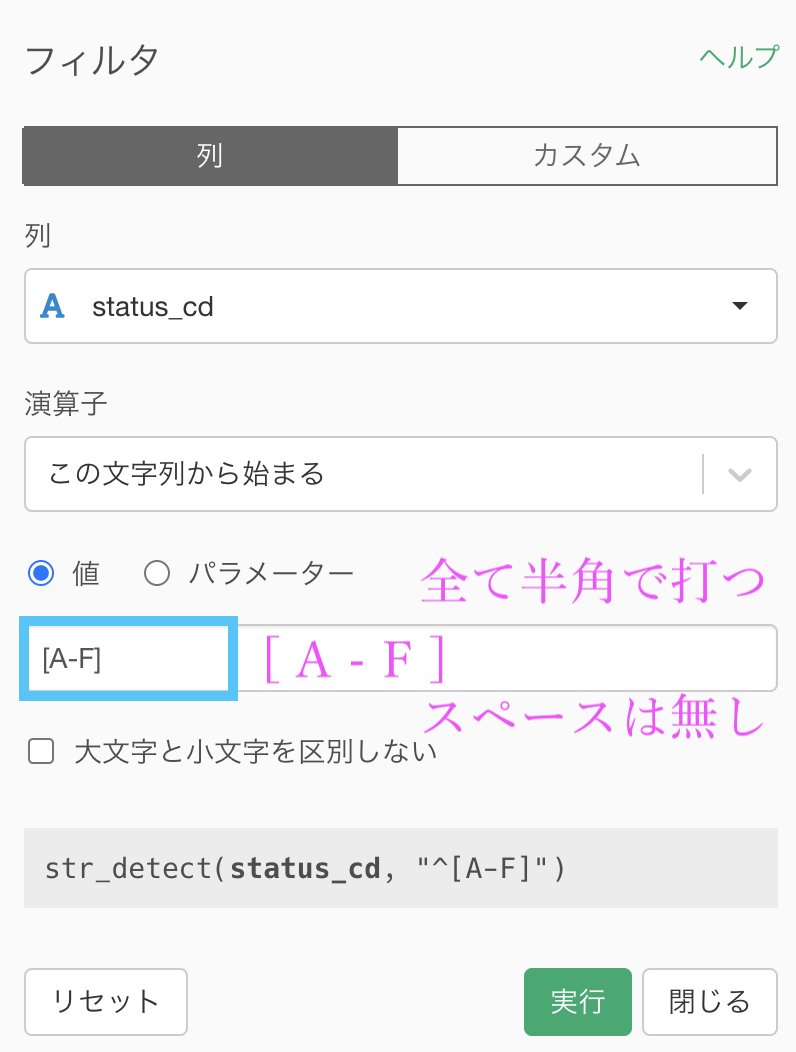
結果はこのようになったかと思います。解答のデータと一致しているか確認してみましょう。 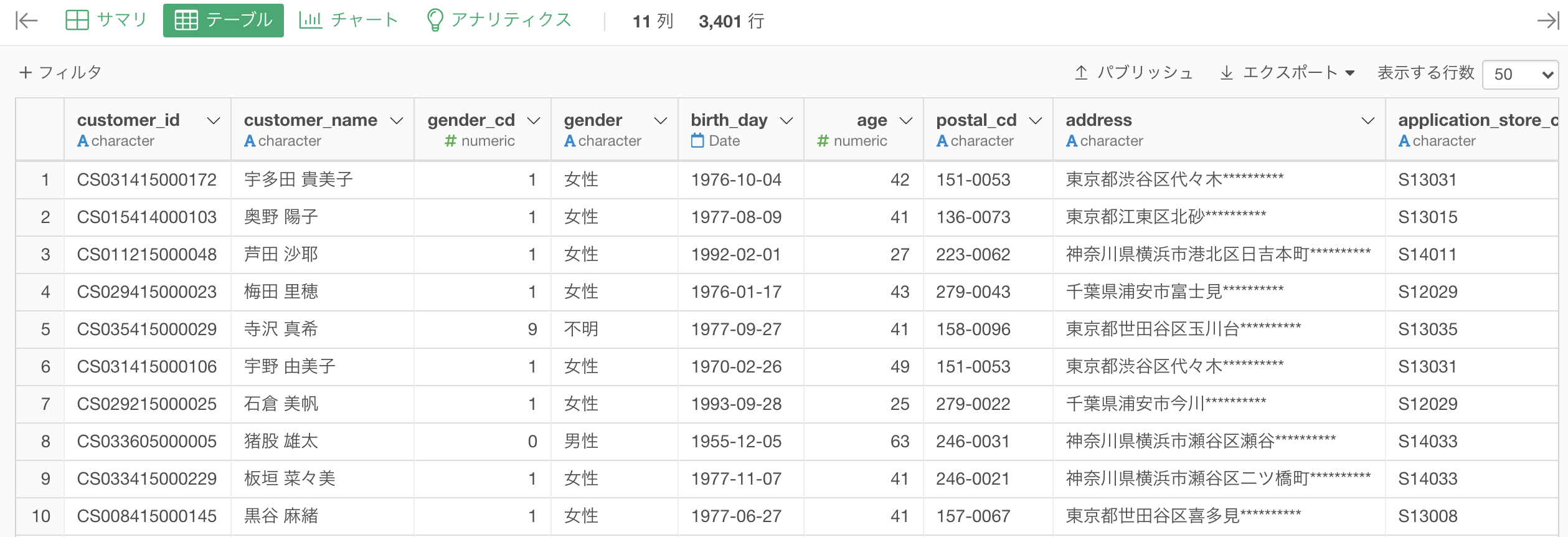
Python 解答コードはこちら
解答コードはこのようになっています。
df_customer.query("status_cd.str.contains('^[A-F]',
regex=True)", engine='python').head(10)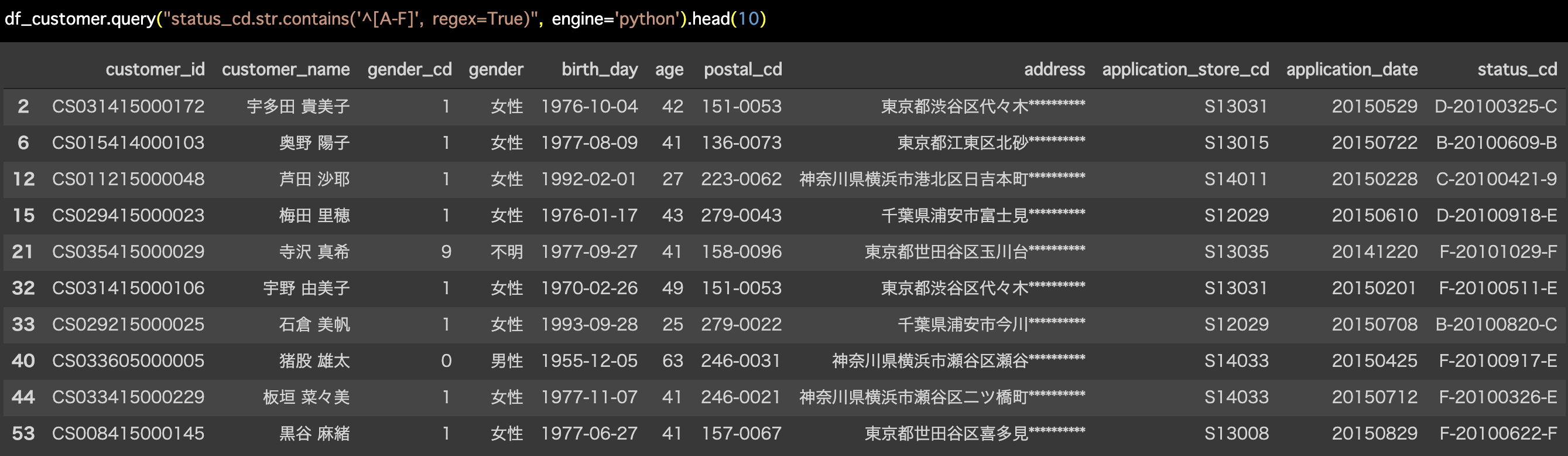
[A-F]の伏線回収
伏線を回収したいと思います。
[A-F] を入力するだけで良かったのですが、これは R言語 でも Python言語 でも使う、共通の書き方です。解答コードをよく見ると(他は読まなくても)書いてありますよね。
ここでは、[A-F] が信用できない人のために「確実に地道に」やる方法...つまり別解を紹介したいと思います。
問13の別解はこちら
まずテキストデータなので、テキスト分析の関数はほぼ全て用いることができます。(この思考は大事!)
なので、テキストデータの加工 (関数) → 「指定した範囲にある文字列を取り出す」を選択しましょう。 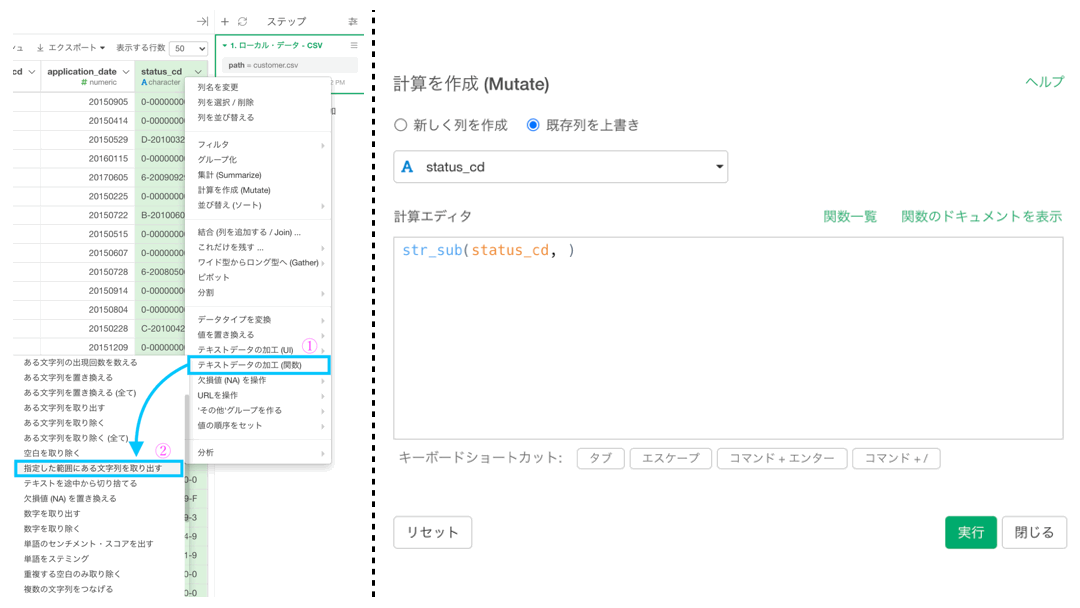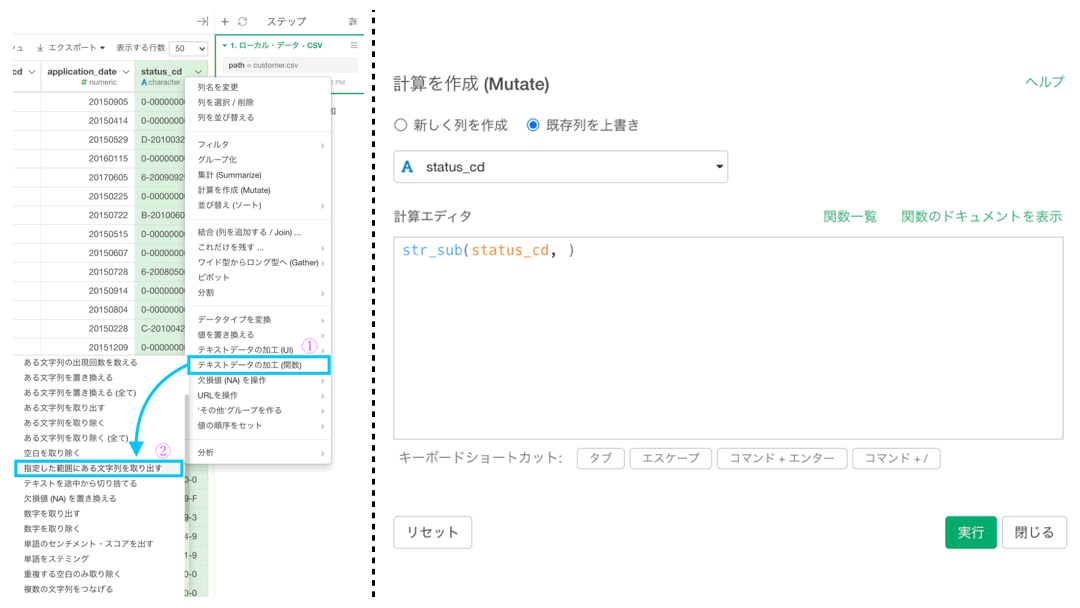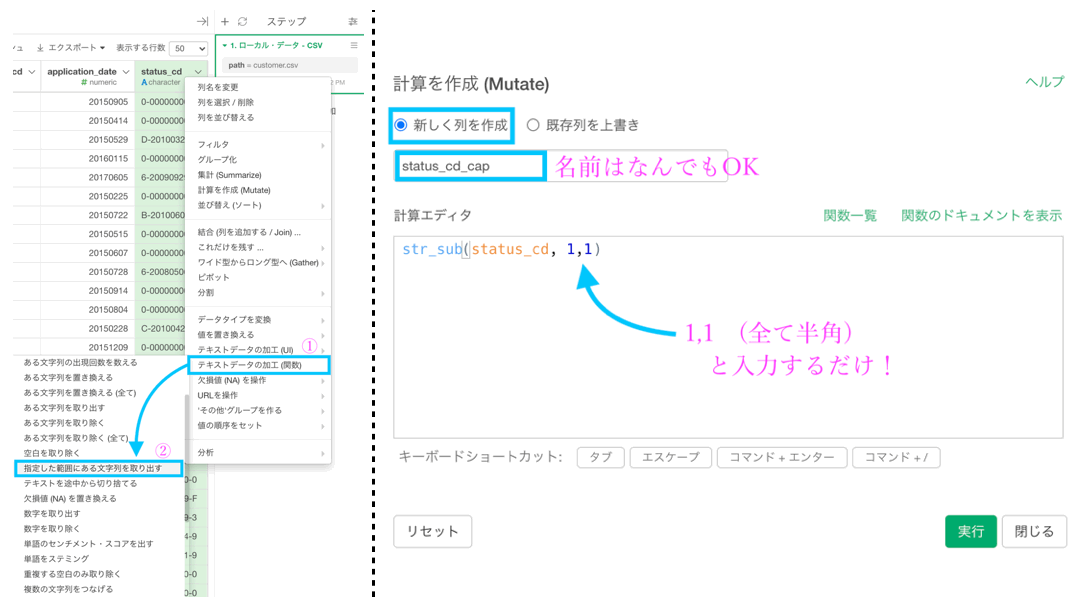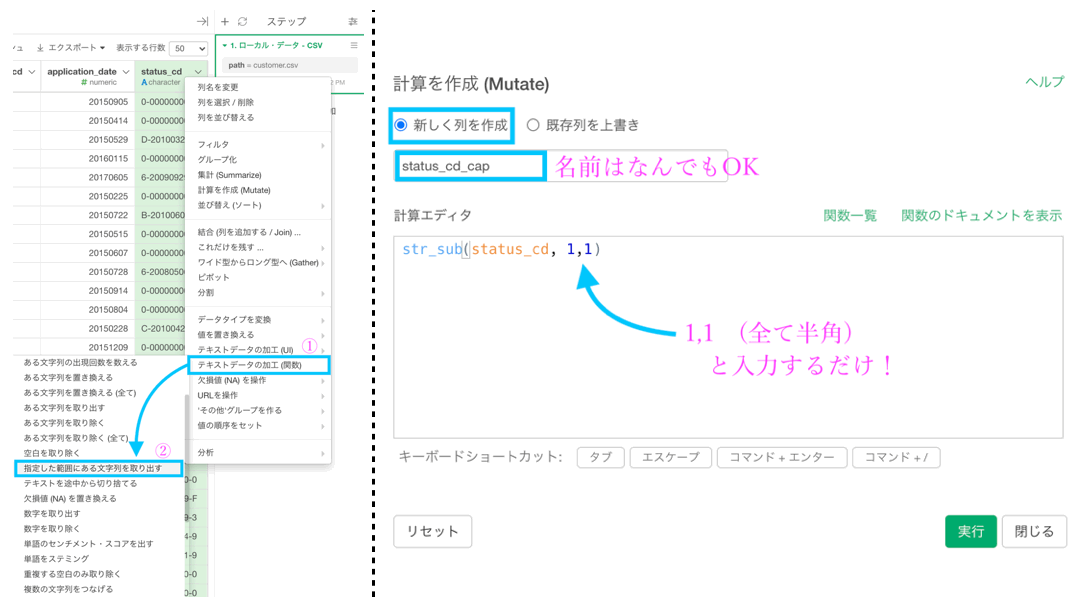 いつものように計算エディタが出た(右上みたいに)と思いますので、次の操作をしてください。
いつものように計算エディタが出た(右上みたいに)と思いますので、次の操作をしてください。
- 「新しく列を作成」にする(名前はなんでもOK. ここでは status_cd_cap)
- 該当箇所に「1,1」と入力する( → 1〜1 の範囲 = 先頭の文字を取り出す意味)
str_sub(status_cd, 1,1)となっていれば良いです。これで実行しましょう。
status_cd_cap という列ができたと思います。
頭文字だけ取り出したので、これに対してA〜Fのものだけのフィルターをかければ良さそうです。
簡単のため、まずはアルファベットだけにフィルターしましょう。
フィルター → 「アルファベットのみ」を選択します。 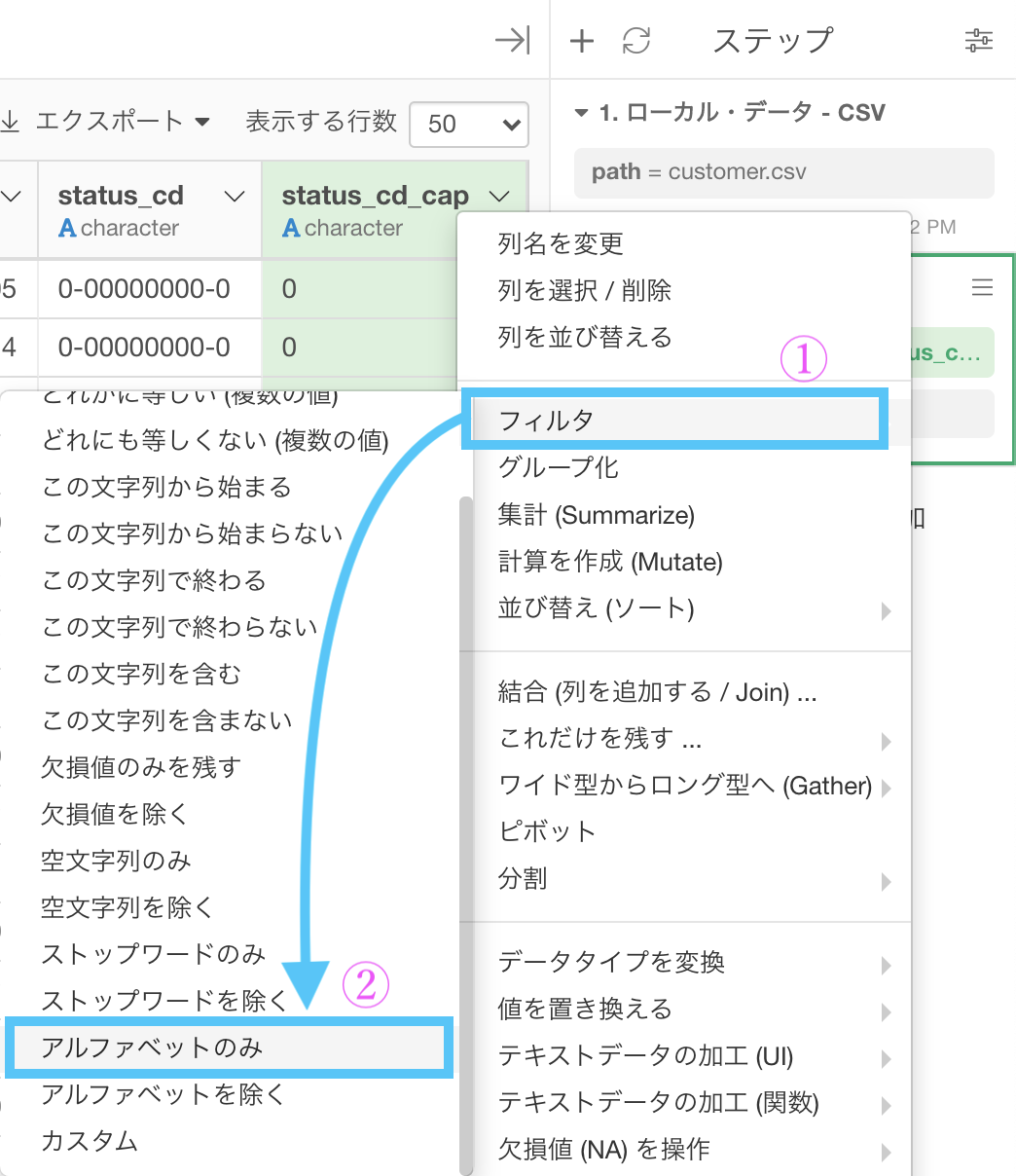
この画面は何もすることないのでこのまま実行します。 
次に、フィルター → 「どれかに等しい (複数の値) 」を選択します。 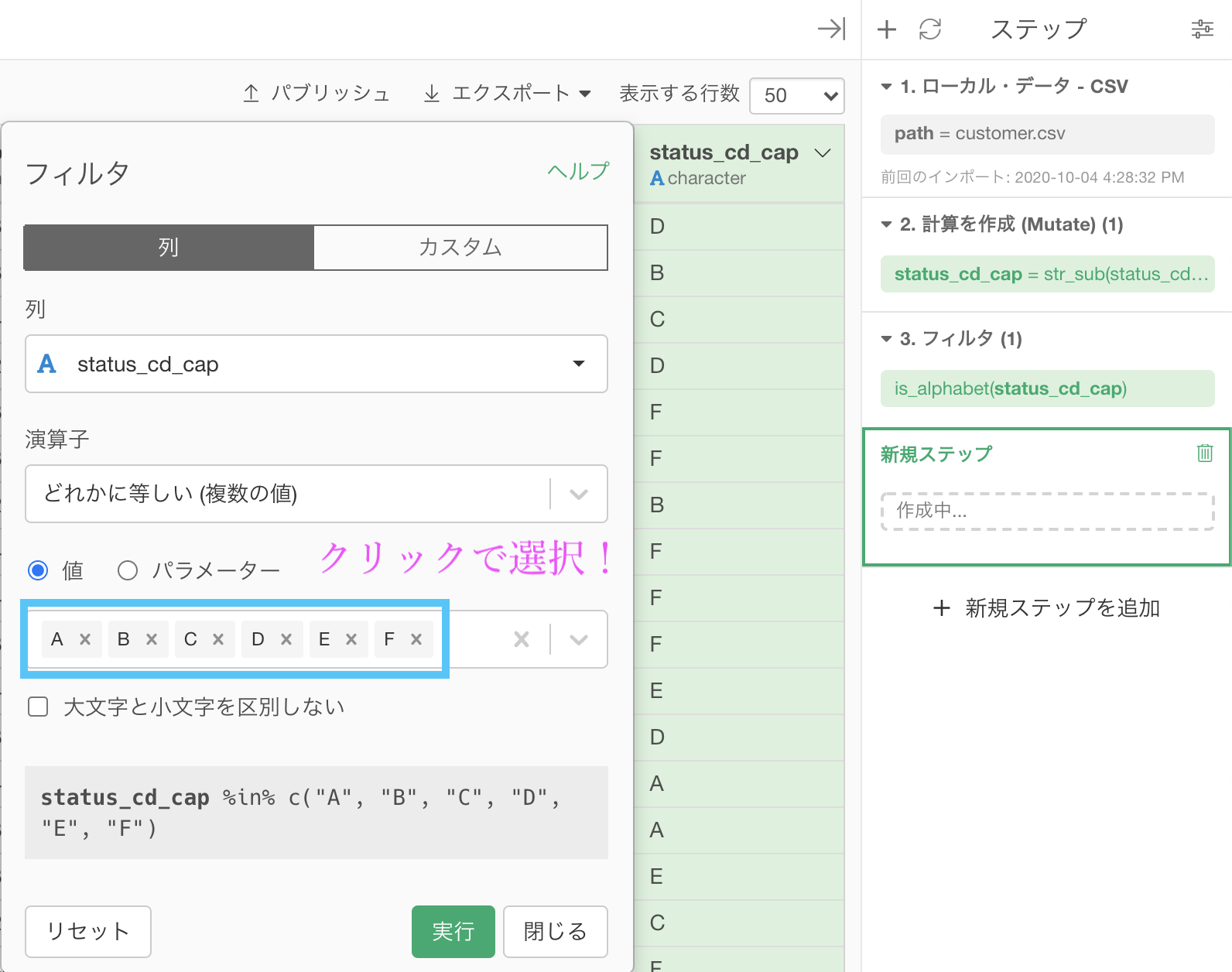 値の中をクリックすると選択肢が出てくるので、A〜Fまで(今回の場合は全部ですが...)を選択して実行しましょう。
値の中をクリックすると選択肢が出てくるので、A〜Fまで(今回の場合は全部ですが...)を選択して実行しましょう。
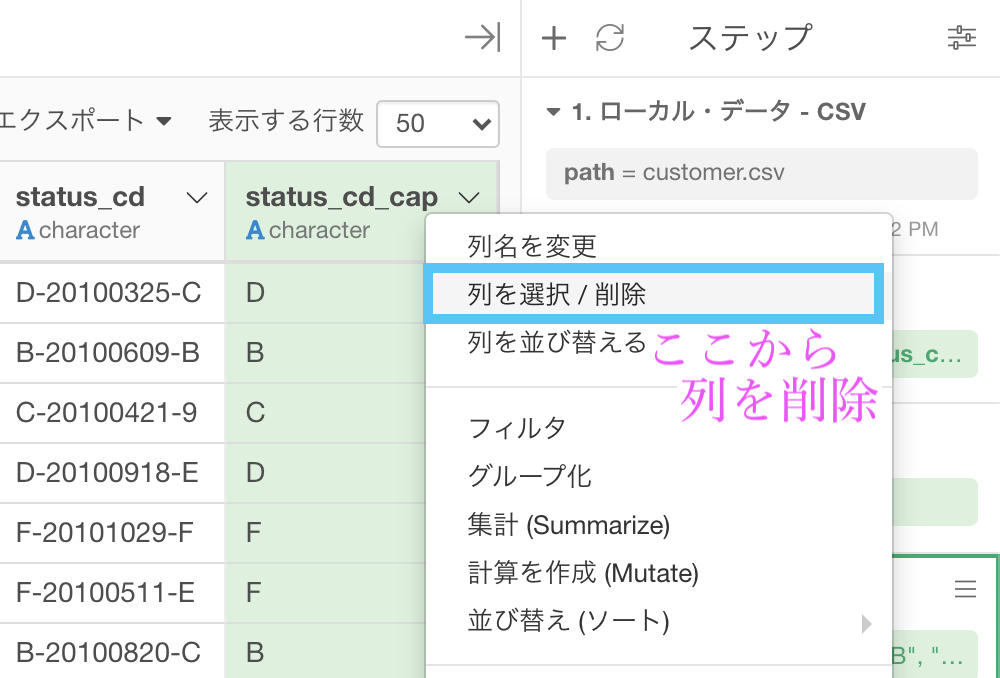
すると答案や解答と同じになります。 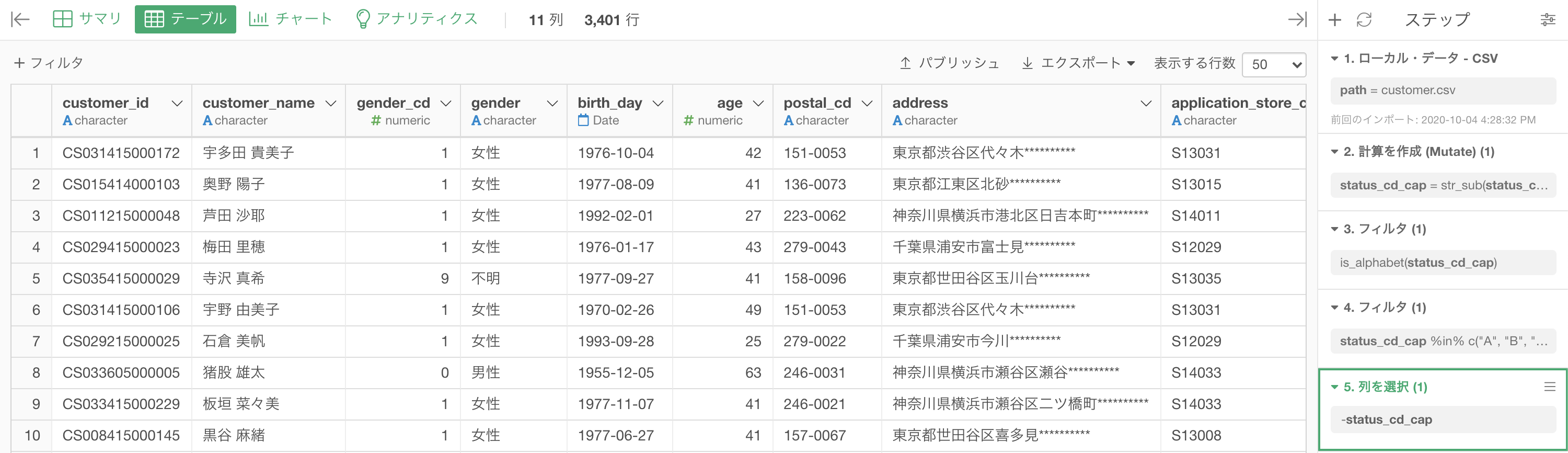
問14 : 正規表現の後方一致で条件指定する

答案・解説はこちら
というノリでやっていただければ良いかと思います。
[A-F]が入力できているとすれば、[1-9]と入力するのは問題ないと思います。 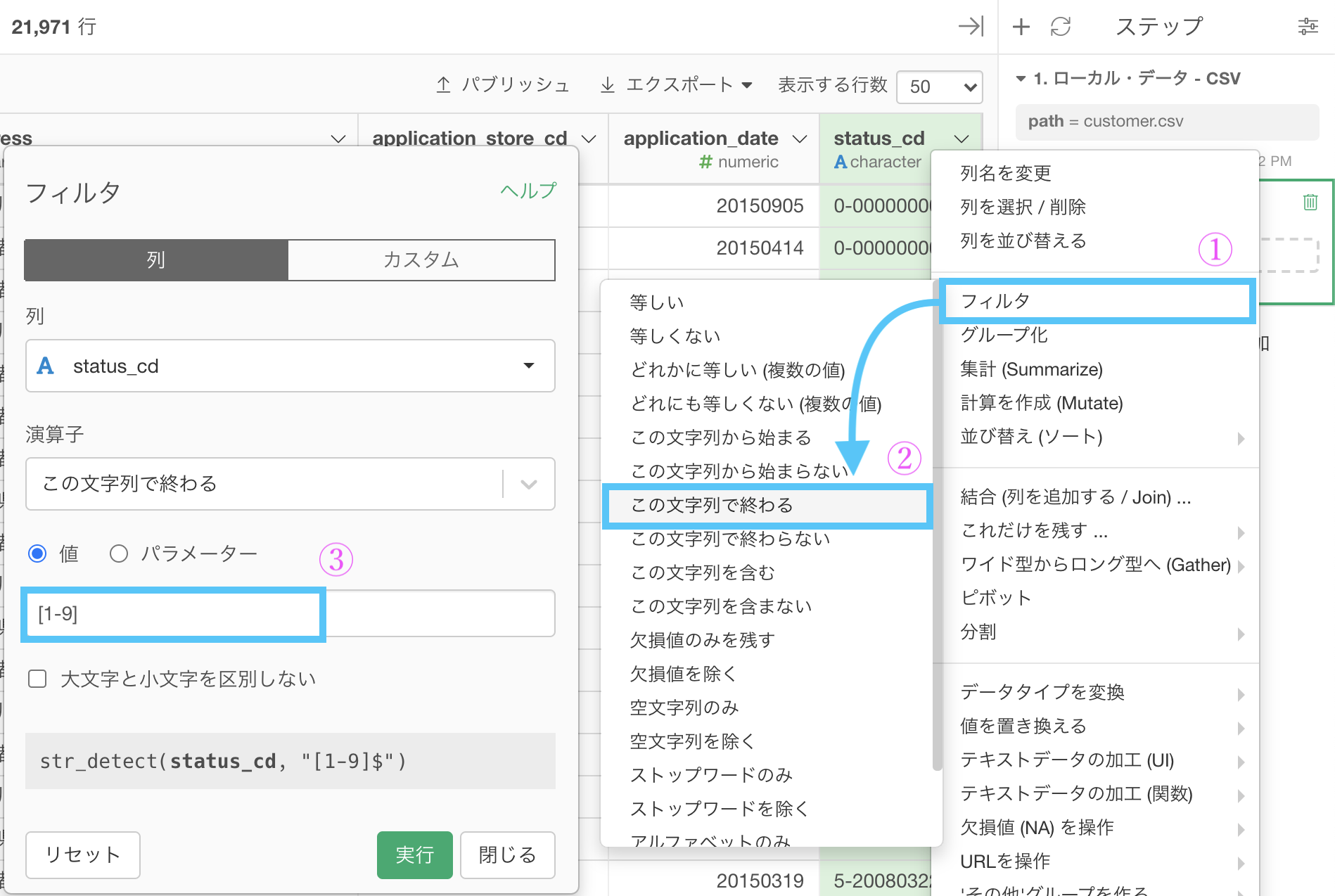
実行すると以下のような結果になったと思います。解答と一致しているか確認しましょう。 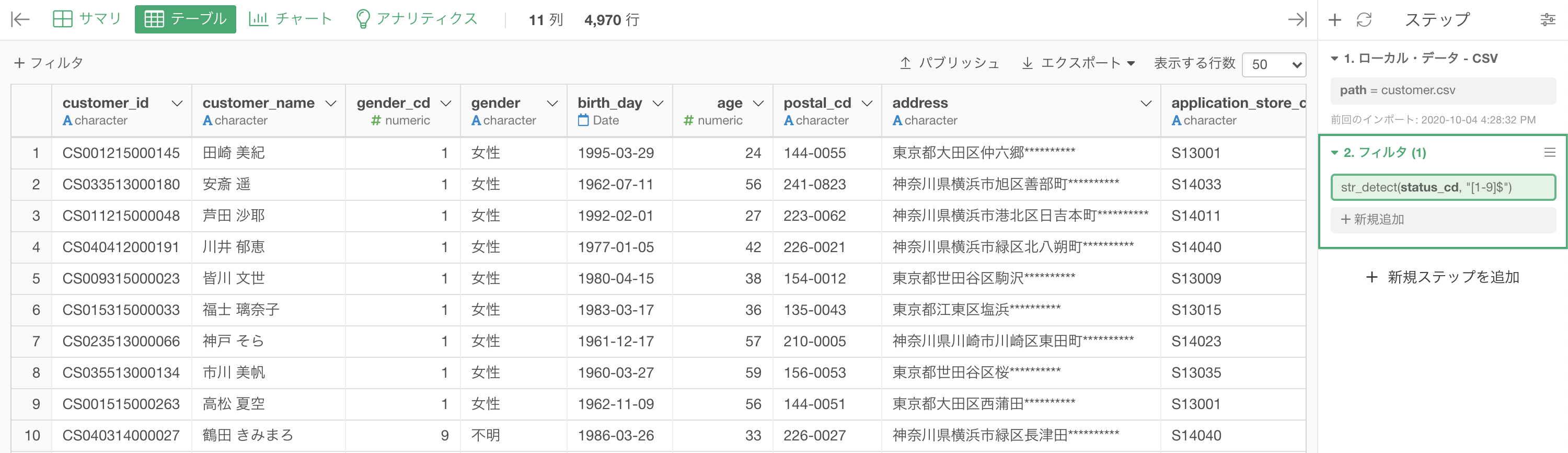
Python 解答コードはこちら
解答コードはこのようになっています。
df_customer.query("status_cd.str.contains('[1-9]$',
regex=True)", engine='python').head(10)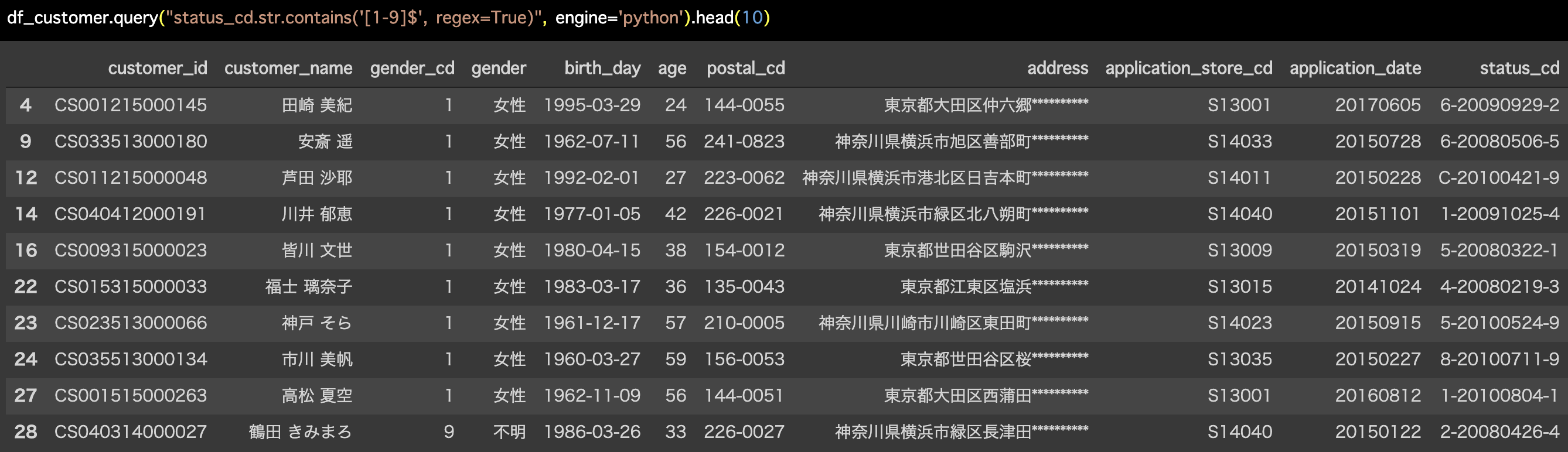
これはぜひ(問13の別解から参考にしつつ)別解を作ってみてください。
問13の別解以外にも、テキストデータの加工 (関数) のメニューから「数字を取り出す」というものがあるのでそれを使ってみるのも手ですよ!
問15 : 正規表現の部分一致で条件指定する

答案・解説はこちら
をすれば良いということになります。
したがって、このことが分かれば答案としてはほとんど終わっています。 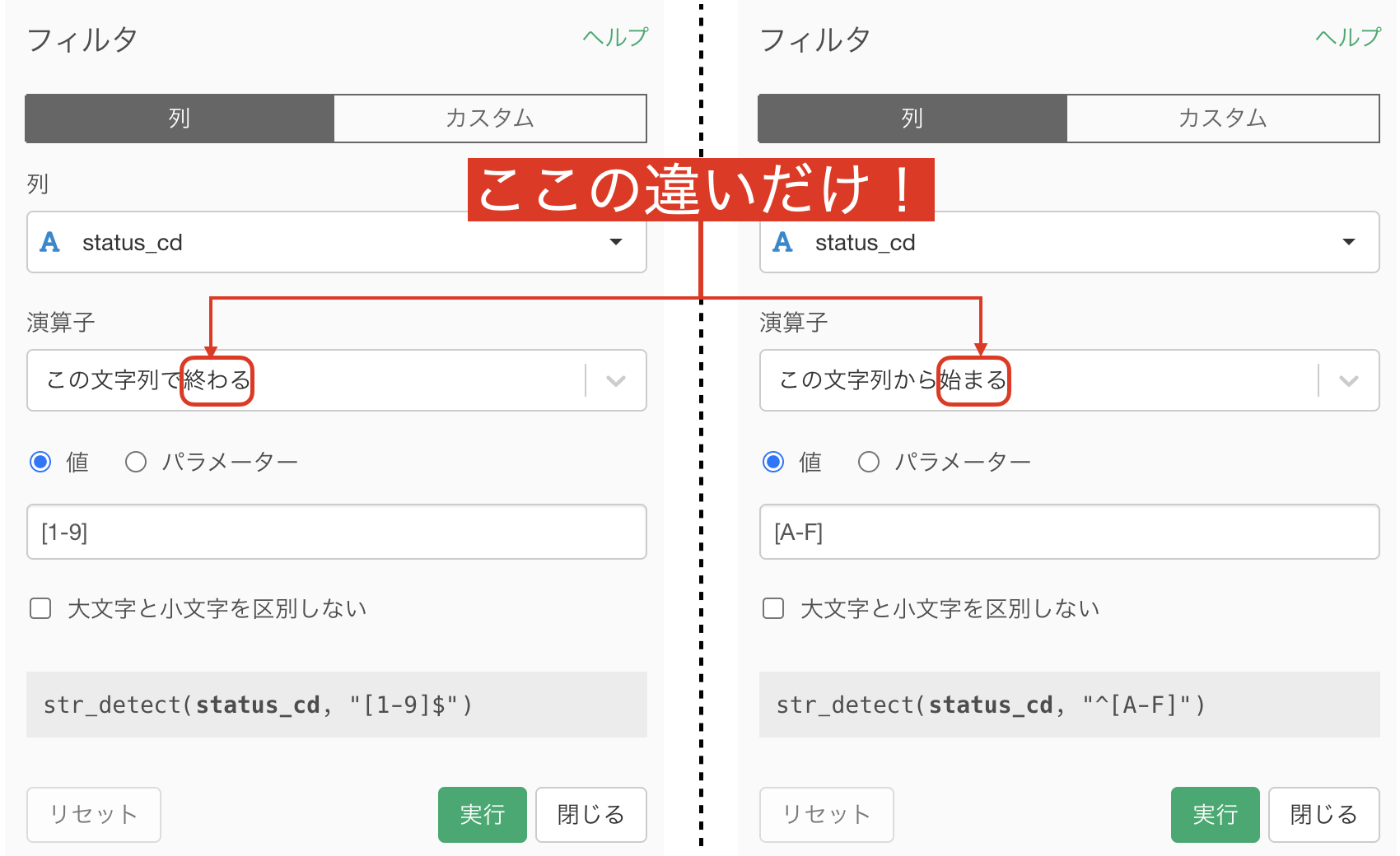 なお、「かつ」なのでフィルターをかけるのはどの順番でも構いません。
なお、「かつ」なのでフィルターをかけるのはどの順番でも構いません。
実行すると以下のような画面になっているかと思います。 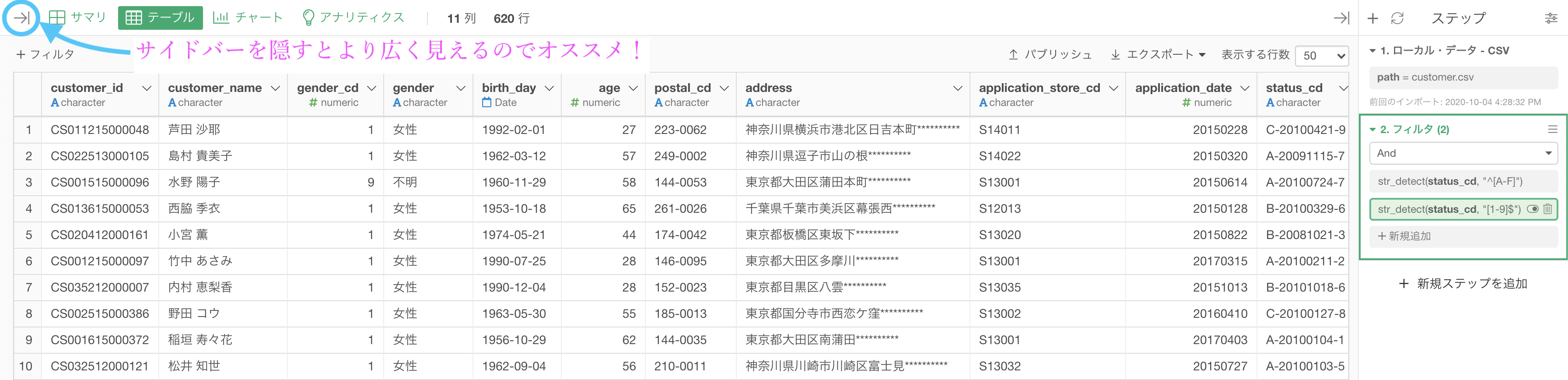
- データを広くみたい・そのデータに集中したいとき : サイドバーを隠す
- データを遷移したい・データ間で操作をしたいときなど : サイドバーを表示する
と良いかと思います。
Python 解答コードはこちら
解答コードはこのようになっています。
df_customer.query("status_cd.str.contains('^[A-F].*[1-9]$',
regex=True)", engine='python').head(10)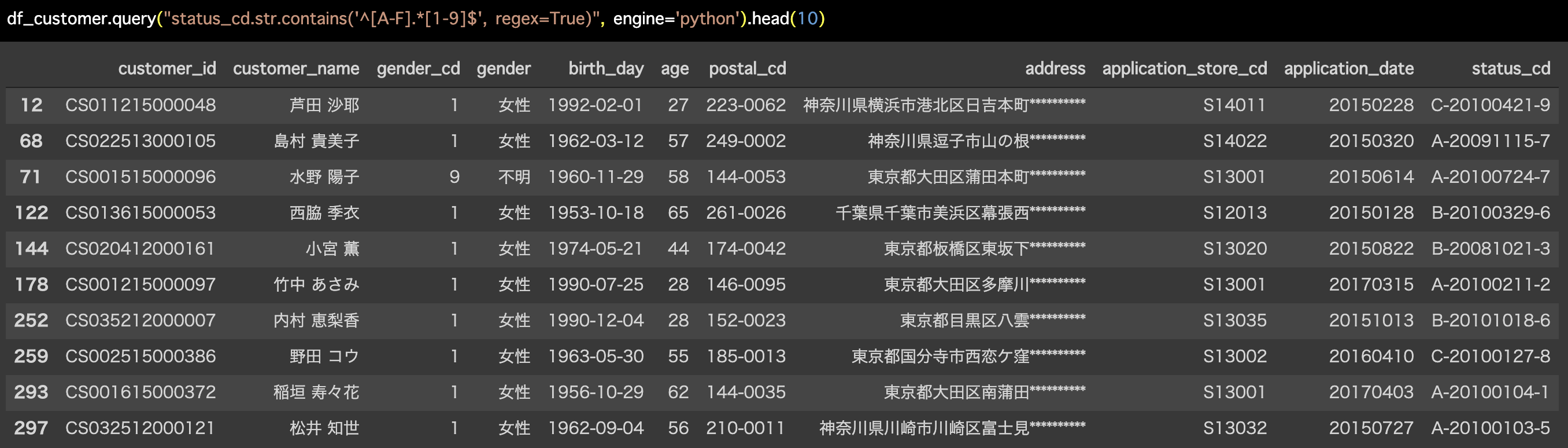
一気にやりたい人向け
Exploratory はR言語で動いているので、カスタムRコマンドに
filter(
str_detect(status_cd, "^[A-F]") & str_detect(status_cd, "^[1-9]"))とするか、フィルターメニューのカスタムに
str_detect(status_cd, "^[A-F]") & str_detect(status_cd, "^[1-9]")とすれば良いでしょう。
そろそろフィルターに慣れてきたでしょうか。
また、無意識に Exploratory を使っていれば、R言語の filter 関数も使っていることになりますので、対応がついてきた人は結構良いセンスしていると思います。
問16 : 特定のデータ書式で条件指定する

答案・解説はこちら
まず、やりたいことはこういうことです。 
df_store のデータフレームにある「tel_no」(telephone_number のこと) があって、3桁-3桁-4桁 と 2桁-4桁-4桁 が混ざっているところから、3桁-3桁-4桁 だけにしたいのです。
3通りの答案を示しておきます。
雑談も入れたので、先を急ぐ人・時間のない人はカンタンな方法を見たら 問17 にいくことをオススメします。
カンタンな方法(正確ではない)
先に行きたい人にオススメです。
終わったら 問17 に進むのもアリだと思います。
ということに気付いた方は、今回のデータに限っては 問13 のレベルまで落とせたことになります。
3桁-3桁-4桁は 042 から始まったり、045 から始まったりしているので、そちらでフィルターなどを考えるよりも、03 から始まらないもの除けば良い(余事象の考え方)ということです。
なので、このようにすれば良いでしょう。
この文字列から始まらないとなっているところだけ注意して見ればOKです。 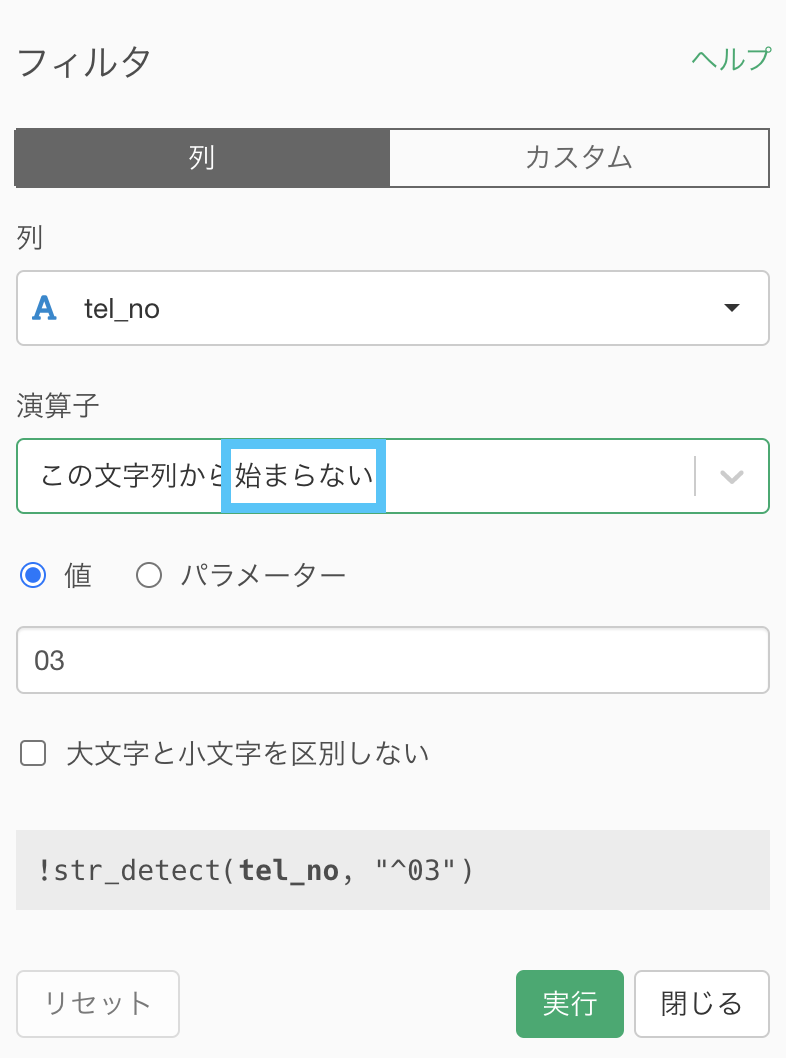
これを実行すれば以下のような画面になっていると思います。
解答と一致しているか確認してみましょう。 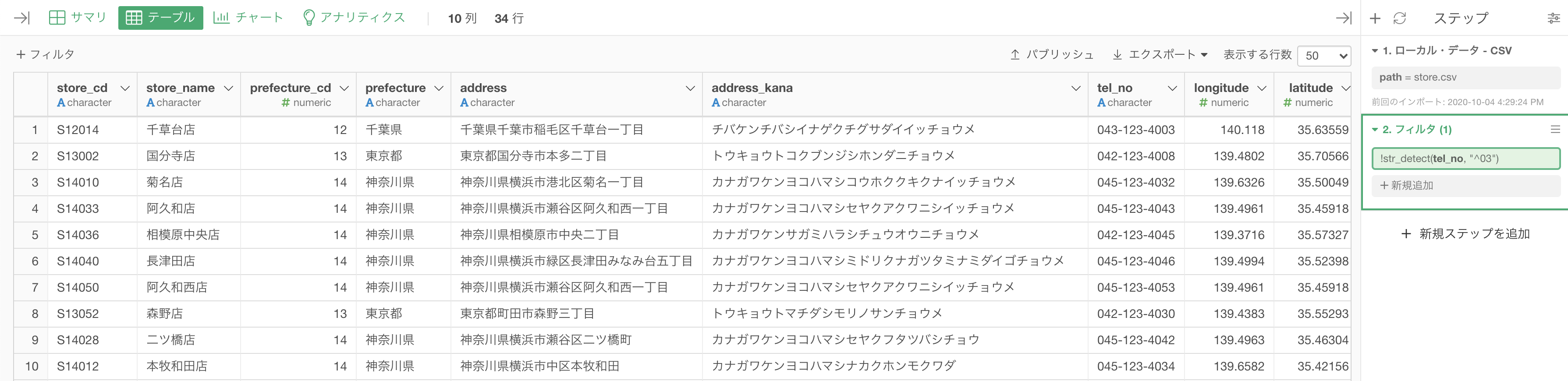
中くらいな方法(頑張って正確さを近づけた)
ということが正しいことがわかっています。(国際の番号や、データ入力ミスなどは入っていないということ!)
なので、先頭の桁の数が 3個 なのか 2個 なのか(あるいは真ん中が3桁か4桁か)を見ればフィルターできますよね.
これを念頭におくと、まず次の工程で行くことになりそうです。
- ハイフンで切る
- 桁の数で区別
ではやってみましょう。
まず 1つ目 : ハイフンで切る 方法です。
分割 → ...で列に分割 →「 ダッシュ( - ) 」を選択します(ハイフンはダッシュとも呼びます)。 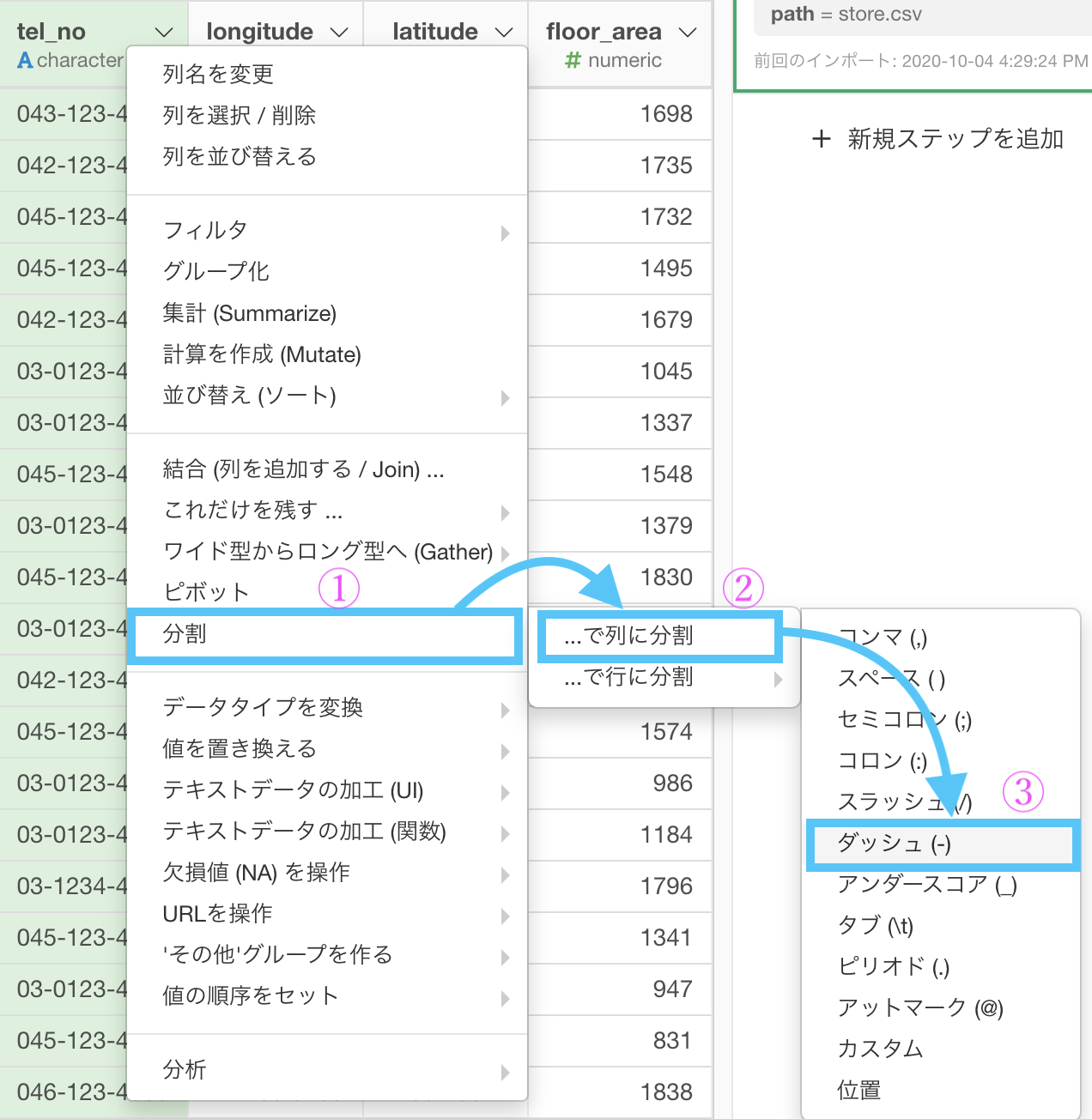
画面の操作はこんな感じです。
変わっているところは示しておきました。
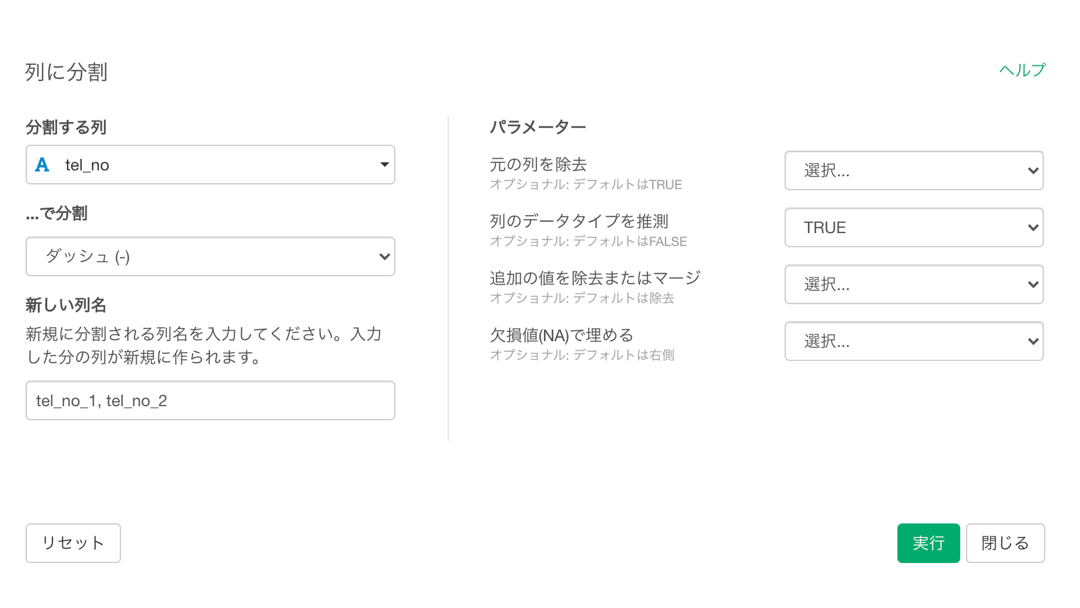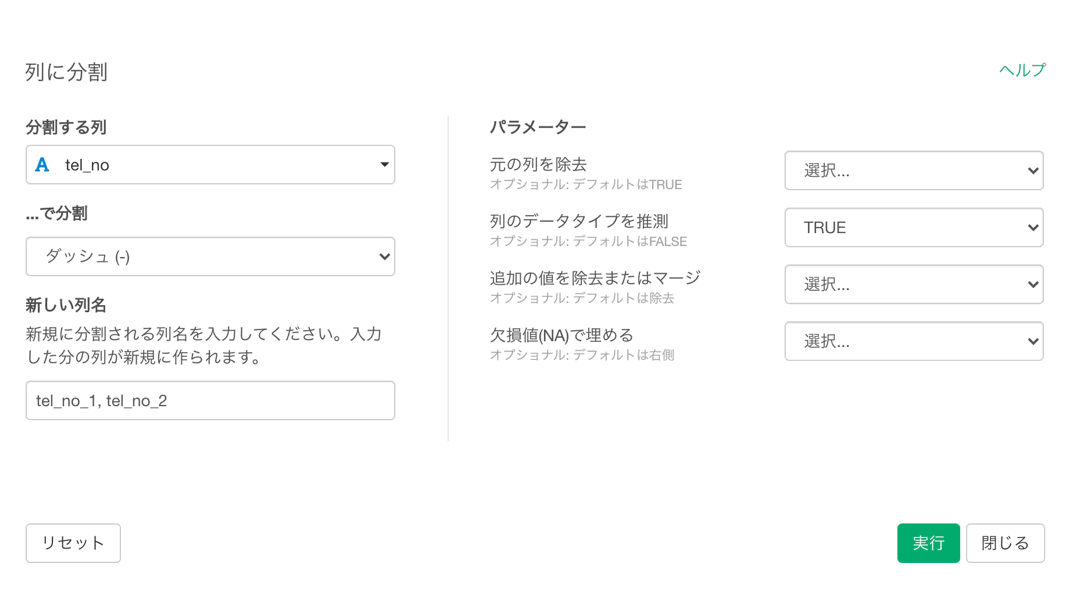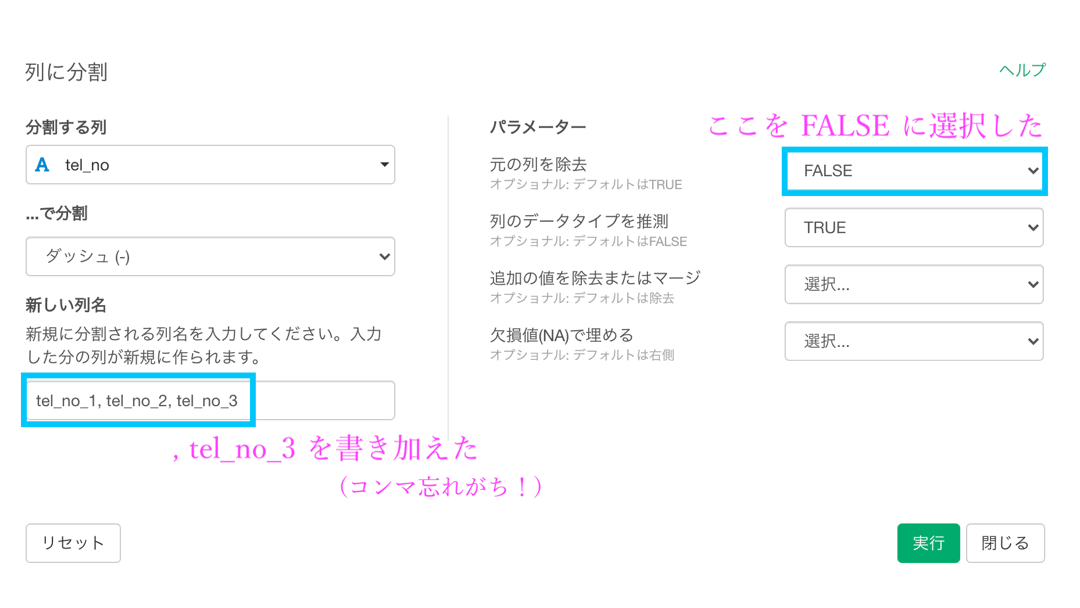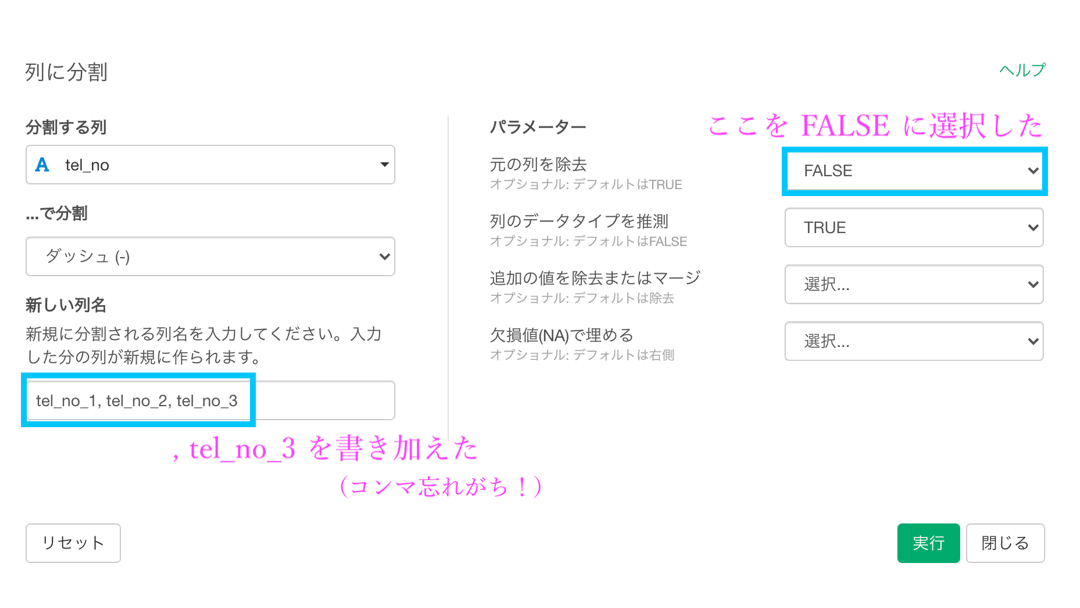
「新しい列名」のところには tel_no_3 を追加
これをすることで、〇〇-〇〇-〇〇 は 3列 に分かれることに なります。tel_no_1, tel_no_2, tel_no_3
「元の列を除去」を FALSE にします。残してみやすくしましょう。
結果はこのようになったと思います。
tel_no_1, tel_no_2, tel_no_3 が効いています。 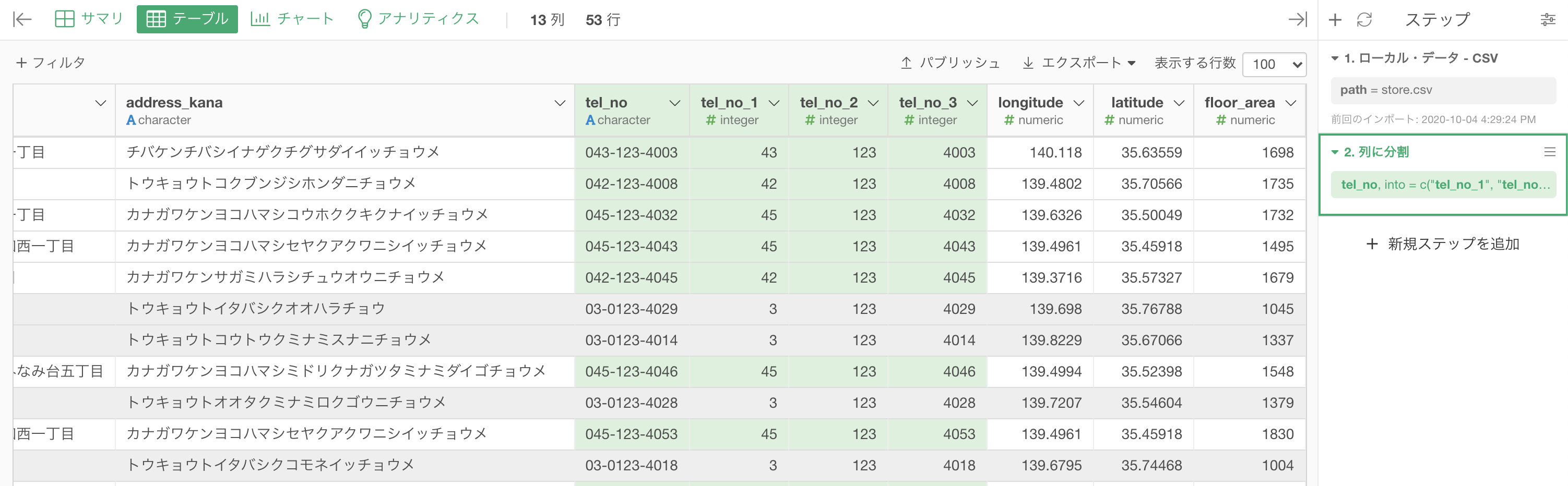 なお 03 や 042 は 3 や 42 として 0 が消去されています。
なお 03 や 042 は 3 や 42 として 0 が消去されています。
これは文字型(character) が 数値型(numeric) になったからです。
先ほどの画面の中にある「列のデータタイプを推測」を FALSE にすると、0 が残ります。
次に、2つ目 : 桁の数で区別 をしましょう。
1つ目の工程がしっかりしているので、ここではフィルターするだけで良いです。 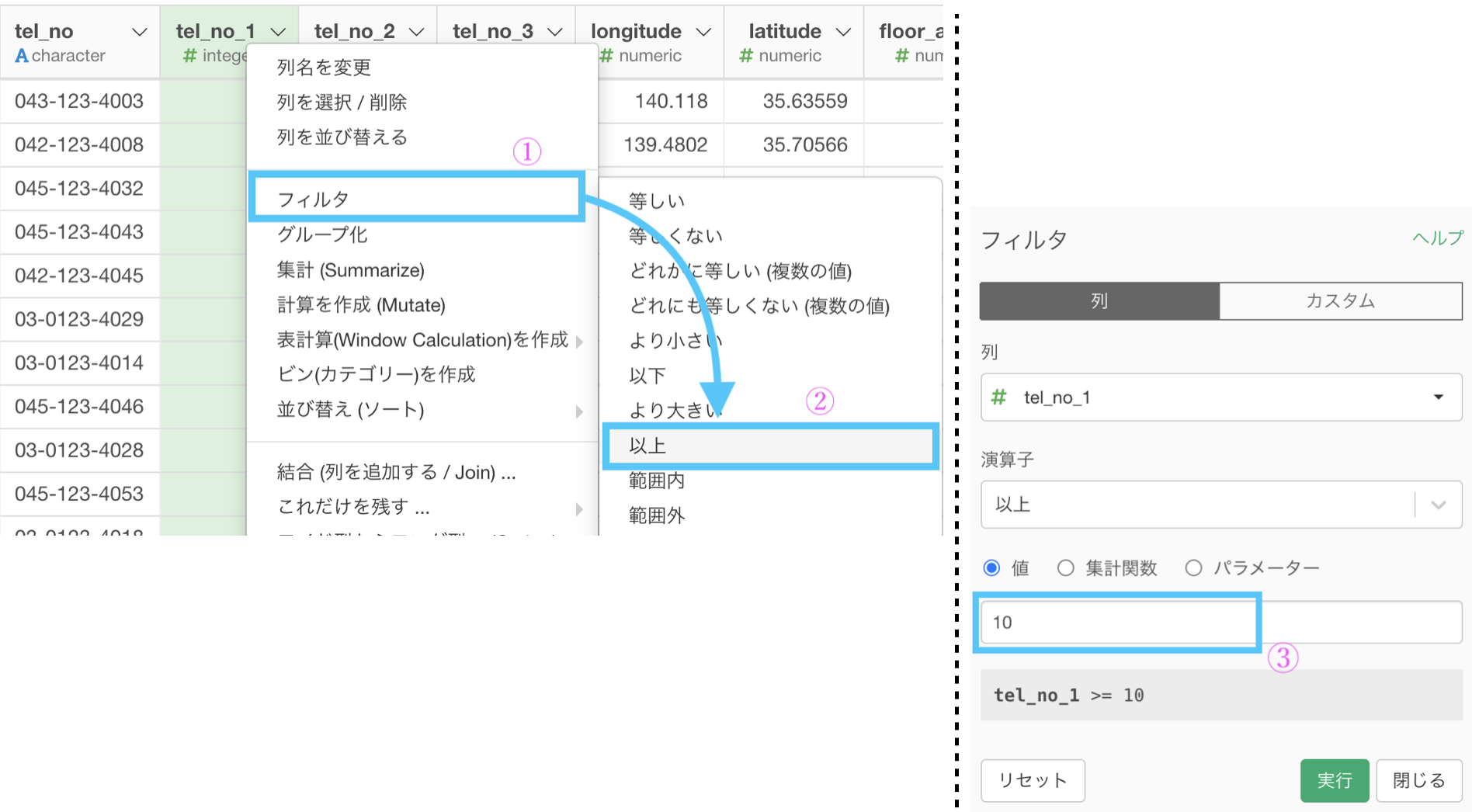
なぜ10以上としたのかには、以下のような理由があってのことです。 
このような規則は、対数(log)の心を知るために必要です。
3 は黒色のゾーン(1桁)で、42 とか 45 とかは赤色のゾーン(2桁)で...ということなので、10で切ることという気持ちを込めて10以上でフィルターをしています。
tel_no_1 〜 tel_no_3の列を削除すれば(問2を参照)以下のような結果になると思います。解答を確認してみましょう。 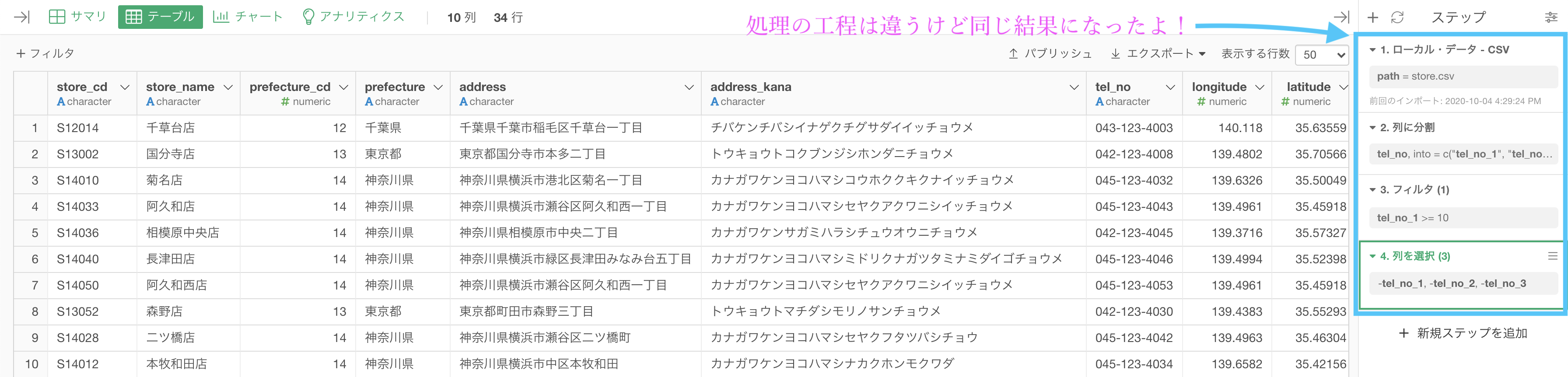
工程が違っても同じ結果になるところをみると、色んなやり方がありそうだと感じることができると思います。
色んなやり方を模索するうちに、Exploratory も勝手に上達していきます。
こうしてからのこうすれば...ということを考えて、実現するのが楽しくなってくるでしょう。
コマンドで解決する方法(解答と同じやり方)
最後に、Exploratory の良さ(データの処理を追跡できることまで)を消してしまいますが、コマンドを用いて一気にやってしまう方法があります。
フィルターのカスタムから、これを打ち込むだけです。
# grepl("^[0-9]{3}-[0-9]{3}-[0-9]{4}$", tel_no)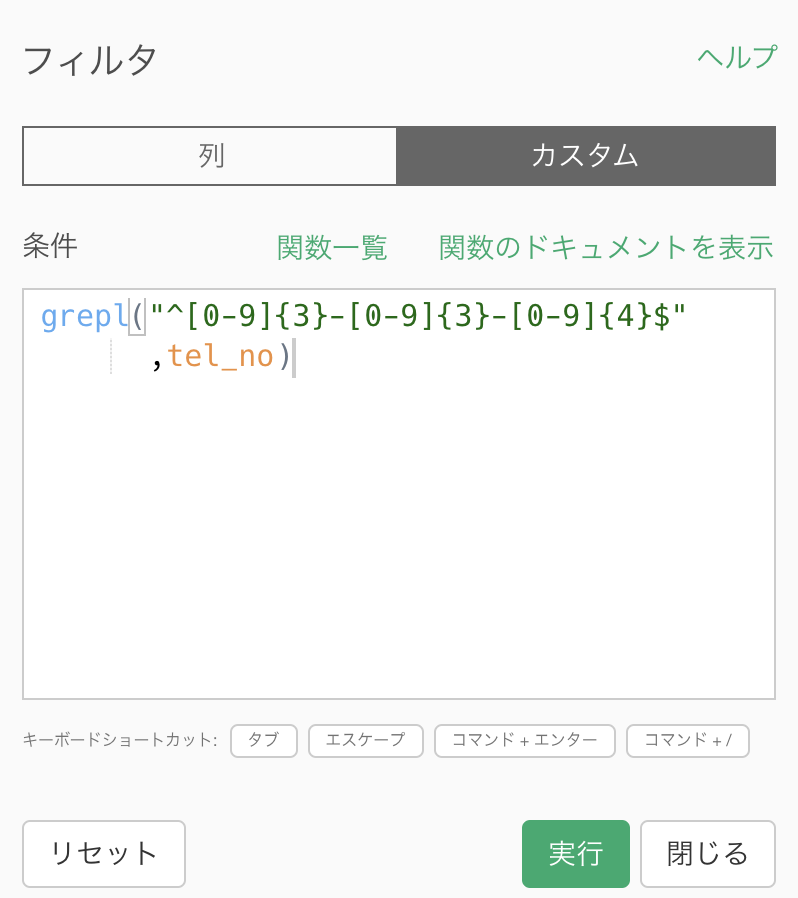
grepl 関数の説明まではしませんが、よくみると 3桁-3桁-4桁という流れが0〜9の数字で...と読むことができると思います。
コマンドは読む・読めるようになるだけでも何をやろうとしているのか大体わかるようになるので、わかったときの快感が好きな人は R言語 も継続して勉強できると思います。
周りの人から刺激を受けることもモチベーション維持の秘訣です。
Python 解答コードはこちら
解答コードはこのようになっています。
df_store.query("tel_no.str.contains('^[0-9]{3}-[0-9]{3}-[0-9]{4}$',
regex=True)", engine='python')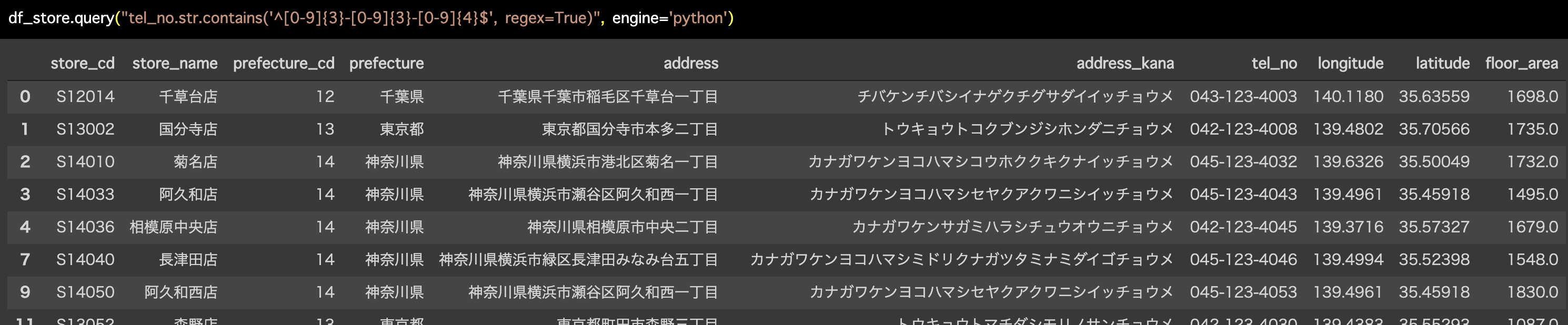

別解をあえていくつか書く理由
やはりコマンドで打ち込む際は、解答のものを書く以外(=別解)はほとんど煩雑になってしまうため、これしかない感が漂ってきます。
別解はそれなりのコマンド量を必要としたため、それだけの説明でも記事が1つ書けるくらいです。
相当のコマンドの経験があって、たくさんの関数を知っていないと、別解なんて思いつかないどころか、データに適した考え方(03しかない!とか)もできないかもしれません。
データに適した考え方をすると一般性を失います。すなわちコードの使い回しができなくなるケースが多くなることが予想されますが、どっちを取るかはその時の状況によります。
一概にコレ!ということはおそらくできないでしょう。
これを多少触ったあとならば、周りの人とも本当に議論がしやすいし、話し合いが活発になることの方が有意義であるように僕は感じています。
したがって、今回は別解を紹介しました。
さて、次の折りたたみではSQL的な視点・考え方なので、要するにただのお話です。
先に進みたい人は 問17 に行ってください。
別解がいくつもある理由(物好きな人向け)
これの理由を、ぼんやりではなくきちんと答えられる人はなかなかいないと思います。
ここで聞いているのは「別解の存在証明」(に近いこと) だからです。
つまり、別解はたまたまあったわけではない ということです。
もう一度聞きます。なんで別解がいくつもあるでしょうか?
SQL的な視点による説明
(数学的・論理的に)証明しなさいよ〜と言われると流石にここに書けるほどのカンタンなものではないですが、説明なら結構カンタンです。
まず熟練者には怒られるかもしれないけど、初めて触れる人のために...をいいます。
データはよくテーブル(表みたいなもの)で表されますよね。 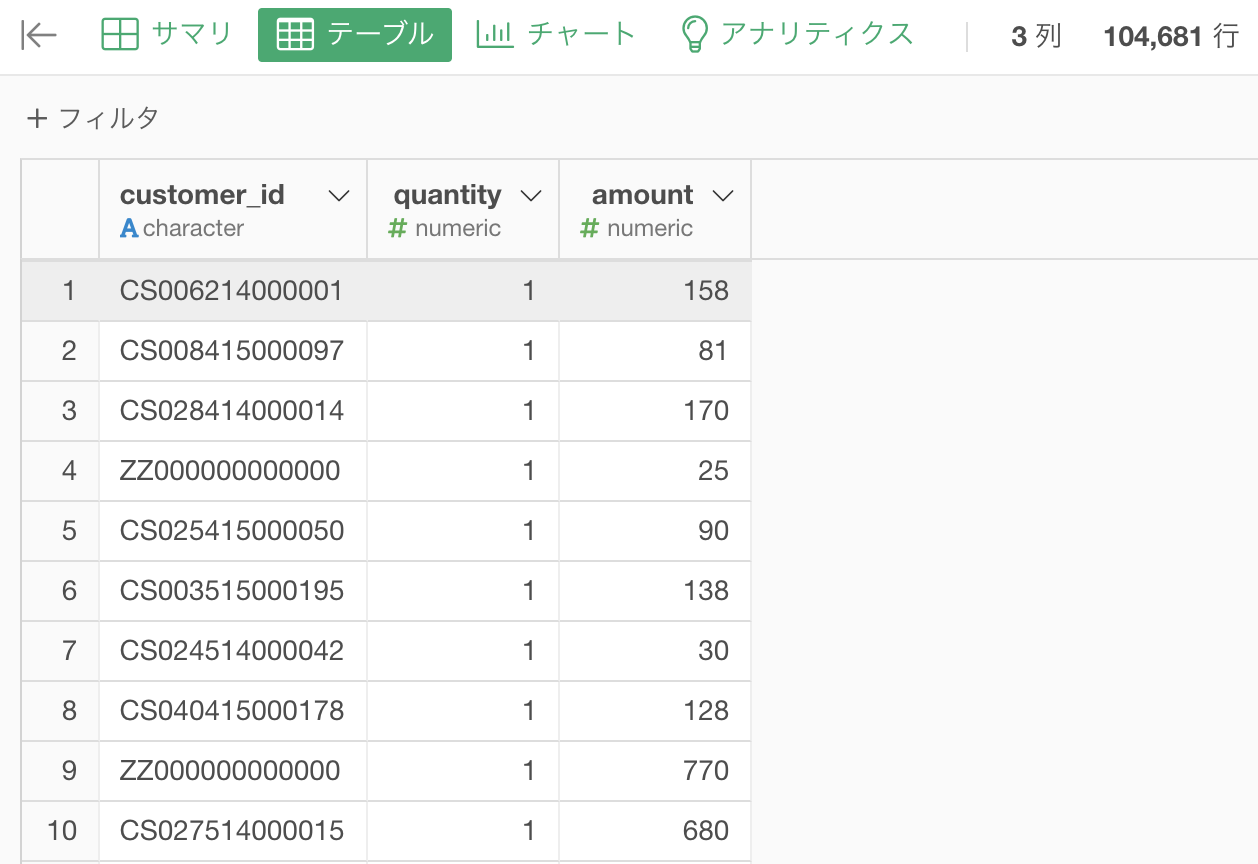
これは df_receipt のデータなので、1行はレシート1枚分です。
A 1 158 : Aさんは 品物を 1点 買って 158円 払いました.
B 1 181 : Bさんは 品物を 1点 買って 181円 払いました.
...
A 2 250 : Aさんは 品物を 1点 買って 250円 払いました.
B 4 600 : Bさんは 品物を 1点 買って 600円 払いました.
...という見方ができるでしょう(customer_id は人です)。
データを集合で見る!というのはつまり、こういうことです。
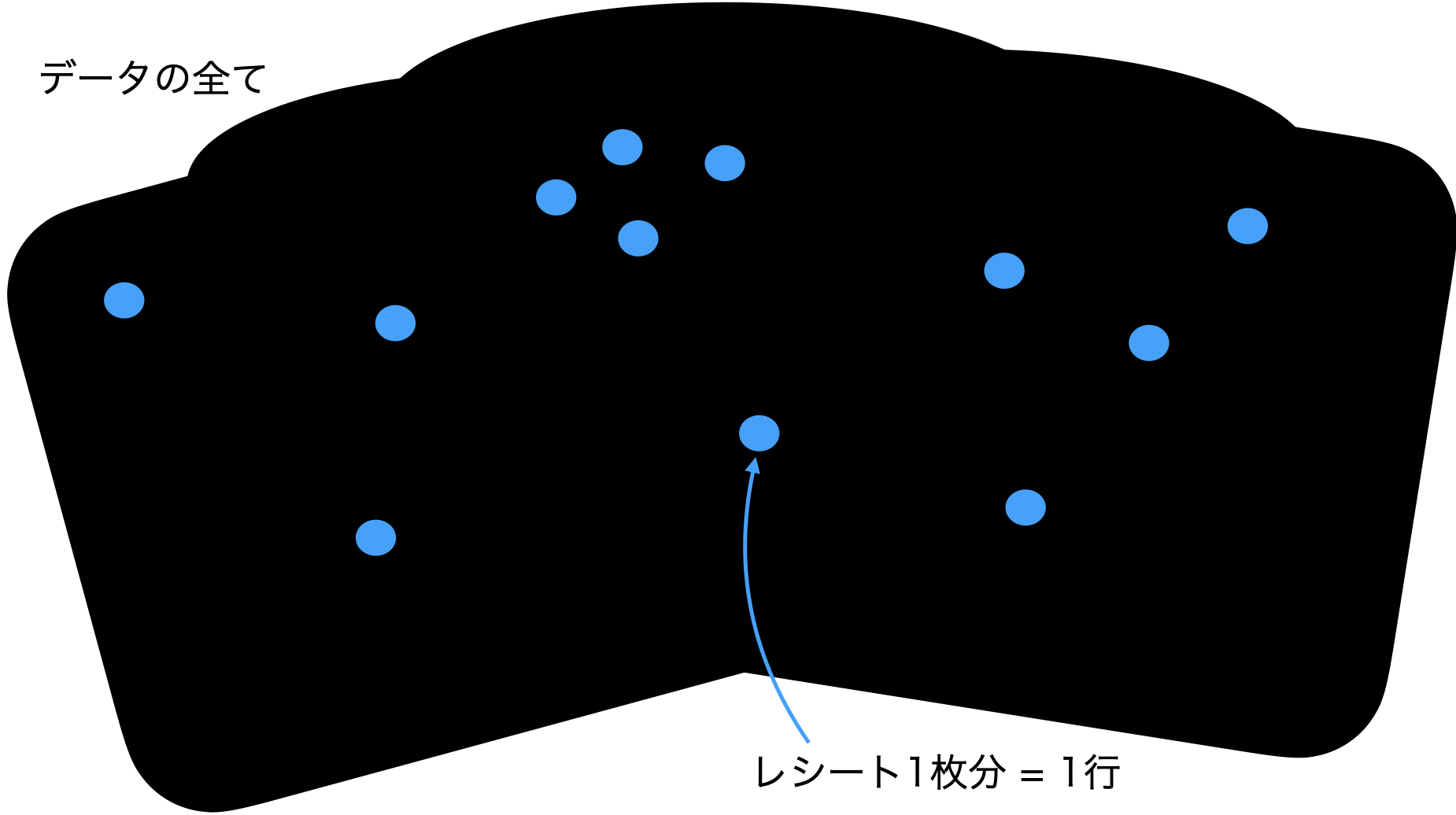
真っ黒の部分が、データの取れる範囲(=定義域と呼ぶ)で、青色がデータ点(= 1行 が全て詰まっている)です。
今見ているデータは、青色の点をかき集めたものしか観測できていません...としているわけです!
さて、フィルターをかけるとか、データを操作してデータの個数を減らしたりするのはつまり、以下のようなことをしています。 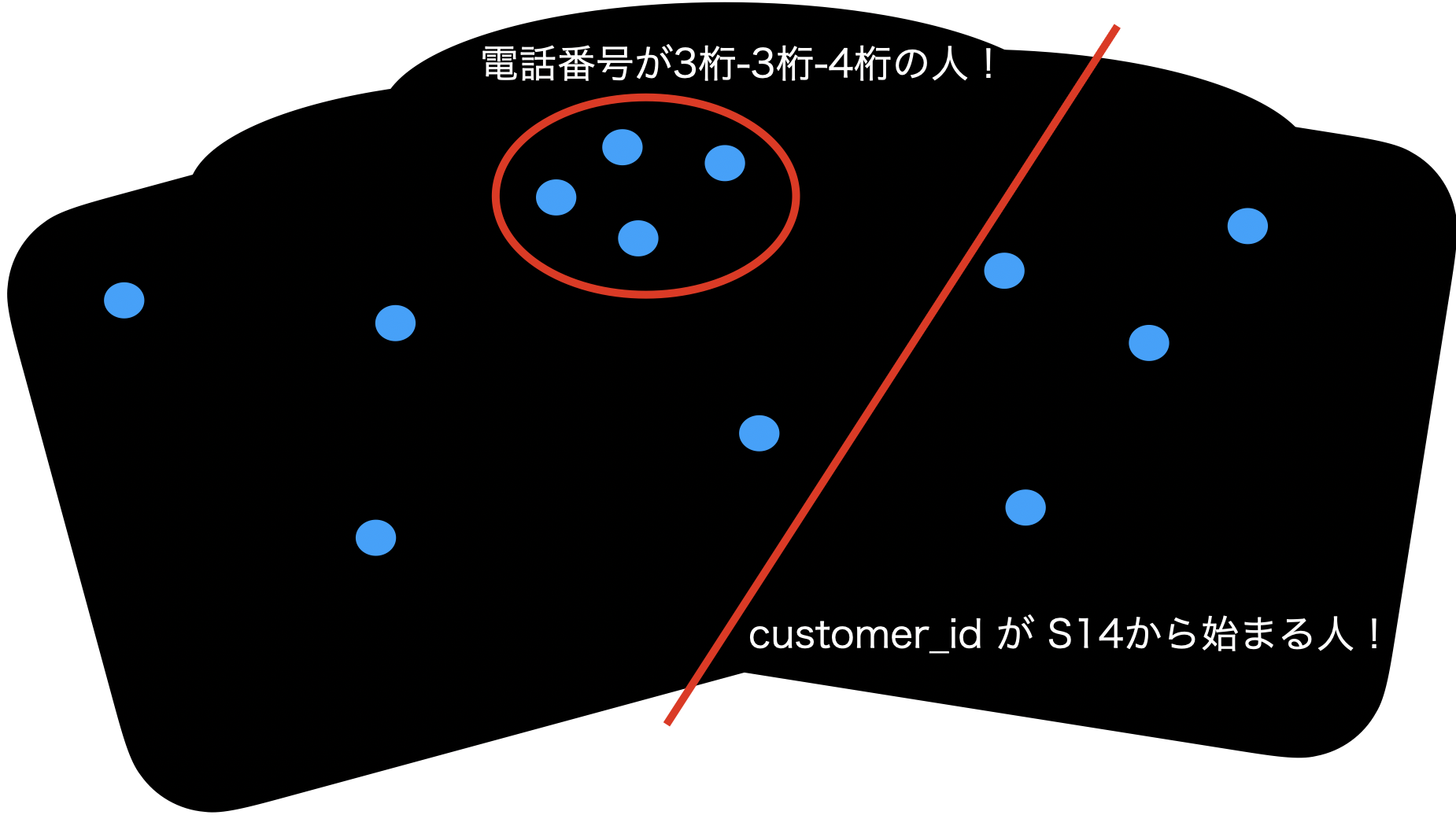
でも、電話番号が3-3-4桁の人って、こういうわけ方もできますよね? 
別にキレイに円で(= コマンドで)分ける必要は最初から 問16 で要求していなくて、ぶつかったところを「かつ」だと思って分けていくことだってOKだったはずです。
計算時間やコンパクトさから、円で分ける方が良いよね?というだけで、それは データをすでに抽出できた人々が語り合って居れば良い わけです。
データを抽出できていない(したこともない)人が、最初から円形でデータを掘り出そうと思うからコマンド嫌いになっているだけ です。
最初は地道に、わかりやすい直線で仕分けるのだって良いではないですか。
それを練習の段階できちんとやっているのなら、本当の意味で思考回路がだんだんできてすぐに円形になるわけですし、もっとたくさんのことができるようになるのも楽しみでしかありませんよね。
問17 : データを昇順に並べる

答案・解説はこちら
長く続いたフィルターも一旦ここまでです。
次からの問題で、順番に並べるという操作をしていきましょう。
df_customer のデータにある、birth_day を選択します。
並べ替え (ソート) → 昇順を選びましょう。 
このような画面が出てくるので、そのまま実行を押します。 
このような結果になっていれば大丈夫です。解答と確認してみましょう。 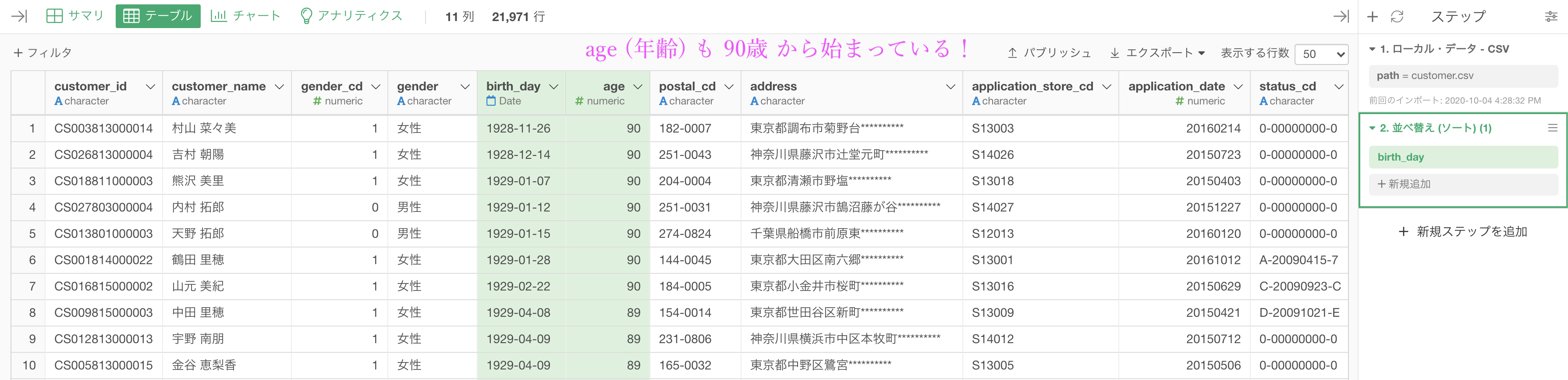
しかもその方が早いでしょう。
大事なのは、データを見て判断することを心がけていることです。
Python 解答コードはこちら
解答コードはこのようになっています。
df_customer.sort_values('birth_day', ascending=True).head(10)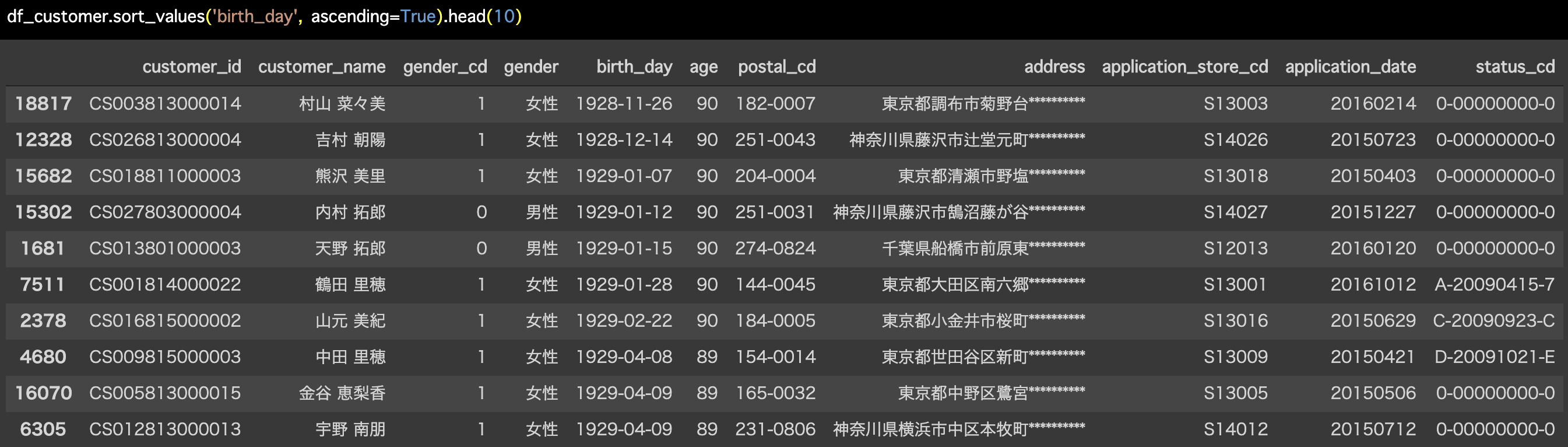
問18 : データを降順に並べる

答案・解説はこちら
問17と同じレベルです。
今度は降順を選びましょう。 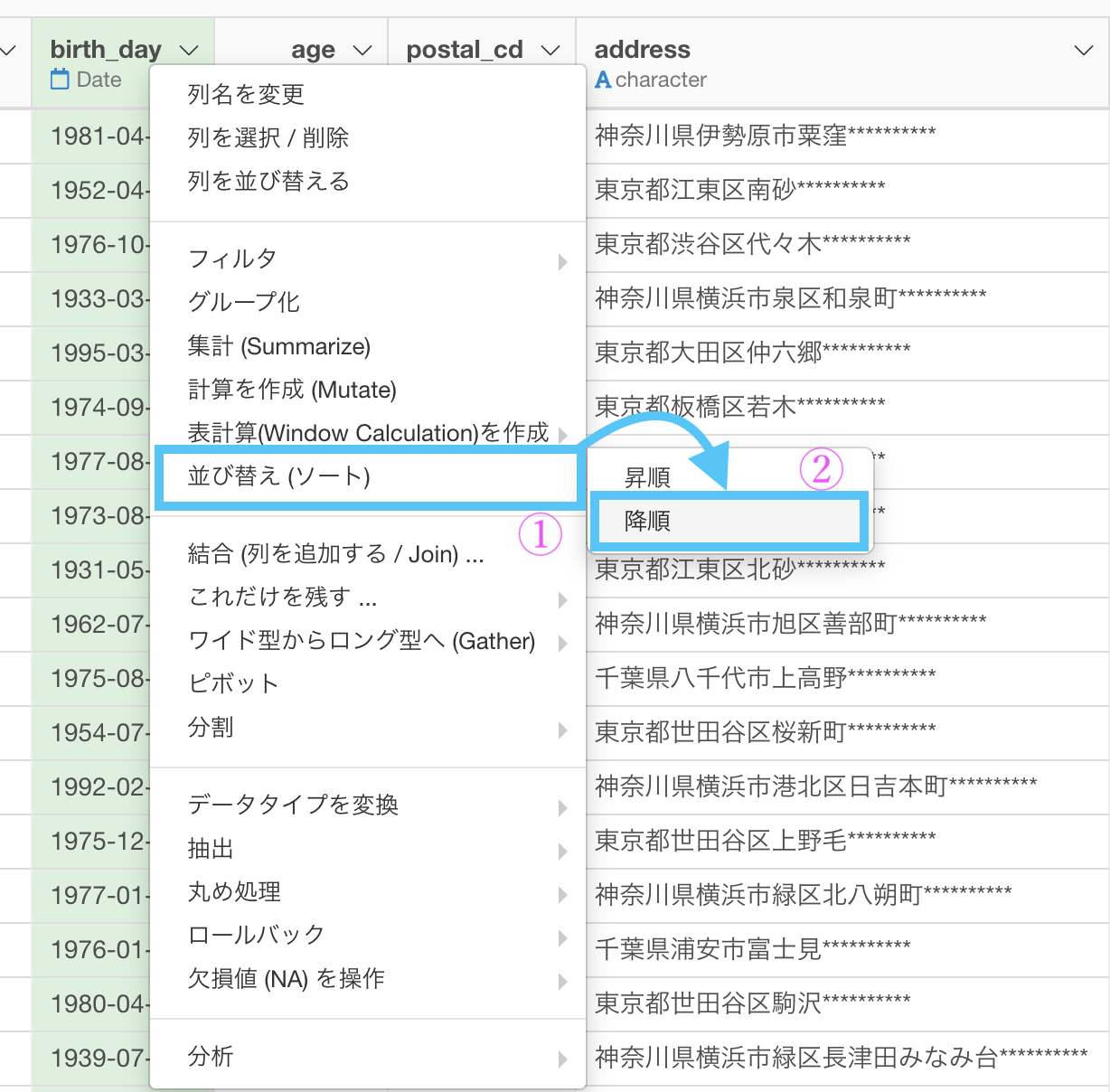
ここもそのまま実行します。 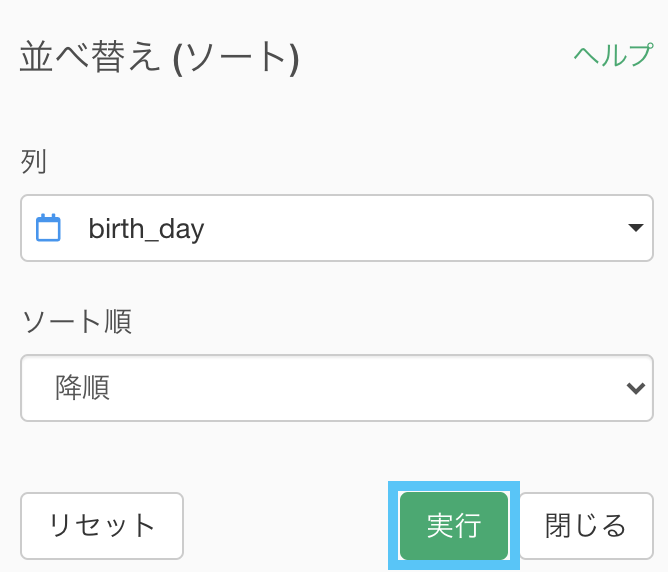
このような結果になっていれば大丈夫です。解答と確認してみましょう。 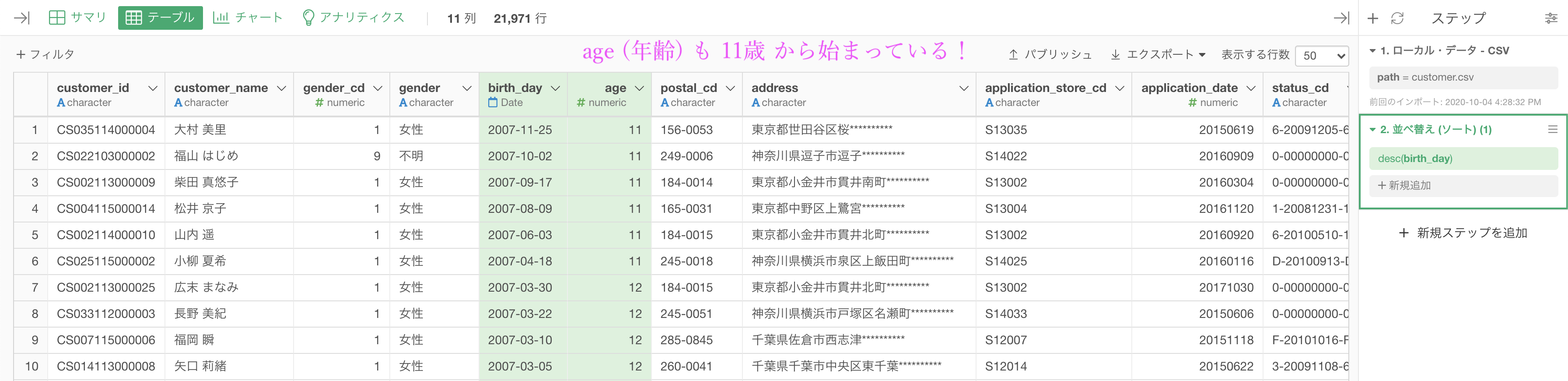
Python 解答コードはこちら
解答コードはこのようになっています。
df_customer.sort_values('birth_day', ascending=False).head(10)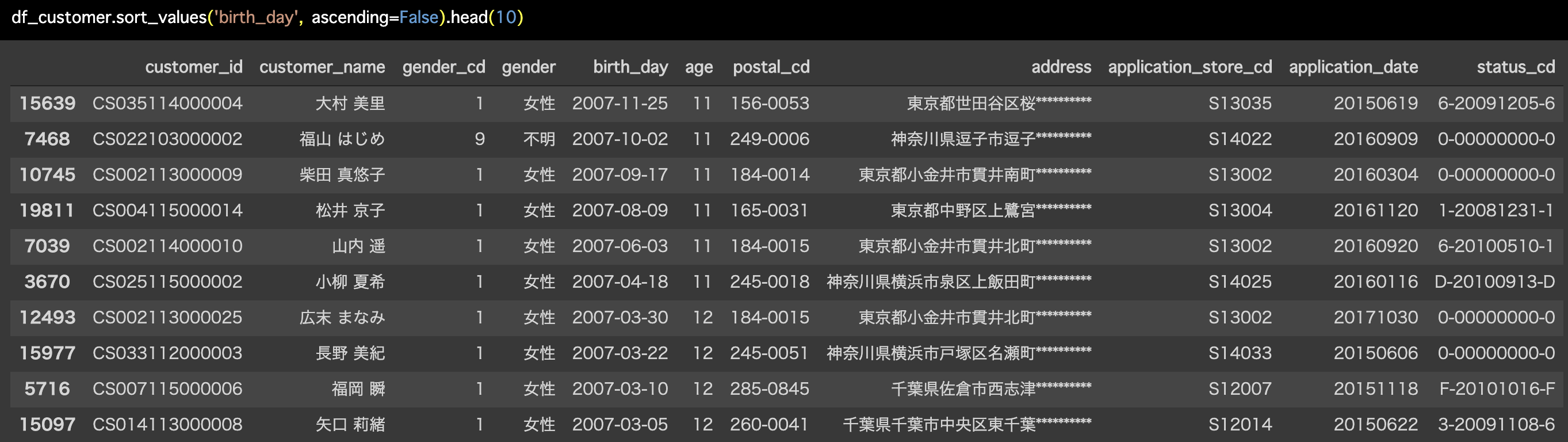
コード全体を覚えようとするのではなくて、問17 との違いがわかればひとまず大丈夫だと思います。
今回であれば、ascending = ... のところですね。
問19 : 順位付けする(同一順位あり)

答案・解説はこちら
という状況です。
まず、df_receipt のデータで amount を降順(高い順)に並べましょう。 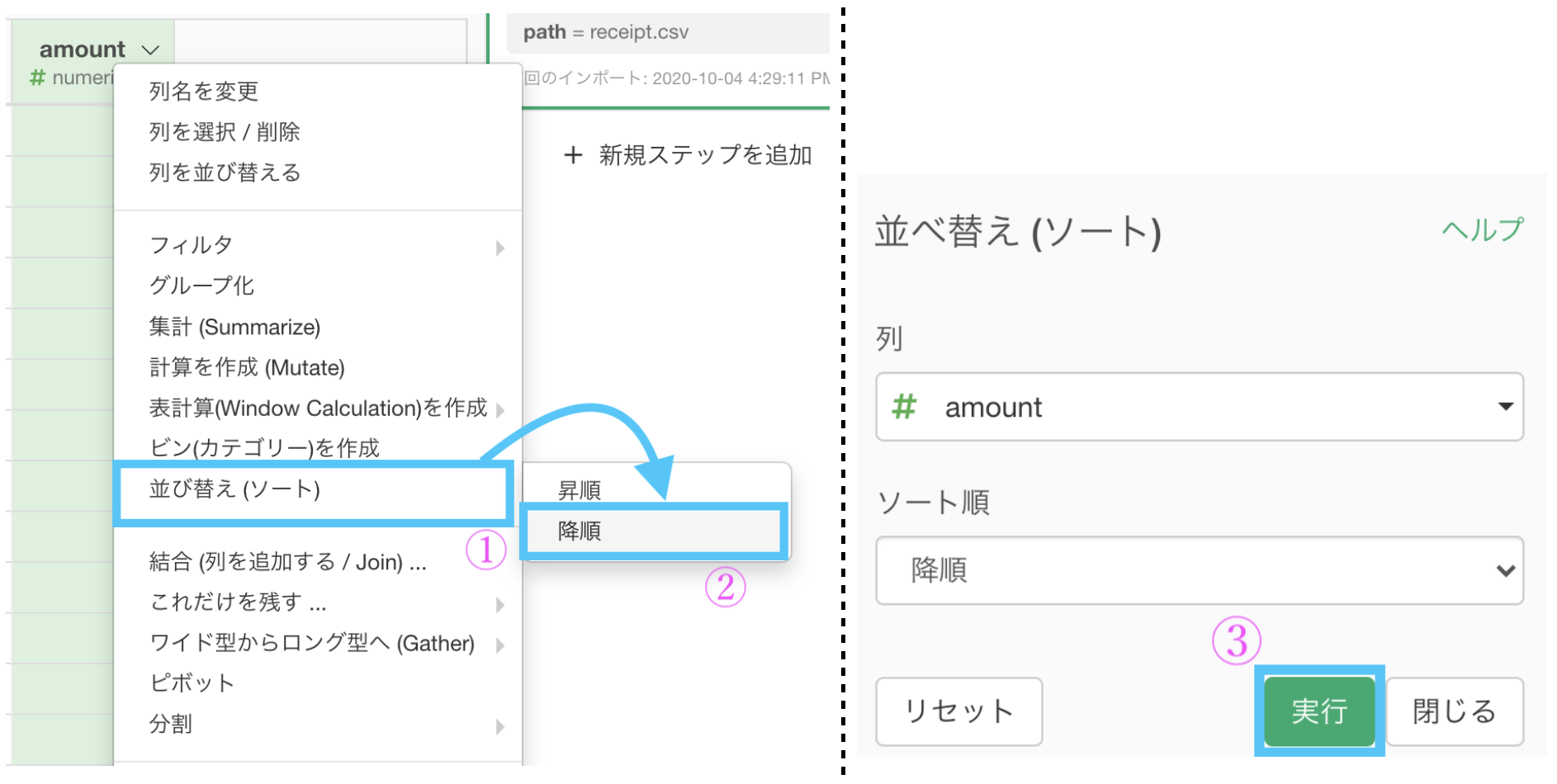
という話です。
ちなみに SQL 言語でも騒がれている話題です。
とは言っても Exploratory でやるので、実装はそこまで難しくないです。
amount の列を選択して、
表計算(Window Calcukation)を作成 → ランキング (隙間あり) →「降順」
をクリックします。 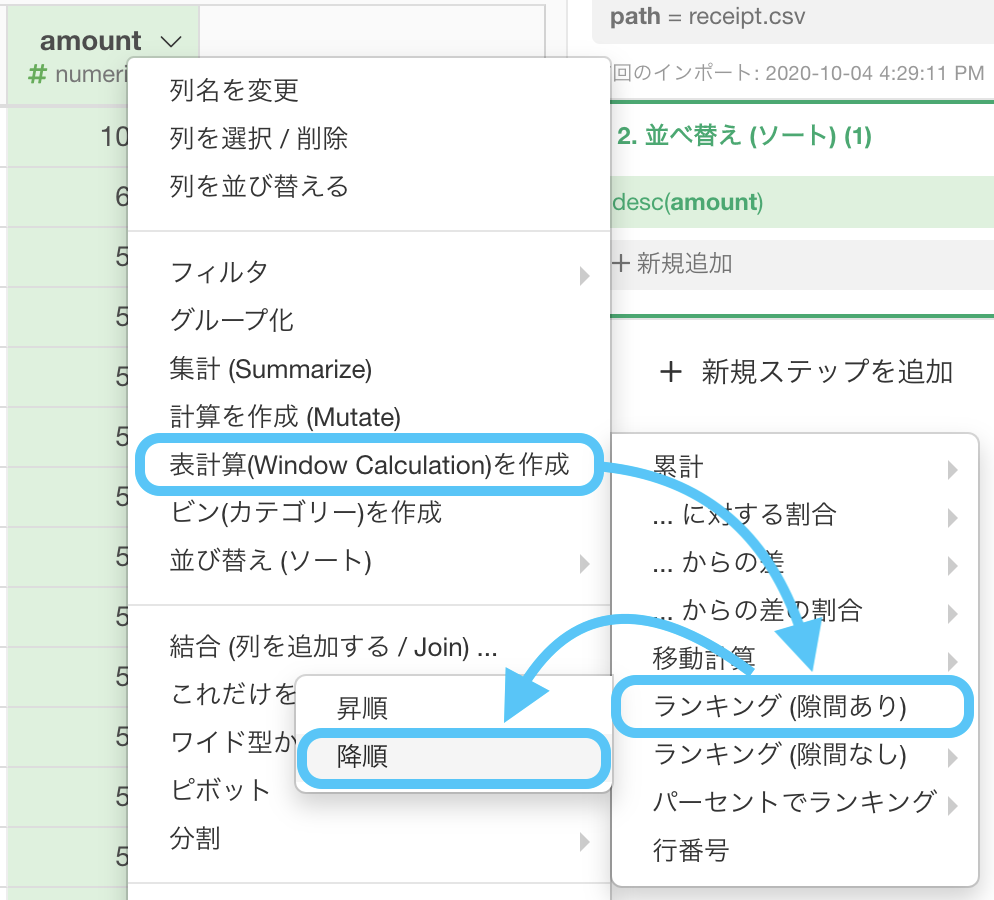
このような画面が出てきたはずです。
このまま実行しましょう。 
最後に問題に合わせるため、customer_id, amount, amount_rank の3列にしたのものがこちらです。解答と確認しましょう。 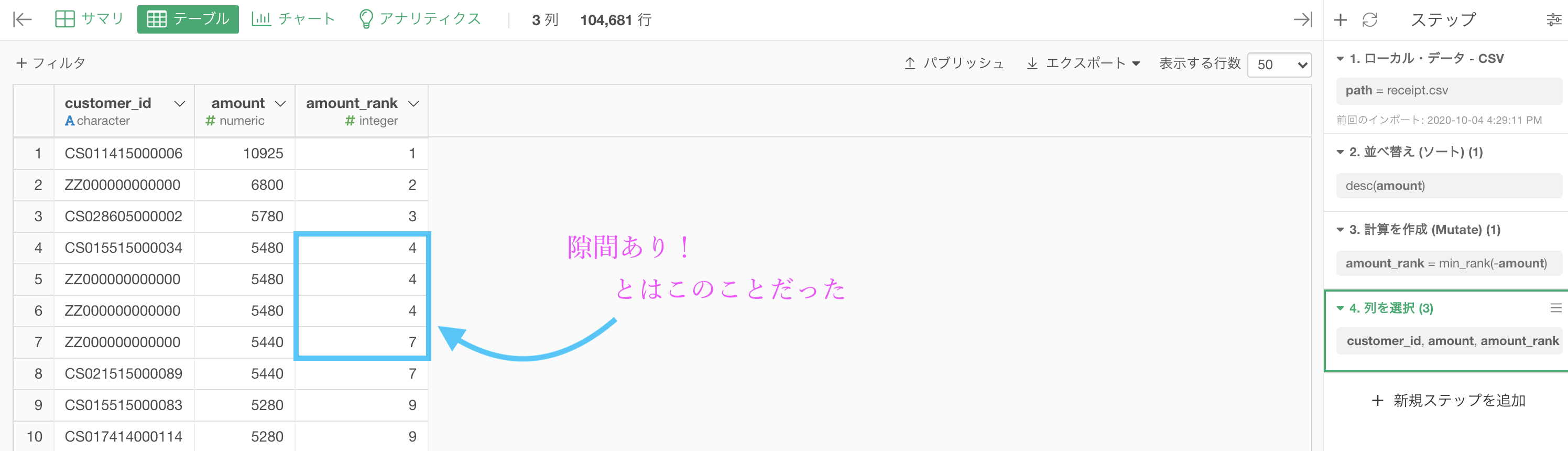
結果のデータをきちんとみることが大事です。
隙間あり!とは 5位 と 6位 が飛んでいるので隙間があるよ!ということでした。
隙間なし!になるとどうなるでしょうか?
もしやってみたくなった人は、同じようにして出来るのでぜひやってみてください。
Python 解答コードはこちら
解答コードはこのようになっています。
df_tmp = pd.concat([df_receipt[['customer_id', 'amount']],
df_receipt['amount'].rank(method='min',
ascending=False)], axis=1)
df_tmp.columns = ['customer_id', 'amount', 'ranking']
df_tmp.sort_values('ranking', ascending=True).head(10)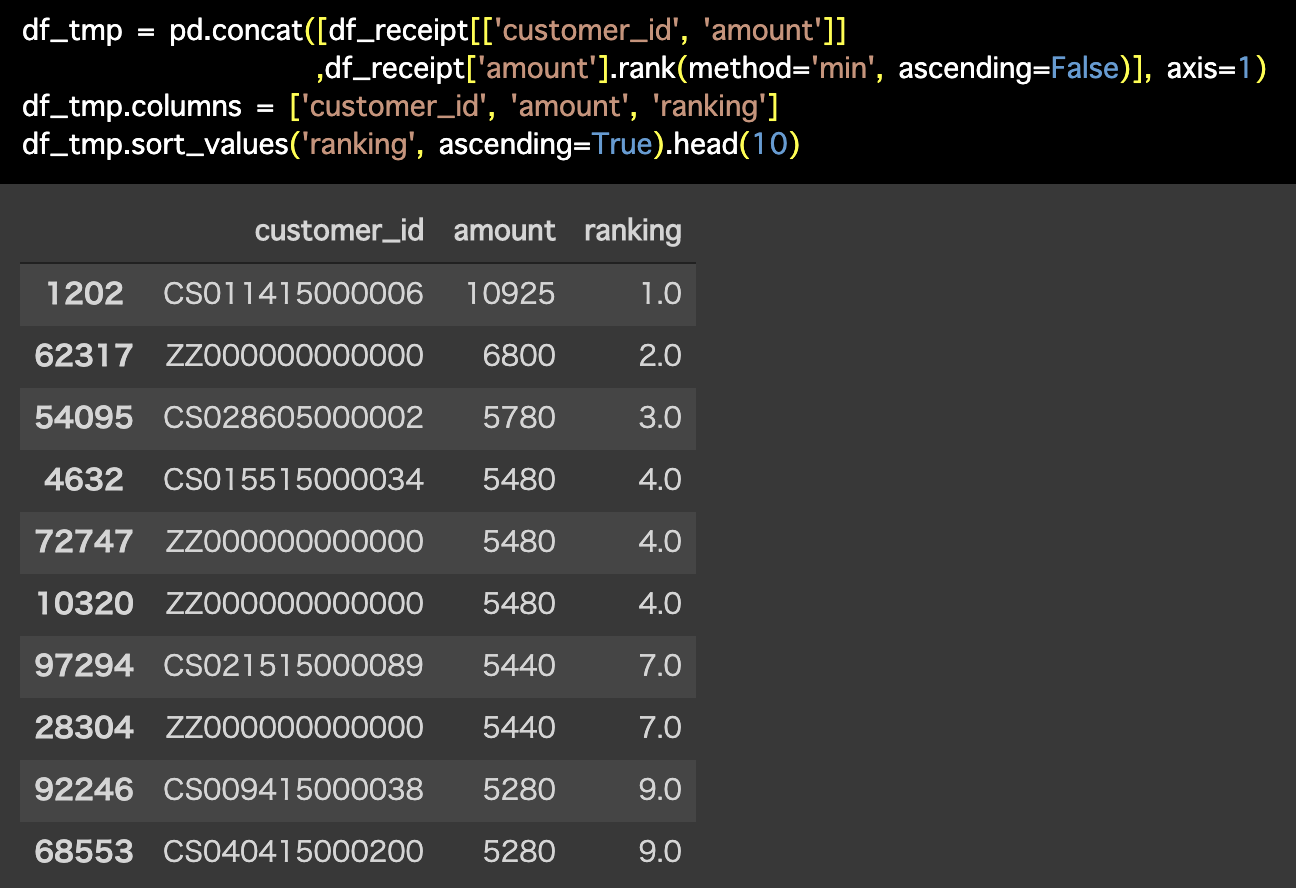
やっていることは単に、amount の数値を並べて順番つけているだけです。 ですが、長いコードを一気に見ると、どうしても息が詰まってしまう人もいるかもしれませんね。
問20 : 順位付けする(同一順位なし)

答案・解説はこちら
同一順位なしとはつまり
だからです。
ではまず、amount を降順にしましょう。問19 の前半と同じです。 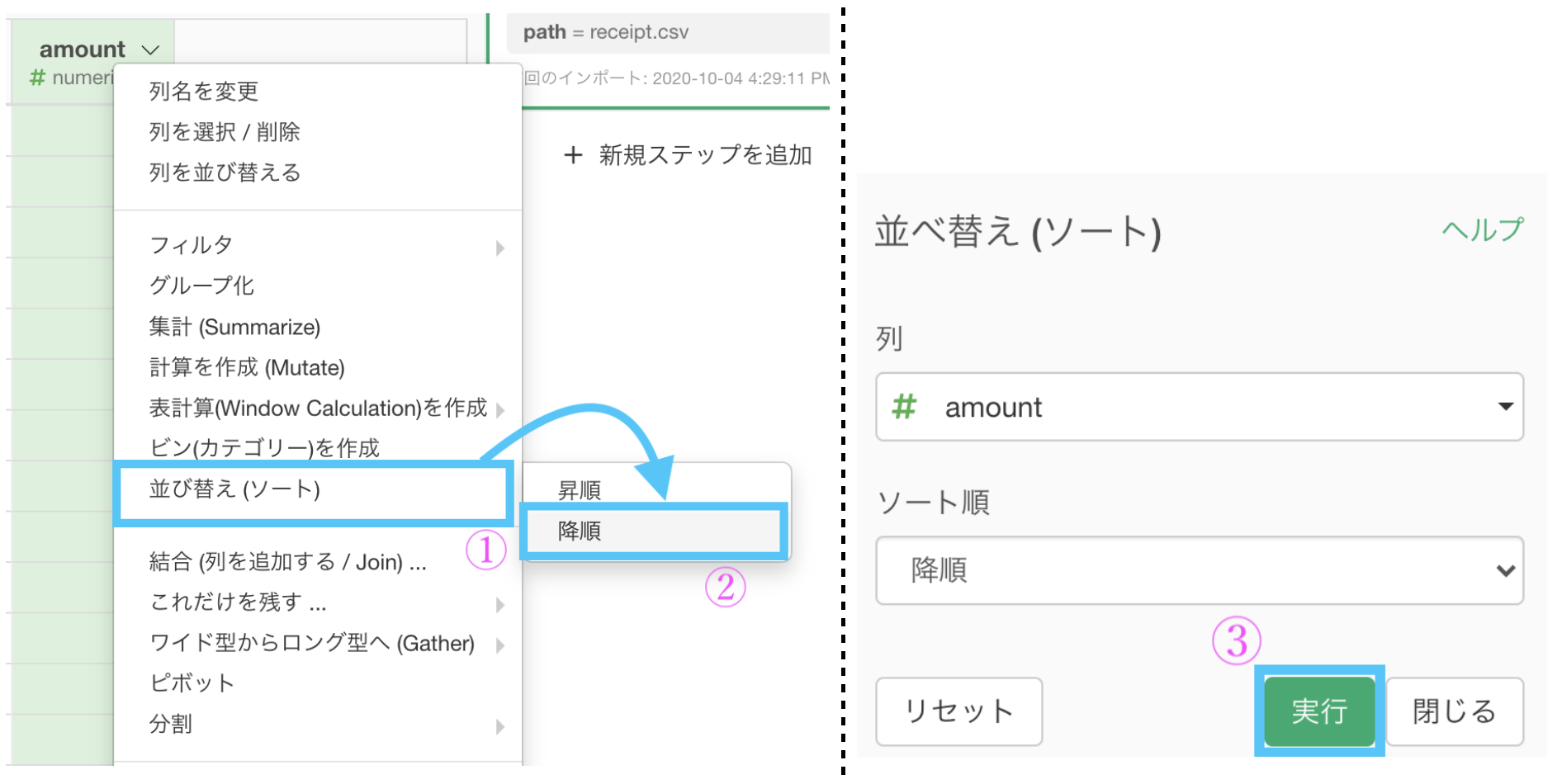
ここからは、上から下へ、1, 2, 3, ... とすれば良さそうです。
具体的にはこんな感じ列が欲しいです。 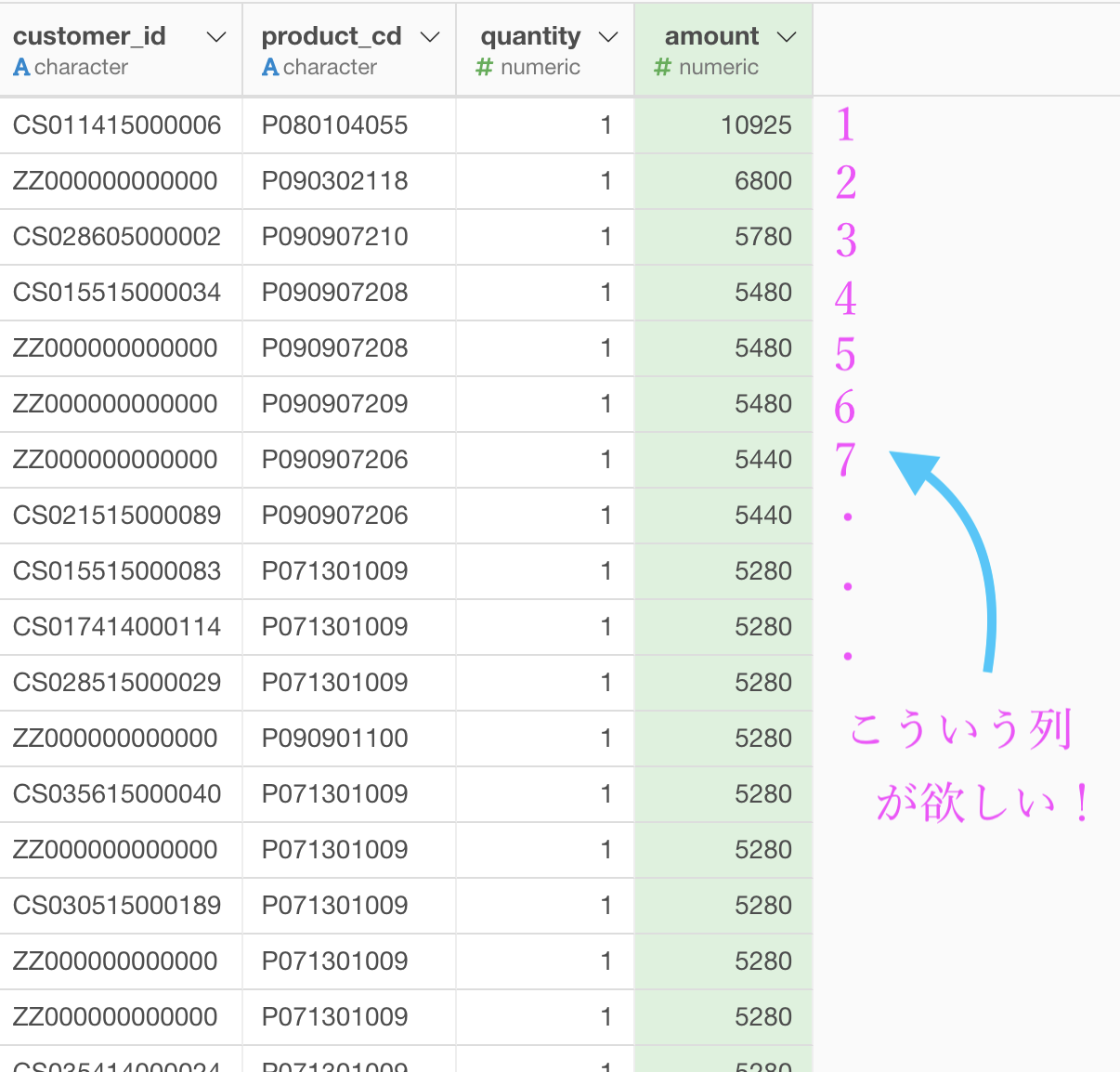
そうなる理由は、先に amount で降順(価格の高い順)にしたからです。
行番号も Window関数 の中にあります。 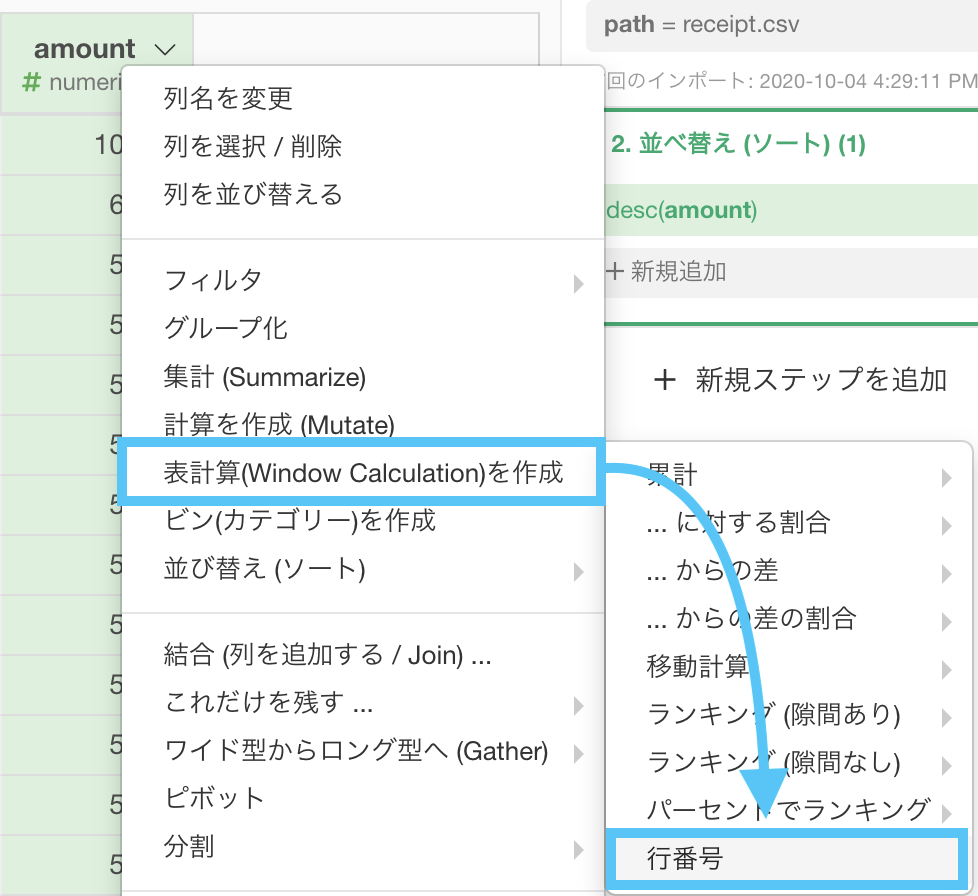
このような計算エディタが出たと思うので、画面に従って操作してみましょう。

行番号は英語にすると row number そのままですので、関数も row_nubmer() ということです(微妙に違うけど)。
カッコの中( = 引数と呼びます)にある amount は消しましょう。
少し心配になりますが、いま見ている順番で行番号を振ってくれるので安心してください。
列名の amount_rank は雰囲気のためです(実際でもわかりやすくするのは大事)。
最後に問題に合わせるため、customer_id, amount, amount_rank の3列にしたのものがこちらです。解答と確認しましょう。 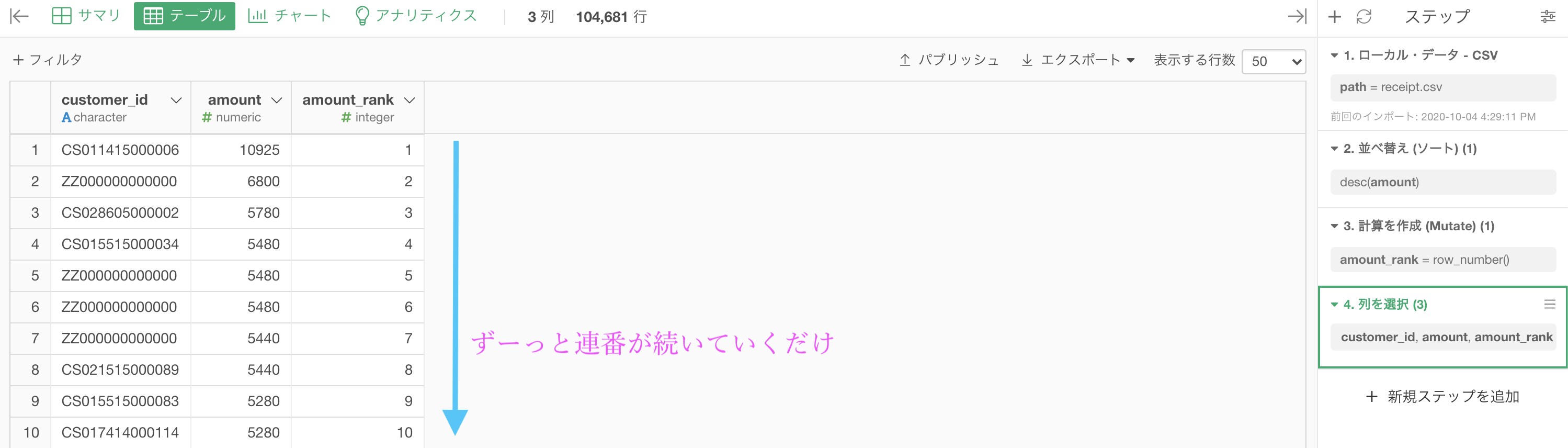
Python 解答コードはこちら
解答コードはこのようになっています。
df_tmp = pd.concat([df_receipt[['customer_id', 'amount']],
df_receipt['amount'].rank(method='first',
ascending=False)], axis=1)
df_tmp.columns = ['customer_id', 'amount', 'ranking']
df_tmp.sort_values('ranking', ascending=True).head(10)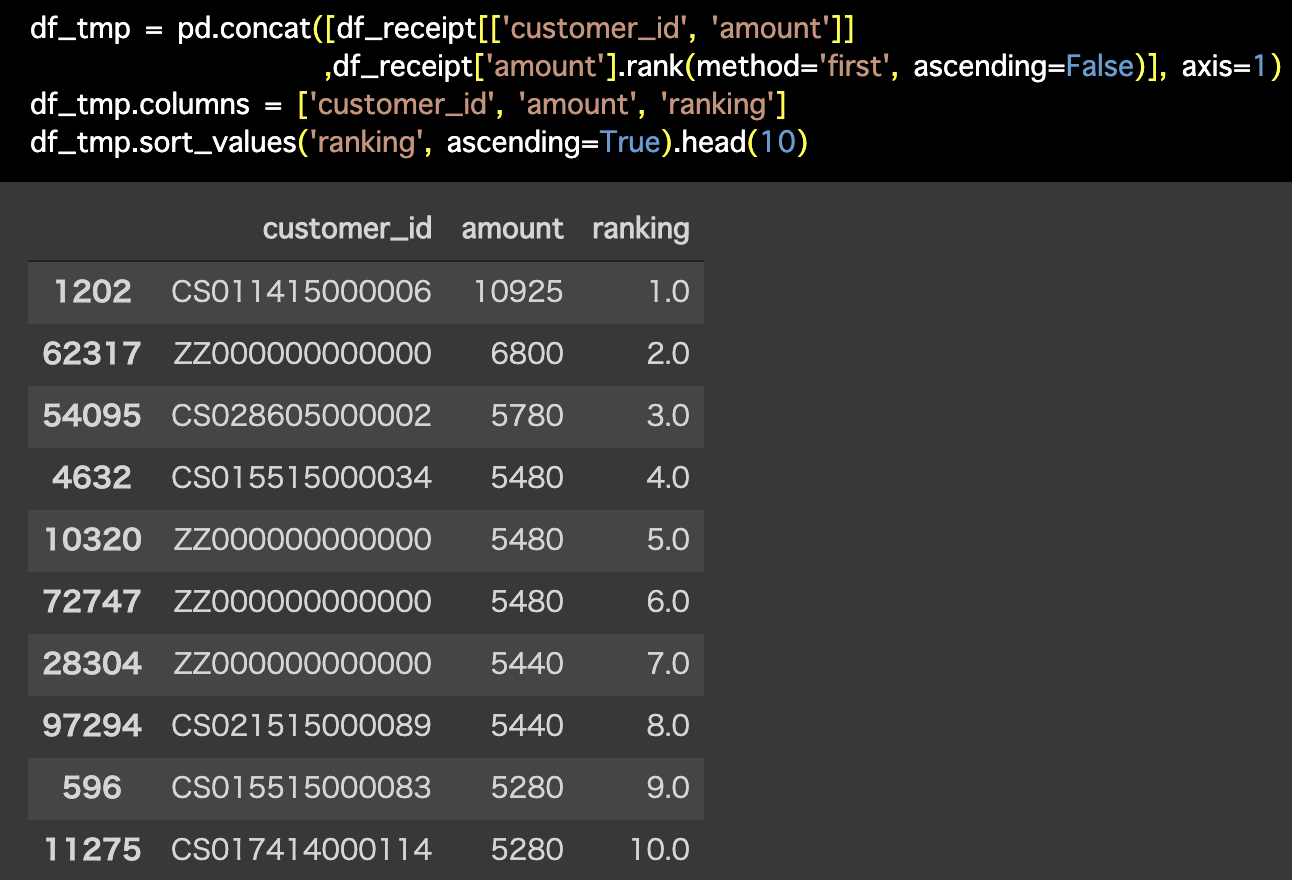
まぁ 問19 であの長さなのでこっちも似たようなもんでしょう。
違いだけみておくか...というノリで大丈夫かと思います。
Window関数 と呼び続けた理由(と本の紹介)
データ分析が注目を集め始めた時に、SQL に Window関数 が搭載されるようになりました。
今では MySQL まで Window関数 が搭載されていますが、つい最近(2017年くらい)まで搭載されていませんでした。
SQL の本来の姿は、順番をつける・行番号をつけることすらも議論されるほどでした。
そんくらいええやろ〜...と思うかもしれませんが、この著書 の第2部 :「リレーショナルデータベースの世界」をざっと読んだらわかるかもしれない...というくらい、外から見ればマニアックなことです(画像からも飛べます)。

雑談っぽいところはつまらないかも〜?
と思ったら読み飛ばしても多少は大丈夫かもしれませんね。